基于CUDA的光纤传像束光纤数量优化检测
2022-08-11张永杰陈文建李武森
张永杰,陈文建,李武森
(南京理工大学 电子工程与光电技术学院,南京 210094)
0 引 言
可以发现,对于圆或类圆的检测已有了深入研究,但在提出或改进算法的同时不能兼顾处理速度是目前最突出的问题之一。不仅如此,现阶段很多算法仅使用C语言或Matlab平台编写都存在着运行速度缓慢的问题,尤其是大矩阵和大数据运算。统一计算设备架构(Compute Unified Device Architecture,CUDA)是一款由英伟达(NVIDIA)推出的通用并行计算架构,该架构使图形处理器(Graphic Processing Unit,GPU)能够解决复杂的计算问题。本文在使用基于欧拉数(Euler Number)计算的边缘优化处理算法的基础之上,对采集样本图像中的光纤数量进行精确检测,并研究了一种基于CUDA使用C语言编写算法的软件系统。实验结果表明,使用该系统对光纤传像束端面图像进行检测,能准确分类光纤轮廓并计算数量,同时大幅度提高了检测速度。
1 光纤传像束端面图像采集


图1 图像采集系统原理示意图
假设光纤传像束端面恰好完整成像于相机传感器靶面上。在相机选型时,记相机最高分辨率为m×n像素(m和n分别为相机靶面的长度和宽度),并设m′×n′为最小像元分辨像素(最小像元是一个矩阵单元,m′和n′分别为矩阵的长度和宽度),则相机在该系统里理论上可以一次性完整检测出的极限光纤数量N为
例如,本次实验使用的相机分辨率为1 920×1 080 pixel。通过测试分析,最小像元分辨像素为4×4 pixel。因此,该相机理论上可以准确检测出完整成像的极限光纤数量约为5.7万个。
通过实验,得到如图2所示的光纤传像束端面图像样本。

图2 光纤传像束端面图像样本
该图像尺寸为1 920×1 080 pixel,单根光纤像元尺寸为26×26 pixel。分析可知,此时β偏高,导致成像过大;若需得到完整的端面图像,结合式(2)可适当增大f1或减小f2。该图像效果基本满足设计要求,本文将主要针对该类采集不完整的端面图像做进一步研究分析。
2 算法设计
2.1 基于欧拉数计算的边缘优化处理
对于图2所示的样本图像,由于β不合适导致图像边缘处的光纤轮廓拍摄不完整。在实际计数或者人为判断时,很难将这些拥有随机不完整度的不完整轮廓逐个分类,因此造成最终计算结果存在差异。针对此类现象,本文提出了一种优化处理算法,即针对每一个轮廓进行欧拉数计算,然后对有着不同欧拉数计算结果的轮廓进行不同的处理,最后将轮廓归为“完整轮廓”和“不完整轮廓”两种类型并分别标记与计算数量。
本次研究两组患者,对照组遵医率77.39%、疾病相关知识掌握程度76.52%、护理满意度75.65%,观察组遵医率98.26%、疾病相关知识掌握程度95.65%、护理满意度99.13%;两组比较可知,观察组遵医率、对疾病相关知识掌握程度、满意度均显著高于对照组,差异均有统计学意义(P<0.05),如表1所示;
在二值图像分析中,欧拉数作为重要的拓扑特征之一,不会因图像的放大、缩小、旋转和变形而发生改变,在图像分析和几何对象识别中有着十分重要的作用[9]。欧拉数的一般定义为图像中包含的连通域数量与孔洞数量之差,其计算公式为
式中:M为连通域数量;H为孔洞数量;E为相减后得到的欧拉数。图3所示为欧拉数测试样本,对于字母A来说,其本身是一个完整的连通域,并且内部有一个三角形的黑色孔洞,因此“A”的欧拉数为0;对于字母B来说,它是一个完整的连通域并且有两个黑色孔洞,因此“B”的欧拉数为-1;而字母C虽然是一个完整的连通域却不存在孔洞,因此“C”的欧拉数为1。由此可见,依据连通域和孔洞信息,便可以将3个不同的英文字母分为3类。

图3 欧拉数测试样本及结果
本文针对边缘检测后光纤轮廓的特点,在此计算基础上对欧拉数做了新的使用定义:将边缘检测后光纤轮廓的外层定义为第1层轮廓即母轮廓,将光纤轮廓的内层即孔洞轮廓定义为第2层轮廓即子轮廓,因此欧拉数新的定义便是母轮廓数量与子轮廓数量之差。对于正常情况下检测完整的光纤轮廓的欧拉数计算,类似于字母“O”的一般定义计算;而对于在图像边缘处被截断的光纤轮廓,由于边界线的存在使其不再具有严格意义上的孔洞,因此这类光纤轮廓仅有第1层轮廓,类似于字母“C”的一般定义计算。图4所示为欧拉数检测结果,模拟绘制边缘检测后的几种光纤轮廓示意图及其欧拉数检测结果。

图4 欧拉数检测结果
其中,左边3个轮廓是为了验证不完整度对欧拉数计算的影响,右边两个轮廓是为了凸显欧拉数的计算方式:当轮廓内有子轮廓时,将母轮廓标记为红色,子轮廓标记为绿色;否则,标记为蓝色。可以发现,完整轮廓的欧拉数计算结果都为0(有子轮廓),不完整轮廓的欧拉数计算结果都为1(无子轮廓)。因此,本文便可将所有光纤轮廓依据新的欧拉数定义进一步分类:若E≤0,将外轮廓填充为红色,内轮廓填充为黑色(背景色);若E>0,将轮廓填充为绿色。具体的边缘优化效果如图5所示。如图5(b)所示,红色轮廓代表检测到的“完整轮廓”,绿色轮廓代表“不完整轮廓”,实验结果基本满足设计要求。为了进一步分析该优化方法的稳定性,通过控制变量改变阈值和形态学参数,实现在不同条件下的光纤数量检测,如表1所示。

图5 边缘优化效果
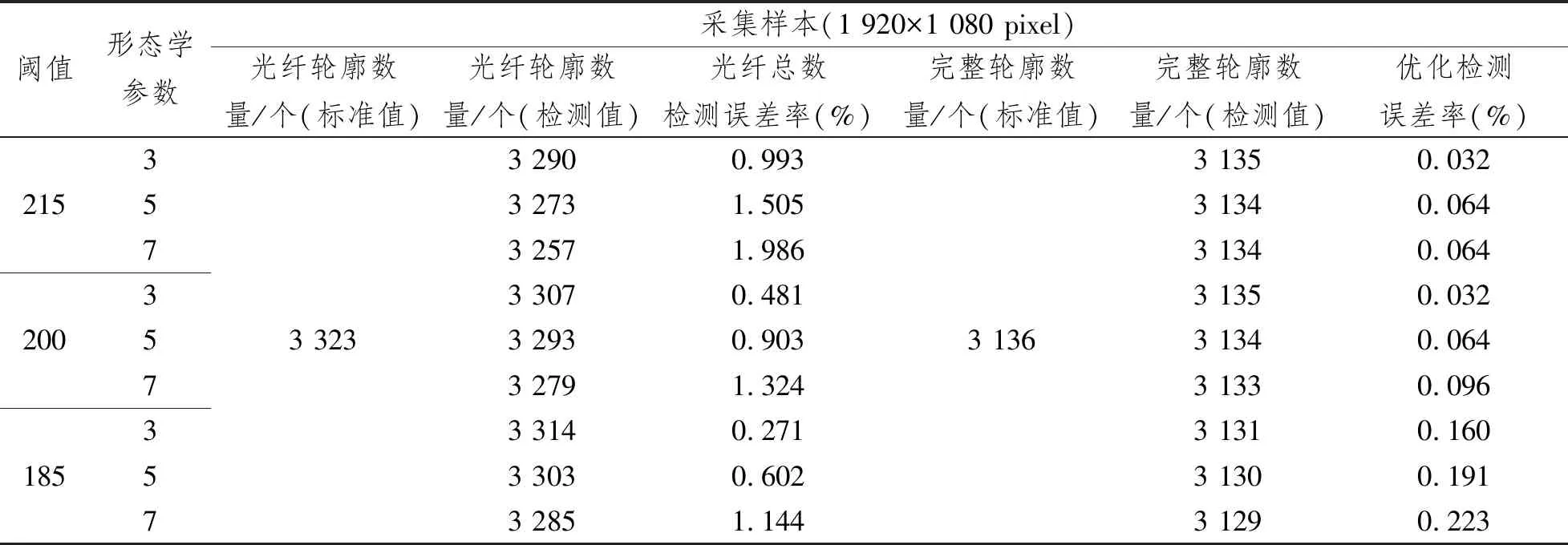
表1 边缘优化检测结果
表中,光纤轮廓数量和完整轮廓数量的标准值是通过人工检测计算出的实际值,检测值是通过本文算法计算得到的测量值。通过分析数据可知,常规检测模式(未采取优化措施)下的检测数量对阈值和形态学参数的变化比较敏感,不同参数会使边缘处轮廓不同程度地被筛除,导致检测结果略不稳定;但是,在本文的预处理操作下,可以将光纤总数的检测误差率控制在0.271%,基本满足设计需求。另一方面,本文主要研究的是“完整轮廓”和“不完整轮廓”的标记与计算,结合图5与表1可知,本文采取的基于欧拉数计算的边缘优化处理算法可以将完整轮廓的检测误差率控制在0.032%,检测值与标准值几乎一致,达到了预期设计要求;同时,该优化算法还降低了检测结果受参数变化的影响,提高了稳定性。
2.2 算法流程
本文所涉及到的算法主要分为3个阶段,图6所示为光纤传像束光纤数量检测流程图。
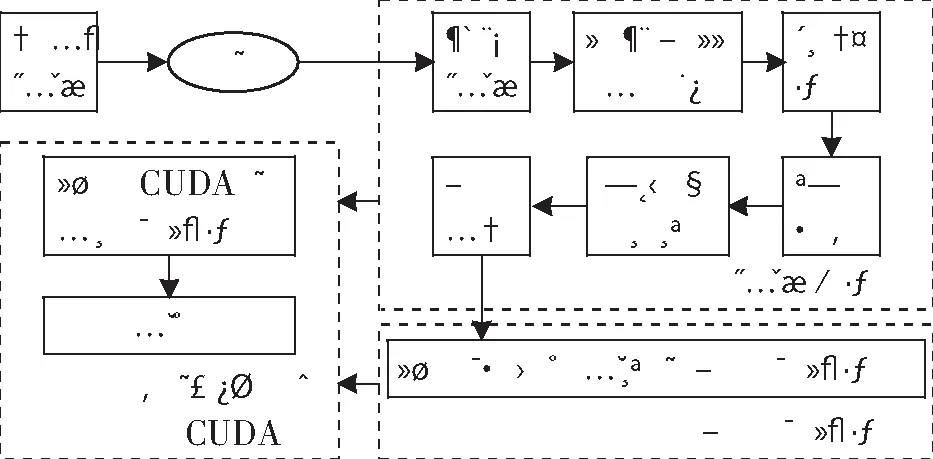
图6 光纤传像束光纤数量检测流程图
(1) 图像预处理
针对性的图像预处理技术可以大幅度提高检测结果的准确性[10]。对传输到电脑的样本图像,首先进行灰度处理及线性灰度增强,将图像中的像素进行线性扩展,从而有效改善曝光过度或模糊不清的问题。滤波处理选择的是双边滤波,虽然运行速度较慢,却能很好地达到保边缘和去噪的双重目的[11]。再进行阈值分割得到所有光纤的二值图像,以及使用形态学运算使目标光纤的二值图像特点更加明显突出。最后进行边缘检测,由于Canny算子易使边缘不连续,因此选择了能用线条较好描述图像的Sobel边缘检测。
(2) 边缘优化处理
针对边缘检测得到的二值图像,在图像边缘处存在具有随机不完整度的不完整轮廓,根据对轮廓进行欧拉数计算,将所有轮廓分类处理并计算数量(具体操作如2.1节所示)。
(3) 各模块调用CUDA
针对以上基于常规预处理方式得到的结果,虽然已可以准确检测出两种类型的光纤数量,但是仍然和文献中一样存在着运行速度缓慢的问题,尤其是双边滤波环节,在对高像素图像进行处理时,等待时间十分漫长。因此,本文研究了一种在Visual Studio的环境下,使用C++及开源计算机视觉库(Open Source Computer Vision Library,OpenCV),通过使用CUDA调用GPU来实现算法加速运行[12]的方法。
3 加速优化
3.1 加速原理
与中央处理器(Central Processing Unit,CPU)不同,GPU是专门为处理图形任务而产生的芯片,一推出就包含了比CPU更大的带宽和更多的处理单元,使得其在多媒体处理过程中能够发挥更大的效能[13]。CPU的串行运算与GPU的并行运算之间的区别如图7所示。
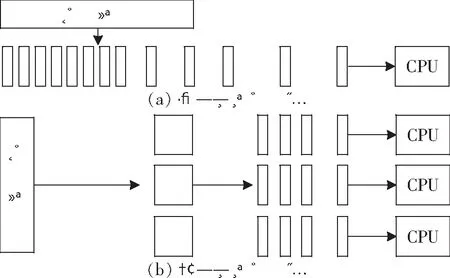
图7 串行运算与并行运算的区别示意图
传统的CPU串行运算包括以下几个特点:(1) 运行在使用单一处理器的计算机上;(2) 一个问题可以分解成一系列离散的指令;(3) 离散的指令必须一个接着一个执行;(4) 同一时刻只能执行一条指令。
相比之下,GPU并行计算做了很多重要的改进:(1) 运行在可以使用多个处理器的计算机上;(2) 一个问题可以分解成若干无直接关联的指令集部分;(3) 每个部分可以进一步细分为一系列离散的指令;(4) 这些离散的指令可以同时在不同处理器上分别执行。
为充分利用GPU的计算能力,NVIDIA在2006年推出了CUDA编程模型,其包含了CUDA指令集架构(Instruction Set Architecture,ISA)以及GPU内部的并行计算引擎。CUDA体系结构包含了3个部分:开发库、运行期环境和驱动[13],其中开发库提供了两个标准的数学运算库——CUDA离散快速傅里叶变换(CUDA Fast Fourier Trans,CUFFT)和CUDA离散基本线性计算(CUDA Basic Linear Algebra Subprograms,CUBLAS),可以解决很多典型的大规模并行计算问题。通过这项技术,用户可以利用NVIDIA GeForce 8以后的GPU和较新的Quadro GPU进行计算。以GeForce 8800 GTX为例,其核心拥有128个内处理器,而利用CUDA技术,就可以将这些内处理器串通起来成为线程处理器去解决数据密集的计算,而各个内处理器之间还可以交换、同步和共享数据[14]。
3.2 加速效果
图8所示为本文研究中针对如图2所示样本图像,在算法流程和性能参数完全一致的前提下,分别使用CPU和GPU检测的效果图。
通过观察可知,其检测结果近乎一致,且“完整轮廓”和“不完整轮廓”均成功标记,证实了该加速功能的可行性。在检测效果图中,有个别位置呈深蓝色或灰色,是因为该位置的光纤存在断丝或暗丝现象;同时,有个别光纤轮廓没有与实际轮廓完全重合,是因为该位置的光纤传像束端面有污渍,干扰了识别检测。表2所示为本文研究中针对该样本分别使用两种检测方式的运行时间对比结果。

图8 CPU和GPU检测效果图

表2 系统加速时间对比结果
表中,滤波处理、阈值分割和边缘检测等预处理算法与现阶段最新的算法相比并无实质性的改进,而边缘优化处理算法则是本文独立设计的改进算法。实验结果表明,本文系统所采取的基于CUDA的加速处理方法,不仅检测结果与标准值一致,而且加速效果明显。其中,双边滤波提速约20倍,优化算法及整体运行减少近1/2时间。实验结果基本符合理论设计和需求,且检测结果符合光纤传像束的实际状况。
4 结束语
本文针对光纤传像束端面图像检测中图像采集不完整的情况,提出了一种基于欧拉数计算的边缘优化处理算法,将图像中所有光纤轮廓依据新的欧拉数使用定义进行分类并计算数量,有效增强了检测结果的稳定性与准确性。在改进算法的同时,针对常规的OpenCV图像处理效率低下的问题,本文研究了一种基于CUDA的并行计算架构,通过调用电脑GPU来加速图像处理系统,在检测准确率不下降的前提下大幅度减少了程序运行时间,提高了工作效率。本文提出的检测思路及方法不仅适用于光纤传像束的端面检测研究,也广泛适用于对圆或类圆目标的定位及数量检测。
