基于潜变量增长曲线模型的糖尿病患者抑郁状况动态变化研究
2022-07-11厚海伟赵亚玲陈方尧曾令霞裴磊磊
厚海伟,赵亚玲,陈方尧,曾令霞,裴磊磊
(西安交通大学医学部公共卫生学院流行病与卫生统计学系,陕西西安 710061)
糖尿病是严重威胁人类健康的世界性公共卫生问题。近30 多年来,我国糖尿病患病率快速增加:1980 年我国成人糖尿病患病率为0.67%,2007 年达9.7%,2013 年更高达 10.4%,2017 年增长至 11.2%[1]。长期高血糖易导致机体出现应激样反应,血浆皮质醇、胰高血糖素、生长激素等水平上升,皮质醇活性发生改变,上述变化使患者更易出现焦虑和抑郁情绪。同时糖尿病的长期治疗给患者及家庭带来沉重的经济负担,这些也可能导致许多糖尿病患者背负沉重的心理压力最终并发抑郁症[2]。国内外大量的研究显示,糖尿病患者的抑郁症发生风险高于非糖尿病患者[3-7]。然而,目前国内外的研究大多采用横断面研究来探讨糖尿病与抑郁症之间的关联,未能分析抑郁状况的连续性变化特征,且不能合理推断变量之间的因果关系。
区别于横断面调查设计研究的局限性,纵向追踪数据可以研究抑郁状况的连续性变化趋势,并由变量的时间先后合理推断因果关系[8]。传统的纵向数据分析方法如重复测量设计的方差分析在对总体趋势进行描述的同时,很少关注个体之间增长趋势的差异,也没有对个体之间的增长趋势的差异进行解释[9]。多层线性模型对个体之间发展趋势差异的问题提供了切实可行的解决途径,但对于变量之间的关系问题的探讨也仅限于直接影响关系的分析[10-11]。为弥补传统分析方法存在的弊端,本文拟采用潜变量增长曲线模型(latent growth curve modeling, LGCM)综合考虑总体水平的平均变化趋势和个体间的发展差异,以便对纵向随访数据做出更合理的解释。
1 对象与方法
1.1 研究对象
本研究采用中国健康与养老追踪调查(China Health and Retirement Longitudinal Study, 简称CHARLS)数据。CHARLS 是由北京大学社会科学研究院负责设计实施的一项专门针对中老年人的全国性大型追踪调查。该调查采用多阶段抽样,样本覆盖了除中国台湾、香港、澳门、海南以及中国大陆的西藏和宁夏以外的全国28 个省(自治区、直辖市)的 150 个县、450 个社区(村)总计 1.24 万户家庭中的1.9 万名受访者,样本具有良好的代表性[12]。本研究纳入CHARLS 研究2011 年基线调查样本中年龄≥45 岁和 2013、2015、2018 年 3 次随访调查均完成的研究对象,剔除缺失值和异常值。
1.2 变量定义
通过问卷中的问题“是否有医生曾经告诉过您有糖尿病或血糖升高(包括糖耐量异常和空腹血糖升高)”对糖尿病定义:糖尿病患者回答“是”。抑郁症状采用流调中心抑郁水平评定量表(the Center for Epidemiological Studies Depression Scale,CES-D)测量。该量表是由ANDRESEN 等[13]对原20 条目量表进行简化后得到的,由10 个条目组成,每项0~3 分,总分30 分,得分越高代表抑郁症状越严重,将≥10 分评定为有抑郁症状。黄庆波等[14]研究发现此量表的克朗巴赫系数在0.8 以上,满足分析要求。
基于既往文献研究[15-16],本研究纳入模型的其他混杂因素包括:年龄、性别、文化程度、婚姻状况、居住地区、医疗保险、家庭收入。其中年龄根据原始数据分为4 个等级。文化程度根据问题“你现在获得的最高教育水平”及给出的11 个选项分为:小学及以下(文盲、未读完小学、私塾毕业、小学毕业)、初中(初中毕业)、高中(高中毕业、中专毕业)和大学及以上(大专毕业、本科毕业、硕士毕业、博士毕业)。婚姻状况根据问题“你目前的婚姻状态”及给出的6 个选项分为:有配偶(已婚与配偶一起居住、已婚暂时没有跟配偶一起居住)和无配偶(分居、离异、丧偶、从未结婚)。医疗保险根据问题“你本人是否参加了以下医疗保险”及给出的12 个选项分为:有医疗保险(城镇职工医疗保险,城乡居民医疗保险、城镇居民医疗保险、新型农村合作医疗保险、公费医疗、医疗救助、单位购买的商业医疗保险、个人购买的医疗保险、城镇无业居民大病医疗保险、长期护理保险、其他医疗保险)和无医疗保险。其他变量根据原始问卷给出。
1.3 统计学分析
首先通过倾向性得分匹配法(propensity score matching, PSM)消除糖尿病与抑郁症关联之间的混杂因素。倾向评分(propensity score, PS)这一概念由 ROSENBAUM 和 RUBIN 在 1983 年首次提出,其基本原理是“降维”,即用一个PS 来概括多个协变量的影响并整合成为一个综合的分数[17]。本文基于Logistic 回归模型计算倾向得分,即以是否患糖尿病为因变量,上述混杂因素(年龄、性别、文化程度、婚姻状况、居住地区、医疗保险、家庭收入)为自变量进行拟合。选用最邻近匹配法进行得分匹配,匹配比例设为1∶4,卡钳值设为0.03。最后检验匹配后非糖尿病组与糖尿病组各变量的均衡性,以P<0.05 为差异具有统计学意义。
然后建立潜变量增长曲线模型分析糖尿病患者和非糖尿病患者抑郁症的变化特征。潜变量增长曲线模型是一种基于结构方程模型基础上的较新的处理追踪研究数据的统计方法,此方法可以同时对个体的发展趋势和个体间的差异进行解释,并且可以对变量之间复杂的因果关系进行分析[18]。采用比较拟合指数(comparative fit index, CFI)、塔克-路易斯指数(Tucker-Lewis Index, TLI)、均方根近似值(rootmean-square error of approximation, RMSEA)和标准化均方根残差(standardized root mean square residual, SRMR)来 评 价 模 型 拟 合 。 CFI 和 TLI>0.90、RMSEA<0.08、SRMR<0.10 被认为是模型拟合充分的证据[19]。所有研究分别采用R3.5.2 和Mplus7.11软件完成。
2 结 果
2.1 研究对象的基本特征
本研究最终纳入5 711 名信息完整的研究对象,平均年龄(57.08±8.114)岁[非糖尿病组(57.02±8.114)岁,糖尿病组(57.98±8.006)岁],非糖尿病组与糖尿病组中男性比例分别为48.5% 和44.1%。2011 年调查时糖尿病患病率为5.79%(331/5 711),其它基线特征见表1。通过倾向性得分匹配后,纳入样本为1 621 人(非糖尿病组1 291 人,糖尿病组330 人),平均年龄(57.65±8.090)岁[非糖尿病组(57.58±8.123)岁,糖尿病组(57.91±7.969)岁],非糖尿病组与糖尿病组中男性比例分别为43.0% 和43.9%。匹配后各变量在两组之间均衡可比。
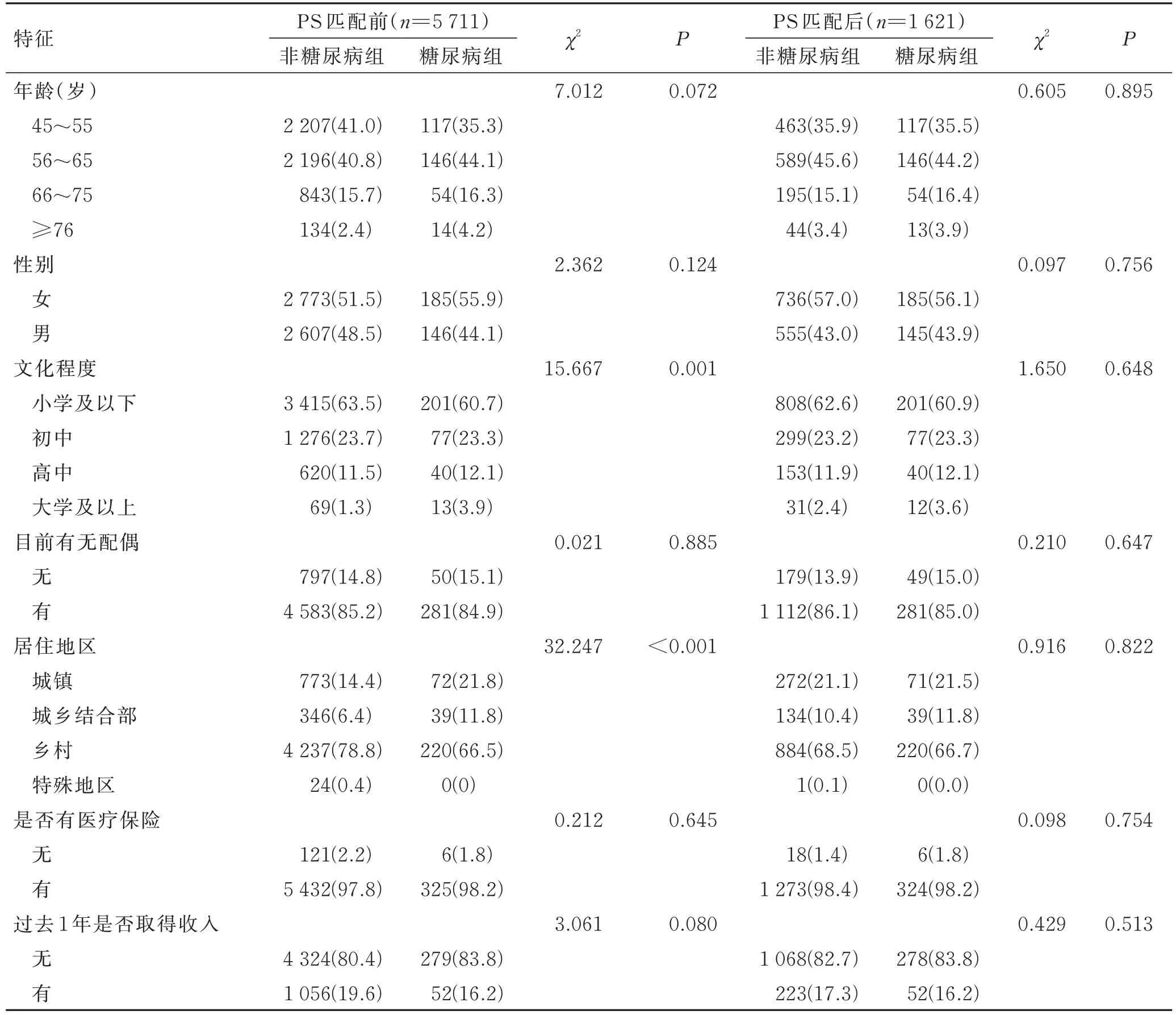
表1 倾向性得分匹配前后研究对象的基本特征Tab. 1 The subjects’basic characteristics before and after propensity score matching [n(%)]
2.2 糖尿病与抑郁症的关联
2011、2013、2015、2018 年非糖尿病组与糖尿病组 的 抑 郁 评 分 分 别 为 9.70±4.723,7.84±4.834,8.78±5.100,11.07±8.646 和 10.10±4.707,8.21±4.782,9.29±5.233,11.30±7.382。以 2011 年基线调查的CES-D10 抑郁量表评分作为抑郁症诊断的依据。PS 匹配前非糖尿病组与糖尿病组的抑郁症状无统计学差异(χ2=2.686,P=0.101)。在控制年龄、性别、文化程度、婚姻状况、居住地区、医疗保险和收入情况后,非糖尿病组与糖尿病组的抑郁症状具有统计学差异(χ2=3.861,P=0.049),糖尿病组患抑郁症的风险是非糖尿病组的1.13 倍(表2)。

表2 匹配前后非糖尿病组与糖尿病组的抑郁状态Tab. 2 Depression status of non-diabetic group and diabetic group before and after propensity score matching [n(%)]
2.3 潜变量增长曲线模型结果
本研究拟合了3 种潜变量增长曲线模型,表3 显示了3 种模型的拟合情况。对于定义的线性增长模型,CFI=0.590 和TLI=0.508,表示模型与数据之间的拟合尚可以接受,但是RMSEA=0.198,SRMR=0.112 表示模型与数据拟合不好。对于定义的二次增长模型,从拟合指数的绝对值上看,二次增长模型拟合结果优于线性模型,ΔAIC=284.191,ΔBIC=241.064。不定义曲线类型的增长模型拟合指标与二次增长模型相比,模型拟合有了进一步的提升,ΔAIC=15.849,ΔBIC =37.412。CFI 和 TLI>0.95,RMSEA<0.06,SRMR<0.04 这四个指标均提示模型拟合良好,因此采用不定义增长曲线类型的模型为增长函数的最优模型解。
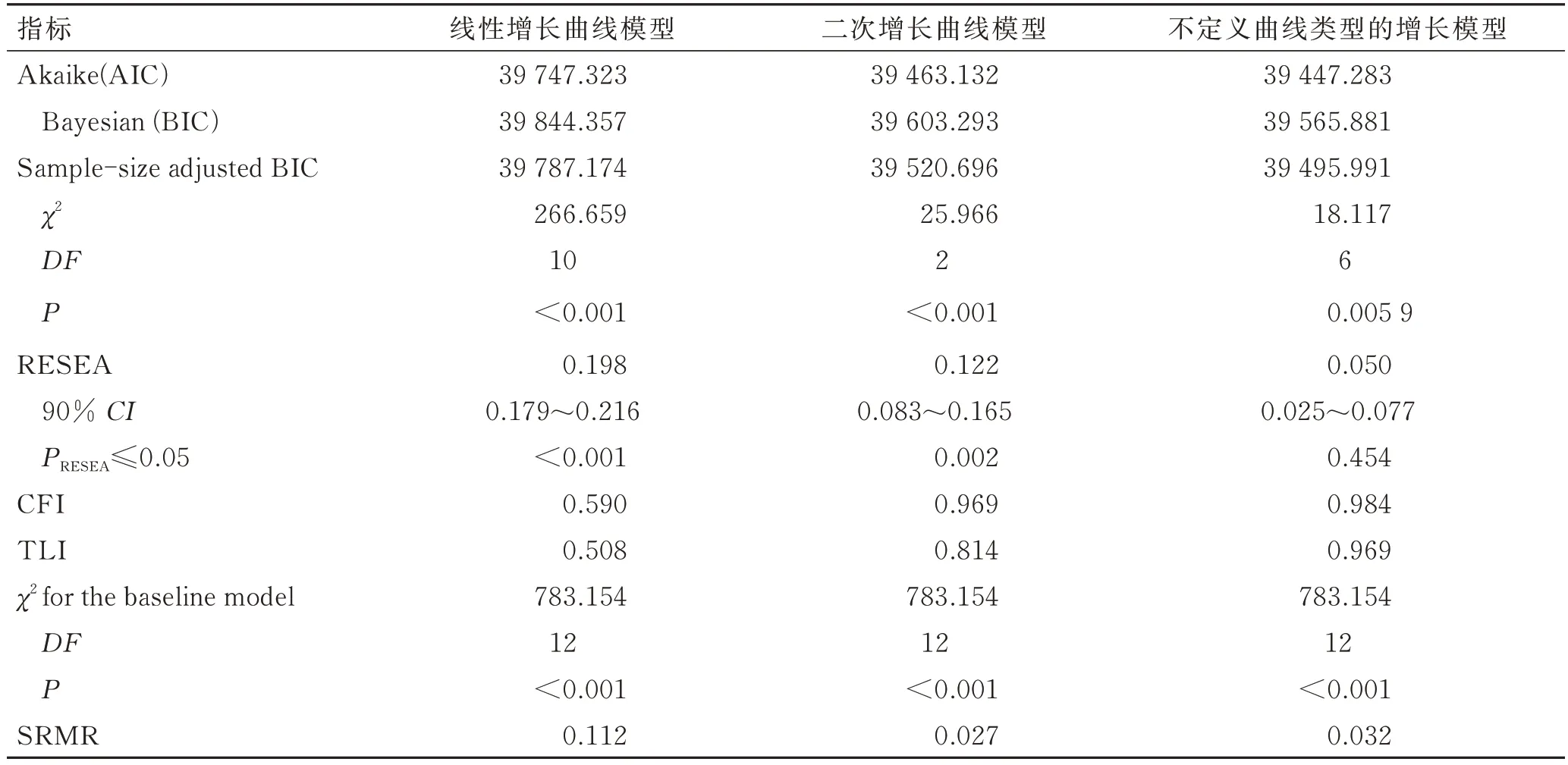
表3 3 种增长模型的拟合情况Tab. 3 The fitting of three latent growth curve models
不定义曲线类型的增长模型潜变量均值的估计结果表明,非糖尿病组和糖尿病组的初始状态平均抑郁评分分别为9.640 和10.097,在随访期内,两组的抑郁评分有先降后升的趋势,但是非糖尿病组的抑郁评分始终低于糖尿病组。潜变量方差估计的结果表明,初始时非糖尿病组和糖尿病组的抑郁状况都存在显著的个体间差异,在随访期内,两组抑郁评分的变化速度却都不存在个体间差异。潜变量截距和斜率之间的协方差,从定义模型的参数估计结果可以看出非糖尿病组的截距和斜率之间的相关为正,糖尿病组的截距和斜率之间的相关为负,两组都未达到显著水平,在追踪期内,初始抑郁评分的高低与后来的变化速度之间相关无统计学意义。详见表4。
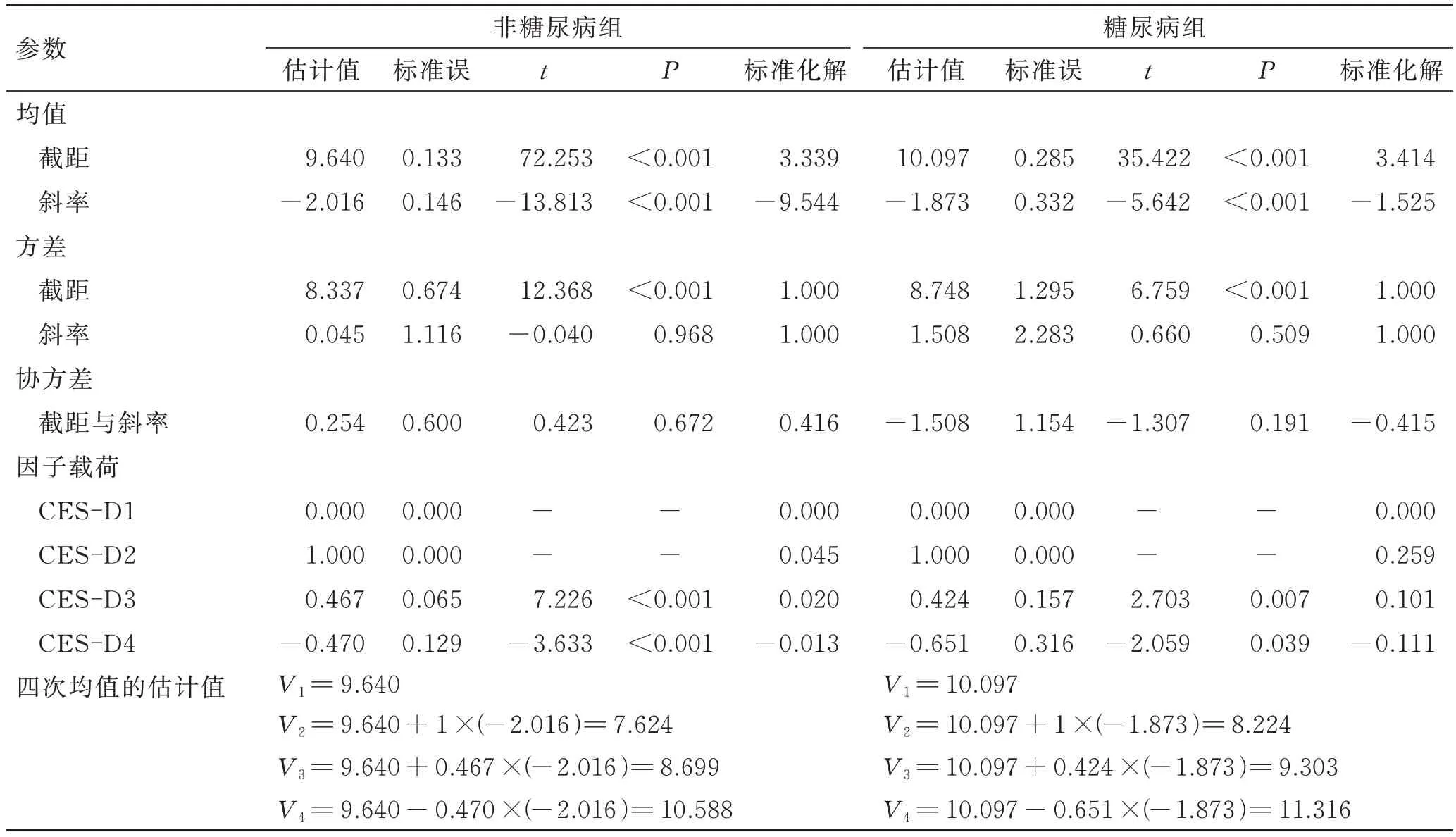
表4 不定义曲线类型的增长模型参数估计结果Tab. 4 The results of parameter estimation based on the model without defined curve type
3 讨 论
糖尿病是一种慢性终身性疾病,病情迁延不愈,治疗费用昂贵,给家庭及社会造成很大负担。研究发现,糖尿病与抑郁症存在共同的生理学基础,二者发病都在于下丘脑-垂体-肾上腺轴功能紊乱[20]。糖尿病患者的促肾上腺皮质激素释放激素高于正常人,而大量的促肾上腺皮质激素释放激素会导致机体出现焦虑、抑郁和厌食等机体功能障碍症状。随着社会医学模式的转变,人们更关心患者的心理状况变化。通过LGCM 模型构建患者的抑郁评分变化轨迹优于传统方法,可以描述个体的发展轨迹并分析个体间的差异及存在差异的原因,可以对给定的增长趋势进行检验,也可以对个体随时间变化的趋势类型进行探索。通过确定适当模型,揭示糖尿病患者抑郁状况动态变化规律,对抑郁状况较严重的患者尽早实施个性化干预。
本研究设定的3种模型均为非条件的增长模型,即不包含任何时间变量以外的预测变量模型。在不知道数据本身发展趋势的情况下,可以用非定义模型进行拟合,用数据来确定最优模型,真实世界的数据往往比较复杂,需要不断深入挖掘,先从线性模型到曲线模型,再从非条件模型到条件模型,并进一步添加协变量拟合模型。通过非定义模型发现糖尿病患者的抑郁状况呈现出先下降后上升的非线性动态变化趋势。因此,医师在控制患者血糖的同时必须注意其心理状况的变化,在不同的阶段给予患者恰当的心理治疗。李玉萍等[21]发现,个性化心理指导联合微信健康教育,可以提升老年糖尿病患者的遵医行为,帮助患者有效控制血糖,提高血糖控制达标率,缓解负性情绪,促进患者回归正常生活。董宗美等[22]发现,认知行为疗法可减轻2 型糖尿病患者的心理压力,进而改善血糖控制水平。
本研究基于CHARLS 的纵向随访数据开展,在探索糖尿病患者的抑郁状况时,将横断面研究与纵向研究相结合,使结论具有较强的说服力。同时,通过倾向性得分匹配,重新定义了非糖尿病组与糖尿病组,消除了一些混杂因素的影响,使两组均衡可比。尽管本研究纳入了7 个混杂因素(年龄、性别、文化程度、婚姻状况、居住地区、医疗保险、家庭收入),但影响糖尿病与抑郁症的因素较多,很明显其余未知混杂因素的影响尚不能排除,且其他慢性病对患者的心理状况也会产生影响。此外,潜变量增长曲线模型包括多种,例如潜在增长混合模型、潜在转换分析等,而本文仅仅使用了最基础的3 种方法,因此糖尿病患者抑郁状况的变化规律需要进一步深入探讨。
