基于BO-XGBoost的煤自燃分级预警研究
2022-08-24王认卓代亚勋张九零孙玉雯
周 旭,王认卓,代亚勋,张九零,,孙玉雯
(1.华北理工大学 矿业工程学院,河北 唐山 063210;2.华北理工大学 人工智能学院,河北 唐山 063210)
矿井火灾严重威胁着煤炭的安全生产,据不完全统计,矿井火灾事故90%以上是因为煤自燃引起的。因此,合理划分煤自燃阶段,精准地确定煤自燃等级,构建煤自燃分级预警模型对矿井安全生产及矿工人身安全具有重要意义[1-3]。
近年来,相关专家学者针对煤自燃预警和煤自燃分级问题主要进行了两方面研究:一方面,不断探索各种机器学习算法对煤自燃温度的预测效果,寻找具备更优普适性及准确性的预测模型。邓军等[4]提出结合PCA、PSO、支持向量机的煤自燃温度预警方法,昝军才等[5]利用BP神经网络构建煤自燃温度预测模型。但SVM预测效果对模型的参数比较敏感,BP神经网络存在过拟合现象,使得煤自燃温度预测并未达到理想状态。刘宝等[6]提出了一种基于相关向量机算法构建煤自燃温度预测模型,郑学召等[7]将随机森林算法应用到煤自燃温度预测问题,相较于支持向量机、神经网络,其预测精度得到了较大的提升。以上研究主要基于机器学习算法构建温度回归预测模型,为煤自燃温度预测提供了新的方法。另一方面,快速、准确确定煤自燃风险等级,进而采取合理防控措施阻止煤自燃。为有效划分煤自燃等级,相关专家学者通过分析煤自燃各阶段的气体指标特征,寻找指标参数特征点位,挖掘关联关系确定阈值进而划分煤自燃预警等级。谭波等[8]选取特征温度点的碳氧化物比率作为预警界限,划分4个等级预警机制,同时结合灰色关联分析法细化预警原则。周言安等[9]结合煤自燃指标气体的温度走势规律,确定临界阈值,划分了适合于顾北煤矿的煤自燃分级预警体系。张铎等[10]结合Satava推断法和Popescu法分析煤样质量随温度的变化规律,确定预警等级临界温度点。赵敏等[11]根据遗煤自燃特征,提出了一种基于模糊聚类法和遗传算法的遗煤火灾检测方法。翟小伟等[12]以系统工程理论为基础,建立基于SEM的煤自燃危险等级综合评价体系。郁亚楠等[13]以唐家矿6号煤层为实验基础,提出将单指标气体、综合指标和标志气体三者结合的煤自燃“三位一体”预报技术。上述研究通过指标气体法、模糊聚类法、测温法等方法划分特定煤层对象分级预警界限,对煤自燃预警和防治具有一定指导意义。由于不同煤矿地质结构、开采环境、煤质组成等因素的不同,相同气体指标在数值上存在很大差异,因此,煤自燃等级阈值也会随着矿井的不同而发生变化。
基于此,为了快速、准确确定煤自燃危险等级,提高煤自燃分级预警精准性与鲁棒性,提出构建基于贝叶斯优化XGBoost的煤自燃分级预警模型,并与传统预测模型进行对比分析,结果显示BO-XGBoost模型在优化方法寻优速度和模型准确率方面具有明显的优势。为进一步验证模型鲁棒性与稳定性,将模型应用到唐山某矿的煤自燃分级预警中。该研究对煤自燃分级预警预报具有重要意义。
1 基本原理
1.1 贝叶斯超参数优化算法
在机器学习中,优化超参数的方法有随机搜索,网格搜索和贝叶斯优化等方法。贝叶斯优化相较于随机搜索和网格搜索,能够在较短的迭代时间内获得较优的参数组合。因此,近年来贝叶斯优化算法在参数寻优领域得到了广泛应用[14]。其中,概率代理模型和采集函数[15]是贝叶斯优化算法中两个重要部分。为了使目标函数代理模型更贴近真实函数,应用概率代理模型增加试验次数。采样函数在最大概率出现全局最优区域选取新的样本点,通过不断迭代更新样本点,使目标函数最小。
高斯过程(GP)与树形Parzen估计器(TPE)是常用的概率代理模型,最大概率提升(PI)与最大期望提升(EI)[16]是常见的两种采集函数。TPE相较于GP在效率和精度上均有提高,因此选择TPE和EI作为贝叶斯优化的概率代理模型和采集函数。
TPE对先验概率p(x|y)与目标函数评估值概率p(y)定义,TPE定义的p(x|y)如式(1)所示。
式中,x为超参数组合;y为目标函数评价函数值;y*为目标函数评价函数最大值;当x(i)的损失函数小于y*时,概率密度函数为l(x);当x(i)的损失函数大于等于y*时,概率密度函数为g(x)。
最大期望提升EI如式(2)所示。
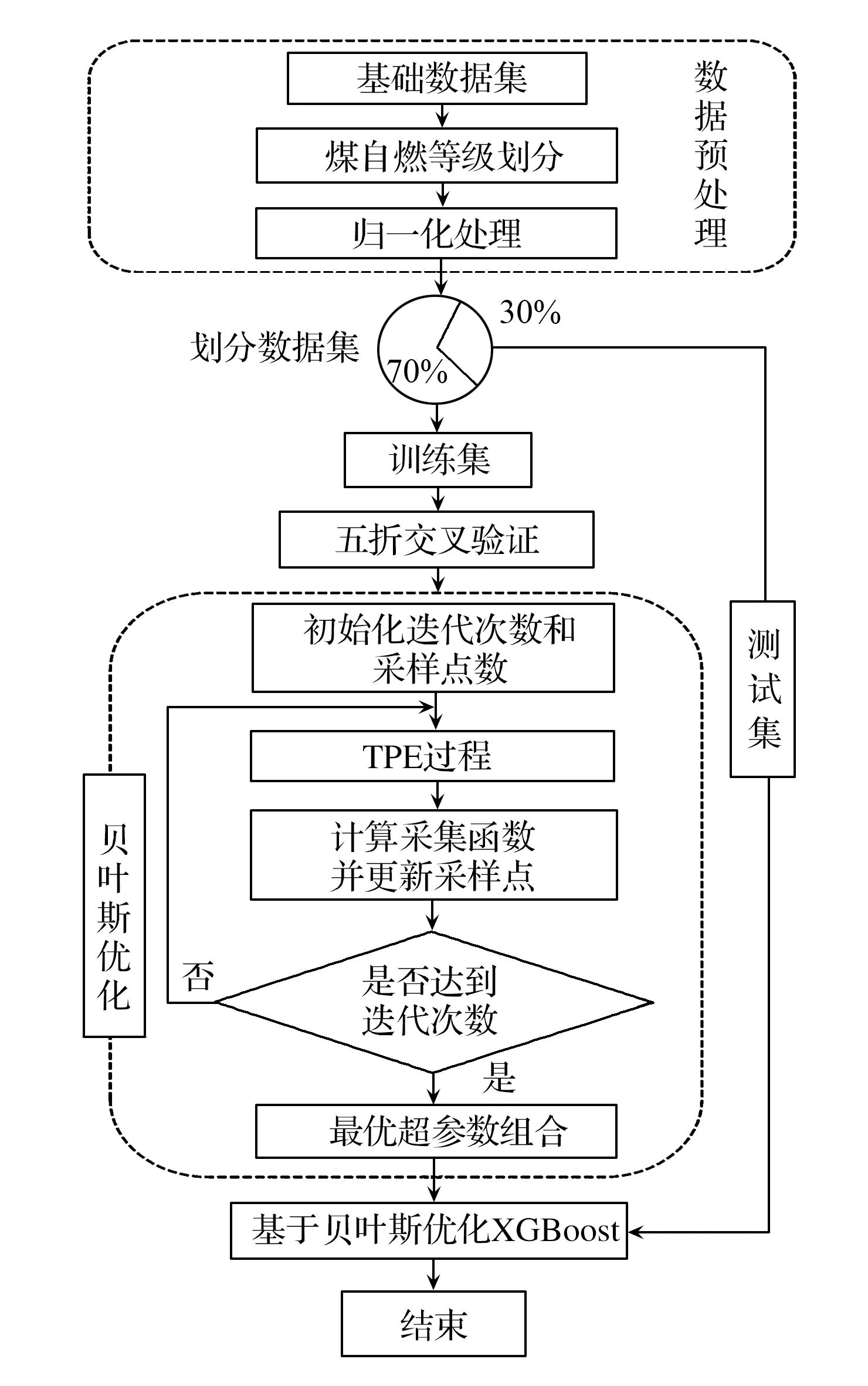
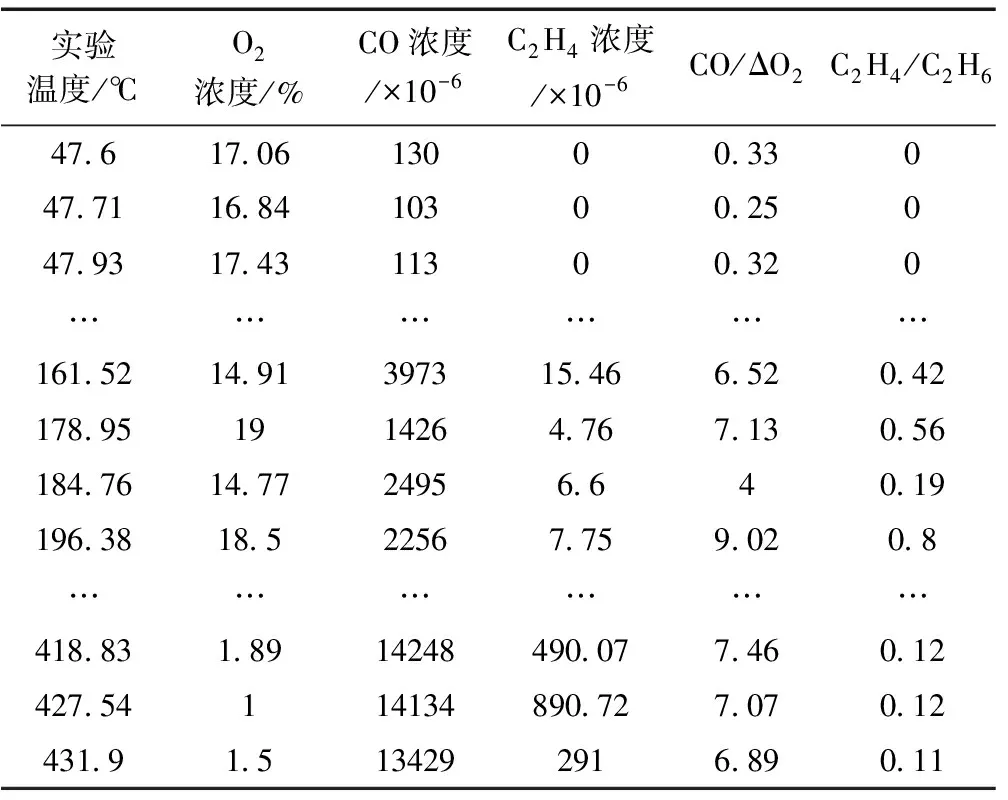
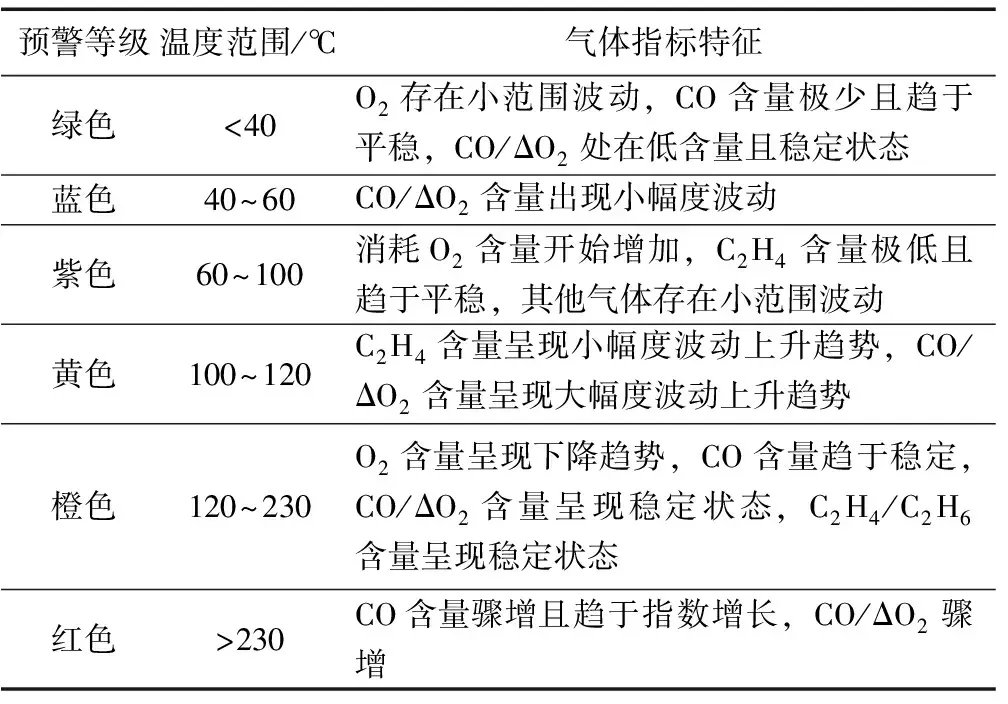
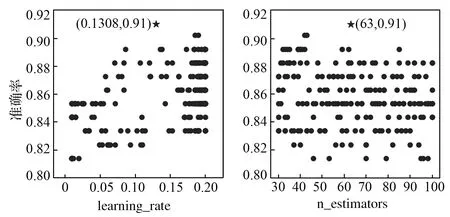
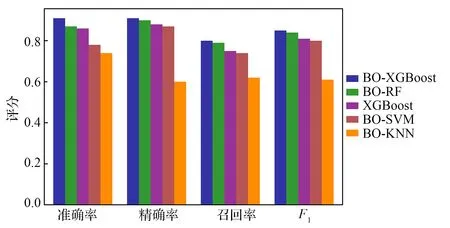
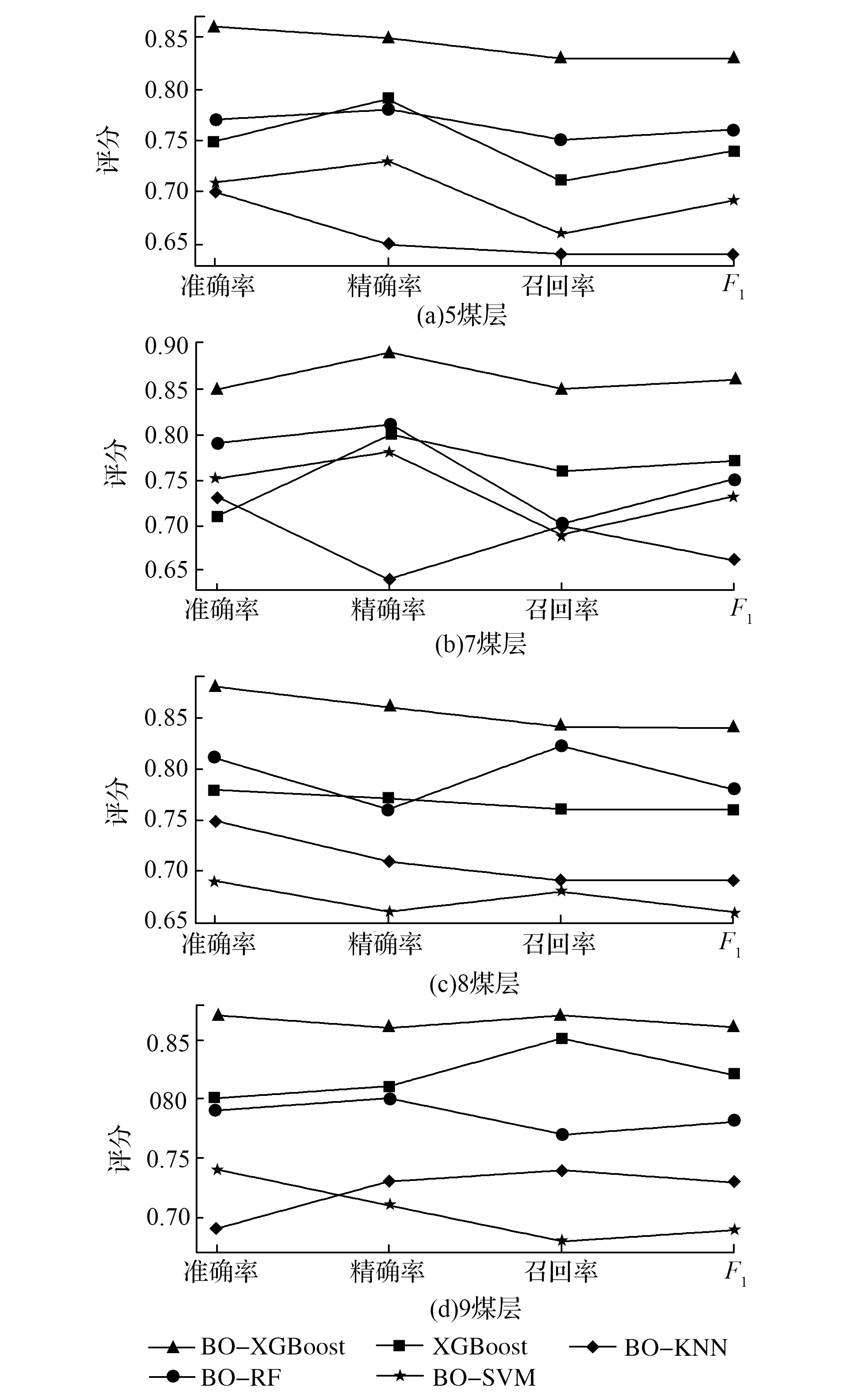
式中,γ=p(y 集成学习算法包括:Bagging、Boosting和Stacking三类。其中,XGBoost算法是基于Boosting集成思想,由梯度提升树改进得来的。它将决策树作为弱分类器,增加错分样本权重,通过加入新的决策树,纠正原分类器产生的误差,最后将多个决策树加权求和,作为最终预测结果[17-19]。 首先定义一棵决策树输出函数如式(3)所示。 f(a)=ωq(a),ω∈RT,q:Rd→{1,2,…,T} (3) 式中,a为输入向量;q为树结构;ω为对应的叶子分数;T为树中叶子节点数量;d为数据特征维数。 XGBoost是一种由K棵决策树基于Boosting的集成算法,其输出函数u如式(4)所示。 在单颗决策树的目标函数中引入惩罚项ζ,以防止决策树叶子节点过多出现过拟合现象,其中,式(5)为单棵决策树的复杂度。 目标函数最优解如式(7)所示: XGBoost模型的准确率和鲁棒性易受参数的影响,本文提出基于贝叶斯方法优化XGBoost的学习率、n_estimators、最大深度等参数的煤自燃分级预警模型,其算法流程如图1所示。BO-XGBoost算法步骤如下: 图1 煤自燃分级预警流程 1)步骤一:数据预处理,将原数据中连续型温度划分为合适的煤自燃温度等级,并将输入气体指标特征数据进行纵向归一化处理。 2)步骤二:将预处理后的数据以7:3比例划分成训练集和测试集两部分,训练集用以模型训练与参数寻优,测试集用以模型检验。其中煤自燃温度等级为输出标签,其对应的气体指标数据为输入。 3)步骤三:确定初始采样点个数init_points与迭代次数n_iter,选取概率代理模型为TPE,采集函数为EI,将min_child_weight、learning_rate、max_depth、n_estimators设置为待寻优的超参数组合并初始化参数寻优范围。 5)步骤五:判断是否满足结束条件,如果不满足继续重复步骤四,如果满足则输出当前最优超参数组合,完成模型构建。 模型采用的源数据是文献[20]中公开发表的山东省某矿煤自然发火实验数据,共有337组数据,部分数据见表1。 根据源数据绘制各指标气体的温度走势曲线,如图2—4所示,根据图中指标气体变化趋势分析煤自燃过程中各指标特征确定各阶段温度节点。 表1 部分源数据 图2 O2和CO气体含量变化曲线 由图2发现,煤O2含量随温度的升高而呈现下降的趋势,因为煤自燃是一个氧化过程,在这个过程中需要消耗大量的氧气;在60℃之前属于缓慢氧化阶段,O2含量存在小范围波动;230℃之后氧气含量呈现急剧下降趋势,说明煤开始剧烈燃烧;中间温度段总体呈现下降趋势。CO含量整体呈现上升趋势;在100℃之前含量极低且趋于平稳,这是因为在反应温度较低时,大部分CO由煤的物理脱附与化学反应生成,而由煤不完全氧化生成的CO含量相对较少;230℃到380℃之间CO含量趋于稳定;380℃后CO含量骤增。 由图3曲线走势分析可得,C2H4浓度整体呈现上升趋势;230℃之前C2H4浓度极低且趋于平稳;230℃之后呈现大幅度波动上升趋势,这是由于原始煤样中仅含有微量C2H4气体,在高温阶段,煤分子键断裂产生大量C2H4气体。CO/ΔO2比值整体呈现上升趋势;100℃之前CO/ΔO2处在微量且平稳状态;当煤温大120℃时,由于煤样复合反应加快,因此120℃到230℃之间呈现大幅度波动上升趋势;230℃到380℃之间呈现稳定状态;380℃之后CO/ΔO2比值骤增。 图3 C2H4和CO/ΔO2气体含量变化曲线 由图4曲线走势分析可得,C2H4/C2H6整体呈现上升趋势;100℃到230℃之间呈现大幅度波动上升趋势;230℃后呈现稳定状态。C2H6含量整体呈现上升趋势;210℃之前C2H6含量极低且趋于平稳;210℃到230℃之间C2H6气体呈现小幅度上升趋势;230℃之后呈现大幅度上升趋势。 图4 C2H4/C2H6和C2H6气体含量变化曲线 根据指标气体随温度变化的趋势图,分析各指标气体与煤自燃危险等级间非线性关系,选定40℃、60℃、100℃、120℃、230℃为煤自燃反应过程重要温度节点。进而将煤自燃划分为6个等级,用6种颜色表示,分别为绿色,蓝色,紫色,黄色,橙色,红色。煤自燃风险等级划分见表2。 证明 (1) 设{xn}是([0,1], ρπ)中的Cauchy-列,则对任意的ε>0,存在N,当m>n>N时, ρπ(xm,xn) 在划分数据集之前,将气体指标特征数据归一化到[-1,1]区间内,归一化后数据能够有效反映气体特征相对变化趋势,可以减少同一气体指标因煤矿差异造成的数值差距,增加XGBoost模型的普适性,能有效地应用到其它煤矿分级预警中。纵向归一化公式如式(8)所示。 式中,Bij为归一化后第i个特征中第j个数据;Zij为原数据第i个特征中第j个数据;minZi为第i个特征的最小值;maxZi为第i特征的最大值。 表2 煤自燃预警分级 预处理后部分数据见表3,其中温度并未进行归一化处理,而是将表2中温度依据煤自燃危险等级从低到高进行等级化处理。 表3 部分预处理后数据 XGBoost模型中参数较多,模型精度易受超参数影响,其中典型参数有:建树棵数n_estimators、最大树深度max_depth、学习率learning_rate、最小叶子节点权重和min_child_weight。为了寻求最优超参数组合,首先划分合理的参数寻优范围见表4。XGBoost模型采用Python中sklearn库,贝叶斯优化模型采用Python中Hyperopt库,迭代次数n_iter设置为200次,初始样本点init_points设置为20个,并以训练集五折交叉验证的平均准确率为目标函数。learning_rate和n_estimators参数寻优过程与煤自燃分级预警模型准确率关系如图5所示。 表4 XGBoost参数 最优的n_estimators参数与learning_rate参数通过迭代获得,圆型点表示不同参数取值下XGBoost在训练集中的准确率,星型点表示全局最优点,即训练集准确率最高时参数值。最优准确率为0.91,此时learning_rate=0.13,max_depth=4,n_estimators=63,min_child_weight=2。 图5 参数寻优 将气体指标特征对分类结果影响权重进行重要性排序,分析各个指标特征在煤自燃分级预警中作用,如图6所示。结果发现所选的各个指标气体均占有较高权重,进一步证实了所选指标气体进行煤自燃预警分类的正确性与合理性。其中C2H4、CO、C2H4/C2H6含量影响权重最大。 图6 特征重要性排序 选取分类学习中常用的准确率、精确率、召回率、F1值四个模型评估指标,由于煤自燃预警等级为多分类问题,采取每一等级计算求平均值的方式得到最终评估指标,评估指标计算公式如式(9)—(12)所示。其中,Ac为准确率;Re为召回率;Pre为精确率;CPi表示第i个等级的预测正确的总数;IPi表示第i个等级预测错误的总数;Pi表示预测为第i等级的总数;Ri表示实际为第i等级的总数。 为了验证贝叶斯优化方法的优越性,将BO-XGBoost模型分别与采用随机搜索、网格搜索的XGBoost模型在寻优速度、准确率上进行对比分析。为了提高对比结果的可靠性,在采用网格搜索及随机搜索时,寻优超参数组合及参数寻优范围同贝叶斯优化算法一致,见表4,迭代次数仍设置为200次。结果见表5。 表5 优化算法性能比较 由对比结果发现,从寻优结果准确率看,未采用优化的XGBoost模型准确率为87.2%,采用优化算法的XGBoost模型准确率均有不同程度提高,贝叶斯优化下准确率最佳为91%,网格搜索和随机搜索下的准确率分别为89.8%、89.7%,相较贝叶斯优化算法准确率低。从计算耗时看,贝叶斯优化算法优化XGBoost模型参数用时1.43min,相较于网格搜索算法和随机搜索算法,其寻优速度较快。因此贝叶斯优化算法效果较好,能在较短的时间内找到最优参数组合。 3.7.1 各模型在源数据测试集上的应用 为了验证XGBoost模型在煤自燃分级预警中的预测效果,将所建立的BO-XGBoost模型在测试集上进行测试,并将预测结果分别同随机森林、支持向量机、KNN模型的结果进行对比分析,其中,各模型的超参数组合均采用贝叶斯优化算法寻优。随机森林模型中最优参数组合为min_samples_leaf=10,n_estimators=30,max_depth=19;支持向量机模型的最优参数组合为核函数kernel选择高斯径向基函数,gamma=3.9,C=50.7;KNN模型中最优参数组合为n_neighbors=20,leaf_size=32;未经优化算法优化的XGBoost模型选用默认参数,默认超参数组合为:learning_rate=0.1,max_depth=3,n_estimators=100,min_child_weight=1。 各预测模型的准确率、精确率、召回率、F1值对比结果如图7所示。在基于贝叶斯优化的XGBoost算法中,四个评级指标均最高,各指标均达到85%以上。各模型预测精度排序为:BO-XGBoost>BO-RF> XGBoost>BO-SVM>BO-KNN,其中,BO-XGBoost模型的准确率为91%,相较于其他四种模型分别提高3%、4%、9%、12%。 图7 模型在源数据测试集上的预测精度对比 3.7.2 各模型在其他矿实验数据上的应用 为了进一步说明BO-XGBoost模型的普适性,首先选取唐山某矿四个煤层的实验数据作为验证模型的基础数据集,然后根据表2进行煤自燃等级划分并进行数据归一化处理。最后将数据分别带入BO-XGBoost,BO-RF,BO-SVM,BO-KNN,XGBoost模型进行对比分析,其中各模型采用的超参数组合选择与前面保持一致。各预测模型评价指标结果如图8所示。 图8 模型在其他矿上的预测精度对比 结果显示基于贝叶斯优化的XGBoost模型在准确率、精准率、召回率、F1值四个评级指标上相对最优。各指标均达到80%以上,且在不同煤层的实验数据下指标浮动范围在4%以内,具有较高的准确性与稳定性。BO-RF,BO-SVM,BO-KNN,XGBoost模型的分类准确率相对较低,针对不同煤层的煤自燃风险等级分类效果存在较大差异,稳定性相对较差。 1)本文提供了一种结合贝叶斯优化算法和XGBoost的煤自燃分级预警模型,并与BO-RF、XGBoost、BO-SVM、BO-KNN模型的分类结果进行对比分析,结果显示BO-XGBoost模型在准确率、精确率、召回率、F1值四个评估指标中都表现出了良好的性能。 2)为了检验贝叶斯优化算法的优越性,将BO-XGBoost模型分别与基于网格搜索算法、随机搜索算法优化的XGBoost模型、未进行参数寻优的XGBoost模型进行对比分析,结果显示经过贝叶斯算法优化后XGBoost模型的准确率最高,而且在参数寻优过程中贝叶斯优化算法速度相对较快。 3)为了进一步验证BO-XGBoost模型的普适性与稳定性,将其应用到河北省唐山市某矿,并与BO-RF、XGBoost、BO-SVM、BO-KNN模型精度与稳定性进行对比分析,结果显示BO-XGBoost模型具有较优的稳定性与分类精度。表明BO-XGBoost模型在不同矿井的煤自燃分级预警中取得了较好的效果。1.2 XGBoost算法
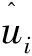
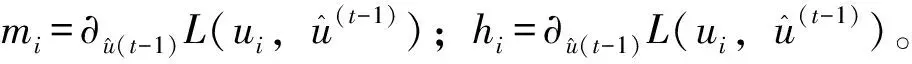
2 基于BO-XGBoost的煤自燃分级预警模型
3 算例测试
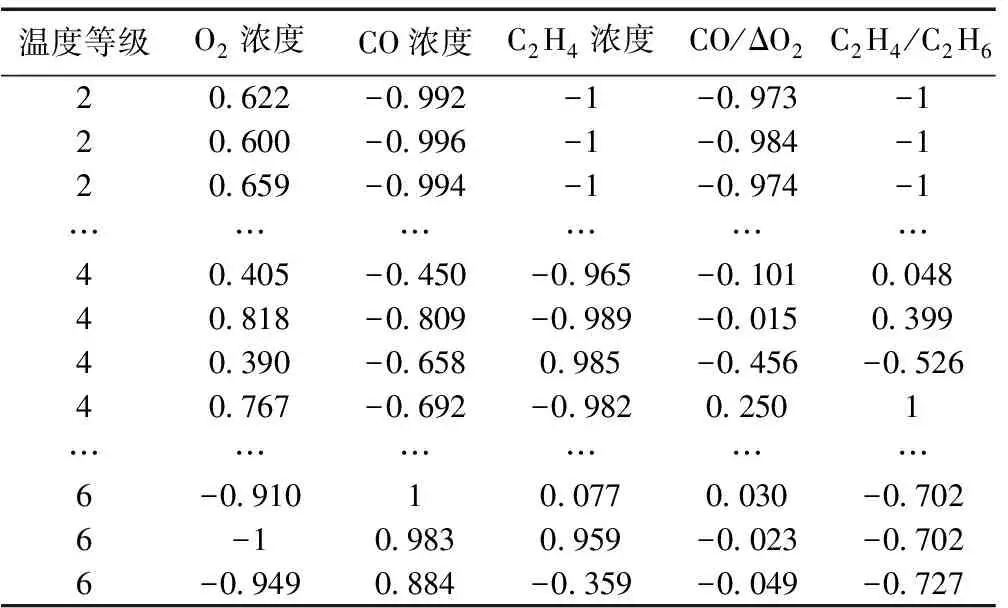
3.1 数据来源
3.2 煤自燃等级划分
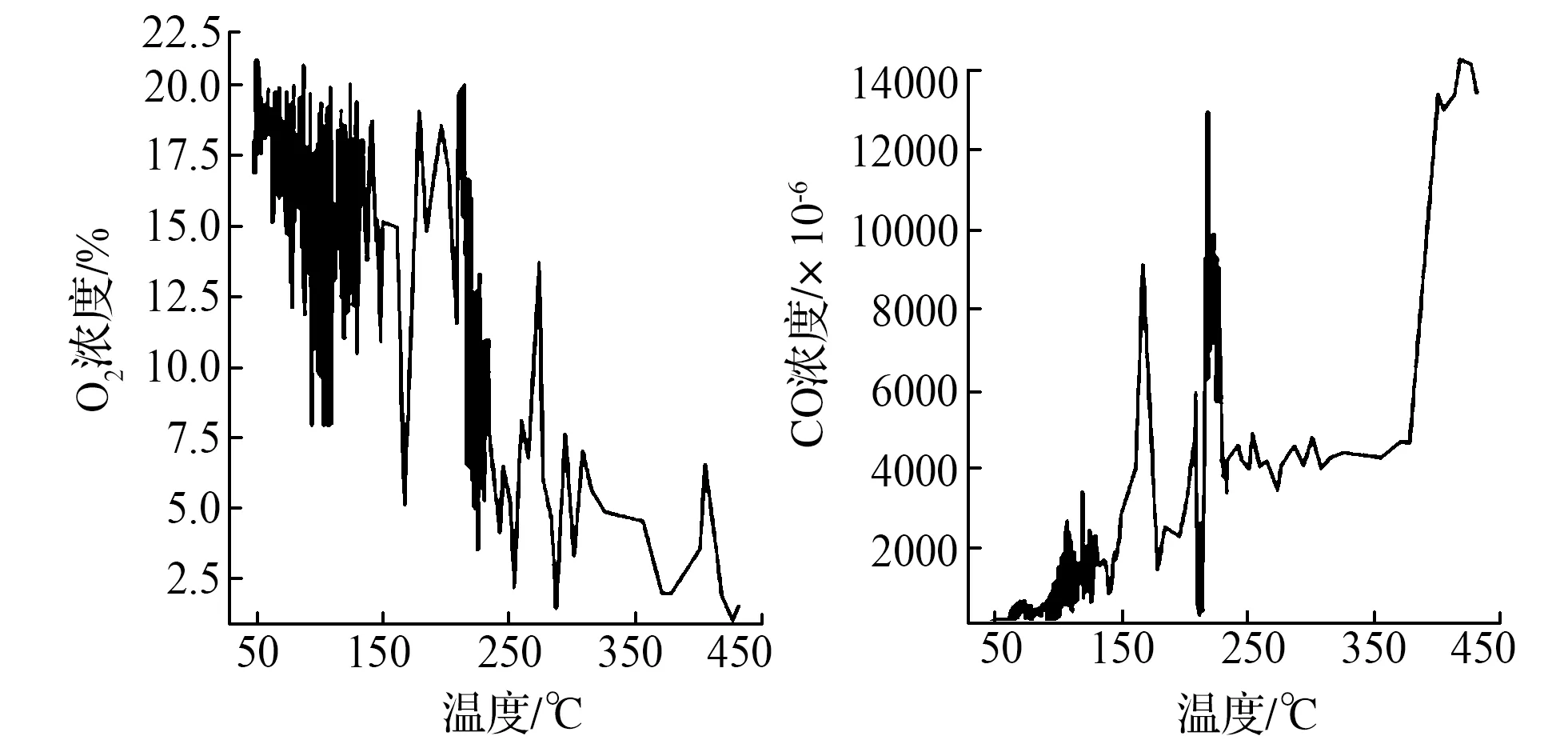
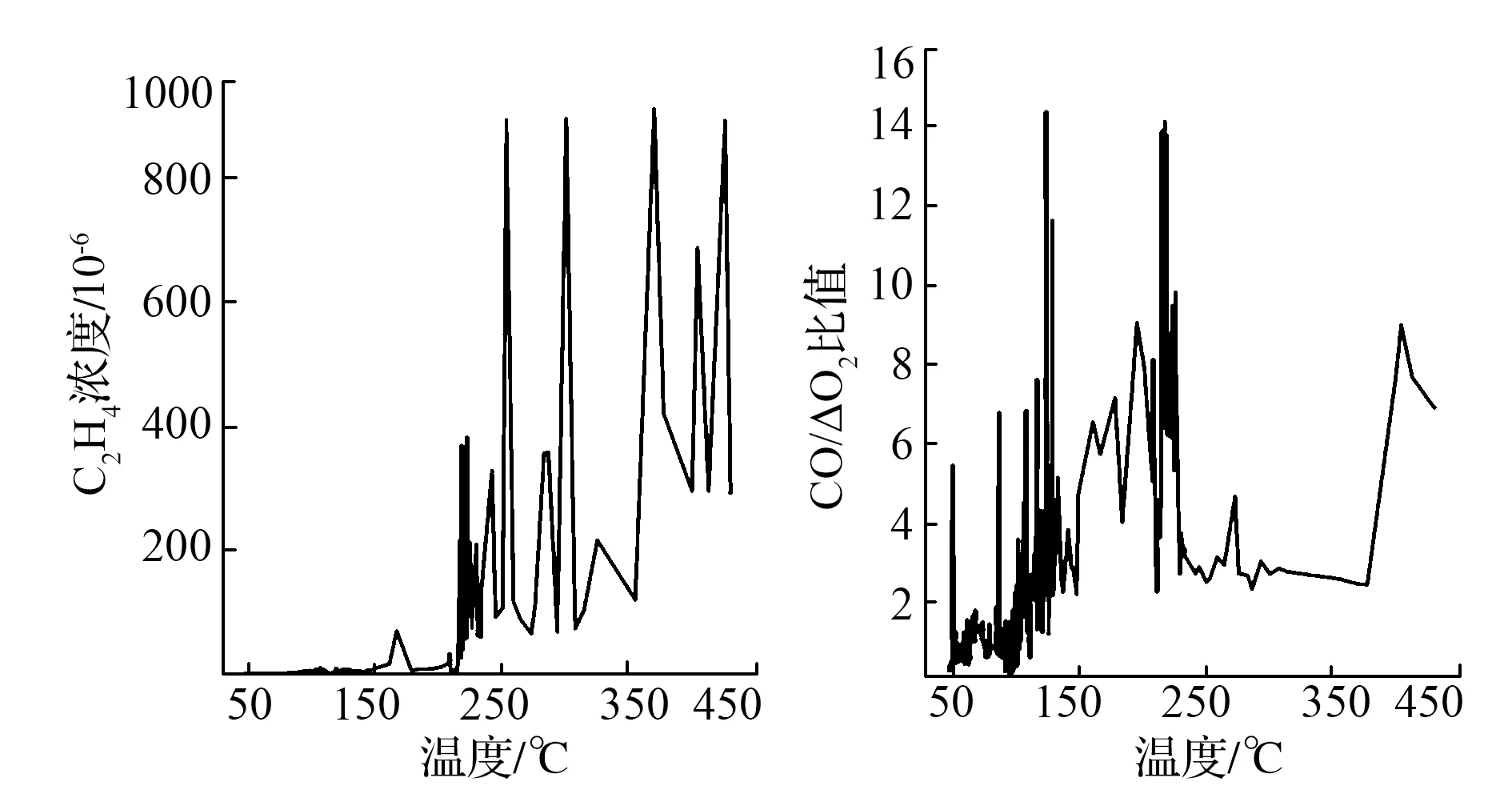
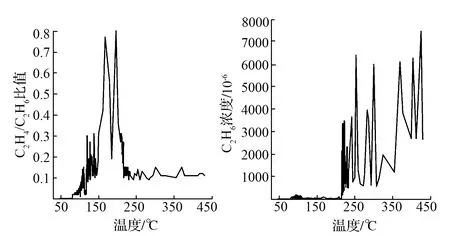
3.3 数据归一化
3.4 基于贝叶斯优化XGBoost模型应用


3.5 模型评价指标
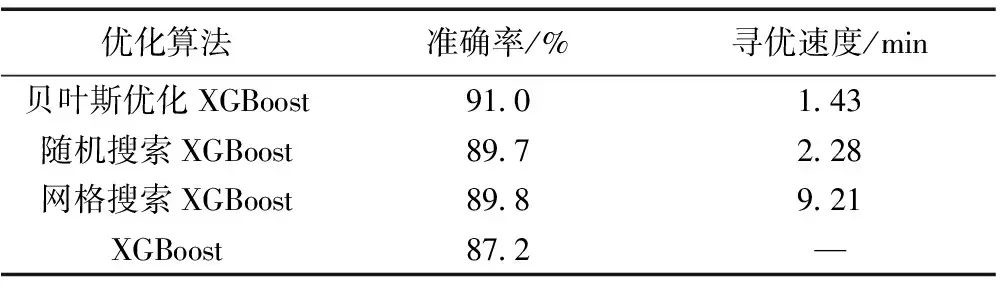
3.6 优化算法对比分析
3.7 各预测模型精度对比分析
4 结 论
