基于融合进化算法的用户日负荷曲线聚类分析
2022-07-07覃日升段锐敏王广雪束洪春
何 觅,覃日升,何 鑫,段锐敏,王广雪,束洪春
(1.云南电网有限责任公司 昆明供电局,云南 昆明 650011;2.云南电力科学研究院,云南 昆明 650217;3.昆明理工大学 电力工程学院,云南 昆明 650500)
0 引 言
随着智能电网建设的不断推进,越来越多的智能电力设备比如智能电表被广泛应用,电力系统行业迎来“大数据时代”.面对庞大的电力用户,很难对每个用户单独建模分析用户特性,而是先要对典型用电用户进行准确的划分,以此递推其他用户[1-3].用户负荷的增加需合理安排调整电网运行方式,将负荷转化为电网的可调节资源,在电网出现或即将出现问题时,对负荷主动调节改变潮流分布,确保电网安全、经济、可靠运行.因此利用数据挖掘技术对大量用户负荷数据进行有效划分,有助于电网人员深度分析电网运行方式,为电网稳定运行提供保障.负荷聚类分析是指对电力负荷按时间序列进行科学有效地划分,通过聚类分析挖掘出不同种类负荷间的关系及构成,在大量无序的负荷中挖掘出潜藏的负荷模式,并对其进行归类.此方法有助于调度人员了解用户用电行为,为电力负荷预测、需求侧响应分析提供保障[4-5].
文献[6]首先利用综合评价体系对用户进行初次分类,其次在考虑季节变化和工作日上对每类用户的用电负荷运用K-means二次聚类,最后运用标杆分析的方法进行评价,但该算法K值的选取不好把握,难以寻找全局最优解.文献[7]提出一种降维思想的日负荷曲线分类方法,通过对日负荷曲线所选取的特征进行降维、配比权重及利用欧式距离作为判据,很大程度上缩短程序运行时间,但该算法涉及专家打分制,结果受个人主观影响.文献[8]提出一种高斯混合模型(Gaussian Mixture Model,GMM)分类算法,从大量负荷数据中提取典型日负荷曲线,再将已知用户打标签作为训练集,最后利用支持向量机建立典型负荷与行业用户相关模型,属于半监督聚类,引入测试集进行行业判别.支持向量机(Support Vector Machine,SVM)拥有优秀的泛化能力,但训练时间较长.文献[9]提出一种采用中心优化和双尺度相似性度量的改进K-means负荷聚类方法,引入局部密度思想获得负荷曲线的初始中心,解决了K-means随机化带来的不稳定问题,但未考虑噪声对欧式距离的影响.文献[10]提出一种基于粒子群优化分段聚合近似的负荷分类方法,该方法通过压缩手段对日负荷曲线降维,并利用粒子群算法优化最优分类数,但降维丧失了原始日负荷曲线的部分特征,且只优化了最优分类数,未对初始聚类中心优化,造成日负荷曲线聚类准确性降低.
综上,大多数日负荷曲线聚类算法易陷入局部最优解,未得到最优初始聚类中心,使得分类结果产生偏差;少数算法为了提高算法准确性,未顾及算法的快速性.因此本文提出一种基于融合进化算法优化模糊C均值(Fuzzy C-Means,FCM)的用户日负荷曲线聚类方法.该方法首先基于重心Lagrange与线性函数归一化的数据预处理方法对数据进行预处理,并整合遗传算法与模拟退火算法的优点寻找FCM最优初始聚类中心;然后给出模拟退火温度迭代曲线,在迭代至22次时达到了算法要求,迭代次数较少.与未优化FCM进行分类结果准确性的对比,结果显示融合进化算法优化FCM解决了传统FCM局部最优解的问题,使得分类结果更准确,最后采用云南某地区实际日负荷曲线验证该算法在一定噪声下仍能准确进行负荷分类.
1 用户负荷特性分析
传统负荷分类按用电部门可分为工业、商业、农业、教育四类.工业包括重工业与轻工业,轻工业包含烟草、纺织、食品等,重工业包括冶金(电解铝)、煤炭、机械制造等,大部分工业企业实行三班制连续工作,负荷率较高;商业负荷主要包括动力、照明、制冷等,且商业性负荷在营业开始后较平稳,营业结束呈低负荷状态;农业负荷一般为农机、畜牧、灌溉等,畜牧、灌溉通常隔一段时间运作一次,因此农业负荷呈现出不连续性;教育负荷主要表现在上午、下午用电量多,中午休息造成负荷率降低,负荷曲线呈双峰状.不同行业负荷由其所在部门的电器消耗功率组成,不同行业设备运行所产生的功率也不尽相同,负荷特征有所区别.
为准确描述用户用电负荷特征,需建立具体特征指标实现负荷分析及计算.负荷特征指标按不同计算方法可分为比较类型、曲线类型和描述类型三类,负荷特征指标体系如图1所示[11].其中,用户负荷随时间变化的曲线称作负荷曲线,不同用户类型的负荷曲线有所不同,同一用户类型的负荷曲线在不同季节、特定时间段(如节假日)所表现的负荷曲线也不尽相同,电网人员可根据负荷曲线进行规划调度.
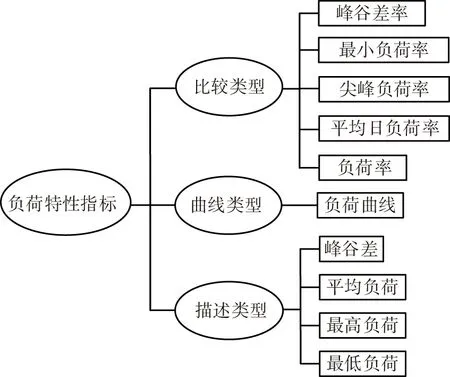
图1 用户用电负荷特征指标Fig.1 Consumer electricity load characteristic index
某商业用户有功功率日负荷曲线(以下简称负荷曲线)如图2所示.商业日负荷曲线在营业开始后起负荷,且较平稳,营业结束后呈低负荷状态.负荷曲线可为发电厂制订发电计划提供有效依据.

图2 某商业用户有功功率日负荷曲线Fig.2 A commercial active power daily load curve
2 数据预处理
2.1 数据清洗
设有n条用户日负荷曲线,每条曲线维数为m,构成n×m阶日负荷曲线矩阵,记初始矩阵为X.负荷异常数据包括数据缺失以及突变.测量装置的损坏以及异常工作状态可能导致数据缺失;测量装置到分析终端的传输可能导致数据突变,包括传输中的噪声、测量偏差等.大多聚类算法对异常数据不具备自适应能力,异常数据可能导致错误聚类,所以需要对异常数据进行清洗.
当某条数据的缺失及突变测量点达到10%及以上,认为该数据无效,剔除该条数据.设需要剔除的数据为x条,则有效数据包含n-x条,形成(n-x)×m的新矩阵,记为Z.当某条数据的缺失及突变测量点小于10%,仅需对缺失点及突变点利用拉格朗日插值进行填补即可[12-13].
Lagrange插值法定义如下:现有k+1个节点的多项式函数(x0,y0),…,(xk,yk),其中xj为自变量,yj为因变量(j=0,…,k).设函数中任意两个xj互异,则Lagrange插值多项式为:
(1)
式中,lj(x)为Lagrange插值基函数:
(2)
Lagrange插值法公式结构整齐紧凑,在理论分析中十分方便,但插值点增加或减少时,所对应的基函数要重新计算,过程繁琐,因此利用重心Lagrange插值法解决此问题.
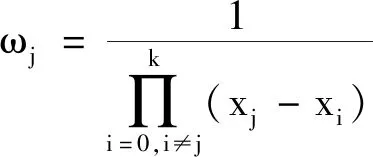
(3)
Lagrange基函数可重新定义为:
(4)
式中,l(x)=(x-x0)…(x-xk),则经改进后的Lagrange插值多项式为:
(5)
改进后的插值多项式优点为当插值点增加一个时,每个ωj都除以xj-xk+1便得到重心权ωk+1,计算复杂度为O(n),相比传统的基本多项式复杂度O(n2)减少一个量级.
将改进后的Lagrange插值多项式对函数g(x)≡1插值,得到:
(6)
(7)
式(7)为重心Lagrange插值公式,其优点为在计算L′(x)时不必计算l(x),可大幅度减少计算量.
2.2 数据归一化
数据归一化处理是数据挖掘的前期准备工作,日负荷曲线因用户属性不同往往量纲不尽相同,数据归一化处理可消除指标之间的量纲影响,使得结果分析更加准确.原始日负荷曲线经过数据归一化后,各维度处于同一量级,适合对比评价分析.线性函数归一化(Min-Max scaling)与0均值标准化(Z-score standardization)是常用的两种归一化方法.其中Z-score归一化后的数据最终结果不一定落在0到1之间,对日负荷曲线的聚类可能造成偏差,所以本文采用线性函数归一化日负荷曲线.线性函数归一化公式如下:
(8)
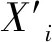
3 融合进化算法优化模糊C均值
同一行业的日负荷曲线具有相似性,例如大工业用电一般进行连续生产,全天负荷率高;而一般商业是在早上9点到夜晚10点负荷较大,其他时间负荷小;农业负荷因电机间接性启动,负荷也呈间接性波动;教育类负荷在上午、下午两段时间呈现较大负荷,其他时间负荷较小.不同行业的日负荷曲线负荷特性差异较大,FCM的本质是计算聚类曲线与聚类中心各点之间的欧氏距离,曲线相似度小,曲线之间的欧氏距离大,以此提出基于FCM的负荷曲线聚类方法,FCM根据距离函数确定样本的相似程度.
3.1 模糊C均值聚类算法
模糊C均值属于模式识别领域分支,广泛应用于电力系统、计算机科学、自动化技术等领域.电力系统中日负荷曲线的分类也属于模式识别问题,为快速实现日负荷曲线的快速、实时、准确的划分,本文采用了FCM聚类算法作为主体算法[14].FCM聚类融合了模糊理论的精髓,将模糊集理论和聚类理论相结合,根据样本内在规律,将样本分为多个模糊组,通过距离函数确定样本间的相似度,利用数学规划理论获得最优聚类结果.
FCM聚类算法:数据预处理后得矩阵Z={z1,m,z2,m,…,zn-x,m},其中n-x为清洗后的样本数量,每个样本为m维向量.将所有样本分为c个类型,2≤c≤n-x,相似分类矩阵U={u1,u2,…,uc},V={v1,v2,…,vc}为各类型的聚类中心,则目标函数Jr为:
(9)
式中:uik为样本zij对于类型Uk的隶属度,uik∈[0,1],r为模糊指数.算法寻优期间,要求隶属度和为1,即:
(10)
dik表示第i个负荷数据与第k个聚类中心的欧式距离:
(11)
FCM算法需要寻得目标函数Jr的最小值,可利用Lagrange函数对目标函数求解,得到最优解uik与vik:
(12)
(13)
FCM聚类算法属于局部搜索算法,搜索速度快,但聚类结果过于依赖初始聚类中心,容易收敛于局部极值点,陷入局部最优解,最终导致日负荷曲线分类结果出现偏差.大数据监测识别应用系统中,日负荷曲线的分类需要保证算法能够求得最优解,否则聚类质量无法保证,因此提出融合进化算法优化FCM以便得到初始聚类中心的全局最优解,达到最优聚类效果.
3.2 融合进化算法
进化算法也被称为演化算法(Evolutionary Algorithms,EAs).进化算法借鉴大自然中生物的进化操作,一般包括基因编码、种群初始化和交叉变异算子等基本操作.遗传算法(Genetic Algorithm,GA)是一种最基本的进化算法.1975年,Holland教授等提出基于遗传学机理与自然选择的遗传算法,该算法将个体的随机信息交换机制与适者生存规则结合在一起,模拟自然进化过程搜索最优解.遗传算法对目标函数的约束较少,全局搜索能力强,鲁棒性强,但是遗传算法在后期容易出现“早期早熟、后期进化停滞”的收敛现象,即容易陷入局部最优解.模拟退火算法(Simulated Annealing,SA)是一种贪心算法,在一定的概率情况下接受较差解,有概率跳出局部最优解,寻找到全局最优解[15-16].该算法的局部搜索能力较强,计算时间较短,但是由于其不能完全掌握整个搜索空间的情况,导致该算法的全局搜索效率不高.本文融合模拟退火与遗传算法(SAGA)的优点对初始聚类中心寻优.融合进化算法的基本原理是将GA算法初始种群的个体适应度值作为SA算法的初始解[17];将GA算法经过选择、交叉、变异等进化过程得到的下一代种群的个体适应度值作为SA算法的新解;将SA算法中满足Metropolis准则的解对应的个体汇集在一起作为GA算法下一代的初始种群.因此有机结合SAGA改进传统FCM算法可更加高效求得全局最优解.
3.3 融合进化算法优化FCM步骤
融合进化算法优化FCM具体算法步骤如下:
Step 1:初始化SAGA-FCM算法参数.除3.1节所提到的FCM聚类算法的参数,还需初始化模拟退火参数:初始退火温度T0,终止温度Te,冷却系数p.初始化遗传算法参数:种群个体数目sizepop,最大遗传代数MAXGEN,交叉概率Pc,变异概率Pm.
Step 2:随机选定日负荷曲线初始聚类中心,初始化遗传算法种群Chrom.
Step 3:计算日负荷曲线各聚类样本个体隶属度、个体适应度fi=ranking(Jr),其中i=1,2,…,sizepop.
Step 4:设定遗传代数初值gen=0.
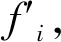
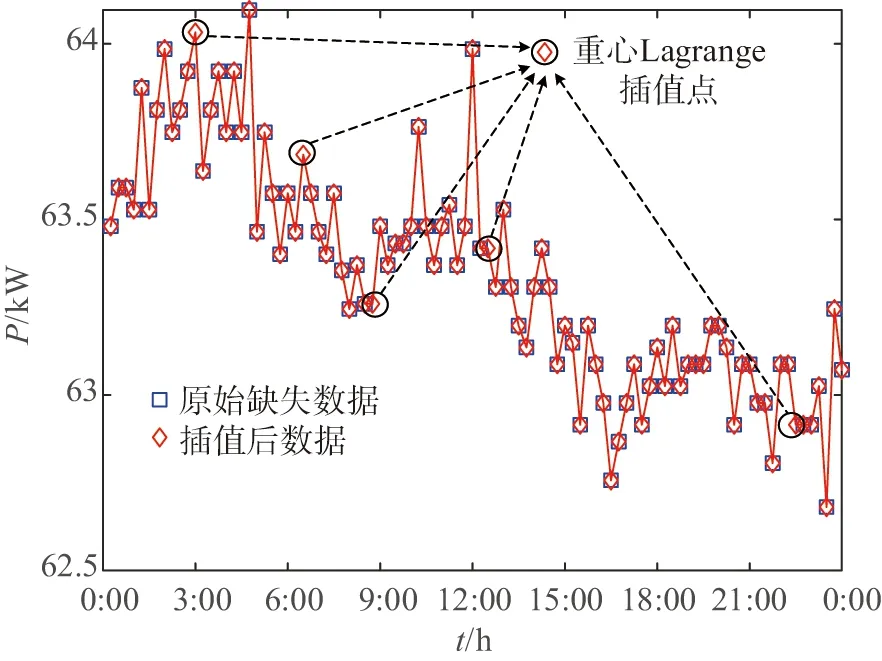
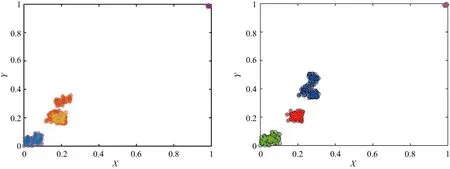
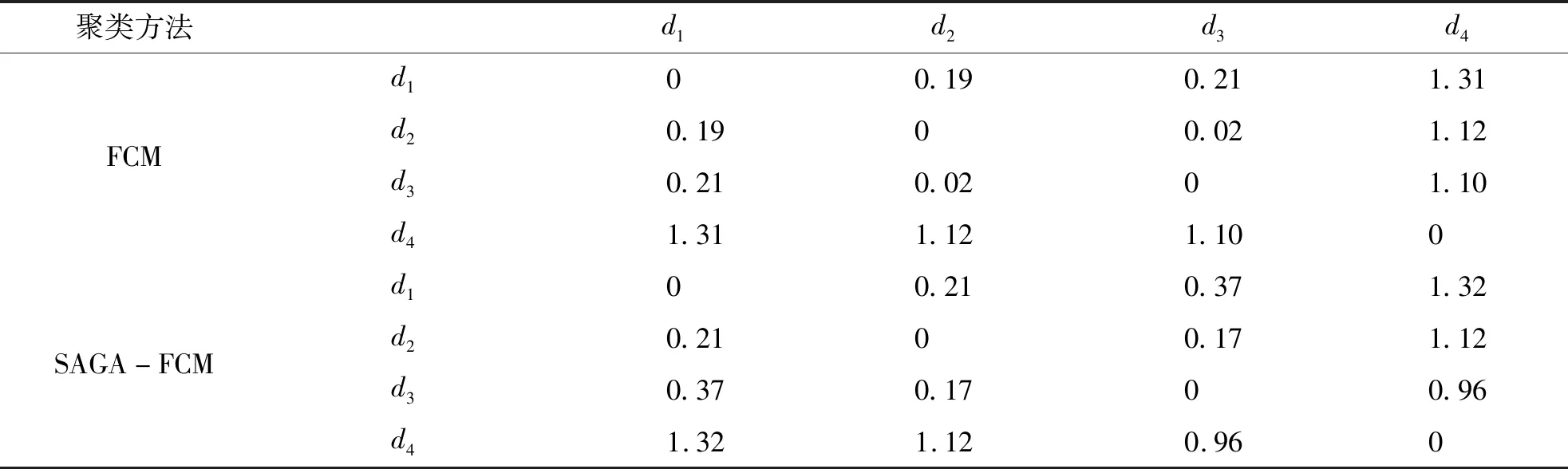
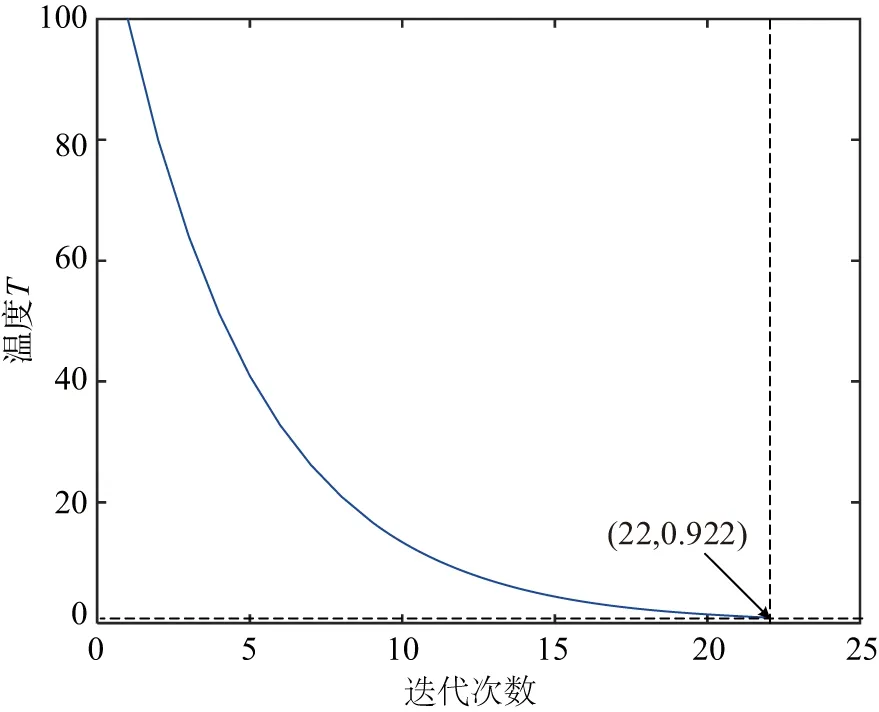
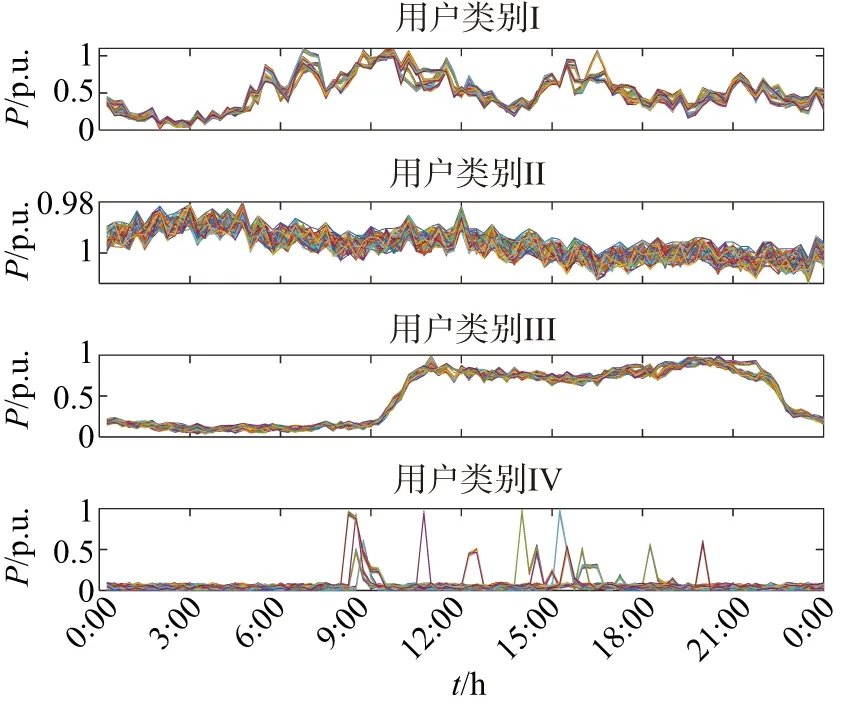
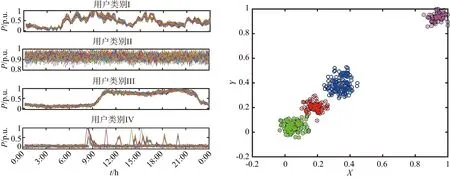
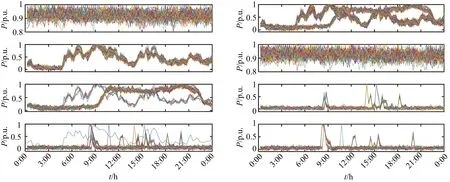
Step 6:若遗传算法进化次数gen Step 7:若退火温度T 融合进化算法优化FCM流程如图3所示. 图3 融合进化算法优化FCM流程图Fig.3 Fusion evolutionary algorithm to optimize FCM flow chart 选取云南某地区若干用户96点(采样点间隔 15 min)日负荷曲线作为研究对象,用户选取范围包括工业、商业、农业、教育四类用电行业共412条数据,以此检验本文所提方法的准确性. 剔除无效数据(缺失10个采样点及以上)12条,剩余400条数据,对剔除后的原始数据利用重心Lagrange插值法进行缺失数据的填补.以某工业用户为例,原始日负荷曲线数据缺失5个采样点,根据删补原则,为达到删除要求,对数据进行填补即可.数据填补前后如图4所示. 图4 重心Lagrange插值法填补数据前后对比图Fig.4 Contrast chart before and after data filling by Lagrange interpolation 给出不同行业日负荷曲线各一条,归一化后的日负荷曲线如图5所示. 图5 不同行业归一化后的日负荷曲线Fig.5 Normalized daily load curves of different industries SAGA-FCM算法所涉及的参数如表1所示. 表1 算法参数Tab.1 Algorithm parameters 将400条预处理后的数据分别进行FCM与SAGA-FCM分类,聚类中心结果如图6所示. 从图6可以看出,由于传统的FCM易陷入局部最优解,其中两个聚类中心距离较近,产生了混叠现象;经SAGA优化后的FCM寻找全局最优解,四个聚类中心距离较远,分类结果清晰.虽然SAGA-FCM较传统FCM聚类中心距离较远,不易产生混叠现象,但SAGA-FCM仿真时间较长,对于本文所使用的400条实际数据,FCM运行时间为0.11s,SAGA-FCM运行时间为0.57s.优化前后聚类中心坐标值如表2所示,聚类中心之间的的距离如表3所示. (a)FCM聚类结果 (b)SAGA-FCM聚类结果图6 不同行业聚类中心Fig.6 Different industry cluster centers 表2 FCM优化前后聚类中心坐标Tab.2 Cluster center coordinates before and after FCM optimization 表3 FCM聚类中心之间距离Tab.3 Distance between FCM cluster centers 由表3可以看出FCM聚类中心d2、d3距离为0.02,SAGA-FCM聚类中心d2、d3距离为0.17,相较于FCM聚类中心d2、d3之间的距离,SAGA-FCM聚类中心d2、d3距离之间区分度较大,不易陷入混叠现象,聚类结果更准确. 模拟退火温度迭代曲线如图7所示.SAGA-FCM对用户负荷曲线聚类后的结果如图8所示. 图7 模拟退火温度迭代曲线Fig.7 Simulated annealing temperature iteration curve 图8 SAGA-FCM分类结果Fig.8 SAGA-FCM classification results SAGA-FCM算法将400条数据准确分为4类,其中用户类别I呈现双峰状态,此类用户多为教育类行业,此类行业清晨起负荷,上午和下午负荷较高,中午需要休息,所示负荷略微下降;用户类别II呈峰平状态,此类行业多为工业,工业包含各种大型机器,大型机器负荷较高,且为保证效益,需全天运行,因此呈高负荷峰平状态;用户类别III多为商业,上午9点起负荷,持续至晚上10点,符合商业运行模式;用户类别IV多为农业,农业机组多数在白天运行,且运行周期不定,时长较短,如灌溉、畜牧. 对原始日负荷曲线增加 30 db 噪声进行聚类,验证本文算法对噪声干扰具有较强鲁棒性. (a)各行业分类结果 (b)各行业聚类中心图9 增加 30 db 噪声SAGA-FCM分类结果Fig.9 Classification results of SAGA-FCM with 30 dB noise added 从图9可以看出,增加 30 db 噪声后本文所提算法依旧可以准确分类,聚类中心距离依旧较远,分类清晰.聚类中心坐标及聚类中心间的距离如表4、表5所示. 由表4、表5知,30 db 噪声下SAGA优化FCM后各聚类中心距离均大于0.1,聚类效果较好,因此从工程角度看,SAGA-FCM算法分类较合理. 表4 30 db噪声下聚类中心坐标Tab.4 Cluster center coordinates after adding 30 dB noise 表5 30 db噪声下聚类中心之间距离Tab.5 Distance between cluster centers under 30 dB noise 将本文所提SAGA-FCM负荷分类算法与K-means、PSO-kmeans算法做对比,验证本文所提算法的优势.K-means、PSO-kmeans对 30 db 噪声下日负荷曲线分类结果如图10所示. (a)K-means分类结果 (b)PSO-Kmeans分类结果图10 增加30 db噪声K-means与PSO-Kmeans分类结果Fig.10 K-means and PSO-Kmeans classification results with 30 db noise added 由图10知,利用K-means与PSO-Kmeans对增加 30 db 的日负荷曲线分类结果均不准确,利用K-means对日负荷曲线进行分类,部分居民负荷与商业负荷、农业负荷分为一类;利用PSO-Kmeans分类时居民负荷与商业负荷分为一类,而农业负荷分为两类,分类准确性低.综上,相较于K-means、PSO-Kmeans等算法,本文所提SAGA-FCM在 30 db 噪声下仍能准确进行负荷分类. 运用聚类算法挖掘电力系统日负荷曲线的负荷模式需要精准分类模型.针对传统负荷分类算法易陷入局部最优解而无法准确分类的问题,本文提出一种融合进化算法优化FCM的负荷聚类算法. 1)利用重心Lagrange插值法解决日负荷曲线数据缺失问题,提出一种基于FCM的日负荷曲线聚类算法,但FCM因初始聚类中心选择不当易陷入局部最优解.模拟退火寻优能力强,遗传算法全局搜索能力强,融合SAGA优化 FCM能够计算出全局最优解,使分类结果最优. 2)利用实际日负荷曲线验证算法准确性,结果表明在数据量较大的情况下仍具有较高的分类准确率,给出聚类中心,使分类结果更具可视化,增加30db噪声验证了SAGA-FCM鲁棒性较强. 3)该方法涉及SAGA优化,相比于传统FCM计算速度较慢.如何对数据进行降维处理,提高算法运行速度是本文下一步的工作.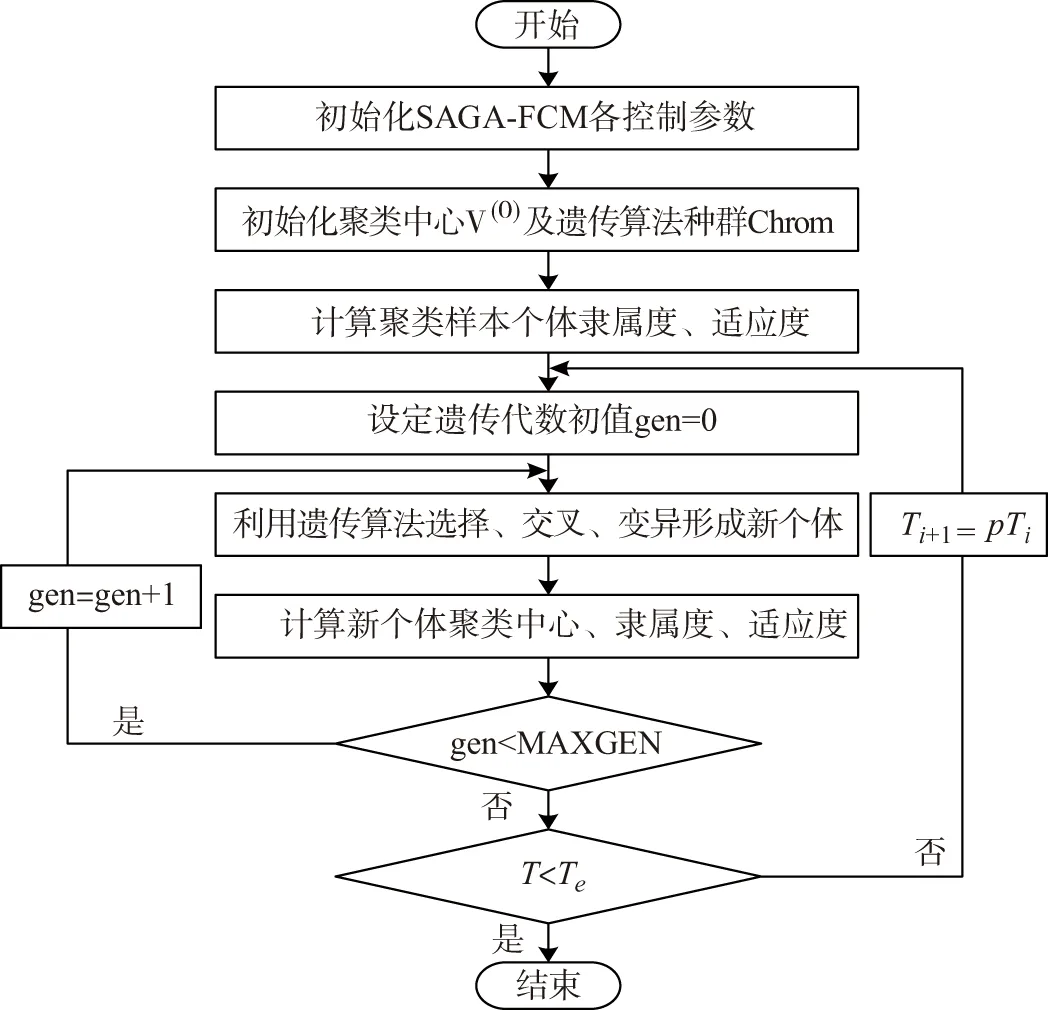
4 算例验证
4.1 实际数据预处理

4.2 SAGA-FCM分类结果与评价


4.3 鲁棒性分析


4.4 算法对比
5 结 论
