基于级联特征和图卷积的三维手部姿态估计算法
2022-09-01林依林林珊玲林志贤
林依林,林珊玲,林志贤,3*
(1. 福州大学 物理与信息工程学院,福建 福州 350116;2. 中国福建光电信息科学与技术创新实验室,福建 福州 350116;3. 福州大学 先进制造学院,福建 泉州 362200)
1 引 言
姿态估计是计算机视觉中的热门研究领域,是对人体姿态的位置估计。姿态估计一般可以分为单人姿态估计(如Open Pose[1])、多人姿态估计(如AlphaPose[2])、人体姿态跟踪、三维人体姿态估计。在姿态估计的研究中,基于手部的姿态估计研究备受青睐。在人所有的姿态中,手势占据了90%,是最主要的人机交互姿态。未来的生活场景朝着越来越智能化的方向发展,智能家居、自动驾驶、智慧医疗及第一视角沉浸式交互等应用场景,都离不开手势交互的身影。
近年来,随着深度学习的发展,针对手部的三维姿态估计研究突飞猛进。Cai 等人[3]提出了一种弱监督网络,使用深度正则化器,将从彩色图像估计的三维手势转换成深度图,将三维坐标估计损失转化为深度图损失,有效地解决了三维关键点标记获取困难这一问题。Ge 等人[4]将手部表面网格估计加入到网络中,将彩色图像估计的二维手部的热度图通过图形卷积网络估计手表面网格,再通过手表面网格回归三维手势。该方法识别精度较高,但是手表面网格真实标记缺乏,制作合成数据也较为困难,数据获取代价较大。对于RGB 图像的三维手部姿态估计任务,手部独有的严重的自遮挡性和自相似性以及复杂的背景处理,在缺少深度信息的任务里并不容易。无约束的自然场景往往包含复杂的背景和多变的光照条件,要准确地从第一视角RGB 图像中检测出指尖的位置依然是一个具有挑战性的问题。 本文在Minimal-Hand[5]的基础上结合图卷积神经网络[6]来解决这种天然的遮挡问题,通过级联的卷积网络从粗到细优化关键点位置从而解决不自然的骨架估计。
2 网络结构
2.1 整体网络框架
在姿态估计中,常见的手部模型有21 关键点、16 关键点、36 关键点。本文采用Open Pose[1]提出的标准手部21 关键点模型。其中编号为0的关键点是手腕,其余每根手指分别有4 个关键点:指关节、近端指关节、远端指关节、指尖。本文所有对二维和三维的关键点估计都是建立在该手部模型之上。
用深度学习的方法进行手部姿态估计,一般是分阶段进行的。本文提出的网络框架按照处理目的分为4 个部分:手部的识别、手部二维关键点的检测、手部三维关键点的检测、手部三维关键点的精细化调整。
手部的识别采用轻量级网络回归手部边框(Bounding Box)作为后续主体网络的预处理操作,使得后续关键点的定位更加准确,同时处理后图片像素的减少也使得后续计算量减小。手部二维和三维关键点的检测通过搭建卷积神经网络提取图像特征,依据区域或者特征的重要程度对权重进行调配,引导级联特征提取模块获取更加丰富的基础提取特征,监督网络主动输出越来越精确的热度置信图。手部三维关键点的精细化调整是将三维关键点粗结果基于图卷积神经网络算法进行优化后处理,拟合出更加精确的手部三维关键点坐标。
2.2 基于YOLOv3 的手部识别预处理网络
常见的手部预处理方法分为基于数字图像处理方法和基于深度学习方法两大类。前者一般采取分割算法得到手部掩模定位手部区域,例如将RGB 图像转化为灰度图像再转换成二值图像并选取二值图像的前景部分作为手势提取区域[7]。
本文采取基于深度学习方法的手部预处理网络,如图1 所示。在进入主体网络流程前,先采用基于YOLOv3[8]的预处理网络用于将输入图片中的手部和混杂的背景剥离。YOLIOv3 相比其他深度学习检测网络的优势在于引入Darknet-53 作为骨干网络,采用K-means 聚类法[5]回归出9 种大小不同的先验框,并且根据金字塔特征图思想,小尺寸的先验框用于耦合大尺寸的特征图,大尺寸的先验框用于耦合小尺寸的特征图,可以很好地整合不同尺度的感受野的特征,识别输入图片中不同占比的手部。我们将自然场景下的图片输入预处理网络,通过调整Darknet-53 网络内卷积核大小可以控制输出的特征图大小,因此对任意尺寸的输入数据经过这个预处理网络都可以输出固定256×256×3 尺寸的、剥离背景单独手部的手部边框图片传输给接下来的网络。
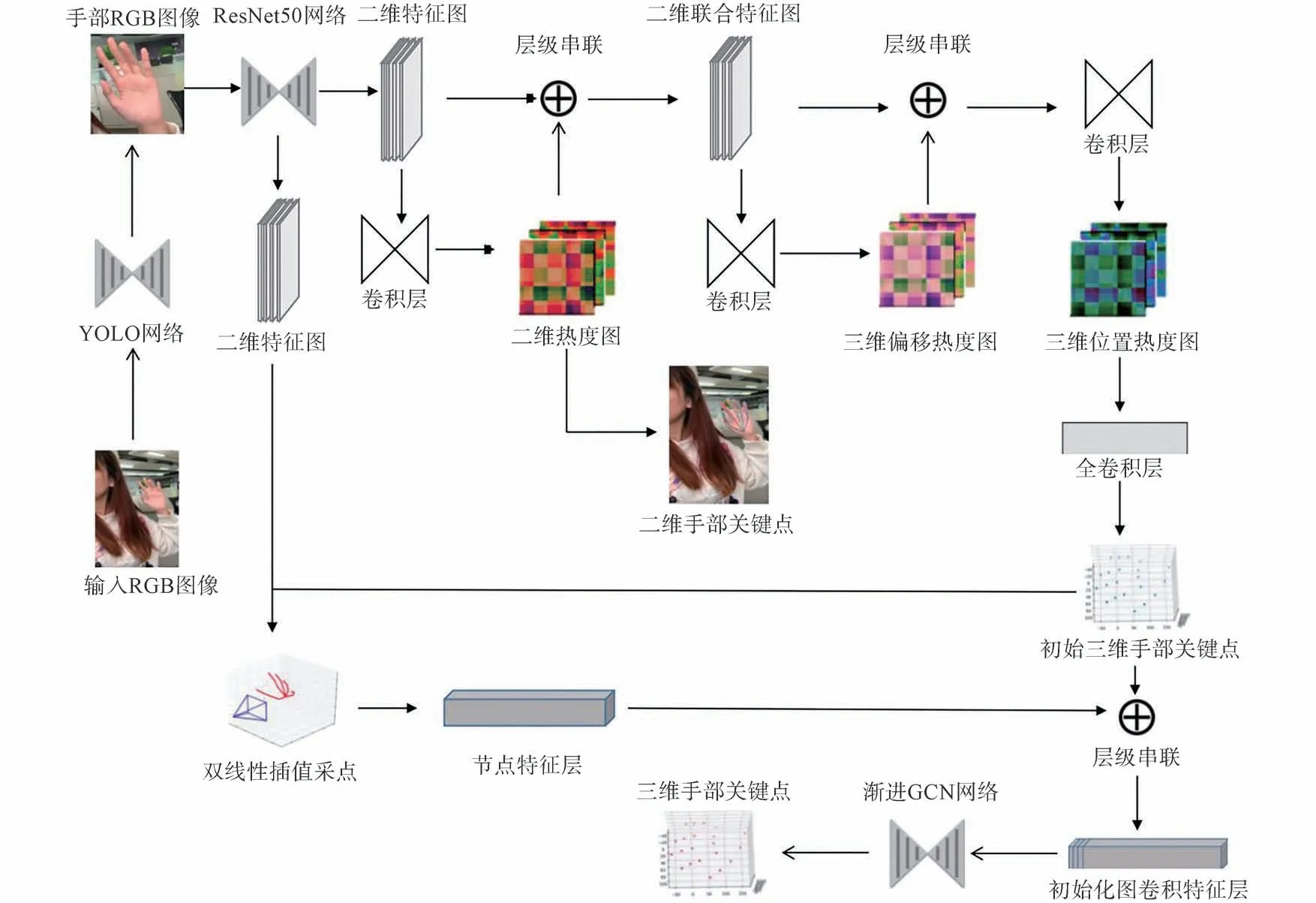
图1 网络流程图Fig.1 Network flow chart
2.3 基于级联特征提取的手部关键点检测网络
如图1 所示,二维特征提取模块使用经典的ResNet50[9]网 络,输 入256×256×3 的RGB 图 像输出32×32×256 的二维特征图。相比于直接回归关节点坐标,基于热度图的方法具有渐变连续可微分的特点,可以提高坐标估计的精细程度[10],因此我们在二维和三维检测模块融合多特征热度图。
二维检测模块是一个两层的全连接卷积层。输入32×32×256 的二维特征图,输出二维热度图(Heat Maps)。二维热度图包含21 个手部关键点的关节预测置信图,通过二维高斯函数编码每个像素点被每个关键点覆盖的置信度,其公式如式(1)所示:
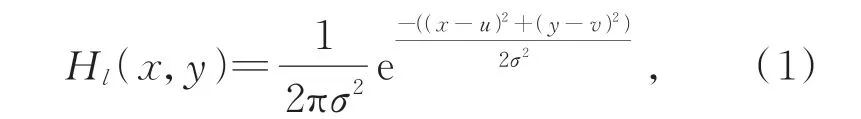
其中l代表第l个关键点,σ为函数的宽度参数,(x,y)代表该点像素坐标,(u,v)是中心点坐标,即该关键点二维真值(Ground truth)坐标。
三维检测模块从多热度图和特征图回归三维手部姿态。如图1 所示,将二维特征图和二维热度图(2D Heat Maps)进行层级串联,得到二维联合特征图,对二维联合特征图进行卷积操作,得到三维偏移热度图(3D Delta Maps)。三维偏移热度图是子节点相对于根节点的三维方向向量,可以很好地反应父子节点之间的位置关系,将三维偏移热度图作为中间热度图为三维检测模块预测结果添加运动学约束,使网络架构嵌入类似手部结构的物理限制。将二维联合特征图和三维偏移热度图进行层级串联和卷积层操作,分别从XYZ坐标轴表示的图中选择置信度最大的点所对应的值为坐标轴的数值,对XYZ轴都执行以上操作,将得到的值保存为三维坐标点[11],就 得 到 了 三 维 位 置 热 度 图(3D Location Maps)。三维位置热度图和二维热度图一样,反映了每个像素被每个手部关键点的三维坐标覆盖的预测置信度。特征提取网络具体级联结构如图2 所示,为了能更好地预测三维位置偏移量,我们先预测一个二维热度图,将其作为三维热度图的一个条件来提升对三维位置预测的准确性。之后我们再将二维热度图和三维偏移图作为共同条件和特征结合在一起去预测最后的三维位置,通过这样多层级联的条件来得到更加准确鲁棒的位置信息。
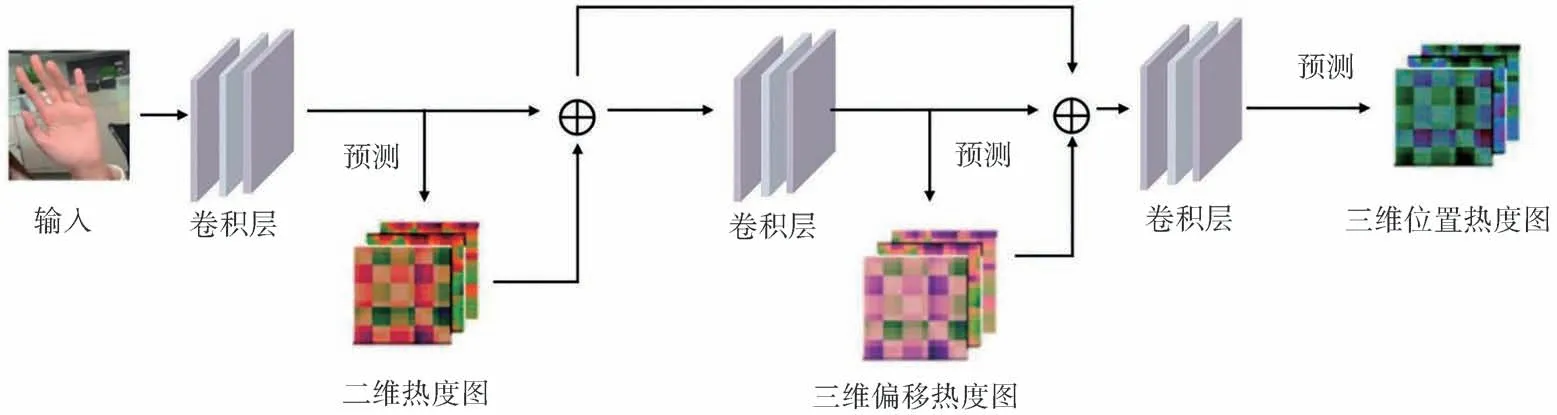
图2 级联特征提取网络结构Fig.2 Cascade feature extraction network structure
2.4 基于GCN 特征增强的手部骨架回归网络
对于手部骨架而言,它本身是一个天然的图结构。因此我们很自然地想到基于图卷积神经网络(Graph Convolutional Network,GCN)方法来获取它内部的隐式关系[12]。GCN 的计算过程与信号处理过程相同,先将卷积核和图数据通过傅里叶变换转换到频域空间,再对频域空间的系数进行数值运算,最后进行逆傅里叶变换得到卷积后的结果。
利用上述模块生成热图后,采用积分回归方法[13]将热图表示转化为坐标表示,作为GCN 特征增加网络的初始输入姿态。对热度图的初始化姿态进行softed-argmax 操作,将热图传播到Softmax 层中,该层将热度图像素值标准化为似然值(0~1)之后,再对似然图层进行积分运算求和操作,从而估算关节位置:
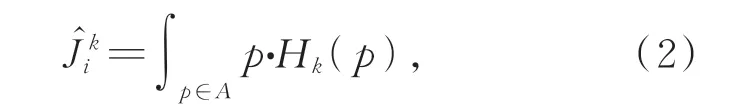
其中,Ĵk i表示第k个关节的位置估计,A表示似然区域,Hk(p)表示p点上的似然值。因此,每个热图矩阵都包含生成初始姿势的信息。
热图模块和坐标转换相互耦合,使得GCN特征增强网络可以获得更准确的初始化姿态,有助于在进行校正之前获得更精确的局部上下文理解。此外,由于尺寸的限制,基于热图的表示在一定程度上导致了关键点的量化误差,转化为坐标后可以解决这个问题。
由于手部姿态估计涉及的节点数量较多,我们使用切比雪夫多项式进行逼近。当有n个节点时,得到GCN 层与层之间传播公式如式(3)所示:
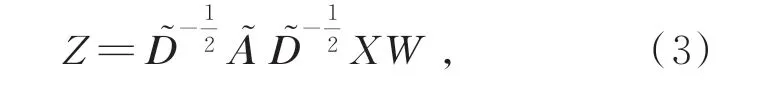
其中,D͂=D+I,A͂=A+I,I是单位矩阵,A是代表各个节点之间位置关系的n×n维的邻接矩阵(Adjacency matrix),D͂是A͂的度矩阵(Degree matrix)。X是输入层的特征,Z是输出层的特征,X∈Rn*m,m是特征向量的维度,W是网络需要学习的权重,W∈Rm*d,d是输出向量的维度。
考虑到特征图之间感受野的由粗到细,我们在模块中设计了一种从粗到精的学习过程,用于增强局部特征学习,纠正部分遮挡的手部关键点的坐标。由于基于坐标的模块缺少图像的上下文信息,我们为每个关节位置挖掘了相关的图像特征,并融合到模块中。如图1 所示,通过双线性插值采点,将从图像特征中挖掘出的初始关键点坐标(x,y)上的节点特征输入到渐进图卷积层中来改善姿态估计结果。渐进GCN 特征增强模块网络结构如图3 所示,对抽取的每个图卷积的节点特征,我们用3 个密集连接的GCN 模块来抽取特征,并通过层级1、2 的预测在每个层级中进行监督,在最后一层输出预测的三维手部关键点坐标。该机制建立了渐进的GCN 架构,并通过逐步融合多尺度图像特征来优化关键点输出。
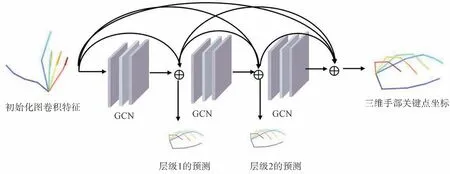
图3 渐进GCN 特征增强网络结构Fig.3 Progressive GCN feature enhancement network structure
2.5 损失函数
整体网络是基于端到端的学习,通过多任务学习的策略使得网络结果更好地收敛。损失函数的定义如式(4)所示:

其中Ω为目标点集,对于我们的手部重建的目标关键点其个数为21 个;j表示的是第j层图卷积网络的输出结果。通过这种多层级的三维骨架估计监督可以让网络表现出更好的结果。M是一维度的向量表示关键点掩模,如果关键点存在标注数据,M[i]=1,否则为0。
3 实验结果
3.1 实验指标
对于手部的骨架姿态估计而言,其本质是一个回归问题,回归问题的指标很难通过上述二分类的指标来进行度量。为了验证模型的优越性,这里使用3D 平均准确性(Percentage of Correct Keypoint,PCK)和2D 的关节点相识性(Object keypoint similarity,OKS)进行评价。3D PCK 的计算公式如式(6)所示:

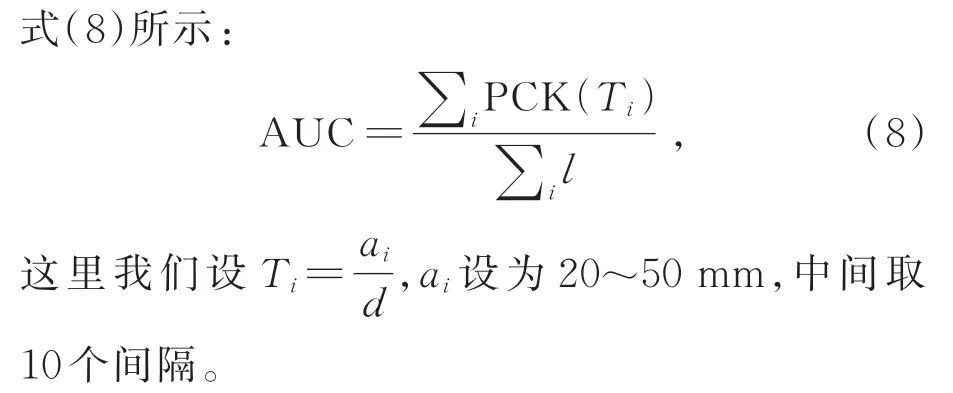
3.2 实验数据集
本文在以下5 个数据集上展开模型的训练和测试,多维度验证我们设计的人体手部姿态估计器的性能。
CMU Hand Keypoints Detection Dataset[14]是由卡内基梅隆大学发布的手部骨架估计的数 据 集。Rendered Handpose Dataset(RHD)[15]是由弗莱堡大学在2017 发布的手部姿态渲染数据 集。Dexter+Object[16]是2016 年 由 德 国 的 马 普所发布的手部重建和手部对象跟踪的数据集。Ego Dexter datasets[17]是 由MPI 于2017 年 发 布 于ICCV2017 的 数 据 集。GANeratedDataset[18]是 由MPI 在CVPR2018 年推出的数据集,该数据集主要是由GAN 生产的合成数据集。
实验所用数据的分布如表1 所示,记录了数据集所含有的标注及被本次实验用作训练集和测试集的数据量。此外,原始的Dexter[16]数据集有1 912 训练集和846 验证集,但是考虑到更加充分的验证算法,我们将1 912 个训练集也作为本次实验的测试集。
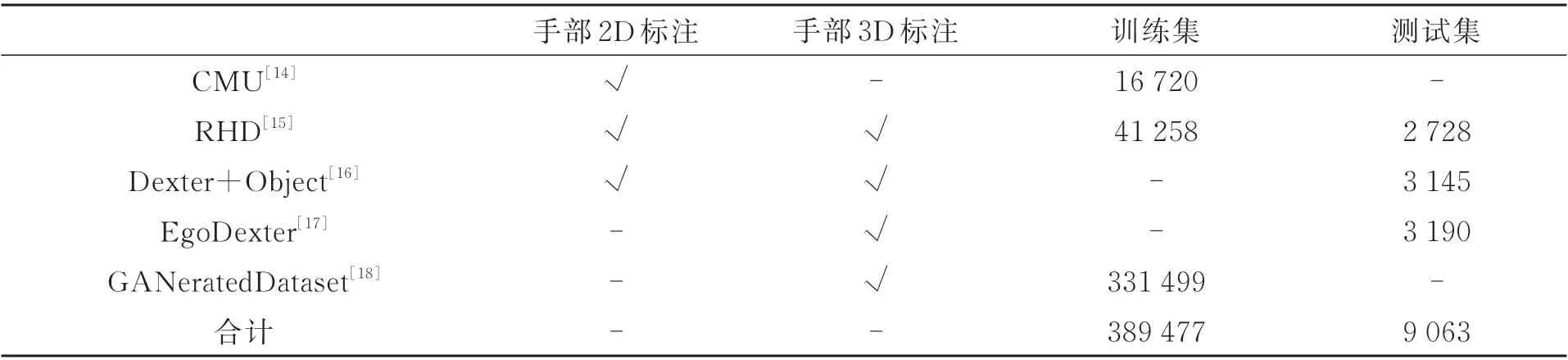
表1 实验所用数据分布Tab.1 Distribution of data used in the experiment
3.3 结果与分析
实验过程中的数值曲线如图4 所示,其中图4(a)是训练过程中的损失曲线,lossH 是二维热度图损失值,lossD 是三维偏移热度图的损失值,lossL 是在经过渐进GCN 模块后的三维关键点损失值。从图4(a)可以看出,输出的粗结果在经过多热度图耦合的三维关键点检测器和渐进的GCN 模块的精细化调整后可以收敛出更低的损失值。图4(b)、(c)、(d)分别表示在RHD[15]、DO[16]、ED[17]测试集下每个训练周期下的AUC 值。
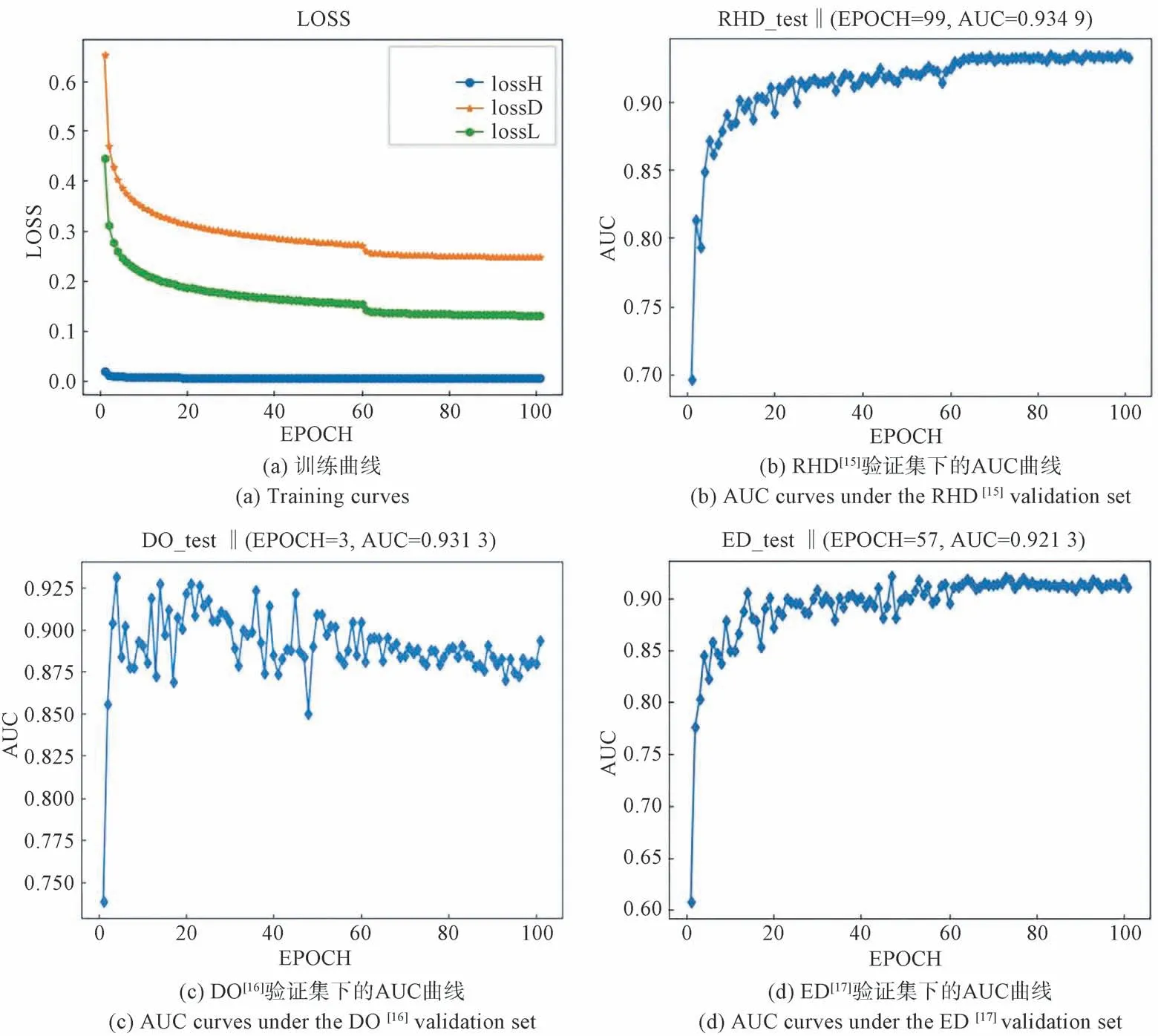
图4 网络训练时的损失函数曲线和在验证集下的AUC 精度曲线Fig.4 Loss function curves during network training and AUC accuracy curves under the validation set
本次实验主要和Xiong Zhang 等人提出的Mesh2HAND[19]、Donglai Xiang 等人提出的Mon-Cap[20]、Adnane Boukhayma 等 人 提 出 的3D pose in the wild[21]以 及Y X Zhou 等 人 提 出 的Minimalhand[5]进行对比。
定量的实验结果与上述4 种方法比较对照如表2 所示,其中20 mm 和30 mm 分别指当阈值取相应值时的PCK 值,AUC 是当阈值取20~50 mm时的PCK 曲线面积值。由表2 可见,我们所改进的方法在3D 骨架回归任务上的结果在各个数据集上的AUC 曲线都优于其他方法。具体来说,我们所提出的方法相较于Minimal-hand[5]在DO 数据集上AUC 大约高了0.8%,在ED[17]数据集上比Minimal-hand[5]AUC 大约高了0.7%。对于RHD[15]数据集,我们所设计的方法比Mesh2 Hand[19]AUC 高了大约3%。就单纯的PCK 值而言,我们所提出的方法更加接近于真实值,在阈值设为20 mm 处,我们提出的方法在DO[16]数据集上比最好的方法高了0.9%,在RHD[15]数据集上比最好的方法高了0.8%。虽然在ED[17]数据集上略低于最好的方法,但是在阈值30 mm 处,我们提出的方法远高于最好的方法(相较于Minimalhand[5]高了大约3.7%)。
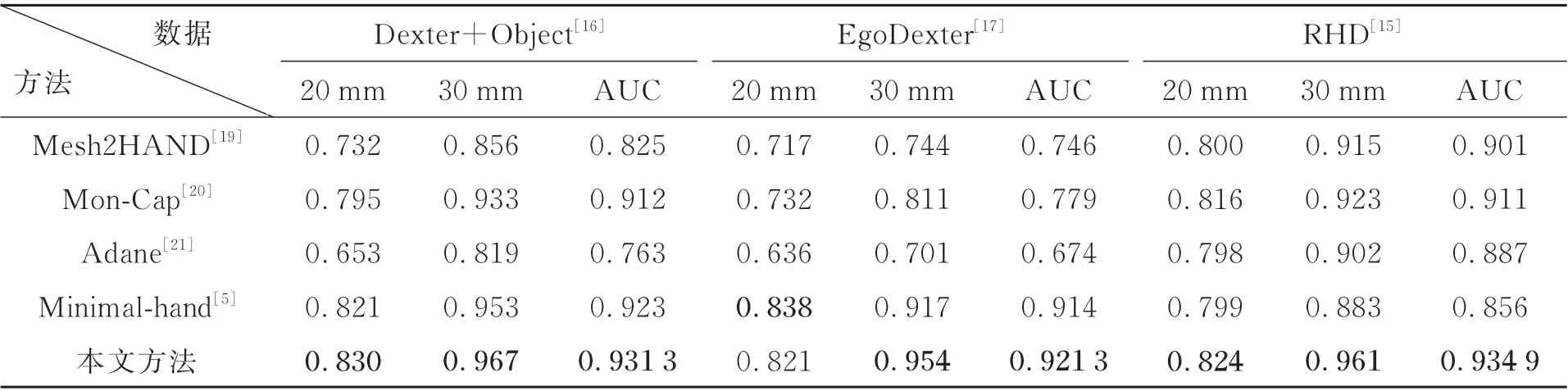
表2 本文方法与其他方法实验结果对比Tab.2 Comparison of experimental results between this method and other methods
本次实验的操作系统为Ubantu18.04,CPU核为i5-6500,GPU 的配置为GTX-2080 11 GB。在图像分辨率为256×256 的情况下,对算法处理时间和所需功耗进行分析。如表3 所示,算法所需的推理时间为52 ms,算法所需的每秒浮点计算量(FLOPs)为9.3×108次。结合算法对照实验分析可知,我们提出的算法在处理时间上和模型复杂度上处于较优水平,不仅推理时间和计算量近 似 于Minimal-hand[5],而 且 姿 态 估 计 精 度 在 多个数据集上都超过了Minimal-hand[5]的效果。
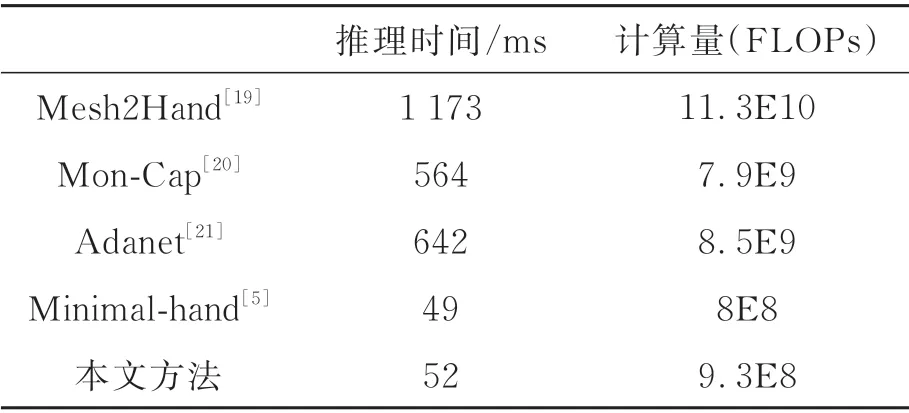
表3 推理速度与浮点计算量比较Tab.3 Comparison of the time of inference and FLOPs
该结果表明在不影响算法速度的情况下,我们提出的算法在效率上得到了较大的提升,识别推理的帧率(Frames Per Second,FPS)达到了19.23,因此该算法可以使用在视频流的实时手部骨架检测中。与此同时,较小的计算量满足了对模型低功耗、轻量化的需求。
我们选择在上述定量分析中4 个对照方法中精度指标表现最好的Minimal-hand[5]作为定性分析对象。定性的可视化结果如图5所示(在RHD[15]测试集上的检测结果)。从图中高亮部分的细节可以看出,本文算法在测试集上的结果明显优于Minimal-hand[5]算法。在引入渐进GCN 模块后,手部骨架耦合了图结构的约束,使得其在一些自遮挡比较严重的场景下,也能够检测出合理的结果。
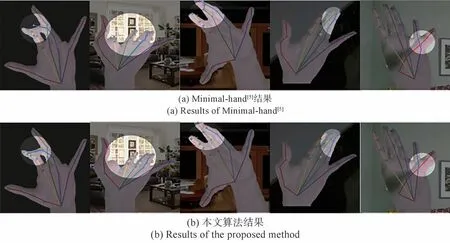
图5 可视化实验结果对比Fig.5 Comparison of visualization experimental results
在自然场景下,涉及手物交互时骨架回归结果如图6 所示。由于人手在抓取物体过程中出现了大面积的遮挡,导致骨架回归结果在尺度的还原上有些许偏差。除了部分关键点遮挡因素外,我们分析误差的产生还有以下原因:由于当前手部3D 训练数据集真实数据不足,因此参与实验的训练数据大多是CG 合成的虚拟3D数据集,或者是通过实验室设备所收集的特定场景下标定好的真实数据集,并且单目RGB 相机在投影时失去了深度信息。因此将该算法用于自然场景下时,存在着较大的状态空间误差(Domain Gap),从而导致了些许计算误差。此外,最终输出的3D 坐标的回归在一定程度上依赖于初始化的3D 坐标位置,在初始坐标位置偏差较大时,会导致系统估计的姿态坐标产生回归误差。

图6 自然场景下的可视化结果Fig.6 Visualization results in the wild
尽管如此,本文模型在精度指标上和大致的形体姿态上还是表现得足够精准,总体上算法可以在自然场景下给出合理的估计结果,这体现了我们算法整体的鲁棒性。
4 结 论
本文所提出的三维手部姿态估计算法通过结合人体关节结构之间的基本约束信息以及级联神经网络和渐进图卷积神经网络挖掘出的特征图中包含的被遮挡关键点的相关数据,能够精确地调整被遮挡关键点的位置,对于人体手部骨架的检测有较高的正确率。我们在3 个公开数据集上验证了网络性能,与现有的4 种算法进行实验比对,本文算法在30 mm 阈值下的PCK 精度表现非常出色,最低精度达到95.4%,高出次优算法3.7%精度值。并且在3 个测试集上的AUC 曲线指标均达到最高,平均AUC 精度达到92.9%。经过与其他方法的定量、定性类比,可以看出本文算法在三维关键点预测精度上比现有的方法有明显提高,并且可视化实验结果表明,本文算法在图像细节的捕捉上也具有优势。此外,本文方法推理的帧率达到了19.23,可以满足实时视频流检测的需求。模型所需FOLPs 为9.3×108次,复杂度较低,满足对模型轻量化的要求。综上,本文基于多任务学习的方法提出了一种端到端的训练方式,加速了网络的收敛,减少了特征的过拟合,使得网络在三维手部姿态估计任务上准确性和鲁棒性相比于现有技术有较为显著的改进。
