基于目标识别的HEVC 分割算法优化与实现
2022-07-25郭江宇靳文兵王宇新
吕 昊,郭江宇*,靳文兵,张 宾,王宇新
(1.北方自动控制技术研究所,太原 030006;2.驻太原地区第二军代室,太原 030006)
0 引言
随着时代的进步和科学技术的发展,现代武器装备的信息化程度越来越高。大数据时代的到来,使得数据的及时传递和分析起到更大的作用,同时也使数据发掘应用,支撑“智能化作战”成为可能,图像信息的获取、压缩、传输和存储对于数据的分析处理具有重要意义。目前主流的视频编码方案大多采用混合视频编码框架,即由多个编码模块组成,它们采取的技术以及在率失真优化技术指导下的模式选择过程都会影响最终的编码性能。
针对视频编码的优化算法进行国产化的设计与实现也具有重要意义,尤其是在国防科技工业领域,武器装备的自主可控关系到我国的国防安全,发展自主可控装备是我国国防工业的重要组成。针对重要技术实现自主可控,发展自主可控装备,有利于消除可能存在的安全隐患,避免国外的软件算法以及硬件平台中可能存在的“后门”造成不利影响,对于实现装备的自我保障,保证持续发展,具有重要的现实意义。
判断视频压缩编码效果的指标有:压缩失真、编码码率以及计算复杂度,而视频编码的根本任务是协调这3 个指标之间的关系,并不断优化。率失真优化是针对码率和失真度之间的优化。针对独立率失真的优化,人们纷纷展开研究。郭红伟等人提出一种内容自适应的拉格朗日乘子计算方法,其对于具有快速运动内容的视频,编码性能改善较大。ZHANG J等则提出一种改进的拉格朗日乘子运动估计算法,对于帧间划分块通过测试最小化失真和最小化码率两种极值,避免了较大的运动估计误差;张世彦采用基于主成分分析的噪声估计算法实现LCU 级的噪声估计,实现自适应优化量化步长并消除噪声影响,能适用于较宽泛的码率范围。
当视频在复杂网络环境下进行传输时,它的工作容易受到在同一局域网环境下其他通信设备的干扰。而其他设备在使用过程中占用绝大部分的带宽,会造成网络拥塞,可能致使视频编码系统产生传输延迟以及丢包等情况。因此,在复杂网络情况下,针对可使用带宽较低的情况,可以提高视频压缩率来保持视频传输的稳定性。但是提高视频压缩比会导致失真度较高,为了解决在降低带宽的前提下,提高视频压缩率造成的失真度,本文针对HEVC(high efficiency video coding)视频编码算法进行优化,并实现优化算法在全国产平台上的适配。主要是通过对编码单元(coding unit,CU)的分割算法进行优化,在保证视频目标区域图像质量的前提下,提高压缩速率,提高整体压缩率。
1 运行环境的搭建
为了实现重要技术的自主可控,本文主要采用全国产化的硬件平台,国产操作系统以及国产的深度学习框架展开。主要选用以FT-2000/4 为CPU 的硬件平台,主频为2.2 GHz,支持单精度、双精度浮点运算指令和ASIMD 处理指令。在操作系统上,本文选用银河麒麟操作系统,具有高安全、高可靠、高可用、跨平台、中文化的特点,并已经广泛应用于多个行业或领域。在深度学习的框架上,选用百度的PaddlePaddle 深度学习框架进行深度学习的训练以及推理工作。PaddlePaddle 是百度自主研发的性能优先、灵活易用的深度学习平台,是主流深度学习框架中唯一完全国产化的产品。
本文通过在基于FT-2000/4 为CPU 的硬件平台上搭载银河麒麟操作系统,搭建适配paddlepaddle运行的软件环境,完成HEVC 编码算法运行的国产化平台。
2 HEVC 分割算法优化
2.1 感兴趣区域的提取
感兴趣区域(region of interest,ROI)是指在图像中人眼主观感兴趣的区域。在本文中,我们认为ROI是在常见环境背景下的目标对象。提取ROI 的目的是针对感兴趣区域以及非感兴趣区域采用不同的编码策略。由于人眼对于视频中的不同区域位置会赋予不同的关注程度,同时也对失真度拥有不同的敏感性,采取不同编码策略可以提高视频图像整体的主观视觉效果。传统ROI 的提取,主要是根据图像颜色纹理特征、运动检测以及通过视觉注意模型等方法,目标检测的方法大多是利用时间域或者空间信息进行处理,采用背景差分法、光流法、帧差法等对运动目标进行检测。本文则采用基于深度学习的目标识别方法提取ROI。
在具体ROI 的提取过程中,通过使用PaddlePa ddle深度学习框架,利用公开数据集VOC2012,在百度推出的AI studio 云平台上使用平台提供的算力,针对Mobilenet-SSD 算法进行训练。MobileNet-SSD将轻量级深度网络模型MobileNet 和目标检测算法SSD 结合起来,很好地继承了MobileNet 预测速度快,易于部署的特点。MobileNet 为了降低整体的计算量,主要使用了深度可分离卷积将标准卷积核进行分解计算,以及通过引入两个超参数来减少参数量和计算量。
深度可分离卷积将标准卷积核分为深度卷积核和大小为1*1 的点卷积核,当输入为M 个通道,输入feature map 大小为D*D,卷积核大小为D*D,输出通道为N 时,标准卷积核和深度可分离卷积的计算量比率为:
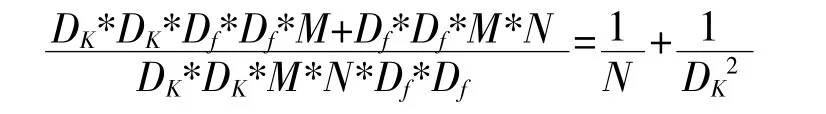
除此外,当引入超参数宽度乘数α 以及分辨率乘数ρ,输入层通道个数M 变为α,输出层通道个数N 变为α,总计算量为:

可以降低原来模型的计算量。
通过训练,获取相关训练模型,并将训练好的模型移植到上一节中所述的搭载paddlepaddle 深度学习框架的国产化运行平台上。通过输入测试视频文件,来展开推理工作,对视频中的目标对象进行识别。

图1 感兴趣区域提取
在一帧视频识别完成后,首先检测该图像中是否存在目标区域,如果存在则输出帧序号、目标标签以及锚框等信息,如果不存在,则设定目标标签为None,锚框坐标为(-1,-1),由于在视频编码过程中,编码单元最大为64*64,因此,将锚框起始坐标及长宽尺寸预处理为64 的倍数,可以方便后续视频编码处理,并将算法中检测出的关于背景的background 标签的目标信息去除,避免影响感兴趣区域的提取工作。在完成最感兴趣区域的预处理后,将感兴趣区域信息存储以便后续处理。
在ROI 的提取工作中,通过利用基于深度学习的目标识别算法将每一帧数据中有用的目标信息,如目标标签、锚框坐标及尺寸等信息输出,并及时传递给编码算法对相应帧进行处理。实现视频图像ROI 的提取。
2.2 编码单元分割深度的确定
视频压缩编码是一类特殊的数据压缩方法。各种视频应用催生了多种视频编码方法。HEVC 是2013 年发布的较新一代视频编码标准,包括变换、量化、熵编码、帧内预测、帧间预测以及环路滤波等模块。并在之前编码方法的基础上,加入了基于四叉树的块分割结构。本文主要针对基于四叉树的块分割结构进行优化处理。在之前的编码算法中,CU 的大小是固定的,在HEVC 中,一帧图像可以被划分若干互不重叠的编码树单元(coding tree unit,CTU),之后依据四叉树原则,CTU 可以被分割为多层不同大小的CU,CU 是否被继续分割取决于算法中的分割标志位。图2 是CU 分割的示意图,对于一个CU,最大为64*64,最小为8*8,即一个CTU 内可以包含最少1 个,最多64 个编码单元。根据图像中不同区域的图像内容以及应用需求等,可以合理分配编码单元大小和最大分割深度,使得编码效果获得较好的优化,例如在平台区域,采用较大的编码单元进行编码可以减少所用的比特数,提高编码效率。在HEVC 编码过程中,视频图像首先根据I、P、B 帧,分为多个图像组(group of pictures,GOP),在GOP 中每帧图像为1 个图片顺序计数(picture order count,POC),之后逐层分解到对编码单元的四叉树划分上。主要针对这部分的实现进行一个修改和优化。

图2 编码单元分割示意图
HM(hevc test model)作为HEVC 的参考软件,在HEVC 协议制定和修改的会议中,每次新的方案和技术提出后,都是利用HM 作为评价和验证优化效率的工具。并且随着方案技术的优化,HM 也会公开相应的代码实现。本文中,针对HEVC 算法的优化,主要利用HM 的代码进行实现。
在HM 中,对编码单元大小和分割深度的判定主要通过TEncCu::xCompressCU 函数实现。xCompressCU 函数主要是通过遍历每种编码大小的编码单元,对比获取最优解。在函数的具体实现过程中,通过依次获取较大的编码单元,遍历该编码单元的所有预测模式,并对比确认最佳率失真代价,之后通过调用自身,对该编码单元内所包含的下一深度的编码单元进行计算,并逐渐计算到最小的8*8 的编码单元,最后对比该深度的4 个编码单元率失真代价之和与上一深度率失真代价,依次进行对比,并最后确认该位置编码单元的大小和分割深度。由上述过程可以知道,对于一个CTU,完成全部四叉树的遍历,需要进行1+4+4*4+4*4*4,共85 次率失真代价的计算,并针对每个编码单元进行预测单元和变换单元的计算。编码器在运行过程中,计算复杂度很高。
在视频编码实际使用的过程中,实际上并不是视频中所有区域的内容都受到人们的关注。目前HEVC 算法中,编码单元的划分与视频内容的复杂度相关,背景内容较多,纹理复杂的区域,编码单元相对较小,这样可以更好地反映出复杂纹理区域的信息,而背景相对单一,纹理简单的区域,采用较大的编码单元就可以反映该区域的信息,而不会显著增加比特率。在此针对这种情况,提出利用感兴趣区域的方法对这一过程进行优化。利用上一小节获取的目标信息,对视频中不同区域分配不同的深度值,对于非目标区域提前终止对编码单元的划分,进而降低编码的复杂度。
本文对非感兴趣区域采取默认最大的编码单元时,仅对感兴趣区域进行率失真代价的计算时,可以很大程度降低编码计算的复杂度,提高编码速率,并且保证了感兴趣区域的编码质量。
2.3 视频编码算法优化整体流程
本文所述的HEVC 分割算法优化在国产化平台的具体实现如图3 所示。在视频输入后,可以分为感兴趣区域的提取和视频编码两部分进行。在感兴趣区域的提取部分,首先利用FFMPEG 软件,将视频格式转为.mp4,之后利用opencv 对视频中每帧进行处理,之后调用paddlepaddle 深度学习框架中MobileNet 的函数,使用2.1 中所述在云端训练得到的模型,针对每帧图像进行目标识别的推理工作。只要针对图像中是否存在目标区域进行判断,如果存在,则将视频帧序号、目标标签以及锚框相关信息按照一定格式进行输出,如果不存在,则标定目标标签为“None”,目标坐标为(-1,-1)。在此之后,针对提取到的感兴趣区域信息进行预处理,为了后期的视频编码方便进行,在这里将锚框相关坐标及长宽信息转化为以64 为单位长度的整数,即一个CU 的长度作为单位长度,方便视频编码工作的进行。在处理完成后,将感兴趣区域信息保存至datafile.txt 文件中,并判断当前处理帧是否为最后一帧,若不是则继续处理,若是最后一帧,则结束对该视频的感兴趣区域提取工作。在视频编码部分,首先利用FFMPEG 软件将视频格式转为.yuv,之后将视频传入HM 软件后,对视频进行逐帧处理。在对一帧图像进行处理前,首先本文通过读取保存在datafile.txt 中的感兴趣区域信息,如果读取不到对应帧的感兴趣区域信息,则延时后再次读取,直到对应帧的感兴趣区域信息。之后本文对提取到的感兴趣区域的信息进行处理,提取锚框坐标及尺寸信息,之后将数据送入xCompressCU 函数。在该函数中,首先对输入的CU 进行率失真代价的计算,之后判断目前处理的CU 是否在坐标范围内,如果在则继续进行下一步分割,直到分割到最小CU,如果不在则停止分割,直接进入下一个CU 进行试验,直到所有CU 遍历完成。之后对下一帧进行以上操作,直到视频结束,完成视频编码。

图3 视频编码算法优化整体流程图
在本文中,由于目标识别是针对每一帧图像进行目标识别,不涉及帧与帧之间目标物的坐标关系,并且编码过程全部采用I 帧,不涉及P、B帧,即不涉及帧与帧之间的预测,因此,不涉及时间相关性。
3 实验结果
本文主要利用HEVC 参考源码HM 中,目前最新版的HM16.20 进行实验和测试,在实验过程中统一采用encoder_intra_main.cfg 标准配置文件,即全部采用I 帧,不涉及帧间预测,针对不同分辨率的测试视频文件进行处理。
在实验中,本文通过对比同一视频文件在采用HM16.20 原版软件,以及在采用ROI 的方法后的视频编码软件的运行效果,对最后编码后数据文件的大小,以及运行时间等信息进行对比,并且利用Python,matlab 等对数据进行处理,通过在视频文件中选取特定帧,在图像中画出编码单元的分割情况,直观确认感兴趣区域算法对视频编码算法的影响。由于HM 和深度学习算法所需要的视频格式不同,因此,本文在进行运算处理之前,首先利用FFMPEG,将测试视频分别转为.yuv 以及.mp4 格式的文件。将.yuv 格式文件传入HM 软件,并利用Python 将.mp4 文件传入感兴趣区域提取的算法中,展开实验。并及时记录编码过程中的测试结果,以及在编码过程中传输回来的编码单元深度信息的数据。
3.1 直观效果对比
通过输出编码单元的分割深度信息等,本文可以有效得知每一个位置的编码单元具体分割情况。通过将输出的数据利用Python 进行预处理以及重新排列,将每一帧的深度信息分开,并将深度信息数据与图像坐标位置进行对应。之后利用Python 调用OpenCV 随机取出测试视频中的某一帧图像,以及对应的编码单元分割深度数据,之后根据图像及数据,在matlab 内绘制出编码单元在实际图像中的分割效果图。
HEVC 视频编码的编码单元分割算法优化前后对比图如图4 所示,可以直观地看出,针对分割算法进行优化后,目前图像主要只针对感兴趣区域内的编码单元进行分割,而对于感兴趣区域外,则采用64*64 的最大编码单元。相比较算法未优化之前,在保证感兴趣区域内的分割效果的基础上,忽略非感兴趣区域编码单元的分割效果。通过整个系统良好的运行效率,证明在全国产化平台上,实现整个系统是可行的。

图4 分割算法运行对比图
3.2 客观数据对比

表1 多分辨率视频实验记录参数对比
在2.2 中,本文提到,在HEVC 协议制定和修改的会议中,每次新的方案和技术提出后,都是利用HM 作为评价和验证优化效率的工具。因此,利用HM 作为编码算法优化的对比,具有客观价值。在实验中主要记录的参数有:测试视频分辨率、帧率、感兴趣区域占原图像比例、原软件处理时间、优化后软件处理时间、原软件压缩率、优化后软件压缩率。通过比对优化前后的处理时间以及压缩率,可以发现,通过对算法进行优化,可以有效降低软件处理时间,并提高软件压缩率。
传统获取ROI 的方法针对视频特征较少的视频流或许可以获得比本文更好的效果,但传统方法无法针对我们所需要的特定对象为目标进行视频编码,仅保证特定对象的图像质量,因此,在本文不进行对比。
4 结论
为了优化视频信号在复杂网络环境下由于网络拥塞出现的数据丢包等情况,本文针对HEVC 编码中的编码单元分割算法进行优化,在保证目标区域编码效果的情况下,降低非感兴趣区域编码效果。本文算法通过在全国产化硬件及软件平台上,通过利用基于国产深度学习框架paddlepaddle 的MobileNet 模型算法进行目标识别,获取感兴趣区域,并在视频编码算法中通过限制非感兴趣区域编码单元的分割,来降低算法运行的复杂度,优化算法执行效率。实现结果表明,优化后的算法可以有效提高视频整体压缩率,缩短软件处理时间,并且从主观视觉上也可以判断出,经过优化的算法可以准确地针对感兴趣区域保证较好的编码精度。
