基于无监督集成聚类的开放关系抽取方法
2022-06-21谢斌红赵红燕
谢斌红, 李 玉, 赵红燕
(太原科技大学 计算机科学与技术学院,山西 太原 030024)
0 引言
关系抽取(Relation Extraction, RE)旨在从纯文本中抽取两个实体之间的关系,并以
现有的关系抽取方法取得了很大的进展,可以有效学习出句子中实体间的语义关系,但大多基于有监督的模型,需要大量的标注数据,而高质量的标注数据往往需要耗费大量的人力。为了降低人工标注成本,Mintz[1]提出用远程监督方法自动生成训练数据,其假设如果两个实体在知识库中存在某种关系,那么包含该实体对的所有句子都将表达这种关系。还有几种半监督方法,包括Bootstrapping、主动学习和标签传播。尽管如此,上述方法都只能提取那些出现在人工标注数据集或知识库中的预定义关系,而却难以涵盖开放域语料库中大量新颖的关系事实。
开放关系抽取(OpenRE)旨在从开放域语料库中提取关系事实,其中关系类型可能没有预定义。一些研究主要使用启发式或通过远程监督的外部标签从开放域语料库中识别关系短语,然后识别实体对[2-3],例如,Banko等人[4]直接从句子中提取单词或短语来表示新的关系类型。然而,有些关系不能用句子中的词语明确表示,因此很难将具有完全相同含义的不同短语对齐,如在“Joanne abandoned Steve Jobs when he was born.”这句话中,“Joanne”和“Steve Jobs”之间是父子关系,但在句子中却没有相应的词语能够显式说明这种关系。基于聚类的关系抽取模型由于能够在很少甚至不需要人工干预的情况下从句子的语义特征中识别出实体之间的关系而备受关注。之前基于聚类的OpenRE方法[5-8]大多是无监督的,不能有效选择有意义的关系模式并丢弃无关信息。为此,Wu等[9]提出关系知识迁移系统RSNs,利用预定义关系的高质量标注数据来实现OpenRE。Hu等[10]的自监督学习框架SelfORE利用聚类生成伪标签并用于训练关系分类器,通过分类误差引导编码器学习更好的特征表示再次用于聚类,但是由于伪标签生成方法的准确率较低,因此性能不佳。
为了进一步降低人工标注的成本,同时获得高质量的监督信息以进行开放关系抽取,本文提出了一种无监督集成聚类框架UEC。该框架从数据本身出发,首先提取句子上下文特征,然后使用无监督集成学习网络的输出构建句子关系相似图,并应用规则对图进行裁剪和聚类,形成k个关系簇,进而从中生成高置信度的伪标记关系样本,最后通过多次半监督聚类来提高无监督聚类性能。UEC包括两个模块: 关系编码模块和集成聚类模块。关系编码模块使用卷积梯形网络(Convolutional Ladder Network, CLN)学习句子的上下文特征并对实体间的关系进行预测。集成聚类模块旨在使用CLN的集成执行聚类过程,以确定句子所属的关系簇,它把半监督聚类作为桥梁,采用迭代的方式逐步提高伪标签质量和聚类准确度。
综上所述,本文的主要贡献如下:
(1) 提出了一种新的无监督聚类框架UEC,用于开放域关系抽取,该框架能有效发现无标记文本中的关系类型。
(2) 实验结果表明,与现有先进模型相比,UEC在F值方面有显著改善。
1 相关工作
关系抽取是自然语言处理中的一项重要任务,旨在识别句子中两个实体之间的关系。传统的关系抽取方法主要是有监督的分类模型,需要一组预定义的关系标签和大量的标注数据,这使得它们不太适用于开放域语料库。远程监督[1]是一种广泛采用的减少人工标注的方法,通过在语料库和知识库之间对齐实体来自动生成关系标签,然而,远程监督仍然局限于知识库中的已知关系,无法有效获取文本中蕴含的新型关系。
为了解决这一问题,近年来研究者们致力于探索开放关系抽取方法,其目的是从无监督的开放领域语料库中发现新的关系类型。OpenRE方法大致可以分为三类: 基于序列标注的方法、基于Bootstrapping的方法和基于聚类的方法。
(1) 基于序列标注的方法侧重于寻找关系提及(mention),即直接从无监督[4,11]或监督范式[12-14]的句子中提取由单词组成的关系短语,但是由于表达方式的多样性,同一种关系类型通常会被提取多个过于具体的关系短语,并且不能很好地用于下游任务。
(2) 基于Bootstrapping的方法[15-16]用一小组种子实例快速适应新的关系,对于开放式关系增长是可扩展的,但是在迭代的过程中容易出现语义漂移现象,而且在发现一定量的关系实例后很难再继续挖掘。
(3) 相比之下,基于聚类的方法通过对从句子中提取的关系表示进行聚类,从而自动形成关系种类,具有发现高度可区分的关系类型的优势。传统的基于聚类的OpenRE方法通过外部语言工具为关系实例提取丰富的特征,并将语义模式聚类为多种关系类型[5-6,17]。随着深度学习的快速发展,神经网络被广泛应用到OpenRE任务中。Marcheggiani等[7]提出变分自编码器模型(VAE),其中编码组件根据上下文特征预测两个实体之间的语义关系,而重构组件根据编码组件预测的关系和给定实体来预测被掩盖的另一个实体。Xie等[18]在VAE的基础上,通过构造辅助分布并使用深度神经网络进行编码能力的学习,最后将低维的隐层向量用于聚类。Elsahar等[8]提出了全新的对词嵌入进行重新加权的方式,并融合实体依赖路径等多种语言特征,最后对降维后的特征进行聚类。关系知识迁移系统RSNs[9]从预定义关系的标记数据中学习关系的相似性度量,然后迁移关系知识去识别无标记数据中的新关系。Hu等[10]等人提出一种自监督学习框架SelfORE,首先编码器提取句子特征获得实体对表示,然后应用聚类算法为所有实体对表示分配伪标签,以此训练关系分类器,从而进一步改善实体对表示和聚类质量。
上述方法要么局限于无监督学习模式,没有利用到监督学习的优点,要么采用伪标签策略自主生成监督信息,但由于生成的伪标签精度较低,当使用低精度的伪标签作为监督进一步训练模型时,导致最终聚类准确率较低。在机器学习领域,研究者们在聚类方面做了很多工作,如Gupta等[19]提出了一种基于半监督学习的无监督聚类学习方法,实现了比其他无监督方法更高的性能。受此启发,本文提出一种无监督集成聚类框架(UEC)用来创建高质量伪标签,从而进一步提高无监督OpenRE方法的聚类性能,更加有效地抽取开放域中的未知关系。与现有基于聚类的OpenRE方法不同的是,UEC不需要任何标注数据,使用完全无监督的方式从数据本身获得监督,既保持了无监督学习的优点,又具有监督学习较强的特征判别能力。
2 无监督集成聚类UEC
UEC主要由两个模块组成: 关系编码模块和集成聚类模块。关系编码模块使用卷积梯形网络(CLN)提取句子的上下文关系特征,它将句子的嵌入表示作为输入,学习预测实体之间所表达的关系。集成聚类模块采用集成模型投票的方式聚类无标注句子,并应用规则选择出高置信度句子为其标记伪标签,基于聚类结果的伪标签被视为半监督训练所需的监督信息,进一步指导关系编码模块更好地进行上下文关系特征学习和关系分类。
UEC的结构如图1所示,其学习模式分为以下五步:
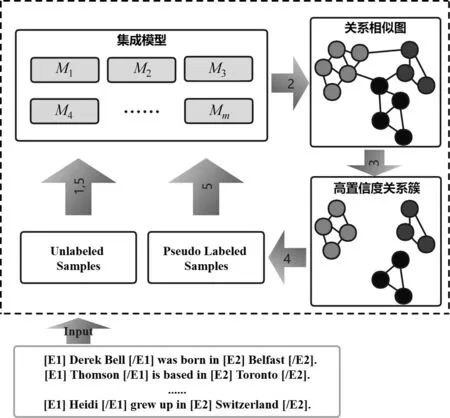
图1 UEC的结构
第一步: 在整个数据集上对集成模型中的每个卷积梯形网络Mj独立地进行无监督预训练。
第二步: 通过集成模型的投票对句子间的关系相似性建模,构建关系相似图。
第三步: 对关系相似图进行剪支,获得k个高置信度关系簇。
第四步: 为关系簇中的句子分配伪标签,生成伪标记样本。
第五步: 使用无标记样本和伪标记样本执行半监督聚类过程。迭代进行第二步至第五步,生成最终的关系集群。
2.1 关系编码模块
关系编码模块旨在通过提取句子中给定实体之间的上下文特征并对其关系进行预测。为此,本文在梯形网络(Ladder Networks,Ladder Nets)的基础上提出卷积梯形网络,其结构如图2所示,包括嵌入层、两个编码器和一个解码器。CLN将一对句子作为输入并将其编码成向量,然后分别对它们进行关系特征提取和关系预测。

图2 CLN结构示意图
2.1.1 嵌入层
嵌入层用于将文本信息转换成向量表示,使神经网络能够更好地理解句子语义。一对实体之间的关系可以通过它们的上下文来反映,因此,本文利用预训练的BERT模型对句子进行编码,得到基于上下文的词嵌入表示。同时将句子中实体对的位置转换为随机初始化的位置嵌入,用于表征句子中某个单词与两个实体之间的相对距离。
此外,直觉上关系可以关联到某些类型的实体,例如出生地关系将一个人和一个地点联系起来。所以,为了更好地提取实体间的深层语义关系,除了其本身的位置信息外,实体类型信息也可以为关系发现提供很强的归纳偏差[20-21]。因此,对于每个命名实体,本文使用其Wikipedia类型和Stanford NER标签作为附加特征。
具体来说,对于句子S={w1,w2,…,wq},其中q为句子最大长度,经过嵌入层预处理之后,得到其完整的嵌入表示U,如式(1)所示。
U=Sw⊕Sp⊕St∈Rq(d+2c+2t)
(1)
其中,Sw是词嵌入表示,Sp是实体位置嵌入,St是实体类型嵌入,d是词嵌入维度,c是实体位置嵌入维度,t是实体类型嵌入维度,将这些嵌入表示串联起来形成向量序列作为网络输入。
2.1.2 编码器
CLN包括两个编码组件: 加噪编码器和干净编码器,其中加噪编码器的每一层施加了随机高斯噪声,通过学习重构叠加噪声的输入句子,可防止编码器只简单地保留原始输入的信息,从而使编码器学习到的句子特征更具鲁棒性,提高网络的泛化能力。两个编码器结构相同,都由卷积层、池化层、全连接层以及分类层组成,其中卷积层的卷积核高度设置为3,宽度为句子嵌入向量的维度,同时为了使获得的特征多元化,使用230个卷积核进行特征信息的提取。经过卷积、池化、全连接操作后获得句子向量z,如式(2)所示。
z=CNN(U)
(2)
分类层用于计算关系预测概率,该层是具有softmax激活的一维输出全连接层,如式(3)所示。
y=σ(kz+b)
(3)
其中,σ表示softmax函数,k和b表示权重和偏置。
因此,对于无标记句子Si,经过嵌入层得到其嵌入表示Ui之后,加噪编码器和干净编码器同时对其进行逐层编码,得到一系列隐层表示,如式(4)、式(5)所示。

2.1.3 解码器
Si经过加噪编码器编码得到带噪的隐层表示之后,各层得到的特征向量通过跳跃连接(skip connection)映射到对应的解码层,解码器对其进行逐层降噪解码,如式(6)所示。
(6)
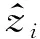
由于加噪编码器的所有层都被噪声破坏,另一个具有共享参数的干净编码器负责提供干净的重构目标,辅助解码器进行无监督训练,以达到对有噪数据的最佳映射效果。因此,以干净编码器每层的隐层表示作为目标值,最小化二者的均方误差,得到CLN每层的无监督重构损失,如式(7)所示。
(7)

2.1.4 无监督关系预测
初始阶段的无监督训练,在常规梯形网络的重构损失基础上增加互信息损失,即最大化编码器中分类层的输入与输出之间的互信息,使CLN对表达相似关系的句子给出相似的关系类别预测,并在总体上最大化关系预测的多样性,从而使不同关系的句子拥有不同的预测结果,如式(8)所示。
(8)
其中:
I(Z;Y)=H(Y)-H(Y|Z)
(9)
式(9)中的H(Y)和H(Y|Z)分别是熵和条件熵,其中最大化熵H(Y),鼓励CLN将完全不同的关系分配给输入句子,从而在输出类别上实现均匀分布。另一方面,最小化条件熵H(Y|Z),使得对给定句子进行明确的类别分配。
此外,还添加另一个正则化损失项,即CLN的干净输出与噪声输出之间的KL散度,如式(10)所示。
(10)
综上所述,无监督学习阶段的训练目标是最小化以下损失,如式(11)所示。
lossunsup=lossrecon-α·lossMI+β·lossKL
(11)
其中,α和β分别设置为0.2和1.0,用来调整各部分损失。
2.2 集成聚类模块
集成聚类模块旨在将句子聚成k个语义上有意义的关系簇,从而发现潜在的关系类型。该模块使用CLN的集成模式对无标注句子进行聚类,以达到比单个网络决策更高的可靠性。同时为了提高无监督聚类性能,集成聚类模块为每个关系类别均生成高质量的标记样本,用于后续的半监督聚类阶段。
具体来说,对于一对输入句子,首先使用CLN集成模型M={m1,m2,…,mm}分别预测它们的关系类别,得到预测结果y={y1,y2,…,ym},其中m是模型中的网络个数。然后,遍历整个数据集,根据预测结果y构造一个具有n个节点的关系相似图G={U,Epos,Eneg},其中,n是数据集大小,G中的节点代表每个输入句子的嵌入表示U,Epos和Eneg是节点之间的两种边,由M中的CLN投票决定。
当M中的大多数CLN对输入的句子对的关系预测达成一致时,在其对应的节点之间添加强正边Epos,即:
当M中的大多数CLN对输入的句子对的关系预测不一致时,在其对应的节点之间添加强负边Eneg,即:
其中,tpos和tneg设置为0.8,代表强正边和强负边的投票阈值。
两个节点之间的强正边意味着大多数CLN网络认为这对句子表达相似的关系,而强负边则意味着大多数网络认为这对句子表达不同的关系。
构建好关系相似图之后,每个由强正边组成的子图就是一个集群,在一个集群内,节点对应的句子高置信度地属于同一关系类别。然后,从图中提取k个高精度的关系簇,同时最大化每个簇的大小,并保证每个簇是不同的。为此,使用一种贪婪近似算法,如算法1所示。

算法1: GETCLUSTERS输入: 数据集句子嵌入U,关系簇数量k输出: 关系簇集合S 1: procedure GETCLUSTERS(U,k) 2: G={U,Epos,Eneg} 3: for k'∈{1,2,…,k} do 4: umax=argmaxu∈U{|(u,u')∈Epos|} 5: Sk'={u:(u,umax)∈Epos}∪{umax} 6: for u'∈U do 7: if (u',umax)∉Enegthen8: 从G中移除u' 9: end for10: if Epos为空then11: break 12: end for 13: 返回S={S1,S2,…,Sk} 14: end procedure
首先,从G中寻找具有最多强正边Epos连接的节点(第4行),将其与通过强正边Epos相连的其他节点添加到一个集合Sk′中(第5行)。然后,删除与该节点没有强负边Eneg连接的所有节点(第6~9行)。重复进行此过程k次,得到k个不同的关系簇,大致满足要求。
通过对G剪支获得k个高精度的关系簇之后,需要找到关系簇与模型的输出类别之间的适当映射,为每个关系簇分配关系伪标签。具体来说,对于网络Mj∈M和关系簇Sk∈S,为Sk中的所有句子分配该簇中大多数句子的预测类别作为伪标签,如式(16)所示。
(16)
这些伪标签可以被看作是来自语料库本身的监督信息,用于指导下一步的半监督聚类过程,并用于监督损失中,如式(17)所示。
(17)
与k-means等聚类算法不同,集成聚类模块不是对整个数据集直接聚类,而是只对可以获得高精度的一小部分数据集进行聚类,以此提取出属于每个类的高置信度样本,这对于提高下一步半监督训练的准确率很重要。
2.3 自启动的伪半监督聚类
通过集成聚类模块提取出属于每个类的高置信度样本之后,将这些样本视为伪标记样本,对集成模型迭代执行半监督训练,进一步提高聚类性能。由于使用了半监督学习思想,而未使用真正的标记数据,因此称为“伪半监督”。算法2描述了完整的迭代训练过程。

算法2: 伪半监督聚类过程输入: 数据集句子嵌入U,集成模型M,关系簇数量k输出: 簇标签 1: for j∈{1,2,…,m} do 2: 初始化Mj权重 3: 最小化lossunsup更新Mj 4: end for 5: forit∈{1,2,…,n_iter} do 6: S=GETCLUSTERS(U,k) 7: for j∈{1,2,…,m} do 8: 获得Mj伪标签用于losssup 9: 最小化losstot更新Mj 10: end for 11: end for12: 使用M的平均结果来返回最终集群
首先,仅使用无监督损失lossunsup(第1~4行)对集成模型M进行无监督预训练。然后,对于每次迭代,使用算法1获得高精度关系簇S(第6行),并从中生成伪标记样本(第8行)。最后,使用半监督损失losstot对M执行半监督聚类过程(第9行)。
半监督训练损失由无监督聚类损失和有监督分类损失组成。由于不免会存在伪标签分配错误的情况,所以,为了降低伪标记样本中的噪声影响,为该部分的监督损失增加一个时变系数α(t),以控制其信号强度。最终,半监督训练阶段的总损失如式(18)、式(19)所示。
α(t)的比例调度决定着伪标记样本在网络更新中的作用,比例太大会干扰训练,引起性能退化,比例太小则提升有限。经过试验,T1、T2和αf分别设置为2、6和2,t为当前迭代数。
算法2的迭代方式将不断提高聚类质量。随着迭代的进行,集成模型的聚类性能通常会不断提高,直到达到饱和为止。算法1返回的关系簇的大小会不断增加,直到它们几乎覆盖了整个数据集,而且关系簇分配也会变得更加稳定,多次迭代之间的方差会减小。
3 实验与分析
3.1 数据集和评估指标
本文使用FewRel和NYT-FB数据集对UEC的性能进行评估。FewRel是以Wikipedia为语料库,Wikidata为知识库对齐获得,包含100种关系类型,每种关系都有700个句子实例,是目前最大的精标注关系抽取数据集,该数据集的一个特点是每个句子只包含一个唯一的实体对,因此关系抽取模型不能选择简单的方式来记忆实体。NYT-FB数据集在之前的开放关系抽取任务中应用广泛[5,7,22],它通过远程监督的方式将New York Times语料库中的文本和Freebase知识库中的三元组对齐生成,遵循Hu等[10]的设置,过滤出非二元关系的句子实例,最后得到包含262种关系类型的41 000个标注实例。
本文使用B3、V-measure和ARI三种评估指标进行分析。B3包括准确率(Precision)、召回率(Recall)以及F1值,准确率和召回率衡量将每个句子放入其所属类或将所有句子聚类到一个类的正确率,F1值是准确率和召回率的调和平均值。
V-measure是从同质性(Homogeneity)和完整性(Completeness)的角度来分析,类似于B3中的准确率和召回率,V-measure对聚类数和实例数之间的依赖关系比较敏感,与实例数相比,应该使用相对较少的簇来保持使用V-measure评估的可比性。
ARI(Adjusted Rand Index)衡量两个簇之间的相似性,其取值范围为[-1,1],值越大,聚类结果越符合实际情况。
3.2 参数设置
对于卷积梯形网络CLN,采用了两种正则化方法,其中嵌入层之后设置了一个dropout层,卷积层和全连接层使用L2正则化,参数分别为0.000 1和0.001。实验中其他超参数的具体设置如表1所示。

表1 超参数设置
3.3 实验结果分析
为了验证UEC在OpenRE任务中的有效性,本文将UEC与FewRel和NYT-FB数据集上最先进的OpenRE方法进行比较,同时还进行了消融实验,以详细考察UEC中各个模块对整体性能的贡献。
VAE[7]是OpenRE中先进的生成模型,它通过从给定实体和预测关系中重构另一个实体来优化关系分类器,并使用实体词、上下文词和依赖路径等丰富的特征来描述关系类型。RW-HAC[8]是基于聚类的OpenRE模型,它首先提取实体的知识库类型和NER标签,并对句子的词嵌入进行重新加权,然后融合特征,最后使用HAC聚类算法对降维后的特征进行聚类。RSNs[9]应用迁移学习的思想来解决OpenRE,它使用关系孪生网络学习从预定义关系的监督、远程监督数据和新关系的无监督数据中度量关系相似度,从而发现未知关系。SelfORE[10]利用预训练语言模型提取句子的实体对表示并对其进行自适应聚类生成关系伪标签,然后将其作为自监督信息训练关系分类器,进而不断改善特征表示和聚类性能。Yao等[5]提出Rel-LDA,将主题模型扩展到了关系抽取任务中,句子和实体对在主题建模中充当文档,而关系类型对应于主题,并使用实体类型、词性等总共8种特征进行训练。UIE[22]是一种先进的判别式关系抽取模型,它使用了两种正则化因子,迫使模型自信地预测每个关系,并鼓励模型平均预测所有关系,这里对比了三种模型架构(UIE-VAE、UIE-PCNN和UIE-BERT)。Etype[23]仅使用命名实体来归纳关系,将关系归纳为实体类型的组合,实现了比现有无监督关系抽取方法更高的性能。
根据表2给出的实验结果可以看到,UEC在两个数据集上的表现都优于所有对比模型。从数据集FewRel上的实验结果来看,UEC比最先进的RSNs在F1值上高出5.3%,这表明UEC能够提取到句子的深层语义特征,有效理解关系语义,从而发现无标注文本中的未知关系。与同样采用伪标签策略的SelfORE相比,UEC并非对所有句子分配伪标签,而是只对高置信度的句子,通过这种方式尽可能地创建高质量标签并用于监督损失中,作为再训练集成模型的正则化器,从而实现了更高的性能。

表2 与现有方法对比结果 (单位: %)
UEC在NYT-FB上的实验遵循Hu等[10]的设置,80%的数据用来训练,20%的数据用来验证结果,在验证集验证的时候随机选择10种关系进行验证,虽然这远少于数据集中真实的关系数量,但仍可以揭示UEC的有效性,也让UEC可以与基线模型进行公平比较。从NYT-FB上的实验结果来看,UEC的性能比在FewRel上有所提升,F1值达到67.1%,NYT-FB中的句子通常共享实体对和关系短语,这使得关系聚类变得容易,在目标关系类别较少的情况下,UEC能够更准确、全面地发现所有未知关系。此外,为了进一步探索UEC的能力,本文在验证时使用全部的关系数量,即262种关系类型再次进行实验,实验结果见UEC-full。可以看到,在大幅增加关系类别数量的情况下,UEC的F1值下降至46.2%,由于关系相似图中节点数量很大,搜索关系簇耗时,在目标关系数量k很大时识别出k个关系簇对集成聚类算法来说存在挑战。
消融实验结果如表3所示,UEC w/o type表示不使用实体类型特征,只使用词嵌入和实体位置嵌入拼接作为句子的嵌入表示;UEC w/o pseudo labels表示不采用伪标签策略,仅使用无监督聚类损失;UEC w/o ensemble表示不使用网络集成,仅利用一个CLN网络的预测结果进行聚类;UEC w/o getclusters表示使用k-means聚类算法代替集成聚类模块。通过分析可以得出结论,所有关键组件都对UEC性能的提高做出了积极贡献。在不使用伪标签的情况下,UEC的性能下降了23.6%,对模型性能影响最大,说明高质量的监督信息可以有效提高无监督OpenRE模型的性能。同样地,仅使用单个网络预测以及使用k-means聚类算法都对UEC造成了不同程度的性能下降。此外,增加实体的类型信息作为附加特征丰富了模型的分布式表示,帮助UEC性能提升了1.1%,说明实体类型的知识可以减少关系的搜索空间,为无监督关系发现提供一定的归纳偏差。
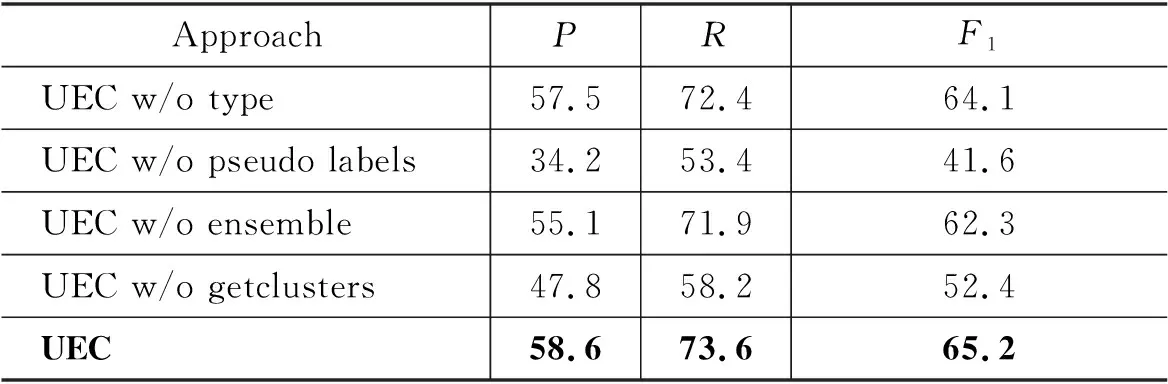
表3 消融实验结果 (单位: %)
3.4 聚类分析
本文使用标准的无监督度量指标(ACC)在FewRel上评估UEC的聚类性能。假设模型预先知道目标关系的数量,将关系簇的数量k设置为真实类别的数量,为了将聚类分配的伪标签转换为用于评估目的的关系标签,将每个关系簇中的大多数真实关系标签分配给该簇中的所有句子作为预测标签。
(20)
其中,li和ci分别为真实关系标签和集成聚类模块分配的伪标签,p表示关系簇和真实关系标签之间所有可能的一一映射。
图3和图4分别展示了伪标签和聚类的准确率以及伪标记样本数量与迭代次数的关系。随着迭代的进行,数据集中分配了伪标签的句子的数量不断增加,但其中伪标签分配错误的句子不可避免地也会增多,因此导致了伪标签的准确率不断下降,然而,这仍然有助于提高整体的聚类准确率。此外,与使用一小部分数据来匹配输入数据分布的纯半监督方法不同,UEC的伪标记样本并不完全匹配输入数据分布,这导致伪标签准确率和聚类准确率之间的差距较大。

图3 伪标签、聚类准确率vs.迭代次数

图4 伪标记句子数量vs.迭代次数
3.5 案例分析
为了得到每个关系簇的关系名称,对于每个关系簇中的所有句子,提取句子中两个实体之间的词,计算最频繁的N-gram作为关系名称的表示形式。本文在FewRel数据集中随机选择了5个关系,并提供了一个简单的案例来展示为每个簇提取的关系名称,如表4所示。

表4 关系名称案例
从表4列举出的例子可以看到,UEC能够获得语义与真实关系名称比较相似的关系名称,其中第二个例子“the president of vs. member of”相较其他提取结果语义上并不是完全吻合,通过分析聚类结果发现,“the president of”所代表的关系簇中共有389个句子,每个句子中实体间的关系短语不尽相同,且大多不能显式地表达“member of”这一真实关系,比如“The stadium is part of the Technical Center Academy of theFootball Federation of Armeniawhich was officially opened on 1 September 2010 by theUEFApresident Michel Platini.”和“On 2 October 1945, Laue, Otto Hahn, andWerner Heisenberg, were taken to meet with Henry Hallett Dale, president of theRoyal Society, and other members of the Society.”,这导致在为关系簇提取关系名称时很难与其真实关系名称达成一致,除此之外,关系簇中还有聚类错误的句子,如“In 2014 the SWAPO presidential candidate wasHage Geingobwho was the Vice-President ofSWAPO.”,句中“Hage Geingob”和“SWAPO”的真实关系是“member of political party”,这在一定程度上也会影响关系短语的统计。因此,对于句子中实体间的关系比较隐含,或数据集中存在语义上比较相近的关系类型,UEC为关系簇提取出的关系名称与真实关系名称在表面语义上可能会出现一定偏差,但这仍可以用于区分具有不同关系的实体对,还可以派生出关系簇所代表的关系类型作为最终的关系抽取结果。
4 总结与展望
本文提出了一种无监督聚类框架UEC,用于开放域关系抽取。与传统的关系抽取模型需要依赖标注数据且仅能对预定义关系进行分类不同,UEC不需要任何标注数据,能够在目标关系类型和关系分布事先未知的开放域场景中工作。与其他无监督OpenRE模型相比,UEC能够利用监督学习的优势,从监督信息中学习判别能力,从而改进关系特征学习,进一步提高无监督关系抽取的性能。在FewRel和NYT-FB数据集上的实验结果表明了UEC的有效性。在未来的研究中,将探索改进集成聚类模块,提升UEC在目标关系数量较大时的健壮性,以应对关系类型日益增长的现实场景。
