基于变量因果图的故障定位和传播路径识别方法及应用
2022-08-11张运锋阳春华周飞跃黄科科桂卫华
张运锋,阳春华,周飞跃,黄科科,桂卫华
(1.中南大学 自动化学院,湖南 长沙 410083;2.楚天科技股份有限公司,湖南 长沙 410600)
1 问题的描述
近年来,工业系统朝着大型化、集成化和自动化方向发展[1-2]。这种趋势使得工业系统变得越来越复杂,各子系统之间相互耦合,各变量之间相互影响[3-4],如果系统中发生了故障,该故障通常会由源头变量传播至多个相关变量,从而导致系统多项指标超出设计范围,造成多个报警,一连串的报警会给操作员带来很大的压力,而且操作员并不能根据多个报警准确地判断故障原因,也就不能有相应地恢复操作。故障源头定位和传播路径识别可以找到最先受故障影响的变量,识别早期故障传播路径,从而可以为操作员提供准确的故障信息。
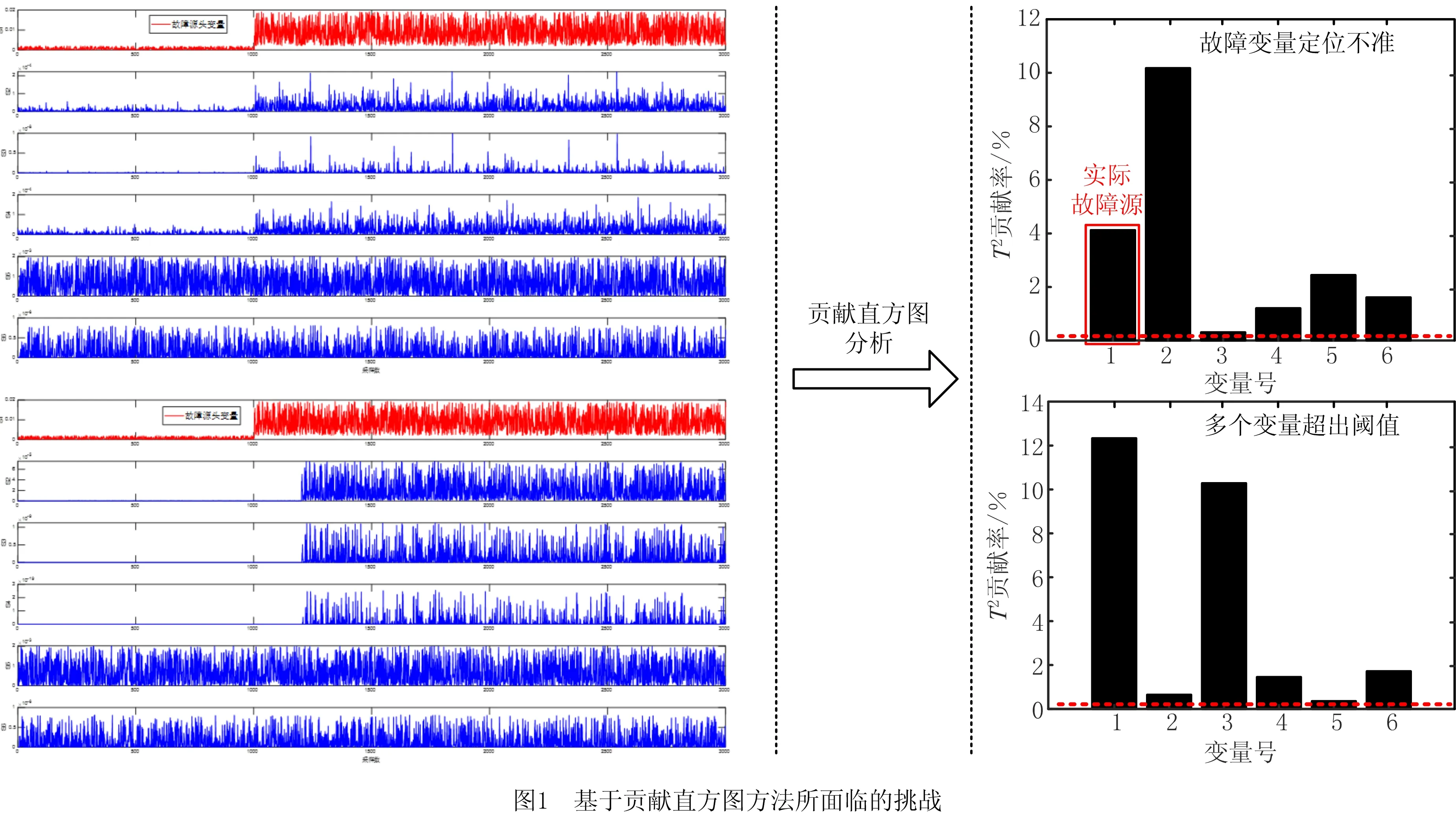
现有的故障定位方法主要包括基于贡献直方图的方法和基于因果分析的方法。其中,基于贡献直方图的故障诊断方法的原理是在检测到故障发生后,系统运行状态会偏离正常运行范围,识别各个变量对这种变化的影响程度,认为影响程度较大的变量应该在故障传播的源头位置。LI等[5]提出了基于贡献直方图的全潜结构投影(Total Projection to Latent Structure, T-PLS)监测方法,并通过计算各个变量对于监测指标的贡献度来进行故障定位。CHAO等[6]提出了稀疏贡献直方图的故障诊断方法并应用到多工况化工过程。HUANG等[7]提出一种分布式字典学习方法,并利用稀疏贡献图来定位故障源变量,为了监测非线性过程,又提出一种基于核的非线性字典学习方法,并应用基于迭代重构的方法来进行故障定位[8]。虽然基于贡献直方图的方法能够给出变量对于故障的贡献程度,诊断出故障,并且被广泛地应用到实际过程,但是这类方法还存在一些问题:①会出现故障定位不准的问题,故障源头变量可能不是贡献度最高的变量,相反受故障影响的变量的贡献度最高,这会导致误诊断;②多个变量贡献度超出阈值,受故障影响的变量较多,都会偏离正常的运行范围,导致多个变量超出阈值范围而被判定为故障变量,这就不能准确地判断故障源头。如图1所示,故障源头均为变量1,即故障最先在变量1发生,然后传播至其他变量,第一组实验以传播链形式传播,第二组实验以级联的形式传播,变量5和6不在传播链上。在传播链实验中,实际的故障的源头是变量1,但是根据基于T2指标的贡献直方图分析,变量1对于故障的贡献度远小于变量2的贡献度,因此变量2更有可能是故障源头,这就表明传统的基于贡献直方图的故障诊断方法存在故障定位不准的问题。在对第二组故障数据进行贡献直方图方法分析过程中,参考文献[9]阈值设置方式,将阈值设置为0.167,发现多个变量的基于T2指标贡献度都超出阈值,这样的结果就不能提供准确的故障源头信息。
为了解决上述问题,基于因果分析的方法受到了广泛的关注,其基本原理是分析变量间的因果关系,利用因果关系构建信息传播网络,通过传播网络定位故障源变量,从而解决故障定位不准的问题。代表性方法包括格兰杰因果分析[10-11]、贝叶斯网络[12-13]和传递熵[14-15]。PYUN等[16]应用多变量格兰杰因果分析方法对变量进行因果分析,从而实现故障定位。LEE等[17]提出一种传递熵方法和图形lasso方法结合来对工业过程进行故障诊断和定位[17]。为了更加清晰地了解故障变量影响关系,识别故障信息传播路径,进而实现故障源头定位,越来越多的研究在因果分析的基础上将因果图的构建引入进来。SU等[18]提出一种基于传递熵和修正条件互信息的方法并且利用传递熵方法构建因果图来实现故障定位。DONG等[19]提出一种基于先验知识的因果网络构建方法和基于偏相关系数的故障诊断方法。MA等[20]提出一种新型分段的贝叶斯网络框架来对质量相关的故障构建因果影响网络,从而实现故障信息传播路径的识别。虽然基于因果图的故障诊断方法已经有了广泛地应用,而且表现出很好的效果,但是这类方法还存在以下3个问题:①在构建因果图时通常需要分析所有变量的因果关系,这个过程计算量大而且所构建出的因果网络较为复杂;②在构建因果图时通常需要先验知识,这些知识在实际过程中很难得到;③传统的因果图构建时通常只关注变量的相互影响情况,而没有对影响关系的时滞进行研究。
为解决传统基于因果图的故障诊断方法所构建的因果网络结构复杂、过程计算量大、依赖先验知识和没有考虑因果影响时滞的问题,本文提出了基于变量因果图的故障定位和传播路径识别方法(Causality Diagram oriented Propagation Path Identification and Fault Isolation, CDPPIFI),该方法能够在没有先验知识的条件下识别故障传播网络和网络中变量的影响关系,从而定位故障源变量并准确地检测故障发生时间。该方法步骤具体包括: ①故障预诊断,对故障进行预检测,检测到故障发生后,利用贡献直方图的方法对数据进行分析,将故障贡献度最高的变量定为潜在故障变量;②构建因果图模型,在训练阶段分析真实因果关系和非真实因果关系特点,构建因果关系阈值,以潜在故障变量为起点,分析变量间因果关系,并利用因果关系阈值对真实因果进行筛选,根据真实因果关系分析结果,构建故障变量因果图模型,并对因果图模型进行溯源定位到故障源变量;③故障重检测,对定位到的故障源变量构建监测指标,进行重检测,找到准确的故障发生时间。据笔者所知,目前尚未有基于因果图来进行故障定位和传播路径识别的方法,因此,本文的主要贡献包括:
(1)提出CDPPIFI方法,该方法能够分析故障发生后变量间的因果关系,从而识别故障传播路径。
(2)CDPPIFI方法能够对故障传播路径进行溯源,并准确定位故障源,同时能够辨识故障传播的时滞。
(3)通过控制系统数值实验和CSTR基准实验,验证了CDPPIFI方法的有效性。
2 基于变量因果图的故障定位和传播路径识别方法
本文所提出的基于变量因果图的故障定位和传播路径识别方法如图2所示。该方法主要包括故障预诊断、因果图模型构建、故障重检测3个步骤,能够识别出故障传播路径并定位故障源头,通过对故障源头变量重检测,提升故障检测效果,接下来对算法步骤进行详细描述。

2.1 故障预诊断
故障预诊断能够确定潜在的故障变量,为后续的故障变量相关的因果图模型构建提供参考,降低传播网络的复杂度,主要包括离线建模、故障预检测和贡献度分析3个步骤。
2.1.1 离线建模
对基于变量因果图的故障定位和传播路径识别算法输入所监测系统正常工况下的运行数据X0=[x1,…,xn]∈Rm×n,其中m表示数据长度,n表示变量维度,按式(1)对数据X0进行标准化,得到数据矩阵X∈Rm×n
(1)

(2)
然后对S进行奇异值分解:
S=PΛPΤ。
(3)

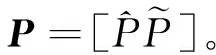
(4)
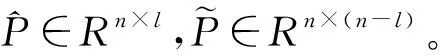

(5)

(6)
当CPV的值超过一个确定百分比时,所对应的l即为所保留的维度,按照T2统计指标确定正常工况的阈值:
(7)
式中Fα(l,m-l)为Fisher-Snedecor分布在自由度为l和m-l时的取值,α为置信度。
2.1.2 故障预检测
(8)
ifT2(i)>Tα,i=1,…,m′。
(9)
若上面的不等式成立,则系统处于故障状态,否则系统处于正常状态。
2.1.3 故障贡献直方图分析

(10)
然后确定失控状态的r(r≤l)个得分,具体确定不等式如下:
(11)
若对于第i个标准化得分满足上面的不等式,则r的值加1,否则r的值不变,r的初始值为0。然后计算每个变量xj(j=1,…,n)对于第i个失控状态得分ti(i=1,…,r)的贡献率cont(i,j):
(12)
式中:pi,j是矩阵P的第(i,j)个元素,μj是第j个过程变量均值。对于cont(i,j)为负值的情况,直接将其定为0。然后计算第j个过程变量xj(j=1,…,n)对于每一个失控得分ti(i=1,…,r)总的贡献率contj:
(13)
得到每个变量对于故障的贡献度后,找到贡献度最大的变量:
conth=max(cont)。
(14)
其中cont∈R1×r,则xh就是潜在的故障变量[2],认为xh在故障影响的传播路径中,注意xh并不一定是故障源头变量。
2.2 基于广度优先的因果图模型构建
基于广度优先的因果图模型构建包括3个步骤:因果关系阈值构建、因果关系分析和传播路径识别与故障定位。首先,分析过程数据的特点,构建出能够区分真实因果关系的阈值,排除因噪声影响所引起的因果关系;然后,以潜在故障变量为起点,分析变量间的因果关系,并与因果关系阈值进行比较,筛选出存在真实因果的节点,得到相关节点的节点集和有向边集信息;最后,根据节点集和有向边集构建出故障信息传递网络,并对因果图模型进行故障溯源。
2.2.1 因果阈值构建
在因果分析过程中,数据中的噪声会对分析结果造成干扰,这些噪声可能是相互传播的,这种传播关系代表了变量之间因果影响的关系,但是也可能这些噪声并不相关,因此因果关系的阈值构建就非常重要,若阈值太小,则会将不相关的噪声也识别为一种因果关系,导致因果网络构建不准确;若阈值设置太大,则会将弱到中的因果关系排除,使构建的因果网络不全面。
考虑如图3所示的系统框图,其中输入S0是服从(-0.1,0.1)均匀分布的随机序列,用来模拟正常工况下的数据,Si(i=1,…,4)是非线性子系统,子系统方程如式(15)所示,

(15)
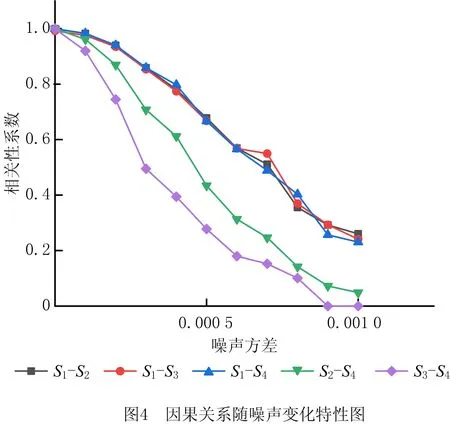
其中:Ai和Bi分别取0.2和0.8;q-2和q-4分别表示2时刻和4时刻的延时,设置了两条不同的传播路径,为了区分两条不同的传播路径,在两条传播路径中分别加入了高斯白噪声ε1和ε2,白噪声的均值为0,方差逐渐递增,研究噪声对因果关系的影响。
在上述系统中S1-S2、S2-S3和S1-S4存在真实的因果,而S2-S4和S3-S4之间不存在真实因果,但是S2和S4都会受到S1的影响,因此从S2和S4数值输出的角度,它们会有一定的相关性。如图4所示,随着噪声的增大,变量之间的相关性都会有一定降低,但是存在真实因果变量的相关性显著高于非真实因果变量间的因果关系,因此,本文采用相关性系数作为衡量因果关系的指标。
2.2.2 因果关系分析
首先,生成空的节点集V(G)和有向边集E(G),将潜在故障节点xh的节点信息存入节点集V(G){…,h,…}中,对于输入数据X=[x1,…,xn]∈Rm×n,以xh为原因变量,以其他变量xj(j=1,…,n)为结果变量,分析它们之间的因果关系,然后颠倒其位置顺序,以xh为结果变量,以其他变量xj(j=1,…,n)为原因变量,分析它们之间的因果关系,其中h≠j。本文采用拓展收敛交叉映射算法[21]计算因果关系。为了使描述不失一般性,下面的计算过程中用参数i代替h。
首先构建变量xj的流形空间:
Mxj(t)=xj(t-τ),xj(t-2τ),…,
xj(t-(E-1)τ)。
(16)
其中1+(E-1)τ≤t≤m,然后寻找Mxj的E+1个临近点,并将这些点与Mxj(t)间的欧氏距离从小到大排列{d1,d2,…,dE+1},记录这些点所对应的时间{t1,t2,…,tE+1}。然后计算这些点对于重构数据的贡献度:

(17)

(18)
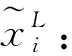
(19)

(20)
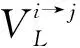
(21)


(22)
若满足上式,则表明i到j存在真实的正向因果,将节点i和j保存进节点集V(G)中,V(G)中节点是n个节点其中之一且不重复,ei→j的影响关系保存在有向边集E(G)中,其中有向边的权值满足:
|ei→j|=Li→j。
(23)
前一个潜在故障变量的相关节点分析完成后,再依次以V(G)中新加入节点为潜在故障变量,分析与其他节点之间的因果关系,重复上述步骤,整个过程满足广度优先的搜索算法,直到V(G)中所有节点的因果关系都分析完成且没有新的节点产生时,算法终止。
2.2.3 传播路径识别与故障定位
首先根据节点集V(G):{i,j,…,i′,j′}标记出所有存在因果关系的节点,然后根据有向边集E(G):{ei→j,…,ei′→j′}对因果关系节点进行连接,构建与故障相关的因果关系网络,注意可能存在节点i和节点j、k都有正向因果关系,同时j存在和k的正向因果关系,则节点i、j和k的连接关系为i→j→k。
再根据有向边集E(G):{ei→j,…,ei′→j′}的权值标记故障传播关系的时滞,得到如图5所示的因果图模型。

在得到故障的因果图模型后,对故障的因果图模型进行故障溯源,定位到故障源头,分析故障源头节点的特征和非源头节点的特征。对于源头节点,只存在由源头节点指向其他节点的有向边,而不存在被指向的有向边,而对于非源头节点,既存在被指向的有向边,又可能存在指向其他节点的有向边,注意在实际过程中可能会出现因果图模型中不存在源变量或者出现多个源变量的情况,在本文中仅考虑一个故障源的情况。综上所述,基于广度优先的因果图模型构建算法步骤如算法1所示。
算法1基于广度优先的因果图模型构建。
Input:数据集X=[x1,…,xn],数据集列数n,因果关系阈值COVthreshold,潜在故障变量xh;
Initialization:V(G)_all={1,2,…,n},V(G)={},V′(G)={index},V″(G)={},E(G)={}
While k≤length(V′(G)) do
i=V′(G)[k],V(G)_all=V(G)_all-V′(G);
While m≤length(V(G)_all) do
i=V(G)_all[m];
步骤1:构建xi和xj的流形空间MxiMxj;
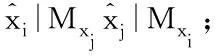

If Li→j≤0

步骤7:将节点i和j存入节点集V″(G),V″(G)中节点不重复;
步骤8:|ei→j|=Li→j,将ei→j的影响关系存入有向边集E(G);
end If
end If
If Lj→i≤0
步骤9:将节点i和j存入节点集V″(G),V″(G)中节点不重复;
步骤10:|ej→i|=Lj→i,将ej→i的影响关系存入有向边集E(G);
end If
end If
end While
V(G)=V(G)+V′(G),V′(G)=V″(G),V″(G)={};
end While
步骤11:根据节点集V(G):{i,j,…,i′,j′}标记出所有存在因果关系的节点。
步骤12:根据有向边集E(G):{ei→j,…,ei′→j′},对故障相关的节点进行连接。
步骤13:根据有向边集E(G):{ei→j,…,ei′→j′}中有向边的权值|ei→j|,标记故障传播关系的时滞,得到故障因果图模型。
步骤14:故障变量溯源,找到没有被指向的因果节点,即为故障源节点。
Output:故障因果图模型、故障源变量。
2.3 故障重检测

(24)
对Sorigin进行奇异值分解:
(25)
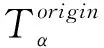
(26)

(27)
在得到测试工况每一个采样时刻的统计量后,将其与阈值进行比较,判断故障源变量进入故障状态的时间,具体比较公式如下:
(28)
若上式满足,则源变量进入故障状态,否则源变量处于正常状态,依此可以确定故障准确的发生时间。
3 实验结果
为了验证CDPPIFI进行传播路径识别和故障定位的能力,设计了控制系统数值仿真和CSTR基准实验。
3.1 算例试验
3.1.1 实验设置
如图6和图7所示,包括大滞后级联实验和传播链实验。在大滞后级联实验中,有两条不同的传播路径,用来模拟信息不同的传递方式,其中S01在前1 000时刻为服从(-0.1,0.1)均匀分布的随机序列,用来模拟正常工况下的数据,在1 000~3 000时刻为(0.1,0.3)均匀分布的随机序列,用来模拟故障工况下数据,而S02在3 000时刻内均为(-0.1,0.1)的均匀分布,即S02这条传播路径上均处于正常工况。考虑6个非线性子系统Si(i=1~6),子系统方程如式(19),其中Ai和Bi分别取0.2和0.8,q-2和q-4分别代表2时刻和4时刻的延时,为了模拟故障在经过长时间的传播后才影响子系统,在S1和S2之间加入200时刻延时。在传播链实验中,同样是设置了两条支路,并且在第一条支路中设置了两条不同的传播路径,为了区分两条不同的传播路径,在两条传播路径中分别加入了高斯白噪声ε1和ε2,白噪声的均值为0,方差为0.005,输入信号S01、S02、子系统S1-S6和子系统间的延时设置均参照大滞后级联系统。


3.1.2 大滞后级联实验
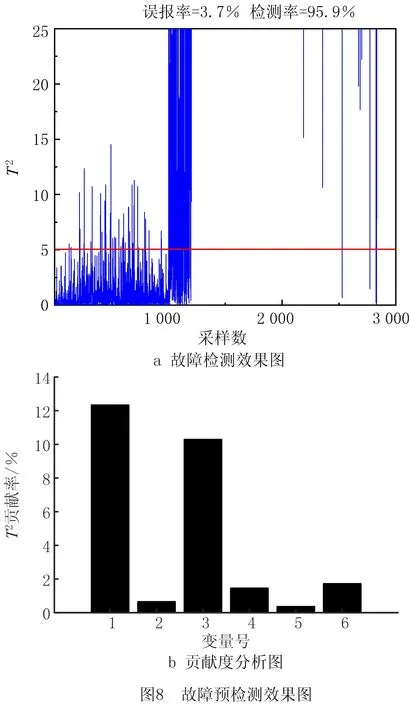
应用CDPPIFI算法对大滞后级联系统数据进行分析,首先是主成分分析(Principal Component Analysis, PCA)预诊断,利用过程正常工况数据构建阈值,然后对测试数据进行故障预检测,得到如图8a所示的故障检测效果图,故障的检测率为95.9%,误报率为3.7%。在预检测发现故障发生后,对故障发生时刻的数据进行贡献度分析,得到如图8b所示的贡献度分析图。贡献直方图显示变量S1、S3和S6对故障都有明显的贡献度,无法定位到具体的故障源头变量,可以确定S1是潜在的故障变量。
然后进行因果图模型构建,分析系统真实因果和非真实因果关系,设置因果关系的阈值为0.9。结合潜在故障变量为S1,对节点间的因果分析,并将分析的结果与阈值比较,筛选出存在真实因果的节点,可以得到节点集V(G):{S1,S2,S3,S4}和有向边集E(G):{eS1→S2,eS1→S3,eS1→S4,eS2→S3,eS2→S4,eS3→S4},其中|eS1→S2|=200,|eS1→S3|=202,|eS1→S4|=204,|eS2→S3|=2,|eS2→S4|=5,|eS3→S4|=3。根据有向边集和节点集可以构建如图9a所示的故障信息传播网络G,可以发现利用CDPPIFI识别出来的因果网络并没有包含S5和S6节点,这是因为S5和S6之间的影响是噪声导致而非故障导致,这说明CDPPIFI算法可以准确识别故障所引起的因果影响关系;同时各节点间的影响时滞和实验设置的延时基本吻合,这样的结果说明CDPPIFI算法可以较为准确地识别因果关系影响的时滞。对故障传播网络进行溯源,可以定位到故障的源头是S1,而实验设置时,故障信号S01首先会影响到S1,即在所有被监测节点中,S1最先受到影响,实验结果和实验设置情况一致,这样的结果表明CDPPIFI算法可以准确地定位到故障的源头。然后以格兰杰因果分析方法对系统数据进行分析作为对比实验,格兰杰因果方法以假设检验的方式来判断两节点之间是否存在因果关系,在本文中采用F检验、卡方检验、似然比检验和参数F检验4种假设检验方法,时间尺度取为10,若出现假设检验的概率小于5%的情况,认为两序列之间存在格兰杰因果关系,否则不存在因果,根据格兰杰因果分析结果可以得到如图9b所示的故障信息传播网络。可以发现,格兰杰因果构建的故障信息传递网络并不符合实际情况,没有反映故障信息的传递情况,根据故障信息传递网络无法定位到故障源头,不能检测出故障信息影响的时滞。

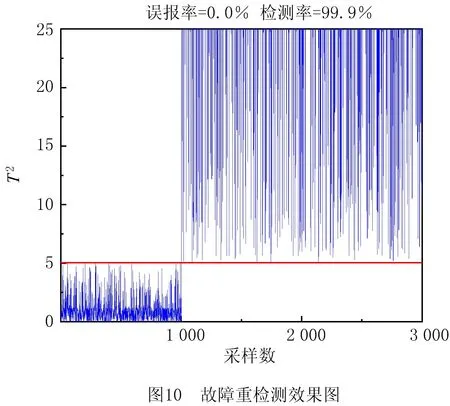
最后,对故障源变量S1进行重检测,可以得到如图10所示的故障重检测效果图,故障重检测的检测率为99.9%,误报率为0%。在大滞后级联实验设置中,故障在1 000时刻被引入系统,并且在节点S1和S2之间存在200时刻延时,故障信息在200时刻之后才传播至整个系统。和PCA预检测相比,本文方法可以更早地检测到故障,而PCA方法因为故障传播时滞的存在,在1 000~1 200时刻有较高的误报。
3.1.3 传播链实验
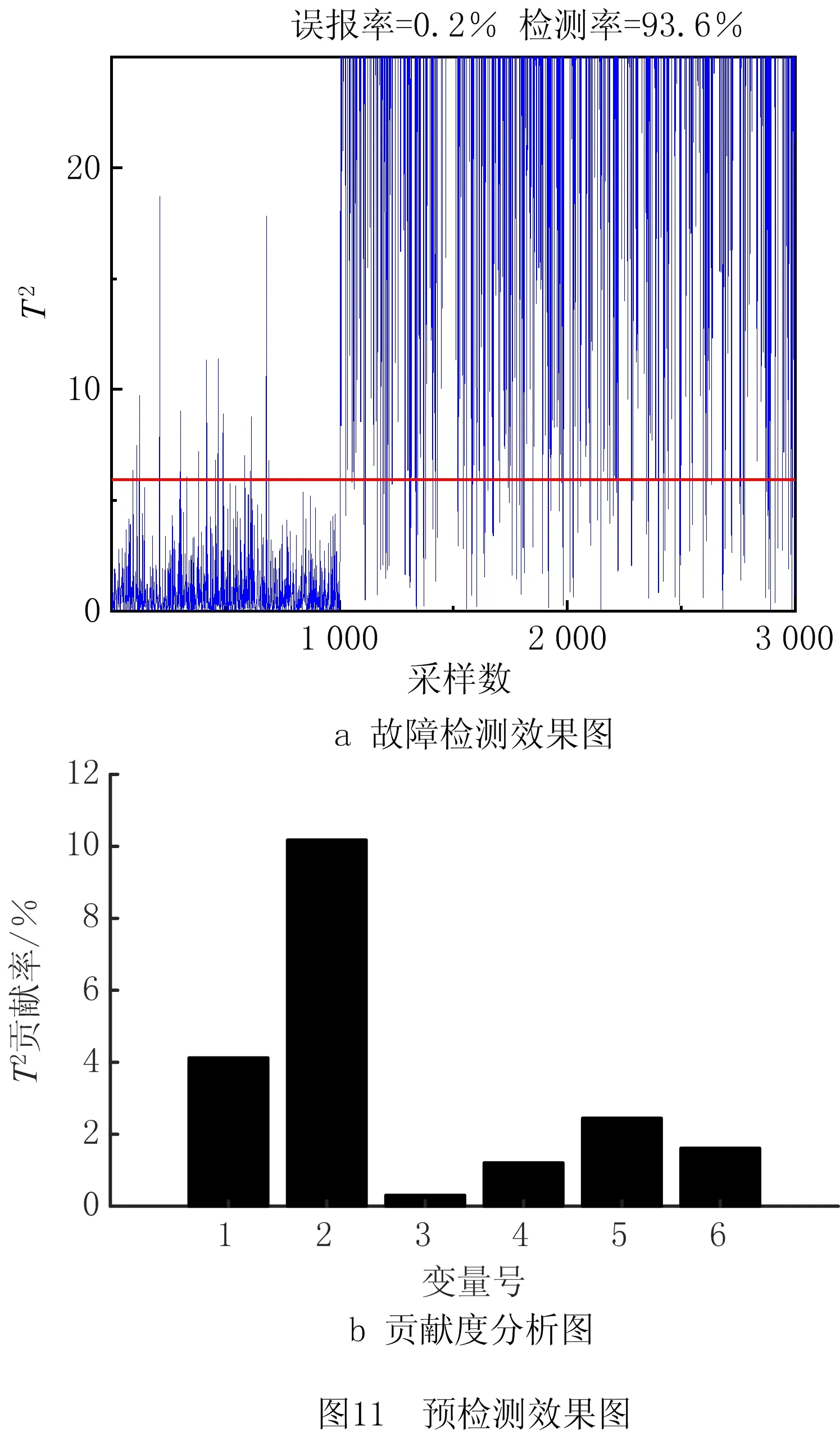
应用CDPPIFI算法对传播链系统实验数据进行分析,首先进行PCA预诊断,得到如图11a所示的故障检测效果图,故障检测率为93.6%,误报率为0.2%。在预检测发现故障发生后,进行贡献度分析,得到如图11b所示的贡献度分析图,定位到贡献度最大的变量,即为潜在故障变量。从贡献度图中可以定位到潜在的故障变量为S2,虽然它不是源头变量但是它在故障的传播路径中。
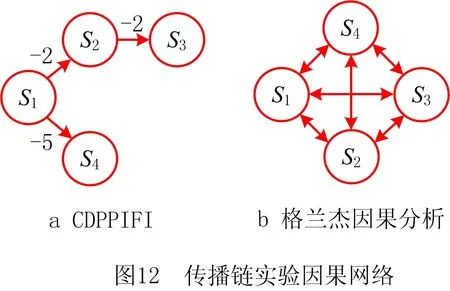
然后构建因果图模型,分析系统真实因果和非真实因果关系,设置传播链实验的因果阈值为0.4;以潜在故障变量S2为起点,对系统节点间因果关系进行分析,筛选出存在真实因果的节点,可以得到节点集V(G):{S1,S2,S3,S4}和有向边集E(G):{eS1→S2,eS1→S3,eS1→S4,eS2→S3},其中|eS1→S2|=2,|eS1→S3|=4,|eS1→S4|=5,|eS2→S3|=2。根据有向边集和节点集可以构建如图12a所示的故障因果网络。网络的连接关系和传播链实验故障支路的设置情况一致,同时,关于节点间因果关系影响的时滞和实验设置的情况基本一致,除了S1到S4之间的时滞存在1时刻的偏差,分析原因是因为系统噪声的影响,这样的结果说明CDPPIFI算法可以识别出传递链实验中因果影响关系以及影响的时滞。对传播网络进行溯源,可以得到故障源变量为S1,和实验设置情况吻合,这个结果说明CDPPIFI算法可以准确地定位到故障源头。以格兰杰因果方法对系统数据进行分析作为对比实验,根据格兰杰因果分析结果可以得到如图12b所示的故障信息传播网络。可以发现,格兰杰因果构建的故障信息传递网络无法识别单向的故障信息传递关系,从识别的故障信息传播网络无法定位到故障源头,不能识别出故障信息影响的时滞。
最后,对源头变量S1进行重检测,可以得到如图13所示的故障检测效果图,检测率为99.3%,误报率为0.0%。本文提出的方法和PCA预检测方法相比,有更高的检测率和更低的误报率。

3.2 CSTR基准实验
3.2.1 CSTR基准过程描述
反应釜的输入为进料浓度Cin和反应温度θf1,Cin=1 mol·L-1并加入N(0,0.1)的高斯白噪声,θf1=350K并加入N(0,3)的高斯白噪声,反应的主要生成物为A,但是会有副反应使一部分A转换为B,再有少部分B转换为C,反应满足式(33)~式(35),CA(t)、CB(t)和CC(t)分别表示在采样时刻t,物料A、B和C的浓度,与反应相关的参数如表1所示。为了能够更好地反映物料反应的时间,在每个参数影响效果上都加入了2时刻的延时。采集正常工况下运行的1 000时刻数据作为训练集;对CA、CB和CC节点在1 000时刻分别注入服从(-5,5)均匀分布的故障信号,模拟故障的发生,故障运行至3 000时刻,以总共3 000时刻的数据作为测试数据集。

表1 CSTR基准模型参数表
(33)
(34)
(35)
3.2.2 CA故障
首先,进行PCA故障预检测,得到如图14a所示的故障检测效果图,故障的检测率为85.95%,误报率为2.00%。再进行故障贡献度分析,得到如图14b所示的贡献度分析图,定位到潜在的故障变量为3号变量,即CA变量为潜在故障源头。

然后,进行因果网络构建,设置因果关系的阈值为2.5,以潜在的故障变量CA为起点,对节点间的因果关系进行分析,可以得到节点集V(G):{CA,CB,CC}和有向边集E(G):{eCA→CB,eCA→CC,eCB→CC},其中|eCA→CB|=4,|eCA→CC|=7,|eCB→CC|=4。根据节点集和有向边集可以构建如图15a所示的因果图网络。对故障因果图模型进行溯源,可以将故障源头定位于CA,和故障的实际设置情况一致,表明CDPPIFI算法可以准确定位到CA故障源头。以格兰杰因果方法对系统数据进行分析作为对比实验,根据格兰杰因果分析结果,可以得到如图15b所示的因果图网络。可以发现,相较于本文提出的方法,格兰杰因果构建的故障信息传递网络无法识别单向的故障信息传递关系,无法定位到故障源头。

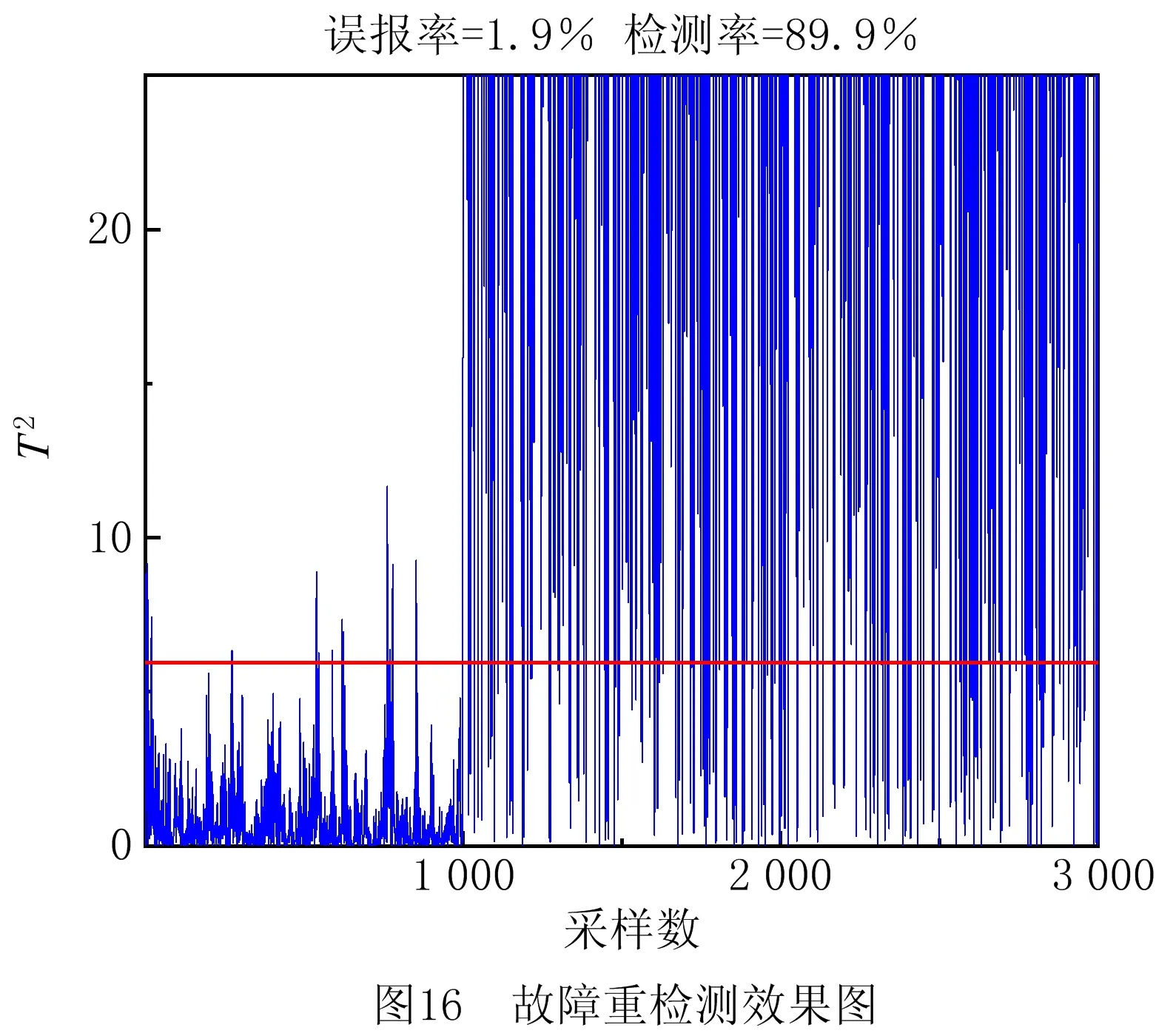
最后,对故障源头变量CA进行故障重检测,检测率为89.9%,误报率为1.9%,具体的故障重检测效果图如图16所示。相比于PCA预检测,本文提出的方法对CA故障有更高的检测率和更低的误报率。
3.2.3 CB故障
首先,进行PCA故障预诊断,得到如图17a所示的故障检测效果图,故障的检测率为68.50%,误报率为0.80%。再进行故障贡献度分析,得到如图17b所示的贡献度分析图,定位到潜在的故障变量为4号变量,即CB变量为潜在故障源头。

然后,进行因果图模型构建,将因果关系阈值设置为2.5,以CB变量为起点,对节点间的因果关系进行分析,可以得到节点集V(G):{CB,CC}和有向边集E(G):{eCB→CC},其中|eCB→CC|=5。根据节点集和有向边集可以构建如图18a所示的因果网络,对因果图网络进行溯源,可以将故障定位于CB,和故障实际设置情况一致,表明CDPPIFI算法可以准确定位到CB故障源头。以格兰杰因果方法对系统数据进行分析作为对比实验,根据格兰杰因果分析结果可以得到如图18b所示的因果网络,可以发现相较于本文提出的方法,格兰杰因果构建的故障信息传播网络无法识别单向的故障信息传递关系,无法定位到故障源头。

最后,对故障源头变量CB进行故障重检测,检测率为87.1%,误报率为1.4%,具体的检测效果图如图19所示。相比于PCA预检测,本文提出的方法,对CB故障有更高的检测率和更低的误报率。

3.2.4 CC故障
首先,进行PCA故障预检测,得到如图20a所示的故障检测效果图,故障的检测率为91.9%,误报率为1.5%。再进行故障贡献度分析,得到如图20b所示的贡献度分析图,定位到潜在的故障变量为5号变量,即CC变量为潜在故障源头。
然后,进行因果图模型构建,将因果关系阈值设置为2.5,以CC为起点,对故障工况下节点间的因果关系进行分析,可以得到如图21a所示的因果网络,分析结果显示,CC节点和其他节点不存在因果关系,这表明CC节点是故障源头,且不会影响其他节点,结合CSTR基准过程分析,CC节点在流程的底端,只会被影响,不存在影响其他节点的情况,与CC故障设置情况一致,这样的结果表明CDPPIFI算法可以准确定位到CC故障源头。以格兰杰因果方法对系统数据进行分析作为对比实验,根据格兰杰因果分析结果可以得到如图21b所示的因果网络。可以发现,格兰杰因果构建的故障信息传递网络无法识别单向的故障信息传递关系,无法定位到故障源头。

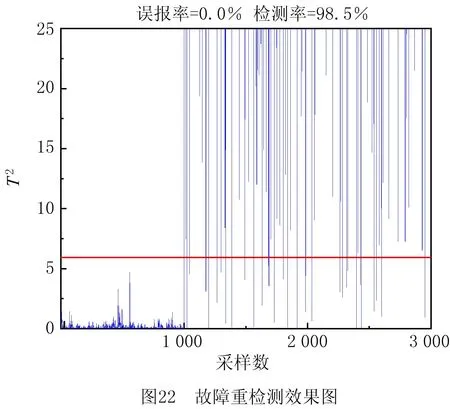
最后,对故障源头变量CC进行故障重检测,检测率为98.5%,误报率为0.0%,具体的检测效果图如图22所示。相比于PCA预检测,本文提出的方法对CC故障有更高的检测率和更低的误报率。
4 结束语
本文提出了CDPPIFI算法框架,设计了级联和传播链系统,并将故障植入到系统中,应用算法诊断框架对系统数据进行分析,验证了所提出算法框架能够定位故障源、检测故障传播时滞和构建故障因果图模型,同时可以在故障传播早期准确检测故障发生时间。将算法框架应用到CSTR进行故障诊断,验证算法能够定位工业过程仿真系统故障源。但是本文的研究对象都是开环系统,关于闭环系统的故障诊断情况是下一步要研究的内容。
