基于主题情感联合分析的游客画像研究
2022-06-16李少波
李 琴,李少波,胡 杰
(1.贵州财经大学 大数据统计学院,贵阳 550000;2.贵州大学 机械工程学院,贵阳 550000)
0 概述
游客画像是对游客属性标签化的过程,主要应用于旅游目的地的精准营销、个性化服务、游客行为分析、舆情治理等方面,是实现智能化旅游的关键。酒店作为旅游经济过程中的重要因素,与旅游经济起着相互促进的作用。酒店是否符合现阶段游客的需求成为游客衡量旅游目的地的重要因素之一。通过挖掘分析获取不同群体的需求或喜好特点继而推荐符合不同群体需求的酒店,是提升游客体验和酒店运营的有效手段。现代旅游过程以社会互动和旅游信息交换为特征,其产物——游客生成文本,能够反映游客的喜好、感知和需求信息,通过对游客生成文本进行分析,准确获取不同群体的情感喜好等信息对旅游酒店推荐具有重要意义。
随着深度学习的发展,以文本数据为主的自然语言处理技术异军突起[1],在主题挖掘和情感分析等领域取得重大进展[2]。在大多数情况下,文本的主题和情感仍被割裂开来分析,然而在实际情况中,通常要求主题和情感具有相互指向性,例如“美丽的”指向具体对象如“花园”或“花园”指向情感要素如“美丽的”。如何进行主题和情感的联合分析成为研究热点。大量无监督主题情感分析模型应运而生,如JST 模型[3]、ASUM 模型[4]、JMTS[5]等。这类无监督主题情感模型认为词的生成与主题和情感都相关,通过对每个句子或每个词进行情感标签和主题标签采样,以生成句子的主题和情感对。另一类无监督主题情感模型(如WLDA[6]、TSLDA[7]、JST-RR[8]等)通过引入先验知识(如互信息、主观性词典、主题意见词对、文本情感等),在获取主题的同时提升情感检测率。这类模型并不是完全无监督,其利用先验知识诱导先验,从而增强主题模型的稀疏性。这2 类模型均以隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)为基础模型,具有较强的挖掘能力。LDA 作为一种贝叶斯生成模型,主要依赖于关键词词频信息。但是LDA 模型缺乏先验信息的指导且仅适用于长文本的分析,采用吉布斯采样进行后验分布计算,当文档数量多而主题个数较少时,LDA 模型的训练速度相对较慢,并且需要在数学上重新推导新的推理算法进行更改。LDA 作为一种无监督模型,缺乏标签的约束,其训练得到的主题通常表达解释能力较差。有监督学习利用标签数据的正向回馈,其准确率优于无监督学习[9]。SLDA 模型[10]将元数据作为标签(如情感评分等),以辅助推断和预测标签相关的主题,相对无监督的LDA,该模型具有更优的预测能力。
LDA 作为概率主题模型中简单且经典的模型,为主题模型提供了一个标准框架,在学术界和工业界具有广泛的研究和应用价值,但其自身的局限性却不容忽视。随着变分自编码(Variational Auto-Encoders,VAEs)模型的提出,使用变分自编码深度学习在特征提取方面(如情感、主题等)取得巨大的成 功[11-12]。VAEs 是一种深度生成模型,又称为AEVB 算法,该模型基于变分的贝叶斯理论,将编码器和解码器设置为神经网络,通过迭代优化过程学习最佳的编码-解码方案。结果表明[13],相比使用吉布斯采样的LDA 主题模型,VAEs 在主题模型上的应用能够有效挖掘主题,且更易扩展。此外,重参数化技巧RT(Reparameterization Trick)及SGVB 估计算法建立AEVB 算法的梯度反向传播机制。RT 在技术方面的提高使得更多的分布能被应用在VAEs中,同时为VAEs 近似复杂概率模型提供更多的可能性。
研究工作表明[14-15],先验分布的复杂度及超参数的选择对于深度生成模型或贝叶斯神经网络的性能具有重要意义。本文提出基于变分自编码的有监督主题情感联合分析模型SJST-VAE。通过先验知识和情感标签辅助主题的训练和生成,利用截断高斯模型变分参数构造适合主题挖掘过程的神经变分推断形式,采用主题分布下的情感分类预测实现主题情感的联合分析。
1 相关工作
变分自编码在主题概率模型中得到广泛应用[16]。LDA 的任何变体都需派生自定义推理算法,然而变分自编码具有较强适应数据特征的能力,其推理方法为隐藏变量建模提供强大的架构,具有更强的可扩展性。AVITM(Autoencoding Variational Inference for Topic Models)模型[13]通过构建变分自编码与主题模型的桥梁,降低Dirichlet 先验和组件坍塌(类似于先验信任的局部最优)对AEVB 算法产生的影响。针对传统主题模型在短文本上表现较差的问题,文献[17]利用词向量和主题向量的点积构建词的主题分布,并定义了词的上下文表征以区分一词多义的现象,提出一种利用词向量语义关系辅助主题挖掘的嵌套变分贝叶斯的主题模型。文献[18]提出使用Gumbel-Softmax 模型和高斯混合模型建模变分自编码主题类别分布,解决局部最优的问题,并分析选择不同分布模型对主题生成的影响。文献[19]利用动态因子图模拟主题在时间上的动态变化,基于变分自编码构建动态的主题模型。针对传统主题模型无法动态确定主题数量的问题,文献[20]基于自编码变分推断的架构,提出一种循环神经主题模型,以发现从概念上无界限的主题。这些模型虽然根据变分自编码易扩展的特性展现出在主题挖掘上的优势,但是缺乏主题的情感指导或主题与情感的联合分析。
主题情感的联合分析是一种细粒度的意见挖掘,其目标是从文本主观评论中获取情感倾向的观点或情感要素。在旅游领域中具体的实际应用尤其是旅游推荐具有重要意义。结合深度学习的思想,基于方面或目标实体的情感分类(TABSA)虽然在挖掘文本特征信息和对应情感属性上取得较大进展,但是大多依赖于文本类别、特征属性及对应情感类别的标注,使得实际工作面临较大的困难。传统的无监督主题情感模型在一定程度上解决数据标注缺乏的问题,但因计算复杂度高且时间消耗久等问题,导致模型难以扩展。变分自编码主题模型的实现成为解决该问题的关键。文献[18]基于传统情感主题联合模型JST,预先定义特征种子词,通过对AVITM 模型进行扩展,实现变分自编码的无监督情感与主题的联合分析。但是任何无监督的模型都无法假设现实中的所有情况[10],其相较于有监督模型的准确率较低。根据当前旅游社交网站中文本评论及情感评分易于获取的特点,本文基于AVITM 模型,以逻辑或知识表示先验知识,利用情感监督主题的识别辅助预测情感分类,从而实现主题情感的联合分析和酒店游客的特征画像。
2 LDA 模型
LDA 模型由Dirichlet 先验的主题分布得名,Dirichlet 先验的选择对于可解释性主题的获得具有重要作用。在LDA 模型中,主题被看作相关主题的词汇分布,每个文档被看作多个主题的分布。为生成文档d,该过程会随机选择主题的分布θd,通过从主题分布中随机选择一个主题zd,n,从相应主题或主题的词汇分布βk随机选择一个词来生成文档中每个可观测词wd,n。因此,LDA 中文档d的生成如下:
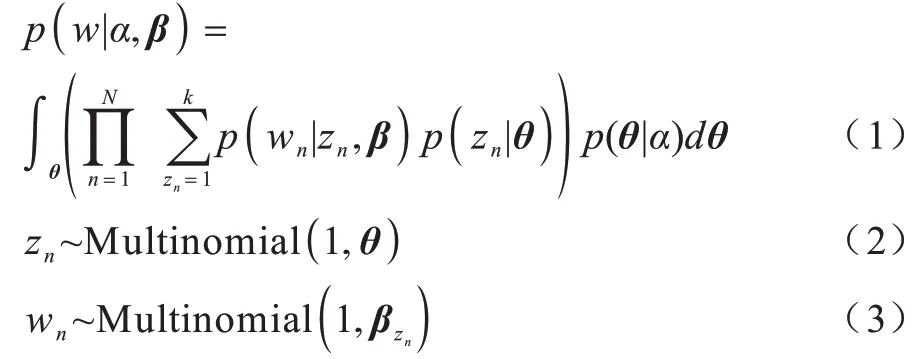
其中:α为Dirichlet 分布的超参数。在多项分布假设下,θ和β之间的耦合导致隐变量θ和z后验分布的推理难以计算,需要借助各种近似方法。LDA 模型采用吉布斯采样方法,即一类MCMC(Markov Chain Monte Carlo)算法,通过抽取大量样本估计真实的后验分布,但该方法计算复杂度高且时间消耗量大。
3 变分自编码框架下主题分布的参数化
针对LDA 模型中后验分布难以计算的问题,研究人员提出变分推理方法,通过优化过程寻求一种变分分布近似真实的后验分布。MFVI(Mean-Field Variational Inference)方法是一种比较经典的变分推理方法,但是由于计算原因难以扩展到新的模型。AEVB 算法旨在以一种“黑匣子”推理方法来解决该问题,该算法利用推断和学习使得简单的采样就能进行有效的近似推断,不需要复杂的迭代推理方式(如MCMC)。
在LDA 模型中,隐变量z是离散变量,无法进行重参数化处理,通过求和运算折叠z变量,即将式(1)转变为:
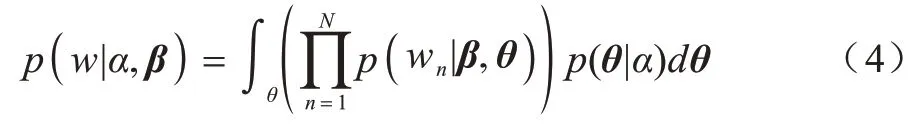
其中:wn|β,θ~Multinomial(1,βθ)。
因此,后验分布难以计算的问题转化为评估θ和β的分布。VAE 使用自编码学习θ和β的分布,同时通过拉普拉斯将原始Dirichlet 先验分布近似为变分分布。在LDA 主题模型中,主题变量的先验θ=(θ1,θ2,…,θK)(K为主题个数)被定义为Dirichlet 分布,经过变分推理,主题变量的Dirichlet 先验p(θ|α)通过拉普拉斯被近似为一个多元高斯分布。多元高斯分布由均值向量μ和对角协方差矩阵Σ定义,其中,所以p(θ|α)近似为q(θ)=LN(θ|μ,Σ),其中LN是逻辑正态分布。逻辑正态分布更能促进主题一致性。
通过拉普拉斯近似计算得到多元高斯分布的均值向量μ和对角协方差矩阵Σ,如式(5)和式(6)所示:
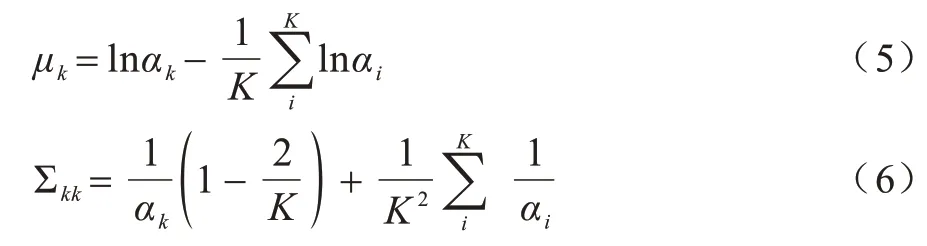
在变分自编码框架下,将观测数据文档w词序列作为输入,将2 个推断网络作为前向神经网络,其中,δ为推断网络的参数,即变分参数,,从而估计的值,每个网络的输出均为K维向量。
变分分布的构造有多种形式,高斯分布是其经典的变分分布形式。在变量原始分布未知的情况下,高斯分布可以为噪声和不确定性建模。通过高斯先验分布和RT 技术为变分分布建立无偏差或低方差的梯度估计器,如SGVB。
3.1 单高斯分布模型
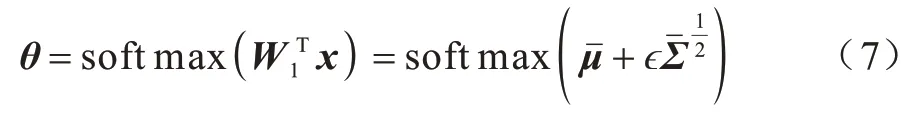
θ服从单高斯分布模型(Gaussian SoftMax,GSM),即:
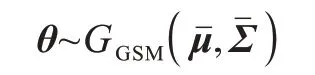
其中:W1为线性变换权重,偏差项做了省略处理。
3.2 截断高斯模型
SB(Stick-Breaking)过程被用于主题变量Dirichlet过程的建设性定义,为其先验提供初始关联权重。在截断高斯(GSB)模型构建过程中,通过逐次分割单位为1的区间顺序获取高斯先验,其中θk表示每个分量。SB 构建过程如图1 所示。
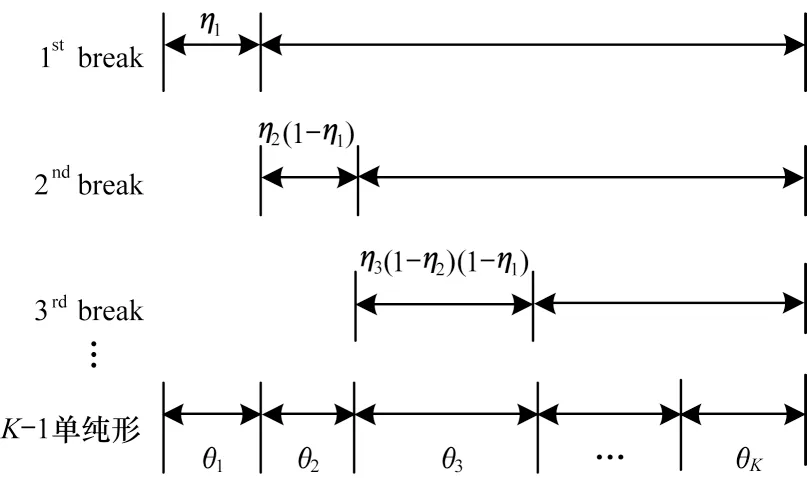
图1 SB 构建过程Fig.1 SB construction process
设第1个类别的概率为分割比例η1,其余比例1-η1为后续的分割计算。高斯先验的每一维计算如式(8)所示:
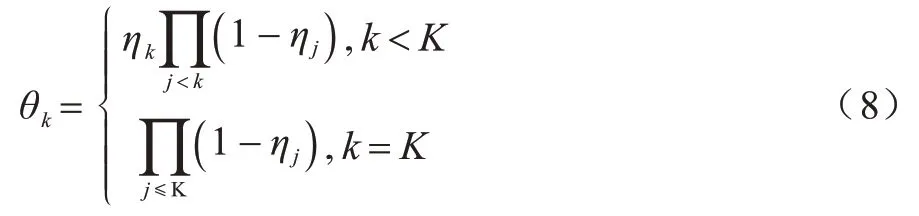
不同的K值需满足=1。多项式概率参数的建模被转化为二项式概率参数的对数建模。
设高斯样本x∈RK,W2∈RK×(K-1),则,其构造过程如式(9)所示:
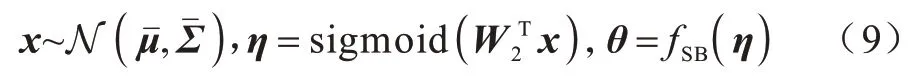
与Dirichlet 过程的SB 定义相比,高斯过程的SB为神经变分推断提供更合适的形式。在高斯先验的分配过程中,SB 构建过程缺乏控制力,SB 先验可以更好地保留类别边界,为半监督学习提供有效的正则化。同时,SB 过程能够降低模型对主题数量变化的敏感度,更具稳定性。
4 本文模型
无监督主题模型缺乏有效先验知识的指导或监督学习中数据的标注。针对该问题,本文基于LDA模型,引入词频相对主题的权重,以影响主题的先验分布,从而指导主题的生成,同时通过情感标签监督生成主题,利用主题特征预测情感分类,从而实现主题情感的联合分析。本文模型SJST-VAE 以VAE 为主要架构,主要由先验知识的指导、情感标签的监督、变分目标损失函数的计算和主题情感的联合分析这4 个部分组成。SJST-VAE 模型架构如图2所示。
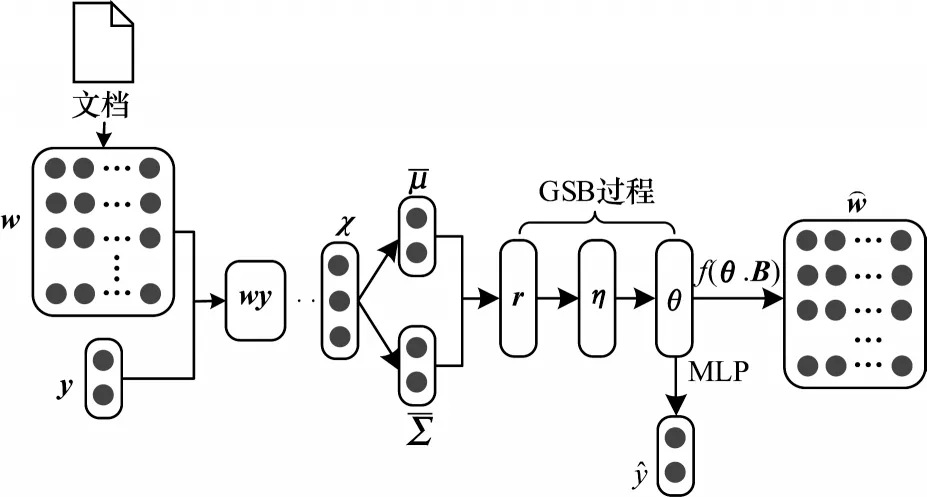
图2 SJST-VAE 模型架构Fig.2 Framework of SJST-VAE model
4.1 先验知识的指导
VAE 架构的优势是为编码网络提供一种可以引入先验信息的扩展方法。本文模型SJST-VAE以词的Bagof-words 表征作为输入,通过变分自编码网络获取文档的特征。此外,针对文本中权重过高的词大多不能进行局部主题表示的问题,如IMDB 语料库中,单词“film”或“movie”在主题模型学习中往往相对不重要,本文通过弱化词频过高的词,设置背景术语从而获取相对常见的词,以此促进主题的一致性。
假设语料由D个文档组成,语料词典大小为V,如图2 所示,在变分自编码网络框架下,SJST-VAE 模型以文档词序列w作为输入,通过2 个MLP 推断网络变分近似为具有对角正态先验的文本表征r,即,如式(10)所示:

从而获得r的近似后验分布,如式(11)所示:

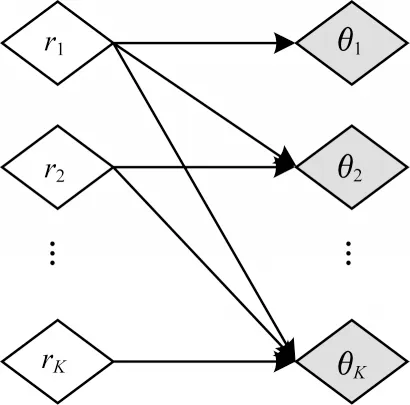
图3 SB 映射过程Fig.3 SB mapping process
单纯形θ如式(12)所示:

本文设置稀疏诱导先验,即正态指数复合先验,置于权重矩阵B∈RK×V(主题词分布矩阵的初始化),使模型学习到词频相对主题的权重信息,同时定义背景术语d∈RV,表示词频中所有词的词频对数值,旨在通过B与d的偏离程度将主题权重倾向于文档中出现频率大致相同的常见词,而不是词频过高的词。权重矩阵B的正态指数复合先验过程如式(13)和式(14)所示:

其中:ξ>0 为指数分布率参数。重构文档为:

整个神经网络的损失函数如式(16)所示:

4.2 情感标签的监督
除了能有效推断文本主题外,本文模型SJSTVAE 还能推断文本的潜在表达及预测文本的情感倾向,利用情感标签对主题生成前后进行监督。生成主题后的监督是在可观测词的条件下,完成主题模型的变分自编码解码的过程,利用多层神经网络进行训练,将预测标签与真实标签的交叉熵作为损失函数,从而实现情感标签的预测。情感预测标签的计算如式(17)所示:

其中:fy为多层神经网络。
在主题生成过程中,情感标签还用于监督主题训练过程,以促进局部主题的生成。SJST-VAE 模型在预测情感标签时,利用one-hot 编码表征文档的情感标签ey,并对编码器网络进行训练,情感标签ey被用于构建文本表征的特征,如(18)和式(19)所示:

其中:fg为多层感知器;Wx和Wy为线性权重参数。
在训练过程中,情感类别标签作为可观测变量。在测试时,本文模型考虑所有可能的情感标签向量,如正向或负向,使得文档中所有词概率对数和最大的标签为所预测标签,如式(20)所示:
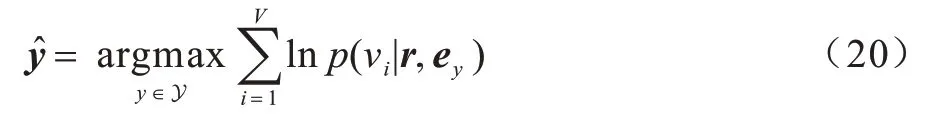
其中:vi为词典中的词,i={1,2,…,V}。
4.3 变分目标损失函数
与传统变分推理类似,SJST-VAE 模型构造一个Dirichlet先验的拉普拉斯近似,使Dirichlet分布可以近似为逻辑正态分布。本文假设Dirichlet先验是对称的,即所有超参数α取相同值,由式(5)和式(6)可得:

在变分自编码架构下,本文设计高斯变分分布,以近似后验分布qδ(r|w,ey)。模型学习的目标是使近似后验分布尽可能接近于真实后验分布p(r|α)。本文采用KL 散度进行相似度计算,找到能使KL 散度尽可能小的变分参数,如式(22)所示:

通过一系列计算推演,式(22)转换为使变分下界ELBO 最大化,其变分下界如式(23)所示:
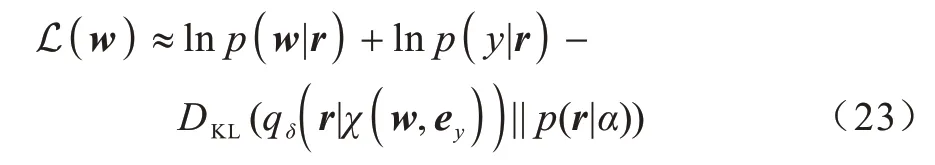
其中:KL 散度为正则项;其他部分为重构损失。KL散度如式(24)所示:
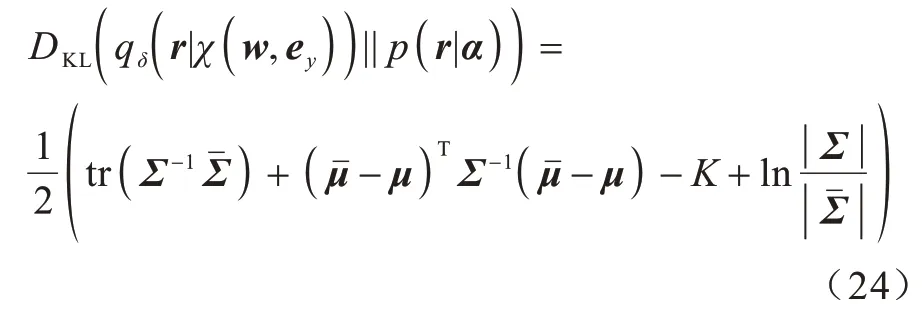
4.4 主题情感的联合分析
SJST-VAE 模型通过变分自编码网络获取各文档的主题分布,并将其作为输入,通过文档的情感监督对MLP 神经网络进行训练,从而实现情感分类的预测。
本文假设文档数据集有K个主题,并将只包含第k个主题的文本主题分布tk定义为除第k个分量为1 外,其余各分量均为0 的向量。因此,为获得第k个主题的情感分布,模型以tk作为输入向量进行情感预测,其中k=1,2,…,K,以获取各个主题下的情感概率分布。
5 实验结果与分析
5.1 数据集与参数设置
本文将IMDB 语料集作为评估SJST-VAE 模型的数据集,该数据集包含50 000 条电影评论,其中25 000 条负面评论和25 000 条正面评论,且训练集25 000 条和测试集25 000 条。在数据集中所有单词通过预处理均被转化为字母小写形式,并删除了标点符号、数字及小于3 个字符和停用词表中的所有单词。词典由在大多数文档中都出现的单词组成,大小设为2 000。在模型训练过程中,本文使用softplus 激励函数、Adam 优化器(参数设为0.99),学习率设为0.002,批量大小设为200,ϵ采样数量设为1,训练迭代次数设为200。在测试文档估计ELBO值时,ϵ采样数量设为20。
5.2 评估标准
SJST-VAE 模型是基于情感监督进行主题情感联合分析。研究人员给出不同的衡量标准,如困惑度、相关性、稀疏度等,以客观评价主题获取的优劣程度。困惑度表示文档属于哪个主题的不确定性,困惑度越低,聚类效果越好,主题与主题的区分性越强;相关性表示模型获取主题的top-n个词的语义一致性,一致性越高表示主题可解释性越好;稀疏度在一定意义上表示模型的可解释性,因为每个主题能够接受被描绘的词往往是有限的,主题的词分布矩阵越稀疏(即稀疏度越大),可解释性越强。虽然这3 种评估标准具有一定的有效性,但其不能完全作为评估标准,有时需要直观的主题表示进行评估。模型主题困惑度如式(25)所示:
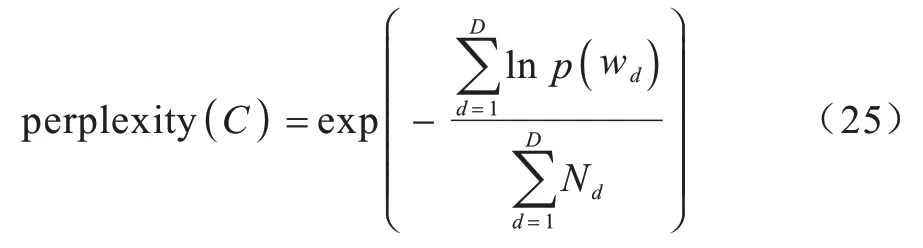
其中:C为测试语料且包含D篇文档;Nd为每篇文档包含词的数量;p(wd)为文档d中词产生的概率。
本文采用NPMI(Normalized Pointwise Mutual Information)对文本语料主题相关性进行评估。PMI主要用于度量一些词的共现,以此判定词的相关性,PMI 如式(26)所示:
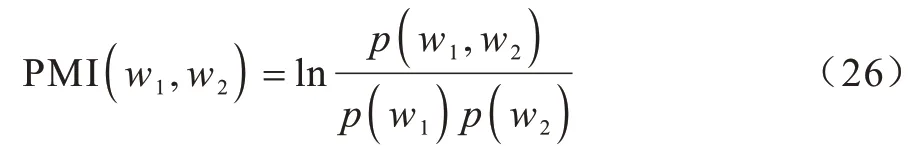
对于PMI 的正则化有多种选择,如通过-lnp(w1)和-lnp(w2)的乘积或通过-lnp(w1,w2)正则化。本文以后者作为正则化选项,该正则化过程规范了上限和下限,具有较优的性能。因此,NPMI如式(27)所示:
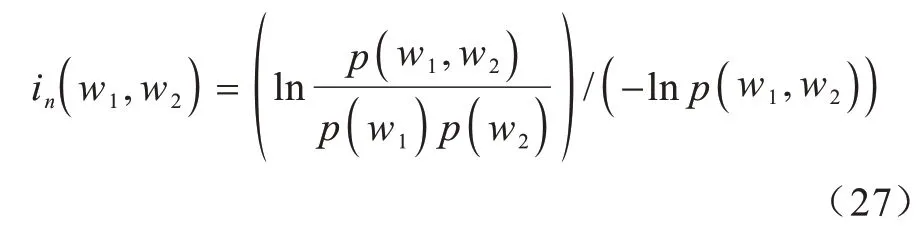
5.3 模型评估与结果分析
本文研究先验知识和情感监督对主题获取的影响,因此,评估分析了模型在相同实验条件和参数设置条件下有先验知识和无先验知识的性能对比,以及有情感监督和无情感监督的性能对比,并验证了在GSM 和GSB 构造下不同主题数目设置对主题分布性能的影响。为验证本文方法的有效性,本文将SJST-VAE 模型与其他3 种基准主题模型进行对比。这3 种基准模型分别为LDA、SAGE(Sparse Additive Generative Model)[19]、NVDM(Neural Variational Document Model)[20]。
IMDB 语料的平均主题分布如图4所示。从图4可以看出,在GSM 过程中获得100 个主题的平均主题分布情况大致相同,而在GSB 过程中的平均主题分布值在接近第10 个主题位置后逐渐递减,在大概第20 个主题后递减速度尤为明显,直至第40 个主题后几乎没有分布。这是因为GSB 过程在建立混合模型时,其SB 结构隐含地假定了主题的顺序,前一个主题获得足够的梯度来更新主题分布。同时,SB 结构的稀疏性使得尾部的主题被采样的可能性较小,模型对于超参数(主题数目)的变化会变得不太敏感,当主题设置数目远远超过模型需要的数目时,GSB 过程的稳定性更强,而且更加有利于主题数目的设置。

图4 IMDB 平均语料主题分布Fig.4 Average topics distribution of IMDB corpus
主题数为10~100 及100~500 时随模型测试集困惑度的变化情况如图5 所示。从图5 可以看出,主题数从10~100 的变化过程中,GSB 过程的主题困惑度略优于GSM 过程,随着主题数从100~500 逐渐增大,GSB 过程在主题困惑度上表现出的优势越来越明显,说明GSB 过程不会因主题数目变化而发生大幅波动,验证了GSB 过程的稳定性。

图5 主题困惑度随主题数的变化趋势Fig.5 Trend of topic perlexities with number of topics
现有的主题模型主要在数据集20newsgroups进行训练,该数据集缺少情感标签数据。因此,本文以IMDB 数据集为对象,选择具有代表性的基准模型对主题挖掘性能进行评估。LDA 是经典的模型,几乎所有模型都以此为基础;SAGE 模型引入恒定背景分布的对数频率,以防止过度拟合,即通过稀疏诱导先验加强模型主题的稀疏性,具有较强的鲁棒性;NVDM 模型首次将神经变分框架的生成模型引入到文本建模中,旨在为每个文档提取一个连续的语义潜在变量,并应用于构建主题分类。
本文将主题数目设置为10 和50,不同基准模型的主题困惑度、相关性和稀疏度的对比结果如表1 所示。
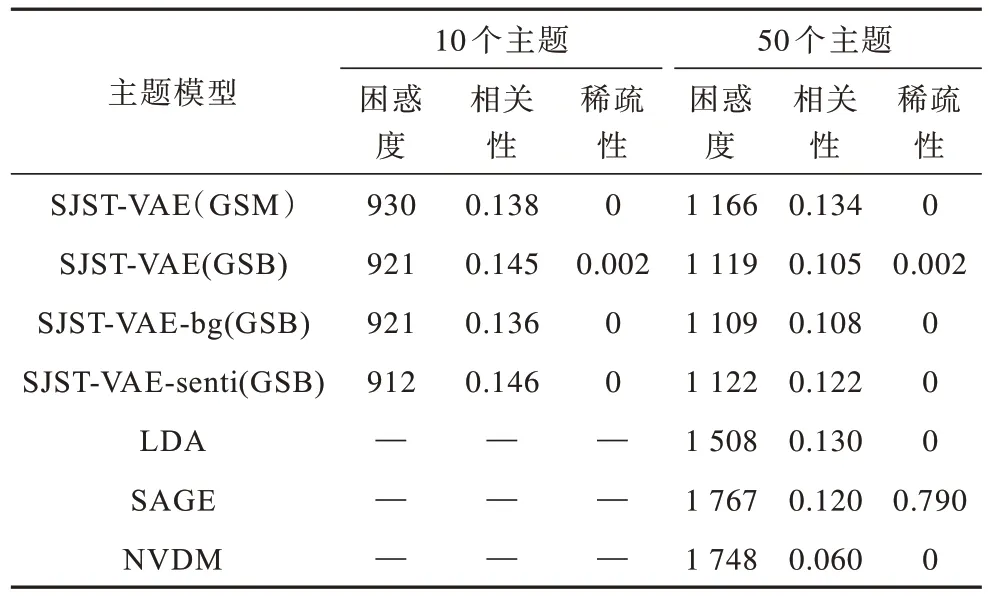
表1 不同模型的主题评估指标Table 1 Topic evaluation indicators of different models
相比基准模型,SJST-VAE 模型在主题困惑度上具有较强的优势;SJST-VAE 模型的主题相关性低于LDA 和SAGE 模型,但优于同是变分自编码框架的NVDM 模型;SAGE 模型的主题稀疏性仍占有绝对优势,SJST-VAE 模型相对于其他模型略有改进。同时,本文对比SJST-VAE 模型在背景术语缺失(SJSTVAE-bg)和情感监督缺失(SJST-VAE-senti)以及GSM 和GSB 过程下的主题性能评估。在主题数目设置为10 和50 时,GSB 过程中SJST-VAE 模型、SJST-VAE-bg 模型、SJST-VAE-senti 模型的主题困惑度均优于GSM 过程中的SJST-VAE 模型,说明GSB过程在主题困惑度的表现上具有绝对优势。当主题数目设置为50 时,SJST-VAE 模型的GSM 过程的相关性具有一定优势。GSB 过程的SJST-VAE 模型相对于SJST-VAE-bg 模型和SJST-VAE-senti 模型的稀疏性略有提高,说明SJST-VAE 模型具有较强的主题可解释性。由于高频背景术语的缺失以及情感词的加入使得模型在主题数目增多的情况下,发生主题一致性降低的情况。其原因为随着主题数目增多时,无明显意义主题词出现的概率会增大,而主题一致性的计算基于词的共现,高频词的缺失和情感词的加入导致词共现率下降。
有情感联合和无情感联合这2 种主题样例对比如表2 所示。本文在主题数目设置为5 的条件下以中文形式分别列举这2 种方式主题的前8 个词。

表2 IMDB 数据集主题样例Table 2 Topic samples of IMDB dataset
从表2 可以看出,有情感联合的主题表示样例大致可以将电影语料的主题概括为色情、犯罪、纪录、动画、恐怖5 种类型,而无情感联合则稍显杂烩,较难概况其主题类型。该过程说明有情感联合可以学习更稀疏、更有意义的表示,其表达的主题关联强,其他主题关联弱的关键词较少,具有较优的表达主题语义的能力,主题解释性更强。相比无情感联合的主题表示,有情感联合的主题表示包含更多的情感词,有利于主题情感特征的获取,具有重要的实际意义。由于引入背景术语先验知识,这2 种主题表示样例中均减少了大量的“movie”、“film”等高频无显著主题表达意义的词的出现概率。
本文将构建SJST-VAE 模型的文本语料的情感预测和主题的情感分布,利用生成的文档主题表征进行情感分类,通过单个主题的表征进行情感分布预测。由于本文主要侧重于挖掘主题的性能,因此不对情感分类准确率与其他模型进行对比。本文分别对10~100 个主题数目进行模型训练,获得在不同主题数目设置条件下的情感分类准确率,并累计计算5 次情感预测准确率总和并取平均值,SJST-VAE模型情感预测准确率如图6 所示。
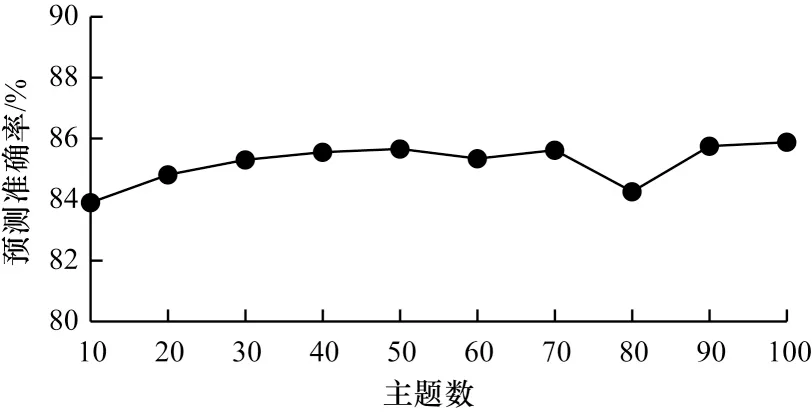
图6 SJST-VAE 模型情感预测准确率Fig.6 Sentiment prediction accuracy of SJST-VAE model
SJST-VAE 模型在低维度文档表达条件下,仍具有较高的情感分类准确率,情感分类准确率并未随主题数增加而大幅波动,具有较强的稳定性。由于电影评论涉及较多情节内容,且其中包含的大量情感词不具有明确的实际褒贬意义,因此本文将在第6 节的旅游具体应用中重点分析主题的情感分布过程,以及其如何用于指导主题的情感特征。
6 基于SJST-VAE 模型的酒店用户画像构建
本文选择一组酒店评论文本集作为分析数据集[21],为验证SJST-VAE 模型在旅游推荐或游客群体画像中的实用性。该数据集中所有评论均来源于TripAdvisor.com 的英国用户评价且每个评论文本均标注了情感极性,并区分了不同酒店级别和男女性别。据调查显示[22],在较高星级酒店的选择上,男性和女性群体分别表现出不同的情感偏好和特征。通过挖掘分析获取不同群体的需求或喜好特点,进而推荐符合不同群体需求的酒店,成为提升游客体验和酒店运营的一个有效手段。
本文选取三星和四星这2 种不同类型的酒店评论各6 400 条,每种类型酒店均包含男女性评论各3 200 条,并以此作为分析对象。整个数据集被划分为4 个不同的特征数据集,如图7 所示。同时,本文将各数据集的80%作为训练集和20%作为测试集(正负评论数量均衡)。在训练过程中,本文设置词典大小为1 000,批量大小设为50。主题个数设为10,既符合旅游酒店属性先验知识,也便于更细粒度了解用户需求和情感。

图7 不同特征数据集的划分Fig.7 Division of different feature datasets
本文针对4 种不同属性的酒店评论数据集分别进行主题情感的联合分析。SJST-VAE 模型在4 种不同属性的酒店评论数据集中情感预测准确率对比如图8 所示。SJST-VAE 模型在训练集和测试集的情感预测准确率均在90%以上,具有较高的准确率,验证了SJST-VAE 模型在挖掘酒店用户评论特征进而获取情感预测的可行性。

图8 在不同数据集上SJST-VAE 模型的情感预测准确率对比Fig.8 Sentiment prediction accuracy comparison of SJST-VAE model on different datasets
SJST-VAE 模型分别对英国三星酒店男性和女性评论提取特征对比如表3、表4 所示。
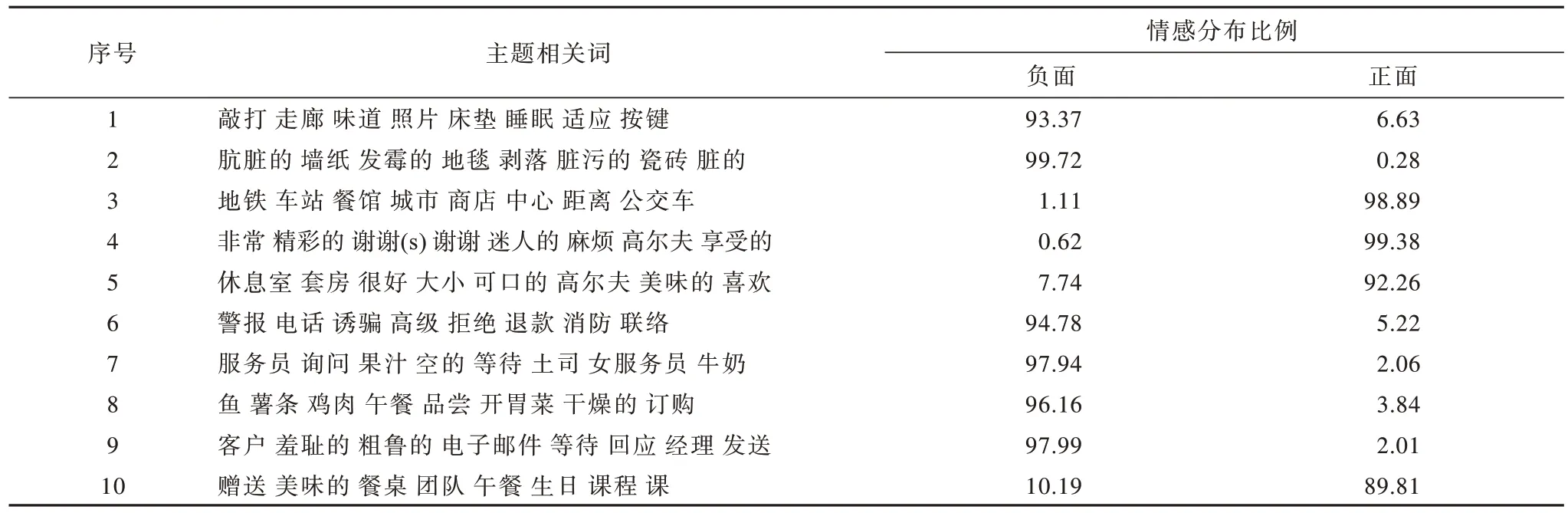
表3 三星酒店男性评论特征Table 3 Feature of male reviews in Samsung hotels %

表4 三星酒店女性评论特征Table 4 Feature of female reviews in Samsung hotels %
男性用户和女性用户均在房间噪音、内饰环境、餐饮、服务质量(包括入住办理、客房服务)上表现出负面倾向,如在内饰环境上的情感特征有“肮脏的”“发霉的”等,在服务质量上的情感特征有“羞耻的”“粗鲁的”“令人震惊的”等。在交通区位、休闲娱乐上,男性和女性均表现出一定的正面倾向,如交通区位上的情感特征有“便捷的”,休闲娱乐上的情感特征有“精彩的”“享受的”“谢谢”等。
女性的负面主题(7 个)多于男性的负面主题(6 个),可以推断女性在三星酒店消费中可能比男性更为苛刻。相较于男性,女性更加注重细节,如房间内饰环境关键词上,女性增加了窗帘、家具的关注,在交通区位关键词上,女性增加了步行、停车、出租车、购物的关注,而男性则只是多了餐馆的关注。另外,在酒店休闲娱乐选择上,男女性也表现出不同的特点,如男性的休闲娱乐相关词有高尔夫等,女性的休闲娱乐相关词有水疗、游泳池、花园等。
SJST-VAE 模型对英国四星酒店男性用户和女性用户评论提取的特征如表5、表6 所示。

表5 四星酒店男性评论特征Table 5 Feature of male reviews in four stars hotels %

表6 四星酒店女性评论特征Table 6 Feature of female reviews in four stars hotels %
与三星酒店类似,男女性用户同样在房间噪音、内饰环境、餐饮、服务质量上表现出负面倾向,如在房间噪音上的情感特征有“打扰”“噪音”等,在内饰环境上的情感特征有“磨损的”“潮湿的”“破碎的”“脏的”等,在服务质量上的情感特征有“封闭的”“慢”“差”等。在交通区位、休闲娱乐、配套服务(如婚礼)上,男性女性均表现出一定的正面倾向,如交通区位上的情感特征有“便捷的”,休闲娱乐上的情感特征有“享受的”“宜人的”“精彩的”“喜欢”等。
男性关注的负面主题(7 个)多于女性的负面(4 个),可以推测四星酒店男性用户较三星酒店男性用户要求有所提高。在餐饮关键词上,男性多关注鸡肉、牛排,而女性更偏向于甜点如蛋糕、奶油和茶等。在房间内饰环境关键词上,男女性用户都关注了地毯、墙,男性相较于女性多了天花板、窗帘、衣柜、厕所的关注,女性则多了床垫的关注。在交通区位关键词上,男女性都关注了购物,男性较女性多了酒吧的关注,女性较男性则多了步行的关注。在休闲娱乐上,男性用户评论的关键词有海滩、海、美味、桑拿、游泳池等,女性用户评论的关键词有护理、蒸汽、水疗、按摩、海、花园等。
通过以上分析,酒店运营者可以从男性和女性用户在不同星级酒店消费过程中所关注的内容和相应感受,获取男性女性用户的不同特征,进而有针对性地从客户偏好层次上进行酒店或房间的推荐。通过对男性女性用户所表现出的负面主题和情感特点进行分析,以促使酒店管理者发现内部不足进而提出改进措施。相对主题和情感的割裂分析,针对主题情感分布的挖掘更具有实际应用价值。
SJST-VAE 模型是基于正负分布均衡的酒店评论数据集,但是表3~表6 所呈现出的用户负面主题却明显大于正面主题,这或许是由于用户的表达习惯所决定的。在评价事物时,负面信息的可诊断性要强于正面信息,消费者会赋予负面信息更高的权重或注意力。对于用户是否习惯于在负面主题的表达更加具象,而在正面主题的表达更加笼统如“太美了、太舒服了、非常享受等”,从而导致模型挖掘到的负面主题方面多于正面,还需要后续大量的实验进行佐证。
7 结束语
为充分捕捉用户细粒度的意见,本文构建基于变分自编码的神经网络训练模型SJST-VAE。利用先验知识和情感标签辅助主题的训练和生成,基于截断高斯模型,构造更适合Dirichlet 过程的神经变分推断形式,其中截断高斯模型中的截断结构能够有效地捕获离散数据中的相关性,适用于主题分类数据的分析。实验结果证明,SJST-VAE 模型能够利用主题分布实现情感分类的预测。酒店运营者通过SJST-VAE 模型获取用户群体的情感偏好或舆情报告,有助于制定详实可靠的改进措施。下一步将把本文模型应用在旅游领域的精准推荐系统中,以实现在不同应用场景下信息的融合与扩展。
