文档智能: 数据集、模型和应用
2022-08-02徐毅恒吕腾超韦福如
崔 磊,徐毅恒,吕腾超,韦福如
(微软亚洲研究院 自然语言计算组,北京 100080)
0 文档智能
文档智能(Document AI, or Document Intelligence)是近年来一项蓬勃发展的研究课题,同时也是实际的工业界需求,主要是指对于网页、数字文档或扫描文档所包含的文本以及丰富的排版格式等信息,通过人工智能技术进行理解、分类、提取以及信息归纳的过程。由于布局和格式的多样性、低质量的扫描文档图像以及模板结构的复杂性,文档智能成为一项非常具有挑战性的任务并获得相关领域的广泛关注。随着数字化进程的加快,文档、图像等载体的结构化分析和内容提取成为关乎企业数字化转型成败的关键一环,自动、精准、快速的信息处理对于生产力的提升至关重要。以商业文档为例,不仅包含了公司内外部事务的处理细节和知识沉淀,还有大量行业相关的实体和数字信息。人工提取这些信息不仅耗时、费力、精度低,而且可复用性也不高,因此,文档智能技术应运而生。文档智能技术深层次地结合了人工智能和人类智能,在金融、医疗、保险、能源、物流等多个行业均有不同类型的应用。例如,在金融领域,其可以实现财报分析和智能决策分析,为企业战略的制定和投资决策提供科学、系统的数据支撑;在医疗领域,其可以实现病例的数字化,提高诊断的精准度,并通过分析医学文献和病例的关联性,定位潜在的治疗方案。在财务领域,其可以实现发票和采购单的自动化信息提取,将大量非结构化文档进行自动结构化转换,并支撑大量下游业务场景,节省大量人工处理时间开销。
在过去的30年中,文档智能的发展大致经历了三个阶段,从简单的规则启发式方法逐渐进化至神经网络的方法。20世纪90年代初期,研究人员大多使用基于启发式规则的方法进行文档的理解与分析,通过人工观察文档的布局信息,总结归纳一些处理规则,对固定布局信息的文档进行处理。然而,传统基于规则的方法往往需要较大的人力成本,而且这些人工总结的规则可扩展性不强,因此研究人员开始采用基于统计学习的方法。2000年以来,随着机器学习技术的发展和进步,基于大规模标注数据驱动的机器学习模型成了文档智能的主流方法,它通过人工设计的特征模板,利用有监督学习的方式在标注数据中学习不同特征的权重,以此来理解、分析文档的内容和布局。然而,虽然传统的文档理解和分析技术基于人工定制的规则或少量标注数据进行学习,这些方法虽然能够带来一定程度的性能提升,但由于定制规则和可学习的样本数量不足,其通用性往往不尽如人意,而且针对不同类别文档的分析迁移成本较高,这距离文档智能技术的实用化和产业化还有相当一段距离。近年来,随着深度学习技术的发展,以及大量无标注电子文档的积累,文档分析与识别技术进入了一个全新的时代。图1是在当前深度学习框架下文档智能技术的基本框架,其中不同类型的文档通过内容提取工具(HTML/XML抽取、PDF解析器、光学字符识别OCR等)将文本内容、位置布局信息和视觉图像信息组织起来,利用大规模预训练的深度神经网络进行分析,最终完成各项下游应用任务,包括文档版面分析、文档信息抽取、文档视觉问答以及文档图像分类等。深度学习技术的出现,特别是以卷积神经网络(CNN)、图神经网络(GNN)以及Transformer架构[1]为代表预训练技术的出现,彻底改变了传统机器学习需要大量人工标注数据的前提,更多地依赖大量无标注数据进行自监督学习,进而通过“预训练-微调”模式来解决文档智能相关的应用任务,取得了显著性突破。
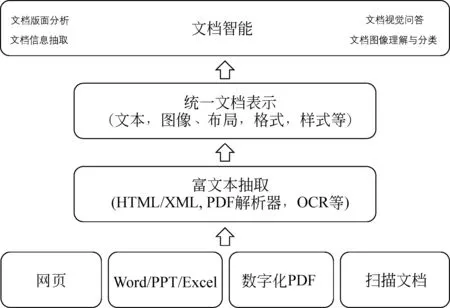
图1 基于深度学习的文档智能技术框架
尽管深度学习极大地提高了文档智能技术的准确性,但是在实际应用中仍然有很多问题亟待解决。首先,受限于当前大规模预训练模型输入长度的限制,文档智能预训练模型通常需要将文档截断为几个部分,分别输入模型进行处理,这对于复杂长文档的多页跨页处理带来了极大的挑战。其次,由于实际场景中的扫描文档图像质量参差不齐,特别是人工标注的训练数据往往质量较高,而业务场景的文档图像由于扫描设备的清晰度、纸张褶皱和摆放位置的随意性,导致了性能不佳,因而需要利用更多数据增强技术来帮助现有模型提升性能。此外,当前文档智能各项任务通常是独立训练的,不同任务之间的关联性还未被有效地利用。例如,文档信息抽取和文档视觉问答有某些共性的语义表示,可以利用多任务学习框架更好地解决这类问题。最后,基于预训练的文档智能模型在实际应用中也遇到了计算资源和训练样本不足的问题,探索基于小模型的深度学习架构和模型压缩技术,以及少样本学习(Few-shot Learning)和零样本学习(Zero-shot Learning)技术也是当前重要的研究方向,并具有很大的实用价值。
接下来,我们首先将介绍当前主流的文档智能模型框架、任务和数据集,随后将分别重点介绍早期基于启发式规则的文档分析技术、基于传统统计机器学习的算法模型,以及近年来基于深度学习,特别是基于多模态预训练技术的文档智能模型和算法,最后我们将展望文档智能技术的未来发展方向。
1 主流文档智能模型框架、任务及数据集
1.1 基于卷积神经网络的文档版面分析模型
近年来,卷积神经网络在计算机视觉领域取得了巨大的成功,特别是基于大规模标注数据集ImageNet和COCO的有监督预训练模型ResNet[2]在图像分类、物体检测以及场景分割任务上都带来了极大的性能提升。具体来讲,随着多阶段检测模型Faster R-CNN[3]和Mask R-CNN[4]等以及单阶段检测模型SSD[5]和YOLO[6]的普及,目标检测在计算机视觉中几乎成了已解决问题。文档版面分析本质上可以看作一种文档图像的物体检测任务,文档中的标题、段落、表格、插图等基本单元就是需要检测和识别的物体。Yang等人[7]将文档版面分析看作一个像素级分割任务,并尝试利用卷积神经网络进行像素分类取得很好的效果。Schreiber等人[8]首次将Faster R-CNN模型应用于文档版面分析中的表格识别任务,如图2所示,在ICDAR 2013[9]表格识别数据集上取得了SOTA的结果。然而,文档版面分析虽然是一个经典的文档智能任务,但是多年来一直受限于较小的数据集规模,仅仅套用经典计算机视觉预训练模型依然是不够的。随着大规模弱监督文档版面分析数据集PubLayNet[10]、PubTabNet[11]、TableBank[12]以及DocBank[13]的出现,研究人员可以对不同的计算机视觉模型和算法进行更为深入的比较和分析,进一步推动了文档版面分析技术的发展。
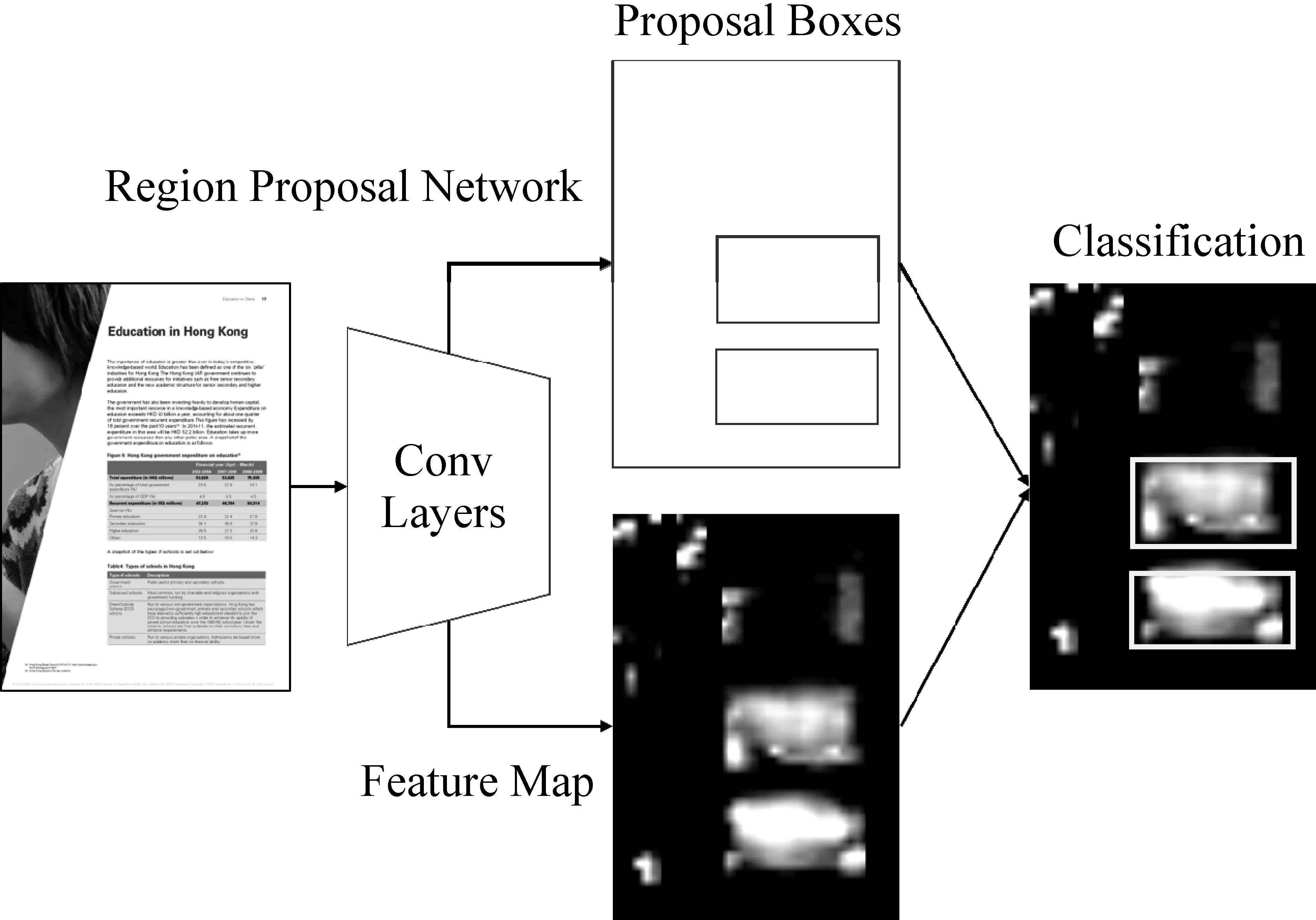
图2 基于卷积神经网络Faster R-CNN的文档版面分析模型
1.2 基于图神经网络的文档信息抽取模型
信息抽取是从非结构化文本中提取结构化信息的过程,其作为一个经典和基础的自然语言处理问题已经得到广泛研究。传统的信息抽取聚焦于如何从纯文本中提取实体与关系信息,却较少对视觉富文本进行研究。视觉富文本数据是指语义结构不仅由本文内容决定,也有与排版、表格结构、字体等视觉元素有关的文本数据。视觉富文本数据在生活中随处可见,例如,收据、证件、保险单等。Liu等人[14]提出利用图卷积神经网络对视觉富文本数据进行建模,如图3所示。每张图片经过OCR系统后会得到一组文本块,每个文本块包含其在图片中的坐标信息与文本内容。这项工作将这一组文本块构成全连接有向图,即每个文本块构成一个节点,每个节点都与其他所有节点有连接。节点的初始特征由文本块的文本内容通过Bi-LSTM编码得到。边的初始特征为邻居文本块与当前文本块的相对坐标与长宽信息,该特征使用当前文本块的高度进行归一化处理,具有仿射不变性。与其他图卷积模型仅在节点上进行卷积不同,这项工作更加关注在信息抽取中“个体-关系-个体”的三元信息,所以在“节点-边-节点”的三元特征组上进行卷积。除此之外,还引入了自注意力机制,让网络在全连接有向图构成的所有有向三元组中挑选更加值得注意的信息,并加权聚合特征。初始的节点特征与边特征经过多层卷积后得到节点与边的高层表征。
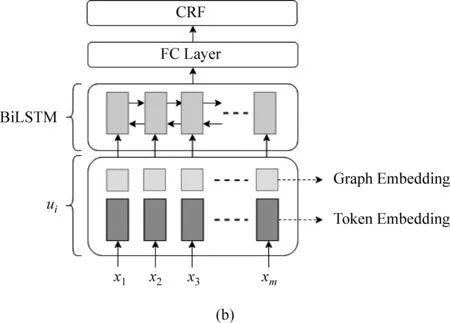
图3 基于图神经网络架构的文档信息抽取模型
这项工作在两份真实商业数据上测试了所提出方法的效果,分别为增值税发票(VATI,固定版式,3 000张)和国际采购收据(IPR,非固定版式,1 500张)。使用了两个基准系统,基准系统Ⅰ为对每个文本块的文本内容独立做BiLSTM+CRF解码,基准系统Ⅱ为将所有文本块的文本内容进行“从左到右、从上到下”的顺序拼接后,对拼接文本整体做BiLSTM+CRF解码。实验表明,基于图卷积的模型在基准系统的基础上都有明显的性能提升,其中在仅依靠文本信息就可以抽取的字段(如日期)上与基准系统持平,而在需要依靠视觉信息做判断的字段(如价格、税额)上有较大的性能提升。此外,实验显示,视觉信息起主要作用,增加了语义相近文本的区分度。文本信息也对视觉信息起到一定的辅助作用。自注意力机制在固定版式数据上基本没有帮助,但是在非固定版式数据上有一定的性能提升。
1.3 基于Transformer结构的通用文档理解预训练模型
很多情况下,文档中文字的位置关系蕴含着丰富的语义信息。例如,表单通常是以键值对(Key-value Pair)的形式展示的。通常情况下,键值对的排布通常是左右或者上下形式,并且有特殊的类型关系。类似地,在表格文档中,表格中的文字通常是网格状排列,并且表头一般出现在第一列或第一行。通过预训练,这些与文本天然对齐的位置信息可以为下游的信息抽取任务提供更丰富的语义信息。对于富文本文档,除了文字本身的位置关系之外,文字格式所呈现的视觉信息同样可以帮助下游任务。对文本级(Token-level)任务来说,文字大小、是否倾斜、是否加粗,以及字体等富文本格式能够体现相应的语义。通常来说,表单键值对的键位(Key)通常会以加粗的形式给出。对于一般文档来说,文章的标题通常会放大加粗呈现、特殊概念名词会以斜体呈现等。对文档级(Document-level)任务来说,整体的文档图像能提供全局的结构信息,例如,个人简历的整体文档结构与科学文献的文档结构是有明显的视觉差异的。这些模态对齐的富文本格式所展现的视觉特征可以通过视觉模型抽取,结合到预训练阶段,从而有效地帮助下游任务。
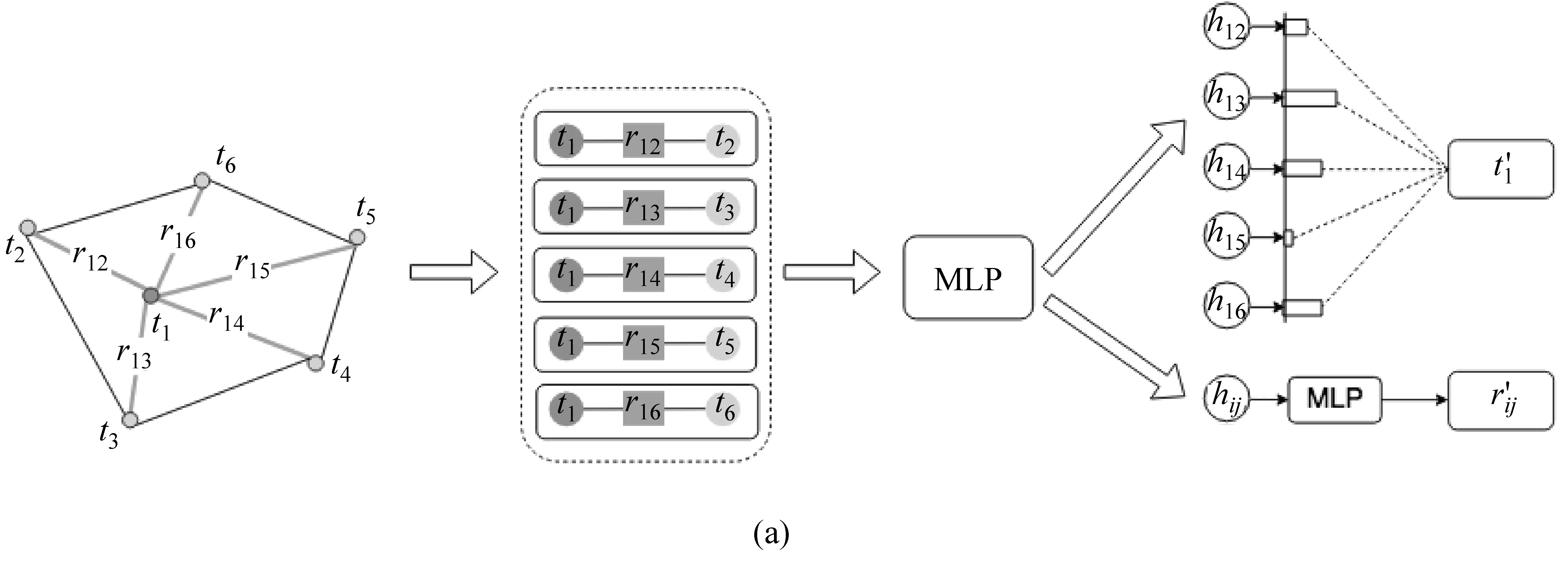
为了利用上述信息,Xu等提出了通用文档预训练模型LayoutLM[15],如图4所示。在现有的预训练模型基础上添加2-D Position Embedding和Image Embedding两种新的Embedding 层,这样可以有效地结合文档结构和视觉信息。具体来讲,根据OCR获得的文本Bounding Box,能够获取文本在文档中的具体位置。将对应坐标转化为虚拟坐标之后,计算该坐标对应在x、y、w、h四个Embedding子层的表示,最终的2-D Position Embedding为四个子层的Embedding之和。在Image Embedding部分, 将每个文本相应的Bounding Box当作Faster R-CNN中的候选框(Proposal),从而提取对应的局部特征。特殊地,由于“[CLS]”符号用于表示整个输入文本的语义,同样使用整张文档图像作为该位置的Image Embedding,从而保持模态对齐。
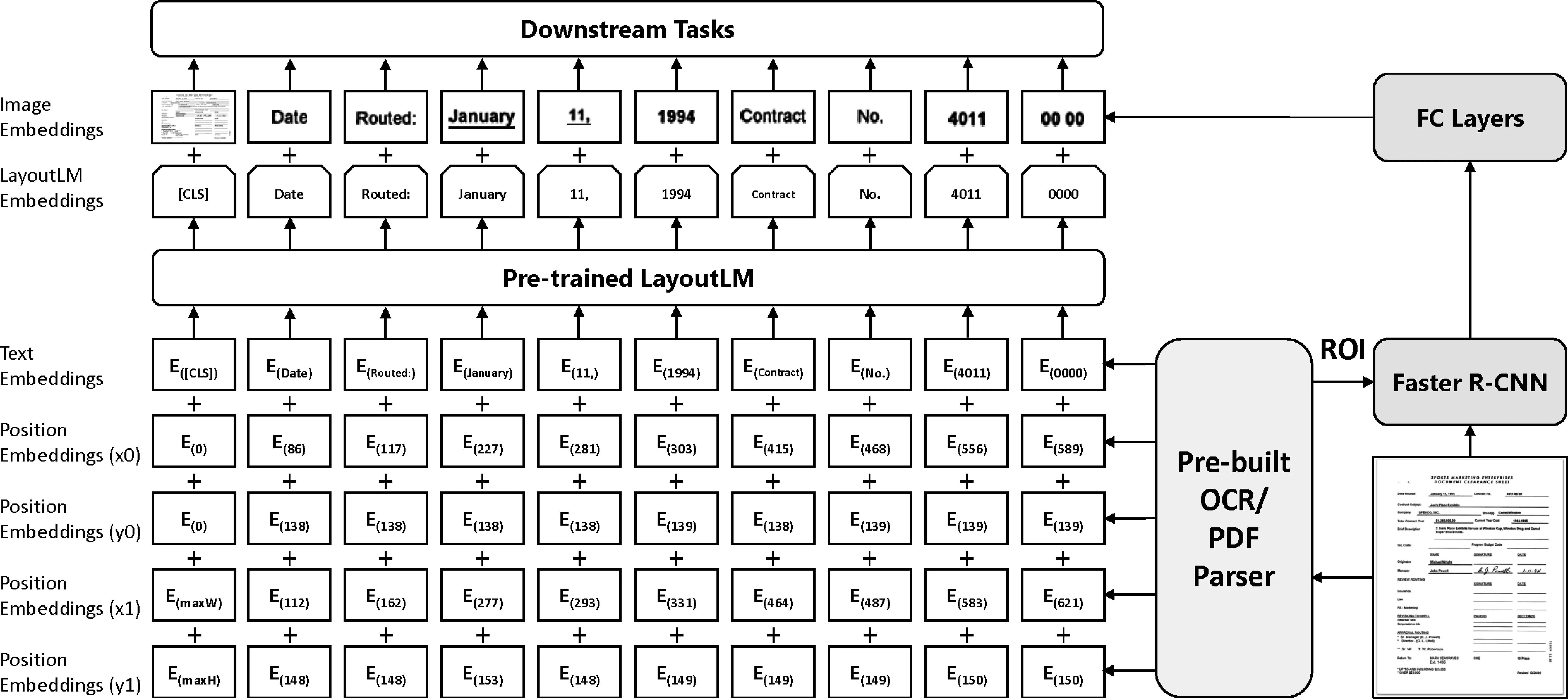
图4 基于Transformer架构的通用文档理解预训练模型LayoutLM
在预训练阶段,针对 LayoutLM的特点提出两个自监督预训练任务:
•掩码式视觉语言模型(Masked Visual-Language Model,MVLM): 大量实验已经证明MLM能够在预训练阶段有效地进行自监督学习。在此模型MVLM基础上进行了修改: 在遮盖(Mask)当前词之后,保留对应的2-D Position Embedding暗示,让模型预测对应的词。在这种方法下,模型根据已有的上下文和对应的视觉暗示预测被遮罩的词,从而让模型更好地学习文本位置和文本语义的模态对齐关系。
•多标签文档分类(Multi-label Document Classification,MDC): MLM能够有效地表示词级别的信息,但是对于文档级的表示,需要文档级的预训练任务来引入更高层的语义信息。在预训练阶段使用IIT-CDIP数据集为每个文档提供了多标签的文档类型标注,同时引入MDC多标签文档分类任务。该任务使得模型可以利用这些监督信号去聚合相应的文档类别,并捕捉文档类型信息,从而获得更有效的高层语义表示。
实验结果表明,在预训练中引入的结构和视觉信息,能够有效地迁移到下游任务中。最终在多个下游任务中都取得了显著的准确率提升。与传统的基于卷积神经网络和图神经网络模型不同,通用文档智能预训练模型的优势在于可以支持不同类型的下游应用。
1.4 文档智能主流任务和数据集
文档智能涉及自动阅读、理解和分析文档的相关技术,在实际场景的应用中主要包括四大类任务,分别是:
• 文档版面分析: 指对文档版面内的图像、文本、表格信息和位置关系所进行的自动分析、识别和理解的过程。
• 文档信息抽取: 指从文档中大量非结构化内容中抽取实体及其关系的技术。与传统的纯文本信息抽取不同,文档的构建使得文字由一维的顺序排列变为二维的空间排列,因此文本信息、视觉信息和位置信息在文档信息抽取中都是极为重要的影响因素。
• 文档视觉问答: 指给定文档图像数据,利用OCR技术或其他文字提取技术自动识别影像资料后,通过判断所识别文字的内在逻辑,回答关于图片的自然语言问题。
• 文档图像分类: 指针对文档图像进行分析识别从而归类的过程。
对于这四种主要的文档智能任务,学术界和工业界也开源了大量相关的基准数据集,如表1所示。这也极大地推动了相关领域的研究人员构建新的算法模型,特别是当前基于深度神经网络的模型在这些任务上都有不俗的表现。接下来,本文将分别详细介绍在过去不同时期的经典模型和算法,包括基于启发式规则的文档分析技术、基于统计机器学习的文档分析技术和基于深度学习的通用文档智能模型,为大家提供参考。
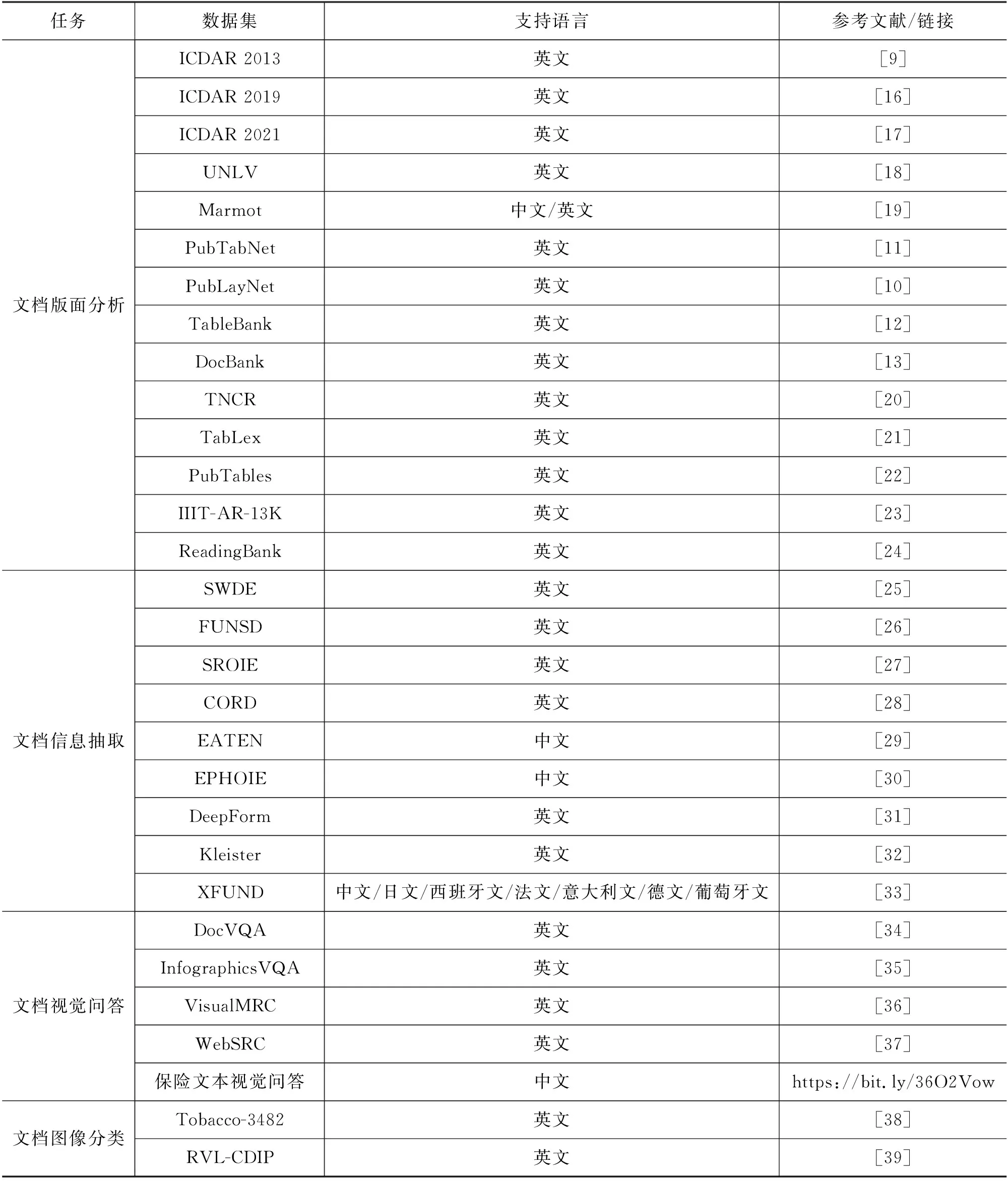
表1 文档智能领域主流任务(文档版面分析、文档信息抽取、文档视觉问答、文档图像分类)开源数据集
2 基于启发式规则的文档分析技术
基于启发式规则的文档分析技术大致可分为自顶向下、自底向上和混合模式三种方式。自顶向下方式将文档图片作为整体逐步将其划分为不同区域,以递归方式进行切割,直至区域分割至预定义的标准,通常为块或列。自底向上以像素或组件为基本元素单位,对基本元素进行分组、合并以形成更大的同质区域。自顶向下方式在特定格式下的文档中能够更快、更高效地分析文档。而自底向上方式虽需要耗费更多的计算时间,但通用性更强,可覆盖更多不同布局类型的文档。混合方式则将其两者相结合以尝试产生更好的效果。
本节从自顶向下和自底向上两种角度出发,介绍基于Projection Profile、Image Smearing、Connected Components等方式的文档分析技术。
2.1 Projection Profile
Projection Profile作为一种自顶向下的分析方式被广泛应用于文档分析。Nagy 等人[40]使用Projection Profile中的X-Y切割算法对文档进行切割,这一方式适用于具有固定文本区域和行距的结构化文本,但该方式对边界噪声敏感且无法在倾斜的文本上提供良好性能,对文档质量要求较高。Itay等人[41]使用自适应局部投影方式计算文档的倾斜度,以尝试消除文本倾斜导致的性能下降,实验证明模型在倾斜和弯曲文本上得到了较为准确的结果。此外,还有很多X-Y切割算法的变体被提出以解决现存的缺陷,O′Gorman[42]将X-Y切割算法扩展至使用组件边界框的投影,Sylwester 等人[43]使用了编辑成本评估指标以指导模型进行分割,所有这些方法均在一定程度上提高了模型的性能。
Projection Profile分析算法适用于结构化文本,尤其是曼哈顿(Manhattan)布局文档。在布局复杂、文本倾斜或包含边界噪声的文档上可能无法展现出良好的性能。
2.2 Image Smearing
Image Smearing分析法指从一个位置向四周渗透,逐渐扩展至所有同质区域,以此确定页面当中的一个区域。Wong等人[44]采用自顶向下策略,使用游长平滑算法(Run-length Smoothing Algorithm,RLSA)判断同质区域。将图像二值化后,像素值0表示背景,1表示前景,当0周围的0数目小于指定阈值C时,该位置的0修改为1,游长平滑算法通过这一操作将距离相近的前景内容合并为整体。这种方式可以逐步将字符合并为单词,单词合并为文本行,继而将范围不断延伸至整个同质区域。Fisher等人[45]在此基础上对其做进一步改进,增加了除噪、倾斜矫正等预处理。此外,游长平滑算法的阈值C修改为依据动态算法进行调整,进一步提升模型的适应能力。Esposito等人[46]采用了类似的方法,但操作对象由像素改为了字符框。Shi等人[47]则是对图片中的每一个位置像素进行扩展,得到一个新的灰度图,随后进行抽取,在手写字体、文本倾斜等情况下仍能表现出良好的性能。
2.3 Connected Components
Connected Components分析法作为一种自底向上的技术,推测最小粒度元素之间的关系,用于寻找同质区域,最终将区域分类为不同属性。Fisher等人[45]采用Connected Components技术,找到每个组件的K近邻(KNearest Neighbors,KNN)组件,通过互相之间的位置、角度等关系来推断当前区域属性。Saitoh等人[48]判断并根据文档的倾角将文字合并成线,继而将线合并为区域,随后将其分类为不同的属性。Kise等人[49]同样尝试解决文本的倾斜问题,作者采用了近似面积Voronoi图(Approximated Area Voronoi Diagram)来获得区域的候选边界,这一操作对于任意倾角的区域有效。但由于计算过程中需要估计字符间距和行内间距,因此当文档中包含大字体及宽字间距等情况时,模型并不能发挥出良好性能。此外,Bukhari等人[50]也尝试在使用Connected Components的基础上使用AutoMLP以便寻找分类器最佳参数,进一步提升性能。
2.4 其他方法
除上文所述外,还有一些其他的启发式规则方法,例如,Baird等人[51]采用自顶向下的方式按空白将文档进行切割划分区域。Xiao等人[52]使用了Delaunay Triangulation算法进行文档分析,Bukhari等人[53]在此基础上将其应用于书写随意的手写文档。此外还有一些混合算法,Okamoto等人[54]通过分隔符和空白来切割块,在每个块中进一步将内部组件合并为文本行。Smith[55]将文档分析分成两部分,首先使用自底向上的方式来定位制表符,借助制表符推断列布局。随后在列布局上采用自顶向下的方式来推断结构和文本顺序。
3 基于统计机器学习的文档分析技术
传统的文档分析过程通常分为两阶段: ①将文档图片切割,得到多个不同候选区域;②对区域进行属性分类,将其判别为文本、图像等规定类。基于机器学习的方法也通常从这两个角度入手,部分研究工作尝试使用机器学习算法参与文档的切割,其余则尝试在已生成的区域上构造特征,使用机器学习算法对区域进行分类。此外,由于统计机器学习技术带来的性能上的提升,较多基于统计机器学习的方法在表格检测任务中被尝试使用,因表格检测是文档分析的一个重要子任务,本节也会对其进行一些介绍。因此与前文基于技术角度的阐述方式不同的是,从下文开始将会从文档分析中的任务角度来对其发展情况做出介绍。
3.1 文档分割
在文档切割过程中,Baechler等人[56]结合X-Y裁剪算法,使用逻辑斯蒂回归对文档进行切割,丢弃空白部分。在得到相应区域后,实验比较了K近邻、逻辑斯蒂回归(Logistic Regression,LR)和最大熵马尔可夫模型(Maximum Entropy Markov Models,MEMM)等算法作为分类器的性能优劣,实验表明,最大熵马尔可夫模型和逻辑斯蒂回归在属性分类任务上可以展现出较好的性能。Esposito等人[57]在文档分割过程中进一步加强机器学习算法在其中的参与程度。在自底向上的过程中,从字母到单词到文本行逐渐合并的过程中使用了一种基于内核的算法[58],并将结果转换成XML结构存储。之后使用文档组织算法(Document Organization Composer,DOC)对文档进行分析。Wu等人[59]则致力于文字同时存在两种阅读顺序的问题,此前的算法均假定文字只有一种书写方向,但遇到诸如汉语或日语等可以水平或者竖直方向书写的文字时无法正常地工作。该算法将文档分割分为四个步骤,用于判断并处理文本,并使用了支持向量机以决定是否执行步骤。
3.2 区域分类
在区域属性分类问题上,大量工作主要致力于尝试不同机器学习算法作为分类器输出结果。其中,Wei等人[60]实验比较了支持向量机、多层感知机(Multi-Layer Perceptron,MLP)和高斯混合模型(Gaussian Mixture Models,GMM)几种机器学习算法作为分类器时的性能优劣,实验结果表明,支持向量机和多层感知机在区域属性上的分类性能明显优于高斯混合模型。Bukhari等人[61]手动构造了多个特征,对区域抽取相应特征后使用AutoMLP算法进行分类,在阿拉伯语数据集中得到了95%的分割准确率。Baechler等人[56]在文档分割上做了进一步改进,使用了金字塔形算法,在中世纪手稿上进行了三个不同级别的分析,最后使用动态多层感知机(Dynamic Multi-Layer Perceptron,DMLP)作为分类器。
3.3 表格检测
除上述方式之外,基于统计机器学习技术在表格识别领域存在大量研究。Wang等人[62-64]使用了二叉树对文档进行自上而下的分析来查找表格候选区,继而根据区域特征确定最终表格区域。Pinto等人[65]则使用了条件随机场在HTML页面中抽取表格区域,并确定表格中的标题、子标题等内容。Silva等人[66]使用隐马尔可夫(Hidden Markov Models,HMMs)抽取表格区域。Chen等人[67]在手写文档中检索表格区域,并使用支持向量机识别其中的文字区域,随后依据文本行确定表格所在位置。Kasar等人[68]同样使用了支持向量机技术,首先识别图中水平和竖直的垂直线,随后使用支持向量机对每条线的属性进行分类,判断该线条是否属于表格。Barlas等人[69]使用多层感知机对文档中的Connected Components进行分类,判断其是否为文本。Bansal等人[70]使用leptonica库[71]对文档进行分割,随后对每一个区域构造包含周围环境信息的特征。使用Fixed-point Model[72]对每一个区域进行分类,用以识别文档中的表格区域。它使得模型在分类过程中不再孤立地对区域进行分类,而是学习区域相互之间的关系。Rashid等人[73]采用了与前一份工作相同的思路,但将操作粒度缩小为单词级别,对每一个词进行分类,之后使用AutoMLP来判断该词是否属于表格。
4 基于深度学习的文档智能技术
近年来,深度学习方法已经成为许多机器学习问题的解决范式。在众多研究领域,深度学习方法被证明是十分有效的。最近,预训练模型的流行也进一步发掘了深度神经网络的性能。而文档智能领域的发展也体现出同样的趋势。本节中我们将现存的模型分为针对特定任务的深度学习模型和支持多种下游任务的通用预训练模型进行介绍。
4.1 针对特定任务的深度学习模型
4.1.1 文档版面分析
文档版面分析包含两个主要的子任务: 文档视觉结构分析和文档语义结构分析[74]。文档视觉分析的主要目的是检测文档结构并确定其同类区域的边界。而文档语义结构分析是需要为这些检测到的区域标记具体的文档类别,如标题、段落、表格等。PubLayNet[10]是一个大规模的文档版面分析数据集,通过自动解析PubMed的XML文件构建了超过360 000个文档图片。DocBank[13]通过arXiv网站的PDF文件和LaTeX文件的对应关系自动构建了一个可扩展的文档版面分析数据集,同时支持对基于文本的方法和基于图像的方法进行评测。IIIT-AR-13K[23]提供了13 000的人工标注的文档图片用于版面分析。
1.1节中介绍了将较为经典的卷积神经网络应用在文档版面分析领域的工作[2-8],但随着对文档版面分析的性能要求逐渐提高,越来越多的科研工作针对文档这一领域对目标检测算法进行了针对性的改进。Yang等人[7]将文档语义结构分析任务视为一个逐像素的分类问题。他们提出了一个同时考虑视觉和文本信息的多模态神经网络。Viana等人[75]提出了一个用于移动和云服务的文档布局分析的轻量级模型。该模型使用图像的一维信息进行推理,并与使用二维信息的模型进行比较,在实验中取得了较高的准确性。Chen等人[76]介绍了一种基于卷积神经网络(CNN)的手写历史文件图像的页面分割方法。Oliveira等人[77]提出了一个基于CNN的多任务逐像素预测模型。Wick等人[78]提出了一个用于历史文件分割的高性能全卷积神经网络(FCN)。Grüning等人[79]提出了一种针对历史文献的两阶段文本行检测方法。Soto等人[80]将上下文信息纳入Faster R-CNN模型。该模型利用文章元素内容的局部不变性质,提高了区域检测性能。
4.1.2 表格检测与表格结构识别
在文档版面分析中,表格理解是一项富有挑战性的任务。与标题、段落等文档元素相比,表格的格式通常较为多变,结构也较为复杂。因此,有大量的相关工作围绕表格展开,其中最为主要的两个子任务分别是表格检测和表格结构识别。表格检测是指确定文档中的表格的边界;表格结构识别是指将表格的语义结构,包括行、列、单元格的信息按照预定义的格式抽取出来。
近年来,有许多针对表格理解这一任务提出的数据集。UNLV[18]和Marmot[19]是较早的表格识别数据集。ICDAR会议在表格检测与识别上举办的多次竞赛提供了优质的表格数据集[9,16]。但这些传统表格数据集通常较小,难以发挥现代深度神经网络的优势,因此研究工作TableBank[12]利用LaTex和Office Word来自动构建了一个大规模的表格理解数据集。此后,PubTabNet[11]提出了一个大规模表格数据集并提供了表格结构及单元格内容辅助表格识别。TNCR[20]在提供表格标注的同时提供了表格类别的标注。
针对表格理解这一任务的特性,许多目标检测方法在表格理解领域都能取得较好的效果。Faster R-CNN[3]在表格检测任务上直接应用就能取得非常好的性能。在此基础上,Siddiqui等人[81]通过将可变形卷积应用在Faster R-CNN上获得了更好的性能。CascadeTabNet[82]使用了Cascade R-CNN[83]模型同时完成表格检测和表格结构识别。Table-Sense[84]通过增加单元格特征、添加采样算法来显著提高表格检测能力。
除了上述两个主要的子任务,针对已解析后表格的理解也逐渐成为新的挑战。TaPas[85]是较早的将预训练技术引入表格理解任务的模型。通过引入额外的位置编码层,TaPas可以使Transformer[1]编码器接受结构化的表格输入。经过在大量的表格数据上进行掩码式预训练后,TaPas在多种下游语义分析任务中显著超过了传统方法。继TAPAS后,TUTA模型[86]引入了二维坐标树来表示结构化表格的层级信息,并针对这一结构提出了基于树结构的位置表示方式和注意力机制来显示建模层次化表格。结合不同层级的预训练任务,TUTA在多个下游数据集上取得了进一步的性能提升。
4.1.3 文档信息抽取
文档信息抽取是指从大量非结构化富文本文档内容中抽取语义实体及其之间关系的技术。文档信息抽取任务,文档类别不同,抽取的目标实体也不尽相同。FUNSD[26]是一个文档理解数据集,其包含199张表单,每张表单中包含表单实体的键值对。CORD[28]是一个票据理解数据集,并包含8个大类共54小类种实体标签。Kleister[32]是一个针对长文档实体抽取任务的文档理解数据集,包含有协议和财务报表等长文本文档。DeepForm数据集[31]是一个针对电视和有线电视政治广告披露表格的英文数据集。EATEN数据集[29]是针对中文证件的信息抽取数据集, Yu等人[87]在其400张子集上进一步添加了文本框标注。EPHOIE[30]数据集是一个针对中文文档数据的信息抽取数据集。XFUND[33]是随着LayoutXLM模型提出的针对FUNSD数据集的多语言扩展版本,包含有除英文以外的七种主流语言的富文本文档。
由于富文本文档具有丰富的视觉信息,所以很多研究工作将文档信息抽取任务建模为计算机视觉任务,通过语义分割或文本框回归等任务进行信息抽取。考虑到文档信息抽取中文本信息同样具有重要作用,通常的框架是将文档图片视为像素网格,并在该特征图上添加文本特征来获得更好的特征表示。根据添加文本特征级别的不同,这一方法的基本发展顺序呈现出了从字符级别到单词级别再到上下文级别的趋势。Chargrid模型[88]利用一个基于卷积的编码器-解码器网络,通过将字符进行Onehot编码来将文本信息融合到图像中。VisualWordGrid模型[89]实现了Wordgrid,通过将字符级文本信息换成单词级的Word2Vec特征,并融合了一定的视觉信息,提高了抽取任务的性能。BERTgrid模型[90]通过使用BERT获得了上下文文本表示,进一步提升了性能。ViBERTgrid模型[91]在BERTgrid的基础上将BERT的文本特征较早地在卷积阶段与图像特征进行融合,从而获得了较好的效果。
由于富文本文档中的信息仍以文本作为主体,很多研究工作将文档信息抽取任务作为特殊的自然语言理解任务。Majumder等人[92]根据抽取目标的类别来生成目标备选,在表单任务上取得了较好的效果。TRIE模型[93]联合文本检测识别与信息抽取,让两个阶段的任务互相促进,从而获得更好的信息抽取效果。Wang等人[94]通过三种不同模态信息的融合来预测文本片段之间的关系,实现了对表单的层次化抽取。
非结构化的富文本文档由多个邻接的文本片段组成,所以通常使用图网络对非结构化富文本文档进行表示。文档中的文本片段建模为图中的节点,而文本片段之间的关系则可建模为边,这样整个文档就可以被表示为一个图网络。在1.2节中,我们介绍了图神经网络在富文本文档中进行信息抽取的代表性工作[14]。在此基础上,逐渐有更多的研究工作基于图神经网络展开。Wang等人[95]将文档建模为有向图,通过依存分析的方法对文档进行信息抽取。Riba等人[96]使用基于图神经网络的模型来进行发票中表格的信息抽取。Wei等人[97]通过在预训练模型的输出表示上使用图卷积神经网络来建模文本布局,提高了信息抽取的性能。Cheng等人[98]通过将文档表示为图结构并使用基于图的注意力机制,结合CRF在小样本学习上取得了较好的性能。PICK模型[87]通过引入一个可基于节点进行学习的图来表示文档,在发票抽取任务中取得了较好的性能。
4.1.4 文档图像分类
文档图像分类是指对文档图像进行归类标记的任务。RVL-CDIP[39]是该任务中的代表性数据集。该数据集包含16个文档图像类别共400 000张灰度图片。Tabacco-3482[38]选取了RVL-CDIP的一个子集进行评测,共包含3 482张文档灰度图片。
由于文档图像分类仍然属于图像分类的范畴,所以针对自然图片的分类算法同样能较好地解决文档图像分类的问题。Afzal等人[99]介绍了一种基于深度卷积神经网络(CNN)的文档图像分类方法来进行文档图像分类。为了克服小数据集样本不足的问题,他们使用了经过ImageNet训练的Alexnet网络进行初始化,从而迁移到文档图像领域。Afzal等人[100]尝试将GoogLeNet、VGG、ResNet等在自然图片领域获得成功的模型通过迁移学习的方式在文档图片上进行训练。Tensmeyer等人[101]通过对模型参数和数据处理的调整,使CNN模型不借助从自然图片的迁移学习就能获得优于此前模型的性能。Das等人[102]提出了一个基于不同区域分类的深度卷积神经网络框架用于文档图像分类。该方法通过对文档的不同区域分别进行分类,最终融合多个不同区域的分类器在文档图像分类上获得了明显的性能提升。Sarkhel等人[103]通过引入金字塔形的多尺度结构来抽取不同层级的特征。Dauphinee等人[104]通过对文档图片进行字符识别(OCR)获得文档的文本,并对图像特征和文本特征进行组合,进一步提升了分类性能。
4.1.5 文档视觉问答
文档视觉问答是一个针对文档图片的高层理解任务。具体来说,给定一张文档图片和一个有针对性的问题,模型需要根据图片给出该问题的正确答案。具体的例子如图5所示。针对文档的视觉问答工作最早出现在数据集DocVQA[34]中,该数据集包含了超过12 000个文档和对应的5 000个问题。后来,出现了针对文档中图表的视觉问答工作InfographicVQA[35]。针对DocVQA数据集的答案较短、文档主题较单一的缺陷,有研究人员提出了VisualMRC[36]数据集。除了文档图片,针对网页视觉问答的WebSRC[37]数据集也受到了广泛关注。

图5 文档视觉问答任务示例来自于DocVQA和VisualMRC数据集
不同于传统VQA任务,文档视觉问答中的文档文本对任务具有关键作用, 所以现存的代表性方法都将文档图片进行字符识别(OCR)处理得到的文档文本作为重要的信息。在得到文档文本后,针对不同数据的特点, 视觉问答任务被建模为不同的问题。对于DocVQA数据来说,绝大部分的问题答案都是作为文本片段存在于文档文本中的,所以主流的方法都将其建模为了机器阅读理解问题(Machine Reading Comprehension, MRC)。通过为模型提供视觉特征和文档文本,模型根据问题在给定的文档文本上进行文本片段的抽取来作为问题答案。而对于VisualMRC数据集,问题的答案通常不蕴含在文档文本片段中,需要给出较长的抽象回答,因此在这种情况下,可行的方法是使用文本生成式的方法生成问题的答案。
4.2 支持多种下游任务的通用预训练模型
以上针对特定任务的深度学习方法,在针对特定文档理解任务上能够取得较好的性能,然而这些方法主要面临两个限制: ①这些模型通常依赖于有限的标记数据,而忽视了挖掘大量无标注数据中的知识。对于文档理解任务,尤其是其中的信息抽取任务来说,详细标注的数据是昂贵且消耗时间的。另一方面,富文本文档在现实生活中大量使用,因而存在着大量的未标注文档,而这些大量的未标注数据可以使用自监督预训练加以利用。②富文本文档不仅有大量的文本信息,同时也包含丰富的版面和视觉信息。已有的针对特定任务的模型由于数据量的限制,通常只能通过预训练的CV模型或NLP模型来获取对应模态的特征,而且大部分工作只利用单一模态的信息或者两种特征的简单组合,而不是深度交互。Transformer[1]在迁移学习领域的成功证明了深度上下文化(Contextualizing)对于序列建模的重要性,因此将文本和其他模态进行深度交互融合是一个较为明显的趋势。
富文本文档主要包含三种模态信息: 文本、布局以及视觉信息,并且这三种模态在富文本文档中有天然的对齐特性。因此,如何对文档进行建模并且通过训练达到跨模态对齐是一个重要的问题。LayoutLM[15]以及后续提出的LayoutLMv2[105]模型的提出正是针对这一方向进行的研究工作。在1.3节中,我们详细介绍了LayoutLM这一通用文档理解预训练模型,通过将文本和布局进行联合预训练,LayoutLM在多种文档理解任务上取得了显著的性能提升。在此基础上,又有许多后续的研究工作对这一框架进行了针对性的改进。LayoutLM在预训练过程中没有引入文档视觉信息,从而在DocVQA这类需要较强视觉感知能力的任务上效果欠佳。对此,LayoutLMv2[105]通过将视觉特征信息融入预训练过程中,明显提高了模型的图像理解能力。具体来说,在结构方面,LayoutLMv2引入了空间感知自注意力机制,并将视觉特征作为输入序列的一部分。在预训练目标方面,LayoutLMv2在掩码视觉语言模型(Masked Visual-Language Model)之外又提出了文本-图像对齐(Text-Image Alignment)和文本-图像匹配(Text-Image Match)任务。通过在这两方面的改进,模型对于视觉信息的感知能力大大提高,并在包括DocVQA在内的六种下游任务中获得了显著性能提升。
LayoutLM提出之后,许多研究工作针对这一框架进行了针对性的改进,其中针对位置表达方式的改进是一个主要方向。许多工作将Embedding表示的位置编码改为了正余弦方式,其中有代表性的是BROS[106]和StructuralLM[107]。BROS[106]在绝对位置编码中使用了正弦函数,同时又在自注意力机制中通过正弦函数引入了文本相对位置信息,提高了模型对空间位置的感知能力。StructuralLM[107]在绝对位置表示方式上通过在文本块内共享相同的位置信息,帮助模型理解同一文本实体内的文本信息,从而对信息抽取任务有进一步的帮助。
除了对位置布局信息这一模态的改进之外,很多研究工作针对图像信息做了进一步的改进。LayoutLMv2的图像输入分辨率较低,这在某种程度上限制了模型对视觉信息的进一步挖掘。为此,许多研究工作针对视觉这一模态进行了优化和加强。LAMPRET[108]通过为模型提供更多的视觉模态信息如字体、字号、插图等,对网页文档进行建模,帮助模型对丰富的网页数据进行建模和理解。SelfDoc[109]采用了双流(Two-Stream)结构,针对给定的富文本文档数据,首先使用预先训练好的文档实体检测模型,通过目标检测将文档中所有的语义单元识别出来,然后使用OCR对识别的区域进行光学字符识别。针对识别出的图像区域和文本序列,模型分别使用了Sentence-BERT[110]和Faster-RCNN[3]进行了特征抽取,编码为特征向量,并使用一个跨模态的编码器进行编码,最终获得了多模态的表示来服务于下游任务。DocFormer[111]采用分离式多模态结构(Discrete Multi-Modal),在每层使用位置信息分别结合文本和图像模态使用自注意力机制。DocFormer首先使用ResNet对图像信息进行编码获得较高分辨率的图像特征,同时将文本信息以嵌入(Embedding)的形式编码为文本特征向量。位置信息向量分别与图像和文本信息相加,并单独传入Transformer层,每层分别编码之后重新相加。在这种机制下,不仅获取了高清图像信息,减小了输入序列,而且不同模态通过位置信息进行了对齐,使模型更好地建模了富文本文档的模态对齐关系。
许多模型在模态信息表示之外,又针对不同的模态设计了更丰富的预训练任务。例如,BROS[106]除了掩码式视觉语言模型(MVLM)之外,提出了基于区域的掩码式语言模型(Area-masked Language Modeling)。基于区域的掩码会对一个随机选择的区域内的所有文本块进行掩码操作。其可以被解释为将SpanBERT[112]中的针对一维文本的区间掩码操作扩展为二维空间中文本块的区间掩码。具体来说,该操作由以下四个步骤组成: ①随机选择一个文本块,②通过扩大文本块的区域来确定一个最终区域,③确定属于该区域的文本块,④对文本块的所有文本进行掩码并预测它们。LAMPRET[108]额外引入的网页实体顺序排序任务,让模型通过对实体排布顺序的预测来学习空间位置进行预测。与此同时,模型还利用了图像匹配预训练任务,通过去除网页中的图像,并通过检索的方式进行匹配,提高了模型对多模态数据的语义理解能力。StructuralLM[107]提出的单元位置分类任务是对文档中文本块的相对空间位置进行建模。给定一组扫描的文件,该任务旨在预测文件中文本块的位置。首先,富文本文档被分成N个相同大小的区域。然后,模型通过文本块的中心二维位置,计算出该文本块所属的区域。这一研究工作较早地提出了针对位置信息进行掩码预测式学习。SelfDoc[109]和DocFormer[111]针对图像这一模态优化加强了输入的同时,也引入了对应的预训练任务,SelfDoc针对图像特征进行了掩码并预测,从而帮助模型学习建模视觉信息。DocFormer引入了一个解码器来对图像信息进行重建。在这种情况下,这项任务类似于自动编码器的图像重建,但又包含了文本和位置等多模态特征。在有图像和文本特征的情况下,图像重建需要两种模式的协作,加强了不同模态之间的交互。
在模型初始化方面,许多模型利用已有的更加强大的预训练语言模型进一步提高性能,同时也可以拓展模型的能力。例如,LAMBERT[113]通过使用RoBERTa[114]作为预训练初始化获得了更好的性能。除了语言理解之外,很多模型着眼于扩展模型的语言生成能力。它们的一个共同特点是都使用了编码-解码(Encoder-Decoder)范式。TILT[115]通过将Layout编码层引入T5[116]模型并结合文档数据预训练,使模型能够处理文档领域的生成任务。LayoutT5和LayoutBART[36]在文档视觉问答任务微调阶段在T5和BART[117]模型的基础上引入文本位置编码,来帮助模型理解并生成问题答案。
这些模型虽然在英文数据上取得了成功,但对于非英语世界来说文档理解任务同样重要。LayoutXLM[33]最早在多语言富文本文档上进行多语言预训练的研究工作。LayoutXLM基于LayoutLMv2的模型结构,通过使用53种语言进行预训练,扩展了LayoutLM的语言支持。与此同时,相比于纯文本的跨语言模型,LayoutXLM在迁移能力上具有明显优势,这证明了不仅多语言文本之间可以进行跨语言学习,而且多语言富文本文档之间也可以进行文档布局的迁移学习。
富文本文档通常可分为两类: 第一类是固定布局的文件,如扫描的文档图像和数字原生的PDF文件,其布局和风格信息是预先渲染的,与软件、硬件或操作系统无关。这一特性使得现有的基于布局的预训练方法(LayoutLM)很容易适用于文档理解任务。第二类是基于标记语言的文档,如HTML/XML等,其布局和风格信息需要根据软件、硬件或操作系统进行交互和动态渲染以实现可视化。对基于标记语言的文档,二维布局信息并不以明确的格式存在,而是通常需要针对不同的设备动态呈现,例如移动/桌面/台式机,这使得目前基于布局的预训练模型难以应用。为此,MarkupLM[118]在一个单一的框架中联合预训练文本和标记语言,用于基于标记语言的文档理解任务。 与固定布局的文档不同,MarkupLM为通过标记结构进行的文档表示学习提供了另一种视角,因为在预训练中不能直接使用二维位置信息和文档图像信息,而MarkupLM利用基于树形的标记结构来模拟文档中不同单元之间的关系,提高了标记语言文档理解问题的准确性。
除了通用多模态预训练模型之外,基于ViT视觉Transformer[119-126]的图像预训练技术近来取得了很大进展,研究人员通过有监督预训练方法或者自监督预训练等技术将视觉Transformer模型应用到图像分类、物体识别、场景分割等领域,取得了显著的进展。受自监督预训练视觉Transformer模型BEiT[123]的启发,Li等提出一种自监督文档图像Transformer模型DiT[127],通过利用海量无标注文档图像数据进行大规模自监督预训练,在文档图像分类、文档版面分析、表格检测等任务均取得了最佳的结果。与自然图像理解领域不同,由于文档图像理解的研究并不存在类似于ImageNet这样的大规模人工标注数据集,因此无须人工标注数据的自监督预训练技术在文档智能领域将发挥越来越重要的作用。
5 未来发展方向
商业文档的自动阅读和分析具有明显的应用价值,是自然语言处理和计算机视觉交叉领域的一个重要研究方向。因此我们分别从自然语言处理、计算机视觉以及多模态融合的角度来梳理一下文档智能的未来发展方向。
从自然语言处理的角度出发,近年来以BERT[128]为代表的大规模自监督预训练成为自然语言处理的主流研究方向。与此同时,在大规模预训练模型基础上,以GPT-3[129]为代表的提示学习(Prompt Learning)研究方法;为文本预训练模型的应用给出一种新型的范式,能够达到低计算量与性能调优的平衡,受到了广泛关注。GPT-3通过上下文学习(In-context Learning)的方法在零样本(Zero-shot)和少样本(Few-shot)学习中展现出与BERT完全不同的结论和性能,因此应该探究在文档智能领域大模型的性质,以及如何利用大模型进行文档智能下游任务的微调,例如Parameter-efficient相关的方法也是非常重要的。
文档智能中有大量以文档图片为载体的信息抽取和问答任务,如表单/发票理解等。由于这些任务所需的数据,人工标注代价很高,对自监督预训练模型有很强的需求。除此之外,如何降低模型参数微调(Fine-tuning)计算量也是这些任务亟待解决的问题,因此文档图像的提示学习技术也是未来十分重要的一个研究方向。
从计算机视觉的角度出发,以ViT视觉Transformer[119]为代表的大规模预训练技术近年来也成为计算机视觉的主流研究方向。由于文档图像理解领域不存在类似ImageNet这种大规模人工标注数据集,但无标注的文档图像却大量存在,因此自监督文档图像预训练模型对于文档智能领域的发展至关重要。文档智能领域中图像理解任务大多与版面分析相关,如光学字符识别(OCR)、文档对象识别,特别是表格识别等。传统的研究方法通常依赖任务相关的标注数据来解决,相信随着视觉自监督预训练模型的发展和成熟,对于标注数据的依赖会越来越小。
作为自然语言处理和计算机视觉的交叉领域,文档智能更多地应用了多模态融合技术。以LayoutLM[15]为代表的多模态文档智能预训练模型成为文档智能的主流研究方向。当前多模态融合主要采用将不同模态的信息通过跨模态对齐任务进行联合学习和预训练,取得了不错的效果。文档智能领域中的多数任务都会同时利用文本信息和图像信息,因此如何挖掘文本与图像之间的关联成为文档智能理解的重要任务。与此同时,不同模态之间的互补性也将决定文档智能任务的精确度和可扩展性。
展望未来,除了解决文档多页跨页、训练数据质量参差不齐、多任务关联性较弱以及少样本零样本学习等问题,还应该特别关注文字检测识别OCR技术与文档智能技术的结合,因为文档智能下游任务的输入通常来自于自动文字检测和识别算法,文字识别的准确性往往对于下游任务有很大的影响。此外,如何将文档智能技术与现有人类知识以及人工处理文档的技巧相结合,也是未来值得探索的一个研究课题。
6 结语
信息处理是数字化转型的基础和前提,如今对处理能力、处理速度和处理精度也都有越来越高的要求。以商业领域为例,电子商业文档就涵盖了采购单据、行业报告、商务邮件、销售合同、雇佣协议、商业发票、个人简历等大量繁杂的信息。机器人流程自动化(Robotic Process Automation,RPA)行业正是在这一背景下应运而生,其利用人工智能技术帮助大量人工从繁杂的电子文档处理任务中解脱出来,并通过一系列配套的自动化工具提升生产力,RPA的关键核心之一就是文档智能分析技术。过去的20年间,文档智能分析技术主要经历了三个阶段,从最初的基于启发式规则,过渡到基于统计机器学习的方法,到近来基于深度学习的方法,极大地提升了分析性能和准确率。与此同时我们也观察到,以LayoutLM为代表的大规模自监督通用文档智能预训练模型也越来越多地受到人们的关注和使用,逐步成为构建更为复杂算法的基本单元,后续研究工作也层出不穷,促使文档智能领域加速发展。
