基于分类重要性与隐私约束的K-匿名特征选择
2022-07-12樊佳锦
樊佳锦 朱 焱
(西南交通大学信息科学与技术学院 四川 成都 611756)
0 引 言
社交网络为用户交流和分享信息提供了良好的平台,也为知识发现和数据挖掘创造了新的机会。然而,在对社交网络进行数据挖掘时,社交网络数据集中所包含用户的隐私信息不经保护可能会造成用户隐私泄露。例如在新浪微博中,用户所填写的个人信息可能帮助用心不良者刻画用户肖像;用户使用微博的行为习惯可能暴露用户生活习惯或行踪;微博内容则很可能破解出用户个人信息图谱和关系网。近年来,隐私泄露事件频发,如2018年媒体披露政治数据公司“剑桥分析”在未经用户许可的情况下,利用了社交软件Facebook上超过5 000万用户的个人信息。由此可见,隐私保护对于社交网络数据挖掘具有重要意义。
隐私保护数据挖掘(Privacy Preserving Data Mining,PPDM)研究数据挖掘与隐私保护技术的融合。PPDM领域经典技术有匿名化及随机扰动等。K-匿名由Sweeney等[1]首次提出,因其灵活有效,在隐私保护领域得到广泛研究。Li等[2]在传统K-匿名模型上利用聚类划分思想,提出一种聚类K匿名方法(K-Anonymity by Clustering in Attribute,KACA),算法始终选取距离最小的元组进行合并泛化,以确保总的信息损失趋于最小化。为了更好地保护敏感属性,文献[3]在KACA算法上引入了敏感属性隐私保护度,提出了S-KACA(Sensitivity-KACA)算法,对敏感属性设置不同隐私保护度,使等价类中敏感属性的隐私保护度更加多样化。文献[4]在S-KACA算法中引入聚类算法k-prototypes,在有效保护敏感属性的基础上提高了算法效率。
特征选择作为应用广泛的降维技术,是数据挖掘的重要手段之一,其主要原理是通过某种评价准则从原始特征集中挑选最优特征子集。此环节因其对特征的加工处理而成为隐私特征保护的关键时机。Jafer等[5]在特征选择中引入多维隐私感知评估条件,能够根据用户期望的效能来选择发布最佳子集。此外,该文还提出一种基于隐私感知过滤的特征选择方法PF-IFR[6],通过计算特征间的相关性,返回最相关特征及其相关性,再根据设定阈值对相关性高的特征进行剔除来实现特征选择;Zhang等[8]利用贪心思想并通过隐藏分类性能低的特征使特征子集对应数据集满足K-匿名,但其只适用于二值属性。
本文提出一种基于分类重要性与隐私约束的K-匿名特征选择方法IFP_KACA。受文献[5]启发,算法定义了特征分类重要性及特征隐私度,结合K-匿名来选择分类性能较高且满足隐私约束的特征子集。将本文方法与PF-IFR及k-prototypes-KACA方法进行对比实验可得,所提算法能够有效地平衡隐私保护度和分类挖掘性能。将本文算法应用于微博垃圾用户检测任务,优选出的特征子集能够在保护用户敏感信息的条件下检测垃圾用户。
1 相关技术
1.1 k-prototypes算法
k-prototypes[9]是处理混合属性聚类的典型算法,其继承了k-means和k-modes算法的思想。给定一个含有n条样本、m个属性的数据集X,其中包含数值属性mr个,分类属性mc个。k-prototypes算法旨在找到k个使目标函数最小化的分组:
(1)
式中:pil∈{0,1},代表在聚类l中有无该样本i;Ql为集群的原型;d(xi,Ql)为相异度距离。
(2)
式中:xir,xic分别代表样本xi的数值属性值和分类属性值;qlr为数值属性r与聚类l的均值;qlc为分类属性c与聚类l的众数;γ为分类属性的权重;δ为分类属性的相异度。
1.2 KACA技术
K-匿名通常采用泛化和隐匿技术,防止外界攻击者通过链接攻击的手段来获得敏感属性和个体身份间的关联,以达到隐私保护的目的[1]。K-匿名将数据表属性划分为标识属性(Identifiers)、准标识属性(Quasi-Identifiers,QI)、敏感属性(Sensitive-Attributes,SA)及其它属性(Others)。其中准标识属性是攻击者能够通过链式攻击间接识别个体的属性,也是K-匿名主要应用的属性。
定义1(等价类)。假设有数据表T(F1,F2,…,Fn),准标识属性QI(Fi,…,Fj)(i≤j),等价类为在准标识属性QI取值上完全相同的元组组成的若干集合。
定义2(K-匿名)。对于数据表T(F1,F2,…,Fn),T[QI]是指表中准标识属性所在列的数据。由定义1可知,当T[QI]中的每个等价类所包含元组数大于等于K时则称T表满足K-匿名,表1为一个2-匿名的数据表实例。

表1 2-匿名数据表实例
由K-匿名的定义可知,K-匿名要求数据表中每条记录在准标识符属性取值上与其他至少K-1条记录的准标识符属性取值相同,即K值的大小决定了隐私泄露的风险,K值越大,隐私泄露风险越低,反之越高。
KACA算法是一种局域泛化的方法,它改进了传统K-匿名属性间距离的度量方法。为了减小数据匿名化所造成的信息损失,KACA算法定义了与传统K-匿名不同的属性泛化的加权层次距离和泛化失真度。
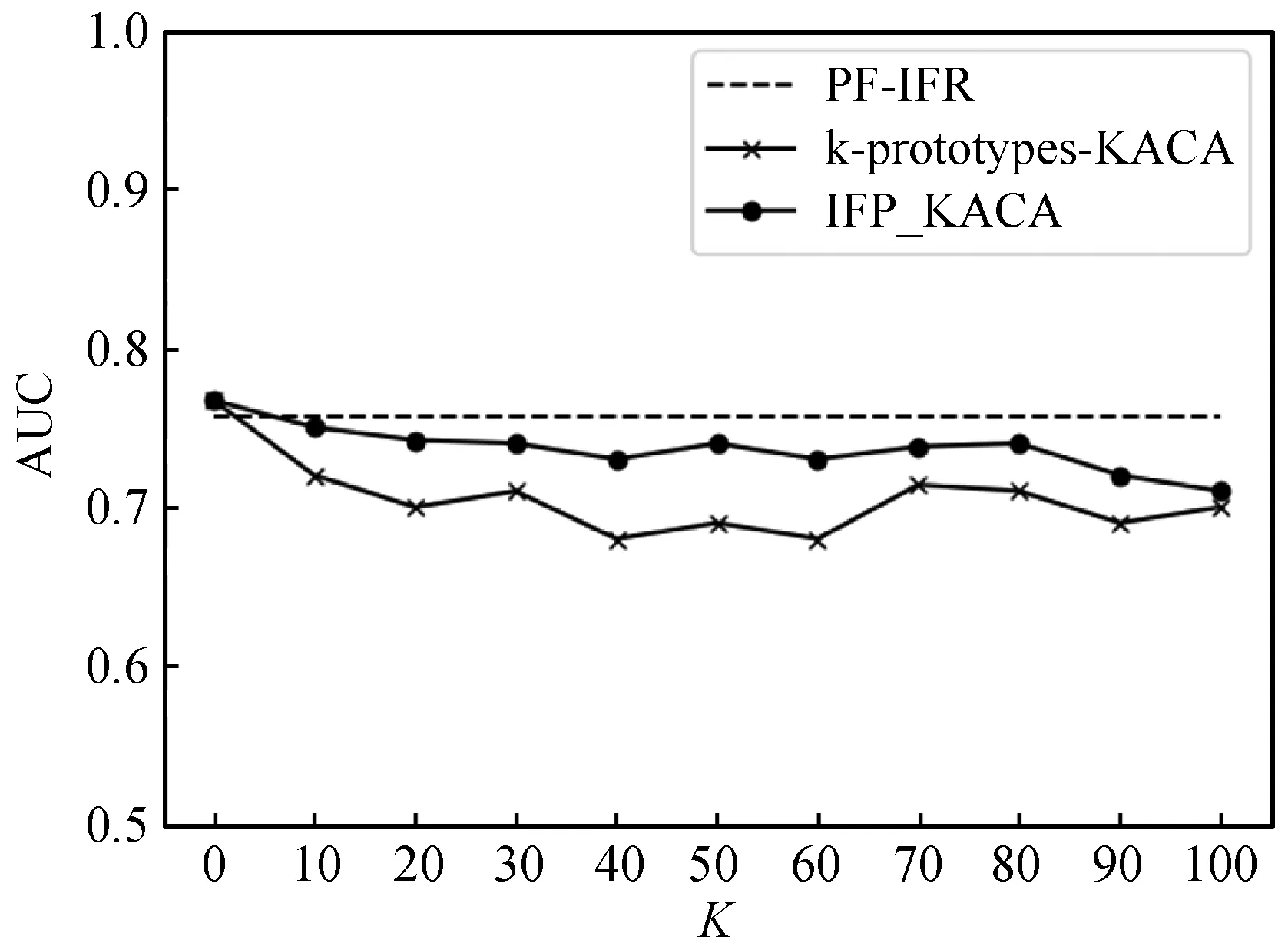
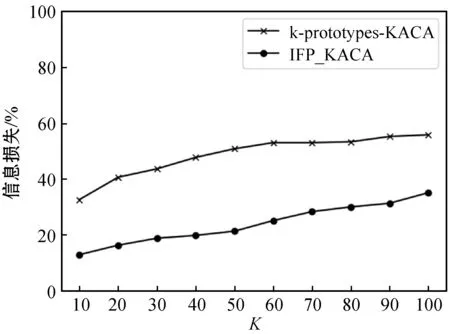
定义3(泛化的加权层次距离)。设h为准标识属性泛化层次树的高度,D1是值域,D2,…,Dh为某个准标识符的泛化域。由Da泛化至Db(a (3) 式中:wj,j-1为Dj~Dj-1(2≤j≤h)之间的泛化权重,其计算式为: wj,j-1=1/(j-1)β(2≤j≤h,β≥1) (4) 式中:β由数据发布者设置,本文中β=1。该方法体现出泛化到不同层级时所造成的数据变形的不同程度。 (5) (6) 本文通过构造分类器,计算单个特征的分类性能并进行排序得到排序结果。首先对原始数据集进行分类以获得分类准确率Acc1,剔除一个特征A后,对新数据集进行分类获得分类准确率Acc2,则该特征的分类性能计算式为: PerfR(A)=Acc1-Acc2 (7) 特征相关度代表了两个特征的相关性,在特征选择中常对高相关度的特征进行剔除以减少特征冗余。对于隐私保护而言,计算隐私特征之间的相关度并根据相关度定义隐私度,隐私度越大代表泄露隐私的风险越高。通过设定阈值,进行基于隐私约束的K-匿名特征选择,减少隐私特征的个数,降低泄露隐私的风险。准标识属性中包含用户的个人隐私信息,是本文要保护的对象。对于每个准标识属性,首先计算其与其他准标识属性的相关度,再设置相关度之和与准标识属性总个数的比值为该准标识属性的隐私度。其中,特征相关度的计算采用SU系数[6],其计算式为: (8) 式中:H(X)和H(Y)分别表示属性X和Y的信息熵,H(X,Y)为X和Y的联合信息熵。 本文算法首先构造分类器对所有特征分类性能进行排序,通过计算每个准标识属性的相关度来设置隐私度;对于准标识属性,选择特征分类重要性较高且满足隐私约束的特征子集使用k-prototypes-KACA算法进行K-匿名操作;对于其他属性,按照排序顺序进行序列后向选择;最后,对所选特征子集对应数据集使用SVM进行分类,评价信息损失及分类性能,选择最优特征子集。具体如算法1所示。 算法1IFP_KACA算法 输入:数据集D,准标识属性QI,其他属性OR,K值,泛化层次dgh,阈值λ 输出:信息损失,匿名数据集 Begin 1. 初始化sub1={},sub2={},temp={},F_List={},priv=0; 2. 构建分类器计算每个特征的分类重要性并降序排序; 3. 得到QI与OR属性排序序列F_QI_List,F_OR_List; 4. 对OR属性按F_OR_List进行序列后向选择得到sub1; 5. for F_QI_List中的每个特征x: 6. 根据式(8)计算x与其他QI属性的相关度之和S; 7. 定义x的隐私度px为S与QI个数的比值; 8. priv+=px; 9. if priv<λ 10. sub2=sub2.append(x); 11. else 12. Break; 13. F_List=sub1∪sub2; 14.D′是D在F_List上的投影数据集; 15. 采用k-prototypes-KACA(D′,QI,K,dgh)得到当前匿名数据集D″及其信息损失; 16. 使用SVM对D″进行分类得到AUC值; 17. temp=temp.append((F_List,信息损失,AUC)); 18. end for 19. 评价信息损失与AUC值,选择最优特征子集F_Best; 20. 输出F_Best对应匿名数据集及其信息损失; End 在IFP_KACA算法中使用k-prototypes-KACA[4]实现K-匿名。k-prototypes-KACA算法在KACA基础上引入k-prototypes聚类算法,对原始数据集采用该算法得到多个较大簇再进行K-匿名,提高了算法效率。具体如算法2所示。 算法2k-prototypes-KACA算法 输入:数据集D,准标识属性QI,K值,泛化层次dgh 输出:信息损失,匿名数据集 Begin 1.D′是D在QI上的投影数据集; 2. 对D′采用k-prototypes算法得到聚类结果k_result; 3. for eachk_resultiink_result 4. 从k_resulti划分若干初始等价类; 5. while存在等价类元组数小于K 6. 随机选取一个元组数小于K的等价类C; 7. 计算C与其他等价类的距离; 8. 找出与C距离最近的等价类C′; 9. 依据dgh泛化C和C′; 10. end while 11. end for 12. if存在小于K的等价类C 13. 隐匿C中的元组; 14. end if 15. 根据式(6)计算信息损失; 16. 返回信息损失和匿名数据集; End 本文采用Adult数据集和构建的中文微博数据集CWBO验证IFP_KACA算法在数据隐私保护度和分类挖掘上的性能。CWBO选取了6 000个资料完整度较高的用户,爬取用户微博数据,对数据集进行扩充。根据微博垃圾用户的行为特点,多人投票标注垃圾用户与正常用户。从微博内容、用户个人信息和用户行为三方面提取了新特征,并对数据集进行了数据清洗、数据标准化等操作。最终构建成实验所用中文微博数据集,包括5 740条数据、27个特征,垃圾用户与正常用户的比例约为2 ∶3。本文从27个属性中选取了年龄、学历等11个属性作为准标识属性,这些属性中包含用户个人隐私信息,也是本文所需要保护的敏感属性。对Adult数据集按正负类原始比例随机抽取2 000条样本,从原始14个属性中选取11个作为准标识属性进行实验。 为了验证本文算法能有效平衡隐私保护度与分类性能,将本文算法与PF-IFR及k-prototypes-KACA算法从分类性能、信息损失两个方面进行对比。其中分类性能采用ROC曲线下的面积AUC值进行评估。 本文采用SVM分类器对特征选择后的数据进行分类,并使用五折交叉验证方式来保证分类的稳定性。实验环境为:Intel(R) Core(TM) i7- 4700MQ CPU @2.40 GHz;8 GB(RAM)内存;Windows 8.1 64位操作系统。算法均采用Python3.6实现。 分别针对中文微博(CWBO)和Adult数据集,本文算法IFP_KACA与k-prototypes-KACA[4]、PF-IFR[6]算法所得特征子集,基于不同的特征集设计了分类对比实验,结果如图1-图2所示。实验中,隐私度阈值决定了加入特征子集的准标识属性的个数,由用户自行设置。隐私度阈值越小,隐私保护力度越大,但可能造成分类性能的急剧下降。本文通过取多个隐私度阈值并比较其分类性能变化情况,设置CWBO的隐私度阈值为0.5,Adult为0.7。 图1 不同K值下CWBO数据集的挖掘性能对比 图2 不同K值下Adult数据集的挖掘性能对比 K值大小决定了K-匿名的隐私保护程度,K=0时表示未加隐私保护的特征优选集的分类结果。随着K值的增大,对于特征的隐私保护度增高,分类性能呈下降趋势。 相比k-prototypes-KACA算法,本文算法一方面设置隐私约束,使优选特征集尽可能少地包含准标识属性,减少了隐私泄露的风险;另一方面,算法根据特征分类重要性排序,每次选择加入分类性能较好的准标识属性进行匿名,提高了分类挖掘性能。 PF-IFR算法同样通过相关度来定义敏感属性的隐私度,但特征选择过程未结合K匿名。本文算法相比PF-IFR,通过K匿名操作进一步保护了准标识属性值,由于按照特征分类性能重要性优先选择分类性能较高的特征加入特征集,减少了K匿名所带来的信息损失。故本文算法相较PF-IFR增加了对于隐私属性的保护力度,同时分类性能比较接近。 对于不同K值下k-prototypes-KACA算法及本文算法所得匿名数据集的信息损失情况如图3和图4所示。在两个数据集上,不同K值下,本文算法设置隐私约束使优选特征集尽可能少地包含准标识属性,再进行K匿名,故信息损失要小于k-prototypes-KACA算法。 图3 CWBO数据集在不同K值下的信息损失 图4 Adult数据集在不同K值下的信息损失 本文提出的IFP_KACA算法定义特征分类重要性和特征隐私度,并结合K-匿名进行特征选择。优选出的特征集满足两个条件:所含的敏感特征尽可能少,分类性能尽可能不受影响,从而较好地平衡隐私保护与分类的双重要求。将本文方法应用于中文微博垃圾用户检测,实验结果表明其能够兼顾敏感信息隐藏和垃圾用户检测的综合目标。 K-匿名只是隐私保护模型中的一种,未来的工作可以考虑将隐私保护的其他模型,如L-多样性、T-接近等与特征选择相结合。除此之外,也可以在特征选择算法上进行改进,集成其他的隐私保护技术,如随机扰动、差分隐私等。

1.3 特征分类性能重要性
1.4 基于特征相关度的隐私度定义
2 基于分类重要性与隐私约束的K-匿名特征选择算法
3 实验设置
3.1 数据集与预处理
3.2 评价指标与实验设置
4 实验结果分析
4.1 分类挖掘性能分析

4.2 信息损失分析

5 结 语
