年龄跨度感知的多任务亲属关系验证
2022-07-12秦晓倩刘大琨
秦晓倩 刘大琨
1(淮阴师范学院城市与环境学院 江苏 淮安 223300) 2(盐城工学院机械工程学院 江苏 盐城 224051)
0 引 言
亲属关系验证的目标是通过学习得到一个分类模型,以判断给定的人脸图像是否具有父子(FS)、父女(FD)、母子(MS)和母女(MD)等直接血亲关系。分类模型所获知的对象间的关系信息可被应用于人脸识别、社会媒体分析、人脸标注和图像追踪等[1]。已有的亲属关系验证方法可大致分为基于特征的和基于相似性学习的。Fang等[2]率先提出利用一些包括器官颜色、人脸的结构和纹理信息等特征来刻画亲属关系人脸图像。此后,研究者提出了其他多种不同的特征[3-7]以及属性[8]。还有一些工作提出融合多种特征[9-12]来刻画亲属关系人脸图像。基于相似性学习的方法学习一个特征转换空间,以达到更好地刻画亲属关系样本间相似性的目的。其中,文献[13-16]使用迁移学习来减少年老父母与子女间的脸部外观差异。度量学习方法是该类别中另一有效的验证方法,其主要目标是学习某个相似性度量,以使得亲属关系样本间相似性大于非亲属关系样本。已有的度量学习方法又可以进一步根据所要学习的特征转换矩阵的个数,继续划分为仅学习一个转换矩阵的单度量学习[9,17]和学习多个转换矩阵的多度量学习[10-11,18-23]两种类型。Zhao等[24]和Liang等[25]则结合了度量学习与核方法,学习一个非线性的特征转换矩阵。近期,深度学习亦被引入到亲属关系验证任务中[18,26],但却无法避免亲属关系人脸图像的数据量较少这一问题。Yan等[27]则使用基于人脸图像的亲属关系验证工作中主流的几种度量学习方法来对视频中的亲属关系进行判断,但仍只是简单地将视频中所有帧的均值作为某主体对象的最终的特征表示,从本质上来看,仍然是基于图像的。
尽管已经有许多用于亲属关系验证的度量学习方法,但已有方法中的大多数都是直接在每种亲属关系训练样本上统一学习,而鲜有讨论年龄跨度对学习模型的影响。但是,随着人的年龄增长,人脸外观会在形状和纹理上发生显著变化,这都将增加亲属关系验证的难度。另外,Xia等[13]的实验结果也表明,主体对象的年龄跨度越大,外观相似性越低,如图1所示,图1(a)是孩子和其父/母在年轻时的人脸图像对,图1(b)是该孩子和其父/母在年老时的人脸图像对,观察发现,图1(a)中对象间的相似程度更高。对分类模型来讲,这些具有不同相似程度的样本对模型的影响程度截然不同。

图1 不同年龄跨度的亲属关系图像对
本文提出一种年龄跨度感知的多任务学习方法,通过在具有不同年龄跨度的亲属关系样本间共享判别信息的方法,达到利用更多判别信息的目的。所提出的方法在学习时区别对待由年龄跨度不同所引起的在相似程度上存在差异的样本对,而不是简单地统一学习,解决了年龄跨度对亲属关系验证的影响问题。
本文的主要工作如下:
(1) 在多任务学习框架下,将具有不同年龄跨度的亲属关系验证问题分别看作一个学习任务,联合学习两类特征转换矩阵,其中一类由所有学习任务共享,另一类则由每个学习任务独享,以利用具有不同相似程度的样本所蕴含的判别信息。
(2) 为了充分利用父母-孩子对象在不同人脸局部区域中所表现的遗传相似性,借助金字塔多层结构进行亲属关系人脸图像特征的表示学习。
(3) 在亲属关系人脸数据库KinFaceW和UBKinFace上与现有的度量学习方法进行对比实验,验证了本文方法的有效性,并获得了较高的验证性能。
1 年龄跨度感知的多任务亲属关系验证
本文提出的年龄跨度感知的多任务亲属关系验证方法整体框架如图2所示,首先将训练样本划分为具有不同年龄跨度的样本簇,再借助金字塔多层(Pyramid Multi-Level, PML)结构进行人脸图像特征的表示学习,然后在多任务学习框架下学习特征转换矩阵,最后使用SVM进行亲属关系人脸图像的验证。
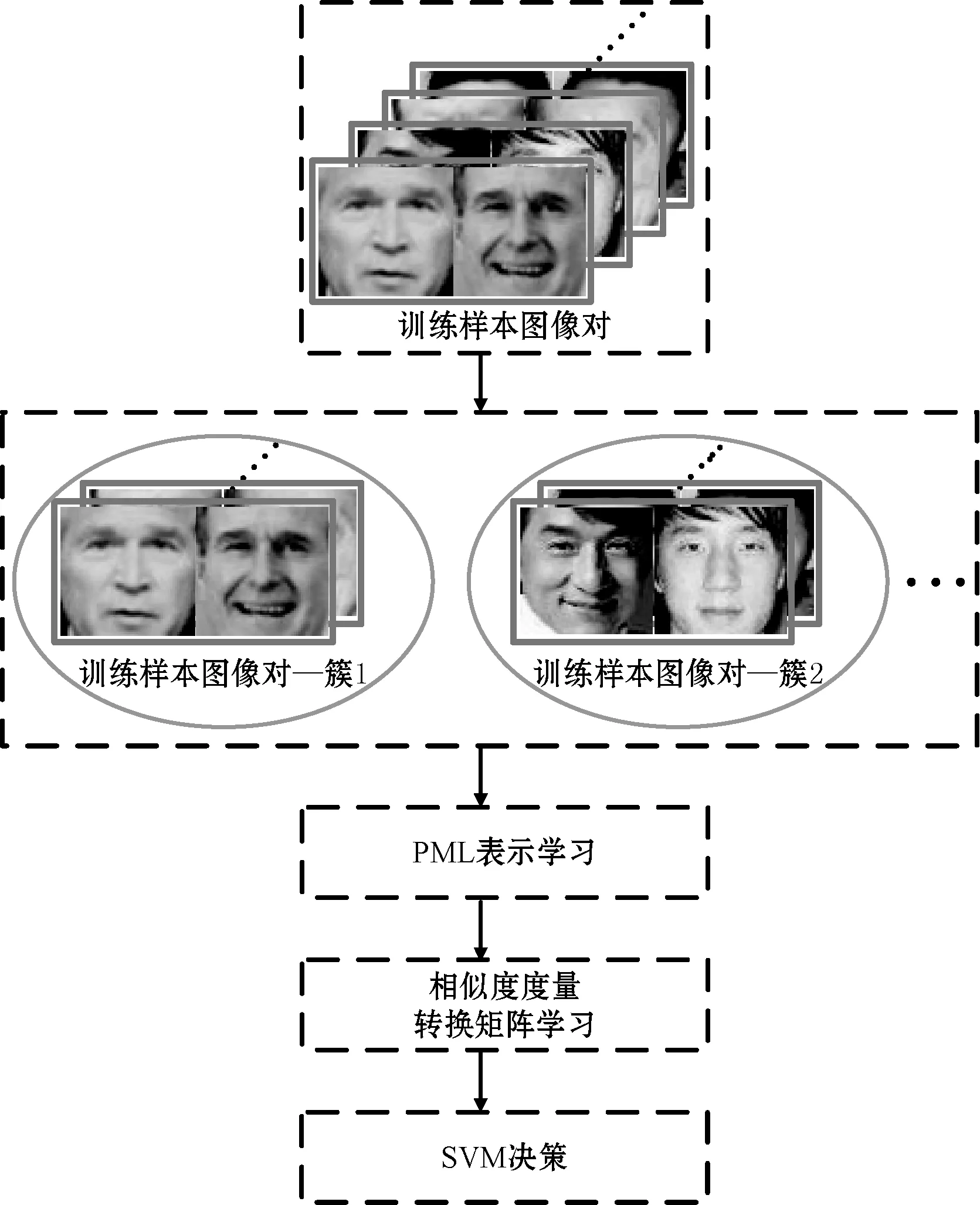
图2 年龄跨度感知的多任务学习 亲属关系验证算法框架
1.1 基于金字塔多层结构的人脸特征表示学习
在日常生活中,我们经常会听到类似“小明的鼻子那儿和他妈妈真像”这样的语句,因此,我们猜想,亲属关系对象间的遗传相似性往往隐藏在脸部局部区域。基于此,我们借助金字塔多层结构,将父母-孩子人脸图像分别划分为不同尺度的多个局部块,如图3所示,我们在L=4个尺度上分别对人脸图像进行划分,其中,在第l个尺度上,人脸被划分为l2个局部人脸块,从每个局部块上,抽取维度为m的特征向量,再将所有特征向量按序置于二维矩阵的列上,最终,得到两个大小为m×B的矩阵Xp和Xc,其中B为所有尺度上的全部局部块的个数,即B=L(L+1)(2L+1)/6。

图3 基于金字塔多层结构的人脸划分(Xpc)

(1)

1.2 年龄跨度感知的多任务学习方法


(2)

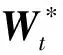
(3)
式中:转换矩阵W0用于刻画具有某种亲属关系样本所共享的遗传特性;Wt则被每个任务独享,用于刻画具有某种年龄跨度的亲属关系样本的遗传特性。
为了学习这两种转换矩阵,我们构建下面的优化问题:
(4)
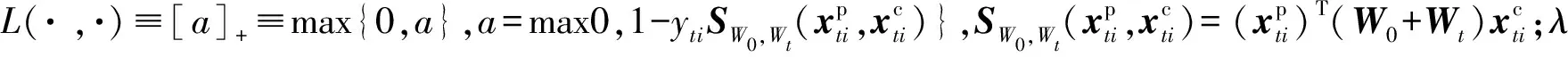
目标函数G(W0,Wt,λ,η)关于W0和{Wt}是凸的,为了获得W0和{Wt},使用随机梯度下降法求解式(4)。具体地,W0和{Wt}的梯度使用式(5)计算:
W0=W0L(·,·)+ηW0
Wt=WtL(·,·)+λWt
(5)
(6)
式中:μ是一个范围在0到1之间的参数。
我们采取交替迭代优化的策略进行学习。具体地,首先固定W0,优化{Wt},再固定{Wt},优化W0。该过程一直重复直至到达预设的某种收敛条件,如迭代次数或相邻两轮经验损失函数的差值变化小于某误差等。
算法的具体过程整理如下:
算法1年龄跨度感知的多任务学习方法(AS-MTL)
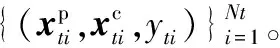
参数:λ,η,迭代次数Nu,误差τ。
输出: 转换矩阵W0和{Wt}。
Step1 初始化
1 随机T+1个d×d的矩阵作为W0和{Wt}的初始值;
2 计算损失函数的值L0(·,·);
Step2 优化
Forr=1,2,…,Nu
固定W0,使用式(5)-式(6)更新{Wt};
固定{Wt},使用式(5)-式(6)更新W0;
计算Lr(·,·);
若r>2且Lr-Lr-1∨τ,转到Step3;
Step3 输出
输出转换矩阵W0和{Wt}
1.3 SVM决策
当从训练样本中学习获得转换矩阵W0和{Wt}后,意味着已经探寻到了所有亲属关系样本所共有的投影转换判别空间,以及具有不同年龄跨度的样本簇各自独享的判别空间。接下来,借助SVM训练一个分类器做最后的决策。
具体做法如下:
首先,对每个训练样本簇中的每对训练样本图像数据,根据其所对应的学习任务t,借助双线性函数计算每幅图像对主体间的相似度,即:
SW0,Wt(xp,xc)=(xp)T(W0+Wt)xc
(7)
接着,基于所有图像对的相似度及其标号,训练一个线性SVM分类器。
当有待验证图像对出现时,首先将待验证图像对划分到某个对应的样本簇t,再根据该样本簇对应的转换矩阵Wt和共有转换矩阵W0,借助式(7)计算该图像对的相似度,最后使用训练好的SVM分类器进行预测。
2 实验和结果分析
2.1 KinFaceW数据库上的实验
2.1.1数据库和实验设置
KinFaceW-I[9]和KinFaceW-II[9]是目前流行的亲属关系人脸图像数据库。这两个数据库最大的不同是前者中的每对人脸图像来自于不同照片,而后者中的每对人脸则来自同一幅照片。考虑到我们的目标,即讨论年龄跨度差异在亲属关系验证问题中的影响,而KinFaceW-II中的父母—孩子年龄跨度情况较为单一,因此,我们在KinFaceW-I上验证本文算法的性能。图4展示了KinFaceW-I数据库中的四对图像,其中每列的两幅人脸图像依次具有父子、父女、母子和母女关系。

图4 KinFaceW-I数据库图像对样本
KinFaceW-I[9]共包含156对父子、134对父女、116对母子和127对母女关系人脸图像。但KinFaceW-I并未给出每幅人脸图像上的主体对象的年龄信息,导致我们无法直接在其上验证本文算法。为此,我们采取人工标注的方法,将该数据库中的所有人脸对按照年龄跨度小于20岁和大于20岁这两种情形进行归类处理,这直接使得式(4)中的参数T=2。当然,也可以使用年龄分类器对人脸图像进行自动年龄标注,但这里为了使得图像样本对的年龄跨度更为精准,使用了人工标注的方法。实验遵循文献[9]中的评估协议。
对本文方法中的参数,即λ、η、Nu和τ,使用4折交叉验证方法设置它们的值,具体地,对λ,其候选值的值域为{0.001,0.01},对η,则根据λ的值确定其值的变化范围,分别是{1×10-4:10:1×103}或{1×10-3:10:1×104}。分别设置Nu=200,τ=0.1。
2.1.2结果和分析
1) 基准实验。首先,我们设计了基准方法Base_1以讨论在学习过程中考虑年龄跨度影响的有效性。具体地,将式(4)中的T设置为1。其次,为了讨论特征选择方法的有效性,我们执行了本文方法的无特征选择版本Base_2。
对这两组基准实验,我们为每幅人脸图像抽取和数据库发布者[9]所使用的相同的两种特征:(1) SIFT:从相互之间有8个像素重叠的大小为16×16的块中抽取SIFT特征。接着,将这些特征拼接为一个维度为6 272的特征向量。(2) LBP:将图像分为4×4个相互之间无重叠像素的块,每个块的大小为16×16。接着,从每个块中抽取256维的LBP特征,并拼接为4 096维特征向量。使用PCA将提取的两种特征向量分别降到100维以去除噪声。
表1是实验结果。通过观察,得到以下结论:

表1 基准方法和本文方法在KinFaceW-I
(1) 由于考虑了年龄跨度的影响,Base_2在所有亲属关系上可以获得比Base_1更高的性能,且平均来看,两种特征可分别获得12.0百分点和12.5百分点的提高,说明在学习时考虑不同年龄跨度的影响是十分有效的。
(2) 所提的AS-MTL可以在Base_2的基础上进一步提升性能,说明特征选择的有效性。实验中每种亲属关系上选择出的人脸区域如图5所示,其中被黑色块覆盖的部分是未被选择的局部区域。观察发现,所选的人脸块大多位于人脸上的关键器官区域,这与我们日常生活中的经验相一致。另外,我们也发现,在不同种类的亲属关系人脸图像数据上选出的局部区域有所不同,这也暗示了性别对亲属关系验证的影响。

图5 KinFaceW-I数据库亲属关系图像选出的人脸区域
(3) SIFT特征在所使用的两种特征中可以获得更好的性能,在后面,我们将使用该特征与其他算法进行比较。
为了进一步展示本文方法的有效性,我们将KinFaceW-I数据库中500对随机的亲属关系对和非亲属关系对在Base_1和Base_2方法下的相似度分布进行了可视化处理,结果如图6所示,其中:图6(a)是Base_1方法所获得的相似度分布;图6(b)是Base_2方法的相似度分布。通过观察可以发现,亲属关系对和非亲属关系对的相似度分布在Base_1方法所获转换空间中存在较为严重的重叠现象,而它们在Base_2方法所获得的转换空间中则变得更可分,再一次说明本文方法的有效性。
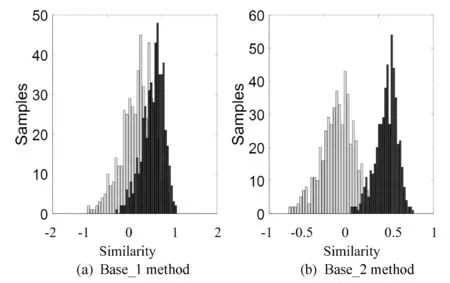
图6 KinFaceW-I数据库中500对亲属关系对和 500对非亲属关系对的相似度分布
2) 与其他度量学习方法的对比。由于本文方法需要学习特征转换矩阵,这与已有的度量学习方法NRML[9]和NRCML[17]的学习目标一致,为此,我们还将本文方法与这两个度量学习方法进行了比较。其中,NRML方法在学习时利用不同非亲属关系样本对度量学习的不同影响,提出寻求一个特征转换矩阵,以使得所有亲属关系样本对的距离尽可能小而所有非亲属关系样本对之间的距离尽可能大。而NRCML则在NRML的基础上引入了相关性度量。
由于两个对比方法仅在前述人脸特征上进行了特征转换矩阵的学习,而没有进行特征学习,因此,我们还将本文方法的无特征选择版本Base_2与对比方法进行了比较。除此之外,我们还将本文方法与两个多视图度量学习方法S3L[22]和MHDL3-V[19]进行了比较。这两种方法旨在利用多种特征相互间能提供互补性判别信息的能力来学习多个特征转换矩阵。其中:S3L[22]使用了SIFT、HOG和LBP特征;而MHDL3-V[19]则使用了FV、Color和LPQ三种特征。所有对比方法的性能均来自对应文献。表2比较了Base_2、AS-MTL和四个对比度量学习方法在KinFaceW-I上的结果。我们有以下几点观察:(1) 与单度量学习方法NRML[9]和NRCML[17]相比,由于NRCML[17]方法是NRML[9]方法的改进,因此可以获得较高的平均性能。相较于NRCML[17]方法,Base_2在KinFaceW-I上平均获得9.3百分点的提高,再一次说明在学习时考虑年龄跨度影响的有效性,而所提AS-MTL则可进一步平均获得4.0百分点的提高,说明本文方法的有效性。(2) 与多度量学习方法S3L[22]和MHDL3-V[19]相比,由于S3L[22]和MHDL3-V[19]使用了多种特征,因此可以获得比仅使用一个特征的NRML[9]和NRCML[17]方法更高的性能。而MHDL3-V[19]方法除了利用多种特征的互补性外,还学习了对称和非对称的多种度量,因此可以获得最高的验证性能。所提的AS-MTL方法也仅使用了一种特征,但在经过特征选择后可以获得与MHDL3-V[19]方法相当的平均验证性能,说明本文方法的有效性。
3)与其他多任务学习方法的对比。由于本文方法构建在多任务学习框架下,因此,我们还将本文方法与No-group MTL[28]和GO-MTL[29]这两个子空间正则化多任务学习方法进行了比较。其中:No-group MTL方法假设所有的学习任务是相关的,并通过对学习参数施加Lq,1正则化范数的方法来约束学习任务处于某个低维子空间;而GO-MTL方法则假设每个学习任务的参数向量是一些潜在的基任务的线性组合。
图7比较了Base_1、Base_2、AS-MTL和两个对比多任务学习方法在KinFaceW-I上的平均验证精度。观察发现,所有多任务学习方法都可以获得比Base_1方法更高的性能,说明在进行亲属关系验证时,考虑年龄跨度影响,并同时学习具有不同年龄跨度的样本间的参数,可以有效提高泛化性能。
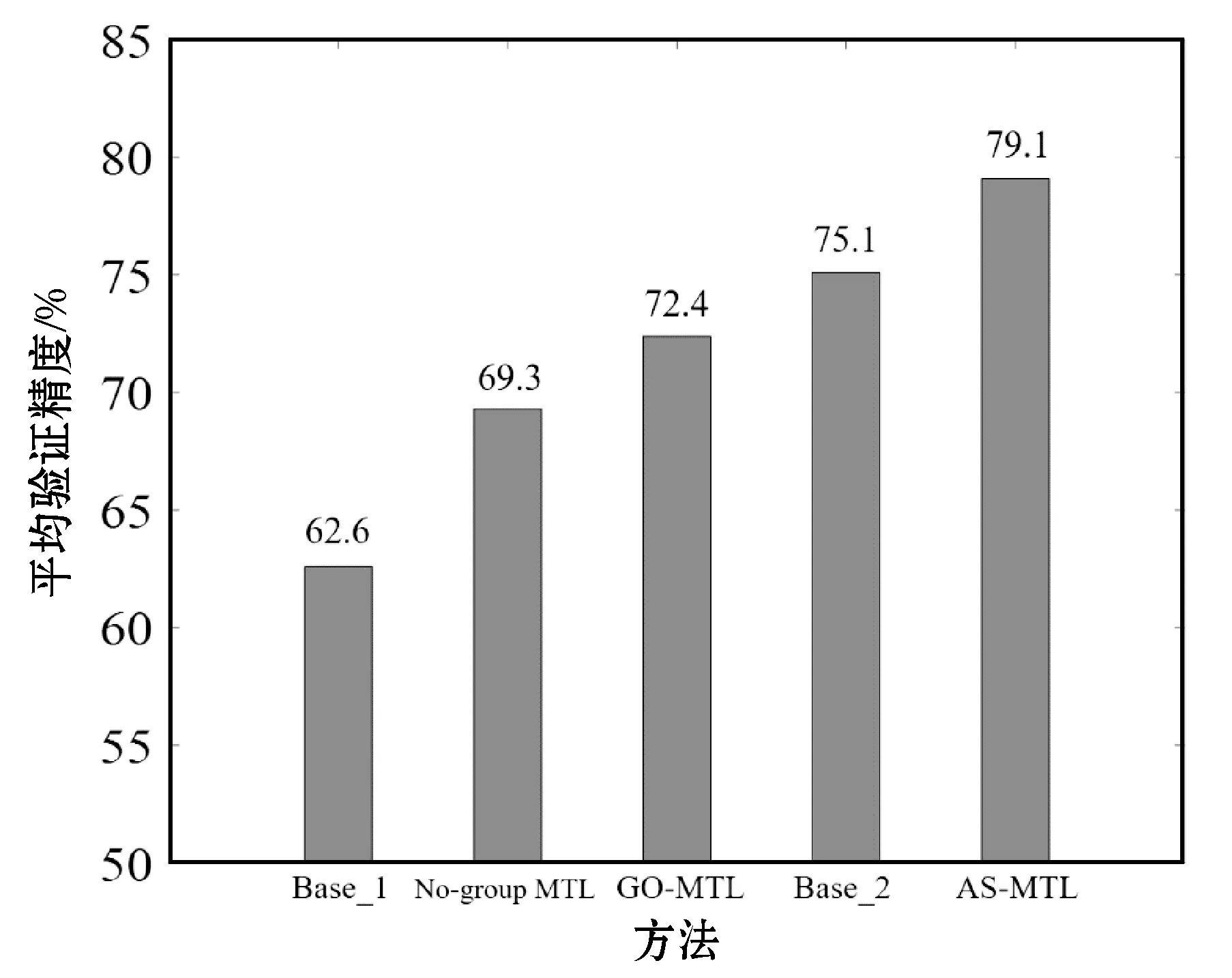
图7 不同方法在KinFaceW-I库上的平均验证精度比较
其中,GO-MTL通过引入重叠组结构,在No-group MTL的基础上获得了3.1百分点的提高,说明具有不同年龄跨度的样本簇相互间具有一定的结构。而Base_2方法则可在其基础上进一步提高2.7百分点。原因是,相较于GO-MTL方法所假设的学习任务间存在的重叠组结构,Base_2方法仅通过在任务间共享一个共有转换矩阵的形式在学习任务间共享判别信息,是一种相对松弛的学习方法,因此有机会获得更高的验证性能。
4) 参数的影响。我们还讨论了参数u=λ/η的大小对算法性能的影响,具体地,通过固定参数λ的值,变化参数η大小的方式进行查看。另外需要说明的是,为了更纯粹地讨论年龄跨度对验证结果的影响,需要将特征选择过程剥离,因此,我们在本文方法的无特征选择版本Base_2上进行具体的分析。图8展示了在u取不同值时,Base_2方法的平均验证性能。观察发现,当u较大时,算法性能相对较低,表明具有不同年龄跨度的亲属关系样本不能被无差别地统一处理。
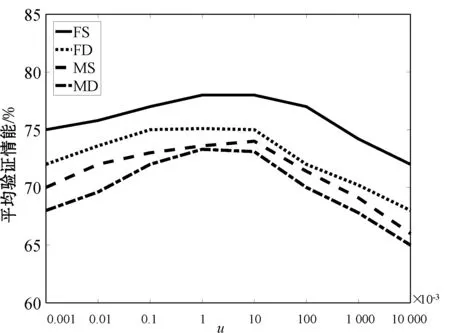
图8 参数u=λ/η对验证性能的影响
2.2 UBKinFace数据库上的实验
2.2.1数据库和实验设置
UBKinFace数据库[13]包含200组亲属关系人脸图像,每组人脸图像由年老父母图像、年轻父母图像和孩子图像组成,图9展示了数据库中的四组人脸图像,其中每列的三幅人脸图像依次是年老父母、年轻父母和孩子的图像。

图9 UBKinFace数据库图像组样本
已有的亲属关系验证算法都遵循文献[13]中的协议,即构建两个子集:“孩子—年轻父母”和“孩子—年老父母”,并分别在这两个子集上验证算法的性能。而我们的目标,是要讨论年龄跨度差异在亲属关系验证问题中的影响,因此,我们在遵循文献[13]中的5折交叉验证协议的基础上,采取将这两个子集合并且按照两种不同年龄跨度情形进行归类处理的策略来验证本文算法的性能。
对本文方法中的参数,即λ、η、Nu和τ,采用与前述KinFaceW亲属关系人脸数据库上相同的策略来设置它们的值。
2.2.2结果和分析
1) 基准实验。我们执行了本文方法AS-MTL及其无特征选择版本Base_2,在实验中,我们为每幅人脸图像抽取与KinFaceW数据库所使用的相同的SIFT特征,表3是实验结果。通过观察,可以发现,所提的AS-MTL可以在Base_2的基础上提升2.5百分点的验证性能,说明方法的有效性。

表3 基准方法和本文方法在UBKinFace
2) 与其他最好学习方法的对比。我们将本文方法和包括基于迁移学习的文献[13]的方法、基于单度量学习的NRML[9]、非线性多度量学习的NMML[21]和基于深度神经网络的KML[26]等在内的四个方法在UBKinFace数据库上进行了比较。但由于已有的方法都是分别在子集1“孩子—年轻父母”和子集2“孩子—年老父母”上验证算法的性能,因此我们取这些对比算法在两个子集上的验证精度的均值作对比。
表4是实验结果,其中所有对比算法的最后一列的精度值是其在两个子集上精度的均值。我们有以下几点观察:(1) 与单度量学习方法NRML[9]和多度量学习方法NMML[21]相比,本文方法的无特征选择版本Base_2可以获得与NMML[21]相当的验证精度,说明在进行亲属关系验证时考虑年龄跨度影响是十分有效的,而AS-MTL可以获得比其高2.7百分点的平均验证精度,说明所提特征选择策略的有效性。(2) 与基于深度神经网络的KML[26]相比,所提AS-MTL可以获得0.9百分点的平均验证精度的提高,再次说明本文方法的有效性。同时也说明,在样本数量较少的亲属关系数据上直接使用深度学习未必是最好的选择。

表4 不同方法在UBKinFace库上的验证精度比较(%)
3 结 语
为了讨论亲属关系验证问题中具有不同年龄跨度的样本对相似性学习具有不同影响的问题,提出一种年龄跨度感知的多任务学习方法。实验表明,由于在多任务学习框架下同时学习具有不同年龄跨度的亲属关系样本所蕴含的共有的、独有的空间结构信息,因此,可以利用更多的判别信息,进而获得较高的验证性能。探讨年龄跨度对亲属关系验证的影响是利用人脸图像进行亲属关系验证的第一次尝试,在今后的工作中,我们将考虑用自动化的方式获取年龄跨度,再在此基础上,构建一个年龄分类和亲属关系验证的统一学习模型。
