融合分形特征的风机运行状态辨识方法
2022-08-11王荣喜高建民
郭 怡,王荣喜,高建民
(西安交通大学 机械制造系统工程国家重点实验室,陕西 西安 710049)
0 引言
为应对全球气候变化,我国提出做好“碳达峰、碳中和”工作、推动绿色低碳发展[1]。以风力发电为代表的清洁能源发电方式,是除水力发电之外技术最成熟的一种可再生能源发电方式,随着清洁能源的需求不断增长[2],以及非水力可再生能源发电比例的扩大,建立和完善智慧运维系统是保证风电机组工作效率、降低系统维护成本的基础,也是保障以风机为代表的新一代电力系统健康发展的必然要求。然而,为满足风力需求,风电机组常被安装在山区、海上[3]和沙漠,工作环境较为恶劣,在追求更大功率、更高效率的同时,风电机组系统的复杂程度也随之增大。长时间在变风载、大温差等极端工况下工作,任何微小异常的积累或部件受到异常扰动都有可能导致系统故障的发生,增加系统维修维护成本。风力发电机组本质上是一种由多种结构机构、电气设备,通过能量、控制信号等多介质网络耦合而成的复杂机电系统[4],其海量、高维的监测数据[5]蕴含着丰富的状态信息[6],运行状态具有复杂多变的特点。然而,风机智慧运维在处理海量、高维的风机监测数据时仍然存在数据挖掘不足的问题[7],且由于风电机组运行状态具有时变性,如何充分利用监测数据、挖掘有效信息,实时监测风电机组的运行状态,是风机智慧运维中亟待解决的问题。
为实时监测风机运行状态的异常[8-9],从而有针对性地指导风机维修,降低风机检修难度,合理的风机运行状态辨识方法[10]至关重要。风机运行状态辨识是实现风机运行状态实时监测的核心步骤,而采用有效的特征提取方法[11]挖掘风机海量、高维监测数据中的信息,是风机运行状态辨识的关键环节[12]。现有的时间序列特征提取方法主要分为基于统计的特征提取方法和基于人工智能的特征提取方法两类[13]。基于人工智能的特征提取方法能够直接处理时间序列,通过神经网络的多隐层结构[14]提取和抽象时间序列的分布式特征。曹大理等[15]提出一种基于卷积神经网络的刀具磨损量在线监测模型,采用深度网络自适应地提取特征,并通过加深网络进一步挖掘信号中隐藏的微小特征;熊红林等[16]提出一种基于多尺度卷积神经网络(Multiscale Convolutional Neural Networks, MCNN)图像识别模型,在划痕缺陷和杂质缺陷识别方面的准确率较高;戴稳等[17]建立了一种基于深度学习特征降维及特征后处理的布谷鸟优化参数的最小二乘支持向量机预测模型,相比于传统的特征选择,摆脱了对先验知识和经验需求的依赖,大幅提升了效率。因此,基于人工智能的特征提取方法泛化能力较强,应用较广泛,可以有效避免人为特征提取的局限,但是容易忽略时间序列不同维度之间的相关性,可解释性较差[18];而基于统计分析的特征提取方法能够兼顾时间序列的形状特征和时间依赖特征[19],因此,该类方法可以有效地弥补人工智能方法在特征提取方面的不足。吴江波等[20]提出一种基于显著度和统计特征的光谱信号检测与提取算法,降低信号提取过程中背景噪声、基线畸变等不利因素的影响;Wang等[21]应用耦合去趋势波动分析(Coupling Detrended Fluctuation Analysis, CDFA)研究了复杂机电系统的多变量耦合关系,分析并提取了分形特征;何涛等[22]针对个性化机械零件的不规则和自相似性,将分形方法与去趋势波动分析相结合,提取零件特征进行缺陷识别。相较于人工智能方法,以统计分析、信号分析为代表的特征提取方法能够提高特征的可解释性,但精度和泛化能力较差[23]。因此,为充分利用风机监测数据,以较高的精度提取数据与状态之间的复杂特征关系[24],同时提高模型的泛化能力,本文提出一种融合分形特征[21]的CNN风机运行状态特征分析方法,即在人工智能特征提取之前,先以分形等统计方法建立样本特征数据集,再以噪声环境下基于密度的空间聚类(Density-Based Spatial Clustering of Applications with Noise, DBSCAN)[25]结果为状态标签,选择重要程度较高的特征训练CNN模型,建立一种风机运行状态辨识模型。该模型能够实现对风机阶段运行状态的实时辨识,也为风机状态维修和“事前维修”模式[26]提供了科学参考和理论指导,同时提高了风电机组安全性和经济性,保障了风电机组的安全可靠运行,为风机运行阶段性状态监测[27]与故障诊断[28]提供科学依据。
1 分形特征分析和无监督聚类原理
为了对风机监测数据进行全面、准确的特征分析,首先对风机各测点监测数据进行整理。其中,齿轮箱是风电机组传动系统中的重要部件,其故障发生率较高且故障诊断难度较大[13],监测风机齿轮箱的运行状态对风机服役质量状态辨识具有重要意义。因此,本文以风机齿轮箱中间轴[29]测点处监测数据作为研究对象,进行数据预处理,建立监测数据时间序列样本数据集。因为风机监测数据具有自相似性,所以对数据集中的各时间序列样本进行分形等统计特征分析,建立样本特征数据集,以DBSCAN无监督聚类方法对样本状态进行标记。
1.1 分形特征分析
分形特征分析包括分形维数特征分析和多重分形特征分析[21],表示组成系统的部分与整体的相似性。以风机为代表的复杂机电系统中虽然存在复杂的耦合关系,但其确定性特征和自组织结构可以通过自我分形挖掘出来,而多重分形通过对概率分布函数及其各阶矩的计算,能够对分形的复杂性和不均匀性进行更细致的刻画。因此,本节分别对风机监测数据集计算分形维数和Hurst指数,用来描述该时间序列样本的分形特征,同时采用多重分形谱函数从多个尺度全面反映系统的行为特征差异。
对监测数据的时间序列样本分别计算分形维数和Hurst指数,使用CHHABRA等[30]提出的标准盒计数法计算分形维数,其计算原理如式(1)所示。
(1)
式中:Dim(F)为盒维数;Nδ(F)为集合F和坐标网格立方体的相交个数;D为无标度区间内(-logδ,logNδ(F))的双对数图的斜率;在无标度区间内,-logδ与logNδ(F)满足线性回归方程,如式(2)所示。
logNδ(F)=-Dlogδ+b。
(2)
式中D和b分别为线性回归方程的斜率和截距。经过最小二乘法拟合,斜率D即为所求盒维数,盒维数D可以由-logδ与logNδ(F)的关系唯一确定。
对监测数据的时间序列样本分别进行多重分形分析,多重分形谱α-f(α)是刻画序列多重分形关系的有效方法,其中,α为奇异强度,f(α)反映了序列的维数随奇异强度α的变化情况,其关系表达如下:
α=h(q)+qh′(q),
(3)
f(α)=q[α-h(q)]+1。
(4)
式中:q为指数变量,h(q)为广义Hurst指数[31]。多重分形特征谱α-f(α)如图1所示。
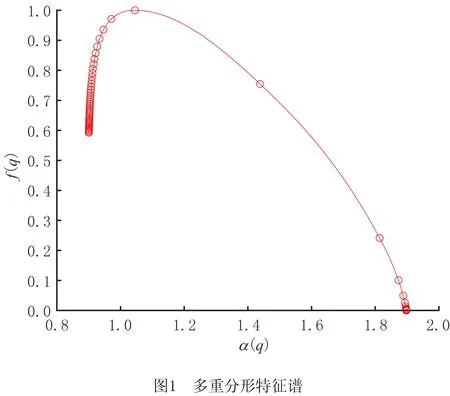
图1中,横坐标α(q)和纵坐标f(q)分别为关于指数变量q的函数,通过分析奇异强度α与奇异谱f(α)的相关关系可以用来刻画多重分形强度。根据分析结果,记录Δf、αmax、αmin和Δα等多重分形特征的变化情况,其中:Δα=αmax-αmin描述多重分形谱覆盖的局部holder指数的范围,反映多重分形程度。Δα小,则信号趋于单一分形,反之则趋向于多重分形,α=1表示均匀的点分布,α<1表示“内密外稀”类型的点分布,α>1表示“内稀外密”类型的点分布。
1.2 基于密度的无参时间序列聚类
通过运行状态特征分析得到风机监测数据的内在特征,相较于原始监测数据,分析后的结果更容易区分出正常和异常的特征样本,从而通过异常特征样本定位到具有异常的监测时间序列段。
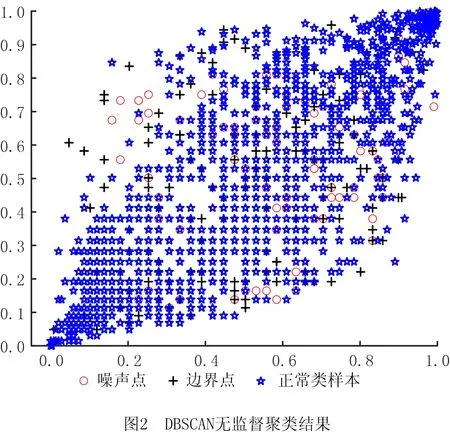
本节选用DBSCAN无监督聚类方法对时间序列样本进行状态标记,该方法为基于密度的聚类算法,即某点邻域内的样本点数不小于最小样本数MinPts时,则以该点为聚类中心进行聚类。对于特征分析得到的样本特征数据集,规定在距离阈值ε内的样本点为正常,超出距离阈值ε的样本点为异常。DBSCAN聚类方法相较于传统的K-means聚类方法,不需要预先设定需要形成的簇类数量,只需给出合适的最小样本数MinPts和距离阈值ε,就能够找到密度相连对象的最大集合,从而有效处理噪声点并发现任意形状的空间簇类。选择合适的参数MinPts和ε后,其具体过程及算法描述如下,DBSCAN聚类结果如图2所示。
算法1DBSCAN算法。
初始化参数:Minpts=6;ε=0.2;
输入:样本特征数据集D,最小样本数MinPts,距离阈值ε;
输出:簇集合(样本状态标签)。
1 首先将样本特征数据集D中的所有对象标记为未处理状态5%-Co-Zn-B
2 for(数据集D中每个对象p)do
3 if(p已经归入某个簇或标记为噪声)then
4 Continue;
5 else
6 检查对象p的Eps邻域ε(p);
7 if(ε(p)包含的对象数小于MinPts)then
8 标记对象p为边界点或噪声点;
9 else
10 标记对象p为核心点,将p邻域内所有点加入新簇C
11 for(ε(p)中所有尚未被处理的对象q)do
12 若其Eps邻域ε(q)包含至少MinPts个对象,则将ε(q)中未归入任何一个簇的对象加入C;
13 end for
14 end if
15 end if
16 end for
图2中,横纵坐标分别代表数据归一化之后的测量值,因此没有单位和具体的意义,通过DBSCAN方法聚类之后,没有明显的聚类中心。图中不同的点形代表了不同的状态,其中,星形为正常类样本点,圆形和十字形分别代表聚类结果中的噪声点和边界点,均归为异常类样本点。最终分别以0和1表示正常和异常两类样本点,完成对样本的状态标记。
2 统计和分形特征融合的运行状态辨识框架
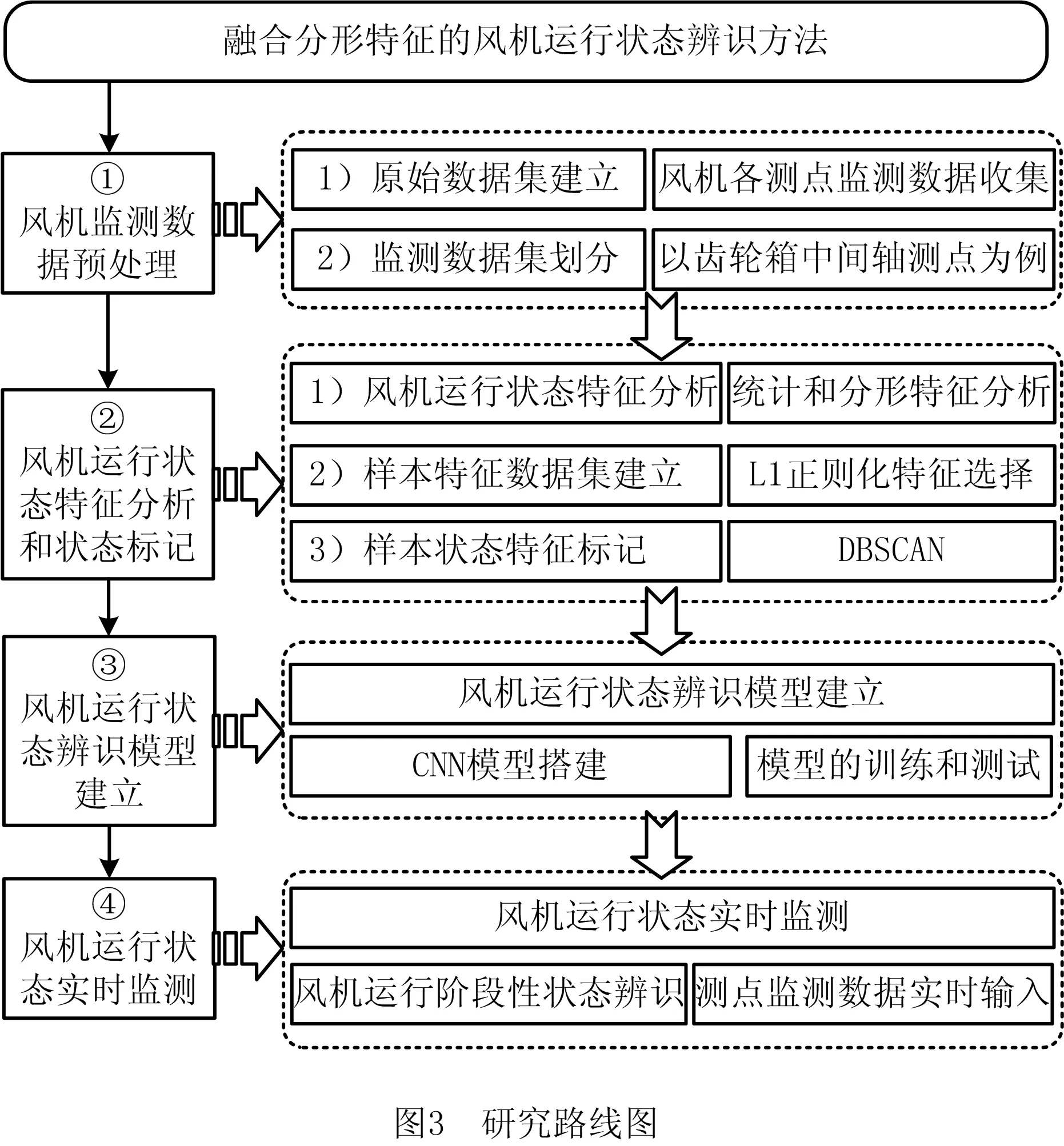
为充分利用风机监测数据,从海量高维的监测数据中准确地学习到内在特征,本章建立风机服役质量状态辨识模型。首先对风机原始监测数据进行预处理,建立时间序列样本的监测数据集;然后提出一种新的风机运行状态特征分析方法,建立初始样本特征数据集;以初始样本特征数据集为依据,采用DBSCAN方法标记状态标签,同时,通过正则化特征选择[32],从初始样本特征数据集中选择重要程度最高的特征建立最终的样本特征数据集;最后,以最终特征选择以及状态标记结果对CNN状态辨识模型进行训练和测试,实现风机运行状态辨识。研究路线如图3所示。
2.1 风机监测数据预处理
按照采样频率和采样时间采集并收集风力发电机组齿轮箱中间轴测点对应的监测数据,利用该测点的监测数据建立原始数据集,其中,每一列为一个时间序列样本,最终建立共包含n个时间序列样本的监测数据集D:
D=[X1,X2,…,XL]T=
其中:Xi为矩阵中每个样本的第i个数据点;xi,j为矩阵中第j个时间序列样本的第i个数据点;L为每个时间序列样本的长度;n为时间序列样本个数。
2.2 风机运行状态特征分析和状态标记
风机运行状态特征分析包括分形等统计特征分析,将特征分析结果整理成初始样本特征数据集,并以此为对象进行DBSCAN无监督聚类,完成状态标记。同时,初始样本特征数据集中可能包含冗余特征,为降低后续训练模型的复杂程度,按照特征对模型的重要程度进行特征选择,建立最终的样本特征数据集。
2.2.1 风机运行状态特征分析
以监测数据集D分析风机齿轮箱中间轴测点处多个时间序列样本的分形等统计特征。
在统计特征分析中,时域特征值是衡量监测数据特征的重要指标。对风机齿轮箱中间轴测点处数据集中的各时间序列样本进行时域统计分析,分别计算其均值、方差、标准差、均方值、均方误差、峰峰值、方根幅值、平均幅值等统计指标和有量纲参数指标。其中,均方值为信号的二阶矩,反映信号的能量;方差为二阶中心矩,反映信号能量的动态分量以及数据的分散程度。经计算,共得到c1个除分形特征外的统计特征。
分形特征分析包括分形维数特征和多重分形特征。不同时间序列样本的分形维数之间有的存在差异,有的较为接近。其中,存在较大差异的样本,其分形维数和Hurst指数能够作为特征反映风机服役质量状态的变化情况,而分形维数较为接近的样本,则需要通过进一步提取多重分形特征进行分析。因此,计算监测数据集D中的n个时间序列样本分形维数和Hurst指数,经计算,得到上述两个分形特征,即c2=2;对时间序列样本进行多重分形分析,得到包括Δf、αmax、αmin和Δα在内的c3个多重分形特征。
2.2.2 初始样本特征数据集建立
综合考虑分形等统计特征,将上述特征建立为初始的样本特征数据集f:
f=[f1,f2,…,fn]T
其中:fi为矩阵中的第i个时间序列样本的全部特征;fi,j为矩阵中第i个时间序列样本的第j个特征;c为分析得到的全部特征的个数,c=c1+c2+c3;n为时间序列样本个数。
2.2.3 样本状态特征标记
选择DBSCAN无监督聚类方法对时间序列样本进行状态特征标记,选取适当的最小样本数MinPts和邻域的距离阈值ε参数,按照邻域内点的个数不少于MinPts的原则进行聚类,得到正常和异常两类样本,分别以0和1表示,样本状态特征标签为y。
2.2.4 风机运行状态特征选择
在以神经网络为代表的人工智能方法中,如果参数太多,则容易造成过拟合,使得模型在训练样本中表现较好,而在实际测试样本中表现较差。为解决上述问题,需要通过特征选择[28]降低模型的复杂程度。本节应用正则化特征选择方法,该方法作为结构风险最小化的策略实现,能够有效抑制过拟合。可以从初始特征集中找到包含信息最多的特征,从而以更紧凑的形式表示原始数据,提高模型的泛化能力。
通过L1正则化对初始化样本特征数据集中的全部特征进行筛选,提取重要程度较高的特征,得到最终的样本特征数据集,用于训练状态辨识模型。L1正则化方法计算最小绝对收缩选择算子(LASSO),其优化目标函数如式(3)所示。
(5)
式中:xi和yi为训练样本及其相应标签;ω为权重系数向量,通过最小化目标函数实现权重系数向量ω的求解;λ为正则化参数,且λ>0。
由式(3)可知,优化目标函数中包含训练样本误差项和正则化项两部分,其中,正则化参数λ起权衡作用。
通过L1正则化特征选择对当前所分析的全部c个特征进行筛选,提取重要程度较高的特征,用于训练状态辨识模型,提取出对模型贡献度最高的8个特征,分别为:分形维数FD、Hurst指数h、均方幅值Xrms、平均值Xmean、峰峰值Xp、平均幅值Xr、分形谱Δf和分形谱Δα。上述特征构成C维样本特征数据集F:
F=[F1,F2,…,F8]T
其中C=8,对应的状态标签为Y。至此,最终的样本特征数据集建立完成。
2.3 建立风机运行状态辨识模型
为充分挖掘和提取风机监测数据特征,表征特征与状态之间的对应关系,本节以样本特征数据集训练CNN模型,通过filter不断提取局部和总体特征,进而建立样本特征与状态标签的对应关系,实现风机运行状态辨识。
CNN具有局部权值共享结构,在处理图像和高维数据过程中可以并行学习,从而降低网络和特征提取过程中数据重建的复杂度。本节将C维样本特征数据与其对应状态标签Y划分成训练集和测试集,将训练集样本特征数据集F作为状态辨识模型的输入,对应的状态标签为Y作为状态辨识模型的输出,训练基于CNN的状态辨识模型,如图4所示。

如图4所示,该模型包含卷积层、池化层、全连接层,最后一层为分类器。以训练集数据作为模型的输入,对应的状态标签作为输出,训练CNN模型分类器,输出状态辨识结果;以测试集数据作为CNN状态辨识模型的输入,经过分类器输出状态标签,输出为0表示模型认为当前输入数据对应的状态为正常状态,输出为1表示模型认为当前输入数据对应的状态为异常状态。
3 实例分析
收集风机各测点的监测数据,取齿轮箱中间轴测点2020年10月17日的24组监测数据,将其划分成包含1 536个时间序列样本的监测数据集D,每个时间序列样本的长度为128;样本数据均为风机齿轮箱中间轴的振动监测量,其物理含义为振幅,单位为mm。分析并选择监测数据集D中各样本的特征值,建立样本特征数据集并标记状态标签,用来训练和测试上述风机服役质量状态辨识模型。
3.1 风机状态辨识模型实例验证
对每个时间序列样本计算样本特征,并采用L1正则化特征选择方法选出重要程度最高的8个特征,建立最终的样本特征数据集。经计算,时间序列样本的特征值见表2~表4。其中,表2为统计特征分析结果,包括均方幅值Xrms、平均值Xmean、峰峰值Xp、平均幅值Xr,列出部分计算结果如表1所示。
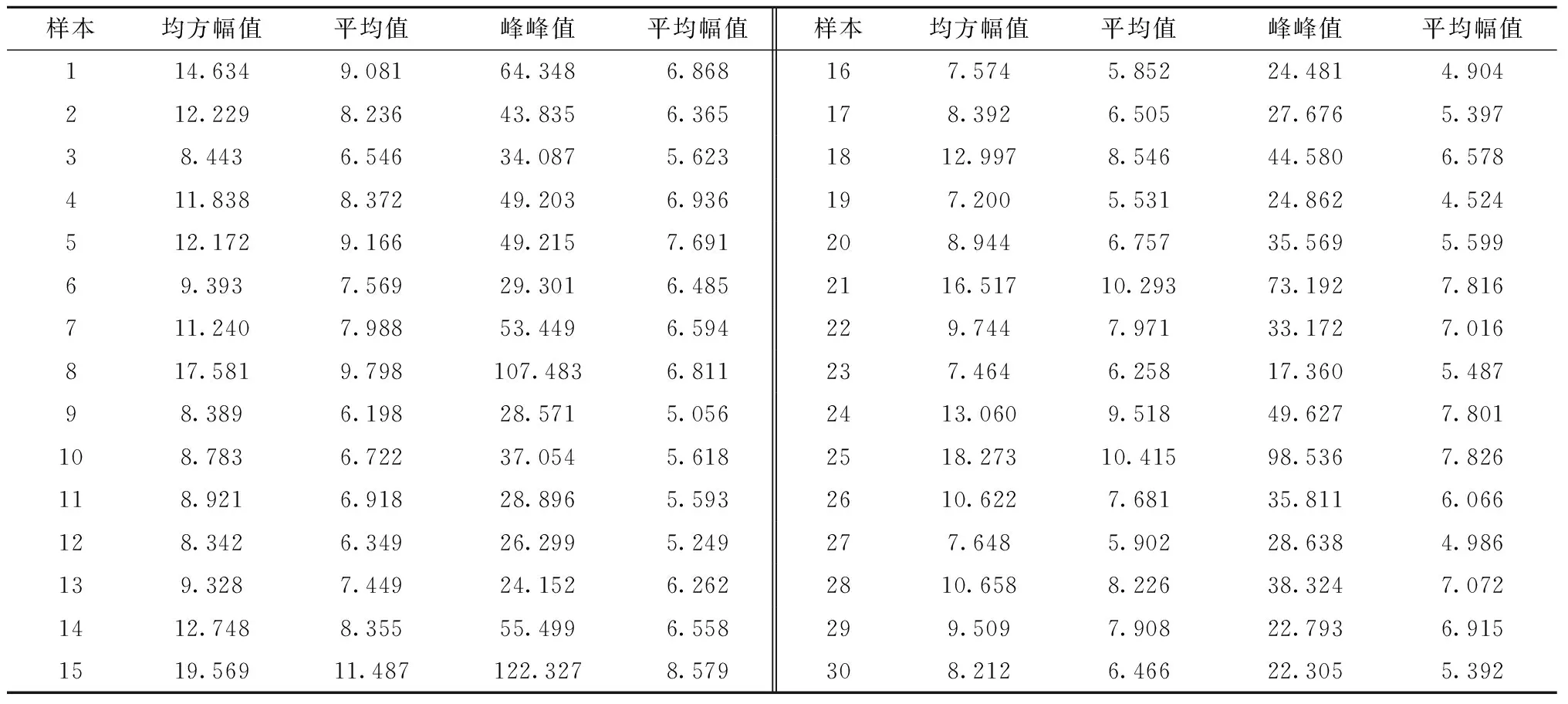
表1 时间序列样本的统计特征分析计算结果
表2和表3为分形特征分析结果。采用Box维数(盒维数)方法计算分形维数,包括分形维数FD、Hurst指数h,列出部分分析结果如表2所示。

表2 时间序列样本的分形维数特征分析结果
由表2可知,不同时间序列样本的分形维数之间有的存在差异,有的较为接近,继续对时间序列样本进行多重分形特征分析,其中部分时间序列样本的特征谱如图5所示。

图5中,不同时间序列样本的多重分形谱的形状和范围存在差异,经过特征选择,提取多重分形特征包括分形谱Δf和分形谱Δα,部分计算结果如表3所示。

表3 时间序列样本的多重分形特征分析结果
将上述样本特征作为状态辨识模型的输入,对应标签作为模型的输出,训练并测试状态辨识模型。CNN状态辨识模型的测试结果如图6所示。
在图6中,状态辨识模型准确率为98.925%,其中圆形图案表示输入的特征经过状态辨识模型后输出的状态为正常状态,菱形图案表示输入的特征经过状态辨识模型后输出的状态为异常状态,星形图案表示状态辨识模型输出的结果与实际状态标签不相符。由图6可知,模型的错分率较低。

将输出结果与真实状态标签对比,记录模型状态辨识的准确率。经多次实验训练,状态辨识模型准确率记录如表4所示。

表4 本文状态辨识模型准确率
由表4可知,经测试,状态辨识模型的准确率随实验次数上升,最高为99.283%,最终状态辨识模型的准确率稳定在98.925%。
综上所述,为验证上述模型的可靠性,从风力发电机组对应测点获取实时测点监测数据,进行预处理和阶段性特征分析,得到样本特征数据集。对重要程度最高的C个特征作为上述状态辨识模型的输入,并记录模型输出的标签,若输出的状态标签为0,表示当前阶段状态为正常状态,则重复上述步骤,持续监测风机运行状态;若输出的状态标签为1,表示当前阶段状态出现异常,则应立即采取停机、维修等措施,避免重大事故发生。
3.2 状态辨识模型效果比较
本文建立的风机服役质量状态辨识模型不同于直接使用监测数据作为输入的状态辨识模型,该模型通过统计分析和分形分析,计算监测数据中的相应特征,能够从风机海量、高维数据中提取有效信息,基于时间序列样本特征,训练CNN模型;而以监测数据作为输入的状态辨识模型只能通过CNN卷积神经网络提取出有限的分布式特征,且可解释性较差。因此,本文对上述两种状态辨识方法进行对比分析。
将风机齿轮箱中间轴测点的监测数据划分成包含1 536个时间序列样本的监测数据集D,每个时间序列样本的长度为128;对时间序列样本,采用DBSCAN无监督聚类方法,标记状态标签;将时间序列样本数据直接作为CNN卷积神经网络模型,样本对应的状态标签作为模型的输出,训练并测试状态辨识模型,测试结果如7图所示。

在图7中,状态辨识模型准确率为93.548%。其中,圆形和菱形图案分别表示状态辨识模型输出的结果为正常和异常状态,星形图案表示状态辨识模型输出的结果与实际状态标签不相符。由图7可知,以测点监测数据直接输入模型进行状态辨识时,相较于本文提出的状态辨识模型,错分率更高。记录该模型的测试准确率如表5所示。

表5 以监测数据作为输入的状态辨识模型准确率
由表5可知,以监测数据作为输入的状态辨识模型,其准确率在89.6%~93.6%之间波动,准确率最高为93.548%,后逐渐稳定在93.190%,但随着实验次数的上升,准确率开始下降。
综上所述,以监测数据作为输入的状态辨识模型,与本文建立的以数据特征作为输入的风机服役质量状态辨识模型不同,由于输入数据较多,模型复杂度提高,造成模型泛化能力较差,此外,参数增加容易造成模型过拟合,使得测试样本表现下降;而本文基于特征分析和特征提取的结果,建立样本特征数据集,用于状态辨识模型的训练,经对比,该方法对海量、高维监测数据处理更有效,对风机服役质量状态辨识的效果更好,模型准确率更高。
4 结束语
本文提出一种新的风机服役质量状态辨识方法,首先基于非人工智能方法提取的时间序列样本特征建立数据集,然后在此基础上应用CNN模型进一步提取分布式特征。针对风机齿轮箱中间轴测点处的监测数据,应用本文构造的基于特征分析和特征提取的状态辨识模型对风机运行状态进行辨识,结果表明,将特征提取结果作为模型输入的状态辨识方法准确率明显高于传统的以监测数据作为输入的状态辨识方法准确率,且模型表现更稳定。
(1)在风机服役质量状态辨识过程中,本文提出的基于特征分析和特征提取的状态辨识模型准确率为98.925%,而以监测数据作为输入的状态辨识模型准确率不高于93.548%,且准确率波动较大。
(2)本文提出的风机服役质量状态辨识方法更加适应监测数据海量、高维的特点,能够有效提取信息,将统计特征、分形特征与神经网络分布式特征相融合,相较于以监测数据作为输入的状态辨识模型,准确率提升5.377%。
(3)本文提出的风机状态辨识方法为实现风机“事前维修”模式提供科学参考和理论指导,可以有效地应用于以风机为代表的复杂机电系统服役质量状态辨识领域,为风力发电机组以及其他复杂机电系统的数据挖掘和模式识别提供了基础。
为兼顾时间序列样本的时间跨度和样本特征数据集的容量,本文将风机原始监测数据合并后直接分段划分,该划分方法虽然能够通过异常特征定位异常段样本,但忽略了时间序列样本的连续性,可能会造成一定的信息损失。后续将针对该问题改进时间序列样本的划分方法,进一步提高风机服役质量状态辨识的效果。
