基于分类回归决策树算法的航班延误预测模型
2022-08-03张文杰陈林烽李泽南
王 辉,张文杰,刘 杰,陈林烽,李泽南
(1.中国民航大学航空工程学院,天津 300300;2.天津(滨海)人工智能军民融合创新中心研究一部,天津 300300)
由空中交通流量增加和机场容量限制等因素导致的航班延误问题日益严重。对航班延误实现精准预测可为相关决策部门提供参考,以便及时治理可控延误,降低航空公司损失,对民航的高效安全运营具有实际意义[1]。目前,国内外已有较多学者对航班延误预测问题进行研究,曹悦琪等[2]使用Logistic 模型对航班延误数量和累积延误时间进行预测;王语桐等[3]使用支持向量回归和线性回归方法对上海浦东国际机场某月进港航班数据进行回归预测;孟会芳等[4]基于K-means 聚类技术对航班延误模式进行时变分析;Kim 等[5]使用循环神经网络(RNN,recurrent neural network)中的长短期记忆网络(LSTM,long short term memory network)对单个机场的起飞和到达航班延误进行有效预测;文献[6-7]基于单变量(气象因子)建立概率统计算法模型,得出航班延误的预测值并与实际值对比,进而实现了航班延误预测;张静等[8]基于模糊线性回归模型得出航班延误的预测值,对航班延误的情况进行评估。上述研究均只对单一机场起降信息进行建模,未考虑机场间延误的相互影响,对机场间与航班延误间的关系研究较少,且以上模型的数据集影响因子较少,数据集的维度不够。
综上,基于国内机场收集了大量数据并将随机森林(random forest)与分类回归决策树(CART,classification and regression tree)算法相结合构建模型,该预测模型的核心是随机森林模型。随机森林模型是由Breiman[9]于2001 年提出的一种基于分类树的算法,通过对大量分类树的汇总提高了模型的预测精度,可处理高维度数据,泛化能力好,同时降低模型过拟合的可能性,是取代神经网络等传统机器学习方法的新模型,目前已应用于较多问题的研究中,如农业预测[10-11],人体信号预测[12]等。同时,本文数据含有国内大部分机场的情况与航班进出港的详细信息,能够很好地反映出多机场间的联系。
1 随机森林回归模型
航班预警系统的核心是具备一个或多个能根据输入信息准确预测延误情况的模型,模型的准确率直接影响了系统的准确率。该模型是基于随机森林与分类回归决策树算法构建的航班延误预测模型,即随机森林。随机森林回归模型是一种集成算法,本身并不是一种单独的机器学习算法,而是通过在训练集上构建多个分类回归决策树模型,最后集合所有模型的最终输出。其基本流程如图1 所示。

图1 随机森林回归计算流程图Fig.1 Flow graph of random forest regression calculation
相较于单棵分类回归决策树,随机森林回归模型解决了决策树泛化能力弱的缺点,能更有效地运行在大数据集上,同时降低了大数据集的维度要求(数据集无须进行降维处理),能获得较好的预测准确率。
随机森林回归模型的结果取决于多棵决策树的结果,决策树的好坏将直接影响森林回归模型的好坏。要想提高随机森林回归模型预测的准确率,先要调节单棵决策树的优劣。
1.1 决策树
决策树(decision tree)是一类机器学习算法,因其结构形似一棵树而得名。一般一棵决策树包含一个根节点、若干个内部节点、若干个分支和若干个叶子节点,其中根节点一般用于输入,每个内部节点表示一个属性上的判断,每个分支表示一个判断结果的输出,最后每个叶子节点表示一种分类的结果,如图2所示。

图2 决策树结构示意图Fig.2 Schematic diagram of decision tree structure
决策树采用类似if-else 的条件判断逻辑进行分类,属于监督学习(supervised learning)的一种。所谓监督学习就是用一批带有一组特征(属性)和一个分类结果的样本进行学习的方法。简单来说,就是用分类的结果和已知的样本进行学习。通过对样本的学习,可以让决策树对新的数据进行回归或分类。
1.2 CART 算法
分类回归决策树算法是由Breiman 等[13]于1984年提出的,既可用于分类也可用于回归。CART 算法本质是对特征向量进行二元划分,即CART 生成的决策树是一棵二叉树,能够对离散量与连续量进行分割。
1.2.1 寻找最优切分点
为了对连续量进行if-else 条件判断,首先要对连续量进行切分处理。
当连续的特征值输入到决策树中时,分别为输入量和输出量,且为连续变量,给定的数据集
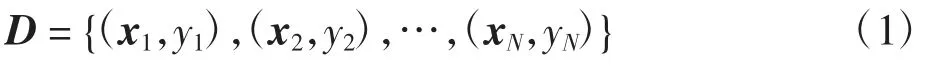
式中:yi为输入的第i 个真实值;N 为样本数量;xi为输入的第i 个特征向量,即
在进行切分前会先枚举所有特征,对于每个特征按特征值升序排列,根据均方误差最小原则选择其中最优的一个作为切分点。均方误差的计算方法如下
式中:f(xi)为第i 组输入的预测值;yi为真实值。可进一步表示为


式中:c1和c2为划分后两个区域内的固定输出值;R1和R2为j 和s 将特征空间切分的两个区域。
对于某个区域的输出值c,根据均方差最小原则,构造的函数为

对式(6)进行求导得
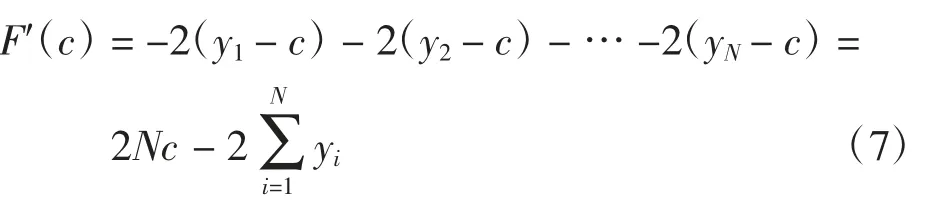
令F′(c)=0,得


对于固定的j 扫描所有切分点s,找出满足式(9)的s,即

在特征空间遍历变量j,寻找最优j,组成对(j,s)。如图3 所示,对于计算出来的j 和s 将特征空间切分为两个区域,切分的两个区域为


图3 特征切分示意图Fig.3 Feature segmentation diagram
对切分出来的区域用同样的方法重复以上步骤继续进行切分,如图4 所示,经过多次切分后,特征空间最终被分成M 个区域。

图4 最终切分结果Fig.4 Final segmentation result
1.2.2 决策树输出
将特征空间切分为M 个区域后,每个区域都有一个固定输出值,计算方法如下

生成决策树,树的最终预测值为

式中I 为指示函数,即

当随机森林与分类回归决策树算法的航班延误预测模型建立完成后,输入数据进行模型训练,但所获得的航班数据的数据类型并不一致,想要让模型能处理各种数据类型,还需要对航班数据进行相应处理。
2 航班数据处理
本文共收集了372 261 条航班数据,查询到的数据共有36 个字段,如表1 所示(仅展示部分字段)。

表1 航班数据字段Tab.1 Fields of queried flight data
所查询到的航班数据中,既有关键性数据,如实际起飞和到达时间,也有和航班延误关系不大的数据,如时区、ICAOID、机场ICAO 代码等。为了在有限的计算能力下尽可能地提高模型的契合度,应避免将相关度较低的字段作为模型特征。故先要对收集到的航班数据字段进行筛选。
2.1 特征选择
2.1.1 主要特征选择
特征选择主要依据特征与预测值(延误时间)的相关程度来进行选择(已省略计算过程),选择出来的特征有:计划起飞/到达时间,实际起飞/到达时间,航空公司出发/到达机场、机型、机龄。
2.1.2 额外特征提取
根据选择出来的特征,可提取出更多特征,这些额外的特征在一定程度上与航班的延误时间有关。
1)出发月份
该字段定义为month:int,表示出发月份,提取方法为将实际出发时间的时间戳换算成日期时间格式后取其月份,与航班平均延误时间的关系如图5 所示。
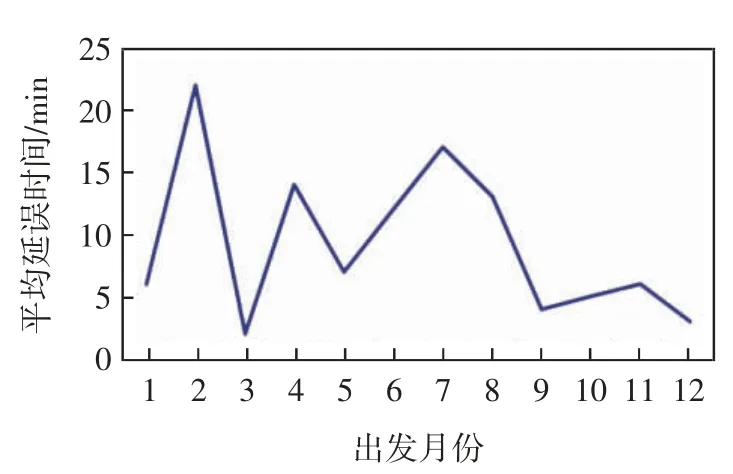
图5 出发月份与航班平均延误时间的关系Fig.5 The curve chart of departure month and the average delay time of flight
2)出发日期
该字段定义为day:int,表示出发日期,即该天是一个月中的第几天,提取方法与月份提取方法类似,与航班平均延误时间关系如图6 所示。

图6 出发日期与航班平均延误时间的关系Fig.6 The curve chart of departure date and the average delay time of flight
3)起飞时段
该字段定义为hour of take off:int,表示起飞时段,取值为0~23 时,提取方法与月份、日期的提取方法类似,与航班平均延误时间的关系如图7 所示。

图7 起飞时段与航班平均延误时间的关系Fig.7 The curve chart of time period of taking off and the average delay time of flight
4)到达时段
该字段定义为hour of arrive:int,表示到达时段,取值为0~23 时,和起飞时段与航班平均延误时间关系基本一致。
5)所在星期
该字段定义为weekday:int,表示出发日所在星期,其与航班平均延误时间的关系如图8 所示。

图8 所在星期与航班平均延误时间的关系Fig.8 The curve chart of the departure week and the average delay time of flight
6)平均起飞延误时间
该字段定义为delay of take off:int,平均起飞延误时间是用实际平均起飞时间减计划平均起飞时间得到的。一般情况下,平均起飞延误时间越长,平均到达延误时间也越长,数据中平均起飞延误时间与平均到达延误时间的关系如图9 所示,很好地印证了这种情况,两者呈强线性相关,故将平均起飞延误时间作为特征之一。

图9 平均起飞延误时间和平均到达延误的关系Fig.9 The relationship between average departure delay and arrival delay
2.2 字符串类型特征及离散型特征处理
原始特征有两种类别:连续型特征和离散型特征。而回归问题是对连续型特征进行回归的,在选择(提取)的特征中,存在着字符串(string)类型的变量。这就需要对string 这种非数值型变量运用标签编码进行特殊处理。string 类型特征经过标签编码后,仍是一个离散型特征,不能直接输入模型,还需要运用独热编码对离散型特征进一步处理。
3 模型训练与评估
3.1 数据分割与训练
经过特征的选择与处理,使用Scikit-Learn(简称sklearn)学习库,最终输入到模型的数据总共16 个字段,如表2 所示,其中:平均到达延误时间delay of arrive 为目标变量;其他为特征变量。

表2 航班数据字段Tab.2 Flight data field
为了对训练模型进行测试,需要将收集到的数据进行分割,一部分作为训练集,另一部分作为测试集,对模型进行评估测试,训练集与测试集的比例为3 ∶1。
3.2 模型评估
3.2.1 评估方法
评价指标是用来衡量模型好坏程度的标准。模型评价指标选用确定系数R2和平均绝对值误差eMAE对模型进行评估,其中:R2表示模型的拟合程度,取值范围为[0,1];eMAE表示预测值与实际值之间的平均误差,取值范围为[0,+∞),使用eMAE能有效降低异常数据对结果的影响。R2和eMAE的计算方法如下

使用k 折交叉验证方法对模型进行评估,使用这个方法无需使用train_test_splite 进行数据分割,直接导入建立好的模型、数据集和评判指标即可自动进行数据分割、训练和评估。
k 折交叉验证原理为将原数据集平均分成k 份,依次取一份作为测试集,其他作为训练集,分别计算每个测试集的成绩,每个成绩包括R2和eMAE,最后将算出的k 个成绩,取其平均值即为k 折验证的最终成绩。由于交叉验证所需时间大约为用train_test_splite手动进行数据分割、训练、验证所需时间的k 倍,为了在准确率和花费时间之间取得平衡,将数据集均分为4 份,即4 折交叉验证,如图10 所示。
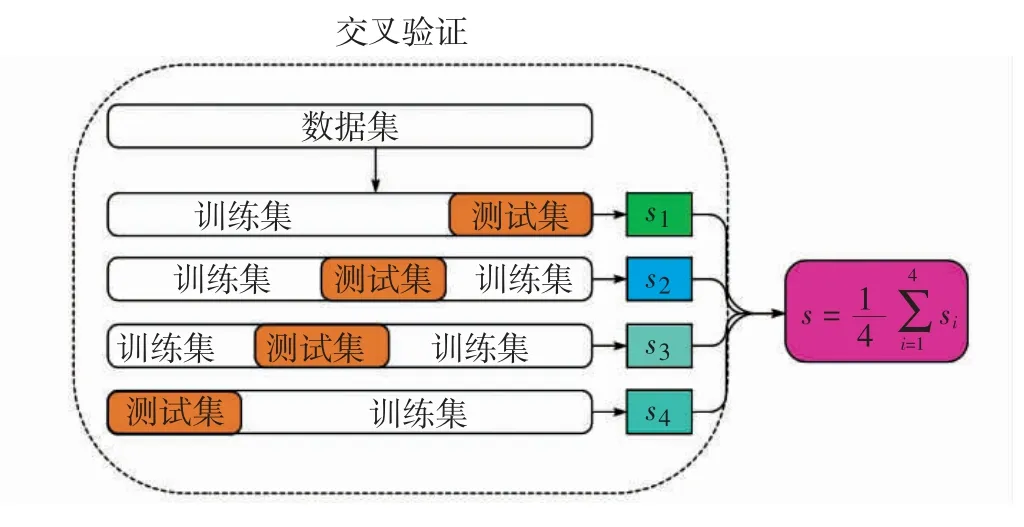
图10 交叉验证示意图Fig.10 Cross-validation diagram
3.2.2 评估结果
经过对模型进行4 折交叉验证,结果为:模型的R2为0.83,均值eMAE约为10 min。表3 为部分测试集的预测值与真实值的比较。
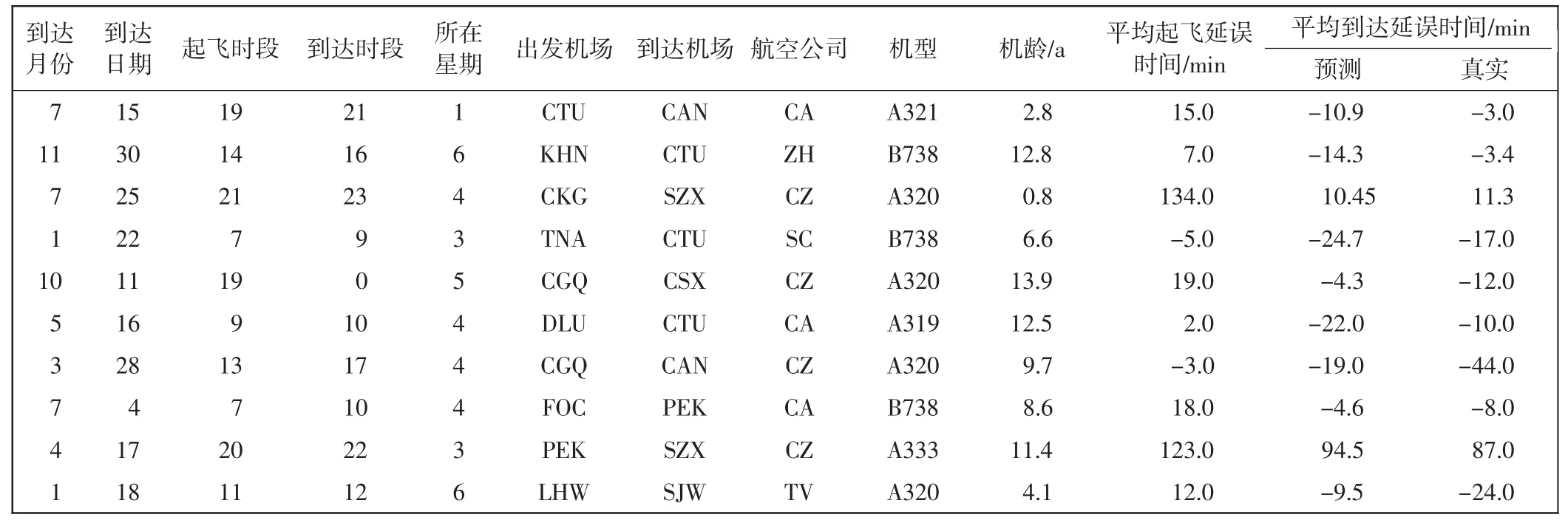
表3 部分测试集的预测值与真实值Tab.3 Predicted and actual values of part of the test set
3.3 模型比较
由于各模型自身存在的优势与缺陷,将使用Logistic 回归算法、K-近邻回归(KNN,k-nearest neighbor)算法和决策树算法与随机森林回归模型进行比较,训练集与测试集使用相同的数据集。使用以上3 种模型及随机森林回归模型评估结果如表4 所示。

表4 模型比较Tab.4 Comparison of model
由表4 的结果可以看出,随机森林回归模型预测效果最好。
4 结语
使用决策树中的CART 算法建立随机森林回归模型,并收集了国内一年内的部分航班数据作为训练数据,并通过大量的模型训练验证了模型的有效性,模型的拟合程度R2可达到0.83。该方法可处理高维度的数据,泛化能力好,降低了过拟合的可能性,但航班延误离不开天气等因素,在下一步的研究中将天气因素加入其中,进一步提高模型的准确率。
