基于轻量化YOLOv4 模型的车辆检测方法
2022-08-19郑伟彬
郑伟彬
(福州福大自动化科技有限公司,福建 福州 350008)
0 引 言
随着社会的发展,智慧城市成为未来城市的发展方向[1]。智慧交通系统作为智慧城市的关键一环,具有重要的研究价值。智能交通系统可以有效地感知城市中各个街道的车流情况,有效提升道路利用效率,减少交通堵塞情况的发生[2]。智慧交通系统的核心是对于道路车辆的检测。相较于传统传感器的感知方法,通过视频图像对车辆进行检测,具有成本低、灵活性高以及可以同时检测多条道路等特点,因此得到了广泛的关注。
车辆检测的主要模型有基于运动的模型、基于特征的模型以及基于卷积神经网络的模型[3]。近些年来,深度学习技术高速发展,卷积神经网络在与图像目标识别领域具有优秀的表现。YOLO 作为一种优秀的一阶段(one-stage)目标检测算法,在各个目标检测领域得到广泛应用,且取得良好的效果[4-5]。相比于Faster R-CNN 这种两阶段(two-stage)目标检测算法[6],YOLO 具有更快的检测速度。进行车辆检测时,需要对拍摄到的车辆视频进行检测,一旦检测速度过慢,就会造成车辆的漏检,因此YOLO 比Faster-RCNN更适合用于车辆检测任务。
1 深度学习模型介绍
1.1 YOLOv4 介绍
YOLO 将待检测图片划分为S×S个网格,对网格进行检测,判断网格内是否是目标物体。YOLO 网络输出的值为预测目标的中心点、锚框宽高与类别[7]。YOLO 算法最早在2016 年由REDMON 等人提出,经过近些年的更新与优化,已经升级到了YOLOv4。YOLOv4 网络采用CSPDarknet-53 作为主干特征提取网络,使用空间金字塔池化提升感受野,使用路径聚合网络(PANet)融合了多个主干输出的特征图,有效提升模型对特征的提取能力。但在精度提升的同时,更加复杂的网络结构使得模型的参数量变得更大,对设备性能的要求也变得更高。因此,需要对原始的YOLOv4网络进行改进,降低其参数量,压缩模型体积。
1.2 MobileNetV2 介绍
MobileNetV2 是一种轻量化的卷积神经网络,网络的关键结构有逆残差结构与线性瓶颈结构。ResNet 的残差结构是对特征图进行降维后再升维,而MobileNetV2 的逆残差结构是先将特征图进行升维,再进行降维,故称之为逆残差[8],如图1 所示。

图1 MobileNetV2 逆残差结构
同时,为了减少模型的参数量,沿用了MobileNetV1的深度可分离卷积。深度可分离卷积在特征图的输入层使用了1×1 的逐点卷积(Pointwise Convolution,PW)进行升维,再经过3×3 的深度卷积(Depthwise Convolution,DW)。由于深度卷积的每个卷积核只对一个通道进行卷积,因此计算量大幅减小。经过深度卷积后,再使用1×1 的逐点卷积,将各个特征图之间的信息聚合,得到与标准卷积相同的输出。
深度可分离卷积与逆残差结构虽然大幅减少了数据量,但是可能会造成低维特征的丢失。因此,MobieNetV2 在完成降维后,不使用ReLu6 激活函数,而是用线性层作为代替,称之为线性瓶颈结构[9],如图2 所示。

图2 MobileNetV2 线性瓶颈结构
1.3 激活函数与损失函数介绍
激活函数使用ReLu6 激活函数,可以缓解激活后权值相差过大的问题,如式(1)所示:

式中:IOU为预测框与真实框的交叠率,c为能够同时包含预测框与真实框的矩形的对角线距离;v是真实边界框与预测边界框的宽高相似比,如式(3)所示;α是v的影响因素,其计算如式(4)所示;d为预测框与真实框的中心点距离,d的计算如式(5)所示。

2 整体模型设计
2.1 轻量化YOLOv4 模型
为了减小YOLOv4 模型的参数量,压缩YOLOv4模型的大小,本文对网络的结构进行改进,使用MobieNetv2 网络替换YOLOv4 原本的CSPDarkNet53主干特征提取网络。改进后的网络结构如图3 所示。替换掉主干特征网络后,同时将YOLO 的特征金字塔与特征融合部分的卷积模块也替换为深度可分离卷积,可以进一步压缩模型大小。
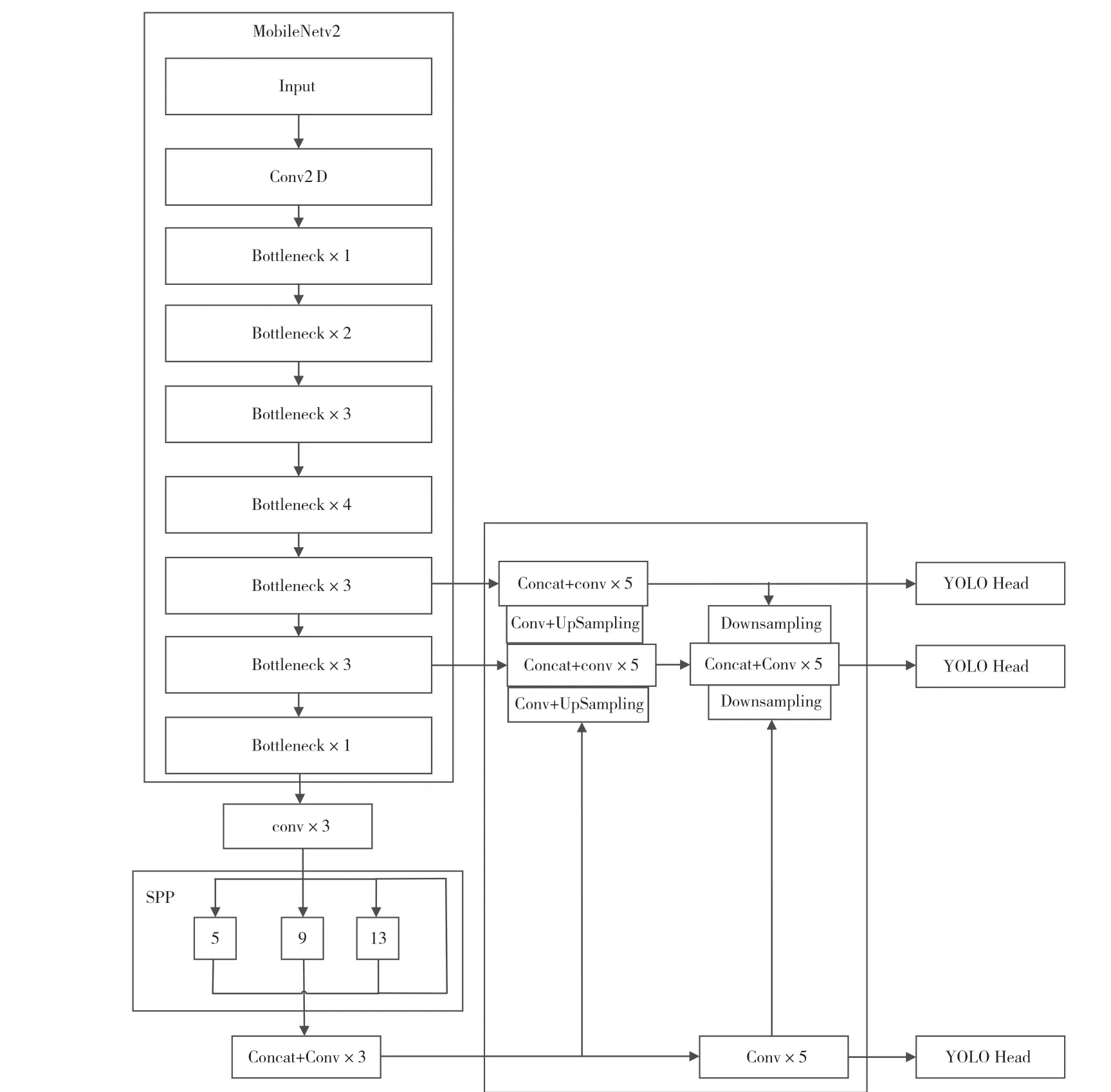
图3 MobileNet-YOLOv4 模型网络结构
YOLO 算法中,每个YOLO Head 都有对应预先设置好的3 个预选锚框,用来检测不同大小、不同比例的目标。预选锚框的初始尺寸会对模型的检测效果有一定影响,如果锚框的初始值更加贴近带检测的目标物体,模型的检测精度就能更高。因此,本研究中使用K-Means++聚类算法,对训练集样本的标注框进行聚类,得到9 类初始锚框尺寸。聚类完成后,得到的锚 框 大 小 为[12,18],[20,26],[29,35],[45,40],[36,58],[66,58],[52,87],[84,93],[133,177]。将聚类得到的9 个锚框大小作为本研究的初始锚框。
2.2 数据集处理
本研究所用的数据集为UA-DETRAC 数据集[11]。该数据集中的图像拍摄于北京与天津的过街天桥。由于UA-DETRAC 中原始数据为视频图像,数据集中的图片每秒有24 张图片,出现的车辆重复较多,过大的数据集会导致网络训练速度过慢。为了提升网络训练效率,需要对数据集进行精简,从每个视频转为图像的文件夹中每间隔500 张图片抽取一张图,重构数据集,可以有效减少重复出现的车辆图片数。同时,将数据集中所有类别的车统一记为类别car。
3 实验结果与分析
3.1 实验环境介绍
实验所用的硬件设备如下:CPU 为i7-9750H,GPU 为GTX1660,内存16 GB。实验所用操作系统为Windows,编译环境为Pycharm,编程语言为Python,搭建模型的深度学习框架为Pytorch,Pytorch 版本为1.6.0。
3.2 模型训练
模型训练的Epoch 设置为200,Batch 设置为16,模型初始学习率为0.01,采用Adam 算法优化模型训练过程,动量参数为0.94。训练时采用马赛克数据增强方法,对输入图像进行反转、拼接等操作,可以有效增强模型的鲁棒性。
3.3 实验结果分析
对于目标检测任务,常用的检测指标为AP,mAP。AP 表示某类检测目标的平均精度,mAP 表示所有类别的AP 均值。由于本研究是单分类任务,因此AP 与mAP 相同。选取模型收敛后保存的权重文件,对测试集图像进行检测,得到模型检测的平均精度与检测速度,同时计算整个模型的大小,实验结果如表1 所示。

表1 实验结果对比
从实验结果可以看出,对比原始的YOLOv4 模型,MobileNet-YOLOv4 模型的AP 值仅减少了0.77%,模型的检测精度并没有发生明显的下降。模型检测速度从28.35 f·s-1提升到了47.31 f·s-1,提升了66.9%,对于路面车辆检测研究来说,更高的检测速度意味着能检测到以较快速度行驶的车辆。与此同时,轻量化改进后的YOLOv4 模型的大小从64.36 Mb 下降到了11.73 Mb,模型压缩了81.77%。从实验结果可以看出,MobileNet-YOLOv4 模型在牺牲了较小检测精度的情况下,有效提升了模型的检测速度,同时压缩了模型的体积,使得模型可以适应计算力较低的运行设备。从测试集中挑选若干图片进行检测,展示检测结果如图4 所示。从图4 可以看出,改进后的模型仍然可以较好地检测出路面车辆,检测框也都具有较高的置信度。

图4 检测结果展示图
4 结 语
本文使用了MobileNetV2 网络来替换YOLOv4 的主干特征提取网络,同时将网络中的卷积替换为深度可分离卷积,实现了在不过多影响模型检测精度的前提下,有效压缩了模型的体积,同时也提升了模型的检测速度。实验结果表明,在不同光线、不同天气、不同角度及不同远近程度下,所设计的模型均能有效地对路面车辆进行准确的检测,验证了模型的有效性。
