领域特定情感词典扩展方法在情感分类中的应用
2022-07-12颜明阳闫国梁李明兰
颜明阳 闫国梁 李明兰
1(济宁学院初等教育学院 山东 曲阜 273100) 2(中讯邮电咨询设计院有限公司 北京 100000) 3(青岛大学数学与统计学院 山东 青岛 266071)
Relevant features
0 引 言
情感是一个会影响人的推理、决策制定和交互的重要因素,虽然情感具有主观性,但会以可推断的客观方式出现在文本中。情感分析[1]涉及到自然语言表达的计算研究,以识别语言表达与不同情感(如愤怒、恐惧、悲伤和惊讶等)之间的关联[2]。
情绪分析广泛应用于量化和分类用户在文本中所表达的意见倾向[3]。如Vytal等[4]在心理学文章中提出了情感理论,同时还提出了两种情感建模方法,及一些情感分类的特征表示。龚安等[5]提出一种针对评论文本的多特征融合的情感分类算法。该方法能让机器学习算法更加充分地利用规则特征,获得更好的分类性能、进一步提高分类精度。Dash等[6]设计了例如n-gram位置特征和词性(Part of Speech, POS)标注特征,以扩充用于微博情感分类的通用n-gram。对于微博的情感分类,Milani等[7]证明与基于GPEL的特征相比,基于DSED的特征利用逐点互信息(Point-by-point Mutual Information, PMI)能够在n-grams上提供显著收益,但是使用DSED的特征提取的研究被局限在二元分类计数的范围内。李向前等[8]对商品评论进行情感分析,得到某件商品各个方面的优劣情况,从而提出利用三层CRF模型进行情感极性分类及强度分析,融合了词、词性、语气词、程度词和评价词的共现等特征。此外,监督式LDA[9](sLDA)能提供更准确的分类建模和词典生成方式,该方法可以将情感分类作为主题进行建模。
现有的通用情感词典(General Purpose Emotion Lexicons, GPEL)通过人工操作将Ekman和Plutchik提出的情感类别与词语关联在一起,但是GPEL对传达情感的词语所在的上下文背景的建模较差。近期的情感分析研究关注于在特定领域上学习的词典[10],以及利用此类词典进行特征提取。然而,情感特征提取[11]局限为使用词典对文档中的情感词进行简单计数,这个方法很简单,但未能全面利用词典知识。
本文扩展了领域特定情感词典(Domain Specific Emotion Dictionary, DSED)的生成方法,以进行特征提取。所提方法在特征提取中使用了DSED提供的知识,而非简单的词语计数。提出的特征提取方法利用DSED捕捉到情感丰富的知识,使用机器学习提取特征将文本分入不同的情感类别。在基准情感分类数据集上,对本文方法提取出的情感特征的有效性进行了比较分析和评价。
1 本文基于词典的特征提取
本文用于情感分类的特征提取过程如图1所示。可以看出,所提方法利用在训练文档上学习到的DSED知识,提取出基于词典的特征。词性标注、情绪词典和GPEL作为提取情感分类相关特征的外部资源。
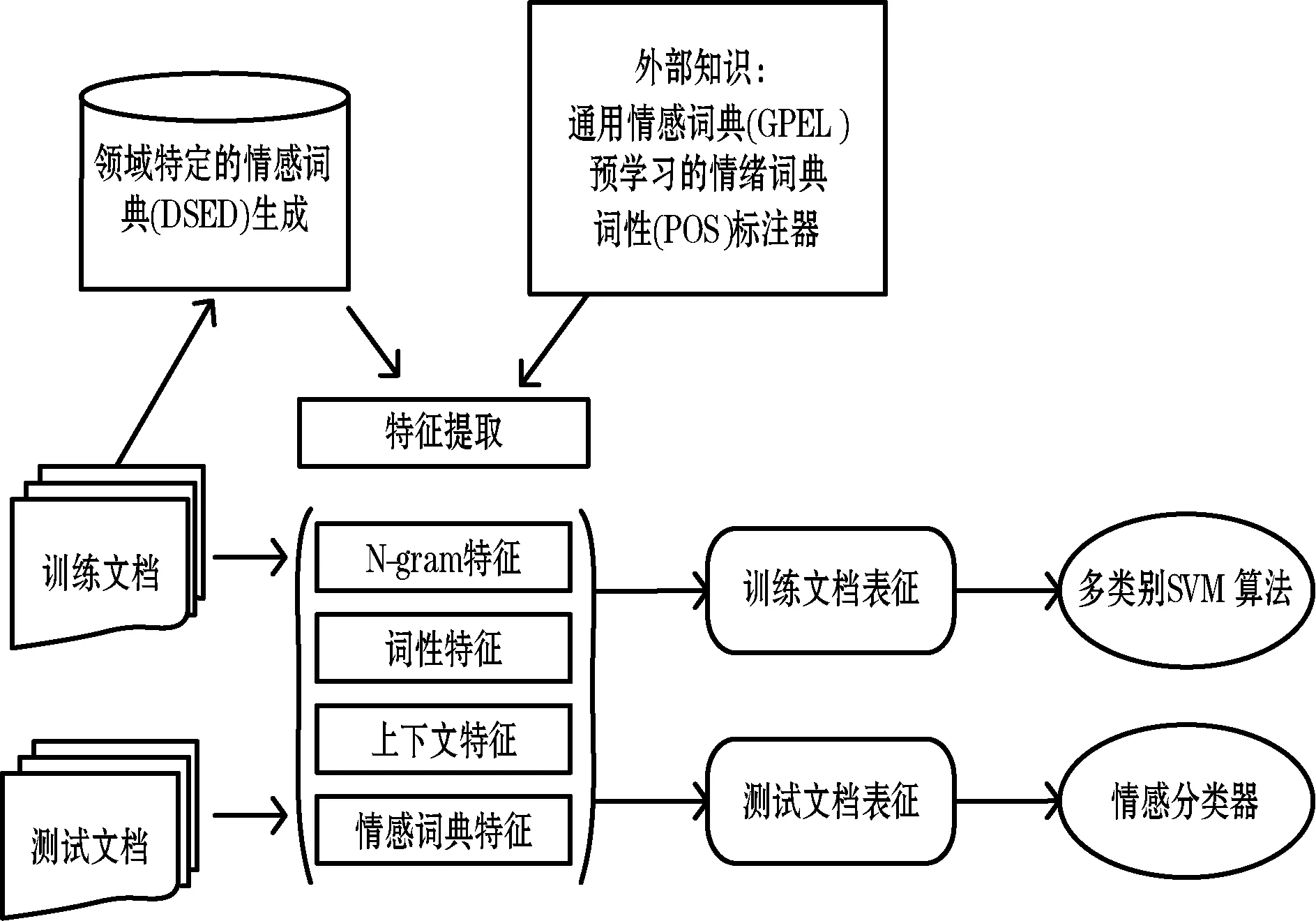
图1 特征提取和情感分类器学习
1.1 情感词典知识
一个GPEL可表示为Lex(w,j),是每个情感类别的一个词语列表:
(1)
式中:List(ej)表示与GPEL中第j个情感相对应的词语列表。与GPEL不同,DSED将词汇表V中的词语与一组预定义的情绪E间的关联进行量化。对于任何一个给定的词w,通过词典计算出该词语所表达的主导情感e:
(2)
本文使用生成的一元混合模型(UMM)对词语的情感性和中立性进行联合建模,从情感标签文件的语料库中习得DSED。对包含情感的词语和情感中立(背景)词语混合在一起的真实情感数据进行建模。所提生成模型通过式(3)的形式,来描述隐含着情感et的文档生成:
(Zw)(1-λet)P(w|N)]c(w,di)
(3)
式中:θet为情感语言模型;N为背景语言模型;λet为混合参数;Zw为二元隐藏变量,表示生成词语w的语言模型(θet或N);c(w,di)表示词w在文件di中的出现次数。
使用期望最大化(Expectation Maximization, EM)完成对参数θet和Z的估计,EM通过在E-步骤和M-步骤之间交替迭代地对整个数据(Det,Z)进行最大化。E-步骤和M-步骤分别如下:
E-步骤:
(4)
M-步骤:
(5)
式中:n表示EM迭代次数。EM用于估计与E中的情绪对应的k个混合模型参数。通过使用k个情感语言模型和背景模型N,习得情感词典UMMlex:
(6)
(7)
式中:k为语料库中的情感数量;UMMlex是一个|V|×(k+1)矩阵。所提UMM词典的一个样例如表1所示。可以看到,非标准的创造性表达在社交媒体上被广泛用于传达情感。此类表达常会加强文本的情感性。对这样的表达进行建模,对于社交媒体情感分析来说至关重要。因此,在文本预处理阶段,情感符号(如“:)”)和序连表示(如“好的!!”)被标记为单个词语,以捕捉其与不同情感之间的关联。

表1 UMM词语-情感词典的样例
1.2 情感词典特征
本文所有基于词典的特征向量长度均为|E|,|E|表示一个数据集中情感类别的数量。本文考虑以下文档表示的特征:
(1) 情绪总计数[7](TEC):该特征捕捉一个文档中与某种情绪相关联的词语数量。给定一个文档d,其对应的特征向量表示为dTEC,则第j个情感的特征值计算如下:
(8)
式中:I(·)是一个指标函数,当论证为真时,值为1,为假时,值为0;count(w,d)表示文档d中词语w的出现次数。TEC表示对词典指示出的一个词流行情感语境进行捕捉。然而,并不是所有词都只关联到单个情感。因此,有必要开发出能够体现一个词语与多个情感间关系的特征。
(2) 情绪总强度(TEI):文档中词语的情感强度得分之和,本文使用DSED给出的词语级情感强度得分,以捕捉沿着多个情感概念的文档情感走向。假设dTEI是与文档d相对应的特征向量,第j个情感的特征值计算为:
(9)
(3) 最大情感强度(MEI):情绪分析研究表明,情绪色彩较强的术语可以明显表明文档的情绪分类。因此,本文考虑了给定文档中情感色彩强烈的强度得分。具体如下:给定一个文档d,及其相应的特征向量dMEI,则第j个情感的特征强度值计算为:
(10)
(4) 分级情感计数[12](GEC):本文通过开发TEC和TEI的变体,对利用高强度情感词语提取文档表示特征的理念进行了扩展。由于本文的DSED对每个词语和情绪集合间的关联以概率分布的形式进行了量化,因此强度得分将始终处于区间[0,1]中。本文将该区间分为4个分区间,分别为[0,0.25)、[0.25,0.5)、[0.5,0.75)和[0.75,1]。使用上述三个阈值从DSED中提取出GEC特征。给定一个文档d,及其相应的特征向量dTEC,则第j个情绪的特征值计算为:
(11)
(5) 分级情感强度(GEI):本文开发了TEI的变体即GEI,是一个文档中超过了阈值δ的词语强度得分之和。给定一个文档d,及其相应的特征向量dGEI,第j个情感的特征值计算为:
(12)
2 基准情感特征
在提升情感分类性能时本文考虑以下特征:
1) n-grams(n=1):在不同的分类任务,包括情绪分类中使用最标准的语料库级特征[13]。本文使用二元加权(存在/不存在)以构建特征向量,其有效性已经在文献[13]中得到了验证。
2) 词性(POS)特征:利用该特征对动词、副词、名词和形容词在文档中的出现进行建模,使用标准POS标注器完成非社交媒体数据集上的词性标注,同时使用微博NPL工具进行社交媒体数据集的词性标注。
3) 上下文特征(CF):虽然标准词语能够传达作者的情感倾向,但额外的表达,例如标点符号和情感符号在社交媒体上经常被用于表达情感[14]。此外,包含情绪的词语可以表示文本中的情感,并将文本的情感走向从正面情感(例如快乐)转变为负面情感(例如悲伤),反之亦然。因此上下文特征也是一个非常重要的特征,具体涵盖以下要素:
(1) 大写单词:该特征对文档中所有带大写字符的词语进行计数。
(2) 拉长词:该特征对带有两次、三次或四次重复字符的词语进行计数。例如单词“haaappy”。
(3) 标点:社交媒体上使用感叹号或问号会增强情感。本文加入了对文档中问号和感叹号的出现进行建模的两个特征。
(4) 情感符号:情感符号是捕捉到的面部表情的图像形式,且在社交媒体上常被用于情感传达。为此,本文设计了一个二元特征,对文档中情感符号的存在/不存在进行建模。
(5) 否定词:虽然在情感分类中否定词的作用尚未得到大量研究,但因为其在情绪分类中有一定作用,本文纳入了一个特征,对文档中否定词的出现进行建模。
3 实验与结果分析
3.1 数据集
所提方法利用在训练文档上学习到的DSED知识,提取出基于词典的特征。词性标注、情绪词典和GPEL作为提取情感分类相关特征的外部资源。实验中的“领域特定”指的是新闻标题、微博、博客3个方向领域。
3.1.1新闻标题数据集(SemEval-2007)
该数据集中包含1 250条具有情感类别的新闻标题,用于评价情感和词汇语义间的联系。每个标题均给出了Ekman基本情感的情感评分,得分区间是[-100,100]。将每个标题得分最高的情感作为类标签,以此对该数据集进行情感分类。训练集和测试集中不同情感类别的分布如表2所示。该数据集相对较小,类别分布较为不平衡。该数据集可适用于多种情感分类方法的研究,且数据集易于扩展,贴近实时消息。
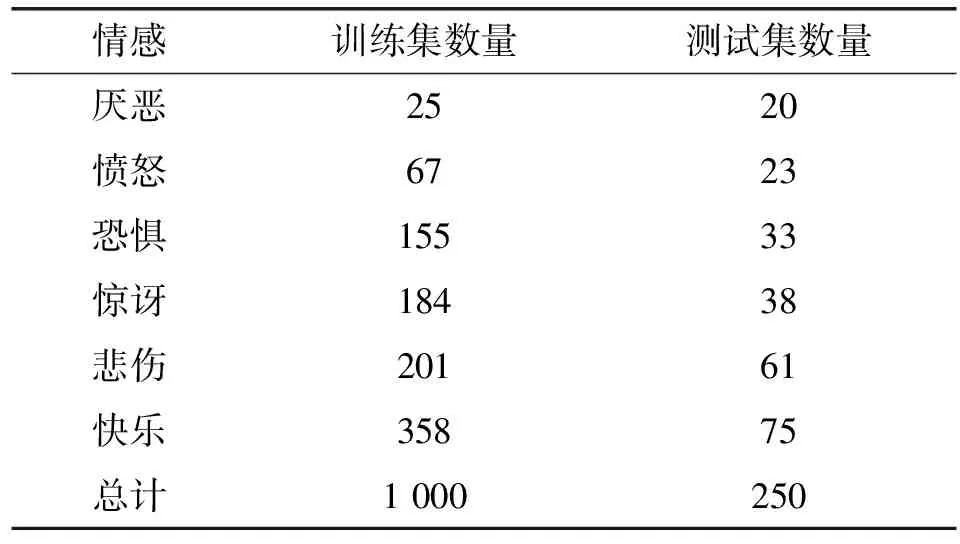
表2 新闻标题的情感数据集
3.1.2微博数据集
本文使用文献[15]所提的微博识别方法,从微博搜索API中采集了280 000条情感性微博作为微博数据集。本文使用该数据集进行情感分类时,进行10次交叉验证。表3给出了不同情感类别在10次验证后的平均分布情况。可以看出,该数据集相对较大,情感分布并不均衡。例如,与恐惧、惊讶相比,快乐、悲伤等情感的占比更多。不同文档表征在这个分类不均衡的数据集上的性能表现是很有研究价值的。

表3 微博情感数据集
3.1.3博客数据集
博客数据集中包含3个注释者以Ekman基本情感[16]进行注释后的5 500个博客语句。注释者之间平均共识率约为0.76。表4给出了5次验证后不同情感类别的平均分布。可以看出,“快乐”情感在该数据集中占比极高,数据集规模较小。因此对于占比较小的情感例如恐惧和惊讶等的建模是有挑战性的。该数据集可用于研究占比较小的情感建模。

表4 博客情感数据集
3.2 文档表征和分类器设置
在比较研究中,本文使用了以下文档表征:
(1) 基准情感特征;
(2) 使用基准GPEL提取出的TEC特征;
(3) 使用PMI[7]、CRF[8]和sLDA[9]生成的基准DSED中提取出的TEC、TEI、MEI、GEI和GEC特征;
(4) 使用本文所提的DSED提取出的TEC、TEI、GEI和GEC特征;
(5) 通过结合性能最优的基线特征和基于词典的特征得到混合特征。
本文在所有情感分类实验中均使用了一个多类别SVM分类器,采用的是线性SVM。不同于RBF核的SVM,线性SVM机只需要调节正则化参数C,起始范围设为[0.1,10],根据模型表现,细化搜索区间。对于本文,正则化参数C的值设为3.6较为合适。
3.3 结果分析
在所有情感分类任务中,使用F1-得分度量和准确率进行性能评价。
3.3.1基线特征的性能
本文从n-grams开始并递增式地加入特征组(例如POS)完成基线特征的情感分类实验。基线特征在4个基准数据集上得到的结果如表5和表6所示。可以看出,n-grams与词性(POS)特征的结合未能显著提升分类性能;POS特征的低效性表明,情感以更隐性的方式表达。

表5 基线特征在不同数据集上的F1得分(%)
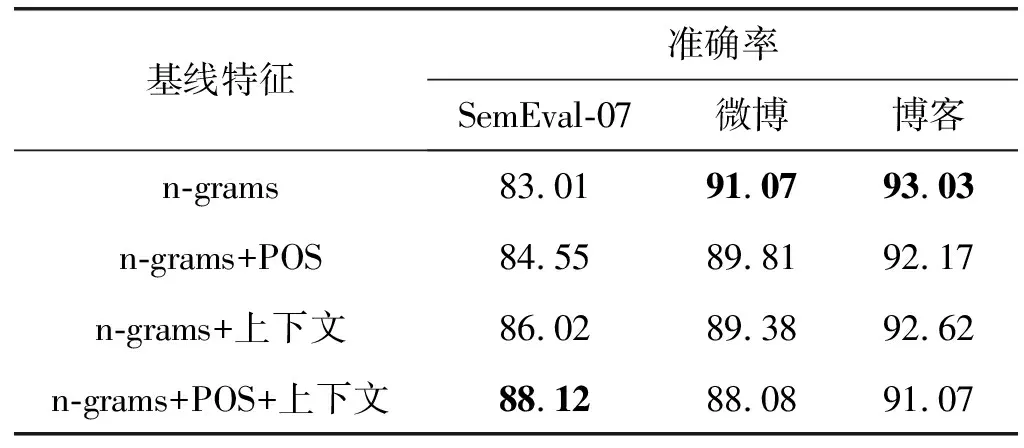
表6 基线特征在不同数据集上的准确率(%)
n-grams与上下文特征结合时,性能优于n-grams与POS特征的结合。但这一结合的分类性能并非始终优于只使用n-grams的情感分类性能。这表明,否定词等实体的简单计数不能直接扩展到情感分类任务中,这也证明了语料库特征的局限性。
3.3.2基于词典的特征性能
图2-图4分别给出了使用基于词典的特征在SemEval-07、微博和博客数据集上的情感分类结果。可以看出,从DSED提取出的特征显著优于使用GPEL提取出的特征。TEI和MEI特征始终优于GEI和GEC特征。该结果符合预期,因为GEI和GEC特征仅利用来自DSED的高强度情感词语,导致覆盖率下降。在使用GEI、GEC特征的所有数据集上,当阈值从δ1至δ2再至δ3增加时,得到性能退化的总体趋势。使用sLDA[9]和CRF[8]的生成性模型不能有效对真实世界情感数据的特点进行建模,影响了提取出的特征质量。虽然在基线方法中PMI[7]性能最优,但所提的DSED能够有效捕捉词语和多个情感之间的关联,提升文本的特征提取的质量,且能够在情感词语和中立词语之间进行区分,提升使用词典知识提取特征的质量。

图2 在SemEval-07数据集上的总体性能

图3 在微博数据集上的总体性能

图4 在博客数据集上的总体性能
3.3.3混合特征性能
混合特征向量是通过结合K维基线特征向量和E维基于词典的特征向量得到的K+E维特征向量。本文对基线特征和基于词典的特征相结合的混合特征进行实验。以博客数据集为例,表7和表8分别给出了使用混合特征情感分类结果的F1得分和准确率。可以看出,本文所提的UMM词典推导出的特征,在结合n-grams后,总体上性能优于仅使用n-grams特征,以及其他的混合特征。此外,博客数据集上惊讶和悲伤情感的分类性能显著优于仅使用n-gram特征,总体F1得分和准确率也较高。这说明了高质量词典能够为机器学习分类器提供有效知识,从而近距离捕捉该领域的情感上下文。

表7 混合式特征情感分类的F1得分(%)

表8 混合式特征情感分类的准确率(%)
4 结 语
本文使用领域特定词典和通用情感词典对情感特征提取问题进行了研究。所提方法在特征提取中使用了DSED提供的知识,而非简单的词语计数。应用了一元语法混合模型,量化情感性词语和中立性词语,提取情感特征。实验结果表明所提DSED知识提取出的特征显著优于从GPEL提取出的特征。此外,所提的特征与现有特征的混合性能显著优于n-gram特征,以及n-gram与基于词性信息等相结合的混合特征。
高质量词典能够为机器学习的分类器提供有效知识,从而更好地捕捉情感上下文。因此,未来本文将进一步研究DSED的优化形式。另外,本文还将利用所提DSED知识,开发用于分析社交论坛(如校园BBS、豆瓣等)中用户的情感签名的分类系统,预测用户潜在情感。
