学术论断句标注与识别方法探索
2022-07-30郭语凡喻雪寒黄雨馨杨婷婷王唯一
徐 健,郭语凡,喻雪寒,黄雨馨,杨婷婷,王唯一,刘 政
(1. 南京农业大学信息管理学院,南京 210095;2. 南京农业大学经济管理学院农林经济管理博士后流动站,南京 210095)
1 引 言
随着数字学术出版物数量的爆发式增长,信息爆炸与知识匮乏的矛盾日益突出。在学术大数据的背景下,如何利用机器学习、自然语言处理等技术对学术文献中的文本进行自动化、细粒度地组织,挖掘其中蕴藏的理论与知识,是摆在科技情报领域学者面前的一个重要且富有挑战性的科学问题。学术观点,或称学者观点(论点),是指学者对于研究问题的看法、发现、见解或主张,是学者开展学术研究对学界形成的主要贡献,也是学术信息交流的主要内容和形式。1644 年,约翰·弥尔顿在其著作《论出版自由》中,首次提出观点的自由市场理论,认为真理是通过各种意见的自由辩论和竞争获得的,并非权力赐予。以“太阳与地球运动关系”这一问题为例,不同历史时期学者提出、丰富和发展了地心说、日心说和宇宙大爆炸等学术论断,如图1 所示。可以看出,新学术论断对原有论断的质疑、证伪、修正或推翻可视为科学研究进步的表现。同时,不同学派、学者学术观点或论断的交锋、争辩、相互补充和借鉴形成了学术研究进步的内在动力。与知识被广泛接受不同,学术论断(或观点)具有主观性的特点,主要是由于不同学者在研究视角、立场、知识结构、价值观等方面存在差异。同时,学术论断的正确性还需在实践中经过同行学者和专家的进一步检验。

图1 学术论断在推动知识更新与科学进步中作用示意图
学术观点(或论点)通常以学术文本中的论断性句子(claim sentences)的形式出现。目前,对领域学术观点的梳理和归纳通常通过人工阅读和整理,繁重的阅读任务挤占了学者思考和实验的时间,降低了其研究效率。基于此,本文探索学术论断句的自动识别方法,选择信息资源管理领域499篇论文摘要和249 篇论文全文作为研究样本,标注其中论断句和非论断句,利用传统机器学习和深度方法对此类句子进行识别。本文关注的研究问题包括:①学术论断句的判定标准有哪些?②何种分类器对学术论断句的识别效果较好?③学术论断句和非学术论断句在长度、位置、TextRank 权重等方面的特征存在什么差异,能否被用于识别学术论断句?通过探究上述问题,在明确学术论断句概念基础上,通过非结构化的外在语言表现形式将学术观点句与非学术观点句区分开来,形成初具规模的标注语料和标注平台,为其他功能类型语句标注、识别提供思路与工具上的参考。同时,通过对比不同类型特征对于学术论断句识别的有用性和各类识别方法的准确性,为后续学术论断句的进一步分类、组织与语义关联奠定基础。同时,本文的研究内容还可以进一步丰富观点挖掘研究场景,完善学术文本处理方法,通过对学术文本中的论断进行识别可以提高读者阅读效率。相关过程对学术信息资源利用效率、知识服务水平和知识交流效率的提高具有重要价值。
本文组织结构如下:第2 节从论辩挖掘、学术文本处理两个角度梳理相关研究,指出现有研究不足;第3 节介绍数据集和标注过程,明确标注标准,对标注结果进行描述;第4 节介绍了所使用模型与基准模型原理、评价指标,开展识别实验,分析实验结果,对比论断句和非论断句文本特征,探索各类特征对识别效果的影响;最后,总结本文的研究结论,讨论研究的局限性和创新性,并对未来研究进行展望。
2 相关工作
2.1 论辩挖掘
论辩挖掘(argument minging)研究可视为观点挖掘(opinion mining)的延续,所分析的文本类型涵盖新闻、政治演讲、学术论文、法院判例等内容。相关研究旨在对非结构化文本进行分析,抽取其中的论辩结构,其理论来源于哲学中的逻辑学。早在20 世纪50 年代,图尔敏模型[1](Toulmin model)就已被提出,包括主张、依据、正当理由、支援、模态限定词、反驳等元素。弗里曼(J. B. Freeman)将反驳分为消解反驳(undercutting defeater)和直接反驳(rebutting defeater),进一步丰富了图尔敏模型[2]。
现有论辩挖掘研究在方法层面重点关注论辩部件(argument component)和论辩结构(argument structure)的识别与抽取。其中,论辩部件可视为论辩结构的基本元素,也称为argumentative discourse unit(ADU)或argument unit,具有判断性(declar‐ative)、可证伪性(falsifiability)的特征。Walton[3]将论辩结构定义为若干前提与结论间组成的支持或攻击关系。论辩关系中的前件(premise) 和结论(conclusion)均可被称为论辩部件。目前,对论辩部件的识别包括非监督学习和监督学习两种方法:①在非监督学习方法方面,Petasis 等[4]在帖子和议论文数据上验证了基于TextRank 的抽取式摘要算法有助于论辩部件的识别。Levy 等[5]通过观察提出一种在语料库层面的查询表达式,并据此进行论断句识别。②在监督学习方法方面,Mochales-Palau等[6]、Palau 等[7]、Moens 等[8]在Araucaria 数据集上使用二元分类的方法进行论辩性句子的识别,并对各类特征与分类器效果进行了对比。此外,Habernal等[9]发现论辩部件与句子并非一一对应,还可能存在一句内包含多个论辩部件或者一个论辩部件由多句组成的现象。针对一句对应多个论辩部件的情况,目前多数研究通过序列标注的方式对句内词汇角色进行标注,通过识别论辩部件边界词进行论辩部件的抽取,代表性研究如Park 等[10]、Sardianos等[11]、Petasis[12]等。
论辩结构主要是指论辩部件间关系,包括微观和宏观两个层面:①微观关系旨在分析论辩部件(argumentative components)间的推理关系,主要应用在独白型文本或篇幅较短的评论信息中。Trevisan等[13]通过词性标注的方式归纳了英文中表示论点和结论间推理关系的提示词(conclusiva)。Carstens等[14]通过对句子对之间的关系进行分类,实现了论辩性句子的识别。Stab 等[15]在使用多类分类器对论辩部件类别进行判定的基础上,进一步采用分类的算法对论辩部件二元对是否存在支持关系进行分类。Lawrence 等[16]从语料库中抽取关联陈述,使用矩阵表示主题不同方面间的关联与推理关系。②论辩性文本间宏观关系多出现在对白型文本或多文档分析中。例如,Palau 等[7]使用语法分析的方法对法律文本中论断间的关系进行判断,Boltužić 等[17]采用文本蕴含分析(text entailment analysis)的方法对论坛中不同帖子之间的语义关系进行判定。受ACL、EMNLP 等国际会议推动,目前该领域方法已经在教育、法律、社交媒体、辩论等类型文本上开展了广泛的实验,涌现出了较多的领域语料库。
论辩挖掘在学术场景下主要有如下三个方面的应用:①对学生撰写的议论文论辩结构进行识别并对其质量进行评估。例如,Ong 等[18]使用基于规则的方法对来自匹兹堡心理学本科生撰写的议论文中的句子类型进行识别并对文章质量进行评分,发现其与专家对文章的评分存在相关性;Song 等[19]对学生撰写论文的论证策略(argument schema)进行标注,并分析其与专家评分之间的相关关系;Beig‐man Klebanov 等[20]研究发现论证结构可以比文章内容本身更准确地预测文章质量。②学术文本中论辩结构表示方法。Green[21]研究了医学诊断报告中的论辩修辞结构的表示方法。Accuosto 等[22]以计算机语言学(computational linguistics,CL)和生物医学(biomedicine,BIO)领域为例,提出一种摘要层面论辩单元和关系的标注方案,并利用转移学习方法预测文本论辩结构[23]。③论断句识别方法方面。Graves 等[24]发现实验性论文标题中的动词出现频次随时间增长,这有助于知识的传播。Park 等[25]探索了利用语义、句法等特征识别学术论文中的比较型论断句。从整体上来看,学术场景的论辩挖掘研究相对较少;而且,国外相关研究热度较大,国内开展的研究还比较少,以中文为对象的论辩挖掘则更加少见。相关研究还存在判断标准缺失、语料标注不规范的问题。本文着重关注中文学术文本中论断句的标注与抽取工作,形成标注语料,并探索其自动化识别方法。未来还将就学术论断的进一步分类、关联和组织开展研究。
2.2 学术文本信息分类
学术文本是学者发表自己观点与思想、研究发现的一种重要手段,通过阅读学术文本可以与同领域学者进行跨时间和空间地信息交流,对学者增长见识、把握前沿、获得启发等具有重要作用。学术文本数量的增长促进了各类学术文本分析与处理工具的产生与发展。相关研究涉及计算机语言学、自然语言处理和语义出版等学科领域。其中,对学术文本按照一定的方式进行分类可以满足用户更细粒度的检索需求,学术文本分类主要关注论文中各个片段功能的识别,按照粒度可以分为句子层面和篇章层面。
句子层面主要关注定义句[26]、创新句[27]、未来工作句[28]、研究方法句[29]等类型句子的识别方法,其潜在应用主要在于为用户提供更细粒度的检索结果。在此基础上,部分学者对特定类型的句子进行了更细粒度的划分。例如,张颖怡等[29]将研究方法句进一步分为使用研究方法和引用研究方法,并对其分布情况做了对比。温浩[30]将创新句分为问题、方法、结果等6 种类型,并研究其自动识别的方法。学术文本中的句子功能在语法、语义和语用各个层面均有不同的分类标准和方式,各个类别之间的重合和覆盖关系也需要进一步探讨。同时,在汉语和学术环境下句子往往比较长,可以视为复句,还需要进一步拆分为具有单一功能类型的子句才可以开展学术评价、知识挖掘等类型的应用。
学术文本结构主要关注学术论文中各篇章的功能,目前各学者主要关注功能的识别。Ma 等[31]构建了一个数据标注平台,旨在解决语料标注过程中的数据管理与规范问题。在识别方法上,Ma 等[32]、陆伟等[33]、黄永等[34]探索了利用章节内容、位置、标题及段落内容识别学术文本结构功能的方法。在应用上,方龙等[35]提出将学术文本结构功能特征应用于关键词抽取,在ScienceDirect 数据库上取得了较好的效果。本文的研究内容可以视为论辩挖掘和学术文本信息分类的交叉领域,其概念的界定和相关理论主要来自前者,而所用的方法与技术则更多地借鉴了学术文本信息分类方面的方法。在研究中,重点关注学术文本中的论断句的判断标准,并探索现有学术文本处理技术在论断句识别过程中的效果,为后续论断句结构化知识建模和关系判断奠定基础。
3 学术论断句标注过程
本文立足图书情报领域,从摘要和全文两个层面研究学术文本论断句标注过程和自动化识别方法。本文选择信息资源管理领域部分学术文本文献,搜集和处理文献题录信息,寻找全文内容,构建数据集。在此基础上组建数据标注小组,在标注过程中探讨标注论断句的判断标准,对论断句和非论断句进行标注,形成语料集,为下文探索学术论文句识别方法提供训练与测试数据集(图2)。

图2 学术文本中论断句标注过程
3.1 数据处理过程
本研究选择《中文社会科学引文索引》(Chi‐nese Social Sciences Citation Index,CSSCI) 作 为 数据源,以“关键词=信息资源管理”为检索式,共获得1998—2018 年这21 年发表的499 篇文献,检索日期为2019 年5 月31 日。之所以将语料限定在该主题内,主要是基于标注团队的学科和专业背景,且数据规模适中。下载这些题录数据,并使用Java程序对这些数据进行解析,存储在MySQL 数据库中。在中国知网中对这些数据进行逐一查询,发现部分文献由于数据库记录错误,或者由于文献较早并未找到数据来源。在这499 篇文献中,有463 篇找到了摘要,249篇有HTML 格式正文。对摘要中数据按照正则表达式[!?。!?]进行分句;对于全文数据,先按照正则表达式[0123346789 零一二三四五六七八九][^.)](.)*[^.,?!。,?!]识别一级标题,然后按照摘要分句的方式对一级标题下的各个段落进行分句,对句子文内和段内位置顺序进行记录。对句子中出现的乱码进行识别,对句子错分和非正文短句进行剔除。
最终,从摘要和全文中分别得到853 个和24401个句子,形成本文的研究数据。在摘要层面,平均每篇文献包含1.85 个摘要句,句均长度为65.1 个字;在全文层面,平均每篇文献包含98.0 个全文句,句均长度为60.6 个字。招募5 名标注人员,以文档为单元分配标注任务,任务分配过程要确保各摘要和全文被3 位人员标注,以便对争议性标注结果进行最终决策。
3.2 学术文本中论断句数据标注标准
在预标注阶段,针对标注过程中存在的分歧进行讨论,形成论断句的6 个判定标准,包括3 个必要条件和3 个充分条件。必要条件可从反面排除非论断句,充分条件可从正面确定论断句。具体而言,必要条件是指论断句一定具有的特征,若不符合则为非论断句,包括:①信念感。主要排除那些作者尚未形成确定判断的语句,包括疑问句和假设阶段的判断句;②对象和判断完备。主要对未形成完整命题的短文本,包括短标题、不完整的句子进行剔除。③可证伪。这个判断标准主要是指存在与该论断相对立或者竞争关系的其他论断,此处主要排除对事实的描述和对现有方法、工具的介绍,此类句子在句前添加“我认为”后,句子会变得不通顺。充分条件是指满足此类条件的一定是论断句,但论断句并不一定满足该标准,包括:①预测性。对未来发展进行预测,预测结果需要未来发展进行验证。②个人理解。对一些抽象概念的定义和理解,学术应允许存在对同一概念的不同理解。③包含一定价值判断和主张倾向的句子。建立在价值观基础上,是一种应然性判断。需要说明的是,本研究并未区分作者本人的论断和引用他人的论断,也未区分个人观点和公认的观点;同时,在标注过程中并未考虑论断句间的论辩关系。因此,本研究识别的论断句既包括论点句,也可能包括论断性的论据句,相关例句如表1所示。

表1 论断句标注标准和反面例句
3.3 数据标注界面
本节对学术观点句的标注可以分为摘要层面和全文层面。标注人员采用如图3 所示的界面对文献摘要中的句子进行标注。单击句子,可将该句标注为论断句(句子底线变为黑色实线),再次点击后可以标记为非论断句(句子底线变为黑色虚线),第三次点击删除其论断句标注结果(删除底线)。在左上角分别有标注完成和清除标注结果两个按钮,分别可以提交标注任务和取消标注结果。文献《重视发展二级学科,科学定名一级学科——再论本学科建设问题》的摘要共包含3 句话。第一句话是对图书馆学教育萎缩的原因进行解读,第二句话介绍了该研究的任务,最后一句话表达了作者的建议。将第一句和第三句标注为论断句,通过异步的方式完成存储。

图3 摘要层面论断句/非论断句标注
在全文层面,本研究选择了与论文整体研究主题契合程度比较高的句子进行标注。学术论文的关键词、摘要、标题等集中反映了学术论文的研究主题与研究对象,因此,主要从这三个部分中识别论文的研究主题词。遍历整个文档库,计算各个词汇的逆文档频率和重要性。考虑各个词汇的位置与数量,计算各词汇对其所在论文主题的揭示程度,其计算过程为
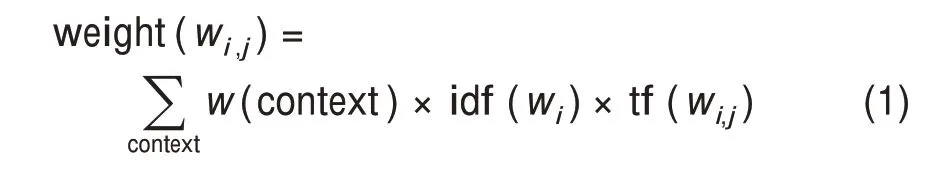
其中,wi,j表示第j篇文献中的词汇wi的重要性;context 可以取值为关键词、标题与摘要,本研究分别设置其权重分别为1、0.5 和0.1,对于未出现在三个主题区的词汇,其权重设定为0.01。对于每一个句子,其重要性记为各个词汇形成的向量与论文重要性词汇形成的向量之间的余弦夹角。计算完成后,从中抽取出主题相似性排在前20%的句子。图4 给出了全文标注的样例界面,背景为灰色的句子是被选出的主题相似性比较高的句子,其余标注过程与摘要相同。

图4 全文层面论断句和非论断句标注
3.4 标注一致性分析
由于标注过程中有多位标注人员参与,本研究选择kappa 指标[36]来评估标注人员之间的一致性程度,该指标取值为[0,1.0]。通常情况下,该指标小于0.2,说明一致性程度较低;该指标位于[0.2,0.4),说明标注的一致性程度一般;该指标位于[0.4,0.6),说明一致性程度中等;该指标位于[0.6,0.8),说明两者标注一致性程度较强;该指标位于[0.8,1.0],说明一致性程度很强。例如,Ai和Aj是不同的两个标注者,计算标注者Ai和Aj对于共同待标注句子的标注矩阵Mi,k和Mj,k,通过计算Mi,k的转置和Mj,k矩阵相乘的乘积形成混淆矩阵,最后计算该混淆矩阵的kappa 值。此外,本研究将所有可标注文献随机分给5 位标注者(分别记作A1~A5),确保每篇文献的摘要和全文至少分配给3 名标注者。将学术文献摘要和全文赋予5 位标注者进行标注,形成20 个kappa 数值,任务分配与标注一致性如表2 所示。

表2 学术观点句识别标注一致性结果
从表2 可以看出,标注者A1和A2一致性高达93.95%,可认为其标注近乎完全一致。剩余各标注二元组的一致性也都大于70%,可认为是高度一致。对于每一篇论文的摘要和全文的标注结果进行合并。为保障数据的准确性,对标注者标注存在不一致的句子召集标注者进行最终决策,采取多数裁定原则。最终,共形成2884 句论断句,2479 句非论断句,具体标注数据如表3 所示。

表3 论断句标注结果
4 学术文本中论断句识别方法探索
在生成论断句标注数据的基础上,本文将学术文本中论断句的识别转化为论断句与非论断句的二元分类问题。选择部分文本用传统机器学习方法与深度学习方法进行训练,评估各算法识别效果。在此基础上,对比论断句和非论断句在长度、位置、TextRank 特征上分布的差异,分析不同特征对识别算法效果是否存在提升作用。
4.1 模型选择与参数设置
本文使用WEKA 和PyTorch 中提供的分类器模型进行论断句识别实验,前者主要包含传统机器学习算法,后者则主要提供一些深度学习算法的实现。
本文选择传统的机器学习算法包括:方法①k近邻(k-nearest neighbor,kNN)[37]:该方法是最简单的文本分类方法之一,寻找与待分类节点最相近的k个节点,然后将其类别设定为这k个节点中数目最多的类别;方法②朴素贝叶斯(naive Bayesian,NB)[38]:该方法采用贝叶斯推理过程将文本类别判定转化为词汇类别判定问题,假设文本中的词汇特征之间相互独立;方法③决策树算法:对待分类数据特征进行分析构建决策树,可视为一系列分类特征,本文选择C4.5 算法[39]进行模型训练;方法④支持向量机(support vector machine,SVM)[40]:该方法使用代数运算的方法计算分类的边界,核心技术包括最大间隔、对偶、核技巧,比较适合二元分类问题;方法⑤最小序列优化(sequential minimal optimization,SMO)[41]:该方法是一种解决支持向量机训练过程中所产生优化问题的算法。
BERT (bidirectional encoder representation from transformers)[42]由谷歌提出,近年来在文本挖掘领域获得了广泛的应用。本文选择的深度学习方法包括:方法⑥BERT+FC、方法⑦BERT+BiLSTM(bi‐directional long short-term memory)两个模型。前者使用BERT 对句子进行表示,使用全连接层(fully connection layer)进行分类学习;后者在BERT 层对句子进行表示的基础上,加入双向长短时记忆网络,输出预测结果。在模型运行过程中,隐藏层设置为768,开启BERT 的fine-turning 微调模式,Epoch设置为10,Batch 为32,学习率设置为2e-5。
4.2 论断句识别评价指标
本文将学术文本中论断句的识别转化为一个句子二元分类问题。尝试使用传统机器学习分类和深度学习算法对学术论断句进行识别。表4 为识别方法结果邻接表。

表4 识别方法的结果邻接表
使用准确率(p)与召回率(r)、F_1 值三种指标对模型识别的效果进行评价。计算公式为

4.3 识别效果分析
为避免过适应性,使用10 折交叉检验的方式进行模型效果的评估。也就是将数据集尽可能平均地分为10 份,训练10 次,每轮选择1 份数据作为测试集,其中,方法①~方法⑤使用剩余9 份作为训练集,方法⑥和方法⑦则将这9 份中的8 份作为训练集,1 份作为验证集。各分类方法在论断句识别任务中的效果如表5 所示。
从表5 可以看出,深度学习方法整体上要显著优于传统机器学习算法的识别效果。其中,BERT+BiLSTM 在摘要和全文层面均取得论断句识别效果最优的效果。SVM 方法在摘要层面表现最差,训练出的模型将所有数据都预测为非论断句,导致论断句识别的准确率和召回率均为0。结合上文训练数据判断,该方法在预测时会更多地将未知数据标注为多数类别。此外,各类方法在摘要层面的识别综合效果F_1 值均不如在全文层面,说明在摘要识别方面还存在比较大的提升空间,数据规模、正负例比例是影响模型识别效果的主要原因。同时,本文是对整句进行标注的,那些既包含论断性子句又包含非论断性子句的长句,加大了论断句的识别难度。

表5 各分类方法识别效果对比分析 %
4.4 论断句文本特征分析
为进一步改善识别效果,本文对标注的摘要和全文中的论断句和非论断句的文本特征进行对比,包括长度、位置、TextRank 等,并将其融入识别模型中,以期提升传统机器学习方法识别论断句的效果。
1)长度特征对比分析
在摘要层面,共有463 篇858 个句子,其中390句被标注为论断句,468 句被标注为非论断句。摘要层面,论断句长度平均为184.2 个字,非论断句平均长度为187.5 个字,图5 为摘要中论断句/非论断句长度频率分布折线图。将句子长度以10 为组距分组,计算各组句子数目及频次占比,将多于300 个字的句子作为最后一组单独呈现。
从图5 可以看出,论断句在50~190 个字长度区间的频次要显著高于非论断句。在全文层面,标注全文中的论断句长度平均为191.6 个字,非论断句长度平均为139.2个字,其长度频率分布折线如图6所示。

图5 摘要中论断句与非论断句长度频率分布折线图
从图6 可以看出,论断句与非论断句长度的频率分布存在显著差异。在低于80 个字的句子中,非论断句占比较高,论断句占比较低,说明长度特征可能有助于学术文本中论断句的识别。这可能是由于在标注过程中,一些较短的句子如标题、过渡句等并未包含完整的命题信息,更多地被标注为非论断句。

图6 全文中论断句与非论断句长度频率分布折线图
2)位置特征对比分析
为揭示摘要中论断句和非论断句位置分布差异,本文对不同句数摘要中论断句出现位置频次进行统计。在标注的463 篇摘要中,数量最多的为9句,大部分文献(97.2%) 摘要句数在5 句以内。为分析摘要中各位置论断句占比,本文绘制了5 句内摘要各位置论断句概率图,每列表示相应句数摘要的情况,括号内数字表示对应该摘要句数的文献数目,黑色部分面积表示该位置论断句占比,如图7 所示。

图7 摘要中论断句出现位置频次分布
从图7 可以看出,在仅包含1 个句子的摘要(223篇)中,包含论断句的情况比较少(20.1%),大多是对研究过程的客观论述。在包含2 个句子的摘要中(150 篇)中,首句为论断句的占比要大于第2 句为论断句的占比。在包含2~5 个句子的摘要中,位置越靠前,论断句出现概率就越高。在全文层面,本文从段内位置和文内位置两个方面对论断句出现位置进行分析。共有249 篇文献拥有全文数据,共标记出论断句2513 句,非论断句1992 句。仅有1 句的段落中,仅20.2%的句子被标注为论断句,这要远低于整体上55.8%的论断句占比。单句段落通常为过渡句,多被标注为非论断句。在包含2 个句子的段落(69.5%)中,首句标注为论断句的概率要高于第2 句(56.5%)。在3句及3句以上段落中,统计段首句、段中句和段尾句标注为论断句的概率分布如图8所示。

图8 3句及3句以上段落中论断句出现位置概率分布
从图8 可以看出,在3 句及3 句以上的段落中,段落首尾处被标注为论断句的概率要比段中句高,且段首句要略低于段尾句。这符合写作过程中,在首句或尾句给出论断的习惯。本文使用文内相对位置来表示论断句与非论断句在全文中的位置,即对论文中各个句子按照出现次序进行编号,句子文内相对位置定义为其编号与全文句子数目的比值。将句子文内相对位置按照0.05 的组距分为20 组(左开右闭),论断句在文内相对位置的概率分布折线如图9 所示。
从图9 可以看出,论断句在论文开头和结尾两处出现的概率较大,整体呈U 形分布。具体来说,论断句在文内相对位置前5%和后15%出现的概率要高于非论断句,其他位置非论断句出现的概率要高于论断句。这可能是因为在写作过程中,多数学者会在论文最前面直接抛出论点或者在论文末尾总结性地给出结论。

图9 论断句和非论断句在文内相对位置的概率分布折线图
3)TextRank 特征对比分析
在文摘研究领域,TextRank 算法[43]常被用于抽取文本中比较重要的词与句子,其核心思想是用随机游走的方式对句子权重进行计算。使用HanLP 工具[44]计算各文献句子初始TextRank 权重,并对该数值采用均值归一化的方式形成最终取值介于0~1 的文内相对权重。对归一化后的TextRank 数值按0.05的组距进行分组操作,共得到20 组(左开右闭),图10 给出了全文层面标注论断句、非论断句和所有句子的频率分布对比。

图10 论断句和非论断句TextRank权重频率分布折线图
整体来看,所有句子的文内相对TextRank 权重呈现倒U 形分布,而本文标注的论断句和非论断句分布频率却随着TextRank 数值的升高呈上升趋势,这是由于本文在选择标注数据时就选择了和全文主题比较契合的句子。从标注结果来看,非论断句和论断句频率分布曲线在TextRank 取值为0.55 处存在交点,在大于该值的组内,论断句分布频率要略高于非论断句。非论断句TextRank 均值为0.520,而论断句TextRank 均值略高,为0.538。
4.5 特征扩充识别实验
根据上文论断句和非论断句文本特征对比分析的结果,考虑在摘要和全文层面将部分特征融入识别模型以提升效果。这些特征包括:
(1)长度特征集。包括31 个特征。将句子长度以10 为组距,分成31 组,多于300 个字的归为第31 组,将句长所属组对应特征赋值为1,其余赋值为0。
(2)段内句数与位置。共包括6 个特征:独段句和两句段落分别将para_single 和para_dual 特征赋值为1,其余特征赋值为0。三句(含)以上段落将para_multi 特征赋值为1,para_first、para_middle和para_last 分别表示是否为段首、段中和段尾句。
(3)文内相对位置。包括20 个特征项。将句子文内相对位置以0.05 为组距,分成20 组,将句子文内相对位置所属组对应特征赋值为1,其余赋值为0。
(4)TextRank。将句子TextRank 值以0.05 为组距分成20 组,所属组对应特征项赋值为1,其余赋值为0。
上述特征中,(1)和(2)是摘要和全文层面共有的特征,而(3)和(4)则是全文层面数据所独有的特征。按照4.3 节的分析结果,在摘要和全文层面分别选择传统机器学习模型中表现最优的SMO 和SVM 进行特征扩充实验。表6 列出了加入这些特征后,模型识别效果变化情况。

表6 特征扩充识别效果分析
从表6 可以看出,在摘要数据上,仅加入长度特征后模型识别效果有较小提升,而段内位置特征加入后,识别效果几乎没有变化;结果显示,将长度特征加入综合特征后,准确率、召回率、F_1 值均小幅度提升0.5%。在全文数据上,长度、段内位置和文内相对位置特征有助于识别效果的提升;TextRank 特征加入后,论断句识别效果几乎没有变化;最终,将有助于提升识别效果的三个特征全部加入特征集,识别准确率提升2.9%,召回率提升0.1%,F_1 值提升2.0%。
5 结 语
在现代科学研究中,系统地掌握、及时地了解各领域、学派、学者最新的研究发现和学术主张对学者开展研究工作起着越来越重要的作用。本文在对前人研究进行归纳的基础上,提出学术论断句的6 个判定标准,必要性标准可用于排除非论断句,包括信念感、完备性、可证伪,充分性标准包括预测、个人理解和价值判断三个标准。选择信息资源管理领域部分论文数据开展摘要和全文层面的标注实验,在此基础上实现论断句自动化识别。对论断句和非论断句文本特征进行分析,研究发现:①使用本文提出的判断标准,标注者在摘要和全文层面对学术文本中论断句和非论断句标注的一致性较高。②基于BERT+BiLSTM 论断句识别方法取得了最优的性能。③论断句和非论断句的长度在全文中的分布差异要大于在摘要中的差异;论断句出现在文内开头和结尾的概率要高于非论断句,段首和段尾句被标注为论断句的概率高于段中句;学术论文中论断句TextRank 特征取值显著高于非论断句。在摘要层面,加入长度特征后,论断句识别效果在F_1值上提升了0.5%。在全文层面,加入长度、段内相对位置、文内相对位置特征后,分类器识别效果在F_1 值上取得了2%的提升效果。
本文不足之处在于:①仅选取了信息资源管理领域的部分数据,数据量较少,范围局限于人文社科领域,对自然科学领域的数据并未涉及,相关识别方法和结论的普适性还需进一步验证,未来应在此方面加以补充;②在论断句语料标注过程中,虽然不同标注人员在一定判定原则的前提下取得了较高的一致性,但数据规模较小,未来应对提出的判断标准进行进一步完善;同时,论文不同区域的论断句重要性并不相同,未来应考虑论断句权重计算问题;③当前学术文本中论断句识别已经取得较好的效果,但使用的方法、选择的特征相对有限,准确率与召回率仍然存在一定提升空间,未来应着重挖掘文本的功能结构和推理结构,探索词汇特征、句法特征、位置和长度特征的融合,提高论断句或学术观点句的识别效果。
此外,在本文的研究基础上未来还应开展如下方向的研究:①本文从整句层面对论断句进行了识别,未区分整句中的论断性和非论断性成分;未来,应从词汇层面精确地识别边界,从主题、研究对象和判断类型等多维视角构建学术论断的分类体系,并使用知识抽取的方式对各类论断句进行细粒度地结构化表示;②论断句仅是学术观点或论点的必要条件,未来应从论断句与上下文的修辞、逻辑关系入手对学术文本中的核心学术论点进行识别;同时,应从归纳和演绎的视角对各个论断的论证方式和论据进行识别、匹配和分析,在此基础上对论点进行权重评估,从论点间关系间角度识别文献核心论点及其之间的语义关系,全面揭示学术论文论证结构;③在对单篇学术论文论证结构进行识别的基础上,对同主题多文档论证结构进行聚类、对齐、比较和归纳,发现研究者在观点上的分歧,综合不同研究视角的观点对研究对象和问题形成整体性和更全面的认知。相关技术与方法在学术观点的查重、创新性评估、自动识别学派上有着广泛的应用前景。
