一种基于机载LiDAR数据的山区道路提取方法
2022-07-11刘国栋
刘国栋,刘 佳,刘 浪
(重庆交通大学 土木工程学院,重庆 400074)
引 言
山区道路因存在着树木遮挡、弯多坡陡的特性,给道路空间信息的获取带来了巨大的挑战。当前道路信息获取方法按照数据来源可分为3类:基于浮动车轨迹数据、基于遥感影像和基于高密度点云数据[1]。基于浮动车轨迹数据获取道路利用车辆的低频低精度全球定位系统 (global position system,GPS) 轨迹数据作为道路信息提取框架,具有数据获取成本低、现实性强等优点[2],但是主要应用在城市及一些车流量大的区域,对于山区道路适用性不大。基于遥感影像获取道路信息的研究已发展多年,有些方法还应用在了一些商业软件上,如:Erdas采用了模板匹配法、eCognition采用了面向对象法[3],但是基于遥感影像提取道路仍存在一些局限:树木遮挡造成的数据空白、同谱异物与同物异谱造成的误判、阴影以及影像的明暗变化造成的误判等[4]。基于高密度点云数据可以很好地规避用遥感影像提取道路的问题:由机载激光雷达 (light detection and ranging,LiDAR) 获取的点云具有同一性,不会有遥感影像因阴影以及明暗变化带来的误判[5]。机载LiDAR还具有一定穿透能力可获得多次回波,能在一定程度上避免由于树木的遮挡而造成的数据空白[6]。因此,利用机载LiDAR点云的丰富信息提取地形陡峭复杂、植被茂密且本身蜿蜒曲折的山区道路引起了众多研究人员的关注。
在机载LiDAR点云数据中,道路点有两个明显的特征:(1)因道路路面较为平滑,故路面点云间的高程差异和起伏差异都小于周围的建筑物、沟坎、植被等地物[4];(2)因一定区域内的道路一般采用的构筑材料一致,获取的路面点的反射强度具有一致性,与周围其它地物地面点具有明显区别[5]。目前,基于机载LiDAR点云数据提取山区道路都是基于以上特征进行。HE等人[7-9]利用道路的连续性与局部区域起伏较小等特性设定多特征阈值的方法来提取道路点取得了不错的效果,但是在阈值的设定上需要人为调试后设定效率较低,且阈值的普适性也较低。为解决道路提取阈值问题,HUI[10]与SNCHEZ等人[11]引入偏度平衡算法自动计算得到道路强度阈值,在城市等道路区域占比较大的区域得到了不错的效果,但是该方法不适合应用在农村及山区道路占比较少的地区。AZIZI等人[12]与FERRAZ等人[13]先将点云转为数字地面模型(digital terrain model,DTM)再分别引入支持向量机与随机森林机器学习算法,训练影像分类模型从DTM中提取道路栅格进而得到道路信息。将点云转为DTM提取道路虽缩短了计算时间,但却降低了道路的辨识度,最终影响道路提取精度。YUAN等人[14]直接引入了随机森林算法从多光谱LiDAR数据中提取获得道路中心线,使用多光谱LiDAR能增加分类特征,提高分类精度,但也同时增加了模型训练与分类的时间,降低了效率。
针对从机载LiDAR数据中提取山区道路阈值设定难、普适性与提取效率低的问题,本文中直接将随机森林分类模型应用在滤波后的地面点云中,选用坡度、粗糙度等5类特征提取初始道路点云,再通过基于密度的噪声应用空间聚类算法 (density-based spatial clustering of application with noise,DBSCAN) 聚类精化,最后栅格投影矢量化得到道路中心线。
1 山区道路提取方法
本文中主要是对参考文献[13]中的道路提取方法进行改进,提出一种将随机森林分类模型直接应用在机载LiDAR点云中提取山区道路,具体方法流程如图1所示。
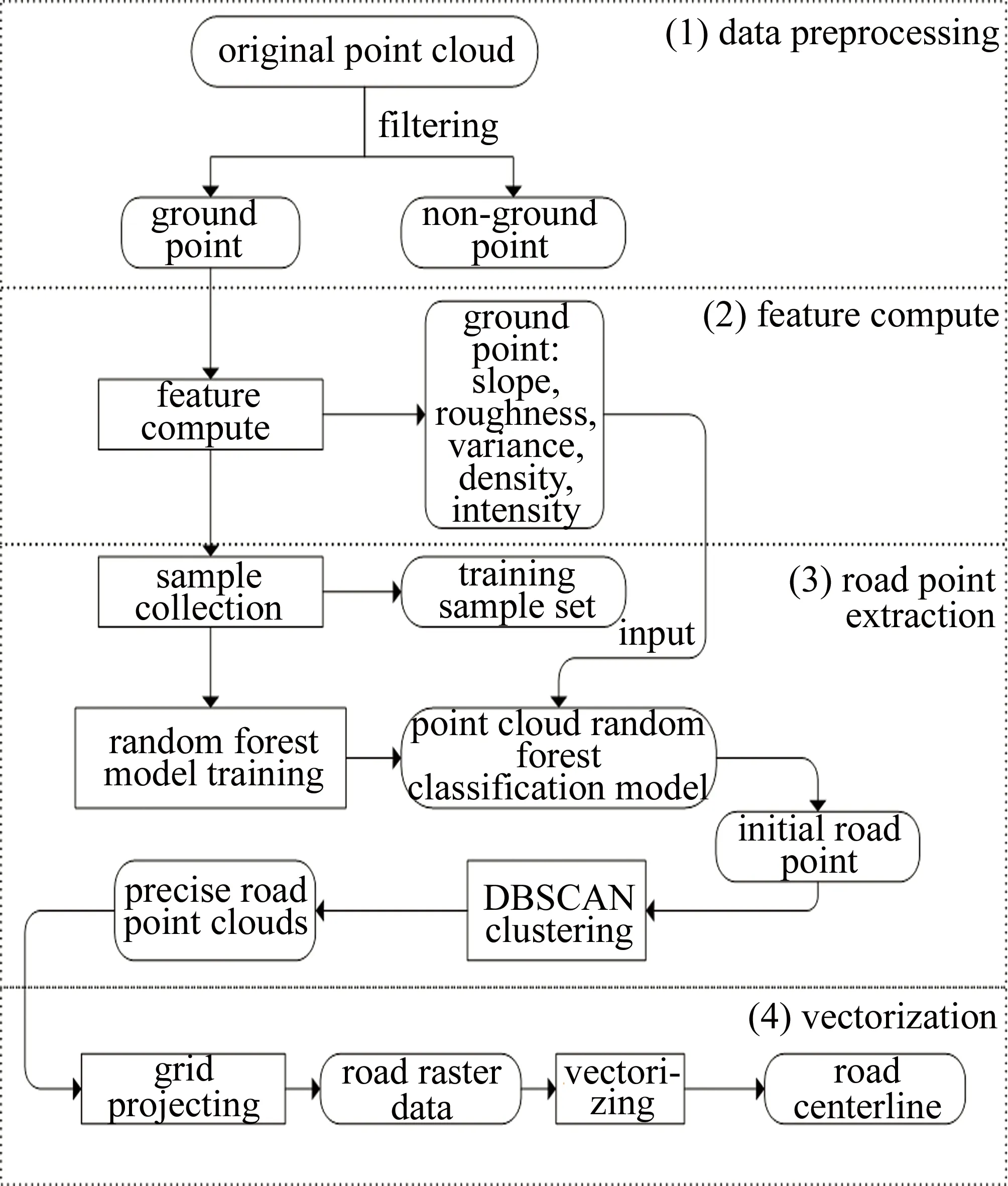
Fig.1 Flow chart of extraction method
主要分4个阶段进行:
(1)数据预处理。点云滤波,道路点归属地面点云范畴,从原始机载LiDAR点云数据出发,滤除房屋、电线、植被等非地面点,滤波获取取地面点云。
(2)特征计算。根据山区道路特性,除原始机载LiDAR点云的反射强度信息之外,计算地面点云各点邻域特征:坡度、粗糙度、高差方差和点密度,与原反射强度共同组成点云分类的特征集。
(3)道路点云提取。样本集制作:从特征计算完成的点云中,手动提取道路点与非道路点,并赋上类别标签制作成样本集。模型训练:将样本集进行随机森林分类模型训练,得到点云随机森林分类模型。初始道路点云提取:把地面点云特征值输入分类模型中,取得各点的类别标签,按道路类别提取初始道路点云。精化道路点云:采用DBSCAN聚类算法对初始道路点云去噪精化。
(4)矢量化。将精化道路点云格网化重采样投影到xOy平面生成道路栅格数据,再对栅格数据矢量化,最终获得道路中心线。
2 点云特征
为将道路点所具备的连续性、平滑性及反射强度一致性等特征应用到道路提取中来,计算地面点云各点在邻域内的坡度、粗糙度、高差方差及点密度,与点云的反射强度组成点云的分类特征。
(1)坡度。邻域点的拟合平面与水平面的夹角。道路区域在局部邻域范围内可近似看作为平面,相对于非道路区域,道路区域的坡度相对较小且稳定。空间中,点的法向量是描述点所在面的朝向,可通过先计算法向量再求得点的坡度值。对每个离散点的邻域点进行平面拟合,将拟合的平面方程转换为一般式,需满足下式:
Ax+By+Cz=D,(D≥0,A2+B2+C2=1)
(1)
式中,A,B,C分别为平面的法向量在x,y,z这3个方向上的分量,D为常数。为获取最佳拟合平面,采用最小二乘法求解拟合平面,即保证所有点到平面的距离之和最小。所求的法向量中,z方向的分量表示点邻域范围坡度的平缓程度,该分量越大表示越平缓,反之越陡峭,为便于理解将之转化为坡度表示:
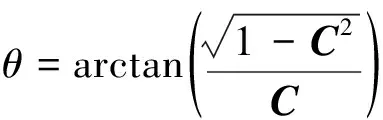
(2)
式中,θ为拟合平面坡度。
(2)粗糙度。邻域内所有点的高程标准差。山区道路具有连续性,在小区域范围内路面高程值差异小,不会出现大的波动与突变,计算的高程标准差可评估局部区域的异质性,值越大表明邻域内高程变化越大,当前点属于道路点的可能性就越小。
(3)高差方差。邻域内所有点与当前点的高差方差,用以描述点在邻域内的高差变化的稳定性。相对非道路点云,道路点云高程变化缓和,高差方差较小。
(4)点密度。即点邻域内的点个数,道路区域相较于其它地面区域因地势平坦、树木遮挡较少,滤波后的该区域点较为密集。
(5)反射强度。LiDAR点云对于相同材质的地物反射强度具有很强的同一性,利用反射强度特征进行道路的提取,这为道路点云的分类提取提供了最重要的特征,也是最有区别力度的分类特征。
3 山区道路提取实验与分析
实验中所使用机载LiDAR点云数据来源于美国普吉特海湾激光雷达联盟(The Puget Sound LiDAR Consortium,PSLC) 2013 Entiat River LiDAR项目所提供的部分山区点云数据,如图2所示。数据中共计点2738288个,平均点密度为13.82/m2,实验数据包含地面、植被、道路、房屋等点,道路位于数据中央地势平缓的沟谷区域,道路两侧为山区常见的陡缓坡交替地形,点云高差达到205.76m,具有很好的山区代表性。
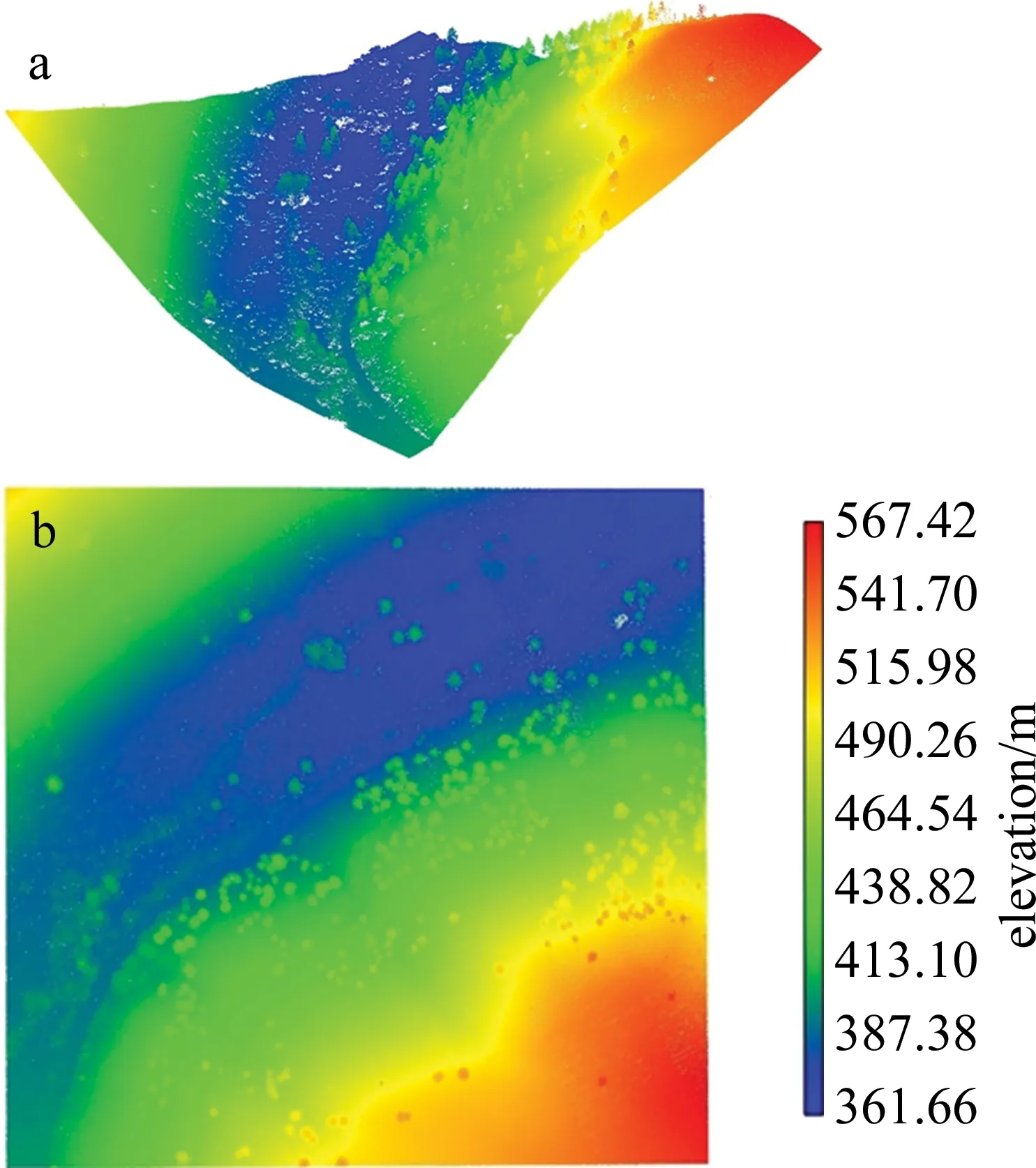
Fig.2 Experimental data
3.1 数据预处理
本文中使用LiDAR360点云软件滤波,考虑山区地形高差起伏变化较大,采用在山地森林地区稳健性较好的渐进加密三角网滤波法[15]对原始LiDAR点云滤波,该方法首先需参考数据内最大建筑物的边长划分虚拟格网,获取格网内最低点作为地面种子点。然后对种子点建立不规则三角网 (triangulated irregular network, TIN) 进行迭代加密,迭代过程中,计算判断其余点到所对应三角形的距离与角度是否满足阈值,满足则加入地面点中生成新TIN。迭代过程一直到没有点再加入TIN为止,最后TIN中的点即为地面点。滤波结果如图3所示,获取地面点共计1281419个,树木房屋等非地面点基本去除,且道路区域点云保留良好。
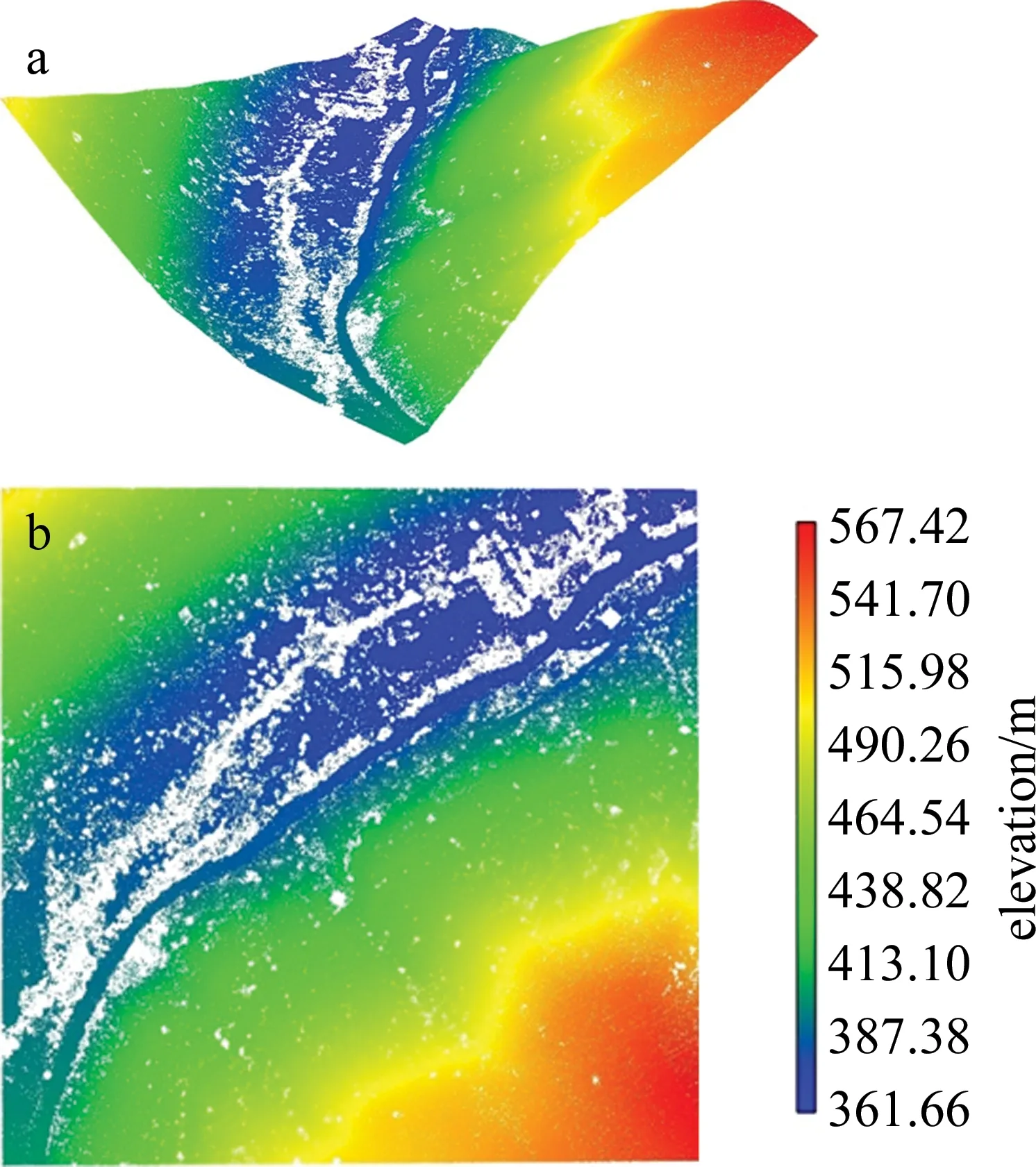
Fig.3 Ground point cloud after filtering
3.2 特征计算
地面点云特征计算可根据点云的密度来设置邻域距离,其原则是计算尽量小的区域范围,但需尽可能地减少计算特征出现空值。本文中数据滤波后的平均点密度为6.5/m2,将点邻域设置为0.5m来计算点云特征,对各个特征进行灰度可视化渲染,如图4所示。
在坡度、粗糙度与高差方差3个点云特征图像中,整体道路点云表征明显,与周围非道路点云差异较大,特征值主要集中在小数值上,可以作为道路点分类判断的重要依据。在点密度特征图像中,整体道路点云密度较非道路点云要大,但是某些路段区域却出现断层现象(点密度变小),分析原因可能是因为原始激光点云采集时扫描不均匀,导致这些区域点密度过小。在反射强度特征图像中,呈现出两条具有不同特性的道路:其中一条道路点云反射强度值集中在较小数值上,与周围非道路点云差异明显;但另一条道路点云反射强度值与周围非道路点云差异不大,推断是因该条道路所用材质为沙石泥土所致。为了能够得到完整的道路点云,在道路点云提取过程中需要将所有道路点云所表现出的点云特征都予以考虑,即在样本采集时对密度小的道路断层区域与道路反射强度差异小的区域选择性采集。
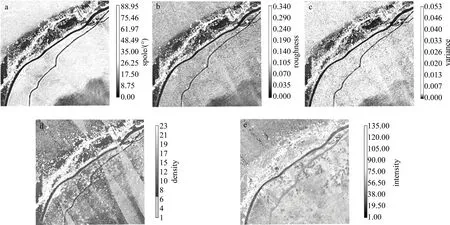
Fig.4 Point cloud characteristics
3.3 道路点云提取
3.3.1 样本集制作与分析 本文中道路点云提取采用一种监督分类的方式,需要对特征计算完成的地面点云人工采集具有代表性的先验点作为样本集。样本类别分为两类,正样本即道路点,负样本即非道路点。为了结果能获取较完整道路点,样本采集尤为关键,需要遵循代表性、概括性与完整性,根据山区道路点云特征,选择主要依据可为反射强度值、坡度和地形表面的高程起伏形态。使用CloudCompare软件从特征计算完成的点云中,手动提取正负样本点,并赋上类别标签。分析山区道路的分布与计算完成的分类特征后,最终确定训练样本集分3个区域采集,主要围绕道路分布在河谷区域、山腰区域(样本集在地面点具体分布如图5所示)共计100494个,道路点(标签值为1)33848个,非道路点(标签值为0)66646个。
为分析点类别与点特征的相关性,绘制样本集的两类点在各特征上的分布图,如图6所示。纵坐标是各个特征对应特征值点云个数,横坐标除了图6a以外,其余都是无量纲量。由图6可看出,道路点与非道路点在各特征中分布具有明显差异,在坡度、粗糙度、高差方差特征中,道路点分布聚集且峰值突出并集中在较小的数值上,而非道路点分布则较为分散,峰值出现在较大数值上;在点密度与反射强度特征上:道路点密度较非道路点大,而反射强度则较小。因此坡度、粗糙度、高差方差、点密度与反射强度可以作为道路点云判断分类的重要特征。

Fig.5 Samples point(“1” for road points, “0” for non-road points)
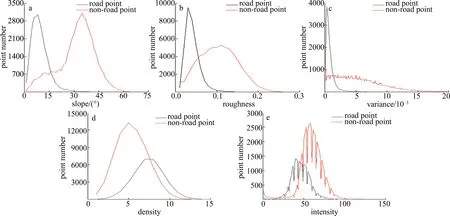
Fig.6 Road points and non-road points are distributed in various features
3.3.2 点云随机森林分类模型构建 随机森林是BREIMAN于2001年提出的一种机器学习预测分类算法[16],以决策树为基本单元,通过将多棵决策树集成在一起,最终结果由每棵决策树结果综合投票所得。随机森林是以随机抽样方式构造出不同训练集,使每棵决策树之间都没有关联,从而提高分类模型的外推能力,不易出现过拟合现象,同时对异常值与噪声都又很强的容忍度[17]。在面对分类数据不平衡时,如山区道路点云占地面点云比例非常小,使用随机森林可进行误差平衡,做到准确分类。
把采集制作的样本集按照7∶3随机拆分为训练集与测试集,使用训练集进行点云随机森林分类模型构建。将计算的5个点云特征以及样本集的类别标签作为模型训练构建的输入值,通过Python编程构建点云随机森林分类模型,构建步骤[18]见下:(1)从训练样本集中有放回的随机抽取n个样本数据,再从所有特征中随机抽取m个特征变量,由此生成新的点云样本集合,训练生成点云分类决策树;(2)重复上述过程生成k棵分类决策树,每棵决策树对应根节点储存抽取的样本数据,从根节点出发,按照最小不纯度原则寻找最佳特征变量,分裂生成子节点;(3)对每棵树递归地选择分裂节点,直至不能继续分裂为止,但在实际过程中,为加快决策树的生成与防备过拟合现象发生,需要设定额外的限制条件——最大树深和最小叶节点,即决策树在小于最大树深才能进行生长分裂;节点数据量在大于最小叶节点才能继续分裂[19];(4)将生成的k棵分类决策树组成随机森林,在测试阶段,每棵决策树都对测试样例进行一次投票,最后综合票数最多的类别属性赋值给测试样例,以实现随机森林分类。
点云随机森林分类模型结构如图7所示。
将测试点云样本集输入分类模型中,随机抽取点云样本集输入给每棵决策树;每棵决策树又对输入的3维点进行决策分类,获得点的类别属性;最后综合所有决策树的分类结果,对测试样本集中各点的类别进行投票,票数最多的类别赋值给该点,即得到测试点云样本集中的模型分类结果。
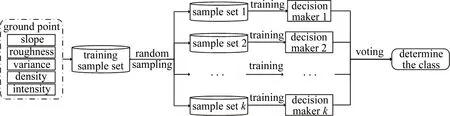
Fig.7 Point cloud random forest classification model
引入分类器评价指标[20]可得到模型精度评定,如表1所示。
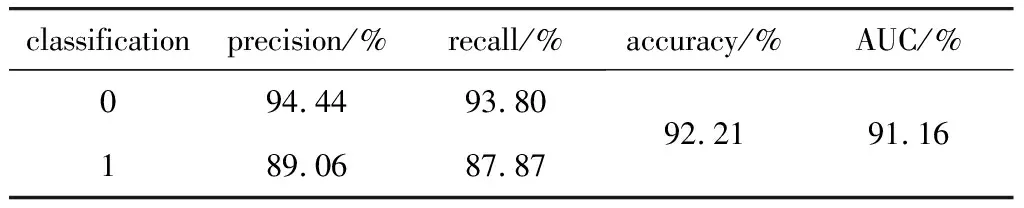
Table 1 Accuracy evaluation table of point cloud random forest classification model
表1中点云类别0为非道路点,1为道路点;precision为查准率,是分类模型判定正例中的正样本比重;recall为查全率,是被预测正例占总正例的比重;accuracy为准确率,是分类器对整个样本判断正确的比重;接受者操作特性(receiver operating characteristic,ROC)曲线下面积(area under curve,AUC),即预测正确概率值。由表1可知,模型对道路点的预测分类查准率达到89.06%,查全率达到87.87%,分类模型的预测分类性也达到91.16%,说明分类模型能较好预测点云类别,能够应用于山区道路点云分类提取。
3.3.3 道路点云分类提取 (1)初始道路点云提取。把地面点云输入进随机森林分类模型中进行分类预测,得到每个地面点的预测类别标签,将其赋值到地面点云数据上,使每个点都有类别标签,按照道路点类别标签1输出得到初始道路点云,结果如图8a所示。

Fig.8 Road extraction results
初始道路点云共计点251887个,由图8a可以看出,道路的整体基本提取完成,形状与走向也还是较为明确,但是道路周围还伴随着大量非道路噪声点,部分还聚集成块状分布。经分析发现这些噪声点主要分为两类:远离道路的平缓离散噪声点和聚集成块且坡度平缓的河谷区域。
(2)精华道路点云。为精化分类提取的道路点云,本文中采用DBSCAN聚类算法进行去噪处理[9]。聚类参量初次设置可参考原始点云密度与特征邻域计算范围,然后根据可视化聚类效果进行调整,如本文中初始参量设置为:扫描半径E=0.5m、最小包含点数M=6。经多次调整试验后,参量设定为:E=0.8m,M=6,初始道路点云聚簇共有1271簇,将聚类结果赋色可视化渲染,如图8b所示,蓝色条带状为道路点簇。将道路点簇的点云输出即得精化道路点云,所得精化道路点云共计点78209个,如图8c所示,相比初始道路点云,噪声点去除效果显著,基本去除。
3.4 道路矢量化
为方便道路数据管理使用,精化的道路点云需要转化为道路矢量线。使用ArcGIS软件将精化后的道路点按1m×1m规格设定划分格网,投影到xOy平面,得到道路栅格图像,再将道路栅格图像二值化,最后矢量化得到道路中线。把本文中方法提取道路中心线与手动提取道路的中心线叠加对比,如图9所示(红色为本文中方法提取,黑色为手动提取)。由图9可知,本文中方法提取的山区道路整体走向基本与手动道路重合,证明本文中方法可高精度提取山区道路。
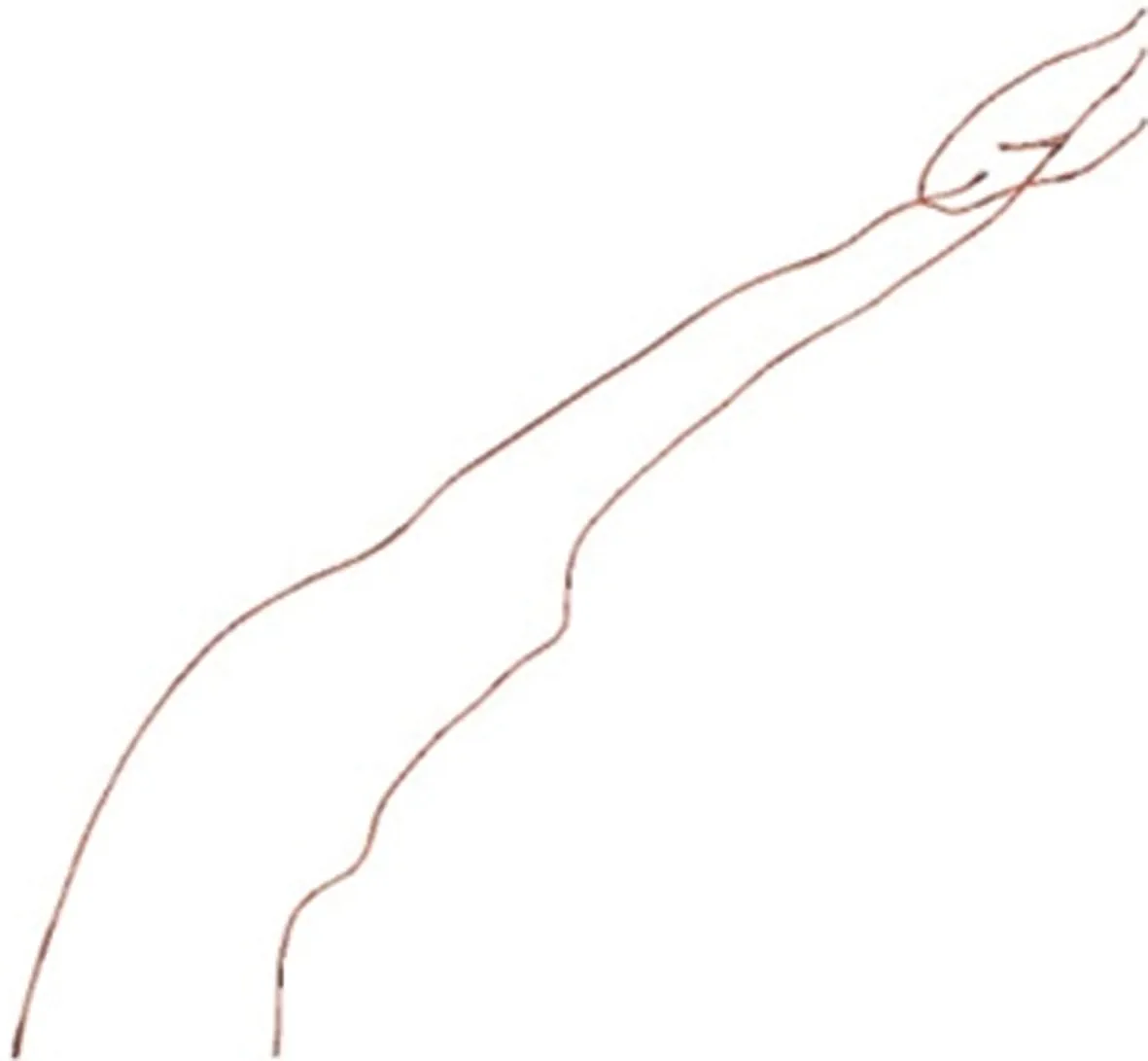
Fig.9 Road centerline
4 精度评定
为评定道路提取的精度,在缺乏实验区域高精度道路信息的情况下,使用手动提取道路信息作评定标准,是道路提取精度评定的重要手段[8]。本文中鉴于机载LiDAR点云在3维空间信息上具有高精度的特点,使用手动提取原数据中的道路点云作为真值,对文中所述道路提取方法提取到的道路点云通过正确率Ct、完整率Cc和提取质量Cq来进行精度评定。
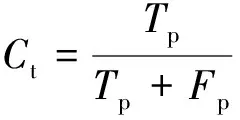
(3)
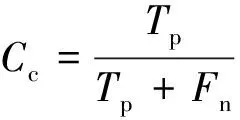
(4)
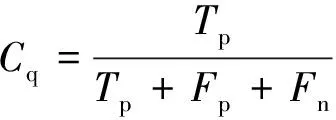
(5)
式中,Tp为正确提取到的道路点;Fn为未提取到的道路点;Fp为错误提取到的道路点。
实验中区域手动提取道路点云为80163个,视作为真实道路点云,计算道路点云提取的完整率、正确率、质量3个指标,进行提取结果精度评定。引用参考文献[9]中的山区道路提取方法进行对比,如表2所示。

Table 2 Accuracy evaluation table of road point extraction
两种方法道路提取的正确率都较高,达到95%以上,完整率与提取质量也都能达到86%以上,综合相比之下,本文中的方法略优于参考文献[9]。在整个道路提取过程中,本文中方法使用对少量样本训练获得的随机森林分类模型,能自动提取道路点云,人为参与度较少,操作简便且结果精度较高。参考文献[9]中则是通过人为设定多特征阈值进行分类提取道路点云,分类提取时若其中一个阈值出现偏差,则会影响到整体的提取结果。因此该方法在每个特征阈值的设定上,都需要人为多次测试找到最佳阈值,操作过程较为繁琐,且阈值设定还都需要考虑数据整体效果,在复杂的场景下将面临阈值普适性差引起道路点云提取困难的问题。综合精度与操作简易因素,选择本文中的方法用于山区道路提取更佳。
将两种方法提取的道路点云与手动道路提取道路点云叠加对比,发现都存在未提取的道路点主要集中在山腰处的道路边界,错误提取点集中在河谷道路边界。经分析可知,是因山腰处的道路蜿蜒崎岖且两侧点的高程差异大、坡度变化大;河谷处的道路较为平坦,两侧点的高程差异与坡度变化较小所致。在计算山腰道路边界点的分类特征时,邻域内包含大量非道路点,从而影响计算的分类特征值易偏向于非道路点造成漏分现象。在计算河谷道路边界外点的分类特征时,邻域内包含大量道路点,使分类特征易偏向于道路点造成错分现象。
5 结 论
本文中以Entiat River 地区部分山区LiDAR点云数据为例,验证所提出的使用随机森林分类模型提取山区道路点云再通过聚类精化、栅格矢量化获得道路矢量线的方法。首先对原始机载LiDAR点云滤波获取地面点云,接着计算地面点的粗糙度、坡度、高差方差和点密度与反射强度组成分类特征值;然后手动采集少量正负样本训练山区道路点云随机森林分类模型,测试验证模型的分类预测正确率达到了91.16%,可用于分类提取山区道路点云;随后使用分类模型对地面点云分类提取初始道路点云,经DBSCAN聚类去噪获取精化道路点云,再栅格化、矢量化得到山区道路中心线;最后用手动提取道路点云对本文中方法道路点云提取作精度评定,又引入多特征阈值提取山区道路方法作比较。结果表明,使用本文中的方法不需要设定特征阈值就能高精度提取到山区道路信息。
使用LiDAR数据提取山区道路有一些需注意的地方:部分路段由于树木遮挡使原始点云中地面点云过于稀疏,导致提取到的初始道路点云较为稀少,通过聚类精化后就会出现孔洞、断截,可在原始激光点云采集时多角度、多架次进行,以提高地面点云密度,减少此类现象发生。
