一种轻量化低复杂度的FDD大规模MIMO系统CSI反馈方法
2022-07-07李玉杰
廖 勇,李玉杰
(重庆大学微电子与通信工程学院,重庆 400044)
1 引言
大规模多输入多输(Multiple-Input Multiple-Output,MIMO)作为下一代无线通信系统的一项关键技术,通过在基站(Base Station,BS)配备数十根甚至数百根天线,可以大幅度提高频谱效率和能量效率[1].为了充分利用空间分集和复用增益,大规模MIMO系统需要获取足够精确的下行链路信道状态信息(Channel State Information,CSI)[2].在频分双工(Frequency Division Duplexing,FDD)大规模MIMO 系统中,用户设备(User Equipment,UE)必须首先估计下行链路CSI,再通过反馈链路反馈回BS[3].当收发端天线数量不大时,基于码本的反馈方法可以有效地解决反馈开销问题,如文献[4,5]提出的通过网格解码和低纬度矢量量化码本的方法.不过随着天线数的增加,码本变得非常巨大,码字搜索也变得异常困难.
在大规模MIMO 系统中,信道间具有很强的空间相关性[6].一方面,由于真实环境中有限的散射环境,时域无线多径信道大部分路径的能量为零,这使得多径信道呈现出稀疏性;另一方面,由于BS 周围的散射体有限,大规模MIMO 信道在角度域内呈现稀疏性[7].因此研究人员将压缩感知(Compressed Sensing,CS)[8]应用在CSI 反馈中.不过现有的CS 方法存在两个问题:一个是严重依赖信道的稀疏特性.然而真实信道并非严格稀疏;另一个是现存CS 算法大多都依靠迭代完成信号的重建,在低压缩率时其重建性能差,重建速度较慢.
近年来,深度学习(Deep Learning,DL)方法逐渐在CSI 反馈中得到应用,已有研究学者提出了一些基于DL 的CSI 反馈框架.如文献[9~11]提出的一系列基于DL的信道恢复框架,即在UE使用编码器将信道矩阵转换为码字,在BS 解码器使用ResNet 或双向长短期记忆网络来恢复信道矩阵.另外,为了降低网络的复杂度,也有研究学者提出了CS 联合DL 的框架[12],先在UE 利用高斯随机矩阵将CSI 矩阵压缩为测量向量,接着在BS 利用金字塔池化网络和ResNet 来恢复信道矩阵,但其性能并未有明显提升.
针对高复杂度和反馈开销大的问题,本文提出了一种轻量化低复杂度的CSI 反馈网络LCsiNet,该网络在UE 采用连续的平均池化层(Average Pooling,AP)、卷积网络(Convolution Neural Network,CNN)和深度可分离卷积网络(Depthwise Separable Convolution Neural Network,DSCNN)[13]所组成的结构逐步缩小原始的CSI矩阵得到压缩后的码字矩阵,其中AP 是利用了一种计算量较小的池化技术来缩小矩阵的尺度,而DSCNN 是一种通过减少网络参数量来降低计算密度的改进型CNN,在加深网络的同时提升其性能.BS首先采用连续的上采样层(Up Sampling,US)、CNN 和DSCNN 所组成的结构逐步扩大压缩的码字矩阵,重建初始CSI 矩阵;接着,利用残差网络[14](Residual Network,ResNet)这种可以逐步微调的结构构建了一种双路的残差卷积块,将初始CSI 逐渐逼近原始CSI.我们在复杂度和重建质量指标对比了目前主流的CSI 反馈框架CsiNet、CSReNet和CsiNetPlus.分析与仿真结果表明,相较于这些代表性方法,本文所提方法在复杂度、重构质量以及运行时间上均有更好的性能表现.
2 系统模型
2.1 大规模MIMO系统
我们考虑一种单小区大规模MIMO通信系统,该通信系统在基站端有Nt(Nt≫1)根发射天线,用户端有单根接收天线,采用正交频分复用(Orthogonal Frequency Division Multiplexing,OFDM),并有Ns个子载波.接收端信号y可以被描述为

为更好地设计预编码向量ui,在CSI反馈流程中,需要在基站端得到一个足够精确的,而这正是CSI反馈当中最需要解决的问题,通过更低的反馈量获得更好的重建效果.在FDD 大规模MIMO 系统中,CSI 反馈即是在UE 经信道估计得到的信道矩阵通过反馈链路发送到BS.此时我们需要反馈的数据量可以被表示为Ns×Nt个复数值,在反馈链路中,这个数据量是非常大的,需要占据大量珍贵的带宽资源.由于CSI 矩阵在虚拟角度域是稀疏的,该虚拟角度域矩阵可通过两个离散傅里叶变换(Discrete Fourier Transform,DFT)矩阵求得

其中,Ds是一个Ns×Ns的DFT 矩阵,Dt是一个Nt×Nt的DFT 矩阵.在真实的信道环境中,信号的多径时延只集中在几条路径上,因此导致角度域中大多数元素是为0的,仅前′行中包含非零元素,因此我们将原始的Ns×Nt矩阵截断为的截断矩阵.在本文当中,我们所涉及的CSI流程中需要反馈的矩阵即为上述的截断矩阵
2.2 CSI反馈流程

其中,Sen是编码器的输出结果,Sen在不同的压缩率下有不同的矩阵大小,fen(·)表示为编码器函数.接着,我们将得到的码字矩阵Sen反馈回BS 端.一旦BS 得到压缩后的CSI矩阵Sen,就可以通过BS基于DL框架实现的解码器重建矩阵H,这个重建过程可以被表述为


3 CSI反馈框架设计
卷积神经网络本身所具有的对“图像”进行特征提取的特性,因此在面对CSI 反馈领域中的大量CSI 矩阵时,二维卷积神经网络可以提取其中的特征信息,实现UE 处CSI 矩阵的压缩以及BS 处CSI 矩阵的重建.现行的基于DL 的CSI 反馈框架基本为CNN 和全连接层(Full Connected layer,FC)相结合的形式所构建,然而这种形式所构建的网络其网络参数量和计算密度都被FC所占据,复杂度较高.因此,本文提出一种轻量化LCsi-Net,目的是为了降低网络的复杂度,同时提高网络的重建性能.
3.1 编码器结构设计
在本文中,我们所提的基于DL 的网络LCsiNet 是一种完全基于卷积神经网络的结构,相比如今较新的基于DL的CSI反馈框架广泛使用FC和CNN结合而言,拥有更低的复杂度,网络参数量也更少.降低网络的参数量和复杂度其目的是为了更低的模型存储占用和计算复杂度.这样一来,UE 通信终端计算负载更低,存储占用更小.
为了压缩CSI 矩阵同时降低网络参数量和计算复杂度,我们引入了AP、DSCNN 和US.前文中,对于CSI复数截断矩阵H∈,为了方便数据的处理和训练,我们将其转化为(即将实部和虚部分为两个不同的通道).在针对不同的天线配置时,矩阵的大小可根据DFT 变换之后确定,此时我们改动网络的输入输出大小即可.理由是在天线配置加大的情况下,角度域矩阵会逐渐增大,但是信号的能量依然只是集中在部分路径上,整个角度域矩阵的稀疏程度也会增大.
具体细节可见图1 中的UE encoder 部分,将H作为UE 编码器的输入,首先经过一个ConvBN(它由一个3×3 卷积核的CNN、批量归一化层(Batch Normalization,BN)和激活函数LeakyReLU 组成),输出特征图数目为64.接着,通过连续的四个AP-SEConvBN(SEConvBN 与ConvBN 不同的是,其中的CNN 被更换为3×3卷积核的DSCNN)和一个AP-ConvBN,得到经过压缩后的码字矩阵Sen,特征图数目的变换为64 →128 →256 →M/4.每个AP-SEConvBN 都由一个池化窗口大小为2×2 的AP和一个SEConvBN 构成,每个AP-ConvBN 由一个池化窗口大小为2×2 的AP 和一个ConvBN 构成.DSCNN 相比CNN,参数量更少.DSCNN 和CNN 的参数量计算的具体细节描述如:假设输入两个卷积层的矩阵规格为(w,l,c),卷积核心大小(k,k)并且不计算偏置项,最后的输出通道数为m.对于CNN 来说,有多少个输入通道,就有多少个卷积核.CNN 的参数量为m×k×k×c.对于DSCNN,首先进行通道卷积(即可以得到与输入通道数相等的特征图数目)接着,在对每个输出特征图进行1×1 的逐点卷积,参数量计算得到(k×k+m) ×c.与CNN相比,DSCNN参数量得到减少.
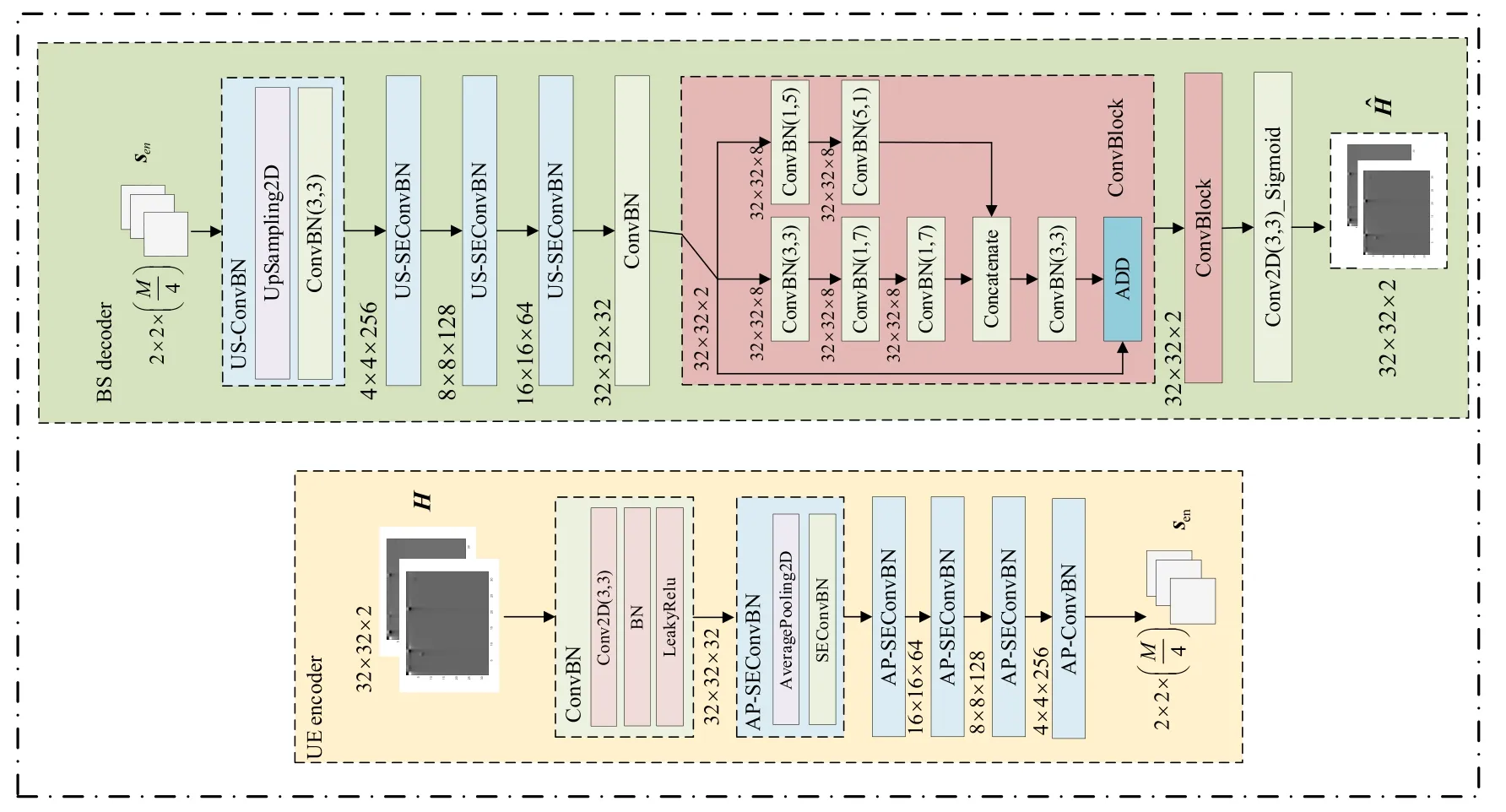
图1 编解码器结构设计
3.2 解码器结构设计
图1 中的BS decoder 部分,对于解码器结构设计,相比于编码器结构设计而言要更复杂,网络层数更深.我们将UE 编码器(encoder)输出得到码字矩阵Sen输入BS解码器(decoder),编码器首先是1个US-ConvBN 和3个连续的US-SEConvBN,每个US-ConvBN 由一个数据插值窗口大小为2×2 的US 和一个ConvBN 构成,每个US-SEConvBN 由一个US 和一个SEConvBN 构成.US 可以使得输入的数据维度提升,其原理是通过对特征图数据的行和列进行重复的插值过程完成升维.连续的4个US-ConvBN 和US-SEConvBN 的特征图数目变换过程为M/4 →256 →128 →64.接着,通过一个ConvBN得到Ns′×Nt×2 的输出后,再输入到连续的两个ConvBlock,每个ConvBlock 都是根据残差网络的形式所构建的一种参数量较少的双路残差卷积块.首先将的输入分为两支路,每条支路均由CNN 构成.上边的支路采用卷积核1×5 和5×1 的两个CNN,输出特征图数目都为8.下边的支路采用3×3、1×7 和7×1 的卷积核的CNN 构成,输出特征图数目也都为8.接着,将两条支路的输出特征图进行合并,即输出特征图数目为两支路之和为16.通过一个ConvBN 后的输出与整个ConvBlock 的输入的和作为ConvBlock 的输出.最后将′×Nt×2 的输出通过一个3×3 卷积核的CNN(激活函数Sigmoid,可以将数据调整至0~1)得到最终的重建结果
对于LCsiNet 的训练,我们采用端到端的训练方式(编码器与解码器作为一个网络进行训练),这样不仅能够方便地对我们所设计的网络进行训练和调试,同时也能更好地学习调整网络结构中的权重和偏置参数.假设我们输入LCsiNet 的数据为Hi,那么整个编解码器的输入输出可表示为其中的i是第i个样本.在训练过程中,我们采用自适应矩估计(Adaptive moment estimation,Adam)算法优化器,计算表达式见式(6).

其中,‖ · ‖2表示为欧几里得范数,T为训练样本的总量.
损失函数采用均方误差(Mean Square Error,MSE),其计算方式如式(7).
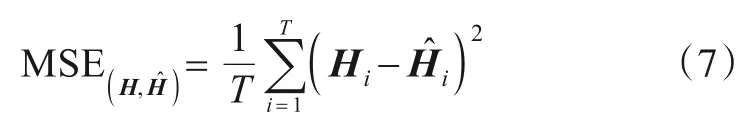
4 复杂度分析
时间和空间复杂度是衡量一个算法复杂度的两个重要指标.同样的在DL 中,也有两个具体的复杂度指标,即对应时间复杂度的浮点运算数(FLOating Point operations,FLOPs),对应空间复杂度的模型参数量(Model Parameters,MP).本文所提的LCsiNet 其目的是为了降低模型的复杂度,提升CSI 重建精度.由于本文所提的模型以及与之对比已提出的模型使用的网络结构主要是全连接层和卷积层.因此对全连接层和卷积层的浮点运算数和网络参数量进行计算分析.
全连接层的复杂度计算:假设输入的数据维度(N,D),隐藏层权重维度(D,out),输出(N,out),那么它的FLOPs和MP见式(8)和(9).

卷积层的复杂度计算:假设输出特征图的宽高分别为W和H,卷积核大小为K1×K2,Cin为输入通道数(卷积核的层数),Cout为输出通道数(卷积核的个数),那么它的FLOPs和MP见式(10)和(11).

根据上述计算方式,我们分别得到了CsiNet、Csi-NetPlus 和LCsiNet 的MP 和FLOPs.由于CS-ReNet 中其编码器是由随机投影矩阵构成,并不是基于DL 所搭建的深度自编码器,因此不纳入该对比中.从表1 我们可以看出,单纯在编码器中,FC所占有的参数量是极多数的,即便是更大的卷积核更多的卷积层的CsiNetPlus,FC 依然占据其模型参数量的大多数.我们所提的网络结构也正是针对该问题所提,通过去除FC,大大降低UE 端编码器的复杂度之外,转而利用参数量,计算密度都较小的DSCNN和AP结合来达到降低特征图大小,完成矩阵压缩过程.
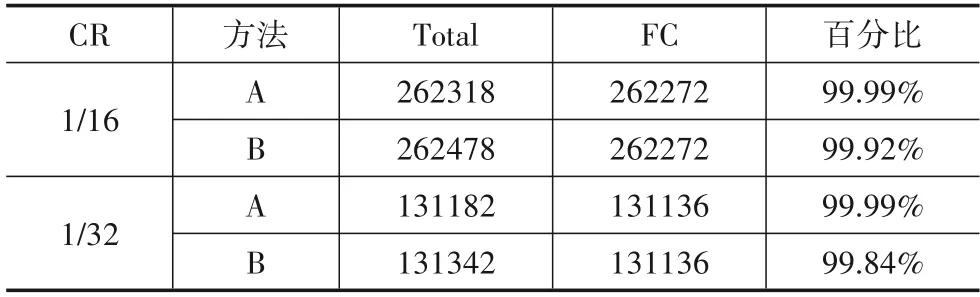
表1 编码器结构中FC层对参数量的占用
另外,从表2 对三种方法的整体结构MP 和FLOPs对比来看,LCsiNet 在AP、US、DSCNN 和CNN 相结合的形式下,MP 和FLOPs 相比其余的网络都要小,NMSE 和ρ也都有明显的提升,说明所提网络LCsiNet 在能够提升性能之外,也降低了网络的复杂度.
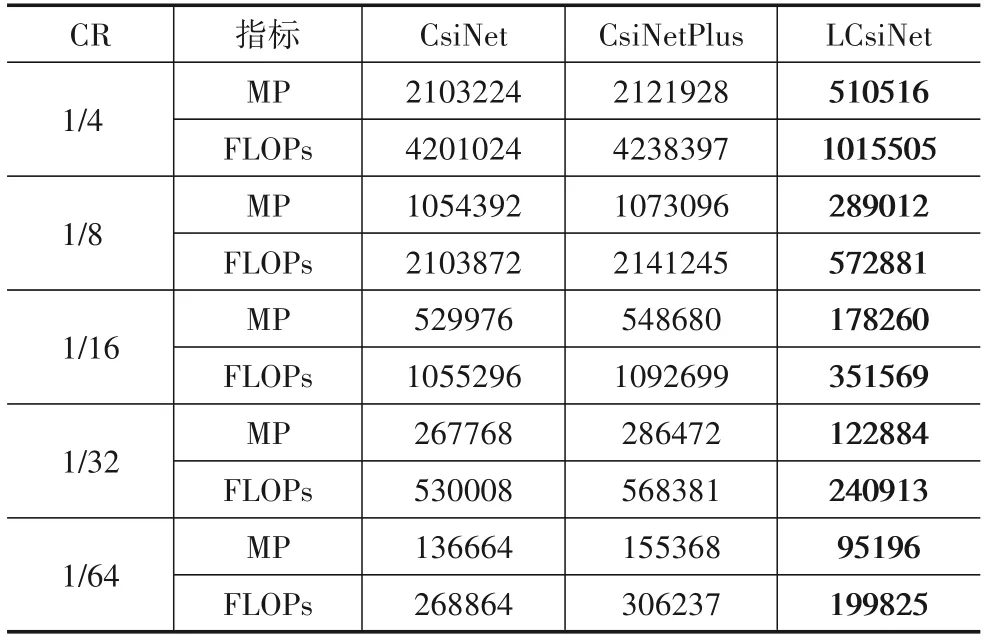
表2 三种方法的MP和FLOPs的对比
5 仿真结果和分析
在Matlab 仿真平台中采用COST2100[15]信道模型产生训练集、验证集和测试集数据,该信道模型是一种基于几何的随机信道模型,产生两类数据集:(1)工作频率为5.3 GHz 频段的室内微蜂窝场景.(2)工作频率300 MHz 频段的室外场景.发射接收天线数32、1,线性天线阵列,波长为1/2天线间距,子载波数1024.原始信道矩阵在角度域是稀疏的,DFT 变换之后,只取前′=32 行.采用的深度学习开源框架为Keras.数据集分布:训练验证测试:1000003000020000.批次数据大小(batch size)为200,训练轮次(epoch)1500,学习率(learning rate)0.001.仿真设备配置CPU:Inte(lR)Xeon(R)E5-2678,内存:64 GB,GPU:RTX 2080Ti.
将LCsiNet 网络与现行CS 算法和DL 算法进行比较.CS 算法有TVAL3[16]、OMP[17]方法.DL 算法有Csi-Net、CsiNetPlus 和CS-ReNet.TVAL3 是一种非常快速的基于全变量的恢复算法,它考虑了越来越复杂的先验知识.OMP 是一种需要知道稀疏度先验的贪婪迭代算法.CsiNet 是最早使用DL 的自编码器方法,它引入了残差结构增强恢复效果.CsiNetPlus 则是在CsiNet 的基础上采用更大卷积核并且使用更多的残差结构来提升CSI 重建质量.CS-ReNet 引入金字塔池化层SPP-Net 的概念来消除CsiNet 出现的过拟合现象,同时利用随机投影矩阵压缩信号减轻UE端的计算存储压力.
以下分析性能优劣采用两个指标:计算H和之间的归一化均方误差(Normalized Mean Square Error,NMSE),见式(12).

计算重建子载波向量与原始子载波向量之间的余弦相似度,见式(13).

根据图2 和图3 所示,压缩率(Compression Ratio,CR)的取值根据式子进行确定.M的取值为32、64、128、256、512,对应的CR值为1/4、1/8、1/16、1/32、1/64.在1/4到1/16压缩率之间,基于CS的方法还是有效的,但是在更低压缩率时,高斯随机矩阵采样无法提取有效信息,因此基于CS 的方法是无法重建信号的.如TVAL3 在1/16 压缩率时,NMSE 和余弦相似度骤降.因此我们可以得出一个结论,低压缩率下,CS算法的重构是无效的.反观基于DL 的方法,虽然也受压缩率大小的影响,但是其在更低压缩率的表现显然是优于CS算法,在应对更低压缩率时,网络所能学习到的原始信号的信息更多,重建效果也就更好.本文所提的LCsiNet在1500轮的训练条件下,也表现出了更好的NMSE 和余弦相似度.从图中可以看到CsiNetPlus 较之CsiNet 有不小性能提升,其本质上是增加了网络的深度,改用了更大的卷积核.而本文所提的LCsiNet 则是在保证良好的NMSE和余弦相似度下,达到更低的复杂度,更少的网络参数量.

图2 不同压缩率下的NMSE

图3 不同压缩率下的ρ
除此之外,由于CSI矩阵获取的精确性往往会影响BS 对预编码向量的设计.预编码向量设计的好坏又会决定整个系统的性能表现,因此我们这里选取两个具有代表性的室内场景下的压缩率1/4 和1/32 进行误码率的仿真.仿真结果如图4,从图中可以看出,本文所提出的LCsiNet 在恢复精度更高的情况下,给误码率也带来一定程度的增益.其次,在执行测试集的单个样本的平均运行时间上,CsiNet:0.18 ms,CsiNetPlus:0.23 ms,LCsiNet:0.15 ms,基于DL 的方法相比基于CS 的算法,会快几十倍到上百倍.
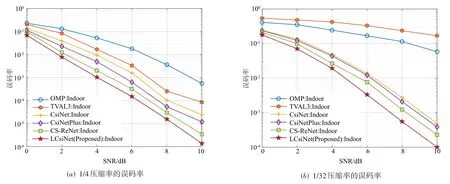
图4 室内场景下的误码率
6 结论
在本文中,我们提出了一种轻量化低复杂度的CSI反馈框架LCsiNet,相比于现有的基于DL的方法和基于CS 的方法,其信道矩阵的重建质量更好.更好地利用了AP、US、DSCNN 和CNN 的特性,合理地将原始CSI 进行压缩和重建,采用参数量更小且性能更优的DSCNN加深网络,提升了CSI 重建的精度.通过仿真分析对比发现,LCsiNet 在降低网络复杂度的同时也获得了不错的性能表现.
