基于改进Fairmot 框架的多目标跟踪
2022-09-01席一帆何立明
席一帆,何立明,吕 悦
(长安大学 信息工程学院,陕西 西安 7100064)
1 引 言
多目标跟踪最初源于雷达技术的研究。在军事上,数据关联算法利用目标的位置和运动信息进行轨迹和观测目标的匹配。近年来,随着我国视频监控和无人驾驶行业的飞速发展,基于视频的多目标跟踪技术显得尤为重要。多目标跟踪根据初始化的方式划分为基于检测跟踪的流程和基于人工初始化的跟踪流程。由于基于人工初始化的跟踪无法处理轨迹的生成和消亡,因此基于检测的跟踪为当前的主流方式。基于检测的跟踪包括目标检测和数据关联,两者功能相互独立,但却在关系上紧密联系,良好的检测器能为数据关联提供较好的观测结果。
早期的目标检测主要依靠人工设计的特征训练支持向量机进行分类。2005 年,Dala[1]利用HOG 特征来训练分类器;2008 年,DPM[2]检测器依据改进HOG 特征,采用根滤波器和部件滤波器在多尺度金字塔上滑动检测;2014 年,随着深度学习的兴起,传统的目标检测方式被逐渐取代;R-CNN[3]在传统目标检测方式的基础上,以卷积神经网络作为特征提取器,训练支持向量机;Fast-RCNN[4]是首个利用全卷积神经网络训练的目标检测器。Faster-RCNN[5]提出区域建议网络,对任意尺度输入的图像都会生成一组后选框,首次引入锚框机制,速度比Fast-RCNN 快一个数量级。YOLO[6-9]系列框架主要基于锚框(Anchor)机制,将目标的位置和尺寸视为回归问题,该系列框架检测速度快,但锚框机制存在正负样本不均衡,超参数管理复杂等缺点。近些年,基于关键点的目标检测逐渐兴起,Cornernet[10]通过利用目标的左上角点和右下角点对目标进行定位。Centernet[11]通过中心点对目标的尺寸、位置和中心点的偏移量进行预测,拥有更高的检测效率。
数据关联负责将目标的轨迹与观测目标进行匹配。数据关联算法分为确定性优化算法和概率推断算法。确定性优化算法将其建模成优化问题,通过优化算法解决匹配问题。二分图匹配模型[12]、动态规划[13]、最小成本最大流网络模型[14]、条件随机场[15]和最大权值独立集模型[16]属于确定性的优化模型。概率推断模型基于现有的观测状态估计目标状态的概率分布。卡尔曼滤波[17]、扩展卡尔曼滤波[18]和粒子滤波[19]属于概率推断模型。
端到端的多目标跟踪框架近些年飞速发展,将目标检测和数据关联都用神经网络来处理,使得网络的训练效率得到提升。DAN[20]跨帧提取特征,计算亲和性矩阵,并用交并比信息作为掩模进行匹配。DeepMOT[21]根据匈牙利算法不可微分的特点,通过MOTA 和MOTP 的跟踪指标创建损失函数,训练深度匈牙利网络替代数据关联。DMAN[22]提出空间注意力模块和时间注意力模块,空间注意力模块匹配两幅图像空间相同区域,时间注意力模块对历史轨迹分配不同的权重,滤除不可靠的轨迹。本文基于检测与数据关联的Fairmot[23]框架,提出一种改进算法,提高对目标对象的跟踪精度。
2 Fairmot 基本框架
Fairmot 框架的目标检测部分包括主干网络、目标检测分支和行人重识别分支。数据关联部分采用DeepSort[24]框架进行匹配。
2.1 主干网络
Fairmot 框架采用改进后深度聚合网络作为特征提取网络,该特征提取网络采用可变形卷积适应不同尺度目标。通过不同层级的跳级连接进行语义信息和空间信息融合,使深度聚合网络以目标尺度、分辨率为关注点。
2.2 目标检测分支

视频帧经过主干网络会产生下采样4 倍的特征图,当目标的中心点预测结果映射回原图时会产生4 个像素的误差,因此通过中心点预测偏移
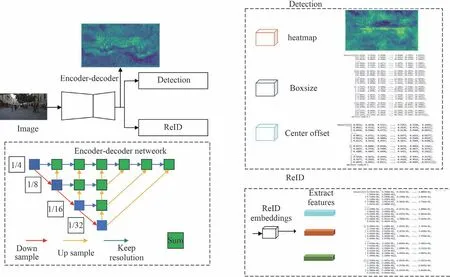
图1 Fairmot 框架Fig.1 Fairmot framework
2.3 行人重识别分支


2.4 数据关联
数据关联部分采用DeepSort 框架。如图2所示,DeepSort 首先通过级联匹配得到最初的匹配轨迹集合、未匹配的检测集合和未匹配的轨迹集合,然后将级联匹配结果中的未匹配轨迹集合和未匹配检测集合进行IOU 匹配得到最终的匹配结果。
匹配的轨迹集合作为观测结果进行卡尔曼滤波更新,经过IOU 匹配得到的未匹检测框集合。如果连续3 帧都匹配上轨迹,则认为是新的轨迹,然后进行卡尔曼滤波更新。最终的未匹配集合依据状态来判断该轨迹是否消亡。卡尔曼滤波更新得到的轨迹若为确认态则送入级联匹配,否则送入IOU 匹配。图2 右下角为部分视频的两次匹配结果。

图2 数据关联框架Fig.2 Data association framework
2.5 卡尔曼滤波
卡尔曼滤波主要分为两个阶段,分别为预测和更新阶段。卡尔曼滤波的预测阶段负责对目标状态均值和协方差进行预测,如式(7)和式(8)所示:

式(10)中K为卡尔曼滤波增益,x̂k和Pk为经过反馈调节后的最优轨迹值和协方差。实验中使用的状态变量为x=[u,v,r,h,u̇,v̇,ṙ,ḣ]T,(u,v)表示行人的中心点位置,r为框尺寸的长宽比,h为高,其余4 个分量表示其速度分量,实验中的状态转移矩阵和观测矩阵为:

各协方差的初始状态设置为:

3 基于Fairmot 的改进
针对Fairmot 框架的主干网络产生的高维信息缺乏维度之间的信息交互问题,采用三重注意力机制,提高对目标中心点的定位能力和特征提取能力;且由于行人重识别分支的Softmax 损失函数优化缺乏灵活性,采用Cirlce Loss 根据当前的状态选择优化程度,使其提取更为精确的身份嵌入向量。
3.1 三重注意力机制
针对深度聚合网络后端高维信息缺乏维度间信息交互的问题,通过三重注意力机制[25](图3)进行维度间信息交互。该机制能分别从(C,H),(C,W),(H,W)维度捕捉信息产生注意力掩模。其中的Z-Pool 模块通过最大池化和平均池化将特征图的第0 维度的通道数降至2,使特征图保持丰富语义信息的同时,进一步简化计算量。其公式如式(16)所示:
Z-Pool=[MaxPool0d(x),AvgPool0d(x)].(16)
第一条分支将输入的特征图(C×H×W)以H为轴进行逆时针旋转90°得到(W×H×C)的特征图,首先通过Z-Pool 单元得到(2×H×C),再利用k×k的标准卷积层、批归一化层和Sig⁃moid 激活函数层产生(1×H×C)的注意力掩模,然后通过残差连接与(W×H×C)的特征图元素相乘得到通道维度与空间高维度的注意力热图,再将特征图进行顺时针旋转90°得到(C×H×W),第二条分支与其类似。第三条分支只需捕捉空间维度的信息,无需旋转,得到空间注意力效果图。最后通过将3 条分支的注意力热图进行平均得到最终的注意力效果图。图3 分别给出了不同维度注意力掩膜作用后的注意效果图,该效果图是将四维张量在第1 维度压缩可视化得到的,展示了不同维度信息交互的过程与结果。
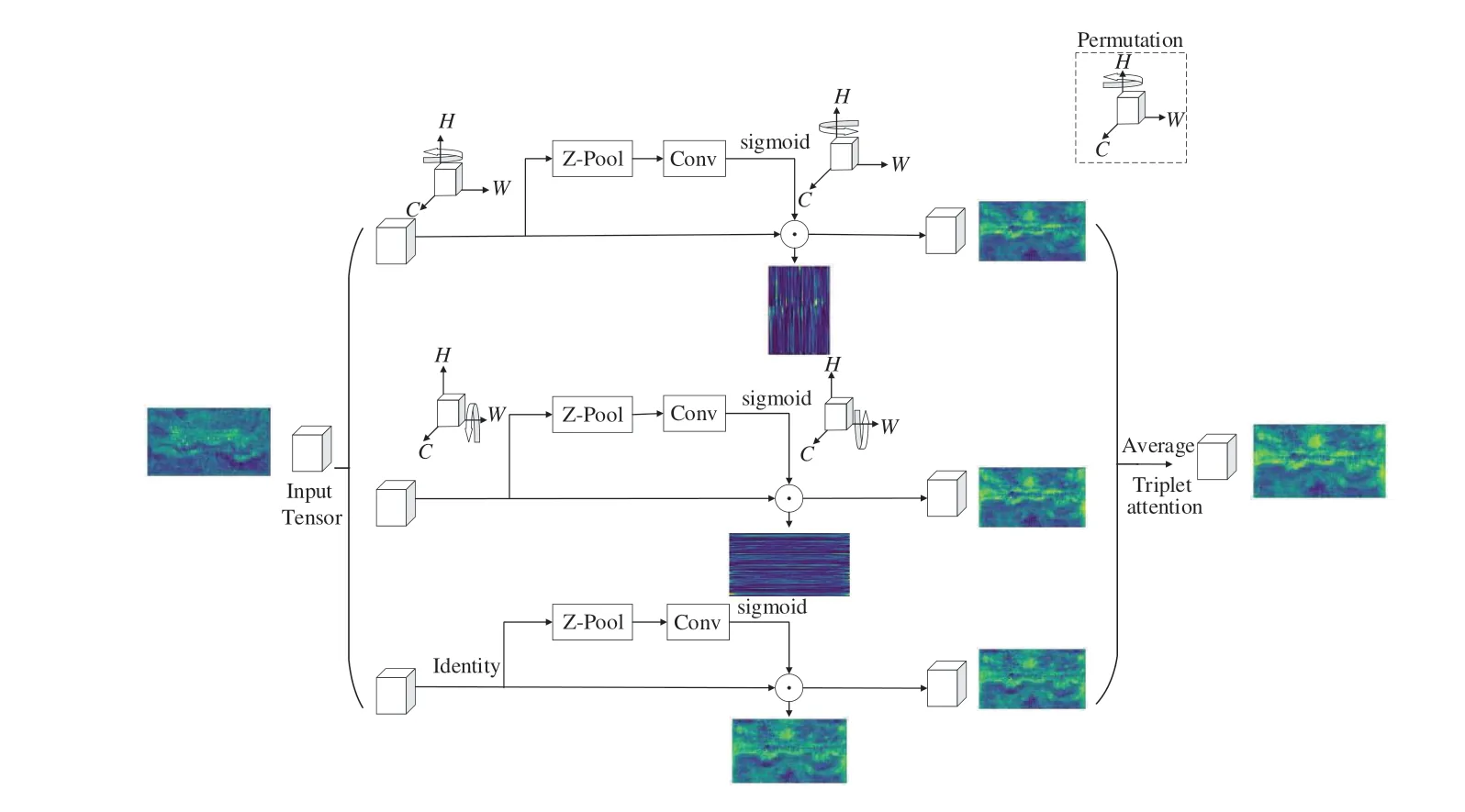
图3 三重注意力机制Fig.3 Triplet attention mechanism
3.2 Circle Loss
深度学习的目标是将类内特征的相似度最大化,类间特征的相似度最小化,因此Circle Loss[26]概括出一个统一的损失函数表达式:


该损失函数对sn和sp优化梯度相等,反向传播时的惩罚项是一样的,因此不利于寻找最优点,优化方式缺乏灵活性。Cirlce Loss 提供一个能够灵活优化目标的损失函数,其公式如式(19)所示:

4 实验结果与分析
4.1 实验环境与数据集
实验运行环境为Ubuntu 16.04 操作系统,GPU 型号为:2 块NVIDIA GeForce GTX 1080TI(11G 显存),基于Pytorch 1.3 深度学习框架。采用的数据集为MOT 数据集,MOT 数据集分为MOT15、MOT16 和MOT17,该数据集包含了静止或者移动拍摄、低中高角度拍摄以及黑夜等复杂的环境。实验首先在CrowedHuman 数据集进行预训练,然后通过MOT16 的训练集进行训练,在MOT15 的训练集进行消融实验。对比实验在MOT15 的训练集训练,通过MOT15 测试集测试。实验超参数设置如表1 所示,实验评价指标如表2 所示。

表1 实验超参数设置Tab.1 Experimental hyperparameter settings

表2 多目标跟踪评价指标Tab.2 Multi-target tracking evaluation index
4.2 消融实验
对Fairmot 模型、采用注意力机制的Fairmot(Fairmot+A)模型和采用Circle Loss 和注意力机制的Fairmot(Fairmot+A+CL)模型进行实验,结果如表3 所示。

表3 3 种模型的消融实验在MOT15 训练集上的测试结果Tab.3 Ablation experiments of the three models tested on the MOT15 training set
采用三重注意力机制后,MOTA 得到了1.1%的提升,且身份切换次数明显降低。注意力机制能够提供更可靠的目标检测,从而提升跟踪精度。Fairmot+A+CL 在采用Circle Loss 后相比原模型在MOTA 上提升3.3%,且在MOTP、MT、ML、FM 等指标上明显优于原模型。但Fair⁃mot+A+CL 模 型 与Fairmot+A 模 型 相 比,IDS指标上升许多,可能采用Circle Loss 之后对多任务学习目标检测分支的性能产生影响,产生漏检或虚检现象,使改进后的模型身份切换指标上升。
图4 展示了3 种模型的跟踪能力对比。对于图4(a)蓝色箭头所指的女士,Fairmot 模型上只在第一个视频帧中检测到该女士,在后续的视频帧中出现部分遮挡未检测出该行人。待遮挡结束时,行人身份发生切换。Fairmot+A 模型在前两幅视频帧中跟踪到该女士,采用注意力机制能够明显提高其跟踪精度,但在遮挡结束时,行人的身份发生切换。Fairmot+A+CL 模型在全程视频帧中均跟踪到该女士。可见,引入Circle Loss 之后,增强了行人重识别分支的特征提取能力,使其能够提取更精确的表观特征。

图4 3 种模型在MOT15 训练集上的测试结果Fig.4 Test results of the three models on the MOT15 training set
4.3 对比实验
如表4 所示,改进后的模型在MOTA、IDF1和MT 上要明显优于其他4 种模型。与原模型相比,MOTA 提升1.4%,MT 得到稍许提升。引入注意力机制和Cirle Loss 之后,提高了对目标的定位能力和跟踪能力,使得提取的表观特征更具区分性。

表4 5 种模型在MOT15 测试集上的对比实验Tab.4 Comparative experiments of five models on the MOT15 test set
如图5 所示,改进模型在目标检测和跟踪上明显优于其他4 种模型。对远处的小目标,改进模型跟踪效果最佳。在第195 帧中,改进模型能准确检测出坐在左侧的行人,而原模型却未检测出,表明三重注意力机制和Circle Loss 增强了对目标的定位能力和表观特征表达能力,产生了较好的跟踪效果(图6)。

图5 5 种模型在MOT15 测试集上的对比效果图Fig.5 Comparison of the five models on the MOT15 test set

图6 轨迹跟踪功能展示Fig.6 Display of trajectory tracking function
5 结 论
本文对Fairmot 框架提出两种改进措施,首先利用三重注意力机制提高对高维信息的维度交互能力,产生精确定位;然后通过Circle Loss损失函数优化行人重识别分支,使其根据当前距最优点的距离选择优化目标和程度,提取更精确的表观特征。实验结果表明,本文所提模型明显优于其他模型,在MOT15 测试集上的跟踪精度为62%,IDF1 提升至65.1%,身份切换降低68次。但是对于长时间遮挡的目标,本文方法会发生身份切换,产生较多的轨迹碎片,未来将着重研究长时遮挡问题以及模型压缩问题。
