基于多元策略改进的灰狼算法机器人路径规划
2022-07-04齐鹏飞丁鑫
齐鹏飞 丁鑫
(①河南省地震局,河南 郑州 450016;②中国人民解放军战略支援部队信息工程大学,河南 郑州 450001)
近年移动机器人技术已逐渐渗入到生活中的各个领域内,极大地节省了人力资源成本。而路径规划技术是移动机器人领域的关键技术之一,它是指机器人在特定环境中,找出一条连接起点与终点的最佳路径[1−2]。路径规划问题上具有代表性的传统算法有RRT法[3]、人工势场法[4]、神经网络算法[5]和A*算法[6]等。除此之外,还有大量仿生算法例如蚁群算法[7]、遗传算法[8]及粒子群算法[9]等等。这些算法也都在路径规划领域内取得了不错的成效。
灰狼算法(GWO)是由Mirjalil S等提出的一种元启发式算法,该算法模拟了灰狼的领导阶层和捕猎过程。近年来灰狼算法开始应用于路径规划领域,同样取得了良好的表现。与其他群智能优化算法一样,灰狼优化算法也存在一些不足之处。例如原灰狼算法在攻击猎物时容易陷入停滞状态,在搜索后期收敛速度逐渐变慢。因此国内外许多学者提出了一系列改进措施。文献[10]提出了一种混合灰狼优化算法,该算法利用混沌序列增强全局搜索的多样性,从而平衡算法搜索和开发能力。文献[11]提出了一种结合动态进化机制的灰狼算法来提高算法的局部搜索能力。但它没有对算法的全局搜索能力进行改进。文献[12]提出了一种融入混合差分进化思想的改进灰狼算法,解决了机械设计函数优化问题。然而,以上这些算法在研究灰狼捕获猎物过程中,没有将单只狼的信息对整个种群的影响考虑在内。
因此,基于上述存在的问题提出一种多策略改进的灰狼优化算法。首先为提升领头狼在算法中的作用,提出了一种随机游走策略。同时,引入一种基于光学凸透镜原理的逆学习机制,对狼群种群中的劣势个体进行逆向学习,从而增加狼群个体多样性,避免算法陷入局部最优。最后,通过B-spline曲线对路径进行平滑操作,提高路径平滑度。
1 基本灰狼算法
灰狼算法是Mirjalil S等人受灰狼捕食行为启发提出的一种群体算法。GWO算法的核心思想来自于灰狼群体中自然发生的狩猎行为和社会领导现象。灰狼是群居的,平均每群5~12只狼。在它们的社会生活行为中,它们严格遵循社会等级,社会等级示意图如图1所示。在层次结构中,最高层次的狼成员被称为α,第二级成员被称为β,随后第三级和第四级成员分别被称为delta (δ)和omega (ω)。领头狼是一个领导者,对狩猎、睡觉、醒来的时间等问题全权负责。领头狼也被称为统治狼,因为它的命令会被狼群遵循。另外,领头狼并不是群体中最强壮的成员,而是在管理狼对猎物的攻击方面做得最好的。
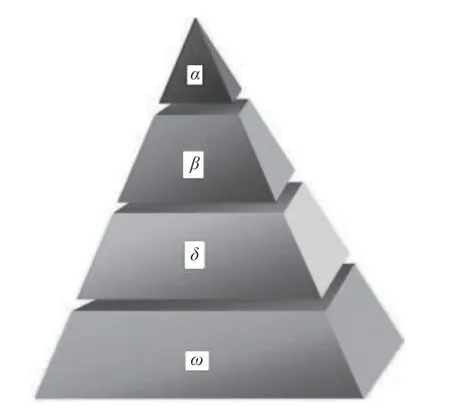
图1 灰狼群体的社会等级
在灰狼狩猎中发生的主要活动是:跟踪和追捕猎物;包围和骚扰猎物直到其停止移动;小心地向猎物移动。GWO的数学模型如下:
阶段1:这基本上是一个搜索阶段,在搜索猎物的过程中,灰狼强烈遵循社会等级制度。
阶段2:这一阶段被称为包围阶段,当搜索过程完成后,他们的下一步是包围猎物。围捕猎物的表现如下。
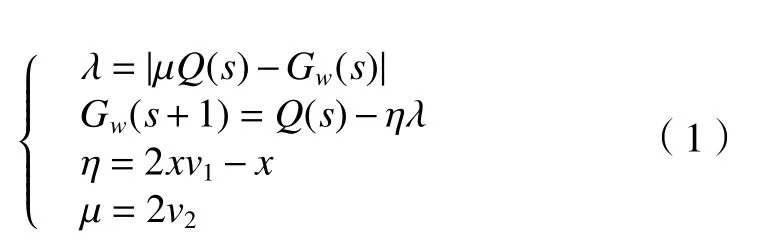
式中:λ为狼和猎物之间的距离;Q为猎物位置;Gw代表灰狼的位置;η和μ为系数矢量;x在区间[0,2]线性递减;v1、v2为[0,1]上的随机向量;s为迭代次数。
阶段3:当搜索和包围阶段完成后,它们的下一个阶段是狩猎。狼群位置更新的数学模型为
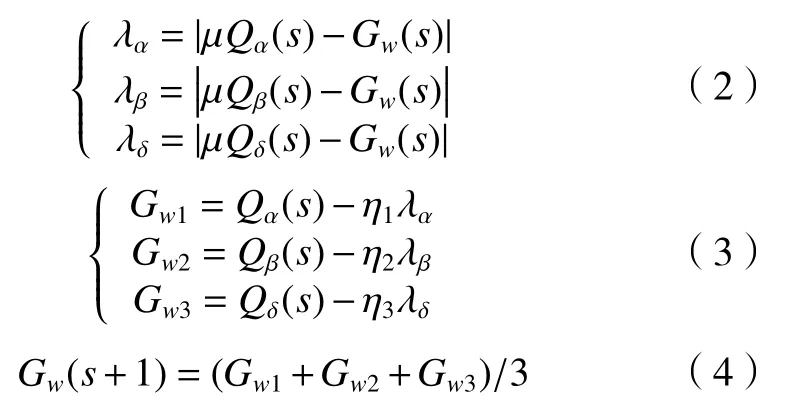
式(2)表示各个类型狼个体间的距离更新模型,式(3)代表移动的方向与步长,式(4)为新一代灰狼位置。
阶段4:最后阶段决定狼群是否攻击目标,或者寻找其他更强壮的猎物。
2 改进灰狼算法
2.1 随机游走策略
在更新狼群中每只狼位置的迭代过程中,领头狼的选择是非常重要的,因为每只狼的位置都是根据领头狼位置更新的。因此,领头狼群需要扩大活动范围,以避免由于局部最优解的停滞而导致的早熟收敛问题,并控制群体内的社会行为。为此,本文提出一种随机游走策略,即领头狼通过随机游走来增大搜索空间,然后ω狼根据搜索空间进行位置更新。
随机行走是由连续的随机步长组成的随机过程。数学表达式如下 。

式中:WN表示当前状态;Si表示从任何随机分布中选取的随机步长。
任意两个连续随机行走之间的关系定义为
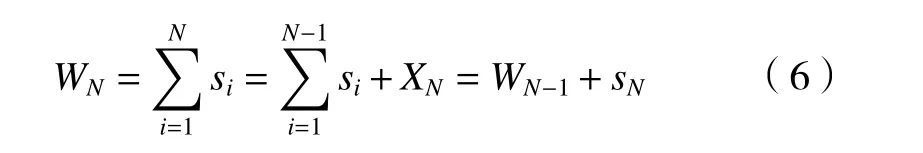
式中:WN−1表示上一状态和SN为上一状态到当前状态所选取的步长。步长Si可以是不变的,也可以是变化的。因此,对于从位置x0开始的狼,假设它的最终位置是xN,那么随机游走也可以定义为
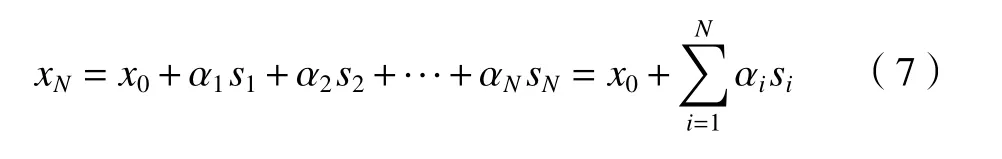
其中:αi是控制每次迭代中的步长si的参数,其值大于零。
2.2 透镜逆学习策略
在灰狼算法中领头狼影响着整个算法的性能,一旦其陷入局部最优,那么算法寻优效率将大打折扣,因此提高领头狼的搜索范围就显得尤为重要。一般学习策略在一些优化算法中取得了较好的效果,但在工程问题中对算法性能影响不大,这是因为一般学习策略在局部空间进行逆解,丰富了种群的多样性,但搜索范围较窄,缺乏灵活性。为了提高领头狼的搜索能力,提出一种基于凸透镜成像的逆学习策略,并将其应用于领头狼的个体更新过程中,其具体原理描述如下:
定义1 逆向点:假定X=(x1,x2,···,xD)为D维空间内的一个点,其中xi∈[aj,bj],j=1,2,···,D,则X的逆向点为,且。
定义2 基点:如果在D维空间内存在若干点o1,o2,···,om,对于任意一点X与X'到oi的欧几里得距离分别为di和,假设,此时称oi为X与X'在k=i时的基点。
在一维空间内,假定有一高为h的个体P,其直角坐标上的投影为x*,o为基点。o点放置一焦距为f的凸透镜,此时可得一个高度为h'的像P',其在直角坐标上的投影为x'*。这个x'*就是个体x*通过透镜逆学习产生的逆向个体,如图2所示。
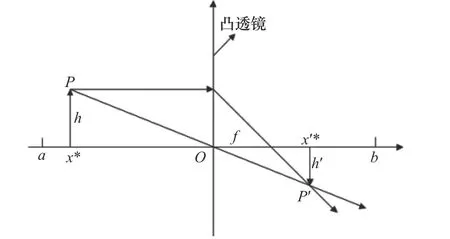
图2 透镜逆学习策略示意图
根据上图可得以下关系。
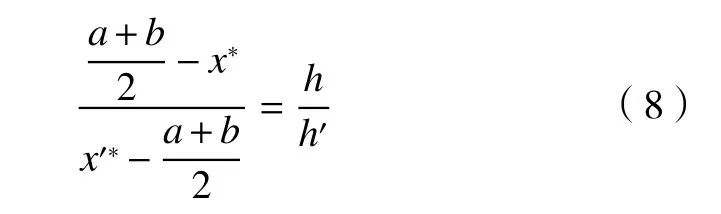
令k=h/h',并且对式(8)进行换算,可得到逆向点的数学表达式。
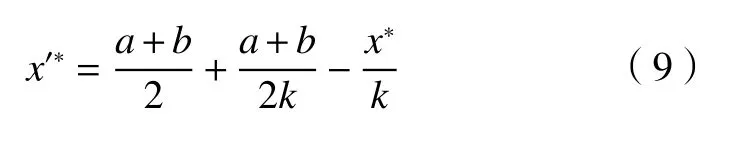
当k=1时,上式可化简为

上式即为一般的逆学习策略,学习过程中个体不会发生变化。本文通过调节不同的k值,实现个体更新,从而丰富了狼群的多样性。
将式(9)推广至D维空间内,可得关系式如下。
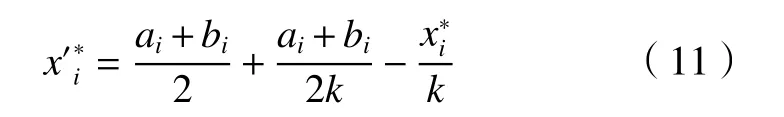
2.3 B-spline曲线平滑操作
B-spline是样条曲线的一种特殊曲线形式,同时也是bezier曲线的一般形式。n次B-spline表达式为
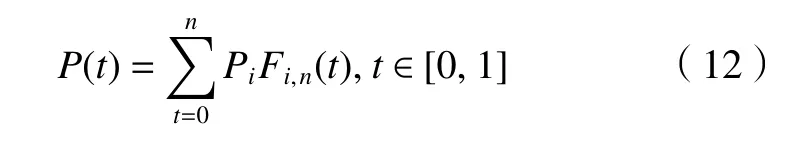
式中:Pi为第i段控制点方程;Fi,n为n次B-spline 的基函数,其公式为
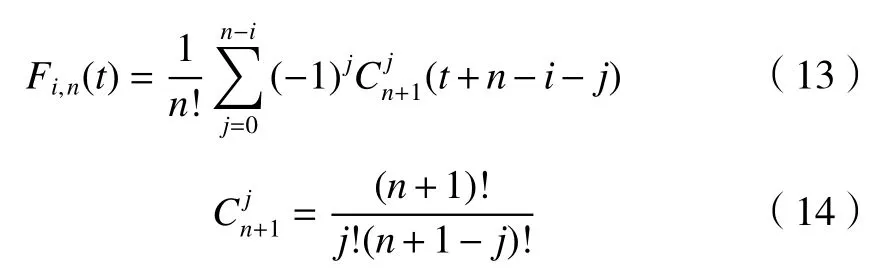
本文采用三次准均匀B-spline对规划的路径进行平滑处理。三次B-spline曲线的具体表达式如下。

2.4 多步长移动方式
基本灰狼算法中一般采用单步移动模式,且转移的方向只能为8个方向。在传统的单步长移动模式下路径距离更长,且转折次数也更多。因此本文采用多步长移动方式。示意图如图3所示,虚线为单步长移动,实线为多步长移动方式。由图可知,多步长移动模式下路径距离更短且转折次数更少。
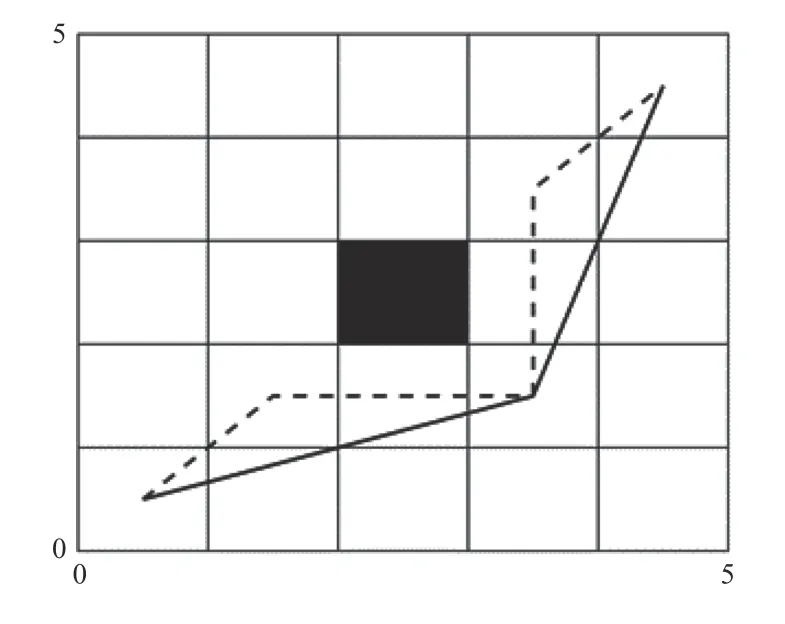
图3 两种步长模式对比
2.5 改进灰狼算法流程
本文改进灰狼算法的具体步骤如下:
步骤1:初始化运行环境及灰狼算法各项参数,确定需要人为设定的参数取值。
步骤2:初始化灰狼种群,计算出种群内各个体的适应度,然后由高到低进行排列,分别将前三最佳个体位置赋予α狼、β狼和δ狼。
步骤3:根据式(2)~(4)更新种群内各灰狼位置信息。
步骤4:依据式(1)更新α狼、β狼和δ狼位置。
步骤5:利用式(11)对个体进行透镜逆学习,获得逆向解。
步骤6:用计算出的逆向解代替原解,加入种群内进行迭代操作。
步骤7:检查是否达到最大迭代次数,若是则输出路径,否则返回步骤3。
步骤8:利用B-spline 曲线对上步得到路径进行平滑,然后输出最佳路径。
3 仿真及分析
3.1 环境建立
本文将栅格图作为机器人建模环境。在栅格地图中用黑色部分代表不可行域,白色部分则代表自由通行区域。若环境中存在障碍物无法完全占据一个栅格的情形,则进行膨化操作使其充满一格,如图4所示。
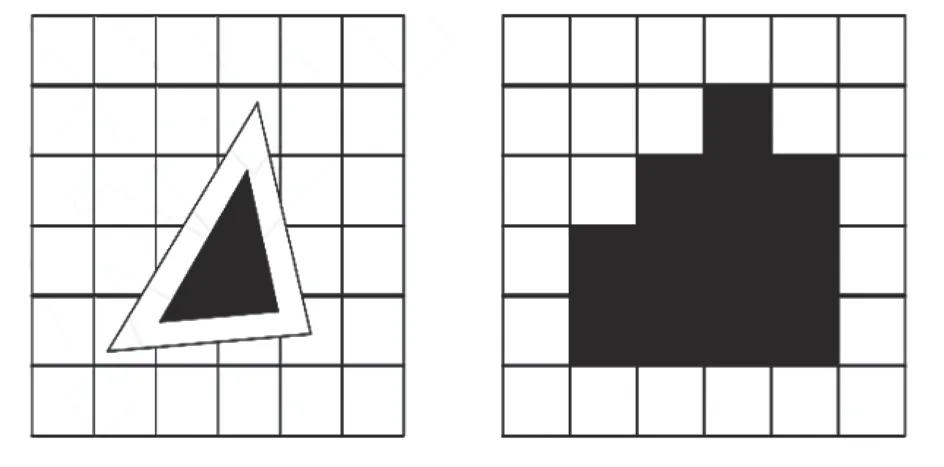
图4 膨化处理
假设栅格图中,栅格号按从下至上,从左到右依次递增。栅格地图规格为m行n列,栅格号为K,栅格粒径为1,则栅格中心坐标可表示为
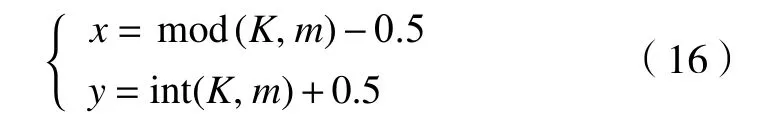
式中:x、y分别为中心点的横、纵坐标;mod为取余操作,int表示求整。
3.2 仿真分析
各算法进行对比时选取的参数值均保持一致,其中灰狼种群规模为50,最大迭代数为100,x的最初取值为2。每种算法均仿真20次,得出平均仿真结果及指标。基于Matlab2018b平台搭建20×20栅格地图环境,运行内存8 GB,CPU 2.5 Hz,设置起点为(0.5,0.5),终点为(19.5,19.5)。
(1)普通多障碍环境
首先基于栅格地图环境并设置相关参数值,分别对基本灰狼、文献[10]算法、本文改进的灰狼算法进行仿真实验。仿真结果分别如图5、6所示,各项指标对比如表1。
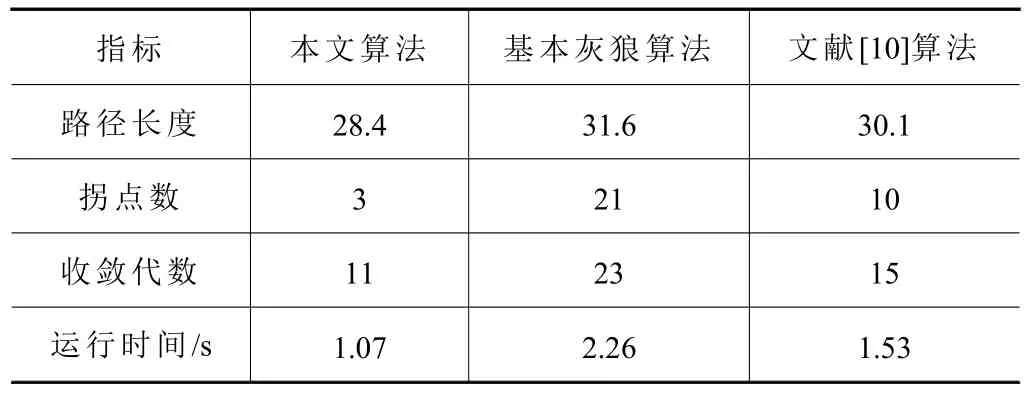
表1 普通环境指标对比
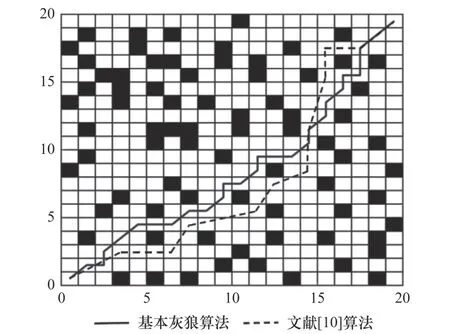
图5 基本灰狼算法与文献[10]算法结果图
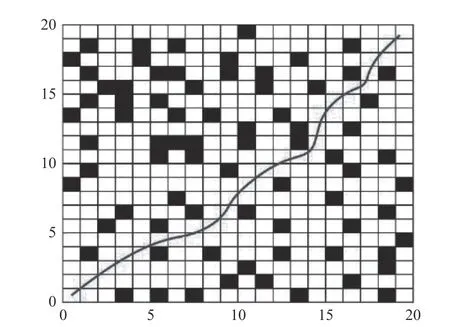
图6 本文算法结果图
从图5~6及表1可以得到,与基本灰狼算法和文献[10]改进灰狼算法相比,本文改进的灰狼算法规划出的路径长度更平滑更短,拐点数远少于其他两种算法,且算法寻优效率更高。相比于基本灰狼算法和文献[10]算法,其中路径长度分别减少约9.9%和5.6%,拐点数分别减少85.7%和70%,收敛代数分别减少约52.2%和26.6%,运行时间分别缩短约52.7%和30%。这显示出本文提出的改进策略可行且规划效率较高,能够用于移动机器人常规环境下的路径规划。
(2)多U型陷阱环境
为了进一步检验算法在复杂环境下的性能。基于栅格图建立多U型陷阱环境的极端情形,在此种环境下因为陷阱较多,对算法的适应性也提出了巨大挑战。仍然将本文算法与基本灰狼算法及文献[10]算法进行对比,结果如图7所示。其中实线为基本灰狼算法仿真路径,虚线为文献[10]算法仿真路径,点线为本文算法仿真路径,指标对比如表2。
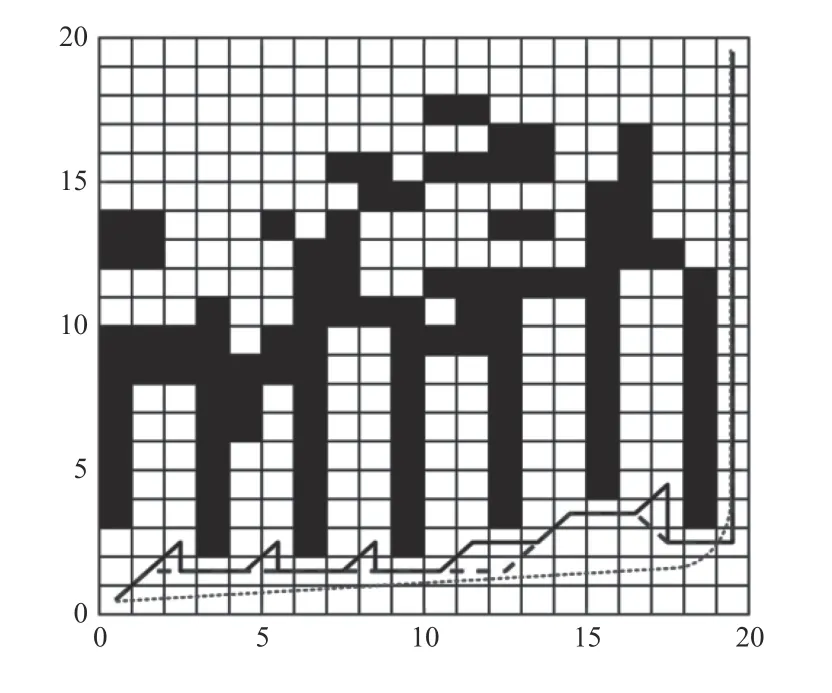
图7 陷阱环境仿真图
由图7及表2可知,在多陷阱复杂环境下,本文算法因引入了随机游走策略及透镜逆学习机制,仍旧保持着较高的规划效率。而基本灰狼算法遇到陷阱环境易陷入局部最优,导致路径距离长,转向多,寻优效率较低。文献[10]算法虽有改进,但其效果不如本文算法。具体体现为相比于基本灰狼算法和文献[10]算法,路径长度分别减少约18.9%和5.6%,拐点数分别减少93.7%和83.3%,收敛代数分别减少约59.5%和34.6%,运行时间分别缩短约60.1%和38.6%。
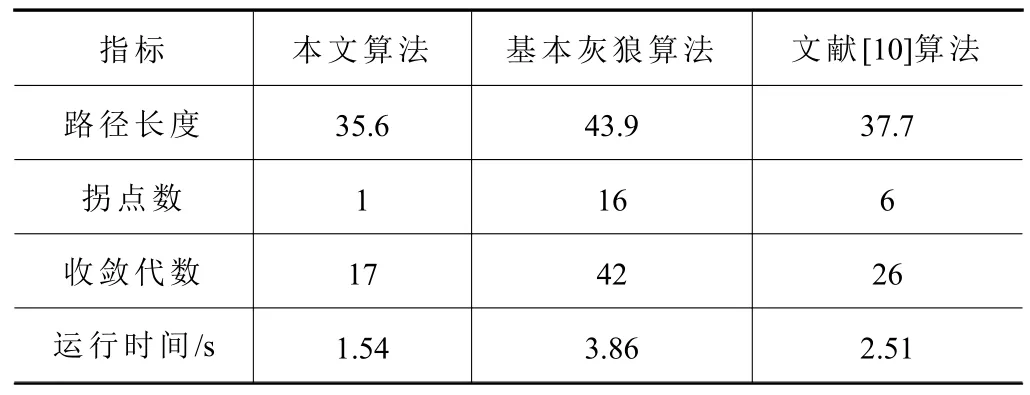
表2 陷阱环境指标对比
4 结语
针对传统灰狼算法在路径规划时易陷入局部极值、探索效率低等不足,提出一种多元策略改进的灰狼算法。首先为提升领头狼在算法中的作用,提出了一种随机游走策略。同时,引入一种基于光学凸透镜原理的逆学习机制,避免算法陷入局部最优。最后,通过B-spline曲线对路径进行平滑操作,提升路径平滑度。分别基于普通环境及多U型陷阱环境进行了仿真,普通环境下本文算法相比于基本灰狼算法,路径长度减少约9.9%,收敛代数减少约52.2%,转弯次数减少85.7%,运行时间缩短约52.7%,而在多U型陷阱环境条件下对比基本灰狼算法,本文算法优势更加明显,路径长度减少约18.9%,拐点数分别减少93.7%,收敛代数减少约59.5%,运行时间缩短约60.1%,展现出多元策略改进灰狼算法的良好性能。
