基于强化学习的渗透路径推荐模型
2022-07-05赵海妮焦健
赵海妮,焦健*
基于强化学习的渗透路径推荐模型
赵海妮1,2,焦健1,2*
(1.北京信息科技大学 计算机学院,北京 100101; 2.网络文化与数字传播北京市重点实验室(北京信息科技大学),北京 100101)(*通信作者电子邮箱jiaojian@bistu.edu.cn)
渗透测试的核心问题是渗透测试路径的规划,手动规划依赖测试人员的经验,而自动生成渗透路径主要基于网络安全的先验知识和特定的漏洞或网络场景,所需成本高且缺乏灵活性。针对这些问题,提出一种基于强化学习的渗透路径推荐模型QLPT,通过多回合的漏洞选择和奖励反馈,最终给出针对渗透对象的最佳渗透路径。在开源靶场的渗透实验结果表明,与手动测试的渗透路径相比,所提模型推荐的路径具有较高一致性,验证了该模型的可行性与准确性;与自动化渗透测试框架Metasploit相比,该模型在适应所有渗透场景方面也更具灵活性。
渗透测试;强化学习;Q学习;策略规划
0 引言
渗透测试是一种通过执行受控攻击来评估计算机系统或网络安全性的方法,是安全测试的最常用形式之一。该过程涉及对系统的任何潜在漏洞的主动分析,这些漏洞可能是由不良或不正确的系统配置、已知和未知的硬件或软件缺陷、过程中的操作弱点或技术对策引起的。这种分析是从潜在攻击者的角度进行的,涉及主动利用安全漏洞[1]。
目前的渗透测试主要是通过人工分析判断来组合各个渗透活动,从而达到渗透的目的。因此,渗透测试的结果往往取决于执行者的个人能力和经验,人工的方法也使得整个渗透过程的时间周期过长,成本较高。渗透测试自动化能够有效降低人工成本[2],其中如何实现自动化生成渗透路径是整个测试自动化过程迫切需要解决的问题。
文献[3]中提出了一种技术用于攻击图生成与分析;文献[4]中通过前向广度优先搜索策略产生渗透攻击图,然后深度优先遍历渗透攻击图生成渗透测试方案;文献[5]中通过使用攻击图寻找漏洞之间的关联,从而挖掘潜在攻击路径;文献[6-7]中提出了一个基于逻辑的网络安全分析器MulVAL,它是一个多层次的推理系统,能将安全因素转换为网络模型,违反安全策略时会给出攻击路径。
随着网络规模的增大,攻击图中会存在大量冗余节点,不利于测试人员与系统管理人员进行安全分析[4],近年来机器学习的兴起为解决渗透测试问题提供了新的思路。文献[8]中设计和实现了基于机器学习算法对SQL注入流程检测的系统;文献[9]中设计了基于XGBoost(eXtreme Gradient Boosting)算法和C-GRU(Convolutional neural network-Gated Recurrent Unit)深度学习模型的跨站脚本攻击检测方法;文献[10]中从Web文档和URL中提取特征,使用朴素贝叶斯算法及支持向量机(Support Vector Machine, SVM)算法对跨站脚本攻击进行分类。上述研究的对象是具体漏洞,因此无法解决整个渗透测试过程中存在的动态和不确定性问题。
近年来,有研究将渗透测试过程形式化为部分可观测的马尔可夫决策过程(Partially Observable Markov Decision Processes, POMDP)。文献[11]中通过知识推理减少测试过程中扫描动作的使用,依靠POMDP实现对单个机器的有效攻击,通过攻击组合实现对整个网络的攻击。
马尔可夫决策过程的研究为强化学习奠定了基础。如图1强化学习的过程,其核心是学习“做什么才能使数值化的收益信号最大化”[12]。为了获得最大的收益,强化学习智能体更加倾向于选择在过去有效产生过收益的动作;但是为了发现这些动作,往往需要尝试从未选择过的动作,因此智能体必须开发已有的经验来获取收益,同时也要进行试探,使得未来可以获得更好的动作选择空间。在实际渗透测试过程中,针对特定服务中漏洞的利用和技术的选择通常需要反复的尝试,并以此不断积累渗透经验,所以渗透测试的过程比较适合转化为强化学习的过程。

图1 强化学习过程
近几年也有不少学者将强化学习应用到渗透测试过程中。文献[13]中提出了一个自主的安全分析和渗透测试框架,将生成的攻击图转换为攻击状态与分析日志数据得到的威胁信息一并输入到强化学习计划生成器,生成器使用DQN(Deep Q Network)算法确定执行测试的最佳计划,但是需要首先生成网络的攻击图。文献[14]中使用强化学习训练智能体,以使其可以发现系统中的敏感文件和网络缺陷。文献[15]中将渗透测试过程转换为POMDP,并将其中的漏洞利用过程建立为强化学习模型,认为将其嵌入自动化渗透测试框架或系统中,比如Metasploit[16],将提高测试质量与持久性;但是POMDP计算复杂度高,只适用于中小型网络。文献[17]中提出了一种基于网络信息增益的攻击规划算法,并利用网络信息构建回报函数,指导智能体从入侵者角度发现隐藏的攻击路径,选择最佳响应操作;但是由于追求每次操作的最大信息增益,将会出现一系列局部最优的路径组合并不是全局最优渗透路径的情况。
综上所述,使用强化学习解决渗透测试问题仍处于研究初级阶段,针对当前研究存在的问题,本文基于强化学习提出了QLPT(Q Learning Penetration Test)模型,将渗透测试中的漏洞选择过程转换为强化学习的动作选择过程。该模型不需要借助攻击图生成状态-漏洞信息,而是利用Q学习使模型通过多回合的利用、探索与奖励形成完备的状态-漏洞Q表,在训练完成之后可以根据每个状态选择对应最佳漏洞从而达到推荐最佳渗透路径的效果。
1 模型构建
1.1 参数定义
为构建模型,首先定义建模涉及的元素,如表1所示。

表1 主要符号及其含义


表2 系统访问权限说明
1.2 模型组成
QLPT模型主要由漏洞选择、漏洞利用、奖励值转换、Q学习、状态-漏洞Q表和状态更新等模块组成(表3),模型训练过程如图2所示。

表3 QLPT内部模块功能说明
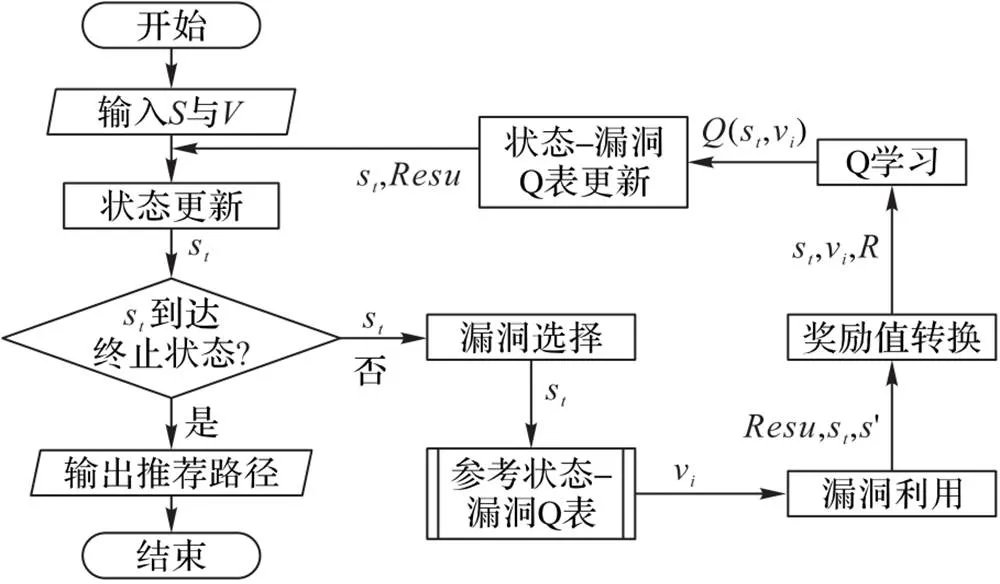
图2 QLPT训练流程


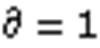
2 Q学习模块设计
Q学习[19-20]是一种无模型强化学习的形式,其目标是学习如何将状态映射到行动,以便在未知环境中最大化数字奖励信号。在Q学习中,待学习的动作价值函数采用了对最优动作价值函数*的直接近似作为学习目标,而与用于生成智能体决策序列轨迹的行动策略无关。

式(3)可以表达状态-动作对的值与其后继状态-动作对之间的关系,Q学习使用式(3)来估计每个状态-动作对:

由于渗透过程中出现的状态及动作是离散和有限的,这些状态-动作对可以用表格形式表示,所以将其放在表格中形成了Q表。其中所有状态-动作对在初始化时都被赋予一个初始值,在学习过程中每次收到一个奖励时,相关的状态-动作值将被依据贝尔曼方程(4)更新:

在模型开始学习之前,根据模型输入的渗透对象状态集与可利用漏洞集对状态-漏洞Q表进行初始化,此时表中的状态-漏洞期望收益值都为0;在模型开始学习之后,每个回合的学习过程中,Q学习模块将根据奖励值更新Q表中的相应期望收益值;经过多个回合的选择与奖励,Q表中的值将会趋于稳定,意味着此时的漏洞选择是利用先前的经验信息得到的。
本文根据Q学习理论提出了QLPT模型的训练算法,如下:

3 实验与验证
3.1 实验过程
为验证本文模型,构建实验场景如图3所示,本实验的渗透对象是OWASP BWA提供的可公开访问的Web应用缺陷测试系统,该环境涵盖了注入类、XSS、管理配置错误、弱口令等常见的Web漏洞类型,具有较强的代表性。测试人员需要使用漏洞扫描工具对渗透对象进行漏洞扫描,将得到的可利用漏洞集(详见表4)、规定的渗透对象状态集(详见表5)及最大学习回合数()800输入模型进行模型初始化;开始学习后,模型不断产生具体漏洞利用动作,测试人员通过使用工具对渗透对象执行漏洞利用,并将得到的利用结果返回给模型,模型将结果转换化为奖励值对Q表进行更新;在经过多回合学习之后,最终产生推荐的一条或多条渗透路径。
表4是使用漏洞扫描工具Acunetix对渗透对象(OWASP BWA Web应用缺陷测试系统)进行漏洞扫描得到的漏洞信息,将其作为可利用漏洞集输入到渗透路径推荐模型中。设置最大学习回合数为800,并启动模型开始学习。学习过程中测试人员依据模型输出的漏洞与工具信息,使用工具对渗透对象进行漏洞利用,并将得到的结果输入到模型中。
图3 实验场景

表4 漏洞信息说明

表5 状态集索引
3.2 实验结果与分析
QLPT模型通过800回合的学习,得到稳定的状态-漏洞Q表,分别选取各状态下期望收益值最大的对应漏洞进行利用,即构成渗透路径,如图4所示,其中箭头代表的是状态转换,例如由状态(web,access,漏洞信息)到达状态(web,user,后台URL)Q表中记录的可利用漏洞有多个,其中利用漏洞CWE-22的概率为91%。经过与手动测试的渗透路径进行对比,发现本文模型推荐的渗透路径与其一致,渗透路径都为:目录扫描漏洞利用→SQL注入漏洞利用→文件上传漏洞利用→暴力破解漏洞利用。

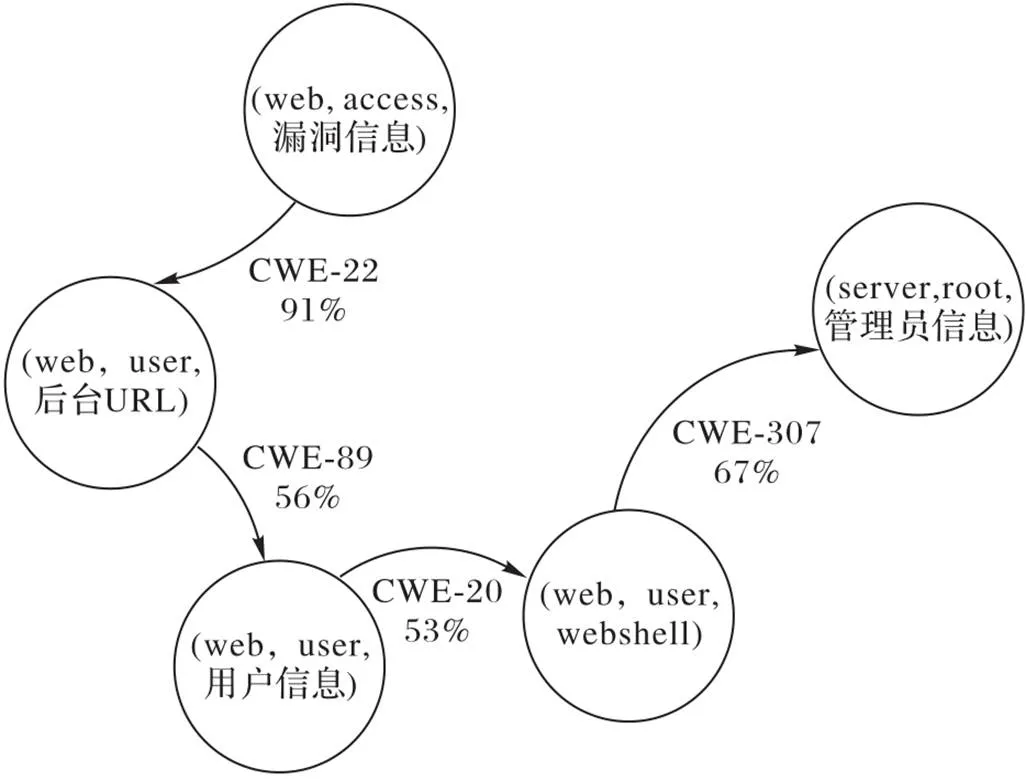
图4 渗透路径
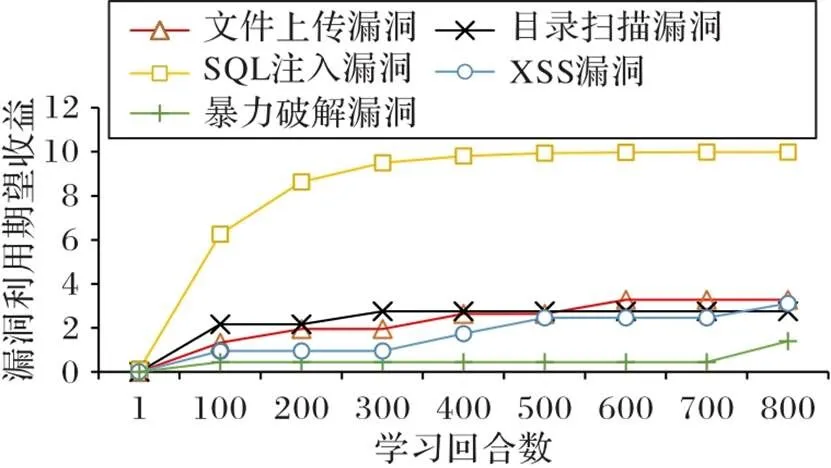
图5 漏洞利用期望收益值随学习回合数的变化
通过将QLPT和渗透测试自动化框架Metasploit[16]的优劣势对比,得出结果如表6所示。Metasploit渗透测试成功率比较高的场景是其框架所包含的场景,由于QLPT是根据渗透目标进行学习训练,所以没有攻击场景限制;在Metasploit框架中,负责渗透路径规划的是威胁建模阶段和漏洞分析阶段,每个漏洞在被利用之后产生的结果对后续此漏洞的利用没有反馈更新作用,而QLPT模型的核心是漏洞利用的反馈更新机制;在使用模型的先验知识层面,QLPT和Metasploit一样不需要使用者具备渗透测试漏洞的利用经验。
统计为达到渗透目标每回合学习所进行的漏洞利用尝试次数如图6所示,发现随着模型学习地不断深入,每回合进行漏洞利用尝试的次数大幅降低。原因是奖励值为漏洞选择提供了导向作用,学习经验以奖励值形式累积,使后续学习中动作选择步骤越来越少,而学习过程中尝试次数偶尔的增加是因为动作选择过程中的随机参数。

表6 QLPT和Metasploit的对比

图6 为达到渗透目标每回合学习的漏洞利用尝试次数
4 结语
本文采用强化学习进行Web渗透测试的路径规划,与以往的研究不同,本文模型不需要事先具备大量的渗透测试知识,而是通过模型不断地试错与接受奖励,以更新状态-漏洞Q表,最终依据Q表输出针对当前渗透对象的推荐渗透路径。本文通过实验验证了使用强化学习进行渗透测试路径规划的可行性。未来的研究可以将漏洞信息和知识图谱相结合,引入深度学习继续提升强化学习的学习效率。
)
[1] SARRAUTE C. Automated attack planning[D]. Buenos Aires: Instituto Tecnológico de Buenos Aires, 2012:23-24.
[2] SINGH N, MEHERHOMJI V, CHANDAVARKAR B R. Automated versus manual approach of web application penetration testing[C]// Proceedings of the 11th International Conference on Computing, Communication and Networking Technologies. Piscataway: IEEE, 2020: 1-6.
[3] SHEYNER O, HAINES J, JHA S, et al. Automated generation and analysis of attack graphs[C]// Proceedings 2002 IEEE Symposium on Security and Privacy. Piscataway: IEEE, 2002: 273-284.
[4] SWILER L P, PHILLIPS C, GAYLOR T. A graph-based network-vulnerability analysis system: SAND-97-3010C; CONF-980534ON: DE98001486; BR: YN0100000; TRN: AHC2DT03%%16[R]. Albuquerque, NM: Sandia National Lab, 1998:8.
[5] YU X H, JIANG J H, SHUAI C Y. Approach to attack path generation based on vulnerability correlation[M]// KOPCHO J, KURZAWA C, MACPHERSON G. IEEE Conference Anthology. Piscataway: IEEE, 2013: 1-6.
[6] OU X M, GOVINDAVAJHALA S, APPEL A W. MulVAL: a logic-based network security analyzer[C]// Proceedings of the 14th USENIX Security Symposium. Berkeley: USENIX Association, 2005: 113-128.
[7] OU X M, BOYER W F, McQUEEN M A. A scalable approach to attack graph generation[C]// Proceedings of the 13th ACM Conference on Computer and Communications Security. New York: ACM, 2006: 336-345.
[8] 张登峰. 基于机器学习的SQL注入检测[D]. 重庆:重庆邮电大学, 2017:1-69.(ZHANG D F. SQL injection detection based on machine learning[D]. Chongqing: Chongqing University of Posts and Telecommunications, 2017:1-69)
[9] 洪镇宇. 基于机器学习的跨站脚本攻击检测研究[D]. 厦门:厦门大学, 2018:1-77.(HONG Z U. Research on detection of cross-site scripting attacks based on machine learning[D]. Xiamen: Xiamen University, 2018:1-77.)
[10] NUNAN A E, SOUTO E, DOS SANTOS E M, et al. Automatic classification of cross-site scripting in web pages using document-based and URL-based features[C]// Proceedings of the 2012 IEEE Symposium on Computers and Communications. Piscataway: IEEE, 2012: 702-707.
[11] SARRAUTE C, BUFFET O, HOFFMANN J. POMDPs make better hackers: accounting for uncertainty in penetration testing[C]// Proceedings of the 26th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2012: 1816-1824.
[12] RICHARD S S, BARTO A G. Reinforcement Learning: An Introduction[M]. Cambridge: MIT Press, 1998: 313-314.
[13] CHOWDHARY A, HUANG D J, MAHENDRAN J S, et al. Autonomous security analysis and penetration testing[C]// Proceedings of the 16th International Conference on Mobility, Sensing and Networking. Piscataway: IEEE, 2020: 508-515.
[14] CHAUDHARY S, O’BRIEN A, XU S. Automated post-breach penetration testing through reinforcement learning[C]// Proceedings of the 2020 IEEE Conference on Communications and Network Security. Piscataway: IEEE, 2020: 1-2.
[15] GHANEM M C, CHEN T M. Reinforcement learning for intelligent penetration testing[C]// Proceedings of the 2nd World Conference on Smart Trends in Systems, Security and Sustainability. Piscataway: IEEE, 2018: 185-192.
[16] Rapid7. Metasploit[DB/OL]. [2021-06-17]. https://www.rapid7.com/products/metasploit/.
[17] ZHOU T Y, ZANG Y C, ZHU J H, et al. NIG-AP: a new method for automated penetration testing[J]. Frontiers of Information Technology and Electronic Engineering, 2019, 20(9): 1277-1288.
[18] Invicti. Acunetix[DB/OL]. [2021-06-17].https://www.acunetix.com/.
[19] WATKINS C J C H. Learning from delayed rewards[D]. Cambridge: King’s College of University of Cambridge, 1989:1-142.
[20] WATKINS C J C H, DAYAN P.-learning[J]. Machine Learning, 1992, 8(3/4):279-292.
Recommendation model of penetration path based on reinforcement learning
ZHAO Haini1,2, JIAO Jian1,2*
(1,,100101,;2(),100101,)
The core problem of penetration test is the planning of penetration test paths. Manual planning relies on the experience of testers, while automated generation of penetration paths is mainly based on the priori knowledge of network security and specific vulnerabilities or network scenarios, which requires high cost and lacks flexibility. To address these problems, a reinforcement learning-based penetration path recommendation model named Q Learning Penetration Test (QLPT) was proposed to finally give the optimal penetration path for the penetration object through multiple rounds of vulnerability selection and reward feedback. It is found that the recommended path of QLPT has a high consistency with the path of manual penetration test by implementing penetration experiments at open source cyber range, verifying the feasibility and accuracy of this model; compared with the automated penetration test framework Metasploit, QLPT is more flexible in adapting to all penetration scenarios.
penetration test; reinforcement learning; Q learning; strategic planning
This work is partially supported by Opening Project of Beijing Key Laboratory of Internet Culture and Digital Dissemination Research (ICDDXN006).
ZHAO Haini, born in 1997, M. S. candidate. Her research interests include network security, penetration test.
JIAO Jian, born in 1978, Ph. D., associate professor. His research interests include network security, blockchain.
TP393.08
A
1001-9081(2022)06-1689-06
10.11772/j.issn.1001-9081.2021061424
2021⁃08⁃09;
2021⁃10⁃16;
2021⁃10⁃29。
网络文化与数字传播北京市重点实验室开放课题(ICDDXN006)。
赵海妮(1997—),女,安徽阜阳人,硕士研究生,CCF会员,主要研究方向:网络安全、渗透测试;焦健(1978—),男,河北沧州人,副教授,博士,CCF会员,主要研究方向:网络安全、区块链。
