基于SSA-BP神经网络的概率积分法预计参数求取研究
2022-09-02吴满毅徐良骥
吴满毅 徐良骥 张 坤
(1.安徽理工大学空间信息与测绘工程学院,安徽 淮南 232001;2.矿山采动灾害空天地协同监测与预警安徽普通高校重点实验室,安徽 淮南 232001;3.深部煤矿采动响应与灾害防控国家重点实验室,安徽 淮南 232001)
概率积分法预计参数与地质采矿条件密切相关,其求取精度直接影响了沉陷预计结果的精度[1-2]。近年来,不少学者采用多种方法求解概率积分法预计参数,并对算法进行了优化,取得了丰硕成果[3-6]。郭文兵等[7]采用BP神经网络求取概率积分法预计参数,通过给定样本建立一种网络结构,这种结构能够根据输入数据尽可能准确地输出结果,但网络结构的不同会影响输出结果的准确性,而网络结构的构建依赖于各种参数变量(如隐含层个数、隐含层节点数以及训练集和测试集的样本大小)选取,它们都会影响最终构建的BP神经网络,从而影响参数预计的效果。因此,需要通过科学的方法确定该类变量取值,其中比较有效的方法是优化算法。于宁锋等[8]采用粒子群算法(Particle Swarm
Optimization,PSO)改善BP神经网络前期的全局寻优能力,该方法能够以较大概率保证最优解,提高概率积分法预计参数的求取精度;牛亚超等[9]采用了遗传算法(Genetic Algorithm,GA)优化BP神经网络,建立了GA-BP神经网络模型求解概率积分法预计参数,该模型加快了神经网络的收敛速度,使得概率积分法预计参数的求取精度有了进一步地提高;吕伟才等[10]采用多种族遗传算法(Multi-Population
Genetic Algorithm,MPGA)优化BP神经网络的权值和阈值,建立了MPGA-BP神经网络模型,通过试验验证了该优化算法的有效性。上述优化算法在很大程度上克服了BP神经网络参数选择的困难,提高了概率积分法预计参数的求解精度,但仍然存在全局寻优能力较差且收敛速度慢等不足,降低了预计参数的求解效率。2020年,薛建凯根据麻雀觅食和反捕食行为提出了麻雀搜索算法(Sparrow Search
Algortihm,SSA),该算法寻优能力强、收敛速度快,具有较好的稳定性[11]。针对BP神经网络求解概率积分法预计参数出现的局部最优解和收敛速度慢的问题,本研究利用麻雀搜索算法优化BP神经网络模型结构,得到最优的权重值和偏置项,建立SSA-BP神经网络组合预测模型,确定概率积分法预计参数。结合50组实测数据进行试验,并将试验结果与BP神经网络模型相比较,验证SSA-BP神经网络的可靠性。
1 SSA-BP神经网络模型构建
1.1 麻雀搜索算法
麻雀是一种小型群居性鸟类,集体觅食时会有明确的分工与合作,按照分工它们的身份可以分为发现者、加入者和侦察者[12-13]。发现者一般为整个麻雀群体寻找食物并为其提供觅食方向;加入者则是通过发现者获取食物;侦察者则是在群体觅食时进行安全警戒,一旦有危险靠近会发出信号提醒正在觅食的麻雀,使其远离危险。麻雀在觅食过程中会根据自己的分工和危险情况及时调整自己的位置,以适应变化[14-17]。薛建凯[11]根据麻雀群体觅食时的这些特点,提出了麻雀搜索算法,并给出了适应度求取方法。假设麻雀群有n只麻雀,每只麻雀可能出现在d维的搜索空间中,那么所有麻雀可能出现的位置就可以组成一个矩阵,即:

则n个麻雀的适应度值可以按下式求取:

式中,e为每只麻雀的适应度值,适应度值的好坏决定着麻雀种群中谁会是发现者。
发现者为了寻找食物通常比其他麻雀具有更大的搜索范围[11],在每一次觅食过程中,发现者的位置会有如下更新:

式中,t为当前迭代次数;i表示第几个麻雀;j为变量维数;itermax为最大的迭代次数;Yi,j表示的是第i个麻雀在第j维中的位置信息;α为随机数,α∈(0,1];Q为随机数,服从均值为0、方差为1的标准正态分布;L为一个1行d列的矩阵,其各元素都为1,R2为预警值,R2∈[0,1];ST为安全值,ST∈[0.5,1]。当R2<ST时,表示麻雀觅食附近没有威胁者,发现者可以搜索更广泛的区域;若R2≥ST,此时侦察者发现觅食附近有威胁者,就会发出信号提醒其他麻雀,其他麻雀根据信号快速飞往安全区域。
对于加入者,在觅食过程中,它们通过监视发现者找到食物,并与发现者进行争夺,赢了就会获得发现者的食物;否则,继续监视发现者。加入者的位置更新满足如下关系:

3种类型的麻雀中,负责警戒周围的麻雀发现危险靠近时,立刻发出信号提醒其他麻雀移动到安全区域,此时位置变化可用下式表示:

1.2 基于SSA-BP神经网络的概率积分法预计参数求取模型
BP神经网络是一种按误差逆向传播算法训练的多层前馈网络[8],通过获取一定数量的样本数据进行训练,一直更新神经网络的权重值和偏置项使得误差函数沿着负梯度方向下降,直到满足要求为止。但是其在进行非线性拟合时,容易陷入局部最优解和收敛速度慢的问题。为此,本研究利用麻雀搜索算法不断地纠正BP神经网络训练时的隐含层节点数,得到最优的权重值和偏置项,以此来缩小网络的输出值与期望值之间的误差,进而提高BP神经网络的收敛速度。SSA-BP神经网络模型流程如图1所示。具体步骤为:①获取实测数据,对数据进行预处理,并将数据随机分成两组,一组作为训练样本,剩下的作为测试样本;②确定BP神经网络的激活函数;③ 重置BP神经网络的网络结构参数;④ 由式(3)计算种群的适应度和最优个体;⑤ 通过觅食与反捕食行为更新个体,即由式(3)、式(4)、式(5)计算更新发现者、加入者和侦察者的位置;⑥判断是否满足收敛精度要求,满足则执行下一步,否则,返回步骤(4),继续寻找最优位置;⑦将得到的最优位置赋给BP神经网络的权重值和偏置项,得到训练后的模型,再输入测试样本进行求解和模型精度验证。

图1 SSA-BP神经网络建模流程Fig.1 Flow of SSA-BP neural network modelling
2 实例测试与结果分析
2.1 模型设置与精度对比方法
2.1.1 SSA-BP神经网络模型设置
概率积分法预计参数与地质采矿条件密切相关,本研究从文献[1]、[7]、[9]和淮南矿区共487组采煤工作面的实测数据中均匀地选取厚松散层、中厚松散层和薄松散层共50组数据进行该模型验证,具体数据见表1。

表1 采煤工作面实测数据Table 1 Measured data of coal mining face

续表
以H、h、M、α、N、n、f共7个地质采矿条件参数作为 SSA-BP 神经网络的输入值,以q、b、θ、tanβ和s/H5个概率积分法预计参数作为SSA-BP神经网络的输出值。将数据经过随机函数乱序后分成两组,一组作为训练样本,共有45组数据;另一组作为测试样本,共有5组数据,用于检验SSA-BP神经网络的精度。由于每个概率积分法预计参数的最优权重值和偏置项可能不同,本研究采用多输入层单一输出层,即7个输入节点1个输出节点,建立5个独立的优化模型。经测试,确定BP神经网络的激活函数为softlim,学习速率为0.01,发现者比例设置为0.7,剩下的为加入者,同时意识到危险的麻雀的比重设置为0.2。
2.1.2 精度对比方法
本研究通过平均绝对误差(MAE)、均方根误差(RMSE)和平均绝对百分比误差(MAPE)来衡量两个模型的求解精度[18]。平均绝对误差用来评估求解结果和实测数据之间接近的程度,其值越小说明模型拟合效果越好;均方根误差是指模型输出结果和实测数据偏差的平方与测试集数量比值的平方根,其值越小说明模型精度越高;平均绝对百分比误差是用于评价模型优劣最受欢迎的指标之一,取值范围为[0,+∞),0表示完美模型,大于100%则表示劣质模型。具体计算公式为

式中,xi为实测值;为模型输出结果;n为样本数量。
2.2 结果分析
2.2.1 模型预测精度评价
BP神经网络模型与SSA-BP神经网络模型精度对比见表2。由表2可知:SSA-BP神经网络模型求解的各项参数的平均绝对误差和均方根误差都接近0且小于1。而BP神经网络的平均绝对误差和均方根误差虽然都接近0,但该模型求解的开采影响传播角θ的平均绝对误差和均方根误差均大于1。由此可见,麻雀算法优化的神经网络模型预测精度更高。从平均绝对百分比误差上看,SSA-BP神经网络的最大值为9.33%,比BP神经网络的最大值小10.27%,说明SSA-BP神经网络预计概率积分法参数精度高、模型稳定。

表2 BP神经网络模型和SSA-BP神经网络模型精度对比Table 2 Comparison of Accuracy between BP Neural Network Model and SSA-BP Neural Network Model
2.2.2 模型解算结果对比
经测试,得出下沉系数最佳隐含层节点数为5,水平移动系数最佳隐含层节点数为9,开采影响传播角最佳隐含层节点数为16,主要影响角正切值的最佳隐含层节点数为20,拐点偏移距的最佳隐含层节点数为13。
模型输出结果经整理如图2所示。由图2可知:SSA-BP神经网络模型和BP神经网络模型两者的解算结果都能很好地接近实测数据,但SSA-BP神经网络模型绝对误差更小,说明其模型预测结果比BP神经网络模型更接近实测值。

图2 测试集输出结果对比Fig.2 Comparison of test set output results
BP神经网络模型与SSA-BP神经网络模型解算结果见表3。由表3可知:SSA-BP神经网络模型5组测试集输出结果的最大相对误差为21.00%,最大迭代次数为89,BP神经网络模型输出结果的最大相对误差为35.00%,最大迭代次数为205,且前者相对误差总体比后者小。说明SSA-BP神经网络模型的输出结果精度更高,迭代次数明显降低。对于第49组中两种模型求解的水平移动系数值,SSA-BP神经网络模型求解精度不及BP神经网络模型,这是由于每组地质采矿条件不同,其个别结果可能会出现BP神经网络模型输出值精度优于SSA-BP神经网络模型输出值的现象,但是并不影响整体的概率积分法预计参数的求取精度。
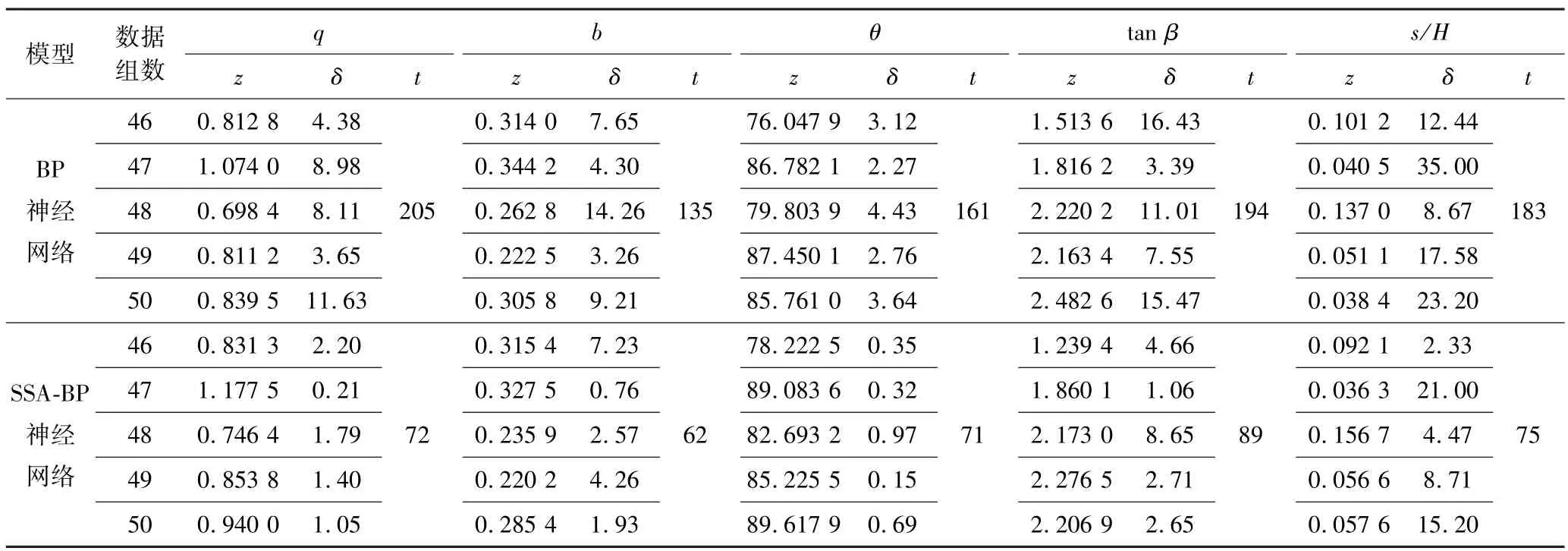
表3 BP神经网络模型和SSA-BP神经网络模型解算结果对比Table 3 Comparison of solution results between BP neural network model and SSA-BP neural network model
2.2.3 训练样本数量对模型精度的影响
为检验测试样本数量对SSA-BP神经网络模型精度的影响,利用表1实测数据,保持样本总量不变,将测试样本数量分别设置为3~7组,其结果如图3所示。为方便比较,图3中平均绝对百分比误差换为小数形式。由图3可知:在误差允许范围内,随着测试样本数量的增加,即训练样本数量随之减少,平均绝对误差、均方根误差和平均绝对百分比误差逐渐增高,这说明模型预测精度与训练样本数量有关,训练样本数量越多,神经网络的学习效果越好,预测精度越好,反之,则越差。

图3 测试集数量对模型精度的影响Fig.3 The influence of the number of test sets on model accuracy
3 结 论
(1)针对BP神经网络模型求取概率积分法预计参数出现的局部最优解和收敛速度慢的问题,建立了基于SSA-BP神经网络的概率积分法预计参数求取模型。利用SSA优化BP神经网络模型的网络结构,得到最优的权重值和偏置项,提高了模型收敛速度,并结合50组工作面实测数据对模型进行了验证,同时讨论了模型训练样本数量对模型精度的影响。
(2)经验证,相较于BP神经网络模型,SSA-BP神经网络模型的MAE、RMSE和MAPE值更小,说明优化后的模型精度更高。优化后模型求解的概率积分法预计参数最大相对误差为21%,比BP神经网络模型的最大相对误差小14%,且优化后的模型收敛速度更快。同时保持样本总数不变的情况下,随着训练样本数量增加,模型精度越来越高。
(3)基于SSA-BP神经网络的概率积分法预计参数求取模型的构建,对于概率积分法预计参数精确求取有一定的参考价值,但该模型存在局部寻优能力较差的不足,后续工作中需兼顾全局寻优能力和局部寻优能力,对其进行进一步优化。
