基于深度学习的驾驶行为识别模型线上训练系统设计与实现
2022-06-24刘永志
林 峰,刘永志
驾驶人员开车时因视线偏离或分心产生的注意力不集中是诱发车辆交通事故的主要原因之一[1].随着车载前后双路摄像头的普及,如何通过实时影像分析,识别司机使用手机、与乘客聊天等不安全驾驶行为并发出警报,已成为交通安全领域的研究热点.近年来随着人工智能技术的迅速发展和普及,基于多层次人工神经网络的深度学习算法,在自然语言处理、计算机视觉、数据挖掘等领域有着广泛的应用[2].利用深度学习技术,构建卷积神经网络模型,对车内监控图像进行分析并识别危险驾驶行为已被公认为是一种行之有效的解决方案.但在该方案中实施人员需要掌握深度学习相关理论知识,并具备较扎实的AI 程序设计和开发能力,具有一定的技术门槛[3-6].鉴于此,本文设计并实现了一套驾驶行为识别模型线上训练系统,通过简单的鼠标操作,使用人员即可快速创建和部署深度学习模型,用于车辆驾驶行为的识别和检测.
1 系统架构
系统整体为B/S 架构,如图1 所示.按层次结构主要分为数据存储层、功能模块层、用户接口层.其中:①数据存储层采用“SQLAlchemy+MySQL”的解决方案,借助SQLAlchemy 的ORM(Object Relational Mapping,对象关系映射)特性,可降低使用Python 编程语言访问MySQL数据库的开发难度;②功能模块层基于开源的Flask Web Framework及TensorFlow Deep Learning 库,提供了会话控制、模型训练、模型管理、模型测试及模型接口等功能;③用户接口层主要服务两类用户:一类用户为系统直接使用人员,依托Jinjia2 模板引擎及Amaze UI 前端工具开发的HTML5 页面,使用人员可“一站式”创建、训练、部署及测试深度学习模型;另一类用户为第三方平台,通过系统对外开放的Web 接口,第三方平台可编写简单的程序代码,间接使用系统提供的驾驶行为识别功能.通过分层设计,本文实现的系统代码结构清晰,各模块“高内聚、低耦合”,在一定程度上提高了系统的可扩展性和可维护性.
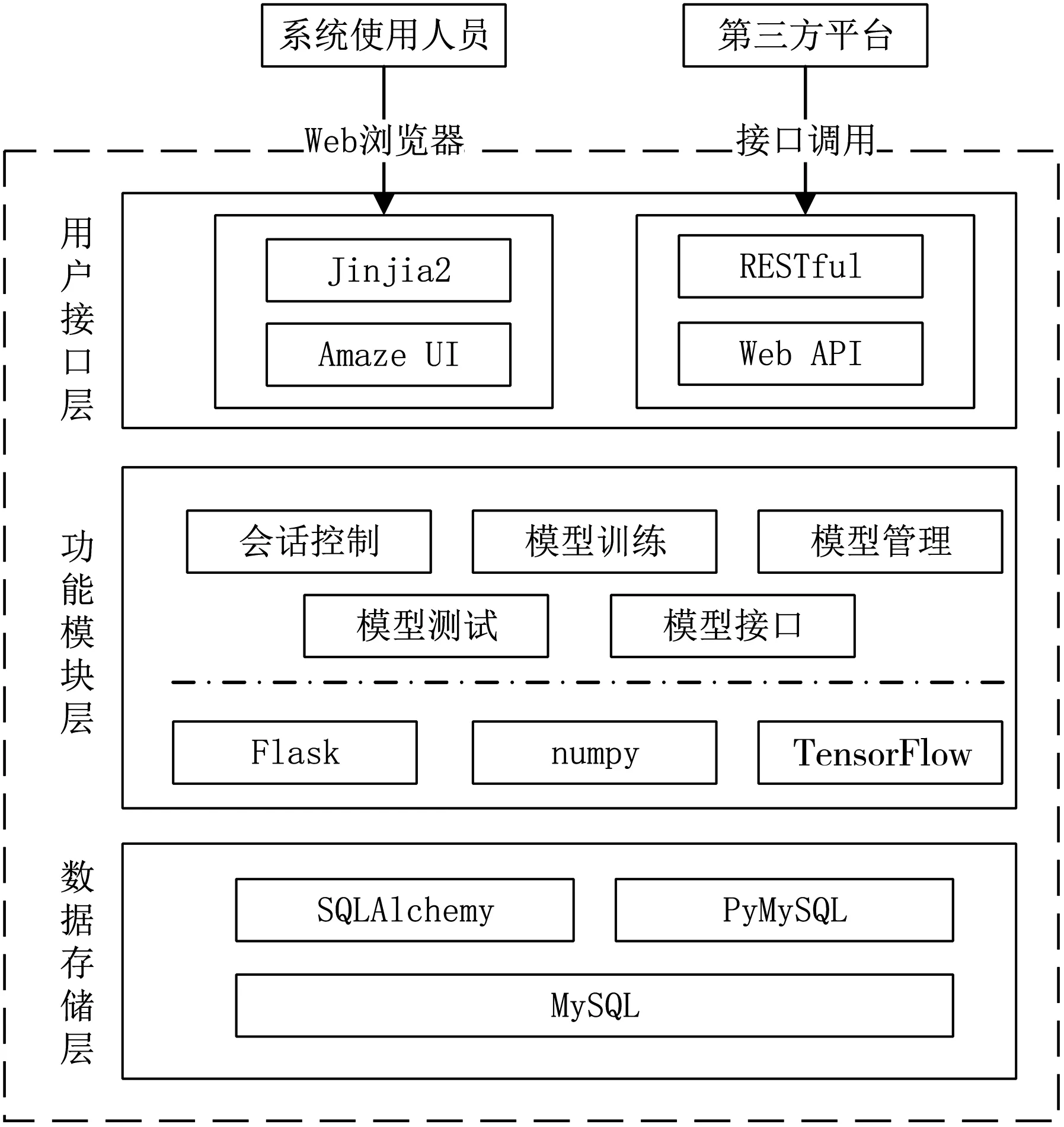
图1 系统架构
2 功能模块
2.1 会话控制模块
为了确保系统安全性,防止非法或未授权用户访问,系统利用Python 编程语言的函数装饰器特性,开发了用户登录检查装饰器login_wrapper.login_wrapper 可在系统运行时自动检查用户会话是否有效,若用户会话已失效可自动跳转到系统登录页面,规避了“URL地址泄露”等网站安全问题.装饰器login_wrapper 代码实现如下所示:

2.2 模型训练模块
模型训练模块是本系统的核心模块之一,为了降低使用门槛,提升用户感知,模型训练模块使用向导模式,分步骤引导用户,通过简单的鼠标操作,用户即可快速创建并训练用于驾驶行为识别的深度学习模型.该模块主要步骤包括:
(1)上传数据集.数据集为zip 压缩包文件形式,其中数据图像按所属类别放置于相应的目录下.系统接收到数据集后,调用zipfile 库解压缩,并进行必要的数据预处理操作,检测图片是否有效,清除图片文件中的EXIF 信息,确保数据集可用于TensorFlow 建模.本文所用测试数据集来源于国外Kaggle网站公开数据集——分心驾驶图像检测数据集(网址:https://www.kaggle.com/c/state-farmdistracted-driver-detection),训练图像样例如图2 所示.

图2 训练图像样例
(2)设置模型参数.该步骤涉及的建模参数包括:模型复杂度、验证集比例、图像批处理大小、训练周期.其中模型复杂度可选项为:简易、一般、复杂;验证集比例可选项为:0.1、0.2、0.3;图像批处理大小可选项为:16、32、64;训练周期可选项为:10、50、100.系统简化了传统深度学习建模中复杂的神经网络设计环节,将模型预设计为简易、一般及复杂三种类型.三种类型模型涉及的人工神经网络层数和结构具有较明显的差异,见表1.
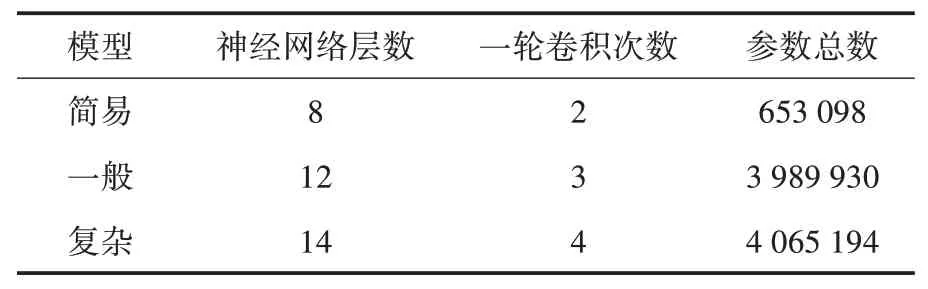
表1 三类预设计模型对比
“简易”模型网络层数少,训练耗时较短但模型识别准确度较“一般”及“复杂”模型低;“复杂”模型网络层数多,训练耗时较长但模型识别准确度较“简易”及“一般”模型高.三种预设计模型各有优势,用户可按需选择.此外“简易”模型详细结构见表2.
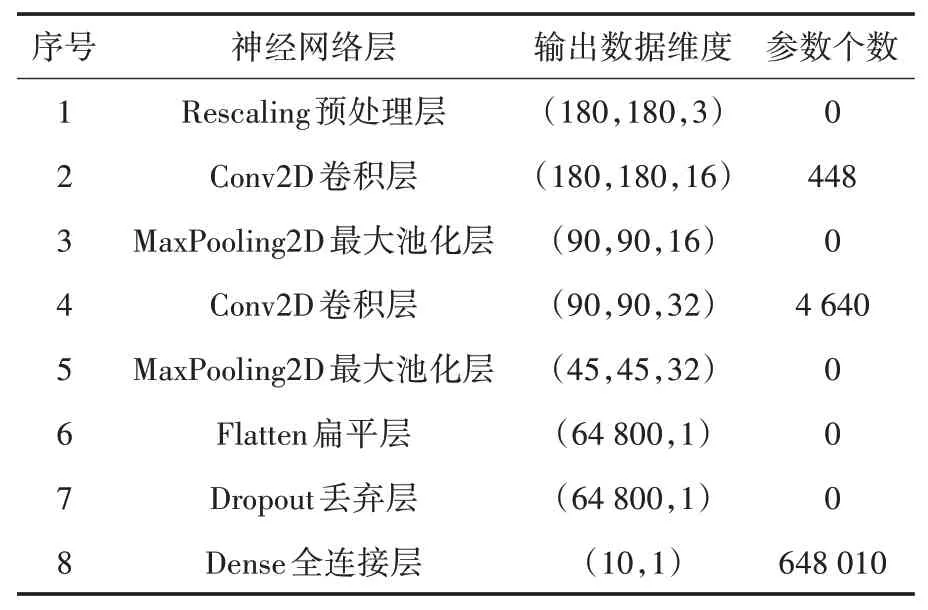
表2 “简易”模型结构
(3)模型创建及训练.用户完成数据集上传及参数设置后,即可“一键建模”.系统自动创建模型,定义模型损失函数为categorical_crossentropy,优化函数为adam,度量指标为accuracy,并调用方法tf.keras.preprocessing.image_dataset_from_directory 快速构建训练数据集及验证数据集.因训练模型通常需要消耗较长的时间,系统新建并启动专门的线程用于模型的训练,用户提交模型的创建及训练任务后即可关闭站点,待任务完成后,系统将主动告知.
2.3 模型管理模块
系统提供独立页面对多个模型进行统一管理,用户可直观查看系统所有线上模型信息,包括:模型ID、模型类型、训练开始时间、训练完成时间、训练周期、训练集准确度、验证集准确度和模型状态.其中模型状态被定义为四种:未训练、训练中、已完成、已部署.在模型管理模块中,用户还可进行模型删除及部署操作.其中处于训练中、已部署状态的模型无法被删除,未训练、训练中的模型无法被部署.如图3 所示,系统通过引入“模型状态”概念并限制状态迁移方向,提升了系统的稳定性,降低了出现BUG 的风险.
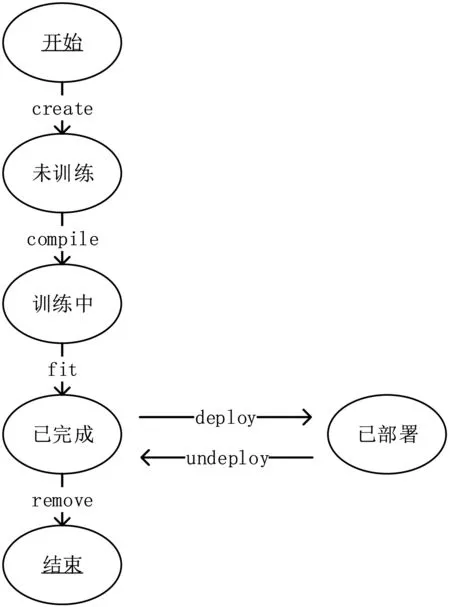
图3 模型状态迁移
2.4 模型测试模块
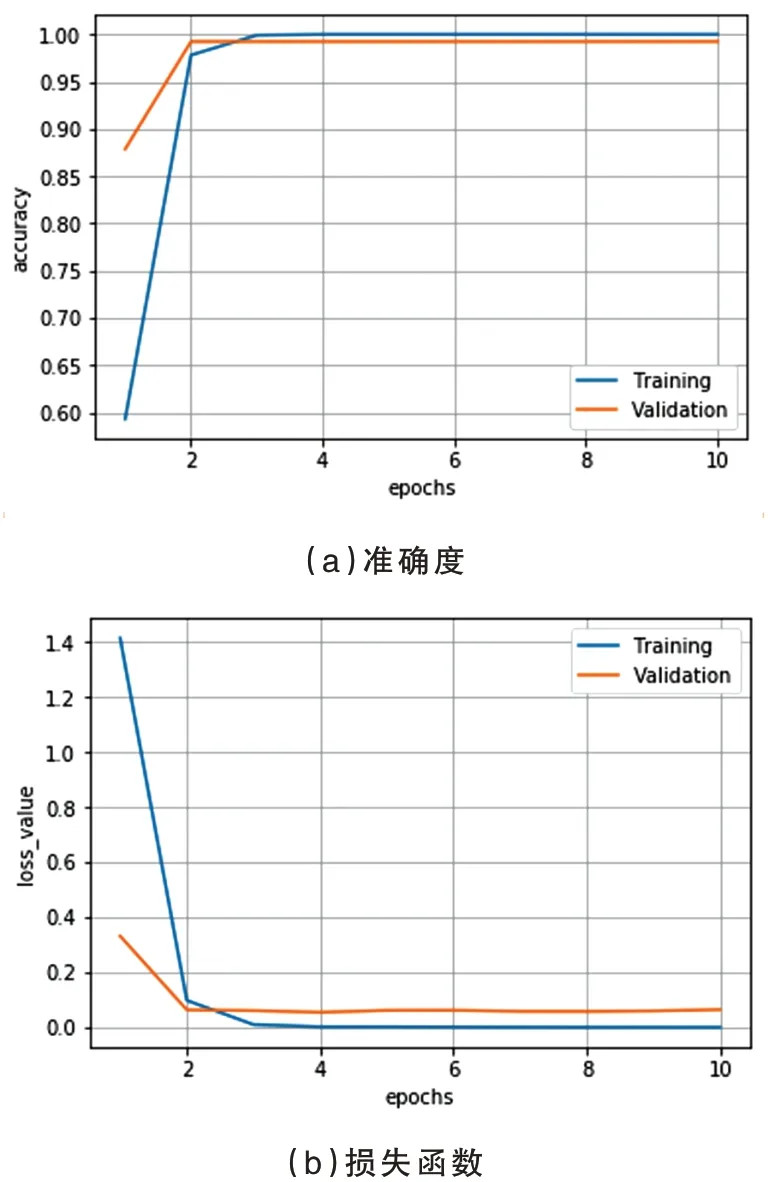
用户可在模型测试Web 页面中,上传车辆内部驾驶图片,对已部署的模型进行测试.为提升测试效率,通过对 图4 测试模型界面 系统提供在线接口功能,供外部第三方平台使用.第三方平台向系统接口predict_image_class 传递转换为Base64 编码的图片数据,即可获取该图片所属类别标签(class_name)及可能性(probability).使用Python 代码调用系统接口示例如下: 系统部署在百度智能云服务器(CPU:2.40 GHz,内存:2 GB,硬盘:40 GB,带宽:1 Mbps),操作系统环境为CentOS 7.4 64 位,主要Python库 及 版 本 信 息 为:Python 3.8.5、Flask 1.1.2、SQLAlchemy 1.3.20、PyMySQL 1.0.2、Jinjia 2.11.2、TensorFlow 2.4.1.基于Kaggle 数据集state-farmdistracted-driver-detection,制作了含safe-driving(安全驾驶)、drinking(饮水)、talking-topassenger(与乘客对话)等10 类驾驶行为的图像训练集,合计1 320 张,zip 压缩包文件大小为49 MB. 利用平台构建深度学习模型,其中模型复杂度为“简易”、验证集比例为0.2、图像批处理大小为32、训练周期为10,经过近8 分钟的训练时长,训练集准确度可达100%、验证集准确度可达99.24%,通过测试验证了系统功能的高可用性.其中模型准确度及损失函数收敛情况如图5 所示. 图5 准确度及损失函数收敛情况 为降低深度学习技术门槛,本文设计并实现了一套驾驶行为识别模型线上训练系统,在系统架构设计上,自底向上划分为数据存储层、功能模块层、用户接口层,通过合理分层提升了系统的可扩展性和可维护性;在核心功能模块开发上,通过预设计三类普适性深度学习模型,引入“模型状态”概念,设计状态迁移机制,提升用户使用感知,实现模型创建、训练、部署及测试“一站式”全流程功能;在对外接口服务实现上,开发基于Flask框架具有RESTful 风格的接口,第三方平台通过少量代码,即可使用系统提供的驾驶行为识别服务.通过测试,系统构建的模型收敛速度快,识别准确度高,未来具有较高的市场推广价值.后续计划引入GPU 计算模块或AI 专用芯片,进一步加快模型训练速度,提高系统模型构建并发数.
2.5 模型接口模块

3 系统测试
4 结语
