基于深度交互融合网络的多跳机器阅读理解
2022-06-21朱斯琪王业相
朱斯琪,过 弋,2,3,王业相
(1. 华东理工大学 信息科学与工程学院,上海 200237;2. 大数据流通与交易技术国家工程实验室-商业智能与可视化研究中心,上海 200237;3. 上海大数据与互联网受众工程技术研究中心,上海 200072)
0 引言
近年来,随着互联网中新闻、电商等平台海量文本数据的产生,如何更好地理解文本从而提高机器的智能化水平,已经吸引了不少国内外学者的关注,而教会机器理解人类的语言也是目前自然语言处理领域最大的挑战之一。机器阅读理解,旨在让机器通过指定的上下文来回答问题从而实现对自然语言文本的理解。SQuAD[1-2]、RACE[3]、CoQA[4]、DuReader[5]等数据集的提出,使得模型在单跳机器阅读理解任务上的性能逐步提升,然而这些模型仍缺少在不同段落中寻找线索和聚集信息的能力。
与单跳机器阅读理解相比,多跳机器阅读理解需要从多个段落提及的实体中找到潜在的内部链接关系,提取与问题相关的线索,并对信息进行融合与分析,从而得到最终的答案。因此,多跳机器阅读理解是一项更具有挑战性的任务。目前,已经发布的多跳MRC数据集有Wikihop[6],ComplexWeb-Questions[7],HotpotQA[8]等。
本文实验基于HotpotQA数据集,数据样例如表1所示。该数据集每个样例包含1个问题与10个段落,其中仅有两个段落与问题相关,而其他8个段落与问题无关。它不仅需要模型从10个段落中筛选出与问题相关的两个段落,而且还要求模型能够在选出的两个段落中进行推理,从而获得问题的答案。此外,由于该数据集不依赖于外部的知识,因此需要模型泛化能力强,这为开放领域的问答打下了坚实的基础。

表1 HotpotQA数据集的数据样例
目前,为了解决多跳推理机器阅读理解任务,主要有三类研究方向。
(1)图神经网络: 将文本中的实体以及其他信息构建为实体图,并通过GCN、GAT等模型对包含链接的实体表示进行更新,从而得到答案。该方法虽具备一定的可解释性,但实体识别工具的不准确性会对该类模型造成一定的干扰,且当答案不是实体时,模型很难给出正确答案。
(2)多跳转单跳: 将多跳问题转化为单跳问题,再对每一个单跳问题用传统的机器阅读理解模型进行回答。此类模型的缺点是在问题分解时缺少标注样本,极大地限制了模型的性能。
(3)当作单跳问题: 预训练模型的强大性能使得部分研究人员将多跳推理问答任务当作简单的单跳任务输入到预训练模型中进行训练,该方法虽然性能较好,但由于受到预训练文本长度的限制,无法同时具备多个段落的视野,以至于此类模型不论是在段落筛选时还是在问答时,都缺少跨段落文本之间的交互。
为了解决上述模型的不足,本文提出了一种跨段落信息深度交互融合的网络结构来加强段落-段落、问题-段落之间的交互。首先,通过对多个段落信息的交互融合,筛选出10个段落中与问题相关的两个段落,降低干扰项段落对模型性能的影响。进而将筛选出的两个“黄金段落”的信息进行交互与融合,这也是目前的工作所忽略的内容。最后,问题与段落通过传统机器阅读理解模型进行交互融合,并通过答案预测模块得到最终答案。
本文的贡献总结如下:
(1) 提出了一种多段落信息融合的思想,可有效地在段落筛选模块和答案选择模块发挥其优势,实现多跳推理任务中的多信息交互,提升模型性能。
(2) 针对段落选择模块设计了一个跨段落的交互架构。以往模型大多仅计算多个文本之间的相似性得分,而本文将一个完整的段落表示当作一个单独的向量,并利用多层自注意力机制实现不同段落间信息的交互融合,从而筛选出与问题相关的段落。
(3) 针对段落信息融合模块设计了一个信息融合网络,可以解决在预训练模型中由于文本长度过长而产生的限制。此外,该网络可适用性强,可以处理超过两个段落以上的文本内容。
(4) 在HotpotQA数据集上对提出的方法进行评测,结果表明,仅使用基础版本的预训练模型就可以在干扰项赛道实现较好的结果,与基准模型相比,精确匹配(EM)提升18.5%,F1值提升18.47%,性能仅次于HGN[9]模型。
1 相关工作
随着SQUAD[1-2]、RACE[3]、CoQA[4]、DuReader[5]等阅读理解数据集的提出,机器阅读理解领域发展迅猛,特别是在基于大规模数据BERT[10]、RoBERTa[11]、AlBERT[12]等预训练模型产生后,机器阅读理解进入了一个全新的时代。而以Wikihop[6]、ComplexWebQuestions[7]、HotpotQA[8]为代表的多跳推理阅读理解数据集则为自然语言处理领域提供了一个更具有挑战意义的任务。
现有的研究工作已经在多跳机器阅读理解任务中发挥了传统机器阅读理解的作用。例如,Sewon等[13]和Perez等[14]将多跳问题分解为多个子问题,进而利用传统单跳机器阅读理解方法来解决多跳推理问题。Nishida等[15]将抽取线索当作一个基于问题的文本摘要任务,并在每一跳时更新问题的表示。
而Tu等[16]、Groeneveld[17]等、Sewon等[18]以及Shao等[19]则通过传统的TF-IDF方法或对预训练模型进行微调来计算问题与10个段落的相似性程度从而获得与问题相关的“黄金段落”,进而通过BERT[10]或RoBerta[11]等预训练模型得到问题的答案。而Jiang等人[20]则设计了三个模块动态地实现不同类型的推理。然而,不论是在检索黄金段落时还是在回答问题时,很少有研究工作关注到多个段落之间的交互。
除了上述工作,研究人员同时也发现了图神经网络在多跳问答领域发挥的作用。Dhingra等[21]、Ming等[22]、Ming等[23]、Nicola等[24]均通过spacy及Stanford corenlp工具包[25]等命名实体识别工具识别上下文中的实体,从而构建一张实体图,并通过GCN[26]、GAT[27]或者它们的变体在构建的整张图上进行推理。
此外,DFGN[28]设计了一个融合层来动态地探究每一个推理步的子图并通过动态掩码来选择合适的子图。然而并不是所有的问题都是由实体组成的,因此,单纯地将文本中的实体当作图结点对模型的性能产生了一定的限制。为解决此问题,HGN[9]利用不同细粒度的异构节点信息创建了一个层级图结构,从而实现HotpotQA数据集中不同类型的任务。而SAE[16]则在构建图的时候,将每个句子当作一个结点而不是将实体当结结点。然而Shao等[19]通过实验证明,在多跳问答中,一个经过良好调整的预训练模型可以完全替代图神经网络。因此,本文不采用图神经网络方法实现段落筛选与答案选择。
2 模型结构
本文所提出模型的整体结构如图1所示,模型主要包括段落筛选模块、文本编码模块、段落-段落信息融合模块、问题-文本注意力交互模块以及答案选择5个模块。下文将给出每个模块细节的详细描述。
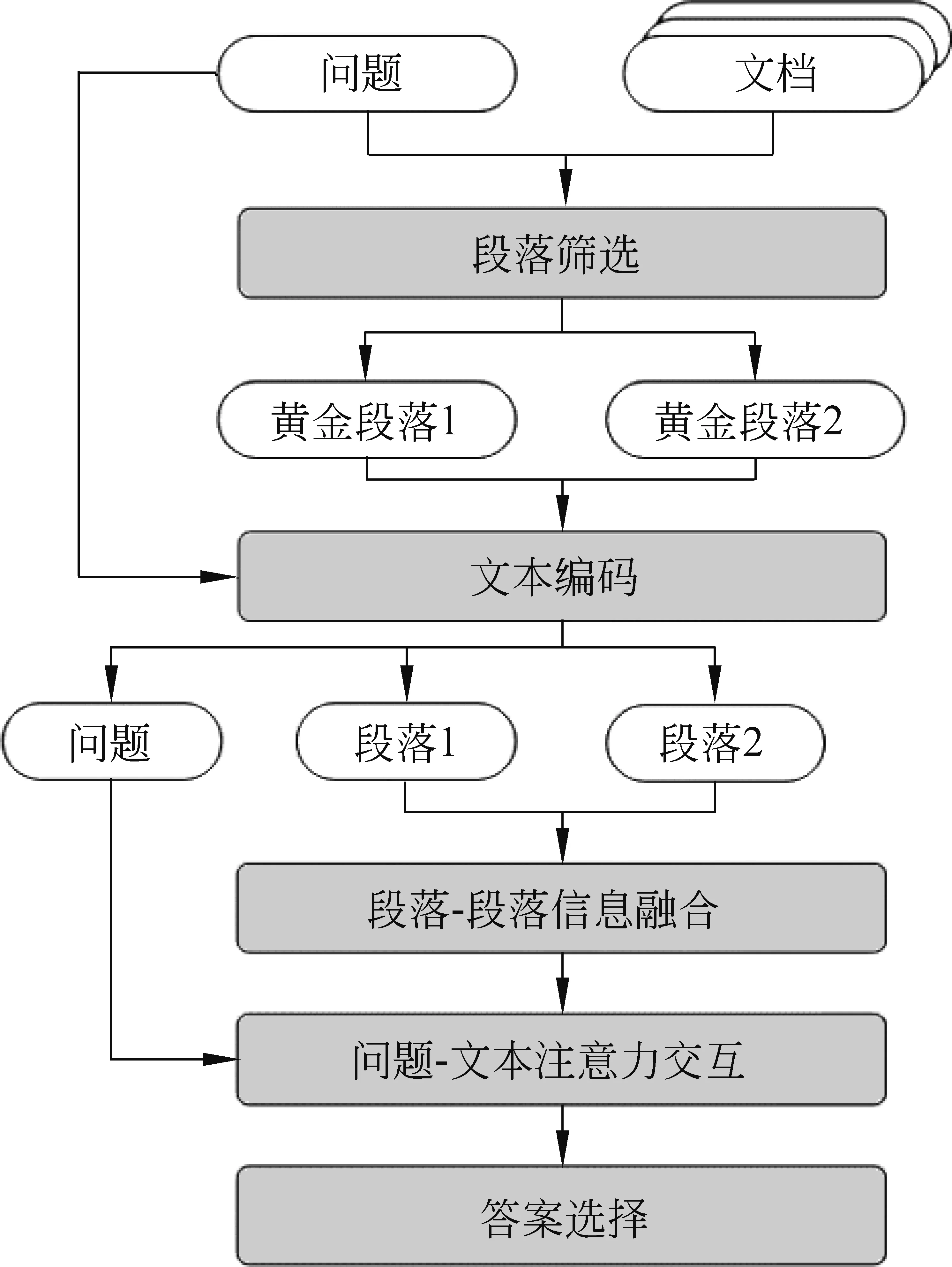
图1 模型整体结构
2.1 段落筛选模块
在HotpotQA数据集中,每个样例由一个问题q与10个段落p1,p2,…,p10组成,然而并不是10个段落均对回答问题有所帮助,因此需要将与问题有关的段落筛选出来,避免对模型造成干扰。目前,筛选“黄金段落”的研究工作[19,28]仅仅计算问题和单个段落之间的相似性分数,而忽略了一个段落对另一个段落产生的影响,因此我们针对这个问题设计了一个新的模型,模型结构如图2所示。

图2 段落筛选模块模型结构
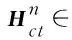
(1)其中,Wc、Wd、Wg是可调节的参数,Ql、Kl、Vl是Xl的线性映射,l是自注意力的第l层,Hl是第l层中融合了其他9个段落信息的上下文表示,Hl也被定义为l+1层的输入Xl+1。最后一层的隐藏层状态被定义为多层自注意力模块的输出Hsa。最后,将段落选择任务当作多标签分类问题,从10个段落中直接选择两个段落,交叉熵损失函数被定义如式(2)所示。
(2)其中,P(yi)是第i个段落是黄金段落的概率,ai表示第i个段落的标签,如图3所示,如果段落筛选模块的输出是(0,0,1,0,0,0,0,0,1,0),则认为第3个和第9个段落是与问题相关的段落。2.2 文本编码模块在上个模块里,对于每个样例,我们获得段落m和段落n。接下来,分别对段落m和n构建特征"yesno"+para+"",并分别输入到RoBerta模型中。本实验针对需要用“yes”和“no”回答的问题,我们在输入的特征中添加了“yes”和“no”两个单词,而不是像以往的模型那样将其作为一个分类任务。接下来,模型分别输出段落m和段落n的文本编码Hm∈lsm×h以及Hn∈lsn×h,其中,lsm和lsn分别表示段落m和段落n的序列长度。2.3 段落-段落信息融合模块目前,已有的工作[16,19]仅将选择出来的段落通过一个预训练模型和线性层得到答案的开始位置和结束位置,然而,大部分的预训练模型都受到文本长度的限制,尽管应用了滑动窗口的方法来解决文本过长的问题,但是对于多个段落来说,一个段落前面的文本和另外一个段落尾部的文本仍然没有办法拥有互相的视野。为了解决这个问题,本实验设计了一个段落-段落信息融合模块。首先,将上一个模块的输出Hm分为lq×h和lm×h,Hn也同样被分为lq×h和ln×h。其中,lq、lm和ln分别为问题的最大长度,段落m的长度以及段落n的长度。接下来,为了融合段落m和段落n所包含的信息,本实验采用交叉注意力机制来生成包含另一个段落信息的段落表示。与自注意力机制[29]不同的是,我们定义的线性映射是的线性映射分别是Kn和Vn。然后,将Qm,Kn,Vn输入到交叉注意力机制层中从而获得深度交互融合的段落信息表示,具体方式与式(1)类似。此外,这里使用了多头注意力机制,定义如式(3)所示。


图3 问答模块模型结构
(4)此外,本文设计了一个问题-文本注意力交互模块来加强每个问题-段落对的双向注意力流的交互。首先,与Seo[31]的工作类似计算问题编码Q和段落编码C之间的相似度矩阵S∈(lm+ln)×lq,如式(5)所示。
(5)其中,Ci和Qj分别表示段落文本的第i个字符表示和问题的第j个字符表示,“⊙”表示矩阵对应元素相乘。
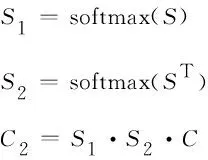

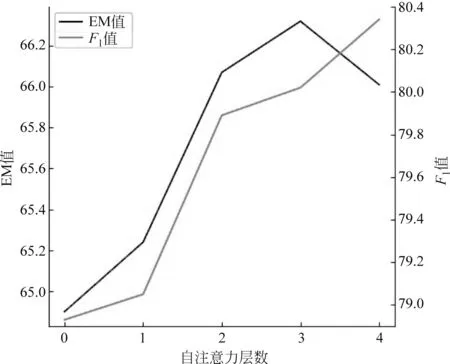
图4 自注意力网络层数对答案选择性能的影响

图5 自注意力层数对答案选择EM及F1的影响
3.2 实验结果表2中列举了在干扰项赛道公开发布的模型性能。可以看出,本文提出的模型仅通过base版本就已经实现了具有竞争力的效果,EM超过基准模型18.5%,F1值超过基准模型18.47%。

表2 实验结果 (单位: %)
3.3 消融实验
为了更好地验证本文所提出的模型的性能,本文进行了段落筛选模块、答案选择模块的消融实验。
首先,对段落筛选模块进行消融实验,指标仅选择精确匹配(EM),结果如表3所示。本文提出的段落筛选模型精确匹配率为93.32%,当去掉平均池化层后EM为93.07%;当去掉一层自注意力层后,EM为92.00%,而去掉两层自注意力层后EM为87.28%,如表3所示。由此可见,增加段落信息之间的交互对选择合适的“黄金段落”有益。此外,将段落表示从768维降为1维的平均池化层也为模型的性能带来了提升。
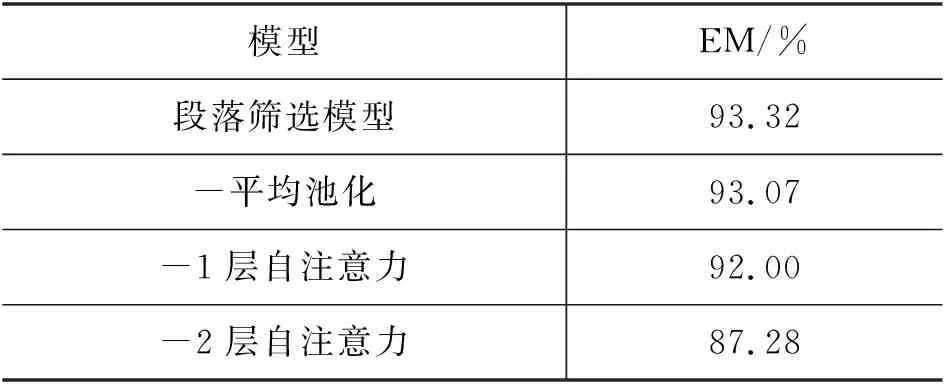
表3 段落筛选模块消融实验
接下来,对答案选择模块进行消融实验,结果如表4所示。为了模型性能不受到段落筛选模块的影响,此处仅使用“黄金段落”作为输入来验证答案选择模块的性能。从表4中看出,段落-文本信息融合模块与问题-文本注意力交互模块均在一定程度上提升了模型性能。
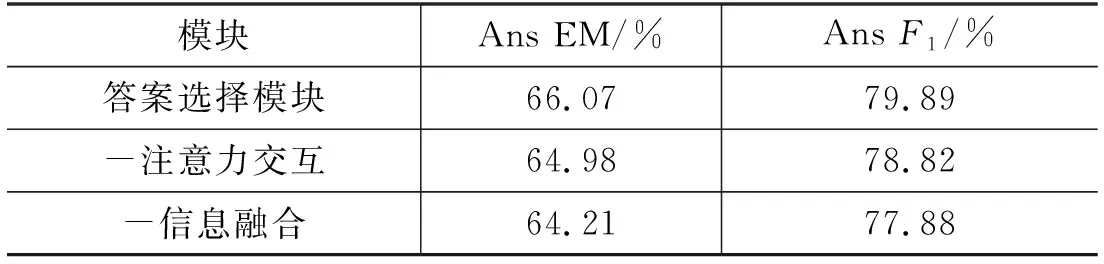
表4 答案选择模块消融实验
此外,通过采用不同的问题-文本注意力交互方法: AOA[36]、BiDAF[31]、交叉注意力[29],来证明本文实验所采用的模型性能优异。为了方便比较,将RoBerta-base模型以及段落-文本信息融合作为基准模型,实验结果如表5所示。
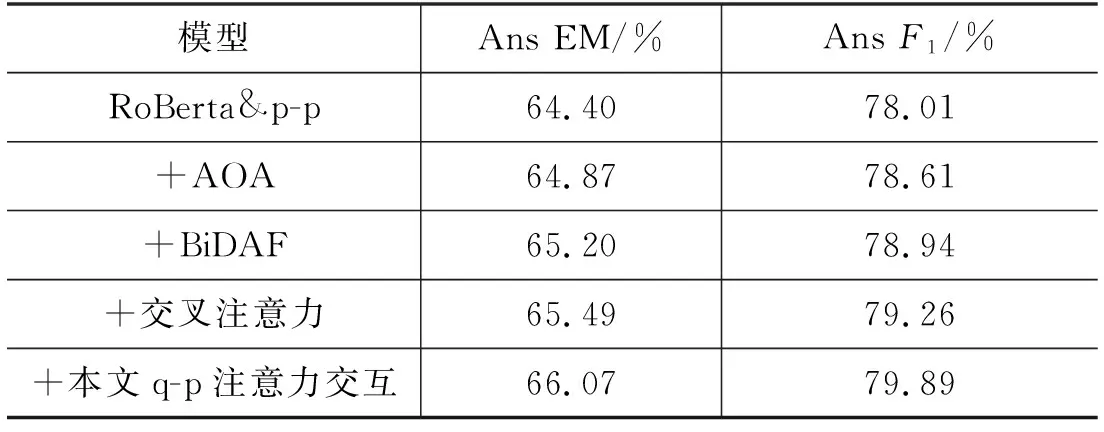
表5 不同问题-文本注意力交互实验结果
值得一提的是,在信息融合之后拼接段落m和段落n的文本表示对模型性能的提升很大。在实验开始阶段并没有拼接两个段落的信息,而是将两个段落分开处理,仅仅使用输入特征的第一个单词“”来决定答案是否位于此段落中。然而,实验结果EM仅有62.64%,F1值仅有76.21%。
4 错误分析
本节探究了数据集中的错误样例,错误类型可以分为以下三种类型: 多少类,是否类,实体错误类。表6列举了每个错误类别的部分样例。
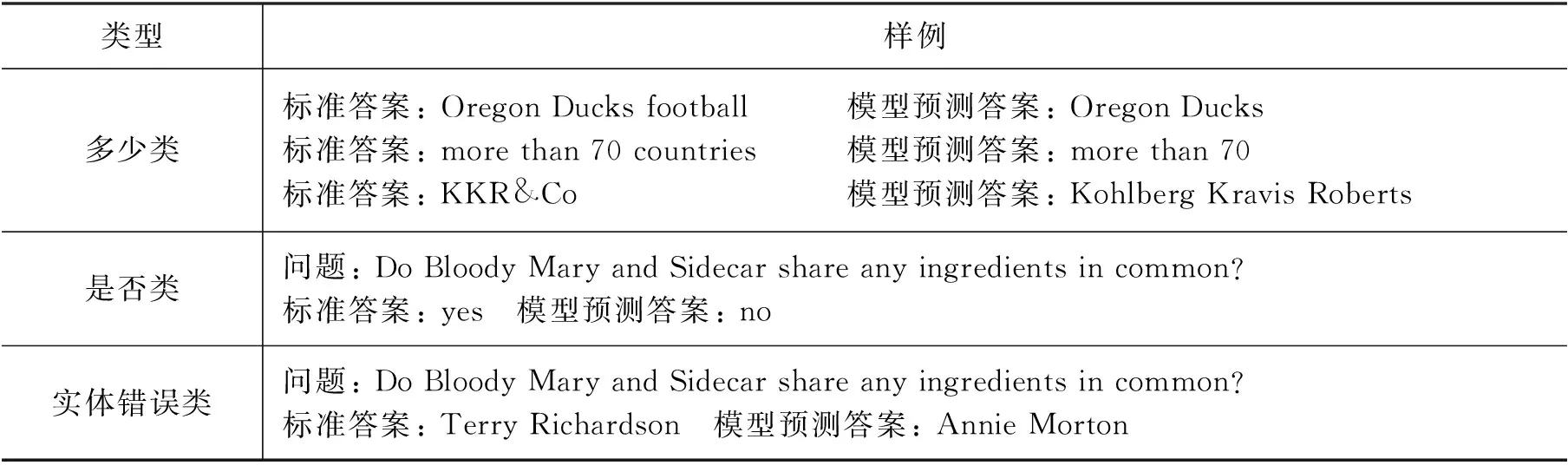
表6 错误样例
对数据集中模型预测错误的样例进行分析,大多数的错误都集中在多少类: 模型预测的答案与标准答案相比多几个单词或少几个单词,但并不影响答案所表述的意思。但是由于模型的评估指标有精确匹配(EM),因此在一定程度上会影响模型性能。
第二种错误类型为是否类: 问题需要通过“yes”或者“no”来回答。以表6中样例为例,问题的标准答案是“yes”,但是模型预测为“no”。因为模型的输入为"yesno"+para +"",所以模型仅在yes和no之间定位答案,缺少足够的逻辑推理与判断。因此,未来的工作中我们将会更多地专注于对是否类问题的回答,以此提高模型的逻辑推理能力。
第三种错误类型为实体错误类,例如,问题“Who is older, Annie Morton or Terry Richardson?”需要比较两个实体的属性。由于缺少对数字的推理计算能力,导致本文模型在此类问题上效果并不优异。因此,在未来的工作中我们将会添加类似于推理机的机制来比较不同实体,并参考在数字推理数据集Drop[37]上进行研究的工作进一步改进本文模型。
5 结论
本文提出了一个处理多跳机器阅读理解任务的模型。首先,本文提出了一种通过多个段落间的信息交互筛选出与问题相关的段落的“黄金段落”筛选模型;然后,为了解决在预训练模型中文本长度限制的问题,提出了一种融合多个段落信息的方法,进而应用传统的机器阅读理解方法得到最终的答案。在HotpotQA数据集上的实验显示,本文模型与排行榜上其他模型相比实现了比较优异的效果。在未来的工作中,本文将专注于对需要进行比较和判断的问题进行研究以提高模型的逻辑推理能力,进一步提升模型性能。
