基于改进YOLOv3的卷纸包装缺陷实时检测算法
2022-06-29李志诚曾志强
李志诚 曾志强
(五邑大学智能制造学部,广东江门,529000)
造纸工业在国民经济中具有重要作用,2020 年,我国纸及纸板生产企业达2500 多家[1]。生活用纸企业是造纸工业的重要组成部分,在经济全球化以及科技不断发展的大背景下,生活用纸企业的竞争日趋激烈。降低生产成本、提高生产效率以及产品质量是生活用纸企业提升自身竞争力的有效途径[2]。卷纸是生活用纸企业的主要产品之一,在卷纸的生产过程中,卷纸包装是其中的一个工序,在包装过程中,不可避免会出现包装缺陷问题。卷纸包装缺陷问题的出现给企业生产带来了多种问题,主要体现在以下几个方面:①导致产品重新包装,浪费包装材料,增加辅料的成本以及废弃的包装材料会增加环境污染;②需要花费大量的人力检测产品包装问题,增加人力成本并难以保证产品包装过程的可靠性;③若有包装缺陷的产品流入到市场,增加客户的投诉以及降低企业的信誉。为此,有效解决卷纸的包装缺陷检测问题对于生活用纸企业的提质增效具有重要意义。
传统机器学习方法具有一定的缺陷检测效果,如通过将方向梯度直方图(Histogram of Oriented Gradi⁃ent,HOG)和支持向量机(Support Vector Machine,SVM)结合[3]的方法对车辆零件进行缺陷检测;使用SIFT 匹配算法对PCB 板进行缺陷检测[4]。然而,以上方法并不能有效地解决卷纸包装缺陷检测问题。随着深度学习的快速发展,其在工业上的应用越来越广泛,尤其是卷积神经网络(Convolutional Neural Networks,CNN) 在缺陷检测[5-7]和缺陷分类[8-9]上的应用。
随着CNN 的快速发展,其在计算机视觉领域也取得了很多重要的突破。例如,为了避免重复计算卷积特征,He 等[10]提出了空间金字塔池化(Spatial Pyramid Pooling,SPP),整个图像仅计算1次特征图,在任意区域中合并特征以生成固定长度的表示形式;为了减少神经网络计算的资源,Wang等[11]提出了跨阶段局部网络(Cross Stage Partial Network,CSPNet);在目标检测领域,Redmon等[12]提出了YOLOv3算法,使用Darknet-53作为骨架网络,提取图片信号的多尺度特征,然后进行多尺度特征融合以提取深层次特征,然后通过检测头进行预测。YOLOv3 算法在目标检测方面具有较高的准确性和较快的检测速度,目前在目标识别、缺陷检测等领域获得了很好的应用[13-15]。
相对来说,CNN 的全局特征提取能力较弱,而Transformer具有更好的全局特征提取能力[16],但其对于细节和局部特征的提取能力不如CNN。Transformer一开始被应用在自然语言处理(NLP)领域,后来,Google Brain 提出了 Vision Transformer[17],实现了图片分块处理,将Transformer 应用到了计算机视觉领域,可获得比CNN 更好的检测效果,有利于图像数据的全局特征提取。Srinivas等[18]结合多种计算机视觉任务的自注意力机制,提出了Bottleneck Transformer,采用多头注意力(Multi-Head Self-Attention,MHSA)替换Resnet网络中的3×3卷积,在实例分割和目标检测方面,减少了参数量,提高了检测速度。
1 基于iYOLOv3的卷纸包装缺陷检测算法
针对卷纸包装缺陷检测问题,笔者提出了改进的YOLOv3(iYOLOv3)算法,考虑卷纸包装图像信息具有很强的局部相关性和全局相关性,在对图像数据的特征提取网络设计上,将MHSA和CNN结合,对于图像的低层特征图和高层特征图分别使用CNN和MH⁃SA 进行特征提取,有利于二者取长补短,更加充分地提取局部和全局特征;同时在特征融合网络层设计上,将特征金字塔网络(Feature Pyramid Networks,FPN)[19]和路径聚合网络(Path Aggregation Network,PAN)[20]结合,以更深层次地提取图像数据的上下文信息。
1.1 iYOLOv3算法的设计
iYOLOv3 算法的网络模型主要分为3 部分:骨架网络、特征融合层、检测头。通过骨架网络提取出图片数据的多尺度特征,然后通过特征融合层对多尺度特征进行特征融合,最后通过CNN 获得初步预测结果,然后通过非极大值抑制(Non-Maximum Suppres⁃sion,NMS)[21]以去除多余的框,得到最终的预测结果。对于骨架网路的设计,并非使用全卷积网络,而是采用MHSA和CNN结合的设计方法,因为自注意力机制的时间与空间复杂度、输入尺寸成二次方关系,而低层特征图的输入尺寸太大,故直接使用MHSA将会消耗较大的计算资源。因此,笔者首先通过CNN获得高层特征图,而高层特征图尺寸较小,故使用MHSA提取高层特征图语义信息。iYOLOV3算法网络结构图如图1所示。
图1中Conv0~Conv10各个CNN的结构参数如表1所示。Conv0~Conv10 各个CNN 在完成卷积操作后,进行BatchNorm操作,而后经过SiLU激活函数,得到相应的特征图。

图1 iYOLOv3算法网络结构图Fig.1 Network structure diagram of iYOLOv3 algorithm
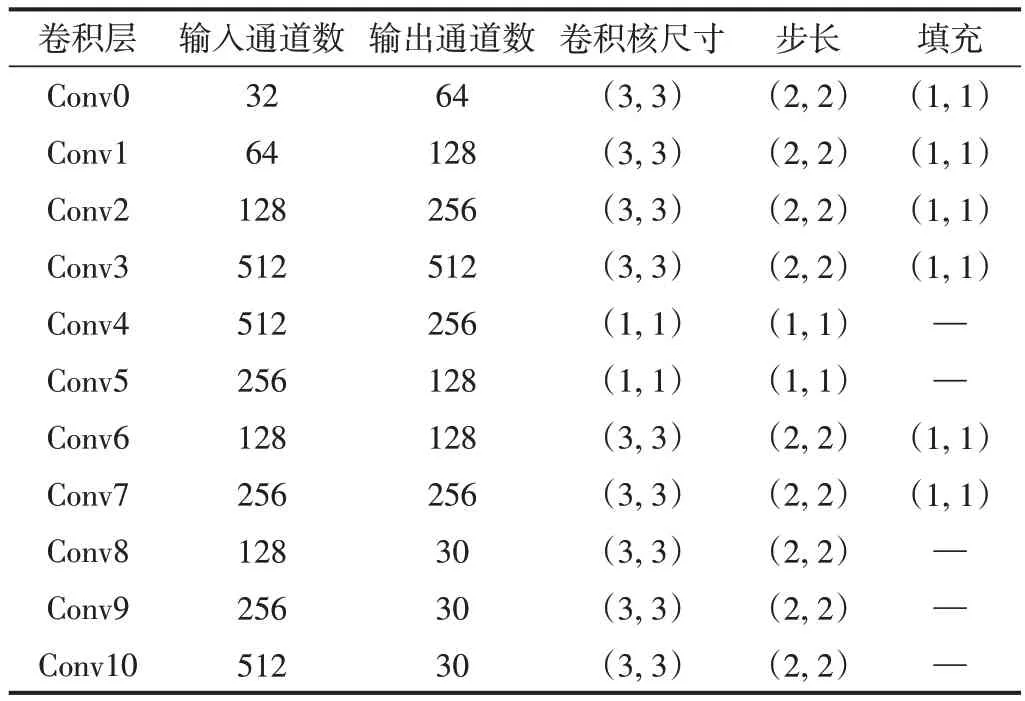
表1 CNN结构参数Table 1 Structure parameters of CNN

式中,(bx,by)是预测框的中心坐标;bw和bh分别是预测框的宽和高;(cx,cy)是预测框相对于单元格的偏移值;pw和ph分别是边界框的宽和高;δ是Sigmoid激活函数,其计算公式见式(2)。
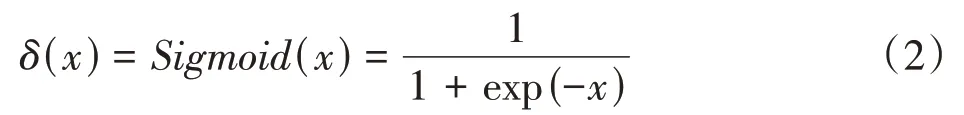
1.2 Slice_CNN网络层
在YOLOv3 的基础上,笔者新增了Slice_CNN 网络层。Slice_CNN 网络层将输入的图像数据信息进行初步的特征提取,相对于全卷积神经网络,其层数和参数量更少,网络推理速度更快。Slice_CNN 网络结构图如图2所示。
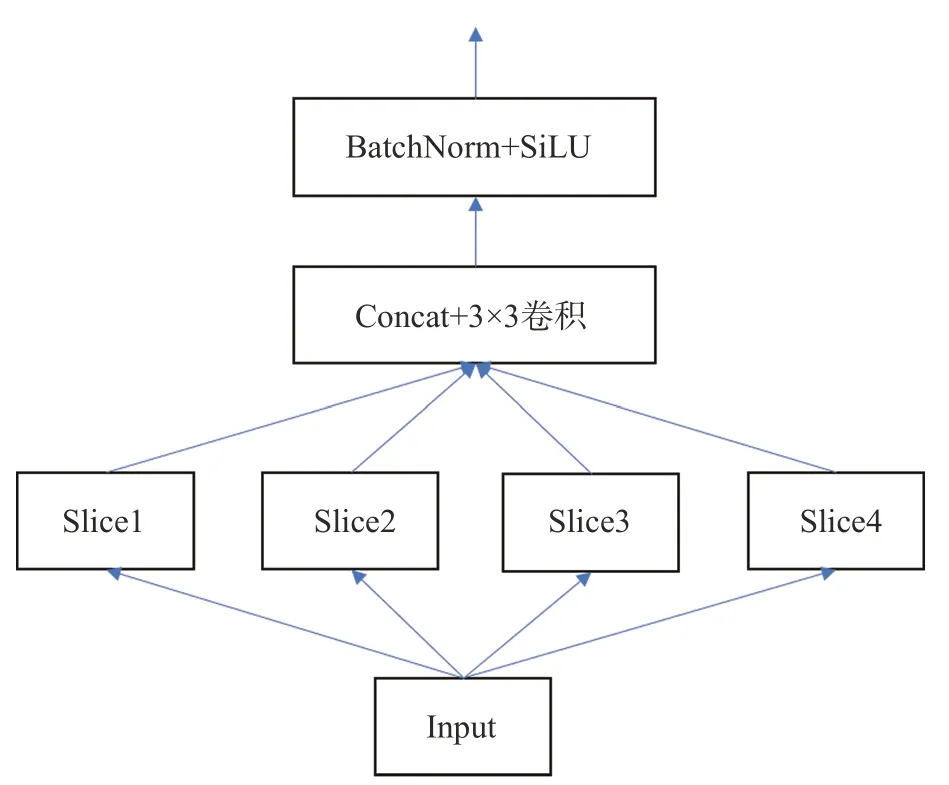
图2 Slice_CNN网络结构图Fig.2 Network structure diagram of Slice_CNN
输 入 图 像 数 据 大 小 为 batch_size×3×640×640,Slice_CNN算法步骤如下:
(1)第0维和第1维维数不变,将第2维和第3维进行切片操作后变成 4 份 [batch_size][3][320][320],4 份切片对应的计算规则见式(3),其中,i,j=1,1,2,3,…,319。
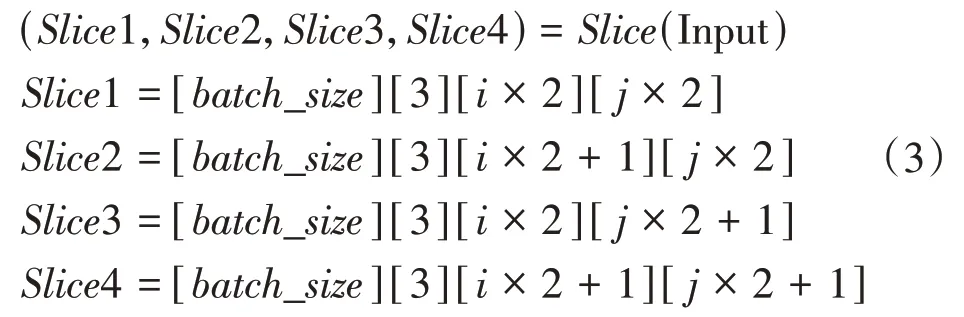
式中,Input 是尺寸为batch_size×3×640×640 的输入图像数据。
(2)对4 份切片数据进行Concat 操作后,依次经过3×3 卷积、BatchNorm、SiLU 激活函数,最后得到输出结果。
二级平台可作为景观带中的步道、活动广场等,其高程适宜选取略高于200年一遇潮位7.93m,以满足越浪自排的要求,同时应低于堤顶高程,以满足景观空间层次感及观海视线通透的要求,宜取8.0m~8.2m。二级平台即主要活动空间与亲水步道的衔接,则主要通过设置景观挡墙、阶梯、跌级花池、阶梯坐墙等多种形式来巧妙消除二者高差,丰富滨水景观。
1.3 多头自注意力模块
为了更好地获取图片数据的全局特征,使用全卷积神经网络可能需要堆积大量CNN,这虽然可提高模型的特征提取效果,但模型的计算速度降低,显然不是最优的选择。因此,可通过MHSA替换部分CNN以获得更好的效果。本研究使用MHSA 的头数量为4,其网络结构图如图3所示。
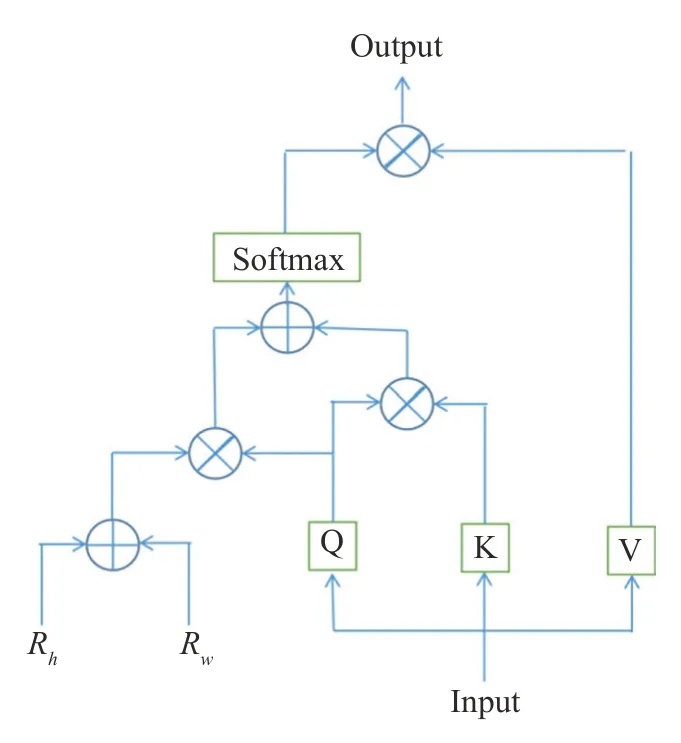
图3 MHSA网络结构图Fig.3 Network structure diagram of MHSA
图3中的Rw和Rh分别是特征图宽度和高度的位置编码,Q、K、V 分别表示查询、键和位置编码,⊕表示矩阵对应位置元素求和,⊗表示矩阵乘法。
1.4 多尺度特征融合网络层
高层特征图具有较大的感受野,而低层特征图具有较多的细节和局部信息。iYOLOv3模型的多尺度特征融合网络层结合了FPN 和PAN 特征融合网络的优点,先对多尺度特征自上而下进行特征融合(见图4(a)),而后对多尺度特征自下而上进行特征融合(见图4(b)),因此可更有效地促进不同尺度特征信息的流通和融合,从而更好地提取上下文信息。多尺度特征融合网络结构如图1中的特征融合层所示。
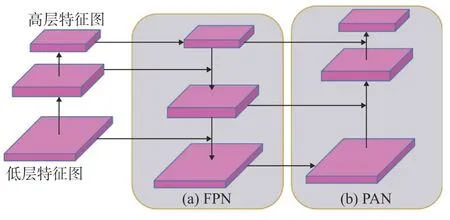
图4 特征融合过程图Fig.4 Diagram of feature fusion process
1.5 损失函数
边框回归的损失函数采用了GIoU_LOSS[23],GIoU的计算公式见式(4)。
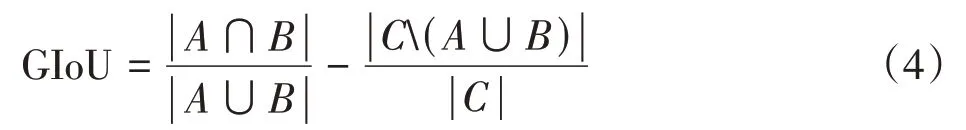
式中,A和B是 2 个待计算 GIoU 的矩形,C是矩形A和B的最小闭包。
计算Objectness 和计算分类的损失函数使用BCE⁃WithLogitsLoss 函数,将 Sigmoid 网络层和 BCELoss 合并成一层,同时使用log-sum-exp 来提高结果的稳定性,使得结果比使用单独的Sigmoid 和BCELoss 更加稳定。令BCEWithLogitsLoss 的计算函数为l(x,y),其计算公式见式(5)。

式中,N是batch_size。
1.6 激活函数
采用SiLU 函数作为网络的主要激活函数,其计算公式见式(6)。

2 实验坏境和数据集
实验软件环境为Win10、CUDA11.0,硬件环境GPU 是 NVIDIA GetForce RTX 2080Ti, CPU 是 i9-10900K CPU 3.70GHz。
实验数据集从江门某纸业公司采集而来,2531张训练图片,843 张测试图片。将包装缺陷类型分为以下5 类:①未包装(Class1),②包装后卷纸倒下(Class2),③包装正确(Class3),④侧部包装问题(Class4),⑤顶部包装问题(Class5)。
3 实验分析
首先对原始数据集的训练集进行数据增强,然后对模型进行训练,模型训练时的batch_size 设为16,一共训练了300个epoch,每个epoch训练完成后对测试集进行测试,保留训练过程中的模型权重文件。
3.1 数据增强
为了增强模型的鲁棒性,在训练数据前,采用随机数据增强的方法,随机对一些训练图像数据进行数据增强,图片对应的标签也根据相应的数据增强方法进行相应的调整。采用的数据增强方法如下:①左右翻转,②对比度、色彩饱和度、色调、锐度调整,③加入椒盐噪音、高斯噪音,④图像缩放。
3.2 训练策略
iYOLOv3算法通过随机梯度下降的方法对模型进行训练。对网络的不同网络层采用了不同的学习率进行训练:权重层使用lr1 学习率进行训练、偏置层使用lr2学习率进行训练、BN网络层和其他网络层使用lr0 学习率进行训练。模型在训练的前1000 个迭代采用warm-up 方法对模型的学习率进行预热,当训练时的迭代过程在warm-up 阶段,使用一维线性插值的方法进行学习率的更新。在warm-up 阶段后,使用余弦退火算法对学习率进行更新,其计算公式见式(7)。
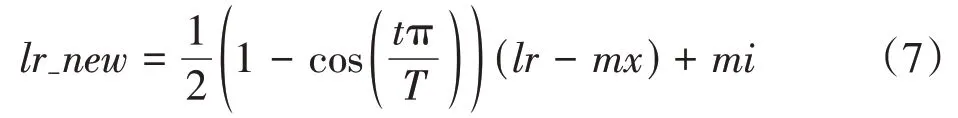
式中,lr_new是新的学习率,t是当前的epoch,T是总的epoch,mi是最小学习率,mx是最大学习率,lr是最初学习率。
3.3 实验和结果
iYOLOv3 算法训练过程中测试集中的准确率(P)、召回率(R)和AP@50∶5∶95(为通过计算具有10个不同IoU阈值(0.5,0.55,...,0.95)的AP的平均值)在不同epoch 的变化如图5 所示。1 个epoch表示完成1次全部训练集数据的训练。
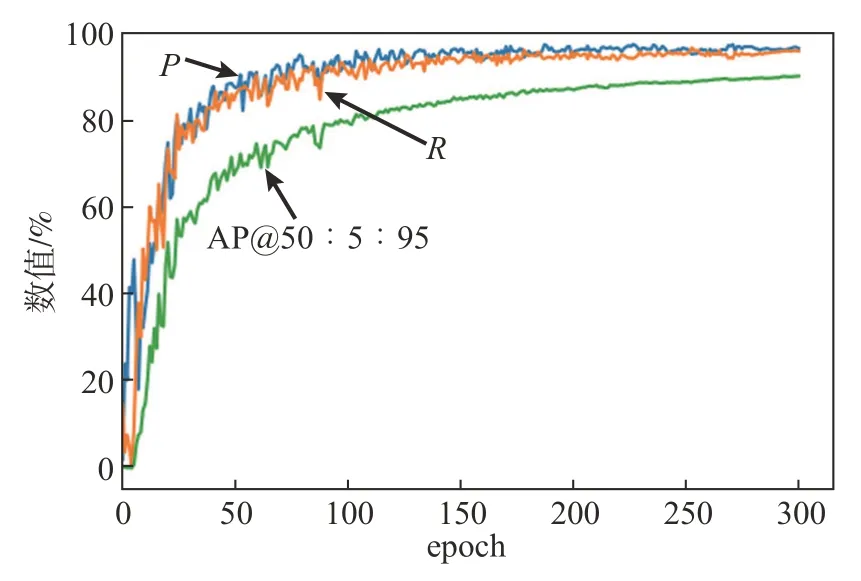
图5 iYOLOv3算法训练过程中P、R、AP@50∶5∶95变化图Fig.5 Variation of P,R,and AP@50∶5∶95 in the training process of iYOLOv3 algorithm
实验采用P、R、AP@50∶5∶95 和F1 作为评价iYOLOv3算法的性能指标,相对P、R、F1,AP@50∶5∶95 对于检测算法的测评更加全面,因为其同时评估了不同阈值时模型的分类和回归的能力。F1-置信度曲线可以很好地反映检测算法在不同置信度和F1的变化关系。将iYOLOv3 算法在测试集上进行测试,测试结果的F1-置信度曲线图如图6所示。
从图6 可以看出,在置信度较大时,Class1~Class5的F1值仍能够保持较高的水平。不同置信度对应的P和R均能较好地反映检测算法的性能[24]。为了更好地评价iYOLOv3 算法的性能,绘制了P-R曲线(见图7)。图7中,iYOLOv3算法的P在R较大时仍能保持较高水平,说明iYOLOv3算法具有很好的查准率和查全率。
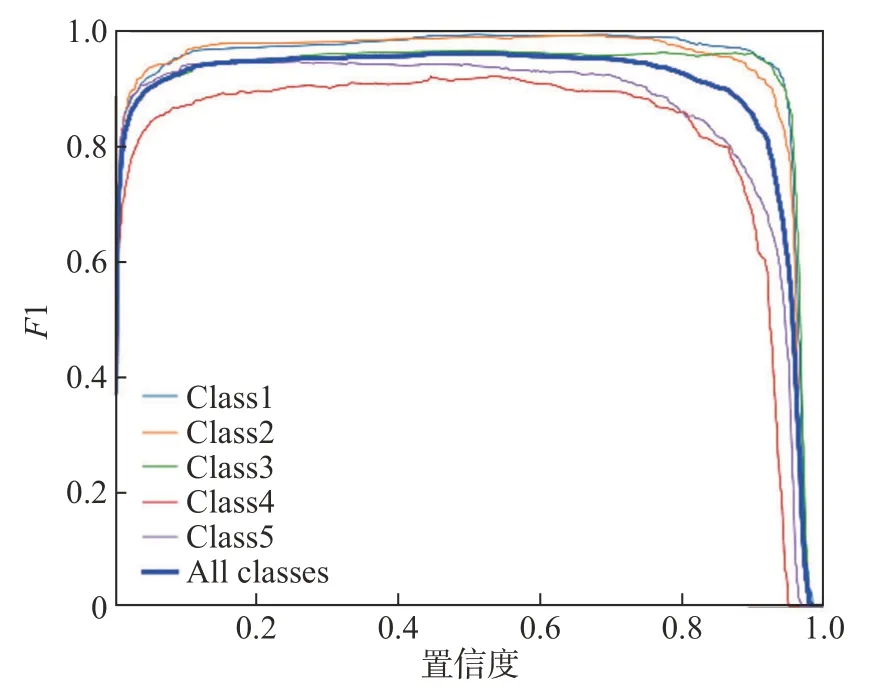
图6 iYOLOv3算法的F1-置信度曲线图Fig.6 F1-confidence curve of iYOLOv3 algorithm
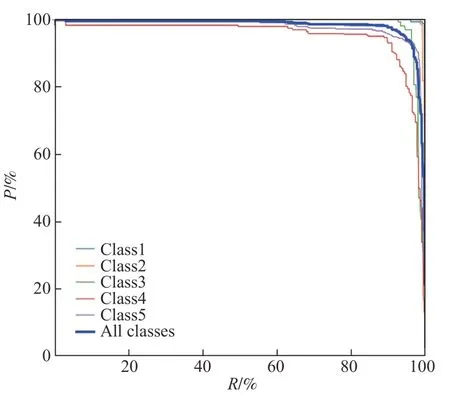
图7 iYOLOv3算法的P-R曲线图Fig.7 P-R curve of iYOLOv3 algorithm
利用训练至收敛后的iYOLOv3算法对卷纸包装缺陷Class1~Class5进行检测,结果如图8所示。
为了比较不同激活函数对iYOLOv3 算法的影响,将iYOLOv3 模型中的激活函数替换成其他激活函数,对修改后的模型进行训练,同时分别进行了测试,结果如表2所示。其中,P、R、AP@50∶5∶95和F1均是 Class1~Class5 的平均结果,P、R和F1 的 IoU 阈值为0.85,P、R和F1的计算公式分别见式(8)~式(10),FPS是算法检测速度,即每秒处理的图像数量(帧/s)。
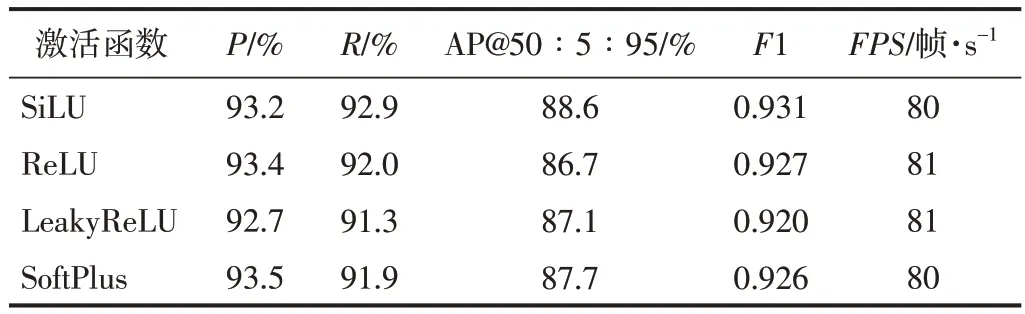
表2 不同激活函数的性能测试结果Table 2 Performance test results of different activation functions
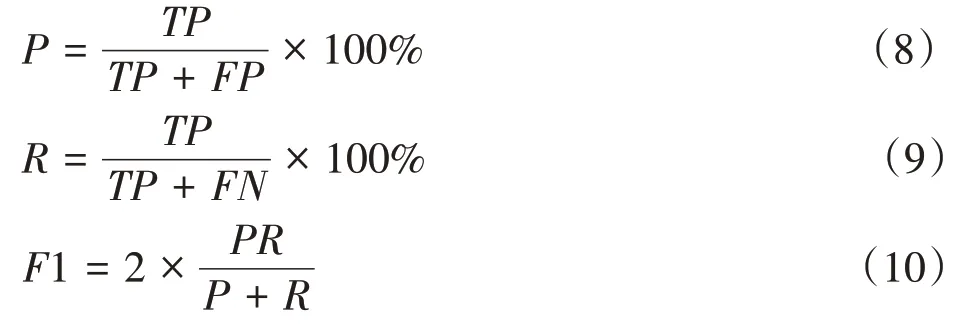
式中,TP(True Positives)是边界框被正确检测的个数,FP(False Positives)是不需要检测的目标被识别为检测目标的个数,FN(False Negatives)是没有被检测到的边界框的个数。
从表2可以看出,SiLU、ReLU、SoftPlus、Leaky⁃ReLU 激活函数对iYOLOv3 算法FPS的影响不大,但ReLU和SoftPlus激活函数对应测试结果的P比SiLU激活函数分别高0.2 个百分点和0.3 个百分点;而SiLU激活函数在R、AP@50∶5∶95 和F1 评价指标上表现出更好的效果。
为了比较不同算法的性能,将iYOLOv3 和YO⁃LOv3 (输入图片分辨率为 608×608)、Faster RCNN[25]和SSD300[26]进行了比较,结果如表 3 所示。其中,Faster R-CNN的骨架网络采用ResNet50[27],输入图片分辨率为600×600。
由表3 可知,相较于YOLOv3、Faster R-CNN 和SSD300,iYOLOv3 算 法在P、R、 AP@50∶5∶95、F1、FPS评价指标上都取得了更好的效果,尤其是FPS,相较于YOLOv3提高了2倍多。
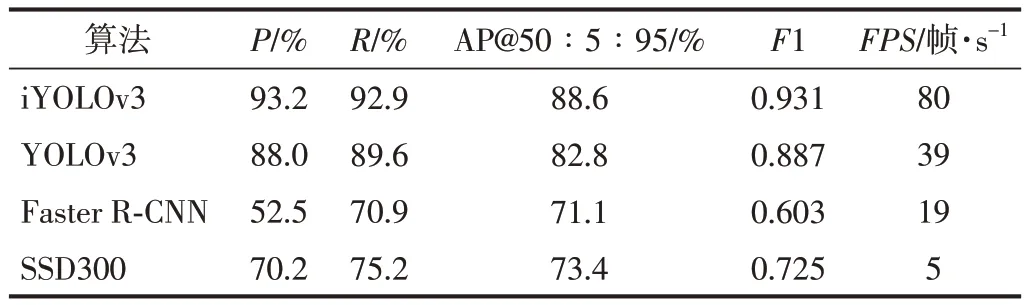
表3 不同检测算法的性能测试结果Table 3 Performance test results of different detection algorithms
4 结 论
针对卷纸包装图像信息具有很强的局部相关性和全局相关性,提出了一种改进的YOLOv3卷纸包装缺陷检测算法(iYOLOv3 算法)。iYOLOv3 算法在特征提取时将卷积神经网络与多头注意力机制结合,更加有利于提取卷纸包装图像数据的局部特征和全局特征;在进行多尺度特征融合时,将特征金字塔网络和路径聚合网络进行结合,更有效地提取卷纸包装数据的特征。此外,本研究采用了简单有效的SiLU 激活函数,改进了YOLOv3 算法预测框的公式和损失函数。实验分析结果表明,相对于YOLOv3 算法,iYO⁃LOv3算法在准确率、召回率、AP@50∶5∶95、F1及检测速度评价指标上都获得了更好的效果,可为流水线上卷纸包装的缺陷检测提供实时准确的检测。
