基于代价敏感学习的半监督软件缺陷预测方法
2022-07-12张金传
张金传 张 震
1(扎兰屯职业学院 内蒙古 呼伦贝尔 162650) 2(中南大学计算机学院 湖南 长沙 410000)
0 引 言
软件缺陷预测技术利用机器学习方法分析软件缺陷历史数据,标记出容易出现缺陷的软件模块。开发人员可以根据软件缺陷预测结果合理地调度资源,提高软件验证效率,从而保障软件质量[1]。由于大部分软件缺陷集中在少数模块当中,软件缺陷数据的分布具有不平衡性[2-3]。此外,将无缺陷软件模块错误标记为有缺陷造成的代价远小于将有缺陷模块错误标记为无缺陷造成的代价。前者会造成测试资源的浪费,而后者会严重影响软件的可靠性[4]。传统的机器学习方法以最大化模型准确率为目标,假设数据分布平衡且不同类别的误分类代价相等,在软件缺陷预测中效果有限。针对这个问题,现有的研究通常基于代价敏感学习方法构建软件缺陷预测模型,为少数类样本与多数类样本设置不同的误分类代价。这些方法包括在数据层面上对有缺陷模块的过采样方法[5-7]、对无缺陷模块的降采样方法[8-10],以及在算法层面上扩展朴素贝叶斯、神经网络等传统机器学习方法得到的代价敏感学习方法[3,11-12]。
目前的软件缺陷预测方法均依赖于主观输入的误分类代价,或者由训练数据的分布得到相对合理的误分类代价。然而,训练数据往往只占整个数据集的小部分,训练数据的分布不能反映真实的数据类别分布,仅仅通过训练数据分布判断模型参数具有很大的局限性。因此,本文在NB(Naive Bayes)和EM(Expectation Maximization)方法的基础上展开,提出一种充分利用未标记数据的代价敏感学习方法——CSNB-EM。CSNB-EM方法在软件缺陷预测中的优势包括:(1) 方法为有缺陷软件模块与无缺陷软件模块设置合理的误分类代价,基于代价敏感学习提高对有缺陷软件模块的识别能力;(2) 方法利用未标记数据迭代优化误分类代价等模型参数,建立的软件缺陷预测模型更加符合整个数据集的分布。在公开的MDP软件缺陷数据集上进行的对比实验表明,CSNB-EM方法在处理软件缺陷数据时,预测性能明显优于CS-NB、CS-NN等现有的代价敏感学习方法。
1 不平衡缺陷数据学习方法
软件缺陷数据是一种典型的不平衡数据,有缺陷软件模块的数量远远小于无缺陷模块。例如,美国航空航天局的MDP数据集[13]中,MC1项目的缺陷率为10.23%,PC1项目的缺陷率为8.04%。用追求高准确率的传统机器学习方法处理缺陷数据时,很多有缺陷模块会被判定为无缺陷。代价敏感软件缺陷预测方法通过为不同类别设置不同的误分类代价解决缺陷数据的不平衡问题,包括数据和算法两个层面的方法。
数据层面的代价敏感方法大多采用重采样技术,包括增加少数类样本的过采样方法和减少多数类样本的降采样方法。针对少数类样本的过采样方法随机生成一定数量的有缺陷样本并添加到数据集中,使得数据集中有缺陷样本与无缺陷样本的数量达到平衡[5-7]。例如,文献[6]结合过采样与Boosting技术提出PCBoost方法,在每一轮训练开始时合成一定数量的少数类样本,并把合成样本加入到训练数据集当中。为了防止部分不合理的合成样本降低模型性能,方法在每一轮训练结束时,删除被误分的少数类样本。针对多数类样本的降采样方法通过减少无缺陷样本的数量平衡数据集的类别[8-10]。文献[9]提出了有效的降采样方法:将多数类样本分成多个子集,每个子集都和少数类一起训练一个分类器,最后集成这些分类器。
文献[14]指出,与数据层面的代价敏感学习方法相比,算法层面的代价敏感学习方法在处理不平衡数据时通常具有更好的性能。算法层面的代价敏感学习方法不改变数据分布,而是让算法对误分类代价较高的类别产生偏置[3,11-12]。例如,文献[12]用不同的误分类代价拓展决策树算法来提高对少数类的识别能力,基于不同的特征子集训练多个弱分类器并且集成弱分类器的预测结果。
代价敏感学习方法能有效提高模型对少数类的识别能力。基于代价敏感学习方法构建缺陷预测模型能显著提高软件缺陷预测的效果。然而,这些方法通常需要人为确定一组误分类代价。在软件缺陷预测的任务中,标记软件模块的成本高昂,有标记的训练样本通常远少于无标记样本。在这种情况下,难以基于训练样本得到适应整个数据集的误分类代价。本文提出的CSNB-EM方法充分利用无标记样本优化误分类代价及其他模型参数,所建立的模型在软件缺陷预测中具有明显优势。
2 软件缺陷预测算法CSNB-EM
CSNB-EM方法首先在训练数据集上构建朴素贝叶斯分类模型,应用交叉验证搜索适合训练数据集与该分类模型的最优误分类代价,并将搜索到的误分类代价应用在分类模型上,然后通过EM算法利用未标记数据集修正模型参数。
2.1 基于代价敏感的朴素贝叶斯方法
朴素贝叶斯方法是一种建立软件缺陷预测模型的常用方法[15-16]。令L={(x1,y1),(x2,y2),…,(xn,yn)}表示训练数据集合。对于任意0≤i≤n,yi表示样本xi的类别。U={xn+1,xn+2,…,xn+m}表示一组未标记数据。数据集中的样本有k个属性,用aj表示第j个属性,用aij表示样本xi的第j个属性,则xi={xi1,xi2,…,xik}。给定一个类别c,P(c|xi)表示样本xi的类别为c的概率,P(xi|c)表示类别c中,样本xi出现的概率,P(c)表示类别c出现的概率。根据贝叶斯理论,P(c|xi)可以通过P(c)·P(xi|c)估计。
P(c|xi)∝P(c)·P(xi|c)
(1)
在软件缺陷预测的任务中,通常可以基于朴素贝叶斯方法假设数据的每个属性独立分布。朴素贝叶斯方法在软件缺陷预测中的应用表明:该假设能显著提高训练模型的效率,而不会明显降低模型性能[15-16]。基于该假设,式(1)可以写为:
(2)
在处理不平衡数据时,基于式(2)标记样本类别可能会降低少数类别样本分类的准确率。针对这个问题,本文基于混淆矩阵引入不同的误分类代价。设正例样本为有缺陷样本,类别用1表示,负例样本表示无缺陷样本,类别用0表示。对于任意1≤i≤n+m,都有ci∈C={0,1}。误分类代价如表1所示。

表1 误分类代价矩阵
基于误分类代价矩阵,可以定义代价函数为:
(3)
本文通过最小化代价函数标记样本的类别。为了简化模型,令F(1,1)=F(0,0)=0。令F(1,1)>F(0,0)以提高负例样本的分类准确率。当ci≠cj时,将F(ci,cj)简写为Fci。
2.2 调整模型参数
CSNB-EM算法基于未标记数据调整模型参数。具体做法为:基于模型参数建立模型,预测无标记样本集的标记,然后利用这些标记修正模型参数。这个过程迭代进行直到模型参数与样本标记收敛。
算法首先在训练数据集上学习一组分类参数,包括P(c)与P(aj|c)。参数P(c)反映了数据类别的分布,P(aj|c)是样本第j个属性的条件概率。基于训练数据集中样本的类别可以计算得出P(c)与P(aj|c)。
(4)
(5)
式中:对于任意α与β,如果α=β,则φ(α,β)=1,否则,φ(α,β)=0。
首先令F(1,0)=F(0,1)=1,然后迭代进行E-step与M-step两个步骤调整样本类别与模型参数。
E-step:标记数据集U中的样本。
f(xi)=argmincL(x,c)
(6)
M-step:调整模型参数。由于数据集U中样本的标记未知,为这些样本分配一个权重0<λ<1来降低无标记样本对模型参数的影响。
(7)
(8)
Fc=argmaxFP(L,U,Z|hc,a|c,F)
(9)
式中:Z={f(xn+1),f(xn+2),…,f(xn+m)}表示对无标记样本类别的预测结果;hc,a|c是P(c)与P(a|c)两个模型参数。式(9)寻找的是适合当前步骤中的模型参数与样本类别的误分类代价。
CSNB-EM算法过程如算法1所示。
算法1CSNB-EM算法
输入:最大迭代次数T,L={(x1,y1),(x2,y2),…,(xn,yn)},U={xn+1,xn+2,…,xn+m}。
输出:U中样本的标签。
1.F0(1,0)=F1(0,1)=1;
2.根据式(4)与式(5)计算P0(c)与P0(a|c);
3.fort=1 toTdo
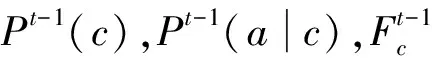
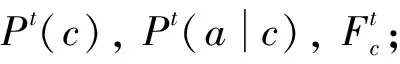
6.returnfT(x)
算法在第2步用朴素贝叶斯方法在训练数据集上计算初始模型参数。第4步与第5步迭代利用模型参数标记数据类别,并利用数据类别修正模型参数,其中第4步对应E-step,第5步对应M-step。
2.3 估计误分类代价
CSNB-EM算法根据训练数据集、无标记数据集、无标记数据集的预测结果计算误分类代价。本节给出误分类代价最优取值的估计方法。方法基于不同误分类代价对应的模型性能确定误分类代价的取值。由于L与U中样本的权重不同,在估计模型性能时,需要弱化U中样本的影响,因此本文提出表2所示的加权混淆矩阵估计模型性能。

表2 加权混淆矩阵
表2中,TP表示被正确标记的有缺陷样本的权重之和,FN表示被错误标记的有缺陷样本的权重之和,TN表示被正确标记的无缺陷样本的权重之和,FP表示被错误标记的无缺陷样本的权重之和。其中:wi表示样本xi的权重,如果xi∈L,wi=1,否则wi=λ;yi是样本xi的标签,如果xi∈U,则yi=f(xi);h(xi)是模型预测的xi的类别。
由于缺陷数据的不平衡性,不能仅仅通过准确率评价模型性能。考虑到性能良好的模型即应该识别出多的正例,又要保证预测的准确性,通过以下两项指标考察模型性能:
Recall=TP/(TP+FN)
(10)
Precision=TP/(TP+FP)
(11)
式中:Recall表示正例样本中被预测正确的样本所占比例;Precision表示被预测为正例的样本中被预测正确的样本比例。显然,Recall的值高说明分类器对正例有较高的偏置,但对正例偏置过高会导致Precision的降低。合理的误分类代价应该能使得模型在Recall与Precision两个指标上达到一个最优折衷,参考文献[17],本文取Recall与Precision的几何平均值作为衡量模型性能的标准。
(12)
本文在误分类代价的范围内迭代取值,构造模型并在数据集上进行10折交叉验证,找到使得GeoM达到最大值的误分类代价。为了计算方便,令F(1,0)=1,F(0,1)在(0,1)区间迭代取值。搜索误分类代价的算法如算法2所示。
算法2搜索误分类代价算法
输入:代价增量ΔF,L={(x1,y1),(x2,y2),…,(xn,yn)},Z={f(xn+1),f(xn+2),…,f(xn+m)},U={xn+1,xn+2,…,xn+m},模型参数P(c)、P(a|c)。
输出:误分类代价F(0,1)。
1.F′=F*=1,Gmax=0;
2.whileF′>0do
3.根据模型参数F(1,0)=1,F(0,1)=F′,P(c),P(a|c)与式(3)计算代价函数L(x,c);
4.通过最小化代价函数L(x,c)标记L∪U中样本,得到h(x);
5.根据h(x)与式(12)计算GeoM;
6.ifGeoM>Gmaxdo
7.F*=F′,Gmax=GeoM;
8.F′=F′-ΔF;
9.returnF(0,1)=F*
算法根据训练数据集合L、无标记数据集合U、U中样本的预测标签集合Z搜索误分类代价的合理取值。通过加权混淆矩阵计算模型的GeoM指标,并返回使该指标最大化的误分类代价取值。
3 实验分析
3.1 数据集
本文采用NASA公开的MDP软件缺陷数据集作为实验数据,如表3所示。数据集可以从PROMISE网站上获取[13]。数据集中的每个数据资源都表示一个NASA软件项目内的模块信息。表4中给出了数据集属性的描述。由于数据属性是连续的,本文使用基于MDL的离散化方法[18]将属性离散化。
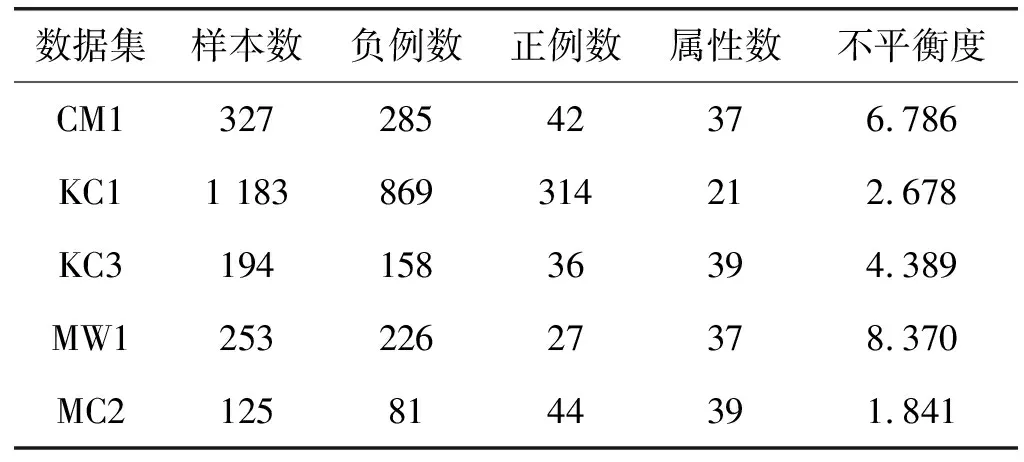
表3 数据集

表4 数据集属性
3.2 与代价敏感方法的对比实验
实验选用GeoM与AUC作为算法的评价标准。GeoM表示模型Recall与Precision的几何平均。AUC是ROC曲线下的面积,被认为是一种评价不平衡数据分类效果的优秀指标。高的AUC值对应理想的分类模型。实验在MDP数据集上随机抽取20%的样本作为训练数据,建立多个模型进行比较,包括:用代价敏感拓展朴素贝叶斯方法得到的CS-NB(Cost-Sensitive Naive Bayes)方法;代价敏感软件缺陷预测方法CS-NN(Cost-Sensitive Neural Network)[11]。为了考察CSNB-EM方法自适应搜索最优误分类代价的效果,首先在误分类代价的范围内动态调整误分类代价构建CS-NB模型,通过在数据集上验证模型效果找到最优误分代价并在每个数据集上都用最优误分类代价构建CS-NB模型与CSNB-EM方法对比。取F(1,0)=1,调整F(0,1)的取值。图1是CS-NB方法在各个数据集上的GeoM值,表5是根据图1为CS-NB方法搜索到的最优误分类代价。

图1 CS-NB模型性能比较
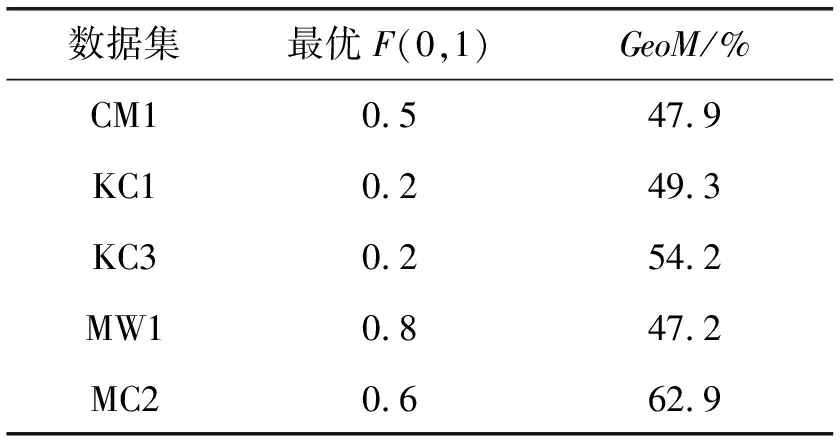
表5 CS-NB模型最优误分类代价
可以看出,误分类代价的选择对CS-NB模型的GeoM值有明显影响,不合理的误分类代价与最优误分类代价构造的模型在GeoM指标上相差很大。这说明CS-NB方法对软件缺陷数据的预测性能严重依赖于误分类代价的选择。但在实际应用中,有标记数据只占数据集的一部分,传统的代价敏感方法难以确定适合整个数据集的最优误分代价。因此,本文提出的方法将传统代价敏感方法所忽略的未标记数据充分利用起来,自适应地搜索适合整个数据集的最优误分代价。用表5中的最优误分代价构建CS-NB模型,λ的值取0.2,进行下一步的对比实验。实验结果如表6所示,每个数据集上的最好结果加粗标出。
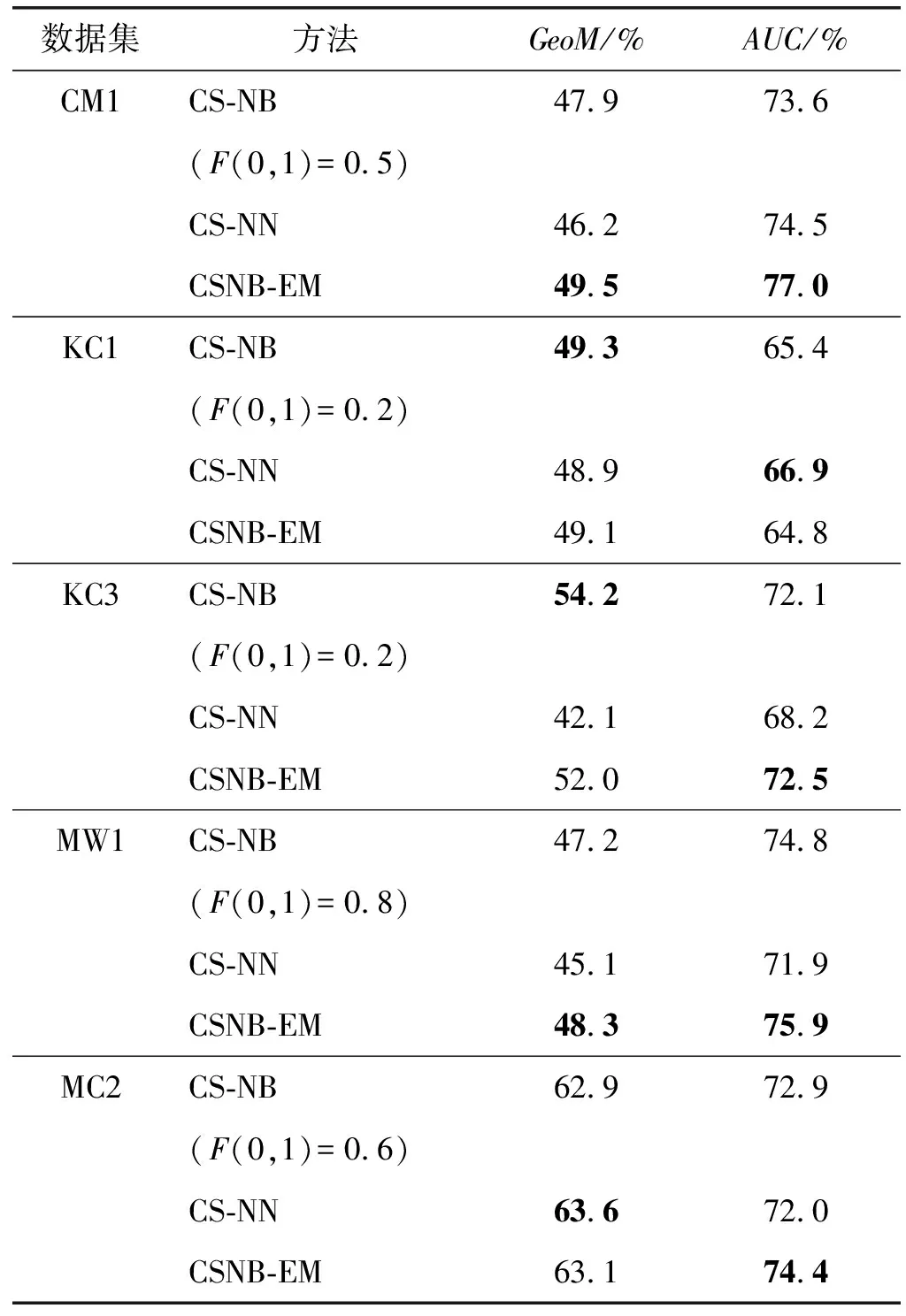
表6 模型性能
可以看出,在KC1与KC3数据集上,CSNB-EM模型的性能接近于用最优误分类代价构建的CS-NB模型,而在CM1、MW1、MC2三个数据集上CSNB-EM模型达到了比CS-NB模型更高的GeoM与AUC指标。这充分说明了CSNB-EM方法自适应调整模型参数的良好效果。虽然未标记数据的实际标签无法获取,不能直接判断最优误分类代价,但CSNB-EM方法利用未标记数据迭代调整误分类代价,同样构建了性能良好的分类模型。在CM1、MW1、MC2三个数据集上,CSNB-EM方法有更好的性能是由于方法还利用未标记数据调整先验概率P(c)与条件概率P(a|c),构建的模型更能适应整个数据集。另外,CS-NN方法在MC2上的GeoM略高于CSNB-EM方法。在KC1数据集上,CS-NN的GeoM与CSNB-EM方法相当,而AUC指标超过CSNB-EM方法2.1百分点。KC1上CSNB-EM方法的性能低于CS-NN的原因是EM算法对初始值的敏感性,得到的模型参数会受到在训练数据集上决定的初始模型参数的影响。在表6中还可以看出,所有方法在MC2上都取得了较好的GeoM性能,这与数据不平衡程度有关。在表3中MC2的不平衡度是1.841,是所有数据集里最小的,方法在相对平衡的数据集上更容易良好地折衷Recall与Precision的值,所以MC2上的GeoM明显高于其他数据集。
3.3 λ对模型性能的影响
本实验的目的是验证训练参数λ对CSNB-EM算法性能的影响。λ是本文在M-step修正模型参数时赋予未标记数据的权值,用来减弱未标记数据的影响。在实验数据中取20%的样本作为训练数据,分别用不同的λ值训练模型。实验结果如图2所示。可以看出,λ取得过高或过低都会对模型性能产生影响,在每一个数据级上,都是λ=0或λ=1的模型性能最低。当λ=0.2或λ=0.4时模型效果较好。当λ的值过低时,未标记数据对模型的修正作用有限。实际上,当λ=0时,CSNB-EM算法相当于用监督学习的方法构建模型。另外,由于未标记数据的数量明显大于训练数据的数量,λ取值过大会使得未标记数据对模型参数的影响过大,用未标记数据调整模型参数反而会降低模型性能。从图2中还可以看出,由于MC2数据集的不平衡程度较小,模型在MC2上的GeoM性能十分突出。
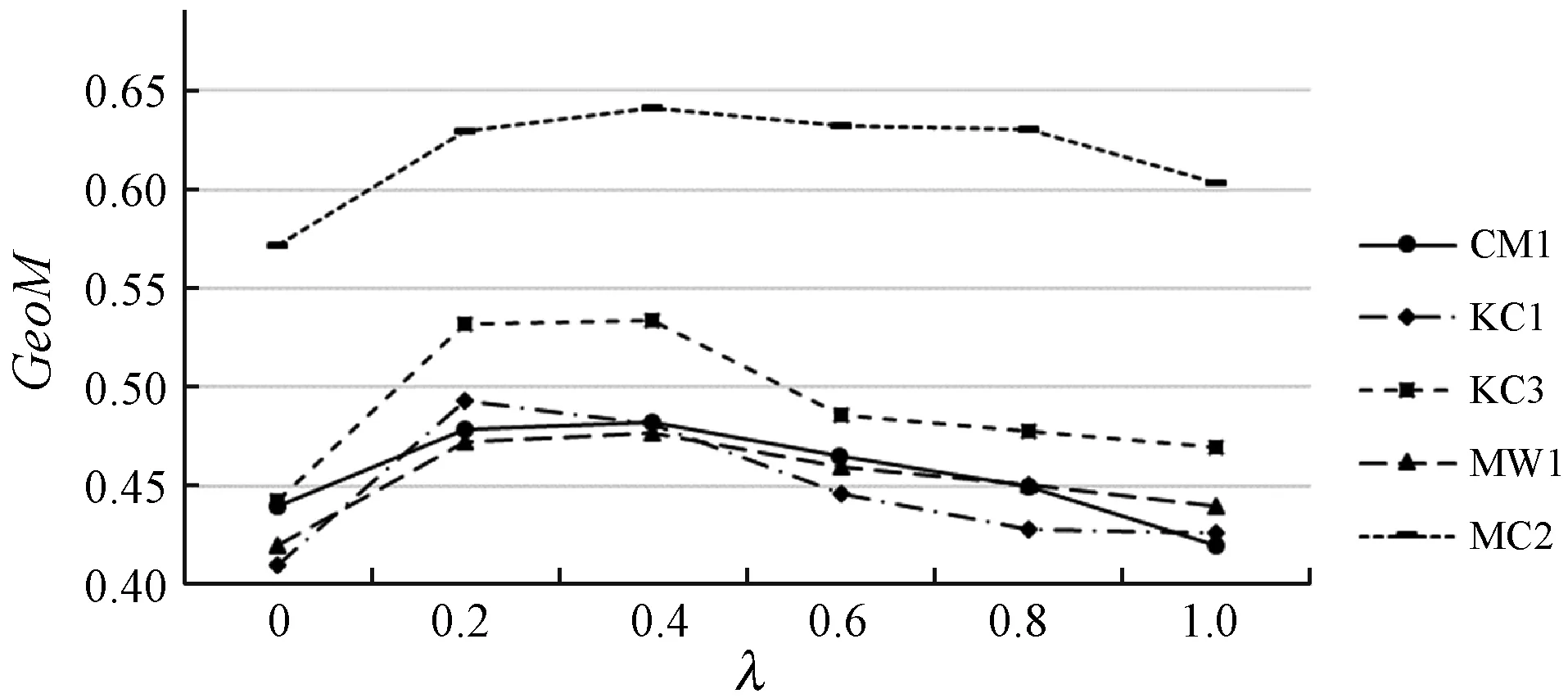
(a) GeoM
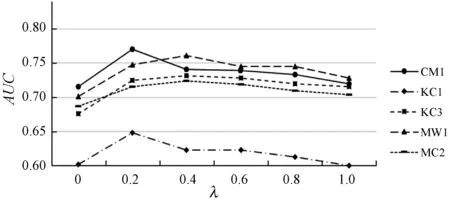
(b) AUC图2 λ对模型性能的影响
3.4 CSNB-EM方法的收敛性
本节通过实验验证方法的收敛性。在每一轮训练结束时都记录下当前模型在数据集中的性能。如图3所示,方法构建的模型总能同时在AUC与GeoM两个指标收敛到一个最优性能,同时收敛速度非常快,在每一个数据集上都在10次迭代之内基本收敛。实验结果表明,CSNB-EM方法具有良好的收敛性。
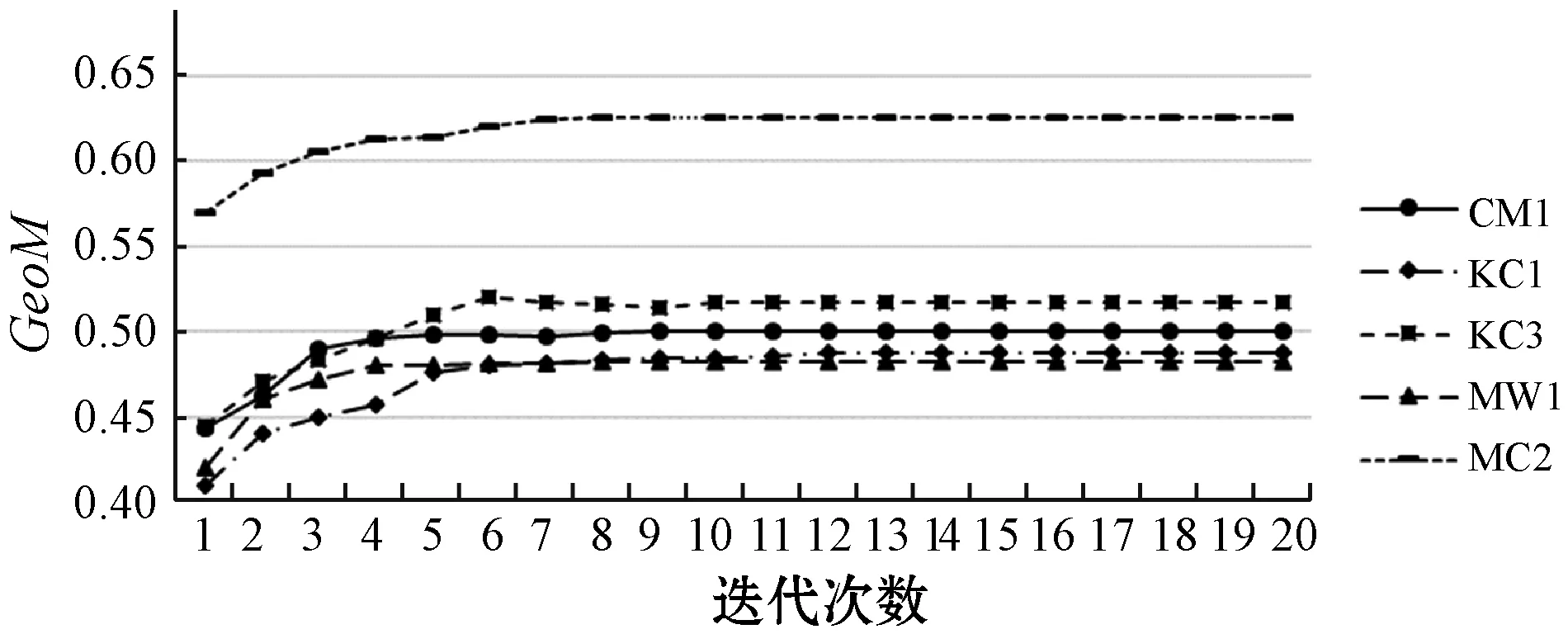
(a) GeoM
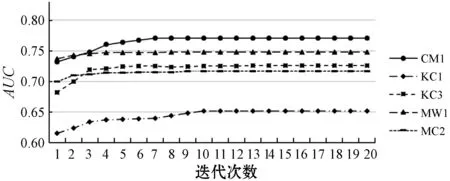
(b) AUC图3 CSNB-EM方法的收敛性
4 结 语
本文针对目前软件缺陷预测研究当中存在的误分类代价难以确定的问题,提出一种动态调整误分代价的半监督学习方法(CSNB-EM)。方法同时利用训练数据与未标记数据迭代优化模型参数,并且自适应地确定误分类代价的合理取值。在公开的MDP软件缺陷数据集的5个项目上进行实验,基于AUC与GeoM测评指标估计模型性能。实验结果表明,CSNB-EM算法与CS-NB、CS-NN等现有的软件缺陷预测算法相比,其构建的缺陷预测模型性能有明显提高。
