大规模复杂路网条件下的快速径路搜索算法研究
2022-08-11范家铭贺俊源
范家铭,李 博,贺俊源
(中国铁道科学研究院集团有限公司 运输及经济研究所,北京 100081)
0 引言
截至2021 年底,我国铁路营业里程已突破15 万km,其中高速铁路超过4 万km,居世界第一,基本形成了以“八纵八横”为主干的高速铁路网。根据统计,我国已建成的铁路干支线、联络线及动车组走行线800 余条,近9 000 个车站。在如此大规模复杂铁路网中,根据开行方案科学高效地制定出列车运行径路,可以有效降低运行图编制工作量,从而提高列车运行图编制质量。在大规模复杂路网中,一对始发站和终到站之间,往往存在不止一个列车运行径路。若仅运用枚举法对始发终到站间各区间的所有径路信息进行检索,其检索量极大,检索效率较低,无法满足实际编图工作的需要。为了能够准确获取列车通过两车站的相关径路信息,提供科学的列车开行方案,相关专家和学者进行了大量研究,研究内容主要有2 个方面,一是路网的网络构建、结构存储和路径表达,二是设计复杂度较低、简便易行的算法。
目前,铁路网径路搜索模式大多数还停留在人工编制阶段,暂无可以利用的高效的计算机手段来自动化规划理想的行车径路,专家学者已研究出的径路搜索方法,尚不适用于大规模复杂铁路网的径路搜索应用场景。因此,面向大规模复杂路网条件下,基于时间复杂度较低的双向搜索算法的基础上引入了优化车站节点搜索、限定车站属性搜索、向量限定搜索、限定节点分支递归深度、建立列车行车径路库等优化策略,不仅提升了算法的执行效率,而且可以制定出科学、合理的行车径路,对更好提供列车开行方案具有重要的现实意义。
1 主要搜索算法优缺点分析
针对径路快速检索策略,国内外专家学者已经进行了大量的研究和测试,同时也创新许多经典检索算法,如Dijkstra 算法[1]、A*搜索算法[2]、广度优先(Breadth First Search,BFS)算法[3]、深度优先搜索(Depth First Search,DFS)算法[4]、K 次短路径算法[5]、定向搜索算法[6]等。国内针对最短路径的研究主要集中在公路交通路线规划领域,而在铁路运输组织中的研究相对较少。传统的最短路径搜索算法都有各自的优点,同时也有不同程度的缺陷。
(1)BFS 算法,是常用的最短路径搜索算法之一,属于传统的盲目搜索法,其主要用于对图的搜索,特点是可以考虑到图中各节点的所有情况,可以完全遍历整张图的所有情况,从而得到搜索所需要的结果。BFS 不依赖历史经验来进行搜索,所以在搜索中会遍历整张网或图以达到搜索的目的。但对于大规模复杂路网条件下径路快速搜索,遍历整张铁路运输网,不仅需要花费大量的时间,而且会因为过度占用大量的计算资源导致搜索算法崩溃,无法满足用户需求。
(2)DFS 算法,是常用的最短路径搜索算法之一,属于一种回溯算法,其优点在于可以同BFS算法一致,完全遍历整张图的所有情况,其不同是当遇到叶子节点有分支情况时,该算法会先将其中一条链完全搜索到尽头后再搜索其他链。DFS 与BFS 一样具有较高的复杂度,不能满足大规模复杂路网条件下的快速搜索的目的。
(3)Dijkstra 算法,是一种盲目算法,与BFS算法相似,首先把起点到所有点的距离存下来找个最短的,然后再次遍历一遍判断刚刚找到的最短的点作为中转站是否会出现更近的情况,如果存在就保存最新的距离,依此遍历便查找到最短距离。这种算法可以较好地解决大规模径路搜索问题,但在单源最短路径问题的某些实例中,可能存在权为负的边,当有向图中出现负权时,Dijkstra 算法失效,因此该算法不能很好应用于大规模复杂路网条件下的最短路径搜索。
(4)A*搜索算法,是一种比较高效的启发式径路搜索算法,在BFS 算法基础上进行改进,引入了与问题域相关的启发因子来缩小搜索范围,从相关启发因子中找到最应该展开的节点并展开搜索其目标点,最终搜索到理想的结果。该算法的搜索方式不是盲目式搜索方式,所以搜索的范围与Dijkstra 算法相比大大缩小。但针对大规模复杂路网条件下,目标点很多时,A*搜索算法会带入大量重复数据和复杂的估价函数,A*搜索算法的计算能力已无法满足实际的计算需求。
(5)B*搜索算法,是为解决大量重复数据和复杂的估价函数这种困境,而被提出的[7]。该算法主要从估价函数入手,提出了一个新的估价函数来替代原有A*搜索算法的估价函数。新估价函数的思路是对当前节点距终点的距离作估计时,估计该节点的所有子节点距终点的距离,然后加上该节点到终点的实际距离,取其最小值。从估价函数的值来说,B*搜索算法优于A*搜索算法,但其估价函数的计算时间花销远超过A*搜索算法,而且其估价函数的计算是以穷举该节点的所有子节点为代价的,所以这种搜索方式同样不能满足现有需求。
(6)双向搜索算法,是一种图的遍历算法,也是启发式算法之一,用于在有向图中搜索从一个顶点到另一个顶点的最短路径,其时间复杂度小于BFS 算法和DFS 算法。双向搜索算法工作时将同时运行2 个搜索:一个从初始状态正向搜索,另一个从目标状态反向搜索,当两者在中间汇合时搜索停止。双向搜索算法通常是初始状态和目标状态都是唯一且完全定义的,以及分支因子在2 个方向上完全相同的场景下被应用。但针对大规模复杂路网条件下,多目标点均为无向图情况,采用双向搜索算法将会搜索出大量无用节点,且递归深度明显升高,无法体现出优越的搜索性能和搜索结果。
在大规模复杂路网中,由于我国铁路网规模非常庞大,路网连接关系错综复杂,如果直接采用传统的径路搜索算法,如A*搜索算法、BFS 算法、DFS 算法等,不仅会因过度消耗资源导致无法快速搜索出最佳径路,而且会因庞大的路网关系导致算法的崩溃,无法提供科学、合理的行车径路,从而影响编图效率[8]。不同径路搜索算法的时间复杂度对比如表1 所示。以时间复杂度为维度对比上述算法的效率,其中O表示算法的时间复杂度函数,n表示执行的遍数,A表示分支因子为A的树,D表示初始节点到目标节点的距离。综合表1 分析可以看出,BFS 算法、DFS 算法和Dijkstra算法均属于平方阶复杂度,相当于一次操作执行了n2次,不满足当前高效的径路搜索效率;而A*和B*搜索算法较BFS 算法的复杂度更高,更无法满足铁路实际搜索效率的需求。结合铁路运输的特点,选择采用时间复杂度较低的双向搜索算法作为算法基础,根据实际的业务需求进行优化和改进,以提升铁路网搜索效率和有效结果为目标,满足铁路运营需求。
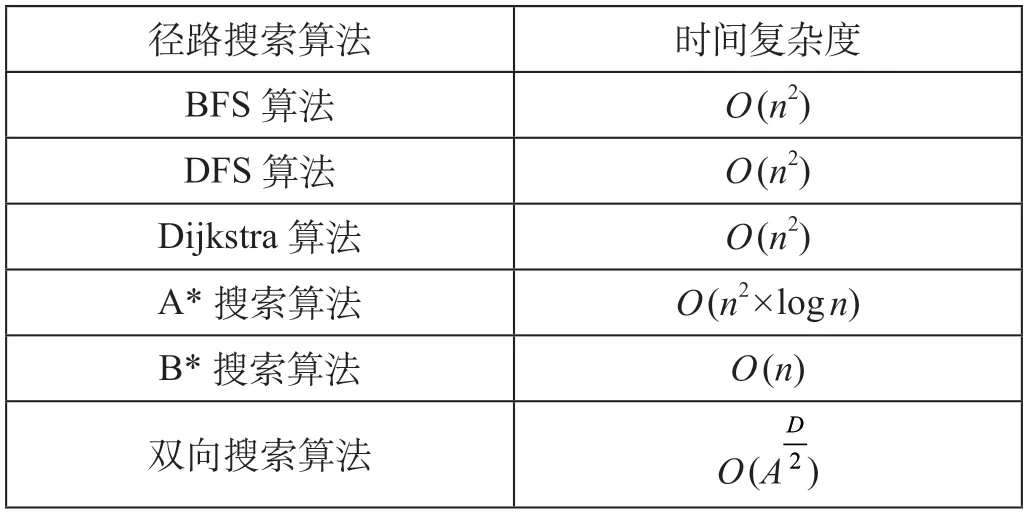
表1 不同径路搜索算法的时间复杂度对比Tab.1 Time complexity of different route search algorithms
2 基于双向径路搜索算法优化
铁路路网中大多数枢纽车站存在着一定的关联关系,每个车站还包含了相关的线路和铁路局集团公司的属性。通过梳理车站间关联关系,在径路搜索时,如果同时考虑全要素则势必会搜索出大量不合理的行车径路结果,或因连接节点过多、递归深度较大而致使硬件资源消耗过高,时效性无法得到保障,不能满足实际业务需求。为此,结合铁路行车特点,从限定车站属性搜索、优化车站节点搜索、向量限定搜索、限定节点分支递归深度、建立现行列车径路库等方面对双向搜索算法进行优化,最终得到科学、合理的有效径路,提升编图质量和效率[9-10]。
2.1 限定车站属性搜索方法
铁路运输实际运营中,车站按照所属的铁路局集团公司可划分为18 类,按照线路划分(含联络线、动车组走行线)可划分为800 类。在实际行车径路搜索时,优先将搜索的2 个车站所属的线路属性作为限定条件进行搜索则大大降低搜索频次,降低递归搜索深度,无须消耗大量硬件资源。对于长大干线进行径路搜索时,若先限定OD 车站的线路属性作为判定条件,那么当OD 中2 个车站所属线路隶属于同一个线路时,无须判定OD 途径各车站节点的分支径路,即可获得最优径路需求。
限定车站属性搜索方法优化前后对比如图1 所示。以北京至深圳为例,优化前需要从北京始发开始遍历与北京站相关联的所有节点,其中包含通辽、哈尔滨、沈阳、秦皇岛、天津、济南、青岛、上海等无用节点信息,通过限定车站属性搜索后,去除这些无须搜索的车站,则直接得到理想的结果。
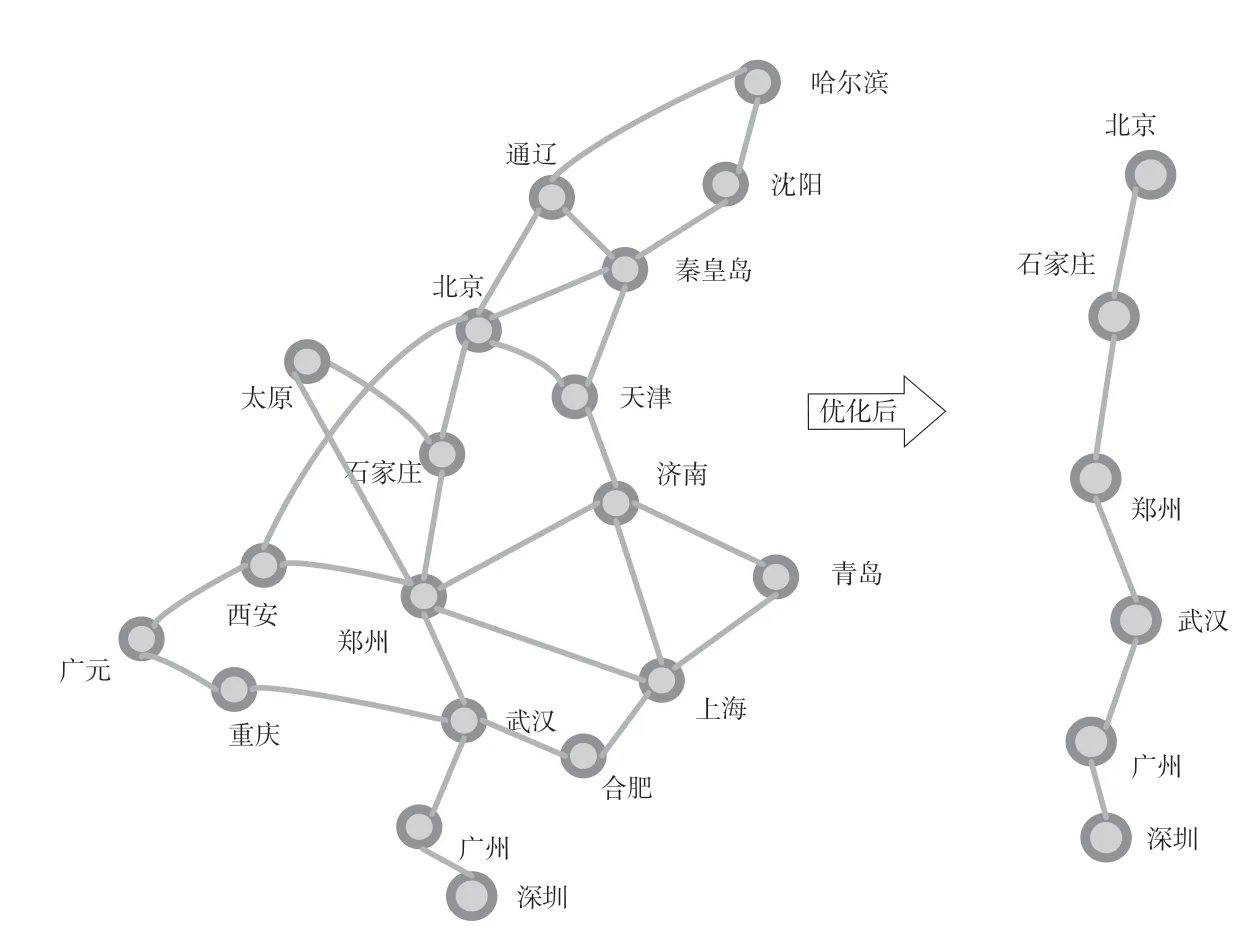
图1 限定车站属性搜索方法优化前后对比Fig.1 Comparison before and after optimization of limited station attribute search method
2.2 优化车站节点搜索方法
我国铁路网结构复杂,车站各节点连接关系众多,当限定车站属性无法满足搜索条件时,由于搜索的分支节点众多且递归深度较高仍然无法快速得到理想的结果。针对全路网复杂的结构特点和车站数量进行深入分析,其中绝大多数需要进行分支递归搜索的车站均为枢纽车站或换乘站,那么车站节点不具备枢纽或换乘属性时,可忽略该搜索节点,若该车站节点具有枢纽或换乘属性时,可将该节点作为递归搜索的主节点进行搜索,同时根据OD 的始发、终到及中间途经的主节点形成最终的列车行车径路。由此优化后,原搜索遍历全路网9 000 个车站数量降至约1 500 个,搜索数量降低至全路搜索量的17%,搜索数量和硬件资源消耗直线降低,搜索效率和能力大幅提升。
优化车站节点搜索方法前后对比如图2 所示。以北京至重庆为例,优化前需要从北京始发开始遍历与北京站相关联的所有节点,其中包含了沙城、大同、黄陵、承德等无用节点信息,通过优化车站节点搜索方法后,去除中间无枢纽或换乘功能的车站,优化搜索节点数量,即可快速得到理想的结果。
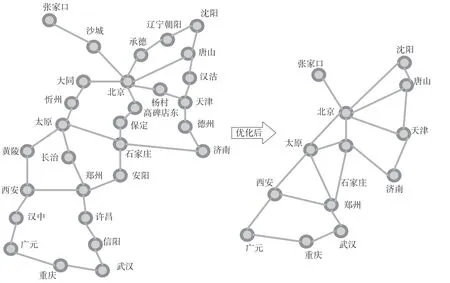
图2 优化车站节点搜索方法前后对比Fig.2 Comparison before and after the optimized station node search method
2.3 向量限定搜索方法
双向搜索算法在对始发站向终到站搜索时,由始发和终到2 个车站节点同时向2 个方向进行递归搜索,而其中一个方向上的搜索大多数都是无效的搜索方向,不仅浪费搜索时间,而且还消耗计算资源。为了解决该问题,引入向量概念,将全国所有车站节点绘制成二维平面图,以郑州作为原点(0,0)坐标,其他各站节点以郑州原点为中心,按与原点的偏移量计算出全路所有车站的相对坐标点信息,向量相对坐标信息如图3 所示。假设搜索始发站为石家庄,终到站为郑州,按照坐标法定义石家庄坐标点信息为(4,2),郑州坐标点信息为(0,0),通过坐标向量查找目标源位置对应图3 中应由C 站向Y 站方向搜索。利用向量限定搜索范围,引入搜索方向理念,则直接忽略有效搜索方向的反方向搜索,缩减搜索范围,最大程度减少无效搜索的时间开销,提升搜索效率又得到合理的行车径路结果。
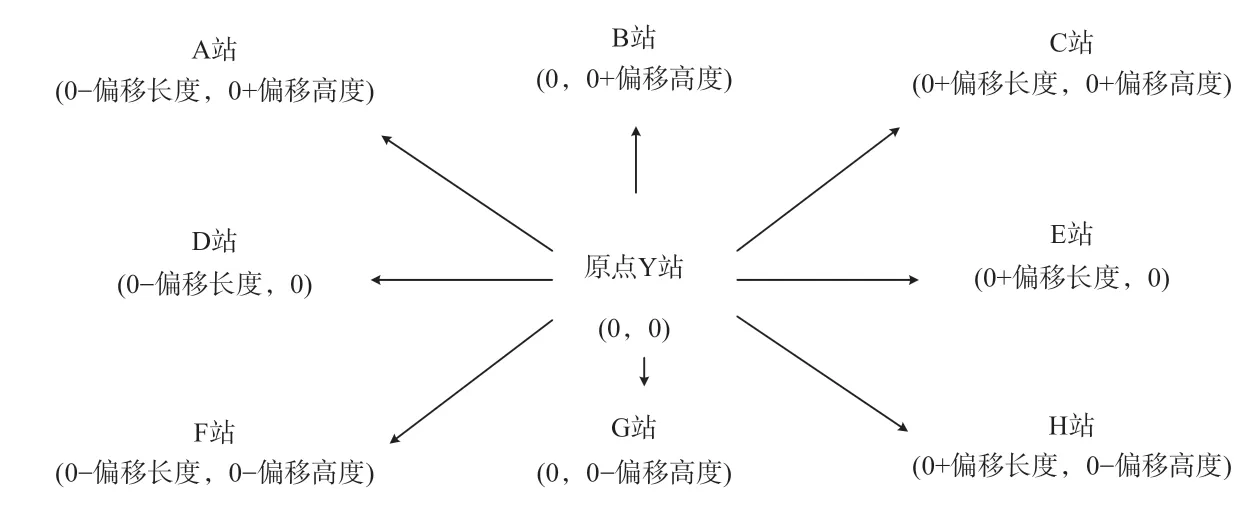
图3 向量相对坐标信息Fig.3 Vector relative coordinate information
向量限定搜索方法优化前后对比如图4 所示。以北京至重庆为例,优化前需要从北京始发开始遍历与北京站相关联的所有节点,其中包含张家口、唐山、辽宁朝阳等非有效向量的无用节点信息,通过向量限定搜索方法优化后,去除无效向量的车站,即可快速得到理想的结果。
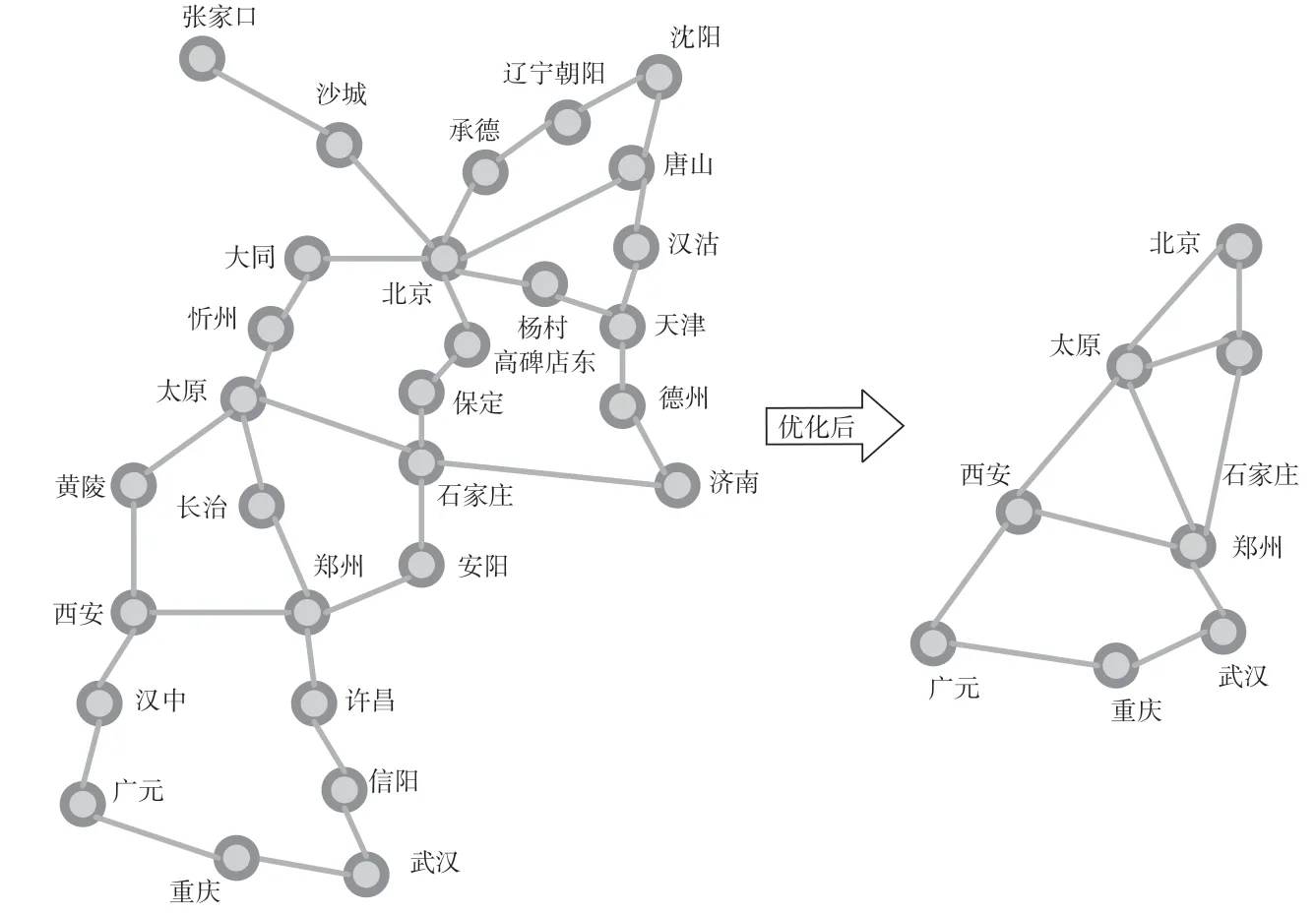
图4 向量限定搜索方法优化前后对比Fig.4 Comparison before and after optimization of limited vector search method
2.4 限定节点分支递归深度方法
为了进一步提升搜索算法执行效率,通过累计里程值和递归深度层数来限定节点分支的递归深度,结合铁路实际运营综合情况,设置递归深度层数的阈值来控制递归深度,超过阈值的分支将不会被继续搜索,从而提升搜索算法的执行效率[11]。
在限定节点分支递归深度方法中,设置递归深度阈值D、累计里程阈值S、向量限定搜索偏移量p1、OD 向量的连线形成的角度A1、校验里程S',校验里程设置允许偏差值为[0,50],第1 条径路里程阈值为
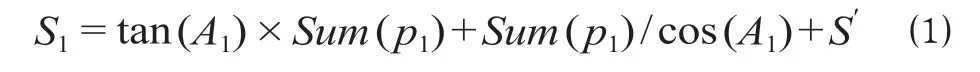
式中:Sum为向量限定搜索偏移量的求和函数。
按最短里程进行阈值修正后,当前径路路程为
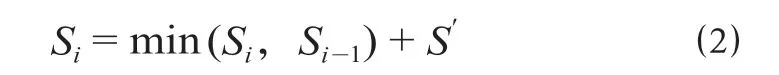
式中:Si为当前径路里程,km;Si-1为前序径路里程,km。
2.5 建立现行列车径路库
为了最大程度提升径路检索效率,在使用双向搜索优化算法后所得到的科学、合理、可行有效径路的结果并作为实际列车行车径路时,可将该结果存储在列车径路库中,当下次需要新建列车并使用径路时,无需径路搜索算法重新规划合理路线,仅需优先遍历列车径路库来判定是否存在科学合理的有效径路信息,若满足检索条件并得到所需的结果,则直接输出该结果即可;若无检索到结果,则继续调用以上算法来获取科学合理的径路规划。该列车径路库会随着时间的推移,逐步形成一个更为完善的列车径路库,以便快速提供给用户有效的列车径路信息。
3 基于实际运营条件的径路搜索优化算法流程及对比分析
3.1 径路优化算法处理流程
针对大规模复杂路网条件下进行快速径路搜索并提供给运输编图人员科学、合理的可行行车径路问题,结合铁路行车特点,从优化车站节点搜索、限定车站属性搜索、向量限定搜索、限定节点分支递归深度、建立列车行车径路库等方面对双向搜索算法进行优化,以提升检索效率,并得到满足用户需求的科学可行结果。
基于双向搜索径路优化算法的处理流程是优先检索已建立的有效行车径路库,从而减少对路网的检索规模,若径路库中无法查询到有效信息,根据OD 车站的车站属性来判定是否隶属于同一线路来缩小遍历范围,此方法面向长大干线的检索效果尤为明显。当OD 车站的线路属性不满足条件时,还可以通过优化车站的节点搜索数量以降低遍历的次数,同时引入向量限定搜索方法和限定节点分支递归深度来提升检索效率,从而得到最优有效结果,并将有效径路结果录入径路库中,以方便下次检索时直接使用,最大程度方便用户使用径路搜索功能,提升列车运行图的编图质量和编图效率。优化径路搜索算法流程如图5 所示。
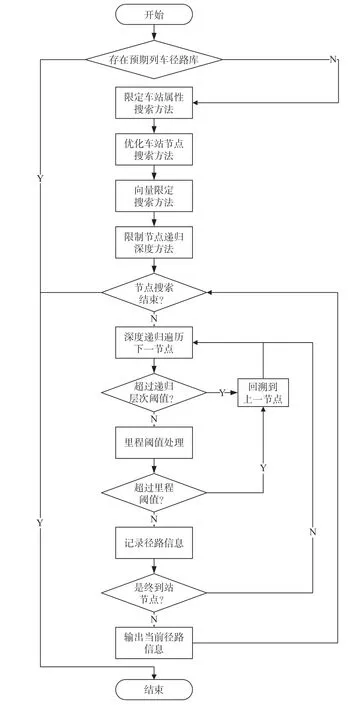
图5 优化径路搜索算法流程Fig.5 Optimization algorithm flow
3.2 优化效果及对比分析
以2022 年我国铁路路网图为例,对北京至藤县径路进行分析,分析未经过各种优化前的传统径路搜索算法的效果和效率,以及经过优化车站节点搜索、限定车站属性搜索、向量限定搜索、限定节点分支递归深度、建立列车行车径路库等一系列优化后的径路搜索算法的效果和效率。算法基于C#开发语言,硬件环境为i7 处理器,8G 内存,1T 硬盘进行算法测试。通过对比搜索的效果可知,未经过优化的算法从执行效率、递归深度、资源消耗等方面效果均较差,而且产生了大量不满足实际运营条件的径路信息。而使用了优化后的算法,得出的径路结果更符合编图人员的实际需求,更贴合实际业务,无论从执行效率、算法简易程度等方面均有明显的提升。算法优化前后径路效果图如图6所示,算法优化前后对比如表2所示。通过图6、表2 对比分析,提出的双向径路搜索优化算法在径路搜索方法优化后的算法耗时、递归深度、搜索节点数均比优化前径路搜索算法表现出更高效的搜索效果。

表2 算法优化前后对比Tab.2 Comparison before and after algorithm optimization

图6 算法优化前后径路效果图Fig.6 Route effect before and after algorithm optimization
4 结束语
针对我国铁路建设规模不断扩大,由各车站节点所组成的路网结构日益复杂,为满足铁路实际运营需求,根据客运的开行方案科学高效地制定出列车运行径路,提高列车运行图编制质量,提出基于双向搜索算法的基础上,引入限定车站属性搜索、优化车站节点搜索、向量限定搜索、限定节点分支递归深度、建立现行列车径路库等方法对双向搜索算法进行优化,可以快速规划出有效径路,提升编图工程师的编图效率和编图质量,为更好服务旅客出行提供技术支撑。该优化方法已基于全国铁路路网图进行实例分析,同时验证了优化算法的正确性和高效性。
