结合k-均值聚类缓解行人检测正负样本不平衡问题
2020-04-30刘丛强王浩森葛成鹏杨建盛
刘丛强 王浩森 范 虹 葛成鹏 杨建盛
(河北建筑工程学院 信息工程学院,河北 张家口 075000)
0 引 言
行人检测是计算机视觉领域的一个经典问题,其特点是应用范围广泛如无人驾驶,机器人,智能监控,人体行为分析,弱视辅助技术等[1,2].传统的行人检测方法主要是应用HOG提取行人特征再用SVM进行分类[3],但HOG只能从梯度或者纹理来描述行人特征,判别力较差[4],同时SVM也不再适应规模越来越大的行人检测数据集.随着近几年卷积神经网络的流行与发展,行人检测的精度依靠卷积神经网络从大规模样本中学习目标特征的能力得到了很大提升,但正负样本失衡,多尺度,行人之间的相互遮挡等问题仍然影响着检测性能.
基于深度卷积神经网络的检测模型可以分为基于锚框(anchor-based)和不基于锚框(anchor-free)两类,目前基于锚框的目标检测模型主要有Faster R-CNN[7],SSD[8]等,不基于锚框的主要有YOLOV1[5],CornerNet[6]等.相比于不基于锚框基于锚框的检测模型尽管灵活性较差,需要调优锚框相关的参数,但在精度上表现更好,Faster R-CNN在训练RPN阶段会生成预先设置好尺度与比例的锚框,通过迭代训练,使RPN能输出更符合检测目标的候选框给Fast R-CNN进行进一步的分类和定位,只要生成锚框的尺度和比例能符合检测目标的分布,就可以提升模型的检测精度.
本文实验基于Faster R-CNN进行,为了获得更适应于行人检测的锚框比例,提升检测性能,通过k-均值聚类算法对CityPersons[9]数据集的标注信息进行聚类,并将聚类出的行人比例应用到RPN中,将结果与原始Faster R-CNN设置的比例和AdaptedFaster R-CNN[9]使用密集比例的方法得到的结果进行对比.
1 基本理论
1.1 模型的训练流程
模型的训练流程如图1所示.首先将行人检测数据集输入卷积神经网络(CNN)中提取特征,生成特征图,然后RPN根据特征图的大小,预先设置好的锚框尺度及通过对行人数据集使用k-均值聚类得到的比例来生成锚框,并按照一定规则挑选部分锚框来来训练RPN,最后RPN再输出经过非最大值抑制(NMS)的候选框到Fast R-CNN中进行训练.
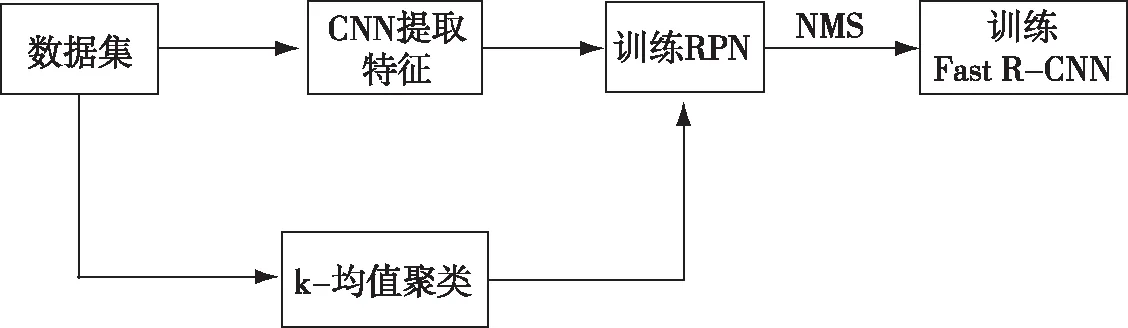
图1 模型训练流程
1.2 k-均值聚类
实际场景中,行人的宽度会因姿态,遮挡等因素变化很大,但人的高宽比仍然处于一定范围内,对于行人检测模型性能的评估都会进行多尺度的评估,将行人样本根据高度,或面积可以分为小中大三类,实际情况中行人距离检测器的远近表现在图像中就是像素大小的变化,所以在类别数范围已知,类间差别大的情况下可以通过k均值聚类算法找到每一类行人的中心比例.算法的描述及实现过程如下[11]:
a)给定数据集D={x1,…,xn},随机选择k个聚类中心C={C1,…,Ck}.
b)根据欧式距离将数据集中的对象划分到某个类之中.
c)计算新的聚类中心Ci:
(1)
d)当满足最小化误差函数E(C)或达到迭代次数,迭代停止,否则转入b)继续迭代:
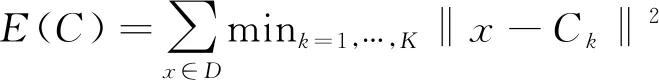
(2)
1.3 特征金字塔网络
FPN[12]是利用CNN本身带有的层次性特征来构建具有更强语义信息的特征图,CNN本身的层次性特征是指底层的特征图分辨率高,有利于定位,但语义信息弱,不利于分类,而顶层的特征图分辨率低,不利于定位,尤其是对小目标,但包含的语义信息更强,有利于分类.FPN的具体构造流程如图2所示,以ResNet[13]为例,将conv2,conv3.conv4,conv5每一层最后一组残差块输出的特征图提取出来,命名为C2,C3,C4,C5,然后先对C5进行11卷积得到M5,将M5上采样成与C4相同的分辨率后加上经过11卷积的C4得到M4,依此类推得到M3,M2,然后将M5,M4,M3,M2都经过33的卷积得到P5,P4,P3,P2,通道数都固定为256.这样得到的特征图都包含CNN顶层较强的语义信息.
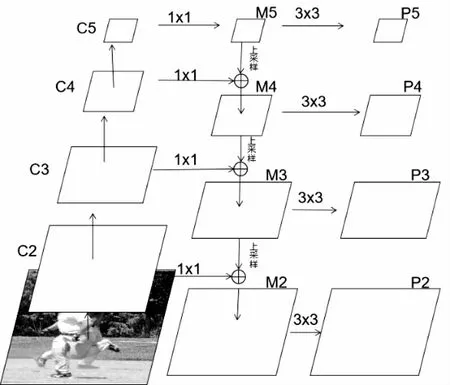
图2 FPN构造过程
1.4 Faster R-CNN
Faster R-CNN结构与Fast R-CNN基本一致,区别在于Faster R-CNN不再使用selective search来获取候选框,而是提出了RPN与CNN结合到一起来生成候选框,实现了端到端的目标检测,有效提升了检测效率.
1.4.1 区域建议网络
在输入一张任意大小的图片后,RPN会输出一批候选框,每个候选框都会有一个类别得分和相对于真实框(ground truth)的偏移量,在训练阶段会根据特征图的大小和预先设置好的尺度和比例生成一定数量的锚框,在测试阶段就不再生成锚框,而是直接将通过卷积计算得到的候选框经过最大值抑制后选择前1000个输入到Fast R-CNN中得到分类和定位结果[12].
1.4.2 损失函数
在RPN训练阶段时,会根据生成的锚框与真实框的交并比分配正负样本,然后按照设置好的比例和数量随机选择正负样本进行训练,根据文献[9],损失函数设置为:

(3)
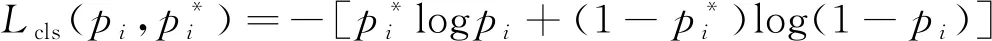
(4)

(5)

2 实 验
本文使用公开的行人检测数据集CityPersons进行实验,CityPersons训练集包含2975张图像,验证集包含500张图像.

表1 Citypersons子集划分标准
实验基于Pytorch深度学习框架进行,GPU为单张GTX 1060.使用在ImageNet分类任务上预训练过的ResNet50[13]作为基础网络架构,不使用数据增强技巧.训练RPN时,设置当锚框与真实框交并比大于0.7时,标记为正样本,当交并比小于0.3时,标记为负样本,然后随机挑选256个锚框计算分类损失和回归损失,正负样本比例为1:1.在训练参数设置方面,batchsize设为1,共30k次迭代,前25k次学习率为0.001,后5k次学习率为0.0001,动量为0.9,权重衰减设为0.0005.

表2 k-均值算法聚类结果
评估标准参照文献[10],在FPPI(false positive per image)的[10-2,100]范围内计算对数平均丢失率,按照官方提供的评估标准根据高度和遮挡率将验证集划分为三个子集.所有实验交并比(IOU)阈值都为0.5.
2.1 通过k-均值算法得到行人比例
如1.2节所述,会将数据集的标注信息聚类成三类及两类做实验对比,对于CityPersons数据集,只对其可见框的标注信息进行聚类,因为其全身框是根据固定比例生成的,而检测时是针对可见部位的检测.聚类结果如表3所示,横坐标为宽度,纵坐标为高度,文中所有比例值都为高比宽.由中心点变化可以看出,行人的面积分布具有明显的尺度变换.
2.2 不同比例下行人检测对比实验
现在将聚类所得比例与Faster R-CNN根据经验设置的原始比例{0.5,1.0,2.0}及AdaptedFaster R-CNN凭直觉设置的密集比例得到的行人检测结果进行对比,密集比例是指把区间[0.5,2]10等分取11个端点作为生成的锚框比例[9],在CityPersons数据集上的实验结果如表3所示,Ori表示原始比例,k-means-3表示锚框比例聚类成3类,k-means-2表示聚类成两类,Dense表示密集比例.

表3 CityPersons数据集上的实验结果
从表3可以看出,使用聚类得到的比例对比原始比例能有效降低行人检测的丢失率,在Reasonable,Reasonable_small子集上分别最大降低了2.8%,4.7%.图4为CityPersons数据集在RPN阶段生成的正样本数量分布图,横坐标为图片生成的正样本数区间,纵坐标为图片生成的正样本数在该区间范围内的频数.从图4可以看出,对比原始比例,聚类得到的比例使图片生成的正样本数在[0,20]之间的频数明显下降,因为实验设置为随机挑选256个正负样本,所以在这一范围内的负样本的数量为正样本的10倍到255倍,属于极端正负样本不平衡,同时在其他范围内的频数基本呈上升趋势,在[20,40]的区间范围内上升最多,平均上升了144次,这表明合适的锚框比例有效缓解了正负样本不平衡的状况,进而提升检测精度.并且从表3还可以看出使用密集比例得到的丢失率相比使用聚类得到的比例并没有明显降低,在Reasonable_small子集上丢失率相比原始比例还上升了0.5%,这表明密集比例对多尺度变换的适应力差.

图4 CityPerosns数据集RPN阶段生成的正样本数量分布
同时观察表3不同比例下生成的正样本总数及图4密集比例在RPN阶段生成的正样本数量分布,从生成的正样本的总数来看,使用密集比例生成的正样本总数最多,是聚类得到的比例的2倍左右,密集比例生成的正样本数对比原始比例在[0,20]范围内下降最多,虽然在[20,100]范围内有小幅下降,但在能满足正负样本平衡的[120,180]范围内上升幅度最大,可丢失率相比聚类所得比例却没有下降,由此可以推测生成的正样本数量并不是降低丢失率的决定因素,再考虑RPN的损失函数,要通过迭代去拟合的是标记为正样本的锚框相对于真实框的偏移量,该偏移量越小,说明越接近真实框,标记的正样本质量也就越高,越能提升模型的定位能力.因此,生成的正样本质量相比正样本数量是影响丢失率下降的更重要因素.
3 结束语
本文使用构建了FPN的Faster R-CNN进行行人检测,通过结合k-均值聚类的方法获得适应于行人检测的锚框比例,从而提升了Faster R-CNN应用于行人检测时的性能.在CityPersons数据集上的实验结果说明聚类得到的比例有效缓解了正负样本不平衡的问题并且生成的正样本的质量相比生成的正样本数量是影响检测精度的更重要因素,使用聚类得到的比例能生成相比密集比例稀疏但总体质量更高的正样本。
