基于聚类算法的用户互联网偏好分析
2022-07-25毕佳佳
毕佳佳
(安徽职业技术学院信息工程学院,合肥 230011)
0 引言
随着移动互联网时代的到来,移动用户每天都会产生大量的网络数据。这些数据中隐藏着很高的价值,对于商家而言,如何从大量的数据中挖掘出有价值的信息,提高其商业价值,是一个具有意义的挑战。对于运营商而言,语音收入正在大幅度下降,但其拥有大量的客户群体,每个用户每天都会产生大量的行为数据,这些数据都会存储在运营商的系统数据库中。运营商可以根据不同的业务数据,从不同的运营方向挖掘用户的不同价值,提高运营商自身的利益及竞争力。因此,如何在经营过程中将用户数据变现,提高经营价值是其核心问题。
移动用户上网时的行为表现往往会具有一般的规律性,运营商可根据用户的不同规律性,有针对性地进行精准营销。针对移动用户的上网行为数据进行挖掘,挖掘出不同用户的不同规律,分析用户的上网偏好,给用户打上偏好标签,为后期精准化营销奠定基础。
本文使用某运营商业务系统的用户行为数据,结合对各网站及社交媒体进行爬取的数据进行解析,经过数据处理以后,使用聚类算法K-means 对用户在互联网上的行为偏好进行挖掘。
1 互联网外部数据爬取及解析
为了精确地分析移动用户的互联网偏好,丰富分析使用的数据类型和规模,本文利用当下流行的爬虫技术,结合容器化及智能化手段,完成各类网站及社交媒体信息的爬取,为上层应用提供基础数据支撑能力。爬虫技术包括微信及微博爬虫、规则爬虫、自动化爬虫、定制爬虫等,涵盖的信源类型包括新闻、论坛、微博、微信、博客、商机、商家等。本文通过爬虫技术采集了9 万条url 信息,同时建立了URL/UA配置库。
本文采用基于DPI技术,结合URL/UA 配置库,对用户上网日志数据进行解析。DPI是一种深度报文解析技术,可解析用户网站访问及app使用情况。本文通过该技术从爬取的用户上网日志数据中解析出16 万款App,涵盖了金融、购物、游戏、娱乐、阅读等800大类信息。通过对网页内容解析后,从9 万条url 信息中识别出图书、视频、音乐、资讯、商品等类型数据。
2 用户行为偏好挖掘
2.1 数据预处理
将用户上网的数据解析后,与其通信行为数据进行关联汇总,形成用于挖掘用户行为偏好的初始数据。数据见表1,主要包括性别、年龄基本信息,上网时间、流量、套餐、ARPU等通信行为数据,以及从上网数据中解析的应用名称、应用分类1级、2级等信息。
通过对表1进行数据挖掘,分析用户上网影响因素,从而细分用户群体,为精细化营销奠定基础。
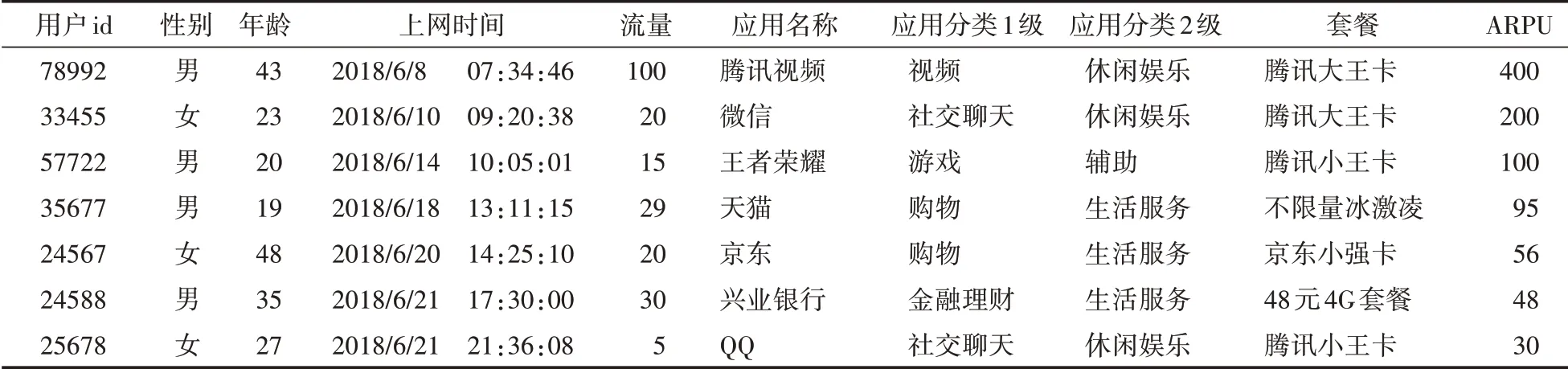
表1 用户行为偏好分析初始数据
为了方便快速地对用户行为数据进行分析,提供有效的决策支撑,需要对数据进行预处理,提高数据的质量,保证挖掘的效果。
首先对初始数据按照以下经验规则进行粗粒度的分类,形成训练样本。
(1)将按照年龄层次划分以下四部分:小于20 为少年,20~30 为青年,30~50 为中年,大于50为老年。
(2)将上网时间按照时间段划分为以下五个部分:9:00 之前为上班途中,9:00~12:00为上午,12:00~17:00为下午,17:00~19:00为下班归途,19:00~24:00为晚上。
(3)根据上网日期可划分为工作日、节假日、周末三种类别。
(4)将ARPU 大于200 元划分为高消费用户。
(5)按照上网天数划分:1~10 号为上旬,10~20为中旬,20~30为下旬。
(6)按照流量划分:0~100 M 为低流量用户,100 M~2 G为中流量用户,大于2 G为高流量用户。
经过预处理后数据如表2所示,由“性别”、“年龄”、“上网日期”、“上网时间段”、“日期类型”、“流量”、“应用名称”、“应用分类1 级”、“应用分类2 级”、“套餐”、“ARPU”11 个特征构成。其中,“ARPU”值为运营商每月从用户身上所获取的利润。

表2 上网记录预处理后的数据
2.2 基于聚类模型的用户偏好挖掘
聚类是一种无监督的学习算法,根据“物以类聚”的思想将数据对象按照相似性进行分类,使得同一组内的数据对象之间的距离尽可能地小,组间数据对象之间的距离尽可能地大。
本文采用基于划分的聚类算法K-means 对用户行为数据进行挖掘。K-means 算法简洁高效,原理简单、易于实现,运行效率快,可适用于大规模的数据挖掘。K-means 的基本思想是把数据集划分为个簇,每个簇内部的样本数据之间都非常的相似,而不同簇之间的样本数据之间差异性很大。K-means 算法聚类的过程以图1 为例,该示例将用户的Arpu 和流量两个特征聚成2组。
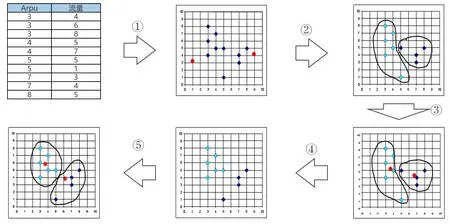
图1 K-means聚类过程示例
步骤如下:
(1)确定=2,将用户聚成两组;
(2)任选两个数据作为初始聚类中心点,如图1中第二个子图中的圆形数据点;
(3)分别计算剩余数据对象与两个初始聚类中心点的距离,距离哪个中心点近,就指派到哪个簇中,最终形成两组初始的簇;
(4)根据划分的两个簇内数据,分别计算两个簇内样本数据的特征均值,来更新两个聚类中心点;
(5)重复步骤(3),直到聚类中心点不再发生变化或变化很小,或者人工设置迭代次数,提前终止迭代更新。
通过K-means 算法将用户行为数据的不同特征聚成不同的类别。根据聚类中心结果的特点,结合专家经验,给用户打上不同的标签。通过实验分析发现,“客户兴趣”概念的标签可能是“游戏爱好者”、“阅读爱好者”或者“视频爱好者”,“游戏爱好者”的游戏偏好可能是“王者荣耀”,用户上网的时间段集中在19:00~24:00。用户更喜欢在周末或放假期间观看视频;通过ARPU 值对用户的消费等级进行评估;通过上网天数观察用户为高频次、中频次或低频次活跃用户。这些实验结果分析用来进一步指导产品的实际运营工作。
3 结语
本文首先采用DPI 技术实现对移动用户上网日志数据进行解析,再结合用户基本通信信息,形成用于挖掘偏好的初始数据。为了提高数据质量,对初始数据进行了预处理,对处理后的数据采用聚类的算法将用户分成不同的类型,挖掘用户的偏好标签,为进一步指导产品的运营工作提供了支撑。
