基于细粒度关键词引用网络的领域知识多维分析
2022-07-30王佳敏程齐凯秦春秀
王佳敏,陆 伟,程齐凯,秦春秀
(1. 西安电子科技大学经济与管理学院,西安 710126;2. 武汉大学信息管理学院,武汉 430072;3. 武汉大学信息检索与知识挖掘研究所,武汉 430072)
1 引 言
对领域知识及其关联关系进行多维度分析,有助于发现和把握科学知识发展变化的特征和规律[1-2]。以往研究多根据学术文献的不同粒度和不同关系构建多种类型知识网络,如引文网络、合著网络、关键词网络等,在此基础上从科学知识图谱绘制[1]、话题演变[2]、网络社区发现[3]、实体关联[4]等角度对领域知识及其关系进行可视化呈现和分析。然而,随着科学出版物数量的急剧增长,从科学文章中理解某一领域的知识结构和概念之间的关系仍然是一项非常具有挑战性的任务[5]。其中一个重要的原因便是传统知识网络对领域知识的表示和揭示是粗粒度的,缺少相应的语义支撑[6]。在这种背景下,如何对领域知识进行细粒度、语义化的分析已经成为情报学领域亟待解决的关键问题之一[7-8]。
随着分析粒度的不断细化,文章层面的引用关系逐渐扩展到实体引用或关键词引用,并产生了各种细粒度的引用网络,如生物实体引用网络[9]、基因-引用-基因网络[10]、词汇耦合网络[11]以及关键词引用网络[12]等,在领域知识多维分析中得到了较快的发展。然而,当前基于关键词的引用网络大多将网络中的节点简化为单一的符号化表达,认为其在整个学科领域内的含义是固定的。实际上,关键词在不同的文献或文本语境中有其特定的角色,例如,关键词“deep learning”(深度学习) 在文献[13]中代表研究问题,而在文献[14]中则代表研究方法。此外,当前关键词引用网络在节点间的关系上也比较单一,忽略了关键词之间关联关系的多样化。例如,关键词“LDA”分别被“HLDA”和“topic analysis”引用,如果不作区分,那么它们之间的关系是等同的,即都是基于引用的关系;实际上,“LDA”可能基于对比关系被“HLDA”引用,而基于使用关系被“topic analysis”引用。因此,识别科技论文关键词的语义角色并对节点之间的关联关系进行细粒度区分,对领域知识网络的构建至关重要,将为相关分析和应用提供更精准的度量[15]。
词汇功能,是指词汇在学术文本中所承担的语义角色[16],科技文献中词汇功能通常包括目标、关键方法、焦点、技术、研究主题、数据集或领域实体等[17-20]。引用功能体现了参考文献在施引文献中的作用,通常包含背景、使用、扩展和对比等类别[21-23]。词汇功能和引用功能为关键词引用网络中节点及节点间关联的语义识别提供了一条现实可行的途径。因此,本研究将通过词汇功能和引文功能来增强关键词引用网络的语义信息,生成一种语义功能敏感的细粒度关键词引用网络。在此基础上,从引用功能敏感的子网分析、特定节点的多维关联分析和细粒度领域知识演化分析三个方面进行领域知识多维分析,以发现和把握科学知识发展变化的特征和规律,为领域知识分析提供一种新的视角和方法。
本研究的创新点为:第一,通过词汇功能增强了关键词引用网络中节点的语义信息,通过引用功能对关键词间关联关系进行了细粒度区分,在此基础上构建了细粒度关键词引用网络,不仅丰富和扩展了知识网络的理论和方法体系,也推动了学术文本语义功能与知识网络的融合;第二,基于构建的细粒度关键词引用网络进行领域知识多维分析,改变了以往知识网络在实际应用中存在的分析维度单一、粒度较粗、可解释性较差等问题,为领域知识分析和应用提供了新的视角和路径。
2 相关研究
2.1 学术文献细粒度引用网络
尽管许多研究试图通过引文网络的方法揭示领域知识发展变化情况,但大多基于学术文献及文献外部实体单元,如文章、作者、期刊等,无法深入到文本内容特征层面。为了揭示施引文献和被引文献在内容上的直接关联,部分学者对细粒度引用网络进行了探索。
Ding 等[9]提出实体既可以是评价实体(如论文、作者、期刊),也可以是知识实体(如关键词、主题、关键方法、领域实体),并将引文网络从论文引用扩展到实体引用,构建了生物实体引用网络。Song 等[10]基于实体计量模型构建了医学学术文本中的基因-引用-基因(gene-citation-gene,GCG) 网络,并证明其在检测隐含的基因相互作用方面是有效的。黄文彬等[24]提出关键词共引分析方法(key‐word co-citation analysis,KCA),若分别包含有关键词A 和B 的两篇文献被另一篇文献同时引用,则称作关键词A 和B 被共引,两个关键词被共引体现了这两个词在主题或内容上有一定的关系。受此启发,Hsiao 等[11]构建了词汇耦合(word bibliographic coupling,WBC)网络,描述了LIS(library and in‐formation science) 各子领域的最新发展和研究趋势。Cheng 等[12]提出关键词-引用-关键词网络(key‐word-citation-keyword,KCK),以ACM (Associa‐tion for Computing Machinery)数据集为例进行了学科知识结构分析。程齐凯等[25]基于引用共词网络从学术文献中发现领域基础词汇,为把握学科知识结构和发展脉络提供了支持。
综上,引用网络的分析单元已逐渐从文章层面扩展到关键词或实体层面,细粒度的引用网络已被证明能有效地进行领域知识分析。本研究通过区分关键词引用网络中的节点和关联关系的语义角色,进一步丰富关键词引用网络研究的方法体系,并通过细粒度引用网络来进行领域知识的多维分析。
2.2 领域知识多维语义分析
知识网络能够直观地对领域知识及其关系进行可视化呈现和分析,揭示知识之间的关联情况、主题结构、发展脉络、演化态势等。但传统的知识网络忽视了知识节点和知识关联丰富的语义信息。因此,部分学者开始探索细粒度、语义化、多维度的领域知识分析方法。
刘臣等[26]将本体理论引入社会网络分析,构建语义社会网络,网络的节点和边都具有特定的语义,并在一个科研合作网络实例上对重要节点和重要隐含关系进行了关联分析。王忠义等[6]提出了一种细粒度语义共词分析方法,借助关联数据将文献信息结构化、细粒度化、语义关联化,采用RDF(resource description framework)三元组描述各实体及其之间的关系,以揭示关键词之间的语义关系。张晗等[27]借助SemRep 对文本主题概念进行了规范化抽取,并识别了共现概念之间的细粒度语义关系,在此基础上构建了医学文献语义共词知识网。吴蕾等[8]将科技论文关键词细分为研究对象、实验品种、研究用途和技术方法4 类,并构建了4 层关键词子网和多种关联超边组成的超网络模型,有效发现了领域常用的知识以及技术空白点等。陈翔等[28]基于word2vec 得到关键词的多重语义信息,结合时间段划分构建了动态语义网络进行主题演化路径识别研究。周萌等[7]以武器装备简氏文本为数据源,确立武器装备细粒度共现关系类型和相应的特征词,构建具有多种类型边的武器装备细粒度共现网络,全面、具体地揭示了该领域的整体、微观知识结构和知识演化情况。章成志等[4]以NLP(natu‐ral language processing)领域为例,将论文中的知识实体细分为4 种类型,结合Apriori 算法和复杂网络方法对实体间的关联关系进行了挖掘,揭示了该领域知识实体的使用及应用情况。Ma 等[29]人工编码了3422 篇文章中的研究主题和方法,以分析图书情报学领域中研究主题和方法的演化和转变。孙震等[30]提出了一种基于知识元迁移的ESI(Essential Science Indicators)研究前沿知识演进分析方法,通过对知识元迁移进行定量分析和迁移程度计算,从语义分析和知识计算的角度探索了研究前沿的演进机理。此外,还有部分学者从单独某个知识元的视角,如研究问题[31]、研究方法[32]等出发对领域知识的使用和演变情况进行量化分析。
上述研究从不同角度对领域知识进行了多维度分析,丰富了领域知识研究的范畴,深化了知识网络的应用途径。但总体来看,该类研究依然将知识节点抽象为单一的符号化表达,鲜有发现从知识节点本身语义功能的细粒度和节点之间语义关联类型的多样性角度出发进行领域知识多维分析的研究。
3 研究方法
本文以国际计算语言学协会(Association for Computational Linguistics,ACL)会议论文集为数据源,对原始文献进行解析,抽取文献关键词、文献间引用关系、引文上下文以及引用对象等信息,采用人工的方式进行词汇功能识别和引用功能识别。在此基础上,采用复杂网络图方法构建细粒度关键词引用网络,并从引用功能敏感的子网分析、特定节点的多维关联分析和细粒度领域知识演化分析三个方面进行领域知识多维分析和可视化呈现,整体研究方法框架如图1 所示。
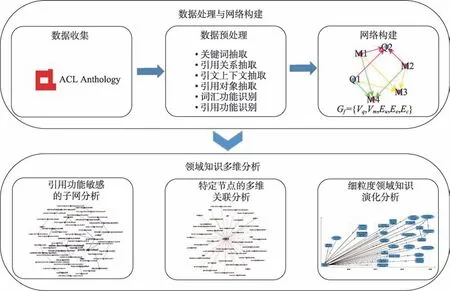
图1 整体研究方法框架
3.1 数据收集
本研究使用的数据来自ACL 会议论文集,该协会是计算语言学(computational linguistics,CL)和自然语言处理(NLP)领域重要的国际学术组织。之所以选择ACL 会议论文集,一方面,是因为该数据集是目前相对较为完整且支持全文开放获取的一个领域数据集,被诸多NLP 相关研究选作数据来源[33-34];另一方面,该数据集代表了国际NLP 领域最高水准,通过对该领域的知识进行多维分析,有助于研究人员更全面、深刻地了解该领域知识发展及其脉络情况。
本研究收集了ACL 成立以来的41109 篇PDF 格式全文文献,时间跨度为1979—2019 年,图2 展示了各年份论文数量分布情况,论文数量整体呈现随年份逐渐增长的趋势。为了便于计算机处理,本研究采用GROBID 工具[35]将PDF 格式文献转换成XML 格式。该工具基于机器学习技术开发,在PDF格式科技文献的数据提取、解析和格式转化方面能达到较好的效果,尤其在引文上下文的解析方面,F1 值达到75%,为本研究中引文关系识别和引文上下文抽取奠定了基础。接着,通过自编Java 程序对转换后的XML 格式文献进行解析和抽取,将文献的标题、摘要、句子和引文等相关字段通过本地MySQL 数据库进行存储。
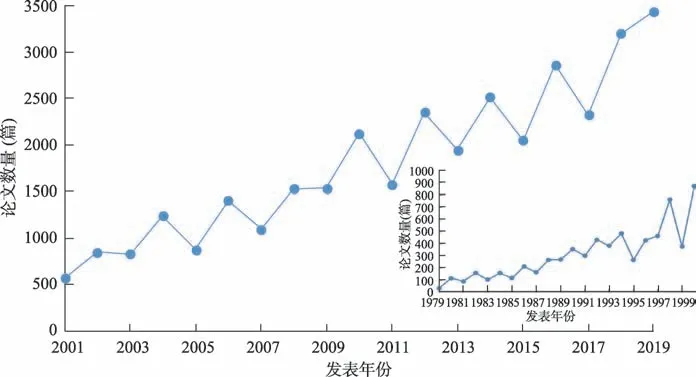
图2 ACL论文发表数量随年份分布情况
3.2 数据预处理
本研究首先通过所有的参考文献信息匹配出ACL 数据集内部的被引文献,共得到19241 篇文献,接着将这些文献在ACL 数据集中的引文上下文抽取出来,共得到引文上下文记录231930 条。本研究的引文上下文为引文标记所在句及其前一句和后一句,若前后都是引文句,则只选择引文标记当前句。通过调研现有文献关于引用功能类别的划分情况[21,36],结合NLP 领域的研究特性和ACL 数据集语料的特点,本研究将引用功能划分为背景、使用、扩展和对比4 个类别,采用人工标注结合规则模板的方式对引文上下文进行功能标注,各类别的描述、示例和标注结果数量情况如表1 所示。为了检验标注结果的一致性,从原始引文上下文中随机抽取1000 条文本,由另一位情报学研究生根据规则进行单独标注,使用kappa 系数[37]对标注结果进行一致性检验,结果显示kappa 系数为0.83,达到了较高的一致性。同时为了检验标注结果质量,分别从各功能类别结果中随机采样100 条进行人工评价,整体准确率达到87%。
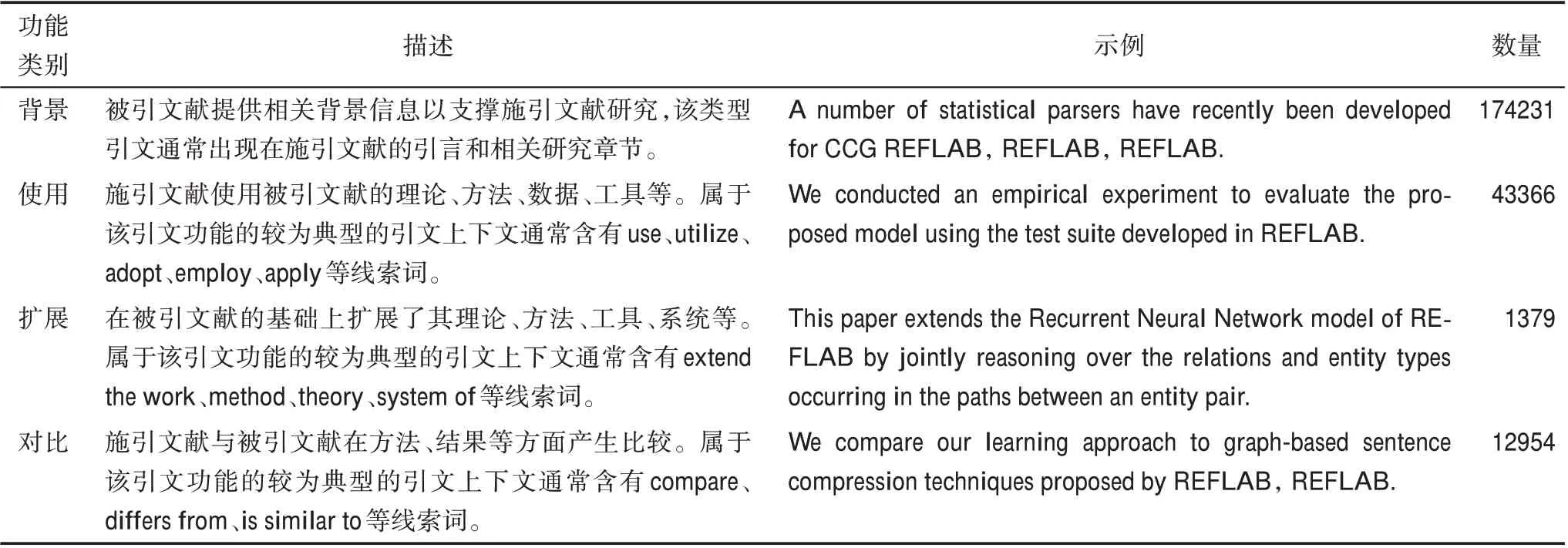
表1 引用功能数据标注结果
考虑到背景类的引文通常是对该研究背景的概述和相关研究的描述,与施引文献的直接关联程度相对较弱,因此本研究重点对使用、扩展和对比3个类别的引文句进行引用对象标注,共计57699 条引文句。通过调研现有文献关于引用对象类别的划分情况[38],结合NLP 领域的研究特性和ACL 引文集语料的特点[39],本研究将引用对象的标注体系划分为4 个类别,分别是研究问题、研究方法、数据和其他。在人工标注的过程中,本研究发现大量引文句中并不存在明显的引用对象,例如,“We compared our approach with approaches proposed by RE‐FLAB”,诸如“the method of REFLAB”“an exten‐sion of a previous approach REFLAB”等指示性描述对引用对象的研究意义不大,因此在标注过程中过滤这些不包含明显引用对象的引文句。最终得到6333 条包含已标注引用对象的引文句,各类别引用对象的描述、示例和标注结果数量如表2 所示。与引用功能标注结果的评价策略类似,对引用对象进行一致性检验,结果显示kappa 系数为0.75,整体准确率为79%,均达到了较好的水平。
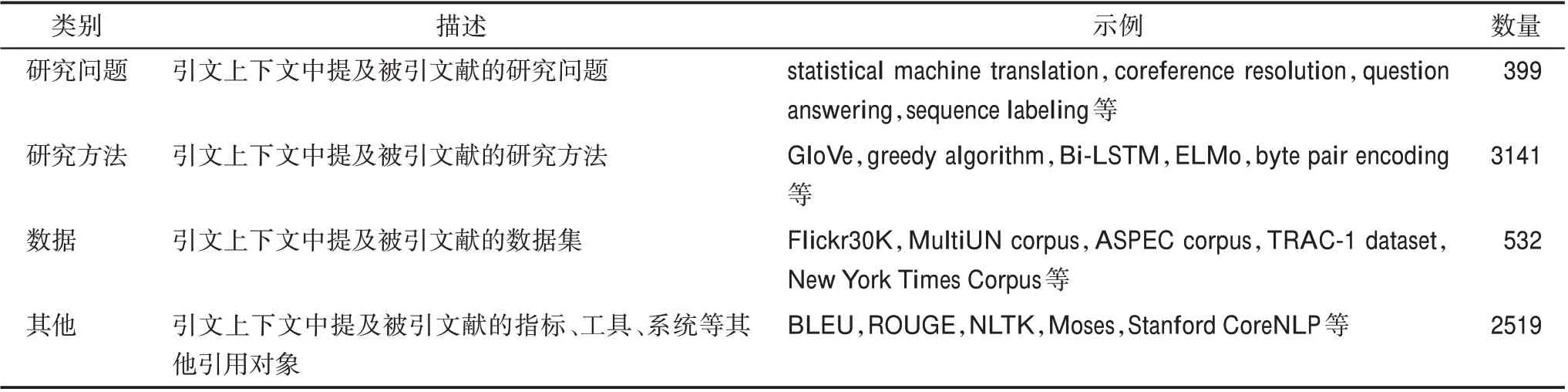
表2 引用对象标注结果
考虑到引用对象类别中的研究问题和研究方法类对引文的代表性更强,语义信息更丰富,且施引文献的关键词也大都是问题和方法类词汇,因此,本研究重点选择研究问题和研究方法类引用对象进行分析。经统计,标注为研究问题和研究方法的引文句共有3333 条(部分引文句中包含多个引用对象)。接着,通过引文关系匹配到与引用对象相对应的施引文献,共得到不重复的施引文献2265 篇。抽取出这些施引文献的标题和摘要,采用人工的方式对文献的研究问题和研究方法关键词进行标注。例如,在标题为“A New Perceptron Algorithm for Sequence Labeling with Non-local Features”的文献中,其研究问题和研究方法关键词分别标注为Se‐quence Labeling 和Perceptron Algorithm。最后,分别对标注后的文章关键词和引用对象进行大小写转换和同义词合并等操作,确保其一致性。
3.3 网络构建方法
本研究所提出的细粒度关键词引用网络,是将带语义功能的关键词和引用对象作为节点,文章间具有语义功能的引用关系作为边,构成的一种知识网络。以复杂网络形式化表述为Gf={Vq,Vm,Eu,Ee,Ec},其中Vq为研究问题节点集合,Vm为研究方法节点集合,Eu为使用功能边的集合,Ee为扩展功能边的集合,Ec为对比功能边的集合。每一条边具有相应的权重w,代表两个节点之间在某一功能类型下的引用频次。图3 展示了细粒度关键词引用网络的构建示例,该网络是一种加权有向网络,网络中不包含词汇自引关系。
图3 细粒度关键词引用网络构建示例
根据上述细粒度关键词引用网络的定义,描述其具体的构建过程:
Step1. 初始化细粒度关键词引用网络Gf={Vq,Vm,Eu,Ee,Ec},Vq、Vm、Eu、Ee、Ec均为空,文献集为P;
Step2.抽取每一篇文献Pi的关键词和引用对象,并识别其词汇功能,为每一个功能词汇赋予唯一编号并统计其频次,得到节点集合Vq和Vm;
Step3.抽取文献集P中所有文献间的引用关系和引文上下文,根据引文上下文识别其引用功能;
Step4.分别对Eu、Ee、Ec中的每一条边匹配施引文献的关键词及引用对象,构建异质边词汇引用关系对;
Step5.为每一对引用关系对赋予唯一编号,统计所有的引用关系对频次,得到边集合Eu、Ee、Ec。
Step6.输出细粒度关键词引用网络Gf。
4 实证研究
对ACL 数据集进行预处理,按照细粒度关键词引用网络的构建方法,得到的Gf由1480 个研究问题节点、2797 个研究方法节点、3118 条使用功能边、299 条扩展功能边以及2605 条对比功能边构成。接下来,本研究从引用功能敏感的子网分析、特定节点的多维关联分析以及细粒度领域知识演化分析3 个方面对NLP 领域知识进行多维分析。
4.1 引用功能敏感的子网分析
所谓引用功能敏感,就是指通过引用功能为细粒度关键词引用网络中的边赋予语义信息,实现知识节点之间关联关系的多样化表示。基于边功能划分网络,能够得到包含某一特定类型关系的子网,对各个引用功能敏感的子网进行分析,可以帮助用户有针对性地分析网络中节点的关联情况。
1)使用功能子网分析
在科技文献写作过程中,不可避免地要使用到已有的知识作为支撑,对使用功能敏感的关键词引用网络进行分析,有助于发现学科领域中知识使用的模式和特点。为此,本研究单独将使用类边抽取出来构建使用功能敏感的关键词引用网络,得到的网络由2327 个节点和3118 条边组成。考虑网络的精简性和可视化效果,按边权重阈值为5 进行过滤,得到剪枝后的网络包含34 个节点和35 条边。通过Gephi 对其进行可视化,结果如图4 所示。其中,网络节点大小与其加权中心度成正比,节点标签以0结尾的代表研究问题词汇,节点标签以1 结尾的代表研究方法词汇,箭头的方向由施引词汇指向被引词汇,表示施引文献出于使用意图引用了该引用对象。
从图4 可以看出,该子网具有两个明显的社区,一个是以GloVe (global vectors for word representa‐tion)方法为核心,多种研究问题和方法指向该节点,反映出GloVe 是NLP 领域中被广泛且频繁使用的一种研究方法;另一个是由统计机器翻译问题、最小错误率训练方法、BPE(byte pair encoding,字节对编码) 算法、神经机器翻译问题、MIRA(margin infused relaxed algorithm) 算法等关键词构成的知识群落,同样体现了该领域对机器翻译相关知识的使用和关注情况。此外,网络边缘还分布着一些独立的小网络或关联对,反映出领域知识之间的频繁使用模式,如攻击识别问题中经常使用到fastText 分类器,这种频繁使用模式为研究问题和方法的推荐提供了基础。

图4 使用功能子网
2)扩展功能子网分析
在已有领域知识基础上的扩展和创新,也是科学研究中常见的范式,对扩展功能下关键词引用网络进行分析,有助于厘清科学知识的发展变迁规律。同理,可构建扩展功能敏感的关键词引用网络,按边权重为1 对网络进行剪枝,得到的精简后的网络包含53个节点和41条边,可视化结果如图5所示。
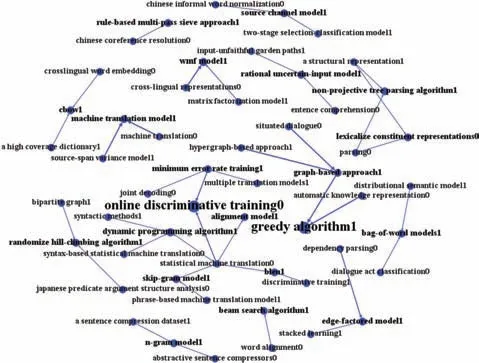
图5 扩展功能子网
从图5 可以看出,扩展功能子网以在线区分性训练问题、贪心算法、机器翻译模型、基于图的方法等关键词为核心,反映了施引文献多在这些问题或方法上进行扩展。网络整体连通性不强,社区较为分散,没有形成明显的知识聚集现象,但网络中分布的众多小网络或连接对反映出该领域存在较多小范围内的知识扩展现象,例如,在词语对齐研究中常对集束算法进行扩展,分布式语义模型和对话行为分类问题均在词袋模型基础上进行了扩展。
3)对比功能子网分析
在科学研究中,经常需要将该研究的方法、结果或结论等部分与其他研究进行对比,以突出该研究的价值和特色,对对比功能下关键词引用网络进行分析有助于挖掘领域知识之间的对比模式和特点。同样,对构建的网络按照边权重阈值为4 进行过滤,剪枝后的网络包含57 个节点和43 条边,可视化结果如图6 所示。

图6 对比功能子网
从图6 可以看出,对比功能子网以实体链接模型、Bi-LSTM(bi-directional long-short term memory)模型、LSTM(long short-term memory)模型、共指消解问题、句子对齐方法、超图模型等知识节点为核心,表明NLP 领域较为关注这些主题方面的对比情况。网络中同样分散着众多小网络或连接对,体现出NLP 领域中知识单元之间存在的多方面的对比关系,其中比较明显的有Bi-LSTM、LSTM 和seq2seq这3 个常用深度神经网络模型之间的对比。
传统关键词网络一般仅依赖引用或共现等单一化关系,相关的分析多集中在网络中类簇的划分。本研究通过对网络中边的语义功能进行细粒度标注,实现了按边类型对网络的划分;对包含某一特定功能关系的子网的分析,有助于研究人员有针对性地了解特定关系类型下的领域知识结构;还可以进一步对各功能敏感的子网进行社区划分,发现其中的知识聚集情况。
4.2 特定节点的多维关联分析
以特定节点为中心,获取与其存在多维关联的其他节点,可组成相应知识的多维关联子网络,由此可以快速方便地定位与某一个知识节点具有多种细粒度关联的研究问题或方法,进而可以系统地揭示特定研究问题的发展情况或特定方法的应用情况。本研究以统计机器翻译问题和卷积神经网络方法为例,分别从整体网络中抽取与这两个节点相关的所有节点,并保留边权重不小于2 的路径,组成的特定节点多维关联子网络分别如图7 和图8 所示。其中,边的粗细与其权重成正比,边标签1、2、3分别代表使用、扩展和对比3 种引用功能。

图7 统计机器翻译的多维关联子网络
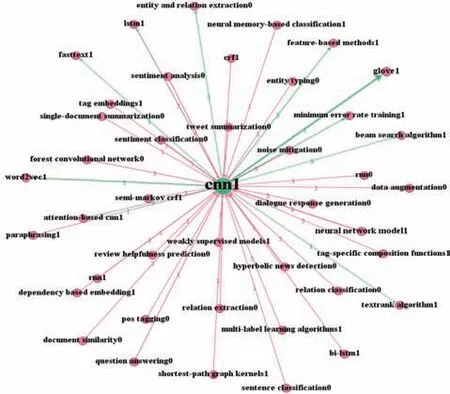
图8 卷积神经网络的多维关联子网络
从图7 可以系统地定位与统计机器翻译问题具有使用、扩展和对比关系的研究问题和方法。例如,使用关系的有最小错误率训练方法、KenLM 模型、词汇化重排序模型等,扩展关系的有在线区分性训练问题、动态规划算法、skip-gram 模型等,对比关系的有语言模型、最小错误率训练方法、L1正则化方法等。结合文献可知,最小错误率训练方法、KenLM 模型、词汇化重排序模型均是统计机器翻译问题研究中常用的算法和模型,统计机器翻译常在在线区分性训练、动态规划算法、skip-gram 模型方面进行扩展以提升翻译性能。此外,语言模型、最小错误率训练方法、L1 正则化方法等也是不同统计机器翻译研究常进行对比的内容。
同样,从图8 可以发现,与卷积神经网络具有使用关系的有GloVe 模型、神经网络模型、情感分析问题和自动问答问题等,对比关系的有循环神经网络问题/方法、神经网络模型、实体和关系抽取问题等。查阅相关文献显示,CNN(convolutional neural network)常使用GloVe 词向量模型进行文本表示,CNN 是神经网络模型中重要的组成成分,情感分析和自动问答等问题的研究也常引入CNN 作为方法之一。RNN(recurrent neural network)等神经网络模型经常将CNN 作为一个重要的对比对象,实体和关系抽取等研究中也常与CNN 模型进行对比。CNN 自提出发展至今,已经成为NLP 领域中一个受到广泛关注和应用的模型。
通过上述实例发现,在NLP 领域中知识节点之间的关联关系基本符合该领域常见的知识实体作用规律,特定节点的多维关联分析能够辅助科研人员有针对性地了解领域中某个关键问题或方法的实际情况。相比于传统关键词网络,考虑词汇功能和引用功能后,能够精确揭示特定知识在领域中与其他知识的交互功能,该结果能够提高实体推荐等研究的语义化水平。
4.3 细粒度领域知识演化分析
传统的知识演化分析多在宏观层面揭示领域主题的发展变化情况,而细粒度领域知识演化关注的是领域中功能词汇的发展脉络,客观把握领域知识发展的内在规律,明确知识发展演化过程中的关键信息,为科研人员预测领域中特定研究问题或研究方法的发展演变态势提供参考。
细粒度领域知识演化的基本思路是将时间维度引入问题-方法词汇的关联中,赋予每一个功能词汇发挥作用的时间(施引词和被引词均为对应施引文献的发表时间),在此基础上通过对不同阶段关键词及其语义关联的分析,揭示领域研究热点和预测领域未来的发展趋势。为此,我们通过原始文献的发表年份和文献间的引用关系为每一个功能词汇标记时间信息,构建带有时间属性的细粒度关键词引用网络,接着选定某一个研究问题或方法,抽取与该节点相关联的重要链路和节点信息,按照时间序列绘制细粒度领域知识演化图。
语言模型(language model)是NLP 领域一种基础且重要的算法,为了探寻该研究方法在领域中与其他方法和问题的交互演化情况,本研究以语言模型这一研究方法为例绘制其细粒度演化路径图。在二维坐标图中,横轴为年份,纵轴为在某个年份出现的关联关键词,以语言模型为起点,在网络中遍历与其相关联的链路,通过关联强度筛选重要链路及节点,并按照关键词所处的年份在图中绘制相应节点,其中椭圆形节点代表研究问题,矩形节点代表研究方法,边的粗细代表关联强度大小,边标签1、2、3 分别代表使用、扩展和对比关系,图9 展示了语言模型引用路线随时间变迁的演化路径。
结合图9,可以将语言模型的演化大体划分为4个阶段。在第一阶段(1979—2007 年)和第二阶段(2008—2011 年),这个时期的语言模型关注的是基于传统方法,如贪心算法、最小错误率训练方法来解决语言模型中涉及的词格解析等相关问题。在第三阶段(2012—2015 年),语言模型在使用基础方法(如对数线性方法、自适应调谐算法)和扩展基础方法(FFBS(forward filtering backward sampling)算法、贝叶斯模型)之外,开始关注机器学习算法在语言模型中的应用,这个阶段的研究问题主要集中于语言模型本身和机器翻译问题,并常常在这些问题中对不同的方法进行对比。在第四阶段(2016—2019 年)可以明显地看出,深度学习和神经网络已经成为语言模型研究的热点和趋势,注意力机制、RNN、BPE、计算语义、表示学习等前沿方法被广泛使用到语言模型中,以解决机器翻译、阅读理解、描述生成等研究问题。此外,我们可以发现,BPE 算法在语言模型发展过程中扮演着关键角色,除了语言模型研究使用了该方法外,神经机器翻译和注意力机制也常使用该方法(在图9 中进行了绘制),彼此间形成了紧密连接的团体。结合文献可知,BPE 算法[40]在NLP 领域的应用始于2016年,用来解决机器翻译任务中的出现的未登录词和罕见词问题,并取得了较好的表现,自BPE 在NLP领域中应用以来,常被运用在机器翻译、语言模型等诸多自然语言处理算法中。整体上来看,语言模型的演化与NLP 领域技术的发展基本是同步的,经历了从传统方法和研究问题到当前融合神经网络方法的演变过程,可以预测未来一段时期内语言模型的研究依然会重点关注结合深度学习的相关应用和研究问题。
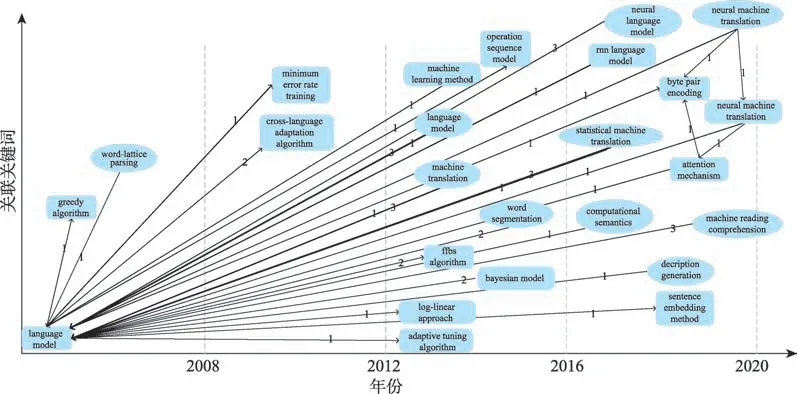
图9 语言模型的细粒度演化路径
为了更好地揭示细粒度领域知识演化的特征,本研究同样以语言模型主题为例,构建了传统基于共词网络方法的主题演化图进行对比分析。具体来说,将关键词或引用对象中包含language model 的施引文献抽取出来,合并施引文献关键词和被引对象作为该施引文献的关键词,同样将共词网络演化划分为相应的4 个阶段,根据每个阶段中所包含的文献集分别构建关键词共现网络,结果如图10所示。

图10 基于共词网络的语言模型主题演化
通过对细粒度关键词引用网络方法和共词网络方法下实验结果的对比和分析,发现两者在对领域主题的揭示、关键路径发现等方面有所差异。在对主题的揭示方面,各阶段两者关注的话题有一部分重叠,但同时也有部分节点存在差异。其原因在于基于共现关系构建的关键词关联关系中会包含一部分不存在直接引用关联的节点关系对,因此网络中会出现较多相关性不是很高的节点,影响了对关注焦点的判断。例如,在共词网络第四阶段中,尽管也出现了神经语言模型、BPE 算法等关键词,但其并没有成为该阶段核心主题,影响了对主题发展趋势的判断。相反,引用关系反映了两个关键词之间的直接关联,能更加准确地揭示领域当前关注的焦点,结合关键词语义功能和语义关联也能提高主题的可解释性。在关键路径发现方面,传统共词网络中节点之间都是基于共现关系,区别仅在于共现频次的不同,很难直接对节点间交互的作用和功能做出解释;而在引用关系中,明确了一个节点出于何种意图与另一个节点发生关联,可以直观发现不同的问题和方法在不同的阶段发挥了什么作用,更加容易识别出主题演变过程中的重要链路信息,例如,BPE 算法的使用在语言模型的发展演化过程中扮演了关键角色。
以上对比结果表明,从关键词之间的细粒度引用关系出发,可以以一种直接的视角对领域主题随时间变化的特征进行分析,揭示领域主题在不同时期的关注焦点和演化趋势。研究主题本质上就是具有不同语义功能的知识单元及其之间的语义关联构成的知识集合,通过细粒度关键词引用网络能够更深入地理解主题的演变机理及其内部的知识关联特征,为领域知识演化分析提供了一个新的视角。
5 总 结
面对日益增多的科学文献,从文本语义功能角度对学术文本进行深度语义理解,并从细粒度、语义化角度构建关键词之间的关联网络是一项迫切且有意义的研究工作。为此,本研究以ACL 数据集为例构建了细粒度关键词引用网络。接着,从引用功能敏感的子网分析、特定节点的多维关联分析和细粒度领域知识演化分析三个方面进行了实证分析和可视化呈现,一方面在实践中验证了本研究提出方法的合理性,另一方面挖掘到了领域知识分析中涌现的一些新的规律和特点,为科学知识网络和领域知识多维分析的研究提供了创新性的视角。
本研究也存在一定的局限。首先,尽管本文初始数据集较大,但由于重点选择了部分功能类型以及引用对象数据量较少,使构建出来的网络较为稀疏。在接下来的研究中,将进一步扩大标注数据集,从而更加完整、准确地表示学科领域知识关联情况。其次,本文仅从三个方面探索了细粒度关键词引用网络在领域知识多维分析中的应用,后续还可以进行网络社区划分等研究,以发现科学知识发展变化中更多的特征和规律。
