单幅图像去雾的多步融合自适应特征注意网络
2022-07-11张嘉伟刘晓晨赵东花王晨光
张嘉伟, 刘晓晨, 赵东花, 王晨光, 申 冲 , 唐 军, 刘 俊
(1. 中北大学 仪器科学与动态测试教育部重点实验室, 山西 太原 030051;2. 中北大学 量子传感与精密测量仪器山西省重点实验室(201905D121001), 山西 太原 030051;3. 东南大学 仪器科学与工程学院, 江苏 南京 210096; 4. 中北大学 信息与通信工程学, 山西 太原 030051)
0 引 言
长期以来, 模糊场景下获取的输入图像严重影响了计算机视觉任务的性能表现. 当环境受到诸如烟雾、 雾霾、 灰尘等大气中漂浮颗粒物的影响时, 人类在自然界的活动就会受到严重的影响, 甚至因为能见度的缺乏而威胁到自身人身安全. 户外拍摄的照片往往会出现对比度下降等问题, 其中包括颜色和结构细节的退化. 因此, 单幅图像去雾逐渐成为一项重要的研究课题, 其目的是有效地从受损输入图像中恢复清晰图像的基本信息. 这可以被用作许多领域的高级视觉任务的预先准备工作, 例如实时目标检测、 遥感和自动无人运输等等. 而其他的一些最初受到雾中环境影响的计算机视觉应用, 也有机会得以完成.
一般来讲, 雾天图像的生成可以通过经典的大气散射模型来描述, 在物理大气散射模型的基础上, 早期研究中大多数去雾方法的提出依赖于物理学的先验知识和各种假设[1-2]. 如He等[1]提出的暗通道先验算法(DCP)就是其中最具代表性的算法, 这种方法在图像去雾方面取得了一定的成绩, 但其假设并不能准确地反映出图像的内在属性. 因此, 这些技术的性能通常是极为有限的.
随着近年来深度学习技术的兴起与发展, 其逐渐被应用到一些简单的计算机视觉任务中, 比如目标识别和图像重建等等. 与传统方法相比, 深度学习方法具有非凡的去雾能力和鲁棒性. 此外, 随着卷积神经网络(CNN)技术在图像去雾方面取得的显著成就, 越来越多的研究团队倾向于使用类似的方法来估计大气光以及传输图, 利用外部数据以达到预期的效果. 例如, 在文献[3]中, 采用端到端的方式来预估传输图. 而在之后的研究中[4-6], 各种新技术逐渐被加入到这一领域来加强网络的去雾效果. 由于深度学习网络具有较强的表达性, 这些端到端的网络模型往往能够获得比以往研究更好的去雾效果. 但是, 通常现实中的雾比计算机模拟的雾要复杂得多, 这也使得这些方法更难处理现实的雾天图像. 另一方面, 它们都不可避免地需要巨额成本来支持计算. 以往的研究过多地集中于通过大幅度增加模型的深度或宽度和使用大量的训练参数来提高网络的去雾性能[5,7-8]. 但它们并没有合理地考虑时间消耗、 内存消耗或计算消耗, 这也使得这些模型不能应用于资源有限的环境中(如移动端设备).
本文提出了一种基于多步融合的端到端自适应特征注意去雾网络用于单幅图像去雾. 以往基于卷积神经网络的图像去雾网络通常采用固定形状的卷积核, 导致无法有效利用特征空间中的结构线索. 而本文提出的自适应特征注意模块可以在训练过程中自适应调整可变形卷积核来获取和处理空间中的关键结构信息. 此外, 多步融合模块的应用能够使网络中不同层次、 不同步骤间的特征有效地结合在一起. 该网络结构简化而紧凑, 不仅降低了计算消耗, 而且在多个数据集和真实雾天图像上皆显示了良好的视觉效果. 大量的实验结果表明, 本文的去雾网络具有较高的有效性和实用性.
1 多步融合自适应特征注意网络
受文献[7]中FA模块的启发, 本文提出了一个新的自适应特征注意模块作为本网络的基本模块, 并且只需要5个该模块用于网络的主要架构. 与此同时, 每个自适应特征注意模块之间采用多步融合模块来实现不同步骤之间的特征融合, 极大程度降低了计算所需的内存(相比于原始网络[7]中的57个特征注意模块). 如图 1 所示, 本文的网络首先应用下采样操作(如一个步长为1的卷积层和一个步长为2的卷积层,其后是各自的ReLU函数)为使后续模块获得学习低分辨率域特征表示的能力. 在经过连续的自适应特征注意模块和多步融合模块后, 最终使用相关的上采样操作生成恢复的无雾图像. 一般来说, 随着网络深度的增加, 边缘等浅层特征会在训练过程中逐渐丢失. 包括文献[7,9]在内的一些研究, 会通过多跳连接的操作将浅层特征和深层特征结合起来形成输出.
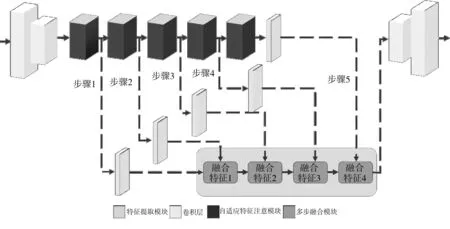
图1 基于多步融合的自适应特征注意网络体系结构
1.1 自适应特征注意模块
在早期的研究中[5,7,10], 通常采用图 2 右上方所示的固定网络卷积核, 这导致了接受域的局限性, 使其无法有效地探索特征空间中的结构化线索. 因此, 为了解决这个问题, 调整接受域的形状至关重要. 如图 2 右下方所示, 由于可变形卷积核的灵活性, 它能够自适应地获取更关键的结构信息.

图2 可变形卷积原理Fig.2 Principle of deformable convolution
空间不变的卷积核通常会导致图像纹理的破坏, 这在之前的研究中已经得到证实. 作为本文自适应特征注意模块的核心要素, 在原始像素注意模块[11]中引入2个具有可变形2D核的可变形卷积层, 如图 3 所示.
该方法实现了感受野的自适应扩展, 提高了模型在聚焦于浓雾像素和高频图像区域计算时的转换能力. 对网格的无约束变形进行采样的能力也使网络能够自适应地整合更多的空间结构信息, 以达到更好的去雾效果. 此外, 在每个自适应特征注意模块中, 深层部署时的可变形卷积效果优于浅层部署时的可变形卷积效果. 因此, 该过程可以定义为
PA=Fin⊗
σ(DfConv(DfConv(Conv(δ((Conv(Fin))))))),
(1)
式中:DfConv代表可变形卷积运算;σ为sigmoid函数. 自适应特征注意模块的其余部分基本保持了特征注意模块[7]的网络结构.
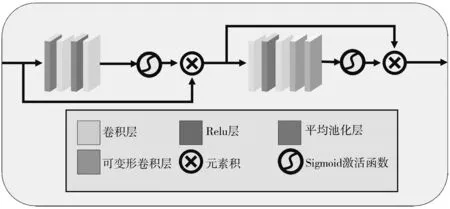
图3 自适应特征注意模块的基本架构Fig.3 The basic architecture of the self-adaptation featureattention module
1.2 多步融合模块
一般情况下, 包括边缘等局部信息在内的低级特征通常很容易被提取出来. 随着感受野的提升, 网络可以通过高级特征获得全局范围的语义. 在诸多例如目标检测、 图像恢复等基于CNN任务的情况下, 应用不同层次的特征提取与融合方法取得了显著的效果. 然而, 在图像去雾领域, 现有的特征融合方法没有充分考虑不同层次的特征融合. 通常, 只使用高级特征会导致图像缺乏局部细节; 而只应用低级特征虽然保留了细节, 但并不能有效地在全局级别恢复语义. 为了充分利用该方法的优点, 本文在去雾网络加入了多步特征融合模块. 如图 1 所示, 从左到右共有4个融合模块. 第1个模块将来自步骤1和步骤2的特征进行融合, 得到的融合特征1将被作为低级特征继续与第2个融合模块中步骤3的高级特征进行融合, 生成融合特征2. 同样地, 步骤4之后生成的融合特征3也被用于步骤5后的最终特征融合模块.
对于每个特征融合模块, 通常分别存在一个低级特征和一个高级特征. 它们在融合之前都要经过一个卷积层, 然后通过一个元素积来完成融合操作. 融合特征将两个不同的特征组合在一起, 经过卷积层和ReLU层, 然后依次由下一个融合模块进行处理. 各融合模块的高级特征和低级特征分别表示为Fh和Fl,δ表示ReLU函数,Fout表示整个模块的最终输出. 最后, 这个过程可表示为
Fout=δ(Conv(Conv(Fh)⊗Conv(Fl))).
(2)
2 实验结果和讨论
由于采集真实的雾天图像及其对照难度较大, 本文首先从RESIDE标准数据集[12]中选择户外训练集(OTS)和合成目标测试集(SOTS)分别作为训练目标和测试目标. 该数据集包含了丰富的合成雾天室内外图像以及与之相关的清晰图像(即真值). 在基于CNN的图像去雾领域, 其一直被研究者作为一个评估网络性能的基准. 为了进一步评估本模型在现实场景中的综合去雾能力, 本文还采用了Dense-Haze数据集[13]和NH-HAZE数据集[14], 这两个数据集分别包含了来自各种室内外场景的均匀和不均匀浓雾及其对应真值的55对图像. 本文采用峰值信噪比(PSNR)和结构相似性指数(SSIM)作为评估部分的度量, 这些也是在去雾任务中用于比较图像质量的最常用标准.
首先, 本文利用合成数据集SOTS, 根据视觉效果和定量精度对所提网络进行测试. 将本文所提方法恢复图像的视觉效果与其他先进技术进行比较, 结果如图 4 所示, 可以清楚地看到, 虽然使用了文献[1]和文献[5]方法的图像成功地消除了雾霾, 但也造成了颜色失真、 亮度过高等问题. 相比之下, 利用文献[6]和文献[7]的方法获得了相对较好的输出结果, 但图像的局部区域中仍存在着少量雾霾.

图4 SOTS数据集图像的视觉结果比较
此外, 本方法还与文献[1]、 文献[5]、 文献[6] 和文献[7]等方法进行了实验比较, 测试集的定量结果如表 1 所示.

表 1 在SOTS数据集上与其它先进技术结果的定量比较Tab.1 Quantitative comparisons of results with SOTAtechniques on SOTS dataset
通过与表1中文献[7]方法比较可以看出, 本文的自适应特征注意网络实现了0.15 dB PSNR的性能提高, 虽然SSIM略微下降了0.007 5, 但由本文方法生成的图像更加自然.
本文方法在文献[13]和文献[14]两个数据集的测试结果与使用其他先进方法的结果进行了充分比较. 由于这两者的浓雾密度都远远超出RESIDE数据集[12], 导致雾的去除难度更大. 从图 5 和图 6 可以看出, 无论是文献[1]、 文献[6]还是文献[5]方法, 对于消除图片中浓雾的视觉效果都是极其有限的, 在处理后的图像中仍然存在大部分雾. 而利用文献[7]方法去雾后的图像中仍存在纹理丢失和颜色退化等特殊问题(尽管该算法的综合性能相对前几种较好). 通过视觉效果的比较, 本文方法在保留原图像细节和结构的同时, 恢复出的图像显然比其他方法更加清晰.

图5 Dense-Haze数据集上图像的视觉效果比较

图6 NH-HAZE数据集上图像的视觉效果比较Fig.6 Visual results comparison of images on NH-HAZE dataset
如表 2 和表 3 所示, 在得到16.23 dB PSNR和0.521 3 SSIM的情况下, 本文的自适应特征注意网络在Dense-Haze数据集[13]上的性能远远优于其它方法. 此外, 其在NH-HAZE数据集[14]上获得的PSNR和SSIM也是令人满意的, 分别为21.38 dB和0.714 4.

表 2 在Dense-Haze数据集上与其它先进技术结果的定量比较Tab.2 Quantitative comparisons of results with SOTA techniqueson Dense-Haze dataset
此外, 通过在相同平台上进行的实验对比, 从表 3 的第3行与第4行中不难发现, 本文提出的网络在相对较少参数的情况下取得了较好的结果, 在计算参数和图像恢复指标之间实现了较好的权衡, 同时, 也有效地降低了计算时间与损耗.
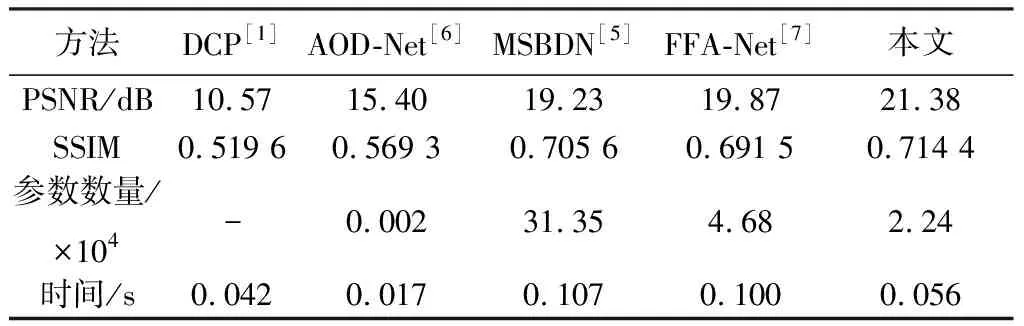
表 3 在NH-HAZE数据集上与其它先进技术结果的定量比较Tab.3 Quantitative comparisons of results with SOTA techniqueson NH-HAZE dataset
为了测试网络在真实雾天照片上的去雾效果, 本文对从RTTS[12]数据集中获得的大量真实雾天照片以及作者在大学校园内收集的部分雾天图像进行了测试和比较, 可视结果如图 7 所示.

图7 真实雾天照片的视觉效果比较Fig.7 Visual results comparison of real photographs with haze
可以看出, 虽然文献[6]、 文献[5]和文献[7]方法在人工数据集上表现很好, 但它们对该类真实图像的去雾效果并不十分令人满意. 另外, 相对有效的文献[1]方法容易产生颜色失真, 使图像受到过度增强. 在某些情况下, 文献[6]方法结果出现了浮动阴影, 而经过文献[5]方法处理后的图像亮度相对变低. 总体而言, 本文模型在保持图像整体亮度的同时, 在图像细节恢复方面取得了较为出色的视觉效果, 重构出的图像清晰、 无雾且感知质量良好.
3 结束语
本文提出了一种端到端的去雾网络, 该网络主要由自适应特征注意模块和多步融合模块组成. 其中前者能够自适应地提取带雾图像的细节特征, 从而扩大了处理复杂信息的范围, 显著提高了网络的转换能力. 后者使用来自多个步骤的特征并从它们的融合中获得增益. 通过在不同数据集上进行的大量实验, 并与几种不同类型算法的结果进行比较, 本文方法均取得了较好的效果, 证明了该网络结构在图像细节恢复方面的明显优势. 此外, 由于网络的深度与设计的复杂性降低, 更紧凑的网络显著减少了算力功耗和操作所需的时间.
