面向中文医疗问答网站的相似问题检索研究
2022-08-02王保成刘利军黄青松
王保成,刘利军,黄青松,2
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 云南省计算机技术应用重点实验室,云南 昆明 650500)
0 引言
随着信息技术的快速发展,大量医疗数据得以产生。同时为了改善线下医疗条件及资源等问题,在线医疗问答平台应运而生。然而患者由于专业知识的不足,不能准确地使用相应术语描述其症状;其次,由于医生通常是在空闲时间来回答患者所提问题,所以医生不一定能及时回复[1]。针对上述问题,让系统自动检索出与患者提出的问题相似的病例,并将其推送给患者,是一种有效的方法。
近年来,国内外的医疗文本检索研究主要是围绕着电子病历及在线医疗问答网站开展的。传统搜索引擎采用开源的搜索引擎框架并对其检索方法做调整以对医疗文本进行检索。韩晟等人[2]通过Lucene开源搜索引擎框架来对无结构化文本进行检索。胡恒文等人[3]通过Clucene开源搜索引擎对电子病历进行全文检索,但以上所有工作都不能满足海量数据的需求。Bahga A等人[4]通过使用云数据库,在一定程度上提升了检索效率。但医疗文本中,常出现一词多义等问题,准确率较低。Qiu Y等人[5]通过同义词进行查询扩展,Bendersky[6]提出一种权重依赖模型,对每个词用不同特征或短语串。这些方法能提升检索性能,但仍基于词粒度,不能准确地把握语义。Cai R等人[7]提出一种CNN-LSTM模型,通过深度学习方法,用文本匹配方式来检索,能更好地保留语义,但检索效率不足。
医疗文本匹配,主要应用于在线医疗问答。较早是用信息检索及统计语言学特征进行文本匹配。Hliaoutakis A等人[8]设计了一种面向生物医学文档的查询系统,用 TF-IDF作为文本特征,衡量语义相似性。深度学习也被应用在医疗文本匹配任务中。Cai H等人[9]提出一种将翻译语言模型和 Siameese CNN 模型结合的方法,分别学习问题和问题、问题和答案的相似性。但因医生提供的答案容易引入噪声,Li Y 等人[10]利用Siamese LSTM模型作为问句匹配的基础模型对结果进行重排序,但忽略了文本上下文语义的特征。
本文主要创新点有两方面:①提出了基于改进 Text-CNN 哈希模型的相似问题检出方法:基于SimHash的哈希最邻近检索,针对文本存在医疗术语较多、否定词较多,需关注局部语义及需关注整体语义特征的特点,提出了一种基于改进 Text-CNN 的哈希码检出方法。通过预训练词向量来解决医疗术语较多、一义多表达问题;针对否定词较多的特点,使用不同窗口大小的卷积核来处理;对于需关注局部语义与整体语义的特点,构建基于Inception的卷积神经网络,通过Inception使最终特征向量不仅包含高层语义,也包含低层特征。②提出了基于集成学习的相似文本匹配方法:它由三个模型集成。第一个构建的模型是Siamese-BERT,该模型主要关注与整体语义的匹配,先通过共享参数的BERT模型,提取各问题特征向量,然后将其仿射变换,得到一个两问题交互的相似向量,并对该向量进行全连接,通过Sigmoid损失判断两个句子是否语义相似。第二个模型是BERT-Match,该模型利用BERT的多头注意力机制,在关注语义信息时,更易关注到两个问句间的一些局部相似信息。第三个模型是梯度下降提升树相似模型,它将一些统计学特征与语义特征进行结合,并用梯度下降树来分类,以确定是否相似,最后通过权值平均,得到更高准确率。
1 相关介绍
1.1 医疗文本预处理
1.1.1 中文医疗文本分词
采用深度学习与统计语言结合的方法在分词中有较好效果。如Li Z等[11]提出基于结构化感知器进行分词的模型,其将分词看作序列标注问题,对于字符序列,以最大熵准则建模一个得分函数,通过最大化得分函数,找到一个最可能的标注。又如Zhang H P等[12]提出基于HHMM的分词模型,它将所有可能分词组合起来构建一个有向图,边的权重为平滑后的log值。现有许多分词工具,如LTP、NLPIR、THULAC和Fool-NLTK、pkuseg等。对100条记录手动分词与标注,评测指标为F1值,结果如表1所示。因pkuseg性能最好,故pkuseg为本文分词方法。

表1 分词结果对比表
1.1.2 词嵌入向量
Word2Vec:Word2Vec[13]的目标是从海量数据中得到高质量的词向量。它在语义和语法上都有较好的性能,目前已广泛应用在自然语言处理中。
TencentAILabEmbedding: 其[14]是腾讯采用DSG进行训练的一种嵌入式词向量,DSG算法基于词向量训练算法Skip-Gram,在文本窗口中词对共现关系的基础上,额外考虑词对相对位置。
1.2 Text-CNN 模型
Text-CNN[15]模型主要对一维卷积层及时序最大池化层进行了使用。假设输入文本序列由n个词组成,其中,每个词用d维词向量表示。那么,输入样本宽为n,高为1,输入通道数为d。该模型的计算有以下几步:先构建多个一维卷积核,并使用它们分别对输入进行计算。宽度不同的卷积核,可能捕捉到不同个数的相邻词的相关性。接下来对输出的所有结果进行时序最大池化,将输出值展平并拼接为向量。最后全连接层将该向量变换为有关各类别的输出并用丢弃层应对过拟合。Text-CNN模型结构如图1所示。
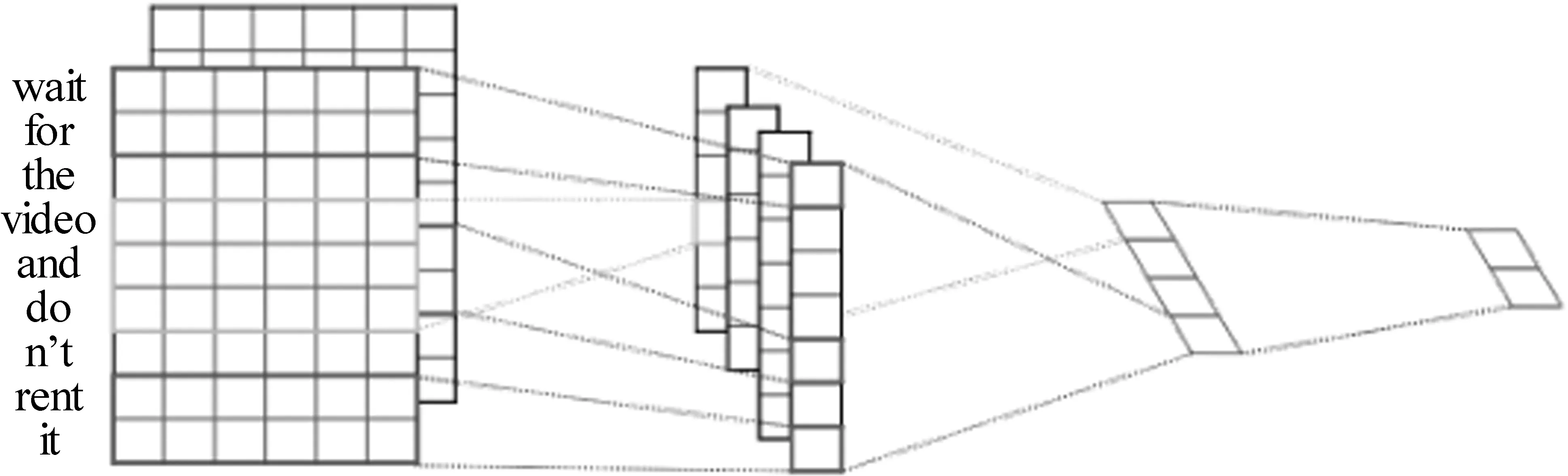
图1 Text-CNN 网络结构
1.3 BERT
BERT[16]原是一种Transformer的双向编码器,通过对左右上下文共有的条件计算,通过预先训练对来自无标注文本进行深度双向表示。预先训练的该模型,通常只需一个额外的输出层,对其微调,即可生成新模型,其核心是Transformer模型。Transformer模型[17]解决了LSTM采用的语言模型所存在的不能双向对上下文内容编码、并行化计算,及LSTM迁移学习较差的问题。它有6个Encoder 层及6个Decoder层,用多头的自注意力机制对文本编码。因本文只关注文本编码任务,仅介绍Encoder层。该层由一个多头自注意力层和一个全连接层组成。
多头注意力层:输入xi并仿射变换,如式(1)所示。
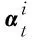
Wq,j、Wk,j、Wv,j均为可学习参数并且都通过随机正态分布初始化。用qi,j分别对输入序列中的元素对应的ki,j进行注意力机制计算。记注意力函数为Att,如式(5)所示。
将结果由softmax函数计算概率,即:
对不同的头进行自注意力计算,即:

bi为输入序列的第i个序列元素经过注意力后的向量,wo通过正态分布初始化。
连接层: 包括残差层及层正则化层。
(1)残差层:将上一层输入与输出叠加,记上一层输入为x,输出为f(x),则输出为:
(2)层正则化层:相对批量正则化,它综合考虑一层所有维度输入,即它针对单个训练样本,不依赖其他数据,计算该层的平均输入值和输入方差,然后用规范化操作来转换各个维度的输入。
全连接层:一个两层的全连接网络,输入经过线性变换再通过ReLU(·)函数后传入第二个全连接层中,如式(10)所示。
其中,W1、W2为通过随机正态分布初始化的可训练参数,b1、b2为偏置项。2数据增强方法论文EDA[18]指出,通过数据增强技术,能有效改善算法在较小数据集上的性能。故本文采用该方法对源数据集进行处理,使其有更大容量,减小过拟合的可能性。本文用两种方式进行增强: 第一种是基于自然语言处理的方式,即通过EDA方式进行数据扩充;第二种是因本文数据集为成对标注,即标注两个提问是否相似,因相似关系有传递性,本文提出了一种方法:基于相似性传递进行数据增强,并基于并查集算法,对传递后是否产生标注的不一致性做检测,对不一致的数据进行排除,避免导致模型训练不准确。基于相似性传递主要是指成对数据集通过相似与不像似的关系传递,从而达到数据增强。如A与B相似,B与C相似。则得到A与C相似。对于该增强方式,本文通过并查集方法扩容,但可能出现与标注数据不一致问题。本文通过算法1解决该问题。
3 改进的哈希码检出方法和相似文本匹配方法
3.1 基于文本卷积神经网络的哈希检索模型
Simhash[19]用于完成亿级网页去重任务。对于大规模数据集,逐次比对非常耗时,故对于大规模数据集,算法性能将很重要。它也被用于大规模检索任务,通过局部敏感哈希,将文本映射到一个哈希码,加快检索。但其在短文本上性能较差,且医学文本有较多专有名词与否定词,不能很好抽取其语义。本文借鉴它的思想,将文本通过特征提取,变成一个二进制哈希码,根据最近邻检索方法,实现快速检索。本文构建Inception-Hash-CNN模型解决该问题,它是一个孪生网络结构模型,实现了端到端训练。先通过改进的文本卷积神经网络进行文本特征抽取;然后由哈希生成网络实现二进制哈希码生成。
3.1.1 整体网络结构
孪生网络通过训练网络得到函数,该函数能将输入映射到目标空间,并计算输入空间的语义距离。它是共享权重的网络结构,接受两个输入,输出值一般表示语义距离。因本文数据集为成对表示,所以采用该网络构建模型,用它的公共参数做特征提取进行哈希码生成。其中按照功能可以分为特征抽取网络与哈希生成网络。整体网络结构如图2所示。

图2 Inception-Hash-CNN 整体网络结构
3.1.2 特征抽取网络
基于文本卷积神经网络,并结合被大量应用的Inception[20]机制,提出一种用于文本特征抽取的网络,共七层。第一层为输入层,输入为句子,输出其对应的词嵌入构成的矩阵。第二层为卷积层,分别设定卷积窗口大小为 3、4、5,用于特征提取。第三层为批量归一化层[21],增加模型泛化能力,以及加快收敛。第四层也为卷积层,再次提取特征。第五层为池化层,用最大池化,增加感受野,减少参数数量。第六层为Inception层,对第二层及第六层的输出进行Inception,使其兼顾到细节信息及语义信息。下面将详细对该网络进行介绍:①输入层,用于接收输入,并将其中的词替换为词嵌入向量,构成矩阵。其本质为一个查找表。其中矩阵的行维度为输入长度,列维度为词向量维度,且嵌入式词向量为可训练的,因文献[15]表明使用 fine-tune性能有提升。②卷积层的目标是提取句中局部特征。通过不同的滑动窗口,获得更全面的局部信息,以更好地提取特征向量。分别选取窗口大小为 3、4、5 的卷积核,对第一步得到的句子的嵌入词向量矩阵进行卷积。计算如式(11)所示。
其中,C为输出,W为卷积核参数,通过随机正态分布初始化,x为输入,b为偏置,f(·)为ReLU激活函数。
为了避免过拟合,添加了批量归一化层。它不仅加快了模型收敛速度,且能缓解深层网络中梯度弥散的问题,使训练该模型更容易。同时对卷积层进行批量归一化。对卷积的多个通道,需要对这些通道的输出都做批量归一化,且每个通道都有独立的拉伸和偏移参数,并均为标量。即若一个batch有m个样本,卷积后输出长度为x,词向量长度为l,通道数为c,批量归一化是对每个通道中m×x×l个元素进行归一化。其中归一化过程如下:考虑一个有m个样本的小批量,经过卷积得到新的批量,这里将结果记为x= {x1,x2,…,xm},xi为该批量中的一个样本,求该批量均值及方差。其中,记均值为ub,方差为σb,计算如式(13)、式(14)所示。
其中的平方计算是按元素求平方。然后对xi标准化,计算如式(15)所示。
ε是很小的数,且ε> 0,其作用是使分母不为0。批量归一化层还引入两个可学习参数:γ和β,拉伸为γ,偏移为β,这两参数和xi大小一样,且都通过随机正态分布初始化,由式(16)得到结果。
其中,⊗表示按元素乘法,yi表示批量归一化的结果。
因卷积后生成的特征向量仍有较高尺寸,不利于全连接,需加入池化层增大感受野。本文选的是最大池化,即在窗口内找到最大值。池化窗口大小设为3。
通常浅层部分保留细节信息,深层部分保留语义信息,由多个卷积核提取不同尺度的信息进行融合,能得到更好表征。因医疗提问专有词较多,需要一定细节信息,且否定词也较多,所以需语义信息。故本文采用Inception层融合细节及语义。即将两个卷积层的输出拼接,并把不同大小的Inception结果拼接,作为该层输出,供之后展平层及哈希生成网络使用。
3.1.3 哈希生成网络
该网络对特征抽取网络得到的特征进行哈希生成。它由用多层感知机构成,即通过多层感知机将特征抽取网络得到的结果,映射为哈希码向量,其中长度的设置会在实验中讨论。最后的哈希生成层,采用tanh函数,相对sgn函数,它更平滑。tanh函数如式(17)所示。
其中β为超参数,用于减小中间值的出现,使生成值接近 1 或-1。
3.2 基于改进的 BERT 模型的文本匹配方法
本文提出两种改进的BERT模型的文本匹配方法。其一,基于BERT孪生结构的Siamese-BERT,该模型主要关注语义层匹配任务。其二,参考Google论文中相似文本多分类方法,构建BERT-Match,该模型利用Transformer的多头注意力机制,更关注局部匹配,供文本匹配及训练使用。
3.2.1 Siamese-BERT模型
因BERT在多项自然语言处理任务中的出色表现,在其基础上,本文提出基于BERT的语义匹配模型。由孪生网络结构,实现有监督训练以解决相似文本的匹配问题及文本特征提取问题。本文采取Google提出的BERT-Base结构作为文本的 BERT 模型,其有12层,隐层大小为768,多头注意力为12,约110个参数。
该模型是端到端的模型,输入是一个字序列,输出是两个文本的匹配分数。采用孪生网络的方式构建,即两个网络共享参数训练。该模型能解决文本匹配问题,也解决了文本特征抽取问题,其结构如图3所示。先是输入层,接受一个字序列,然后预训练BERT模型,该部分模型参数是共享的,之后取BERT的特殊字符“CLS”所对应词向量作为该句的特征向量,可得到两句的特征向量,分别记为u,v。分别取u和v,及相减所得的特征向量u-v,并将其展平作为特征向量,记为x。经过一个仿射变换降维,降为 1 维,如式(18)所示。

图3 Siamese-BERT 模型的结构
其中,t为一维特征向量,W是通过随机正态分布初始化的可训练参数。将该向量全连接,并通过Sigmoid 函数输出两个向量是否相似。Sigmoid 函数如式(19)所示。
3.2.2 BERT-Match模型
本文参考BERT构建的用于多句的分类任务的模型,通过NSP方法完成句子匹配任务。NSP是Google在BERT论文中为理解句子间关系而提出的训练方法。该任务从语料库抽取句子对,即由句子A和B来生成。B有50%的概率是A的下一句子;50%为随机句子。NSP预测B是否为A的下一句。该论文表明,NSP方法对于问答及自然语言推理任务有较大性能提升。因NSP能获取句子间的信息,这是回归语言模型无法直接进行捕捉的。
在医疗文本匹配中,部分关键词往往是起决定性作用的因素。如疾病名称、症状等。该模型可充分利用Transformer的多头注意力机制,实现需要的局部关键词匹配特点。
本文先在首部加“CLS”作为开始标记,也将其经BERT所输出向量作为两句子特征向量;然后加入成对数据的第一句;在两句间用“SEP”分割,再加入第二句。之后通过Sigmoid感知机输出。BERT-Match模型是端到端的模型,其输入是一个字序列,输出是两个文本的匹配分数。模型架构如图4所示。

图4 BERT-Match 模型架构
3.3 特征选取及融合
本文分别选取编辑距离、编辑距离比、Jaro距离和去重子集比率以及语义特征等特征作为文本的统计特征。
编辑距离:指在两个字符串间,由一个字符串转换成另一个字符串,所需要的最少编辑操作次数。
编辑距离比: 由式(20)计算,其中sum为两个字符串的长度和;ldist表示类编辑距离,即在编辑距离中删除插入操作,距离记为l,但字符替换距离记为2。
Jaro距离:用来衡量两个字符串是否相似,为“0”表示两个字符串不相似,为“1”表示两个字符串相似。距离计算如式(21)所示。
其中,|s1|、|s2|是两个字符串长度,m是匹配的字符数,t是换位的数目。
去重子集比率:衡量相同词占句子的比率。如式(22)所示,其中setl函数表示得到该集合中的元素个数。
语义特征: 用Siamese-BERT模型最后一个全连接层的结果作为该特征。其有两个语义向量的相似度信息。
最后,将语义特征及统计特征拼接,构成新的特征向量以进行特征的融合。
3.3.1 梯度下降提升树匹配模型
本文通过XgBoost系统[22]实现梯度下降提升树模型。它是Boosting方式的集成学习算法,将许多树模型集成,从而构建出一个很强的分类器。每棵树其实是一个新函数,对上次预测的残差拟合。当训练完成后,可得到k棵树。当预测一个样本的分数时,根据样本特征,在每棵树中,得到其对应的叶节点,每个叶节点对应一个分数,最后将每棵树对应的分数求和,作为该样本的预测值。XgBoost的目标函数如式(23)、式(24)所示。

3.4 模型融合
本文用加权平均进行模型融合。因本文的模型输出均为两个文本的匹配度,故使用该方法,如式(25)所示。
其中,oi是模型输出的相似度,wi是该模型融合时对应的权重,首先随机初始化权值,然后进行迭代,通过最小化损失函数来确定权重。
4 实验与分析
4.1 基于文本卷积神经网络的相似病例语义检出方法的实验
4.1.1 实验数据集
本文通过爬虫从某在线医疗问诊网站爬取了42 765条语料,去除低质量的问题后,得到14 563条语料。取其中3 000对信息人工标注,如果两个问题相似,则标1,否则标0。然后由上文所述方式进行数据增强,得到34 534条成对数据作为数据集。本文用k折交叉验证的训练方式,按7:2:1进行训练集、测试集、验证集的划分。
4.1.2 实验数据预处理
(1) 文本清洗。因文本中有较多字符不易被神经网络处理,如标点符号等,通过正则表达式,进行清除处理。
(2) 对文本进行分词,根据实验结果,用带有医疗领域预训练的pkuseg分词。
(3) 去除停用词,针对提问的特点,将“医生”“你好”“请问”等无意义词加入停用词。又因神经网络不能直接接受分词数据,需构建词表,将句子转为索引形式,以输入神经网络。
(4) 进行词向量选择,本文对Tencent AI Lab Embedding、Word2Vec评测。其中Tencent AI Lab Embedding用腾讯发布的预训练模型,Word2Vec用在百度百科上训练的预训练模型[23]。在本文所构建的基于TextCNN的baseline模型中,用Tencent AI Lab Embedding训练后得F1为 0.75,用Word2Vec的F1则为0.67,故用Tencent AI Lab Embedding作为词向量。
4.1.3 实验评测标准
考虑到病例检出主要关注是否检索准确与相关文档的检出率。本实验用查准率(Precision)、查全率(Recall)、F1值(F1-Score)作为评测指标。
TP为真正例,即应被检索且被检索的数量;FP为假正例,即不应被检索但被检索到的数量;FN为假负例,即应被检索但未被检索的数量;TN为真负例,即不应被检索,且未被检索的数量。
4.1.4 实验环境配置与参数设置
实验环境的机器配置:CPU为Intel (R) Xeon(R) Silver 4110 CPU 2.10 GHz * 2;GPU为NVIDIA TITAN XP;内存128 GB。
实验环境的软件配置:宿主机操作系统Ubuntu Server 16.04 64-bit;容器引擎为 Docker CE;用的容器镜像为Deepo;镜像中操作系统为Ubuntu 18.04;CUDA用 10.1版本;编程语言为Python 3.6;深度学习框架为Pytorch 1.4。
因模型要求输入矩阵有固定大小,即文本的单词长度是固定长度。本文设定输入长度为70个单词。即少补空白词,多进行截断。
本文epoch设为25,batch为256。训练时,本文用Adam优化器,学习率设为0.001,betas参数设为(0.9,0.999),eps设为1e-08,L2惩罚项设置为 0。
4.1.5 实验结果及对比分析
数据增强效果: 用基于TextCNN的孪生网络模型为基础模型在不同的数据增强下进行验证。依次用基于自然语言处理、基于关系传递性及两者结合,最后使用本文增强后的数据集进行实验,结果如表2所示。

表2 不同数据增强方法性能对比 (单位:%)
可以看出,两者结合的结果最好,所以用数据增强对模型训练的影响进行了测试。先将数据进行基于关系传递性的数据增强,再利用自然语言处理对数据增强,如图5所示。

图5 数据集扩容大小效果对比图
由图5可知,当数据增强至18 000时,收益趋于平稳。故选择将源数据增强至18 000个成对数据作为本文数据集。
哈希码长度对检索的影响: 选取长度为32、48、64、72、84来实验,用F1值、查准率、查全率作为衡量标准,结果如表3所示。

表3 不同哈希长度的性能对比 (单位:%)
可以看出,当哈希码长度为64时,查全率最高,因检出步骤在其他值合理的情况下,更关注查全率,故选取长度为64。
模型中卷积窗口大小的选择对模型的影响: 选择(2,3,4),(3,4,5),(4,5,6),(2,3,5)进行对比,用查全率为衡量标准,结果如图6所示。可以看出,选取(2,3,5)时查全率最高。
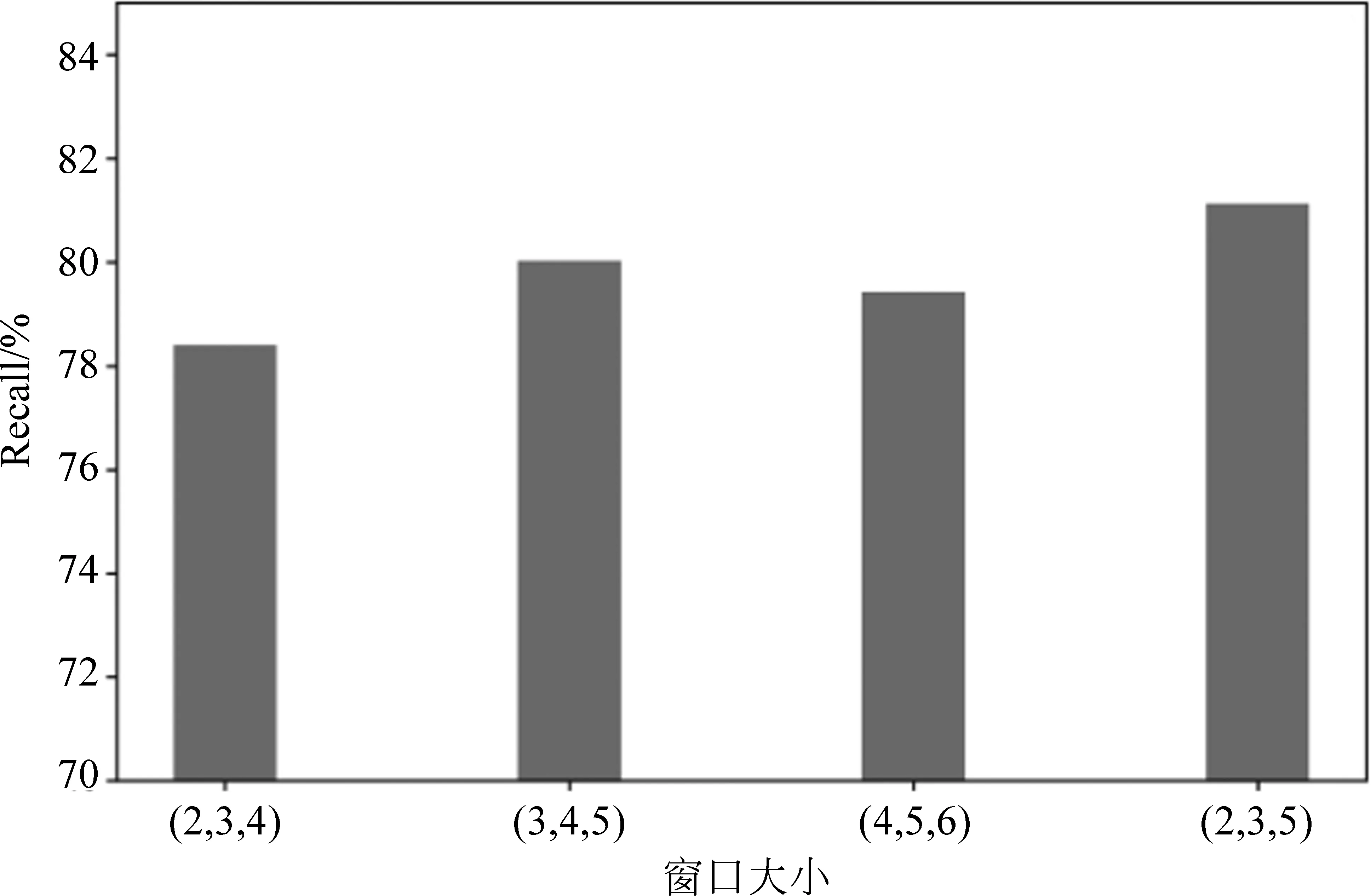
图6 不同窗口大小的查全率对比图
检索性能: 哈希生成效率会影响检索所需时间。由于用户请求通常是单次的,若用消息队列,会使等待时间线性增加;若用多线程,则当有大量并发请求时,会导致宕机;且依次处理用户请求,不能充分利用GPU的并行性。本文针对需求,用流方式将请求排队组成一个batch,再进行哈希生成。本文对比了不同方法的哈希生成速度,结果如表4可知。可以看出,本文的检索效率,可被用户接受,对于大规模数据,有一定的适用性。

表4 不同方法检索性能对比
算法对比: 本文选取ISTR[24],BM25-IDF[25],DMRM[26],GSRM[27]等检出方法进行实验对比,结果如表5 所示。
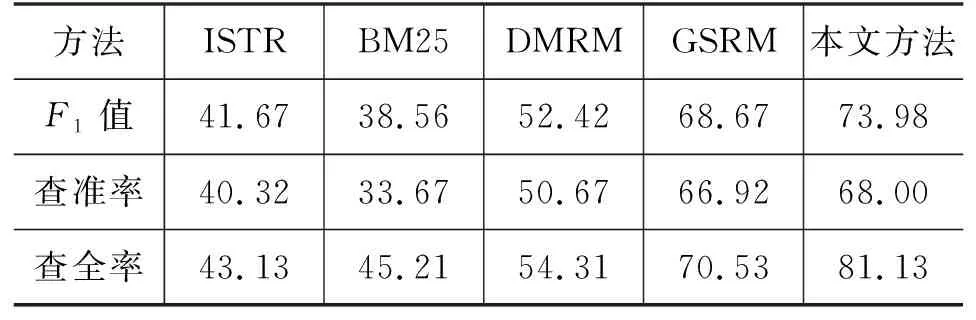
表5 不同算法性能对比 (单位:%)
4.2 基于集成学习的相似问题匹配方法的实验
4.2.1 实验数据集
使用与4.1.1节相同数据集对BERT模型再训练。3 000对人工标注的语料由数据增强得到的24 000条成对数据,它主要用于Siamese-BERT模型及BERT-Match模型进行fine-tune及梯度下降决策树相似模型训练使用。按照7:1:2把增强后的成对数据分成训练集、验证集、测试集。
4.2.2 实验评测标准
因匹配度是[0,1]区间的数,且数据集标注为0或1,即匹配或不匹配。因数据集可能存在不平衡,同时应兼顾查准率与查全率,用F1值作为评测指标。考虑到数据平衡性的影响,当其输出匹配度大于γ时为正样本,γ是位于[0,1]区间的数,通过在验证集以网格搜索的方式得到。
4.2.3 实验环境及参数设置
实验环境同4.1.4节的介绍。
本文的预训练模型是Cui等[28]提出的中文预训练BERT-wwm。该模型在中文维基和通用数据中训练,通用数据包括百科、新闻、问答等数据,总词数达5.4B,处理后的文本大小约 10 GB。fine-tune阶段,batch取32,epoch为10。
4.2.4 实验结果及对比分析
先探究对模型进行迁移再训练的效果。分别在选取不同的epoch的情况下,对BERT再训练。再对模型进行fine-tune训练,结果如图7所示。可以看出,相比不进行再训练,进行迁移再训练,得分高了1左右,说明利用未标注数据再训练,准确率有提升。且在第二个epoch时,效果提升最大,故选择两个epoch,进行后续的fine-tune训练。
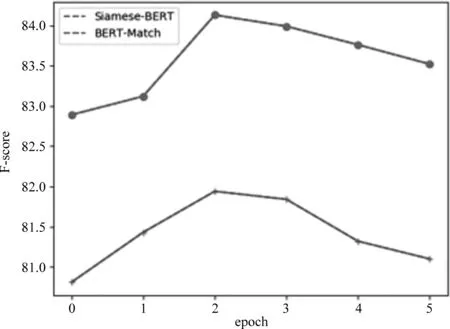
图7 再训练模型性能与 epoch 关系图
接着进行语义相似特征的选择实验。分别将Siamese-BERT与BERT-Match的相似向量(即CLS字符所对应向量)替换入决策树中,结果如表6所示,用Siamese-BERT的相似向量比用BERT-Match的相似向量的F1值高0.2;若两者拼接,F1值反而下降,可能是因维度过高导致过拟合。故选择 BERT-Match的相似向量作为梯度下降决策树的语义向量。

表6 不同语义向量的选择的性能对比 (单位:%)
对比Siamese-BERT、BERT-Match模型、梯度下降决策树及融合后模型分别在最好情况下的F1值,结果如表7所示。

表7 不同模型性能对比 (单位:%)
由表7知,BERT-Match比Siamese-BERT的F1约高0.02。本文认为,主要是BERT-Match可利用多头注意力机制实现两个句子间的关键词的具体对应,且相对于Siamese-BERT,梯度下降决策树也有提升,主要是其进行了特征工程,提取部分传统特征用于匹配的作用。最后,用基于权重均值的多模型融合,又使F1值有不少提升,说明本文所提出的模型可行。
最后,将集成学习构建好的模型,与常见文本匹配方法及部分医疗文本匹配方法做对比。对于中文文本匹配模型,与BiLSTM、BiLSTM-Att、DSSM、ESIM、MatchPyramid 等模型进行对比。其中,BiLSTM模型采用孪生网络并使用双向 LSTM对文本特征抽取;BiLSTM-Att为融合自注意力机制的BiLSTM模型;DSSM是用全连接网络对提取的N-Gram匹配的方法;ESIM是阿里提出用于问答的模型,该模型运用分解注意力实现对问句的表示及交互的同时建模;MatchPyramid将匹配矩阵用于文本匹配。对于医疗文本,选择STMT[29]、CNNs[30]作对比,结果如表8所示。
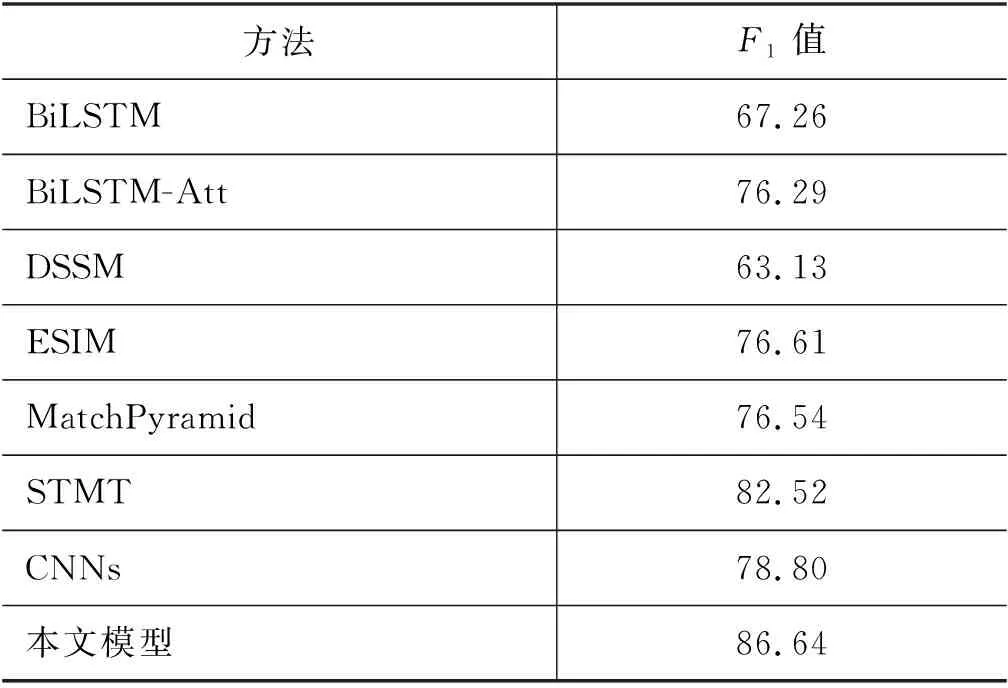
表8 匹配性能对比表 (单位:%)
5 总结与展望
本文提出了一种两阶段模型。第一阶段,通过对提问生成哈希,用哈希检索的方法进行最近邻检索,确定一个待匹配集合。第二阶段,构建一个基于集成学习的匹配模型,对第一阶段的检出结果进行匹配,去除一些匹配度较低的病例,使检索更加准确,并且根据匹配度将病例进行排序,使用户更容易得到所需的结果。通过实验对比,本文的两个模型的性能相对于现有模型都有很大的性能提升。在下一步的研究工作中,会考虑如何将结构化数据与非结构化数据进行统一的检索等问题。
