高校图书馆OPAC 读者检索行为数据挖掘与分析
2022-07-11牛兰金曲淑敏
牛兰金 曲淑敏 姚 震
(山东农业大学图书馆,山东 泰安 271018)
0 引言
联机公共目录查询系统(Online Public Access Cata logue,简称OPAC)是图书馆为读者提供馆藏书刊目录信息检索和个人借阅信息查询的在线系统,它是读者利用图书馆纸质文献资源的网上第一入口,在图书馆的网络服务中一直占有重要的地位。读者借阅图书之前一般都要先在OPAC 系统中做检索查询,所以检索词能反映出读者对于纸质或电子图书的阅读需求,而读者行为数据反映出读者的使用习惯和规律,也反映出OPAC 系统功能的友好程度及使用效果,这些方面都值得图书馆的工作人员进行研究。
山东农业大学图书馆使用的是汇文OPAC 系统,百度统计云平台能够记录读者使用OPAC 的详细数据并按天进行了初步的汇总,其中读者进行书目检索的数据记录每年大约有20 余万条, 对这些读者检索行为数据进行分析与挖掘, 可以了解读者使用OPAC的基本情况,了解读者的借阅需求、阅读倾向,以及读者使用OPAC 系统的习惯和规律等,进而可以为图书馆的馆藏建设、读者服务等工作提供具有一定参考价值的数据和结论。
1 读者检索行为数据挖掘与分析研究设计
1.1 程序编写与数据文件格式
本文研究使用Python 语言作为编程和数据挖掘工具,使用Excel、Json 作为数据文件格式,按照功能需要共计编写Python 小程序近20 个。
1.2 数据获取与整理
利用统计系统提供的数据下载API 编写程序下载所需原始数据,本文研究按日下载数据,每天的数据保存为一个文件, 下载的数据是Json 格式, 编写Python程序将其转换为Excel 文件,方便直观浏览和处理。
1.3 OPAC 总体使用情况的统计分析
统计系统已经将网站的多项总体使用情况进行了统计,形成了数据列表和简单图表,利用这些通用型的数据列表, 结合OPAC 的实际需要进行数据提取、组合、合并和统计分析。
1.4 检索行为与检索词数据挖掘与分析
把读者检索相关的数据记录从下载的原始数据中提取出来,根据特征字符串区分出不同的检索方式并加以研究,其次将检索词从检索式URL 中提取出来作为单独的字段,再经过数据处理和分组聚合形成检索词列表并进行数据分析和数据挖掘研究。
1.5 数据可视化
对多个数据集合根据其特点和需要选择不同的图形类别进行可视化处理, 利用图形进行概况了解、数据分析和规律发现。
2 读者检索行为数据挖掘与分析研究结果
2.1 会话时长统计分析
读者的每次访问从开始到结束都可以视为一次会话,一次会话中可能会包含多项操作,本文以2021年1月至6月的数据为例进行分析,半年中总的访问次数为15 014 次,按会话时长分段统计出各段的总访问次数绘制成图1,其具体数据显示,有6 318 次访问会话时长少于1 分钟, 占比为42.08%,72.75%的访问在3 分钟内完成。另外,笔者在详细数据中发现时长少于等于9 秒钟的访问会话有2 997 次, 占比19.96%,为了验证这部分数据的有效性, 笔者进行了多次模拟,发现在2-3 秒钟内完成一次简单的检索任务是完全可行的,这部分数据完全可以作为有效数据来进行分析。从数据来看,大多数读者都在较短的时间内完成了检索,这反映出大部分读者都希望尽快结束搜索过程,也与读者大量使用图书馆门户首页的快捷综合检索框进行书目检索有关。
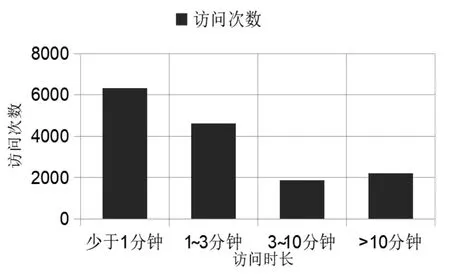
图1 会话时长分段与其总访问次数统计图
2.2 访问页数统计分析
访问页数统计的是读者每次访问会话一共浏览了本网站多少个页面,访问页数的多少反应了读者需求获得满足的效率,如读者只需要检索到一种图书的馆藏位置, 在理想状态下只需要在OPAC 中访问1~2个页面就完成检索离开了。表1 是2021年1月至6月的访问页数分段与对应的总访问会话次数统计表,数据显示,51.82%的读者只访问了1 到2 个页面就离开了,不超过4 个页面的总计占68.28%,访问5 个页面以上的占31.72%,总体上看大多数读者是在已经有了基本明确的意图的情况下使用OPAC, 比如查询某书有没有可借复本或是查询馆藏地点和位置信息,而在OPAC 中探索性发现有用图书的行为不多。
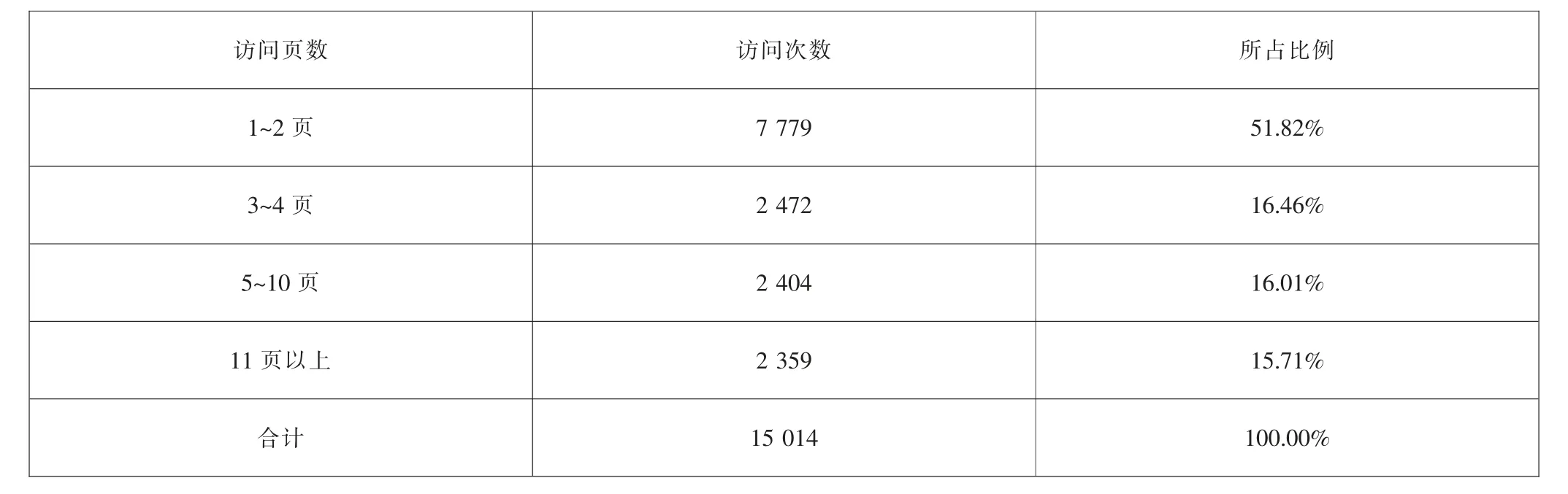
表1 访问页数分段与其总访问次数统计表
2.3 读者检索行为数据分析
基于对多个因素的综合考虑, 本文选用2018年的数据为研究对象,首先从每天的数据文件中把读者检索相关的所有数据记录提取出来并合并成一个Excel 文件,经过数据处理、分组聚合,形成可分析的数据集。
2.3.1 检索方式的分析
统计系统记录的是读者每次检索生成的检索结果列表页的URL 以及其访问次数、 平均停留时长等多项统计数据,每种检索方式生成的URL 不相同,所以可以简单使用Python 的df1=df.loc [df[‘name’].str.contains(“**”)]语句把某种检索方式的所有数据提取出来,其中name 为URL 字段的名称,“**”为某种检索方式区别于其他方式的特征字符串。
OPAC 的检索方式包括简单检索、多字段检索、综合检索框检索、二次检索,具体数据表明,读者基本忽略了所谓高级检索即多字段组合检索的存在,只有96条检索URL, 总检索次数不到300, 而简单检索的URL 条数则达到17 439 条数,总检索次数达到20 余万次。在图书馆门户网站首页的综合检索框进行OPAC 检索和在检索结果列表页上的二级检索界面进行检索本质上也是简单检索,综合检索框产生的URL有8244 条,总检索次数有54 770 次,二次检索产生的URL 共计8 826 条,总检索次数20 261。读者的行为数据表明,读者都倾向于简单方便的检索方式而不是去构造复杂的检索式。
2.3.2 生成完整的年度检索词统计列表
在统计系统记录的URL 中含有检索词, 提取出检索词作为一个字段,使用Python 分组聚合函数将相同检索词记录合并为一条,本文的原则是,无论是题名检索还是著者检索,只要检索词相同的记录就合并为一条,删除不合理数据后,形成检索词的统计列表,2018年度共计产生21 406 条数据。列表的字段包括检索词、检索次数、检索结果页的平均浏览时长、访客数、访问IP 数、检索结果页跳转其他页面的次数,等等。通过浏览、统计、分析此列表,可以比较精确的了解全部的读者检索情况,本列表的生成是一个重要研究步骤和成果,有了它可以从多个角度和层面展开数据分析和挖掘。
2.3.3 检索频次排行榜
将检索词列表按检索频次排序生成排行榜,其中“东野圭吾”的检索频次最高,达到2 116 次,是2018年度的最热门检索词。检索频次排名前20 位的检索词中与热门小说和经典文学相关的有13 个、 思政类检索词共计5 个、基础课程类检索词共计2 个,这基本反映了读者最关注的热点。在汇文OPAC 系统的检索界面上仅提供了30 天热门检索词列表, 统计显示30 天热门检索词列表也具有较高的使用率,所以可以推定:整理并选取一定数量的热门检索词在OPAC 检索界面发布年度热门检索词排行榜,对于读者的检索会更加有帮助,也更有参考价值,对于读者阅读推广也有协助作用。
2.3.4 检索频次分段统计分析
2018年全年搜索量大于1 000 次的检索词共有13 个,这些检索词平均每天被检索3 次以上,其相关的图书理应受到重点关注。年度检索频次未超过9 次的检索词个数占据了检索词个数总量的75.24%,虽然数量达到16 106 个,但仅完成了57 171 次检索,检索频次大于等于10 次的检索词共计5 300 个,累计检索次数为228 364 次,80%的检索是由这不到25%的检索词来完成的,这些检索词无疑应该是分析研究的重点, 而检索频次较低的检索词里面可能会存在新兴的、潜在的知识和图书热点。
2.3.5 对检索词进行分类研究
对检索词进行分类,既可以参照中图法也可以根据读者课程学习或是生活娱乐的需求来进行,还可以按检索频次分段来分类,针对不同类型的检索词可以采用不同的策略来分别进行研究。对于检索频次较高的与各学科课程密切相关的这一类检索词需要长期关注,如“高等数学”和“生物化学”等,研究相关分类图书的种数、出版日期、馆藏量、馆藏分配、借阅量、检索频次的动态变化以及各个数据之间的相互关系,从多个层面进行研究并落实,确保读者的学习需求得到满足并提高相关图书的借阅率。
3 结语
本文通过对2018年度的OPAC 读者检索行为数据进行研究,比较系统、全面、精确的了解了OPAC 系统的读者使用情况,同时也探索了研究方法,积累了经验, 并为后续年份的研究提供了可行的思路方法和整套的程序。另一方面,由于OPAC 的检索访问不需要用户登录,而且大部分访问是在公用查询端上进行的,无法取得读者个性化特征数据来进行关联性研究,因此本文的研究具有一定的局限性。后续年份的数据分析还将继续开展,再结合馆藏量、借阅量等相关数据来增加数据的维度, 通过不断对相关数据的分析和挖掘,全面了解读者的阅读需求和行为特点,一定能为资源建设、流通和阅读推广等工作提供一定的帮助。
