基于多视图和显著性分割的古生物三维模型检索
2022-07-20周宇航冯宏伟刘建妮
周宇航,冯宏伟,冯 筠,刘建妮
(1.西北大学 信息科学与技术学院, 陕西 西安 710127;2.西北大学 地质学系/大陆动力学国家重点实验室 陕西省早期生命与环境重点实验室 西安市古生物信息学重点实验室,陕西 西安 710069)
随着三维技术的快速发展,三维对象在建筑设计、电影制作、三维游戏、医疗等领域都有着广泛的应用,涌现了大量的三维模型检索方法,这些方法可以分为两类:基于模型的方法和基于视图的方法。基于模型的方法是较早期的方法,它直接从三维模型中提取特征,如属于低层特征的几何矩[1]、表面分布[2]、体积描述子[3]和属于高层特征的骨架描述子[4],由于这类检索方法需要大量的时间和计算复杂度来构建三维模型,因此,基于模型的方法在实际应用中受到严重的限制。
如今,基于视图的方法受到广泛的关注,因为它可以利用一组二维图像表示一个三维模型,将复杂的三维信息转化为多个二维图像进行处理,使得许多成熟的二维图像处理方法能够应用在三维模型处理上。基于视图的三维模型检索方法重点在于特征提取,传统的特征提取方法或是不具有尺度不变性和旋转不变性,或是只能提取算法固定好的简单特征,无法在不同领域广泛应用。使用深度神经网络提取图像特征要远远优于传统的特征提取方法,通过引入多层网络结构能够对图像进行逐步分析,提取有效特征。因此,基于深度学习的方法成为图像处理领域的主流特征提取方法。
虽然深度学习的方法在数据驱动下发挥了重要作用,但在一些数据量较少或者数据质量不高的情况下效果欠佳。如在古生物领域,化石数据年代久远,在形成和挖掘时都会造成不同程度的损坏,而且化石形态主体与背景部分岩石相融合,难以区分,这就造成了古生物专家只能人工提取化石特征并复原古生物模型。由于人工提取的特征具有很强的主观性,导致许多古生物学家对相同物种的三维模型多次建模,不仅使得古生物三维模型的复用率低,而且多次建模使时间成本和制造成本非常高。而现有的基于深度学习的三维模型检索技术[5]无法有效提取化石图像特征,也就使得检索精度不高。因此,如果能有效提取古生物化石的特征,从而检索已有的古生物三维模型,对其进行复用,将节约大量的开支。
通过对化石图像的分析,结合计算机视觉领域的方法,本文提出一种古生物三维模型检索框架,通过输入化石图像实现模型检索。在基于视图方法的基础上,结合显著性图像分割网络对化石图像和三维模型多视图投影主体分割,再从主体分割图像中提取有效的特征进行匹配,为了得到更加精确的分割图像,采用一个残差结构的U型网络对主体边缘进行细化。在自建的古生物数据集上,通过实验验证了本文方法的有效性。
1 相关工作
基于视图的三维模型检索方法[6-7]不仅有效降低了三维模型的复杂性,并且可以借助优秀的二维图像处理算法实现三维模型的检索,其关键是视图的选择和特征提取。
常见的传统特征有尺度不变性(scale invariant feature transform,SIFT)[8]、傅里叶描述子[9]、Zernike moments[10]、方向梯度直方图(histogram of oriented gradients,HOG)[11]。Yi等人利用几何信息形状描述子和fisher形状描述子定义了一种新的深度形状描述子,这种描述符倾向于最大化类间边距,最小化类内方差[12]。Hsieh等在三维模型检索中采用了多种特征拼接和流形排序[13]。Zhao等人提取不同的视觉特征,并对多特征加权后融合实现三维模型检索[14]。Shih等人提出了高程描述符(elevation descriptor,ED),该描述子从三维模型中反映了6个不同视角的空间信息,对平移、旋转和伸缩具有较好的鲁棒性[15]。Wang等人利用三维模型视图集的尺度不变性,基于特定类数据和最大后验(maximum a posterior, MAP)准则的带类词汇实现检索[16]。
而随着深度学习的普及,各种深度学习网络被研究用于3D模型识别和检索,如PointNet[17]、3D ShapeNet[18]、VoxNet[19]和RotationNet[20]。同时,基于视图的三维模型检索方法也有了较大的提升,Su等人提出了一种新颖的CNN网络(multi-view convolutional neural networks,MVCNN),处理3D模型的多视图,提取信息作为3D模型描述符,MVCNN的重点是在完全连接之前进行特征融合[5]。RotationNet[20]将视点标签作为潜在变量,以对象的多视图图像作为输入,预测其姿态和对象类别。Liu等人提出一种检索框架,利用视觉和空间上下文共同实现代表性视图的选择和相似度量的计算[21]。Guo等人提出了一种由分类丢失和三重丢失共同监督的深度嵌入网络,将高维图像空间映射到低维特征空间,减少输入图像的类内变化,增加类间变化,该网络可以保证在学习的特征空间中相似的图像比不同的图像更接近[22]。Uy等人提出了一种新的深度嵌入方法,通过利用位置相关的自我中心距离场学习不对称关系[23]。Fu等人提出RISA-Net,旨在学习旋转不变的3D形状描述符,这些描述符能够编码细粒度的几何信息和结构信息,从而在细粒度3D对象检索任务中获得准确的结果[24]。Uy等人提出了一种联合学习方式,可以同时训练神经变形模块和检索模块使用的嵌入空间,使得网络能够学习变形感知嵌入空间,以便检索到的模型在适当变形后更适合匹配目标[25]。Guo等人提出了一种用于自监督表示学习的跨体系结构对比学习(cross-architecture contrastive learning,CACL)框架,使得模型能够从不同但有意义的对比中学习强表示[26]。
基于多视图三维模型的表示,近年来也有许多方法[27-28]。Gao等人通过不同的相似性度量方法,系统地评估了深度学习特征在基于视图的三维模型检索中的性能,探索了多视图深度学习网络体系结构中不同视图之间潜在关系[29]。Su等将复杂的基于多视图的相似性度量分解为多个基于单视图的相似性度量并进行融合,提出了MVGM方法,避免了传统高阶图的定义和计算难题[30]。Sfikas等人利用一组全景图,包括空间分布图、法线偏移图和其梯度图像的幅值表示三维模型[31]。Feng等人提出了一种GVCNN架构,在框架中添加了组模块,将所有视图划分为不同的组,并根据不同组的权值将描述符融合为形状描述符[32]。Hamdi等人引入了多视图转换网络 (multi-view transformation network,MVTN),基于可微渲染的最新研究进展实现3D形状识别的视点回归,MVTN可以与任何用于3D形状分类的多视图网络一起进行端到端的训练[33]。
为了能够有效提取具有复杂噪音的图像特征,本文对图像主体进行分割再进行特征提取。在图像分割领域,一些具有优异性能的网络模型被相继提出[34-39],这些模型具有较传统方法[40-43]更为优越的特征学习与表征能力,并且传统的方法无法同时捕捉局部细节和全局上下文,缺乏高层次的语义信息,限制了它们在复杂场景中检测整体显著对象的能力。受到U型网络结构[44-46]的启发,本文以ResNet[46]为主干网络,结合残差跳跃的方式构建残差结构的U型网络,对图像进行分割,同时为了细化边缘,采用一个小的残差连接的U型结构对边界的完整性进行补充。
2 本文方法
本文提出一种基于多视图和深度神经网络相结合的古生物三维模型检索方法,由于古生物化石数据难以收集,无法采用数据驱动的方式进行模型训练,因此,本文采用迁移学习[47]的思想进行模型迁移,整体算法框架如图1所示。
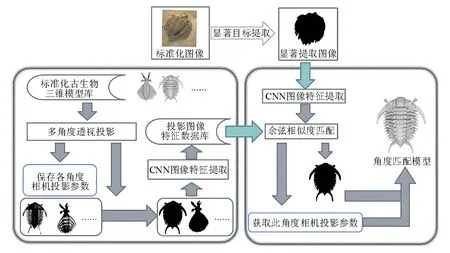
图1 算法框架图Fig.1 Algorithm frame chart
首先,为模型库中的三维模型进行多角度的二维投影,使之信息降维;然后,采用显著性图像提取网络对得到的二维投影图像进行边缘细化,并对细化后的投影图像提取特征,形成投影图像特征数据库。
对于输入的化石图像,由于在原始的二维化石图像中,岩石部分和其他噪音对化石主体部分的影响十分严重,并且三维模型与其投影图像都不具有色彩信息,因此,采用显著性图像提取的深度网络进行主体提取。受U-Net[44]和SegNet[35]的启发,本文的显著性图像提取网络在此基础上进行修改来适应古生物数据,采用DUTS图像分割数据集对网络进行训练,并进行模型迁移以适应古生物图像数据。
在特征提取部分,采用显著图像提取网络提取1 024维的特征向量,再使用余弦距离度量方法进行图像匹配,通过所得到的匹配原始输入图像的二维投影图像,就能够得到所匹配的三维模型。此外,在训练时,对训练数据进行平移、旋转、缩放与对称映射等预处理操作,以此使显著图像提取网络学习到一定的平移不变性、旋转不变性与尺度变换不变性[48]。
2.1 三维模型透视投影
三维模型信息较多且复杂,直接对三维信息进行处理不仅会增加计算成本,也不适用于采用二维化石图像对三维模型的检索。因此,需要将三维模型转换成便于处理的二维图像,不仅使后续处理的对象更加简单统一,而且能够充分利用图像处理领域中性能卓越的卷积神经网络。
在将三维模型转换为二维图像时,采用透视投影法将物体形状投射到多个投影面上,从而得到各个视角的投影图像。图2展示了多视图投影的设置,三维模型被一个正方体包围,在正方体的6个面中心和8个顶点处设置摄像机,所有虚拟摄像机都指向三维模型的中心。对于每个三维模型,14个虚拟摄像机可以投射14个不同的视图。这14张投影图像包含三维模型的大部分特征,包括形状、纹理和其他常见特征。利用这些信息,本文的方法可以准确判别不同的三维模型。
在透视投影计算中,式(1)说明了三维点云投影在二维平面的具体计算。其中:(Px,Py,Pz)是三维点云坐标;Aspect是投影平面的纵横比;θ是相机视点与三维模型中心连线和世界坐标系y轴之间的夹角,用来调整摄像机的位置,随着θ的改变,相机位置也在做相同的同心圆变化,以此来得到多角度透视投影。
(1)

图2 三维模型多角度投影示意图Fig.2 Schematic diagram of multi-angle projection of 3D model
2.2 显著性图像提取
古生物化石图像背景复杂,噪音极多,存在由于模型边缘部分点云的离散分布而造成投影图像边缘模糊问题。因此,本文采用显著性图像提取的方法对化石图像和投影图像进行处理,提取图像的边界和形状信息,以达到更好的检索结果。考虑到古生物图像数据获取难度大并且质量较差,因此,采用迁移学习的思想进行数据迁移训练,其网络结构如图3所示。该网络结构的前部分采用一个粗估计的编码器-解码器网络得到输入图像的粗分割特征图,因为这类结构能够同时获取高等级的全局信息和低等级的细节信息,后部分采用一个残差修正模块对分割特征图进行细化得到最终结果。
分割网络的编码部分使用预训练好的ResNet-50[46]中的bottleneck模块对图像的多尺度特征进行提取,然后,采用空洞卷积池化金字塔(atrous spatial pyramid pooling,ASPP)[36]将高级语义信息传递到各个级别的解码部分。从图3可以看到,解码部分的特征图由编码部分对应层的特征图、解码部分前一层经过2倍上采样之后的特征图和空洞卷积池化金字塔不同比率的上采样得到的特征图相加而得到。其中,空洞卷积池化金字塔结构如图4所示,空洞卷积在不降低空间维度的前提下增大了相应的感受野指数,从而提升分割网络的性能,并使用不同空洞率的多个并行空洞卷积捕捉特征图的多尺度信息。其中,一维卷积和图像级的最大池化有效地克服了空洞卷积空洞率过大时退化为一维滤波器的问题。最后,将一维卷积、{6,12,18}空洞率的空洞卷积、最大池化所得到的特征图按通道拼接经过一维卷积得到空洞卷积池化金字塔的输出。
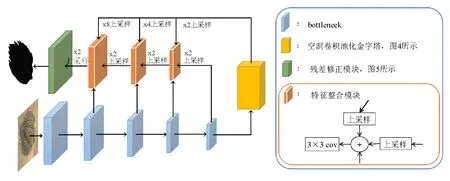
图3 显著性图像分割网络Fig.3 Significance of image segmentation network
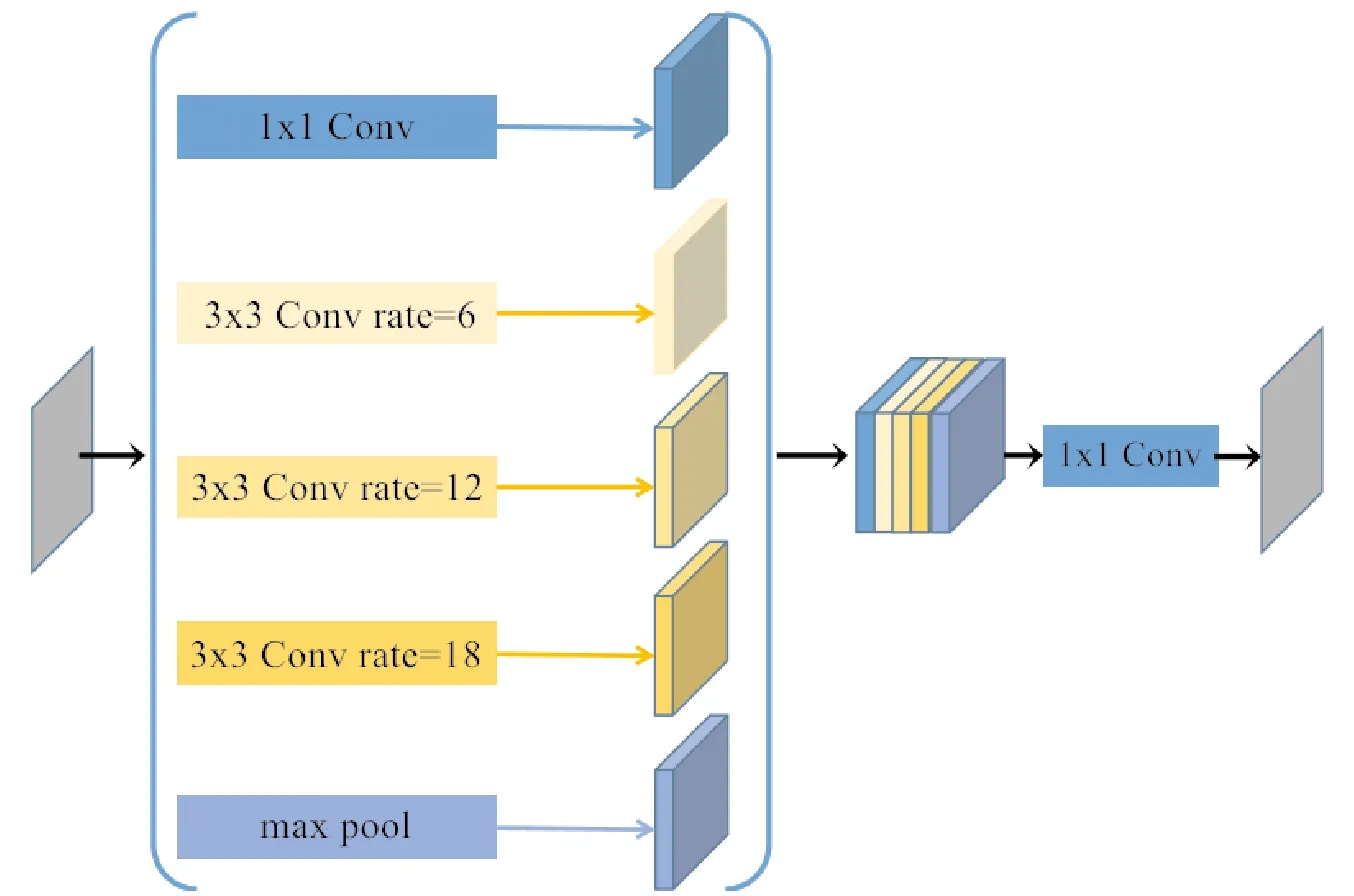
图4 空洞卷积池化金字塔模块结构Fig.4 Module structure of atrous spatial pyramid pooling (ASPP)
在采用粗估计的编码器-解码器网络得到的显著图像提取结果存在明显的区域和边界缺陷的问题,而在二维原图搜索三维模型投影图的框架中,其主要的特征都在其边界和形状上,因此,本文构建了一个残差修正模块(residual refinement module, RRM)对边界和形状进行细化,其网络结构如图5所示。该残差优化模块利用残差编码器-解码器架构,主要架构包括一个输入层、编码器、残差连接、解码器和输出层。和粗估计模块不同,编码器和解码器有4个阶段。编码器每个阶段只有一个卷积层,每一层有64个滤波器,大小是3×3,后面跟着一个批量归一化层(batch normalization,BN)和一个非线性层(rectified linear unit,ReLU),并使用非重叠的最大池化(max pooling)层。解码器与编码器的结构类似,是将编码器最后的最大池化层替换为双线性插值进行上采样。这个残差修正模块的输出就是模型最终的特征图输出。

图5 残差修正模块结构Fig.5 Residual refinement module structure
3 实验分析
本文提出的框架基于python和PyTorch框架实现。三维模型多角度投影初始化角度为0°,投影平面长和宽都为512像素,近截面距离为5像素,在正方体面投影的远截面距离为20像素,每次投影变换角度为90°,使得模型在正方体8个顶点和6个面都得以投影。显著图像提取和特征提取实验都使用Adam优化器进行,其权重衰减为5×10-4,初始学习率为5×10-5, 每20个epoch降低为原来的1/10。网络共训练了40个epoch。网络的主干参数(ResNet-50[46])用ImageNet数据集[37]上预先训练的相应模型初始化,其余的随机初始化。消融实验在DUTS数据集上进行。
3.1 数据集
本文使用以下两部分数据集:一是常用于图像分割领域的图像数据集,包括DUTS、DUT-OMRON、ECSSD和SOD,其中,训练采用DUTS数据集,其他数据集用于测试。训练集和测试集都包含了常见的场景,用于显著性检测。另一部分数据集是用于古生物三维模型检索,其中包括43个古生物模型,分别有8类,这些古生物模型都是在古生物学家的指导下制作的高质量标准姿势的模型;还使用了在网络上收集到的高质量现生生物的模型进行数据集扩充,包含76个三维模型,分别由14类组成,这部分模型共计119个,22类。
实验平台为NVIDIA Quadro RTX 4000 8GB显卡,英特尔Core(TM)i9-9900K CPU @ 3.6GHz处理器,操作系统为64位Windows 10。
3.2 显著图像提取网络预设参数
预训练模型采用在ImageNet数据集上训练好的ResNet-50模型,损失函数采用交叉熵函数,显著图像提取网络的初始化学习率为0.000 05;通过迁移学习的方式,使用DUTS数据集进行网络训练;在消融实验上采用常用的MAE、F-measure、Dice、IOU等指标对显著图像分割进行评价。
3.3 消融实验
本节证明网络中加入的空洞卷积池化金字塔模块结构(ASPP)和残差修正模块(RRM)的有效性。对这两个模块进行消融实验,并评估最大F值(max-F),平均绝对误差(MAE),平均F值(mean-F),平均dice值(mean-Dice),平均IOU(mean-IOU)等指标。表1为消融实验结果。
消融实验对不同模块进行测试,其主干网络都是采用ResNet-50,表1中第1行展示了以采用特征金字塔(feature pyramid network,FPN)结构的主干网络为基线进行显著图像提取的结果,再搭配不同的模块进行实验,可以看到评价分割结果的指标都有不同程度的提升;表1中第2行展示了搭配空洞卷积池化金字塔模块结构(ASPP)融合的不同尺度的全局信息,使网络能够更关注突出目标的完整性,极大地提高了显著性图的质量;表1中第3行展示了搭配的残差优化模块(RRM)可以有效关注局部的边界信息,从而对网络产生性能增益;通过在基线中引入空洞卷积池化金字塔模块和残差优化模块(表1的最后一行),与上述两种情况相比,在F-measure和MAE等多个评分上,其表现可以得到进一步提高,这说明空洞卷积池化金字塔模块和残差优化模块是两个互补的模块。利用它们使本文的方法具有很强的准确发现突出目标和细化细节的能力。图6展示了采用粗估计的编码器-解码器网络得到的部分结果,即未经过残差修正模块细化的实验结果,是消融实验的定性结果展示。
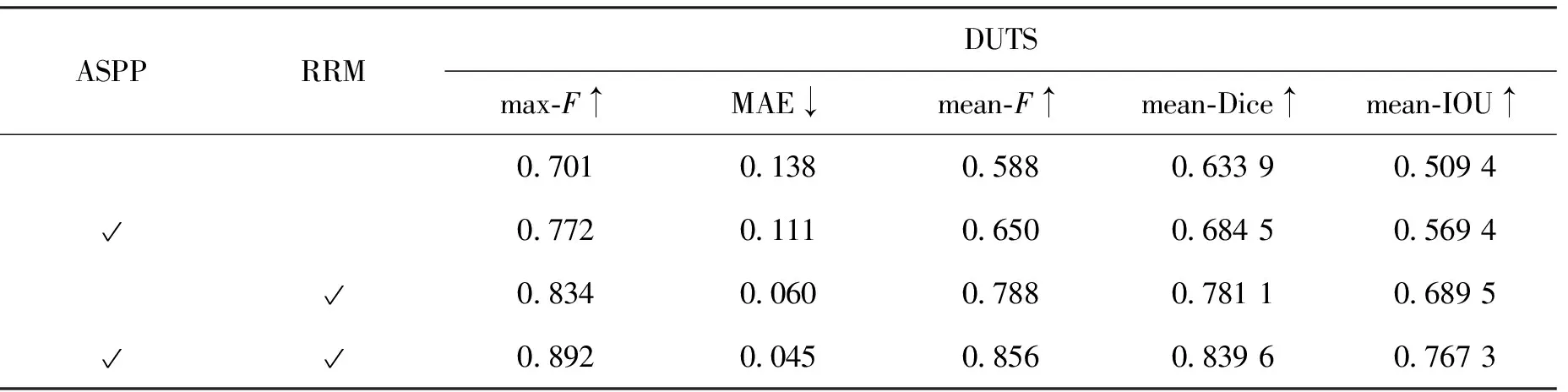
表1 消融实验Tab.1 Ablation experiments

图6 显著图提取中间结果Fig.6 Significant graph extraction intermediate results
3.4 与其他网络对比
将本文方法分别与SRM[49]、PiCANet[50]、poolnet[51]等用于显著图像提取的网络进行对比,并在4个广泛应用于显著图像提取网络的数据集上进行测试,在不同的数据集上测试网络的泛化性能。从表2可以看到,本文的网络在DUTS数据集测试下,表现了优异的性能,同时在不同的数据集上,其泛化性能也比其他的分割网络要好。

表2 评价结果Tab.2 Evaluation results
除表2之外,还展示了4个网络在DUTS数据集上不同阈值下的F-measure曲线(见图7)和PR(precision-recall)曲线(见图8)。从图7可以看到,在不同的阈值下,本文网络的F-measure都高于其他的网络结构,也就说明本文网络的综合性能要高于其他网络。在图8中,本文网络的PR曲线相比对比方法的PR曲线更加突出,阈值在极端情况下,也就是当达到0.96以上时,poolnet的性能略高,但是在大多数情况下,本文的网络有着更准确和完整的分割效果。
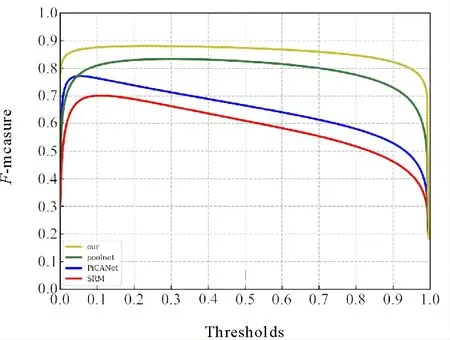
图7 不同阈值下的F值Fig.7 F values under different thresholds
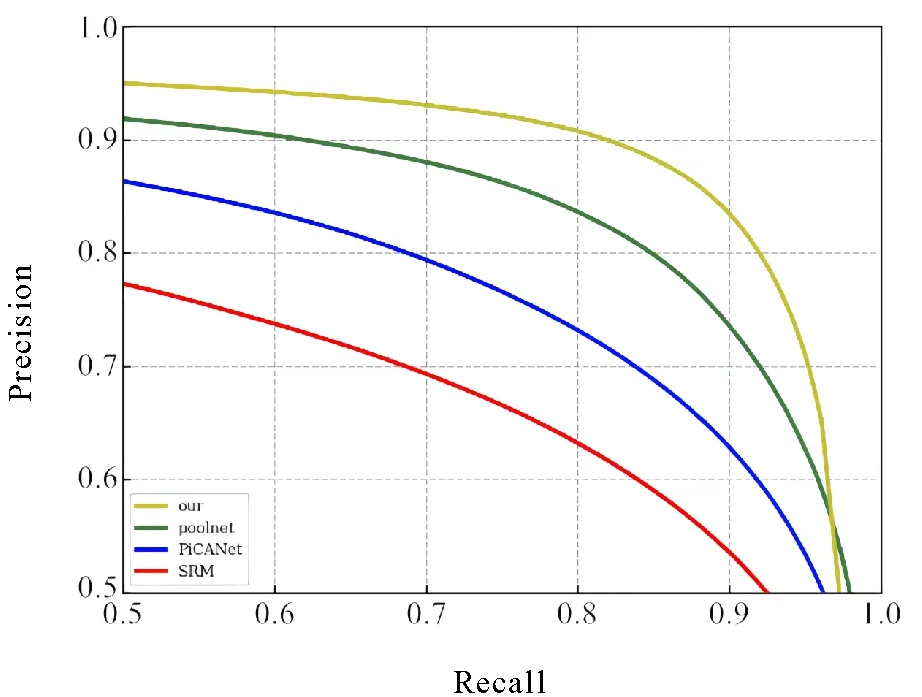
图8 PR曲线 Fig.8 PR curve
图9展示了定性评价结果,可以看到,图9A展示了在DUTS数据集上的部分分割结果,本文的网络在边界和细节处提取的结果更为明显和准确;图9B展示了在古生物图像上的部分分割结果,在古生物数据集上,本文的显著图像提取网络也较为适用,边界的局部性特征和全局的完整性特征都能够得到非常好的处理。

图9 部分显著图像分割结果展示Fig.9 Shows the significant image segmentation results
3.5 三维模型检索性能对比
本文的网络和实验的最终目的是为了以化石图像或者复原图等自然图像对三维模型进行检索,使用自建的古生物三维模型数据集将本文方法和HOG-SIL[52]、CDMR[53]、BF-FGALIF[54]、SBR-VC NUM 100[55]、MVGM[30]进行实验对比,采用以下几个评分标准。
最近邻准确度(nearest neighbor,NN)是准确查询到的三维模型占查询总数的比例,值越大表示检索越有效。式(2)中TP表示查询准确的三维模型个数,SUM表示查询模型总个数。
(2)
综合评价指标(F-measure,F)是衡量查询性能的一项指标,式(3)中β参数为1,表现出对查准率和查全率给予相同的权重比较。
(3)
为了让排名越靠前的结果越能影响最后的检索结果,采用折损累计增益(discounted cumulative gain,DCG)作为评价手段之一。其中,G(i)表示当前第i项的检索结果与查询目标同类时为1,否则为0,实验中每个检索按照相似度排序取前10个模型投影来计算每个检索的折损累计增益。
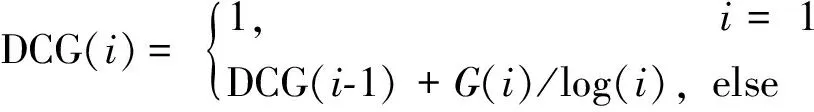
(4)
用mAP(mean average precision)来衡量此算法在所有测试集上的总性能,式(5)展示了其计算方法。其中,K表示检索的同类模型个数,index(i)表示检索模型在检索排序列表中的位置,N表示总检索数目。
(5)
采用以上几个评价标准对本文方法和其他方法进行比较,结果如表3所示。其中:HOG-SIL[52]使用方向梯度直方图(histograms of oriented gradient,HOG)特征来实现三维模型检索;CDMR[53]是一种选择性搜索的方法;BF-FGALIF[54]和SBR-VC NUM 100[55]是两种基于草图的粗粒度检索方法;MVGM[30]方法是一种无监督的三维模型多视图检索算法,使用在ImageNet数据集[37]上预训练的AlexNet[56]提取视图图像特征。通过表3可以看出,在自建的古生物数据集上,本文方法在各项指标上都表现出优异的性能,一方面是本文方法融合的深度神经网络对化石显著图像和投影显著图像的特征提取非常有效,能够提取到有效的形状特征,另一方面也说明,本文方法能够有效适用于以化石等具有复杂背景和噪音的图像检索与其形状相似的三维模型的任务。
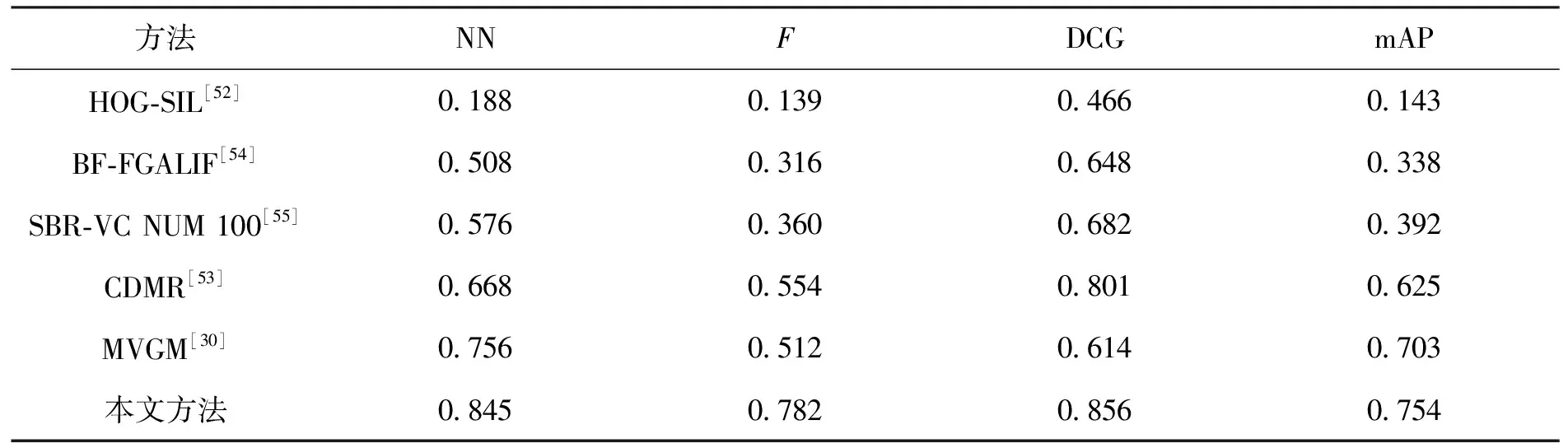
表3 本文检索方法与其他方法评价结果Tab.3 Evaluation results of retrieval methods in this paper and other methods
4 结语
本文针对古生物信息学领域中古生物三维模型复用率低和古生物三维模型制造成本高两个问题,提出了一种基于多视图和显著性图像分割的古生物三维模型检索方法。由于在地质变迁过程中,化石形态可能会发生不同程度的变形,导致用来检索的化石图像质量差,本文提出的方法通过对三维模型的多个角度进行投影来弥补这种影响,然后,利用显著性图像分割网络进一步对图像处理,以提高三维模型检索的性能。实验结果证明了本文方法对古生物化石数据和古生物三维模型匹配的有效性,并且在自建的数据集上具有较好的性能。
未来,将从以下两个方面对本文的工作进行扩展和改进:
1)基于多视图和显著性分割网络相结合的古生物三维模型检索方法虽然对古生物数据有良好的适应性,但是多角度投影还是增加了算法的时间和空间复杂度,下一步可以尝试在模型投影方面寻找最佳角度进行投影,从而减少算法的时间和空间消耗。
2)目前的各种类古生物数据量还不具备以一个数据驱动的方式进行模型检索,因此,古生物数据集还需要进一步扩充。
