一种面向问答系统的多标签答案检索模型
2022-06-24李珊如周岩乔晓辉杨丹青王志刚
李珊如,周岩,乔晓辉,杨丹青,王志刚
(1.河北汉光重工有限责任公司,河北邯郸,056017;2.河北省双介质动力技术重点实验室,河北邯郸,056017)
0 引言
智能聊天机器人模仿人类的交流能力,使用对话系统技术[1-2]使机器与人类互动。基于不同行业的不同需求,聊天机器人的使用框架也不尽相同。一般来说,聊天机器人必须了解人类的意图,然后预测人类的行为,并做出相应的反应。
聊天机器人的日益普及也导致了这个研究方向在自然语言处理社区中成为热门课题。例如Facebook人工智能发布了他们最大的开放领域聊天机器人BlenderBot,并将其开源,它包含了更像人类的对话技能,如个性、同理心和常识识别等能力[3]。此外,像XiaoIce、Mitsuku和MILABOT这样的聊天机器人基于规则[1-2]、基于知识的[3-4]或基于检索的系统[5-6]的对话管理器来执行类人的属性。尽管这种对话机器人在过去几年中取得了显著的进步,但在对话系统中,距离人类水平的智能还有很长的路要走。在实际应用中,局限于特定知识库的面向任务的对话系统更为常用。通过与开放域代理集成,构建具有更自然和域外响应的面向任务的聊天机器人更有意义且更合理。除此之外,问答系统[4,10,2]是聊天机器人的核心部件,它需要自动地从检索到的文档中获取用户询问的答案。
在本文中,我们提出的模型包括一个了基于注意力的五层编码器和一个基于标签的解码器。具体来说,我们首先将上下文和用户查询数据分别提供给字符级和词级的嵌入层。双向长短时记忆网络(BiLSTM)将应用于嵌入层的顶部,这是对循环神经网络(RNN)的一种改进。BiLSTM的优点是可以在存储单元中获取过去的信息。具体来说,我们使用sigmoid函数来确定保留信息的比例,以及需要忘记信息的比例,并使用它来决定RNN的输出。在第四层,双向注意力层将上下文向量和用户查询向量连接起来,产生查询感知的表示向量。双向注意机制是指我们使用context2query和query2context的注意力机制来最小化训练过程中的语义信息损失。建模层再次利用了BiLSTM对输入文本进行语义和位置信息建模。为了获得更高的预测精度,输出层采用了基于标记的解码器。
同时,受到文献[9]的启发,我们将文档中的每个词标记为二进制分类,以确定答案的起始和结束位置。在我们的模型中,我们使用指针网络[10],根据输入数据计算输出的条件概率。我们的任务是仅从给定的上下文查找标记,并从原始上下文使用标记生成答案,在这种情况下,将指针网络用于我们的任务是一个潜在的理想方案。
1 相关工作
Amrita Saha等人[1]引入了复杂顺序问答(CSQA)系统,该系统将问答和对话结合在一起,因此,它可以学习在大规模知识图的基础上通过一系列连贯的问题进行聊天。但这个系统在复杂问题上有局限性。为了解决这一问题,作者探索了推理聚合或逻辑函数以及能够解析复杂问题的更有效的编码器。在处理间接问题时,可以利用显性的监督注意力机制。
Sen Hu等人[2]提出了一种状态转换框架,将复杂的自然语言问题转换为语义查询图,并通过知识图将问题的答案与查询图匹配,以解决目前在回答复杂问题时存在的局限性。具体来说,首先,作者从问题中识别出实体和变量等节点作为初始状态。其次,他们提出了连接、合并、扩展和折叠原语操作的条件,以促进状态转换过程。再次,利用所提出的MCCNN模型提取实体和关系。最后,利用支持向量机排序的奖励函数进行状态转换,选择下一个状态。实验结果表明,他们的框架比现有的方法在复杂问题上表现更好。但是,在使用折叠操作时,有时会出现一些结构失效、实体链接失效、关系提取失效、复杂聚合问题性能低下等问题。
Anusri Pampari等人[3]提出了一种在特定领域和大规模生成问答数据集的方法。该方法将专家现有的注释用于其他NLP任务。它们为第一个具有大规模的问答对和问题-逻辑形式对的患者特定电子医疗记录(EMR) 问答数据集做出了贡献,允许用相应的逻辑形式验证答案。研究表明,具有符号表示的逻辑形式有助于语料库的生成。未来的工作可能是使用原始实体的词汇变体来生成问题-逻辑形式,更多的多重句子推理问题和生成没有内容相关实体的问题。
Lisa Bauer等人[4]提出了一个问答系统框架,该框架可以有效地执行多跳推理,并使用双向注意和指针发生器解码器产生准确和一致的答案。他们还提出了一种算法,可以利用常识知识填补问答系统推理的空白。
Xinya Du和Claire Cardie[6]研究了一种利用共指信息训练问题生成系统的方法。为了更好地编码用于段落级问题生成的语言知识,他们提出了用于神经问题生成的门控关联知识(CorefNQG)。对于问题生成,该生成器将文本输入作为位置特征嵌入、答案特征嵌入和词嵌入的连接。

图1 模型结构与流程
2 模型与方法
■ 2.1 总览
我们的模型是一个分层的多阶段结构,其中包括了基于注意力机制的编码器和基于标签的解码器。作为一种层次结构,我们的注意力编码器首先将输入上下文和用户问题用字符级卷积神经网络映射每个字符到一个字符向量。然后,我们通过预先训练的词嵌入模型将每个单词映射到一个词向量。在上下文嵌入层,我们通过BiLSTM网络获取每个给定单词的上下文表示。之后,在注意力流层,模型可以同时获取上下文和用户提问向量,并将它们转换为每个单词的问题感知特征向量。在模型编码器部分,首先是建模层,该层部署了一个BiLSTM来进一步提取高级语义特征,并将相应的输出作为基于标签的解码器的输入,用于我们答案范围的预测。
■ 2.2 基于注意力机制的编码器
(1)字符嵌入层。利用神经网络将每个单词的字符嵌入到高维向量空间中。其中输入文本是一维的,输出是固定大小的向量。输入上下文的表示形式是{c1,c2,… ,cT}和{q1,q2,… ,qJ}用于输入用户问题。

(2) 词嵌入层。使用预先训练好的向量进行词级嵌入。
(3) 上下文嵌入层。取C表示上下文的d维向量序列,Q表示查询的d维向量序列作为该层的输入,是以前两层公路网的输出。由于我们生成上下文词向量F和查询词向量来服务于下一个双向注意层,所以在它们的顶部使用了两个LSTM。
(4) 双向注意力层。通过将C和S作为输入上下文标记和输出上下文标记作为查询感知向量W来实现双向注意力机制。这种注意力机制使用Softmax计算权重 w =softmax ((maxcol(S) )∈RT,从而确定用户问题和上下文之间的最高概率的单词,生成新的用户问题向量和上下文向量。
(5) 建模层。使用W作为输入。使用双向LSTM,输出发送到解码器进行最终的答案预测。
■ 2.3 基于标签的解码器
基于标签的解码器旨在提取上下文中的文本跨度作为我们的预测答案。传统上,以往的工作[5]主要把这个问题看作是整个上下文范围内的多分类任务,模型需要预测上下文概率分布上的开始和结束索引。在我们的工作中,我们提出了一种新颖的方法,将该问题重新建模为多个二元分类任务,并对给定上下文的每个单词施加一个分类器。
为了实现这一点,给定上下文中的一个单词,我们使用一个指针网络[10]来预测当前令牌是否属于开始索引。类似地,我们建立了一个相同的二进制分类器来预测当前标记是否属于结束索引。具体来说,给定基于注意的编码器建模层的输M,我们通过以下公式计算每个单词的概率:

其中pi
start和piend表示上下文中预测第i个单词的概率作为答案文本的开始和结束位置。如果概率超过某个阈值,则将相应的标记赋值为标记1,同样,如果没有,则将标记赋值为0。通常,我们将阈值设置为0.5。im是来自建模层的第i个单词的上下文表示。W为可训练权矩阵,b为偏置矩阵。
如上所述,不难推测我们的模型是通过交叉熵损失函数进行训练优化的。具体来说,该模型优化下方的似然函数来识别给定上下文表示C和查询表示Q的预测答案S的范围。
3 实验
■ 3.1 数据集
我们在SQuAD数据集[9]上评估我们的模型,SQUAD是阅读理解和问答系统的常用研究性数据集,由超过10万对问题和答案组成,这些问题和答案是通过在500多篇维基百科文章上的众包手工创建的。每个问题的答案都在相应的文章中,以一段文本[9]的形式出现。创建这个数据集的目的是让机器能够读取上下文并相应地回答问题。
■ 3.2 模型细节
我们的模型的参数设置基本上与基线模型[9]一致,这样保证了效果对比的公平性。如表1所示,我们将CNN LSTM的隐层大小设为100。词嵌入维度为100。训练集以0.5学习率进行学习,并训练64个轮次。我们使用AdaDelta[2]进行优化。在训练过程中,保持模型各权重的移动平均,并设定指数衰减率为0.999。在环境配置方面,我们使用一个特斯拉P100 GPU对模型进行了大约8小时的训练。另外,我们的操作系统是Linux Ubuntu 16.04, Python版本是3.6。

表1 模型细节与实验设置
■ 3.3 实验结果
值得注意的是,在我们的实验中,所有的基线都是单一模型,而不是集成模型。由表2所示,由于缺乏处理高维语义特征的能力,朴素机器学习方法,即逻辑回归获得了最低的性能。其他基线模型在EM和F1-score指标方面实现了差不多的实验结果。先前的最先进的基线模型BiDAF,获得了68.0 EM和77.3 F1-score。我们的模型分别优于BiDAF的0.5 EM和0.5 F1-score,这有力地证明了我们的模型的有效性。我们的模型取得较好性能的原因是多个二进制分类器能够在更细粒度的层次上区分特征多样性。

表2 在SQUAD数据上的实验结果

BiDAF 68.0 77.3我们的模型 68.9 78.0
4 分析与验证
■ 4.1 不同的阈值设置
我们在0.3~0.7的范围内选择阈值。从表3可以看出,当阈值设置为0.5时,模型的效果最好。说明训练样本相对均衡。
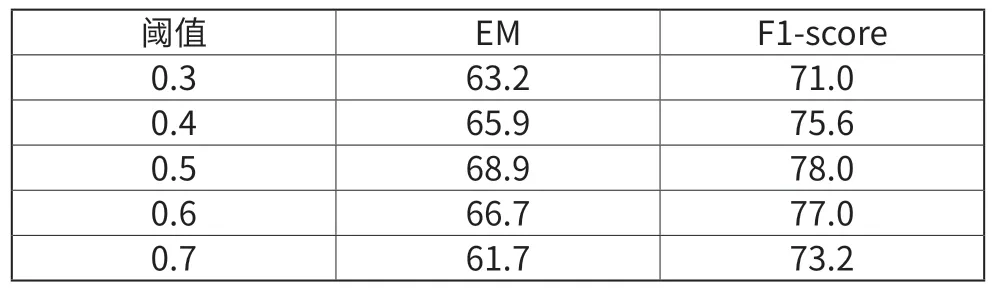
表3 不同阈值设定下模型结果
■ 4.2 超参数微调
我们选取了几个超参数用于模型微调。具体地,我们选择了不同的LSTM隐层大小和学习率进行参数优化。如表4所示,当LSTM隐层大小为256,学习率为0.5时,模型得到了最先进的结果,这与基线模型的结果一致。

表4 超参数微调
5 结语
本文旨在通过对现有方法的探索和改进来提供问答系统的性能。本文首先从现有文献中列举了一些基线框架作为相关工作。之后我们提出了一个多标签解码器,这是我们的框架的基本结构。基于编码器-解码器模型的改进可能是未来研究中提高性能的一个有前景的方向。在SQUAD数据上的实验结果验证了我们模型的有效性。
