近红外光谱和支持向量机用于凌霄花产地鉴别
2022-07-13王燕李颖叶桦珍李泳宁徐杰林振宇
王燕,李颖,叶桦珍,李泳宁,徐杰,林振宇
(1. 福建卫生职业技术学院药学院,福建 福州 350101; 2. 厦门海洋职业技术学院海洋生物学院,福建 厦门 361102; 3. 江苏省食品药品监督检验研究院,江苏 南京 210019; 4. 福州大学食品安全与生物分析教育部重点实验室, 福建省食品安全分析与检测技术重点实验室,福建 福州 350108)
0 引言
凌霄花原名紫葳,始载于《神农本草经》,为紫葳科植物凌霄或美洲凌霄的干燥花,具有活血通经、凉血祛风的功效,主要用于治疗月经不调、经闭症瘕、产后乳肿、风疹发红、皮肤瘙痒和痤疮等[1]. 凌霄花作为我国传统中药,来源广泛,主产于我国东部和中部省份. 不同产地的凌霄花化学成分存在显著差异,对其质量和药效影响较大[2-4]. 因此,鉴别不同产地的凌霄花对其药材的质量控制具有重要意义.
目前, 凌霄花产地鉴别的方法主要有高效液相色谱法[5]、高效液相色谱-串联三重四极杆质谱[6]和胶束电动毛细管色谱法[7]等理化分析法,但这些方法均需对样品进行破坏性处理, 检测过程费时费力,且消耗试剂多. 近红外光谱(near-infrared spectroscopy, NIRS)技术作为一种现代仪器分析方法,具有检测快速、处理简便、对样品无破坏和无需化学试剂等优点,已被广泛应用于中药材的产地鉴定与质量评价[8-12].
本研究通过采集6个不同产地凌霄花的近红外光谱数据,建立支持向量机(support vector machine,SVM)模型来鉴别不同产地凌霄花,并采用竞争自适应重加权采样(competitive adaptive reweighted sampling,CARS)变量选择方法筛选波长变量,以期实现对不同产地凌霄花的快速鉴别分析.
1 材料与方法
1.1 样品的采集与制备
凌霄花药材采集于山东(45份)、江苏(99份)、河南(25份)、河北(52份)、云南(22份)和广西(28份)6个省,共计271个样品,用作建模分析. 所有样品经福建中医药大学杨成梓教授鉴定,均为紫葳科植物凌霄的干燥花. 每个样品利用超微粉碎机粉碎,过90 μm孔径的筛网,置于60 ℃的烘箱中烘干至恒重,编号并置于干燥器中密封保存.
1.2 光谱数据的采集
实验采用Antaris Ⅱ型傅里叶变换近红外光谱仪(美国Thermo Fisher公司),光谱分辨率为8 cm-1,扫描范围为4 000~10 000 cm-1,共扫描32次. 以空气作为检测背景,采集环境为室温25 ℃,空气湿度为60%. 每个样品采集3条光谱,运用Matlab(R 2017a)编写程序对扫描所得的光谱数据进行分析.
1.3 训练集和测试集的划分
采用Kennard-Stone算法将样本按9∶1的比例划分为训练集样本与测试集样本,如表1所示. 训练集样本用于建立凌霄花产地鉴别模型,测试集样本用于验证模型对凌霄花样品的预测能力.
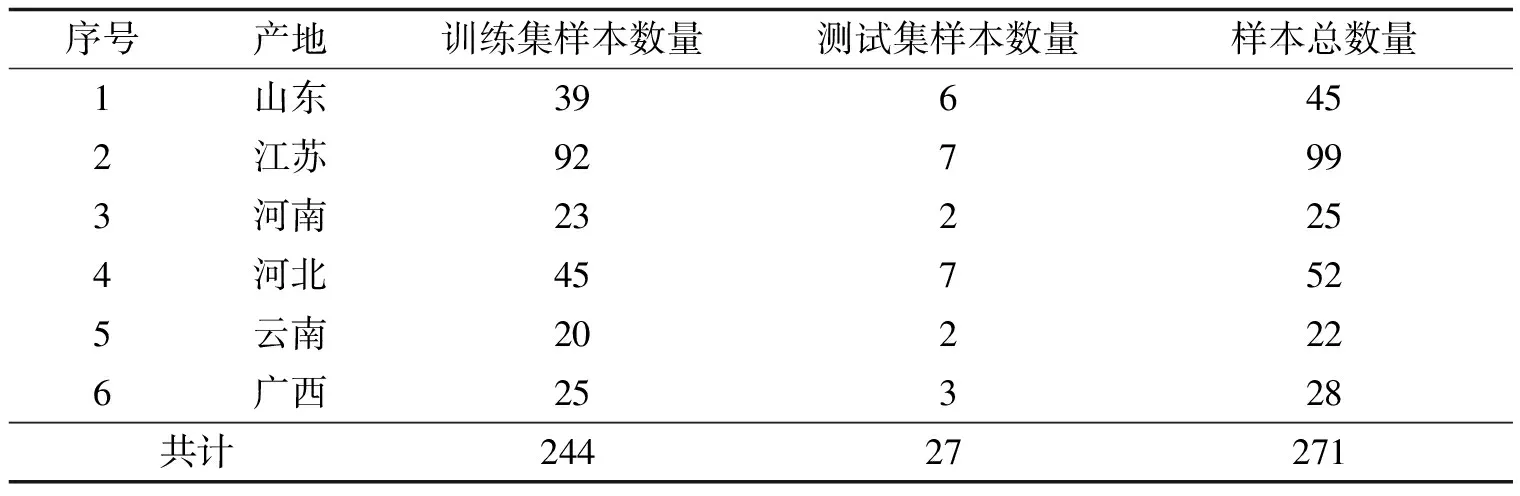
表1 凌霄花产地来源及样本集划分
1.4 模型建立及特征变量筛选
SVM是由Vapnik[13]提出的一种用于分类和回归分析的监督模式识别方法,具有良好的泛化性能和准确的预测能力. SVM算法将训练数据映射到高维空间,在分类误差最小的情况下寻找最优超平面. 利用特征空间中种类分布边缘的训练集样本来定位最优超平面,并定义最大边界超平面的训练集样本为支持向量, 而所有其他对超平面位置估计没有贡献的训练集样本都可以丢弃. 因此,SVM通过使用少量的训练集样本即可获得较高的分类精度.
为实现原始数据到高维空间的映射,在SVM中引入核函数. 核函数包括线性函数、径向基函数(RBF)、多项式和S型函数. 由于RBF在校准过程有效且快速[14],本研究采用RBF作为SVM分类的核函数. RBF核函数的公式如下:
其中:x和y分别表示不同样本的测量数据;σd表示径向基核函数的宽度,其值需要在模型优化过程中确定.
在建模的过程中,NIRS变量含有大量冗余信息,不仅增加模型的复杂程度,还降低模型预测的准确性. 当相关性不强的变量过多时,从大量的光谱变量中提取出对建模有用的特征变量,可简化模型,提高模型的稳定性与准确性. CARS是一种提取特征变量的方法. 该方法模仿达尔文进化理论中的“适者生存”原则,根据CARS技术搜寻与所测性质相关的最优波长组合,从而达到简化模型、提高模型预测能力的目的[15].
2 实验结果与分析
2.1 光谱分析
图1(a)为6个不同产地凌霄花在4 000~10 000 cm-1的近红外平均光谱图. 其中,4 400~4 800 cm-1的特征吸收峰是C—H伸缩振动与弯曲振动的组合频、O—H伸缩振动的倍频,5 000~5 100 cm-1的特征吸收峰是O—H伸缩振动与弯曲振动的组合频,5 800~6 000 cm-1的特征吸收峰是C—H伸缩振动的倍频,6 800~7 050 cm-1附近的特征吸收峰是O—H伸缩振动的倍频. 如图所示,不同产地的凌霄花样品的峰强度差异可能是由于不同产地的凌霄花样品中所含的主要活性物质,如麦角甾苷、环烯醚萜、三萜和黄酮等含量不同而造成的,但总体相似性很高,因此需要进一步建立模型进行判别.
2.2 光谱预处理
在建立模型之前,为消除样品物理性质和噪声等因素对样品光谱的影响,需要对光谱进行一定的预处理. 本实验分别采用多元散射校正、一阶导数、标准化、均值中心化、矢量归一化和标准正态变量变换方法对样本的原始光谱进行预处理,最后选择预处理效果最佳的一阶导数作为光谱预处理方法,如图1(b)所示.
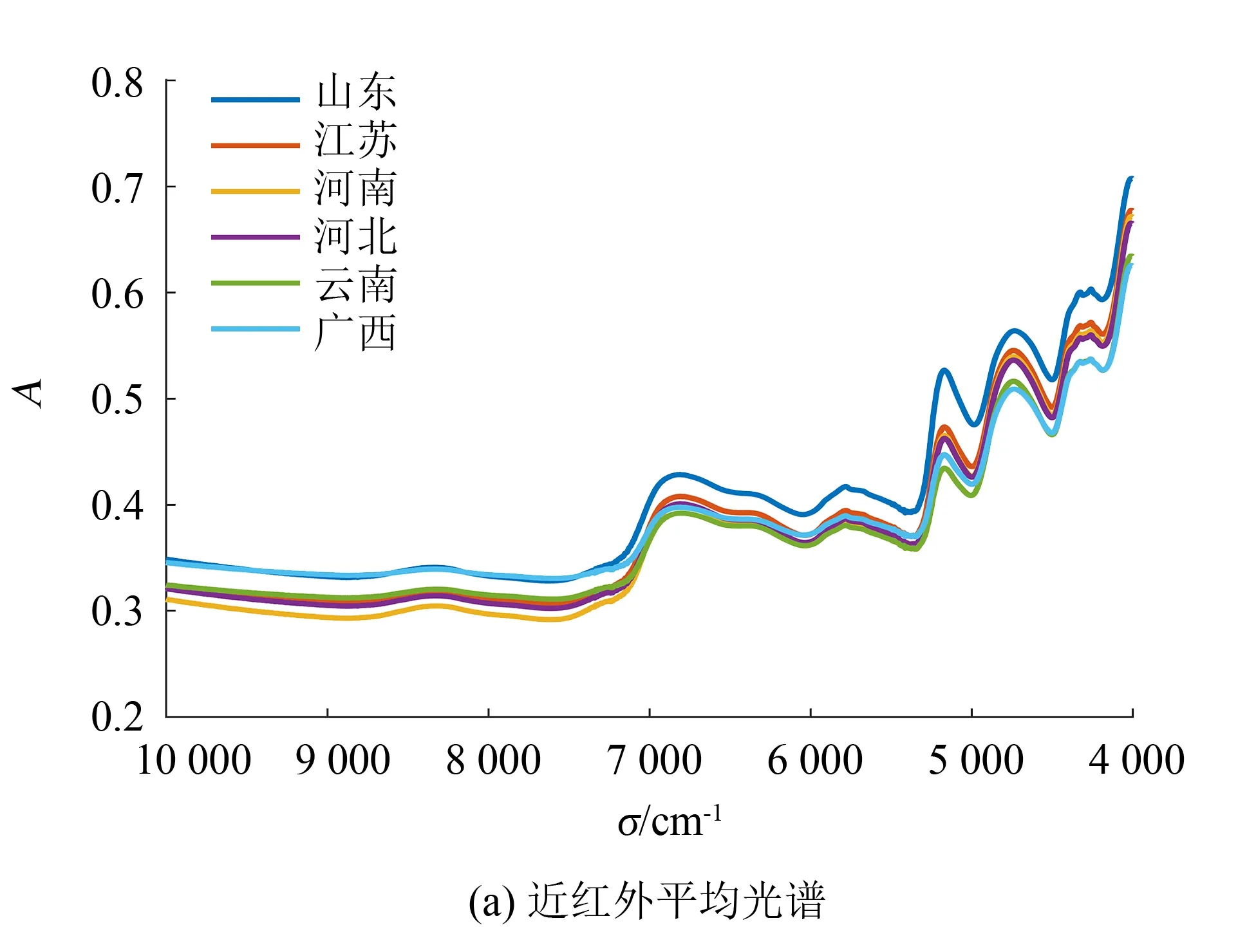
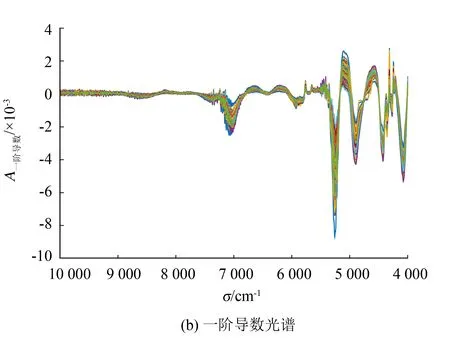
图1 凌霄花的光谱图
2.3 主成分分析
图2(a)为凌霄花样品前两个主成分(PC1和PC2)的得分聚类图. 从图中可以看出,训练集和测试集的样本整体呈均匀分散状态,说明样本集的划分是比较合理的. 为观察样本是否可能聚类,对其进行主成分分析,结果如图2(b)所示. 前3个主成分(PC1、PC2和PC3)的累积方差贡献率达99.43%,说明前3个主成分可以代表近红外光谱中99.43%的化学信息. 从图中可看出,不同产地的样品之间存在粗略的分离,但重叠仍然很明显,分类效果不是很理想. 因此,需要进一步建立模型对凌霄花的产地进行鉴别.
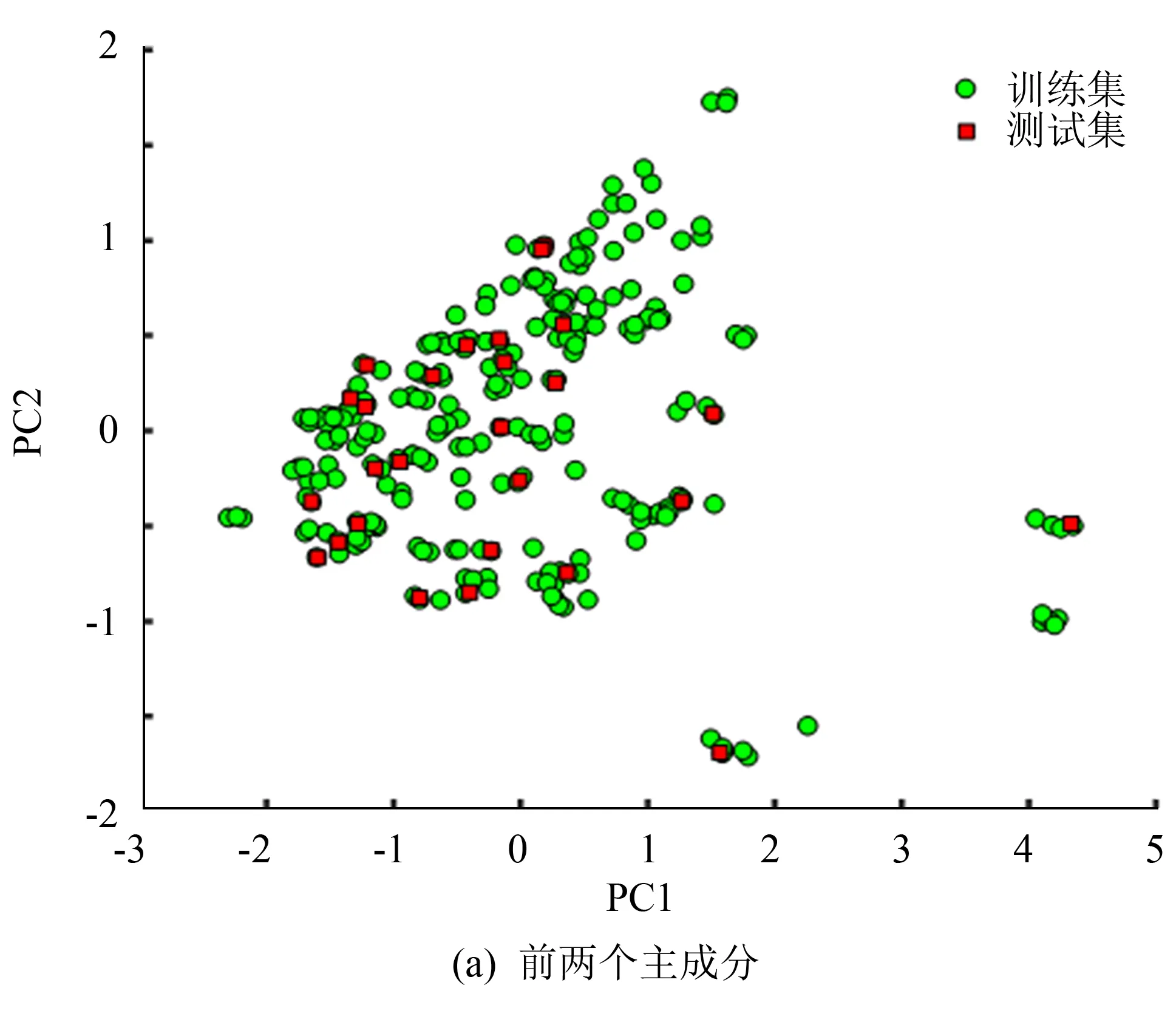
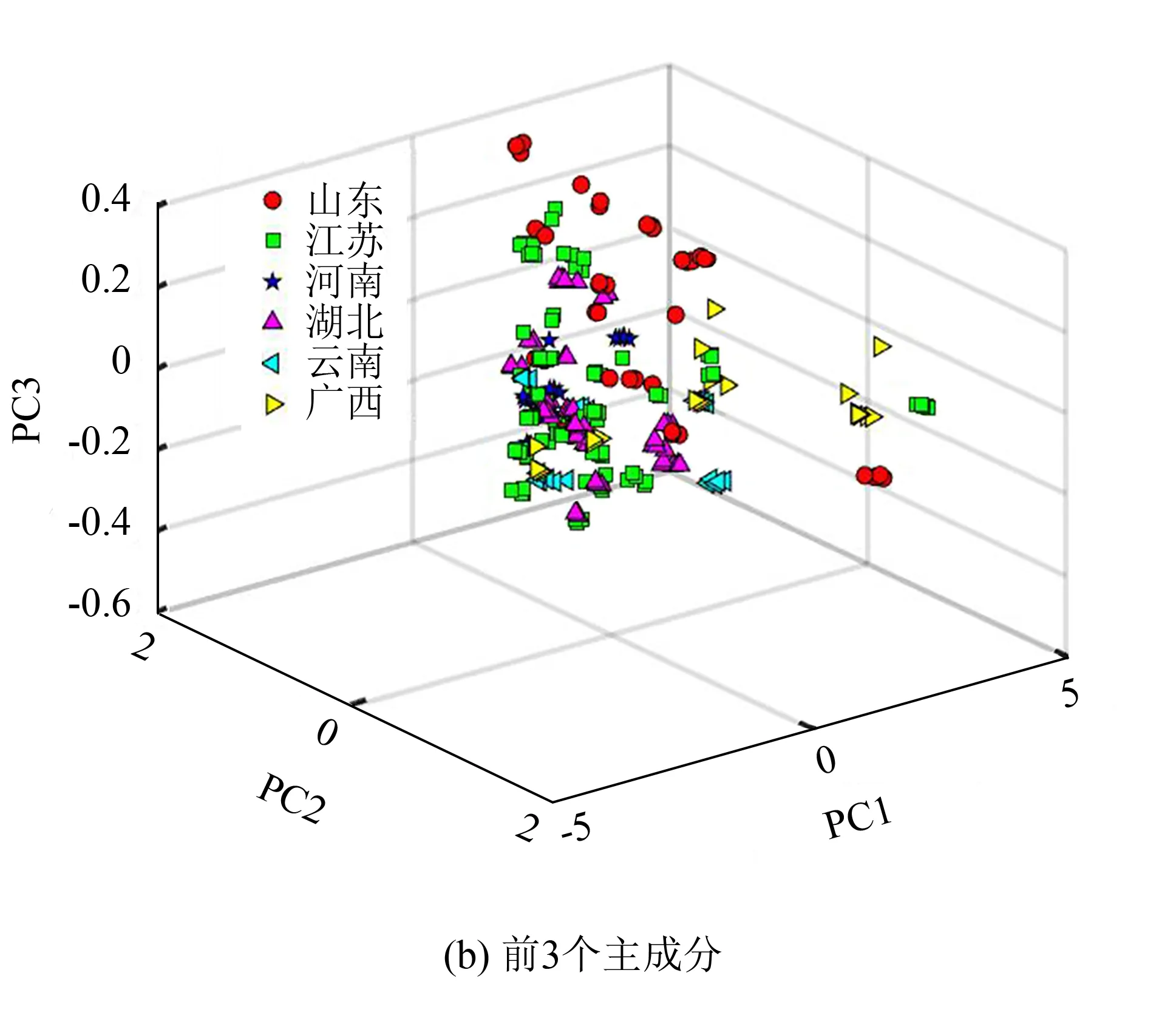
图2 凌霄花样本的聚类图
2.4 CARS-SVM模型构建

图3 参数C和g优化结果的3D视图Fig.3 3D view of the optimization results for parameters C and g
SVM的性能取决于惩罚参数C和RBF核函数参数g[14]. 本研究采用5折交叉验证结合网格搜索技术来确定最优的C和g. 在5折交叉验证中,将训练集样本平均分成5个子集. 然后随机选取4个子集来构建模型,剩下的子集用于验证. 因此,对每个实例进行一次预测,并以识别率来评价优化结果. 网格全局搜索算法是将待优化的参数先划分为网格,通过遍历网格上所有点对应的目标值,得出最优的目标值和最优值对应的参数值. 网格搜索优化的精度与参数范围和区间大小有关. 增大参数范围或者减小步长,都可以提高精度.C和g经过2-10~210范围内的评估,设定步长为20.2. 图3为采用5折交叉验证结合网格搜索技术对参数C和g进行优化的三维视图. 当C为6.062 9,g为0.082 5时,识别率最高. 以上述最优参数构建SVM模型,模型对6个产地凌霄花鉴别效果良好,其中训练集识别率为98.36%,预测识别率为96.30%.
为剔除冗余光谱变量,提高模型的稳定性与准确性,运用CARS算法提取特征变量. CARS波长选择过程中的波长变量个数、交叉验证均方根误差(root mean square error of cross validation, RMSECV)与回归系数路径的变化情况分别如图4所示. 随着运行次数的增加,RMSECV值开始下降,光谱中的冗余波长变量个数在减少. 当运行次数为24时,RMSECV达到最低点,此时的波长变量个数从1 557减少到52,达到最佳值. 以优化后的特征波长变量建立CARS-SVM模型,与SVM模型相比,训练集的识别率从98.36%提高到100%,测试集的识别率从96.30%提高到100%. 结果表明,通过CARS提取特征变量后,CARS-SVM模型比SVM模型具有更强的准确性.
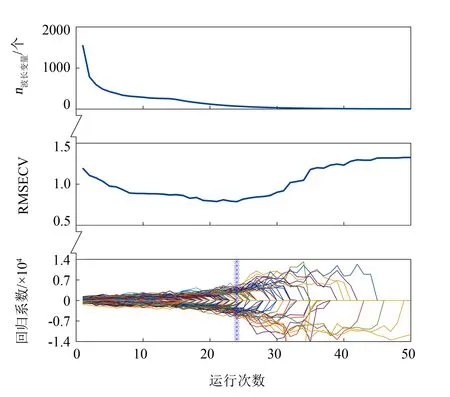
图4 选定波长变量个数、RMSECV、各波长变量的回归系数随着运行次数的变化Fig.4 Variation of the number of selected wavelength variables, RMSECV and the regression coefficient of each wavelength variable with the number of runs
2.5 模型比较分析
为进一步说明CARS-SVM模型的鉴别效果,以52个特征波长为变量,分别构建线性判别分析(linear discriminant analysis, LDA)、偏最小二乘法判别分析(partial least squares discriminant analysis, PLS-DA)和簇类独立软模式识别(soft independent modelling of class analogy, SIMCA)模型. 表2为不同模型对不同产地凌霄花的鉴别结果. 从表格中可以看出,无论是训练集还是测试集,CARS-SVM模型的鉴别效果均优于其他4种模型. 经分析,影响不同模型判别结果的因素可能如下:由于光谱数据的波长变量之间存在很强的相关性,降低LDA的分类精度[16]; SIMCA是在主成分分析基础上对未知样本进行识别,由于未知样本虽然符合某种类型的主成分分析模型,但样本可能会远离该类的训练集[17],从而使SIMCA模型的识别率偏低; CARS-PLS-DA模型的判别结果最差,因为PLS-DA模型是一种线性判别方法,当特征变量与分类目标之间存在非线性关系时,其识别率并不理想[18]; CARS-SVM模型的识别率优于其他4种模型,在样品数量较少的情况下也具有较强的泛化能力,且能适用于复杂非线性光谱的分析[19],是一种有效鉴别不同产地凌霄花的方法.
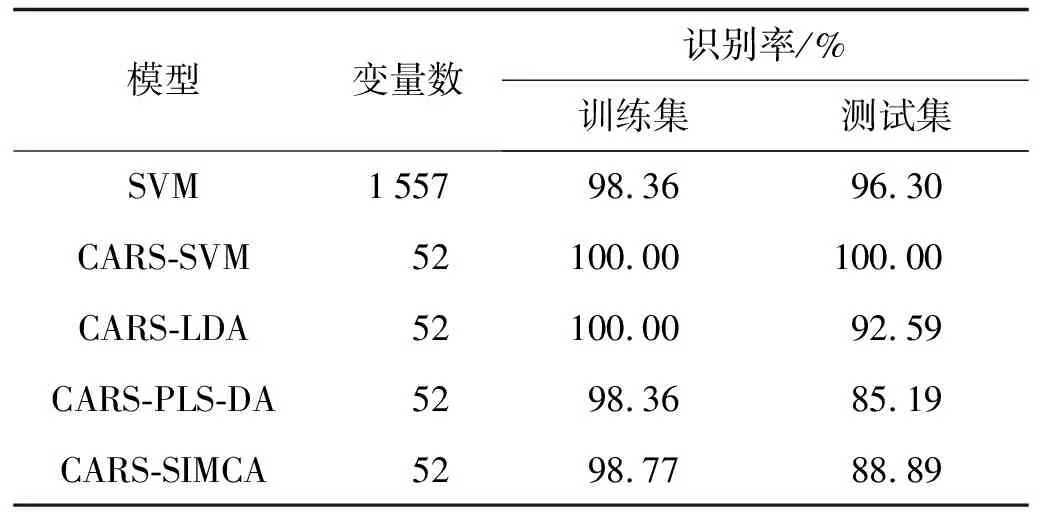
表2 不同建模结果的比较
3 结语
本研究采用基于NIRS技术的SVM算法对不同产地凌霄花进行有效判别. 为消除冗余光谱变量,对模型进行简化,采用CARS提取特征波长,建立CARS-SVM模型. 将该CARS-SVM模型与其他3种分类模型(LDA、PLSDA和SIMCA)进行比较,其判别准确率达到100%,明显优于其他模型. 结果表明,与传统的感官评价和理化试验的鉴定方法相比,NIRS技术结合CARS-SVM模型可快速准确判别凌霄花的产地, 为凌霄花的真伪鉴别及质量评价提供一种新的方法.
