基于IP网络质量优化的监测方案设计
2022-08-11成梦虹成芝言
黄 旭,成梦虹,成芝言
(中国移动通信集团设计院有限公司,北京 100080)
0 引 言
网络质量一直是运营商重点关注的指标,主要影响因素包括网络链路拥塞、时延和丢包等。目前常采用因特网包探索器(Packet Internet Groper,PING)、路由追踪(Traceroute)和远程包探索(Remote Packet Internet Groper,RPING)等方法完成网络质量的主动探测[1],利用简单网络管理协议(Simple Network Management Protocol,SNMP)采集链路流量实现链路拥塞监控。但现有主动发起的探测及监控方法都不具备时效性,往往是故障或质差发生后的问题查询手段。
随着用户业务的多元化、网络架构的复杂化和边缘化[2],现有探测方法和监控手段已无法满足运营商对网络质量提升的要求,更无法支撑行业重点客户的服务级别协议(Service Level Agreement,SLA)保障需求。现有网络目前没有一套完整的、有效的网络整体质量和用户业务质量监测方案。为解决这一问题,本文结合随流检测(In-situ Flow Information Telemetry,IFIT)、双向测量(Twamp)、高速采集(Telemetry)和数据流分析(Flow)等技术,提出了基于IP网络质量的监测方案设计,采用统一架构实现网际互连协议(Internet Protocol,IP)网络不同维度的质量监测。最终,结合不同场景的人工智能(Artificial Intelligence,AI)预测完成整体网络及客户业务的质差预警,利用运维方法及流程设计实现网络质量提升的目标。
1 研究思路
1.1 架构设计
以设备层、协议层、采集层、应用层和分析层设计方案架构,统一部署Twamp、IFIT和Netflow等协议/技术,完成网络设备时延和丢包等性能数据封包。利用Telemetry+SNMP完成性能和流量等数据的采集,结合网络时延、丢包率和链路利用率等质差分析方法及AI预测方法,最终完成网络整体质量及行业重点客户的端到端业务质量提升。
1.2 应用思路
(1)网络整体质量监测:采用Twamp技术代替现有PING和Traceroute等技术,完成网络全链路质量监测,实现全网质量透明化。
(2)大客户业务质量监测:利用IFIT+Flow技术完成用户的业务质量保障,实现特定业务的端到端故障定界,填补时效性业务监测能力的空白。
(3)采用Telemetry技术协同SNMP共同完成流量采集与统计,针对时效性强的性能数据通过Telemetry完成亚秒级采集,传统流量数据采用SNMP分钟粒度采集,完成流量拥塞统计,支撑网络运维。
图1所示为网络质量监测方案架构及应用。质量监测方案通过不同技术的结合应用部署,采用整体架构设计完成网络整体质量和大客户业务质量的监测,结合AI预测实现链路和业务质差预警,从而达到网络质量监测自动化和智能化的目的,最终网络质量提升。

图1 网络质量监测方案架构及应用
2 技术优势及应用部署
2.1 网络整体质量监测
2.1.1 Twamp网络监测能力
Twamp是一种用于IP链路的性能测量技术,可以在正反两个方向统计网络双向时延和抖动[3]。Twamp属于主动探测技术,能较好地反映网络质量整体情况,如亚秒级反馈链路双向时延、丢包和抖动等质量数据。相比传统以及现在常用的传输控制协议(Transmission Control Protocol,TCP)/网际IP提供的PING和Traceroute等服务,Twamp更具时效性和准确性。
2.1.2 应用部署
图2所示为Twamp与现有技术应用对比。选取已部署探针监测的城域网络进行Twamp现网部署[4],实测并对比两种技术应用下宽带接入服务器(Broadband Remote Access Server,BRAS)至城域网络核心层设备(Metropolis Backbone,MB)之间的链路质量数据。

图2 Twamp与现有技术应用对比
(1) Twamp应用:只需设备开启相关服务,数据将自动上报。
数据包访问路径:BRAS1或BRAS2至MB(双向)。
时延计算:举例BRAS1和MB链路时延。设BRAS1发包时间戳为T1,MB收包时间戳为T2,MB发包时间戳为T3,BRAS1收报时间戳为T4,则单向时延=T2-T1和T4-T3,双向(往返)时延=(T4-T1)-(T3-T2)。
丢包率计算:丢包率=(收到的返回包数目)/(发出的包数目)。
(2) 现有探针应用:需路由器设备下挂探针服务器,Sever下发PING和Trace等指令后探针执行。
数据包访问路径:Sever下发指令至探针,探针发出检测报文至BRAS,BRAS发包至MB(双向)。
时延计算:举例:BRAS1和MB链路时延。设Sever指令下发时间为T1,探针读取指令时间为T2,探针执行指令并发包至BRAS1时间为T3,BRAS1发包至MB时间为T4,探针只支持双向时延计算,双向(往返)时延=2(T1+T2+T3+T4)。
丢包率计算:丢包率=(收到的返回包数目)/(发出的包数目)。
表1所示为Twamp与传统探针监测数据对比。数据结果说明Twamp网络性能质量探测比探针更精准,避免了探针系统自身的指令下发时间和读取时间,以及Sever、探针和BRAS间的链路性能数据叠加。从为期一周的性能测试结果来看,Twamp亚秒级监测的平均时延为1.0 ms,探针分钟级监测平均时延为1.5 ms,相差0.5 ms,可以判定,多出的时延是探针网络的自身时延。探针系统的实际网络性能监测结果=网络性能质量+探针系统质量,且图2中探针的丢包数据是探针本身宕机导致,因此数据真实度较低。而Twamp监测时延及丢包以数据报文的时间戳和实际报文数量为准,数据真实度较高,能实时保障链路真实质量。同时,在部署上更具灵活性,除分析服务器外,无需额外部署服务器,减少了成本投入及维护投入。

表1 Twamp与传统探针监测数据对比(监控时间:2021/5/4-2021/5/11)
2.2 大客户业务质量监测
针对行业大客户的业务保障,现有网络多采用服务质量(Quality of Service,Qos)、隧道绑定和网络策略等方法[5],但诸多应用也只停留在业务保障层,无法做到业务质量精准监测。
现有手段根据业务穿越的网元节点逐跳PING测,但无法保证业务质量的时效性和准确性,多数都是问题排障时的查询和复现手段。因此可采用IFIT逐流监测技术完成大客户业务端到端的质量监测,实现SLA等级较高业务的保障支撑及故障定界。
2.2.1 IFIT业务随流监测
IFIT是一种基于真实业务流的随路测量技术,具备真实业务流的端到端及逐跳SLA(丢包、流量、时延和抖动等)测量能力,可快速感知网络相关故障,并进行精准定界和排障。IFIT属于被动监测技术,可做到业务质量随流精准测量,其基于RFC 8321,是一种对实际业务流进行特征标记(染色)的随流监测技术,支持丢包及时延染色,可测量获得包数、字节数和时戳3个原始数据[6]。因此,其在保证丢包数量真实性的同时,根据包中的时间戳也保证了时延数据准确性,IFIT当前支持的监测周期有10 s、30 s、1 min和5 min。
图3所示为报文染色,进入端(Ingress)按照一定周期i对被监测流的标记字段进行交替染色,统计本周期的染色报文数量Tx;出端(Egress)按照Ingress相同的周期,统计本周期特征业务流染色报文数量Rx。同时,在Ingress和Egress进行时延染色,记录报文入口时间戳T1和T3,报文出口时间戳T2和T4。计算业务流在周期i的丢包数及双向时延分别为
IFIT主要通过报文头部的染色封装,根据同一个数据包随业务流进出设备后的染色报文统计完成时延和丢包的精准计算。

图3 报文染色[6]
2.2.2 应用部署
选取某省网、城域网和省内互联网数据中心(Internet Data Center,IDC)联合部署测试,流量访问路径:访问用户→BRAS→MB→省网络核心层(Province Backbone,PB)→IDC内部服务器,在BRAS、MB和PB设备上开启IFIT服务及逐跳监测功能。模拟两个访问用户为SLA保障专线,并通过网络策略划分两个用户的访问路径。对比不同链路相同业务的数据监测结果,验证IFIT端到端业务监测能力。
图4所示为IFIT应用部署。两条SLA专线以不同路径同时完成网络测速和视频文件访问。

图4 IFIT应用部署
表2 所示为用户性能监控数据对比。用户1端到端访问总时延为15.083 ms,丢包率为1.92%;用户2端到端访问总时延为10.187 ms,丢包率为0。经过对比,用户1访问视频文件首帧访问时间较长,卡顿率较高,视频播放成功率较低,业务感知较差。通过IFIT业务逐跳监测数据,可短时间内判断影响业务质量的故障发生在2021/5/11 08∶56∶01的BRAS节点至MB1节点。登录BRAS设备查询与MB1互联端口,发现互联端口循环冗余校验(Cyclic Redundancy Check,CRC)误码率增长较快,MB1设备无异常。经查询故障是由BRAS与MB1之间的光传送网(Optical Transport Network,OTN)链路光衰导致,OTN更换业务波道后业务质量恢复。

表2 用户性能监控数据对比(选取时间:2021/5/11 08∶56∶01~09∶13∶44)
目前现有网络没有客户业务实时监测技术,只限于Qos等质量保障,无法真实反馈用户业务质量。同时,网络结构复杂也导致用户质差时无法快速定界问题。因此可通过IFIT部署及应用实现行业为大客户业务的质量分析和故障定界,有效支撑大客户业务运营及运维工作。
3 Telemetry+SNMP采集
方案中提出的Twamp和IFIT等技术对时效性要求较高,采集粒度较小,因此细粒度的数据采集通过Telemetry完成高效采集,保障整体网络及业务质量时效性。传统SNMP技术部署在网络整体流量采集中,用于链路拥塞管控。
两种采集方式联合部署可实现大客户业务的实时质量监测和全网链路拥塞质量监控,通过Telemetry+SNMP两种采集方式的结合部署完成网络整体到具体用户业务的双重质量保障。
4 网络质量优化
4.1 质量优化支撑-Netflow
设备开启Netflow功能完成链路中明细路由、流量大小及流量方向等数据获取,实现流量精细化调度[7],快速恢复质差业务,提升网络质量优化效率。以方案中提出的网络整体质量监测和大客户业务质量监测结果为调度触发事件,结合链路流量拥塞占比和链路性能指标完成质差业务调度,实现业务质量优化。
4.2 应用部署及质量提升
图5所示为网络质量提升方案部署。网络在部署Twamp和IFIT后实时监测网络及业务质量,发现被监测网络视频业务的IFIT时延偏大并伴随丢包,同时Twamp链路监测时延和丢包数据也出现劣化。开启Netflow流量明细分析,进行流量调度,优先保障网络视频高价值业务质量。

图5 网络质量提升方案部署
网络质量优化流程:
(1) IFIT监测大客户业务质量,Twamp监测网络链路质量;
(2) 分析网络整体链路质量及端到端业务质量监测数据,完成故障定界;
(3) 开启Netflow流量分析,获取链路中各业务明细路由,按Flow比例还原SLA保障用户流量大小;
(4) 评估流量调度后是否会对现有链路造成流量拥塞;
(5) 下发策略,完成调度;
(6) Netflow分析调度后的链路,通过流量明细、流量大小验证调度是否成功;
(7) IFIT、Twamp继续监测网络及业务质量,保障网络质量,支撑网路运维。
通过以上调度流程,成功地将链路1中的网络视频业务流量调度至链路2,调度成功后业务监测显示数据时延降低,丢包率为0,业务质量恢复,业务调度前后数据对比如表3所示。

表3 业务调度前后数据对比
5 AI预警
网络质量监测目的是降低网络故障发生率及用户投诉数量,从而提升网络及业务质量。因此,AI预警从故障和业务投诉出发,设定触发条件为时延、丢包和流量拥塞。
5.1 场景设定
(1)故障类场景:链路down、端口闪断、CRC误码率高和端口光衰等。
(2)业务类场景:业务访问缓冲问题、业务卡顿问题和业务掉线问题等。
5.2 预测周期
考虑包粒度的质量数据量级较大,采用短周期预测方法,结合10周历史数据计算结果完成预测。
5.3 数据建模
(1) 故障类建模:获取告警信息/设备告警日志,通过相同时间和相同节点的链路/端口大量网络质量数据完成计算建模,输出各类故障对应的不同条件基线值,如某一时间点链路down,查询此时间点前后链路时延/丢包率,完成基线值计算。
(2) 业务类建模:获取不同业务投诉时间,通过时间段内网络质量数据完成建模计算,输出各类业务质差投诉对应的不同条件基线值,如晚忙时用户投诉业务卡顿,查询该时段网元端口流量拥塞情况/时延,完成基线计算。
通过触发故障和业务投诉的各类条件基线计算实现网络质差预警功能[8],部署后结合运维手段,实现网络质差自动发现自动处理的能力。
6 方案整体应用效果
为验证监测方案的整体应用效果,选取具备传统探针的省内网络环境,部署本文的监测方案。设备监控范围包括PB路由器2台,MB路由器2台,BRAS接入服务器8台。BRAS与MB互联采用10 Gbit/s端口4上联,MB与PB互联采用100 Gbit/s端口4上联,MB与MB、PB与PB间均采用100 Gbit/s端口双互联。如图6所示,本方案服务器部署在省核心设备PB处,通过堆叠交换机完成采集、存储和分析等监测服务器主备接入;传统探针服务器下挂在BRAS接入服务器下,与用户接入网同层级。
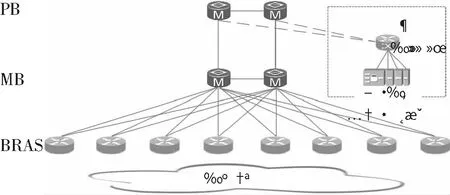
图6 方案部署拓扑
6.1 网络性能质量监测数据对比
表4所示为网络性能监控粒度对比,表中的数据是本方案与传统探针部署在相同网络环境中各指标的监测粒度对比,由表可知,本文方案部署后,网络监测粒度变的更小、更精准。其中,监测周期最小粒度为秒级,比传统监控周期缩小一个量级,可实时感知网络变化情况。同时,传统的聚合链路监测基于固定的Hash算法做选路,相同流量大概率通过固定端口/链路转发,导致监测结果与网络实际质量情况不符。通过本方案监控可实现网络链路最小集监控,共计44条全量物理链路,远超传统探针的10条聚合链路监控数量。路径监测也由传统的点到点演进为所有节点间逐跳监测的形式,可满足网络全链路监控需求及网络自动驾驶演进要求。

表4 网络性能监控粒度对比
表5所示为网络性能指标监测数据对比情况(天),表中监测数据最小更新粒度是传统探针的1/60,由于探针本身需要处理时延,因此时延的监测数据往往大于本方案的时延监测结果,天粒度的平均时延对比相差0.5~0.7 ms。由丢包数据对比也可发现,探针的监测周期粒度较大,加上服务器相关命令处理时长,导致网络丢包时探针无法及时监控此部分间隔数据。抽取某天丢包数据对比,BRAS-MB链路传统探针少监控丢包数67个,MB-PB链路传统探针少监控丢包数38个。因此,传统探针监测数据中时延增加和丢包数量较小情况多为数据不真实导致,此类不符合业务逻辑的现象也为网络故障处理增加了难度。

表5 网络性能指标监测数据对比情况(天)
6.2 大客户业务质量监测
方案部署前本省网不具备大客户业务质量精准监测能力,传统的监测手段均为模拟监测,在探针系统预置客户经常访问的目的地址,设定监测时间间隔,完成粗粒度的业务质量监测。此方案只能模拟监测用户到目的地址端到端间长链路数据质量,无法根据网络情况判定省内节点设备间的业务质量情况。因此,传统监测方式中业务的路径、时效性和质量情况等都不足以支撑用户业务质量精准分析。
表6所示为大客户业务质量监测能力对比(周),表中数据是针对159条互联网专线客户业务的监测数据统计。数据结果不仅包括BRAS-MB和MB-PB链路间的业务性能指标评估,同时具备节点设备间不同业务路径逐跳质量监测能力,可实时反馈用户业务质量变化情况,解决方案部署前省内网络无法精准监测大客户业务质量的难题。

表6 大客户业务质量监测能力对比(周)
方案部署后,某BRAS-MB链路上的客户视讯专线出现监测预警,详情如表7所示,3条链路中承载4个大客户业务,客户C的BRAS-MB业务链路时延为13.70 ms,明显高于其他客户业务,同时伴随业务丢包,丢包率达5%。而MB-PB上行链路数据无异常,因此判定故障出现在BRAS与MB互联端口或互联链路上。手动开启质量优化功能,自动计算业务流量、业务明细及链路流量占比,选择流量占比小且调度后不超限的链路下发调度策略,客户专线业务最终调度至BRAS的GE1/0/2后业务质量恢复正常。运维人员登录BRAS和MB两台设备,发现BRAS的GE1/0/1端口光衰导致客户业务时延突增且出现丢包,现场更换光模块后网络质量恢复。
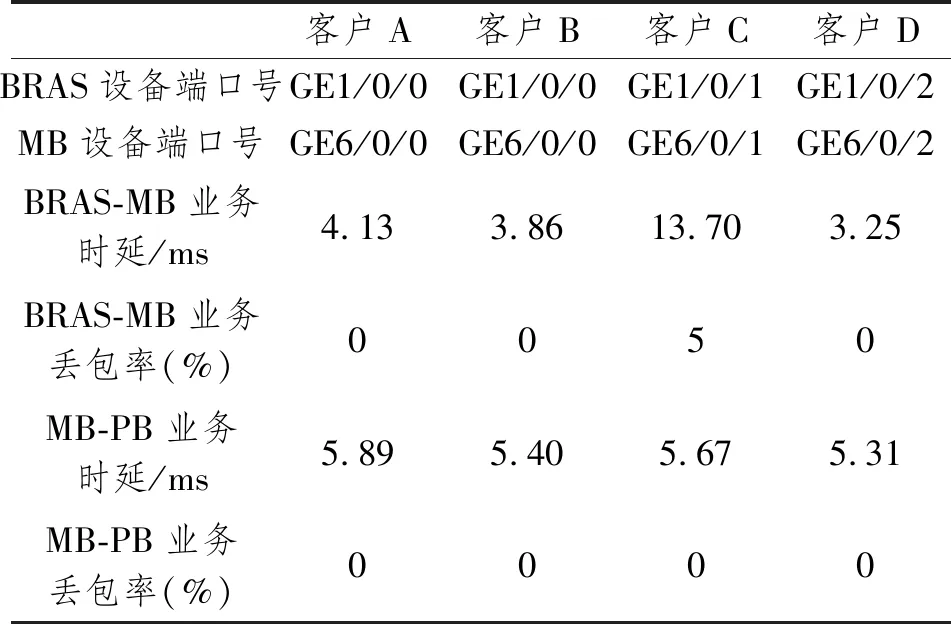
表7 大客户业务质量波动情况
正常情况下,业务丢包率达5%以上大概率是因为整体链路质差导致,但未收到相关预警。因此,查看Twamp整体链路质量监测模块,发现此条链路也有质差数据出现,但未超过阈值,因此未上报链路质差消息。专家分析此客户业务属于视讯专业业务,码流较大丢包较明显,考虑网络整体质量,为防止再次出现类似现象,将全网整体Twamp质差上报阈值调低。
6.3 工单投诉比
图7所示为互联网质量投诉工单前后对比。投诉工单部署后每月平均投诉量减少349单,投诉量环比下降57.5%。通过整套方案的应用及部署,本省的省网及多个城域网在两个月内通过Twamp监测功能优化质差链路67条(其中AI智能预警44条)、IFIT监测保障SLA级别专线375条、Netflow支撑流量调度10.2 G/天,初步统计近两个月节约人工成本300人天。
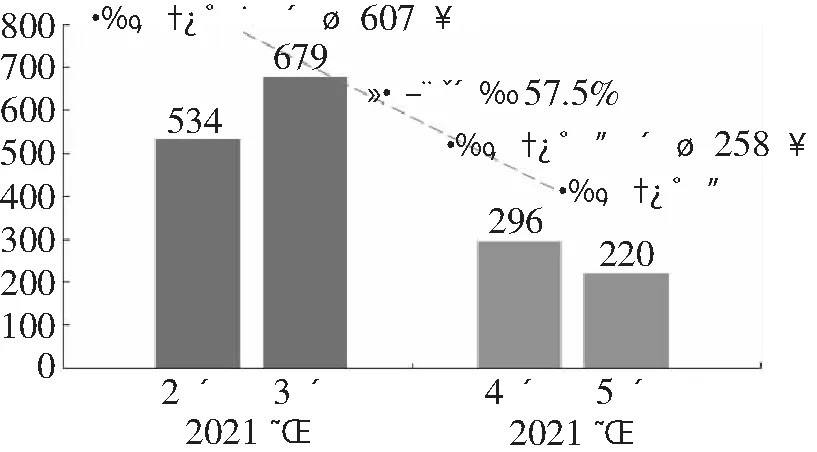
图7 互联网质量投诉工单前后对比
7 结束语
与传统监测方案不同,IP网络质量监测方案将Twamp、IFIT、Telemetry和Netflow等技术做整合,在统一框架下利用不同技术的部署、采集和应用,共同完成网络整体性能质量和行业大客户端到端业务性能质量的监测。结合AI预警完成网络整体链路质量、用户业务质量和流量拥塞占比等多维度质量预测,最终实现网络精细化管理及质量提升。本文设计的质量监测方案在数据时效性、真实性和可靠性等方面均具备较强能力,可逐步替代现有探针监测技术。同时,随着云网融合发展,本文提出的重点业务实时监测能力优势将更加突出。
