基于约束优化的Petri网可达性FIJ模型
2022-07-20王慧英周恺卿
王慧英,周恺卿,周 辉
(1.重庆工程学院计算机与物联网学院,重庆 400056;2. 吉首大学信息科学与工程学院,湖南 吉首 416000;3. 湖南中医药大学,湖南 长沙 410208)
1 引言
随着社会的进步,科技的不断创新,计算机系统结构也变得愈加复杂,Petri网的出现给计算机系统带来了新的表现形式。而随着Petri网的利用率越来越高,Petri网的可达性就越高,Petri网中的伪标识也随之增加,如何有效地去除Petri网中的可达性伪标识一时之间成为人们争相讨论的热门话题。当传统的可达性伪标识判定方法满足不了更新后的Petri网可达性伪标识的判定,提出一种行之有效的判定方法成为必要。
郑学恩等人提出基于面向对象Petri-net的LWF建模方法。该方法首先基于跃迁状态转移机制确定Petri网的虚拟托肯标识,并将Petri网中LWF从无限循环的活锁状态转变为可计数的有限循环迭代状态;再基于获取的托肯标识对Petri网进行可达性分析;最后依据分析结果构建Petri网可达性伪标识判定模型。由于该模型未能利用独立成分分析方法对Petri网中的数据特征进行提取,导致该方法构建的模型在运行时CPU的占用率较高。王媛媛等人提出基于逻辑Petri网的模型修正方法。该方法首先利用一致性检测技术计算数据的最优校准度,并通过标识数据库对偏差位置进行定位;再依据逻辑校准和逻辑最优校准的定义对Petri网中的异常数据进行校正处理;最后基于最优校准的计算拟合度构建Petri网可达性伪标识判定模型。该方法由于未能依据获取的独立成分偏度对Petri网数据进行排序,导致该方法构建的模型在进行伪标识判定时的网络路径覆盖率低。翟禹尧等人提出基于层次广义随机Petri网的测试性建模方法。该方法首先基于依据层次广义理论对Petri网中的数据进行层次化处理;再依据层次划分的结果构建分层GSPN模型;最后将Petri网中的数据放入模型中进行求解,从而实现对Petri网可达性伪标识的判定。该方法由于未能通过对Petri网数据集正交矩阵计算,获取Petri网数据的独立成分偏度,所以该方法构建的模型在进行伪标识判定时的判定效果较差。
为解决上述Petri网可达性伪标识判定模型构建时存在的问题,提出基于约束优化的Petri网可达性伪标识判定模型构建方法。
2 特征提取
利用独立成分分析法对Petri网中数据进行降噪处理,再基于UICA算法对降噪后的数据进行特征提取。
2.1 数据降噪
2.1.1 查找异常数据
基于约束优化原理寻找Petri网中的异常数据,并对其进行灵活性表示。


(1)
式中,Petri
网数据的期望系数为γ
,G
为Petri
网数据中的约束条件。获取的Petri
网中的异常数据如下式所示
(2)
式中,Petri
网数据中的异常数据指数为σ
,,…,,获取的Petri
网异常数据为s
,,…,。2.
1.
2 降噪基于上述计算结果将查找出的异常数据进行剔除,再利用主成分分析法对Petri
网中的数据进行降噪处理。首先利用主成分分析法在Petri
网中构建一个三维坐标系,设定坐标中x
处的数据向量为Z
(x
),且Z
(x
)=[Z
(x
),Z
(x
),…Z
(x
)]=S
(x
)+N
(x
),其中,Petri
网数据的p
维信号以及噪声向量分别用S
(x
),N
(x
)表示。通过MNF
(最大噪声分量)变换法则将Petri
网中的数据进行线性变换处理,过程如下式所示
(3)
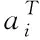

(4)
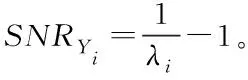
2.2 特征提取
基于独立成分分析方法将去噪后的Petri网数据进行特征提取。
设定Z(x)为Petri网中的原始数据向量,经过MNF变换后的数据向量为Y
(x
)。对Y
(x
)中的前k
项进行保留,其余的p
-k
项归零处理,从而获取Y
(x
)的前k
项数据集,并对其进行MNF
反变换,过程如下式所示
(5)
式中,获取Y
(x
)的前k
项数据集为Y
()(x
),MNF
反变换后获取的数据集为Q
(x
),a
为变换时的转换量。基于上述计算结果,构建该数据集的正交矩阵,过程如下式所示
(6)
式中,A
为构建的Petri
网数据集的正交矩阵。依据三阶中心距对矩阵进行计算,获取各个数据的独立成分偏度,过程如下式所示det(Q
)=det(0)°det(A
)=0(7)
式中,获取的数据独立成分偏度为det(Q
)。依据获取的独立成分偏度对数据进行排序,从而获取Petri网数据的特征。3 构建伪标识模型
基于LDA算法对获取的Petri网数据特征进行计算,从而获取Petri网的边界特征向量;再依据获取的特征向量,构建Petri网可达性伪标识判定模型。
3.1 边界特征向量
基于LDA原理可将Petri网中数据样本之间的距离进行压缩,扩展类别间的边界,从而降低类别边界的信息干扰。将LDA算法加入类别边界公式中,以边界最大化为目标获取Petri网的特征变换轴。利用多类问题的类内离散度对Petri网中的类别区间边界进行计算,过程如下式所示


(8)
式中,获取的Petri网中类别区间为D
(ω
,ω
),β
,α
为Petri
网中的系数,β
∈[0,1],α
∈[0,1],且β
+α
=1,用来调节均值方差和方差差异对边界的影响,Petri
网中的类别样本均值为u
,方差为σ
。将Petri
网中原始高维数据沿着向量p
进行变换,过程如下式所示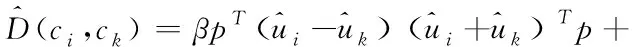
α
|p
(i
-k
)p
|-p
(i
-k
)p
(9)
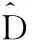

(10)
式中,获取的Lagrange函数表达方式为L
(p
,λ
),λ
为Petri网中的有效特征值,相对应的有效特征向量用p
表示,CS为Lagrange函数中的系数。基于上述计算结果对上式进行偏导,偏导过程如下式所示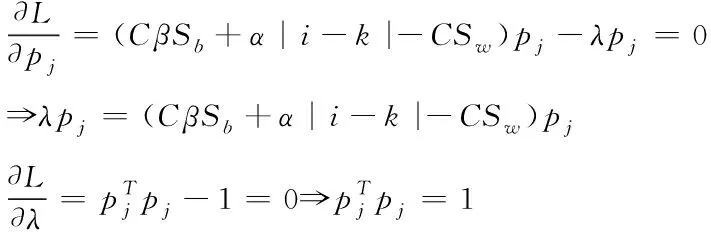
(11)

3.2 Petri网可达性伪标识判定模型构建
基于上述获取的边界最优特征值,利用支持向量机构建Petri网可达性伪标识判定模型。
首先将Petri网中的数据进行聚类处理,将Petri网中的数据分为C个类别,再随机选取其中的类别,将该类别与其余类别进行对应的特征向量提取。基于提取的C-1组特征向对Petri网的原始数据进行数据变换,获取C-1组的Petri网变换数据,并利用支持向量机对其进行训练,获取C-1个分类模型,过程如下式所示

(12)
式中,各个子模型的输出为f
(x
),模型输出为y
,组合参数为γ
。设定组合中的参数如下式所示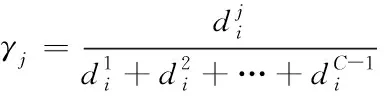
(13)
将该步骤进行迭代计算,直到提取出Petri网数据中所有特征向量。由此构建Petri网可达性伪标识判定模型
Y
=sgn(y
γ
)(14)
依据上述构建的分类模型,完成Petri网中可达性伪标识的判定。
4 实验验证
为了验证上述模型构建方法的整体有效性,需要对此方法进行测试。
4.1 实验环境设置
实验环境具体如表1所示。

表1 测试环境选择
在上述实验环境下,分别采用基于约束优化的Petri网可达性伪标识判定模型构建方法(方法1)、基于面向对象Petri-net的LWF建模方法(方法2)、基于层次广义随机Petri网的测试性建模新方法(方法3)进行测试。为了保证实验结果的准确性与可靠性,在实验过程中需保证实验条件的一致性。
4.2 实验结果及分析
1)随机选取Petri网中不同的数据,对方法1、方法2以及方法3在模型运行时的CPU占用情况进行检测,检测结果如表2所示。

表2 不同方法的CPU占用情况检测结果
依据表2可知,方法1构建的Petri网可达性伪标识判定模型在运行时的CPU占用率要低于方法2以及方法3,并且方法1能够在数据较大的情况下依然能将CPU占用率稳定在75%以内。这主要是因为方法1利用了独立成分分析方法对Petri网中的数据特征进行了提取,所以该方法构建的可达性伪标识判定模型在运行时的CPU占用率低。
2)在Petri网中添加一组杂乱数据,对方法1、方法2以及方法3的网络路径覆盖性能进行检测,检测结果如表3所示。

表3 不同方法的网络路径覆盖性能检测结果
分析表3可知,方法1构建的判定模型在对Petri网可达性伪标识进行判定时网络路径覆盖率要高于方法2以及方法3,并且在第一组与第五组路径杂乱的情况下,依然可以将检测出的路径覆盖率稳定在90%以上。方法2虽然在第三组网络路径相对规整的情况下能够将检测出的覆盖率稳定在90%以上,但是该方法在路径杂乱的情况下,路径覆盖率不太稳定。方法3对比方法1和方法2来看,路径的覆盖率较低。
3)构建一个虚拟化的Petri网,并在该Petri网中随机选取若干数据,对方法1、方法2以及方法3构建模型的判定效果进行测试,测试结果如表4所示。

表4 不同模型的判定性能测试结果
依据表4可知,方法1构建的判定模型,检测出的误判与漏判个数均维持在5个以内。方法2虽然也可以将误判个数维持在5个以内,但是该方法的漏判个数却高达10个。而方法3构建的判定模型在对Petri网可达性伪标识进行判定时的误判漏判个数均在10个以上,综上所述方法1构建模型的判定性能要优于方法2以及方法3。
综合分析上述实验结果可知,本文方法在CPU占用率、网络路径覆盖率以及判定效果方面均优于现有方法,说明其针对Petri网可达性伪标识进行判定得出的结果具备较强的可靠性。
5 结束语
近几年,随着网络技术的不断发展,Petri网的利用率也随之增加。Petri网的出现成功地使计算机系统变得简单,但是随着使用次数的增加,Petri网数据的可达性也随之增加,此时对Petri网中的可达性伪标识判定成为重中之重。针对传统判定方法中存在的问题,提出基于约束优化的Petri网可达性伪标识判定模型构建方法。该方法首先基于独立成分分析方法将Petri网中的数据进行特征提取;再利用支持向量机对获取的数据特征进行训练,构建Petri网的可达性伪标识判定模型,从而实现对Petri网中可达性伪标识的判定。由于该方法在数据去噪时还存在一定问题,今后会针对这一缺陷继续对该模型构建方法进行优化。
