基于SARIMAX模型区域用水量短期预测
2022-06-17李建
李 建
(上海威派格智慧水务股份有限公司,上海 200032)
1.引言
供需平衡是生产供水系统正常运行的基础。为达到这一目标,需要按需调整生产水厂水泵、阀门以及其他配水装置,以达到平衡供需,满足客户的用水需求。在不同的时刻城市居民的生活和生产情况都在不断的变化,因此对水的需求也在不断的变化。由于城市需水量的变化呈现出一定的周期性和趋势性,使得需水量预测[1]成为可能。水量预测主要是通过分析城市历史用水量数据的变化规律,综合考虑节假日、重大事件、气候条件等因素的影响,利用数学方法,在符合一定精度要求的前提下,对未来某段时间内的城市用水量进行预测[2]。用水量预测已成为现代供水调度系统学科中一个重要的研究领域。
近年来,很多学者对用水量预测算法进行了深入的研究,目前比较常用的需水量预测模型主要有时间序列模型[3]、人工神经网络模型[4]等。时间序列模型是一种定量分析方法,它在时间序列变量分析的基础上,运用一定的数学方法建立预测模型,但是该模型无法兼顾外界因素的影响。神经网络模型可以利用历史数据并且结合外在影响因素,但是在大数据量时会出现预测速度缓慢,预测效果不良的现象。
本文对天气因素、节假日因素和特殊事件因素进行综合分析建模,在对影响因素考量时选择对水量预测有明确影响效果的因素作为外生变量以防止过多外生变量或外生变量无明确影响关系导致的关系混乱问题,从而提高对小时级用水量进行预测的预测速度和预测精度。
2.SARIMAX模型
自回归差分移动平均模型(ARIMA),是一种时间序列预测分析的方法,是不同于回归模型的一种分析方法。ARIMA模型是美国统计学家Box和英国统计学家Jenkins在20世纪70年代提出的[5]。
有一些时间序列存在明显的季节性周期变化,通常使用季节性差分自回归滑动平均模型SARIMA来表示,该模型是从自回归差分移动平均模型ARIMA中衍生而来[6]。该模型是一种分析工具,用于构建具有动态时间序列和季节波动的数据序列模型。该模型不仅可以对非常规和非平稳的时间序列信息进行处理,还将季节信息纳入考量。若某时间序列经s个时间间隔后观测值呈现出相似性,如同时出现波峰或波谷状态,则称该序列是以s为周期的季节时间序列。
周期为s的非平稳季节时间序列为Xt,则经过了d阶非季节差分,p阶自回归、q阶移动平均的ARIMA(p,d,q)模型为:
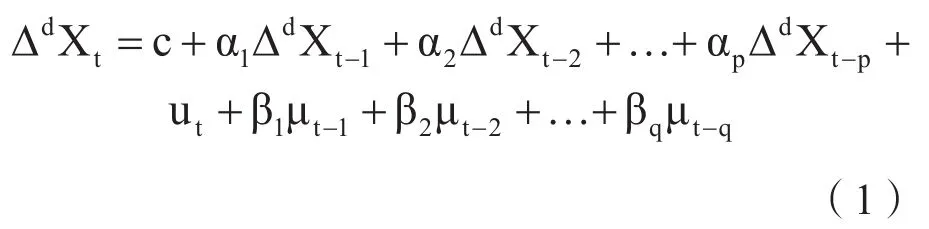
上式中c为常量,α1为自回归系数,为移动平均系数,为随机扰动项。上式引入滞后算子L,可以得到如下等式。
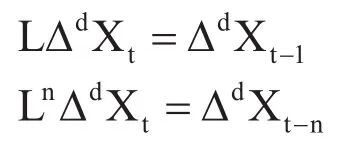
上式中,n为任意正整数。可以将式(1)可以转换换为如下公式:
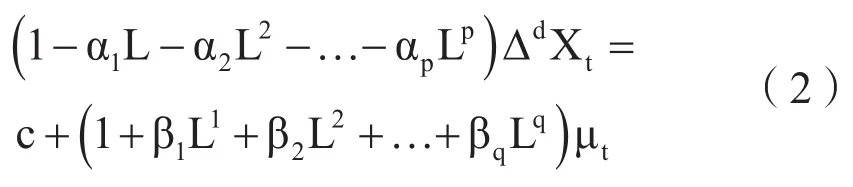
其中平稳的自回归算子
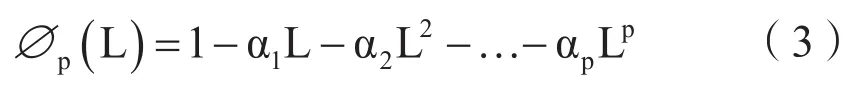
可逆的移动平均算子
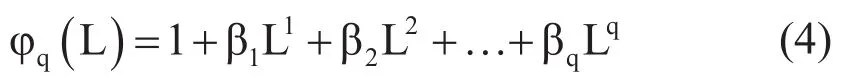
代入式(2)即得到ARIMA(p,d,q)的简式
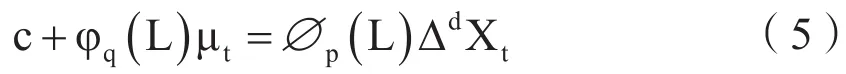
同时,定义季节差分算子Δs=1-Ls,则一次季节差分表示为
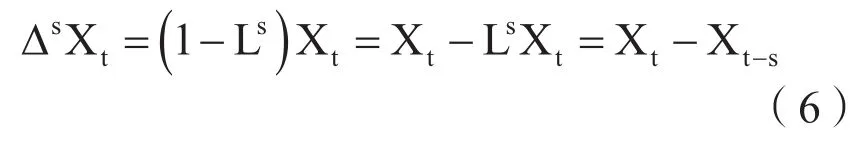
对于非平稳季节性时间序列,需经D阶季节差分来消除季节影响,才可以建立周期为s的P阶自回归、Q阶移动平均季节时间序列模型。
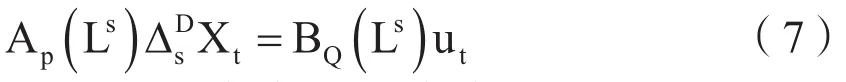
上式中Ap(Ls)、BQ(Ls)分别为非平稳季节时间序列的自由回归算法与移动平均算子。
当上式的随机扰动项ut非平稳且存在自由回归AR或移动平均MA时,再对ut建立ARIMA(p,d,q)模型。
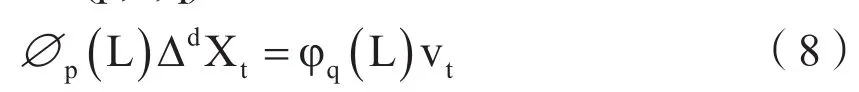
上式中的vt为白噪声。把(8)代入(7)中,得到模型ARIMA(p,d,q)×(P,D,Q)
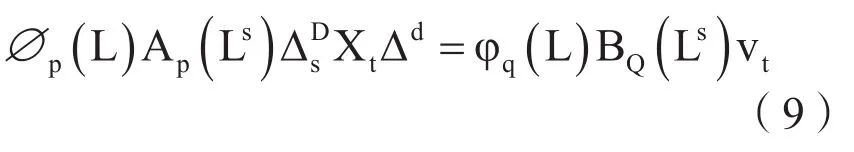
本文进一步加入外生变量,扩展为SARIMAX模型。外生变量X基本上允许在模型中考虑外部变量,本文的外生变量主要是区域天气温度,区域天气湿度,区域降雨量,法定节假日,特殊事件。
3.算法实现
基于SARIMAX模型的短期水量预测,主要分为如下几个模块,包括数据预处理,影响因素相关性分析,算法模型调整与算法实现,预测结果及误差分析。本文主要预测1天和7天的小时级的水量数据。
3.1 数据处理
数据预测的工作基础为历史数据,预测天数为一天则获取要预测时间前九天的原始小时级用水量数据,若预测天数为七天则获取要预测事件前二十八天的原始小时级用水量数据。原始数据量为Dn,则预测的天数Dp计算公式为:
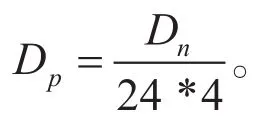
数据的准确性、完整性对水量预测模型产生了极为重要的影响。然而在数据的采集过程中会出现数据缺失或数据异常的情况。这些异常数据的存在使系统中蕴涵的确定性成分更加难于把握;甚至会使预测过程中产生错乱,导致不可靠的输出。本文通过四分位法来判断极端数据或者噪声数据。其中上四分位点Q1,其位置计算公式为:
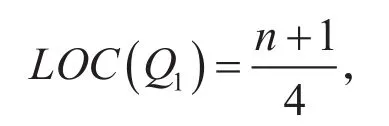
下四分卫点Q2,其位置计算公式为:
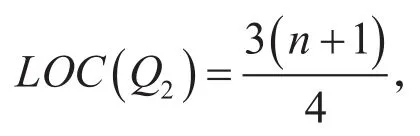
其上限值和下限值分别如下公式:
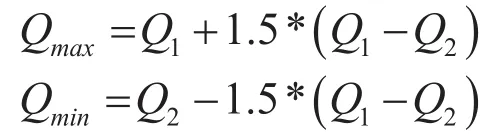
超过上限或低于下限则认为此数据为异常数据。如果出现了异常值,那么用此数据前两个数据的均值代替。
3.2 相关性分析
将预处理后的用水量数据Y和预影响因素数据X外生变量进行皮尔逊相关性分析,这里的外生变量主要是温度、湿度、降雨量。如果分析结果具有相关性,则将此影响因素纳入外生变量范畴。采用如下公式进行相关性分析。
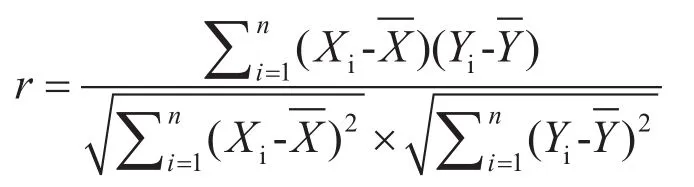
其中,X和Y分别为样本Xi和Yi的均值,相关系数r的结果关系为:0.8<r≤1.0表示极强相关;0.6<r≤0.8强相关;0.4 <r<= 0.6中等程度相关;0.2<r≤0.4弱相关;0<r≤0.2为极弱相关或无相关;
若皮尔逊相关分析结果显示用水量数据和影响因素数据不具有相关性,则对两者再进行格兰杰因果检测。若格兰杰因果检测结果显示用水量数据和影响因素数据具有关于n阶滞后的相关性,则将该n阶滞后的影响因素纳入外生变量范畴。
3.3 算法模型调整与算法实现
对于城市用水,每天的用水量都有一定都规律性。本文以每天的小时用水量数据作为研究样本,即模型的周期s取24。
在每次预测的时,将模型变量参数记录并保存下来,在下次进行预测的时候,通过序列的平衡性和白噪声检验,来判断已有的变量参数的特性及预测结果的趋势来判断是否可以使用当前参数,若能使用则确定已有参数作为预测模型参数,若不能使用则根据参数调整的范围进行网格化调用参数并得到模型结果,根据模型结果对模型的bic结果进行选择,选择出bic结果最小时的模型参数,并记录此结果作为下次预测的已有参数。参数的调参范围如下表1所示。
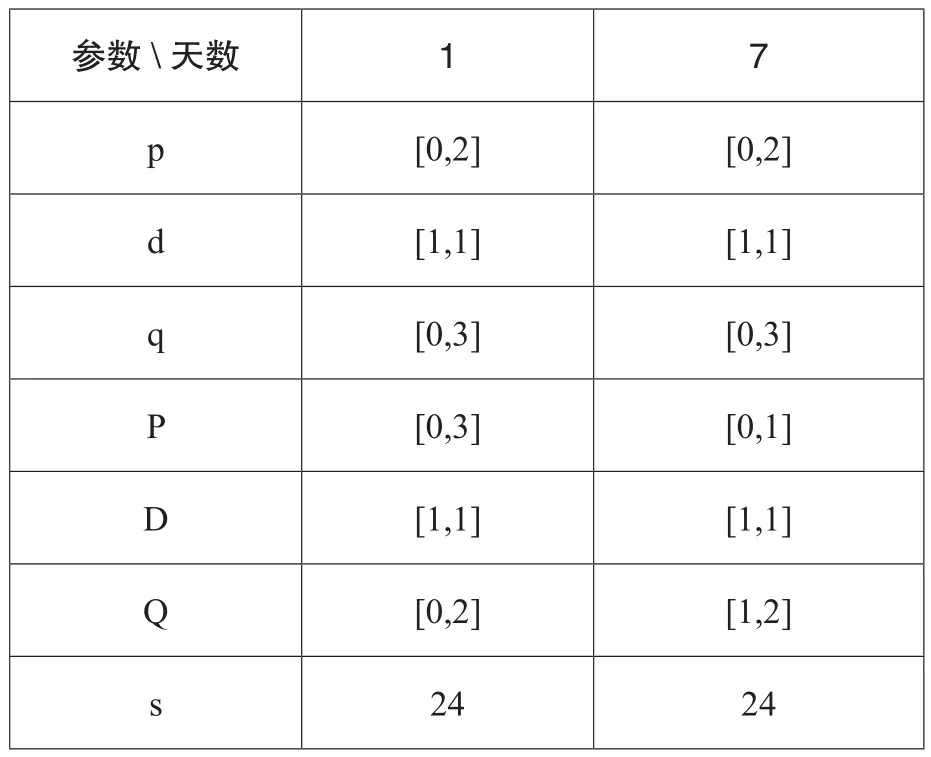
表1 参数的调整范围
其中,p自回归模型AR(p),该模型描述当前值与历史值的关系,可以通过变量本身的历史数据对自身进行预测。q移动平均模型MA(q),该模型关注的是自回归模型中的误差项的累加,能有效地消除预测中的随机波动。
3.4 预测结果及误差分析
使用SARIMAX模型预测,模型中的训练数据采用我国西南地区A市的真实数据,抽取了该市两个区域的历史数据进行分析预测。
用预测值和测试集数据对比,得出预测结果与实际值的相对误差来初步判断预测结果。通过平均绝对百分比误差MAPE (Mean Absolute Percentage Error)来判断模型整体的拟合及预测效果,其中MAPE值越低,说明拟合和预测效果越好。MAPE的值小于10%,说明预测有较高的精确度;MAPE的值在10%-20%之间表明预测精度良好,平均绝对百分比误差判断标准的公式如下。
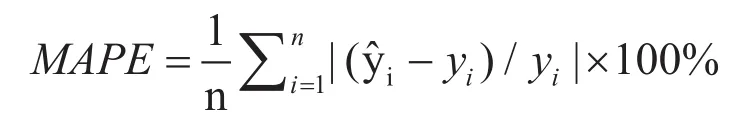
下图为不同区域的水量预测结果和实际数据的拟合曲线。下面两张图中可以看出预测结果的平均绝对百分比误差都在5%之内,表明预测结果具有较高的精确度。
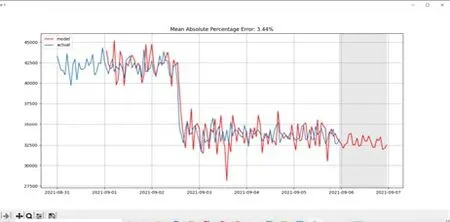
图1 区域一的预测数据
图2 区域二的预测值与真实值曲线
4.系统设计与实现
对于整个系统实现来说,历史水量数据的获取是关键,本文通过对底层物联网数据的采集,每块水表间隔15分钟上传一次数据。结合水务集团实际的供水分区,将A市划分为多个用水区域,区域边界数据通过远传大表将数据接入到系统中。远传数据经过处理后,将小时的用水量数据存入库。
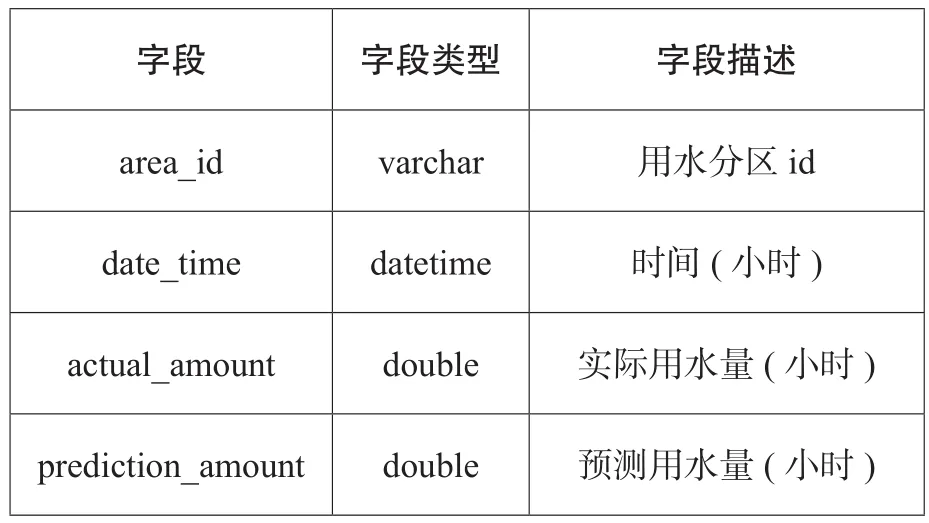
表2 区域用水量数据表
本文将模型算法中的温度、湿度、降水量这些外生变量的数据维护到系统中,因为不同分区都在同一个城市,所以将所有分区的外生变量数据都维护到同一张表。预测时可以直接从这里获取计算数据,缩减算法的计算时间。外生变量的数据维护关系如下表。
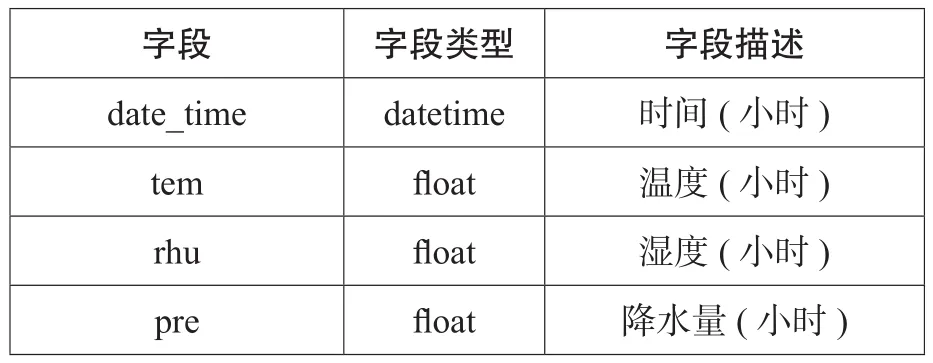
表3 外生变量X数据表
在执行预测算法之前,先从数据库中获取最优的参数集合,然后将这些参数进行序列的平稳性检验和白噪声检验,如果平稳性检验p值小于0.01,并且白噪声检验值大于0.05时,认为当前参数可以使用,否则重新计算p,q,P,D参数。当这些变量因子的数据都确定后,进入水量预测阶段。
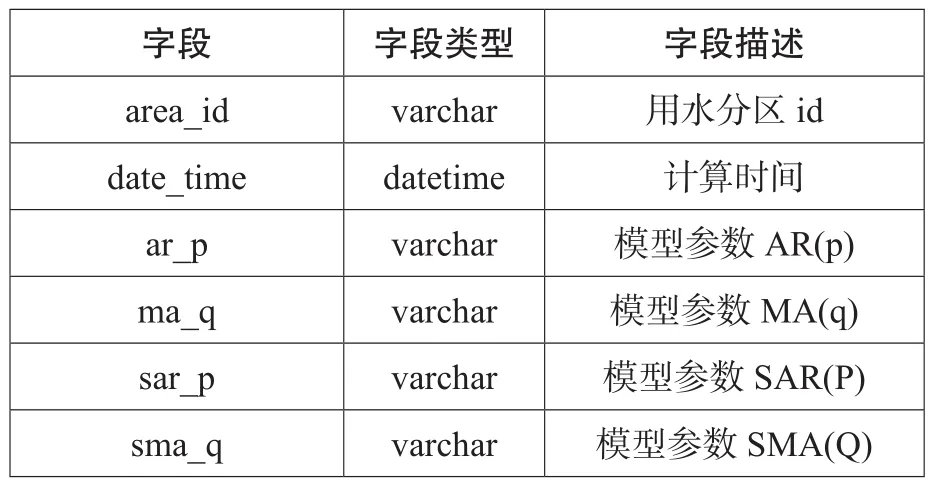
表4 SARIMA影响因子表
系统展示页面,将不同区域的水量数据分开展示,默认将24小时的预测数据和当天的真实数据通过对比的方式进行曲线展示,下图是具体区域的预测数据。
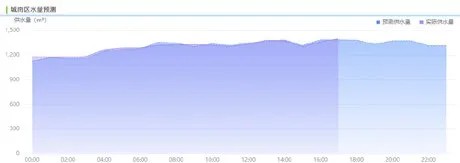
图4 预测值和实时值曲线对比展示
5.结论
城市用水量预测城市水资源管理和城市供水管网系统的优化调度提供数据指导,预测结果的准确性决定了决策的合理性和科学性。
本文根据历史的小时用水量,通过历史数据预处理、相关性分析,引入外生变量,构建时用水预测模型。预测结果平均绝对百分比误差较小,表明基于SARIMAX模型区域用水量短期预测具有较高的精度。同时本文已将该算法模型集成到了业务系统中,系统在实际的运行过程中,能较好的预测未来24小时以及未来7天的区域用水量。根据预测值,结合历史相似的水量数据,获取水厂水泵的历史运行情况,为水厂未来1天或7天的水泵开停计划提供有力的支撑。
