基于大数据神经网络算法的学生成绩分析与预测模型仿真
2022-06-15徐艳华周荣亚
徐艳华,周荣亚
(陕西铁路工程职业技术学院,陕西渭南 714000)
传统的学生成绩分析通常是统计学生已有的考试成绩,通过分析变化趋势来判断学生的学习状况。预测学生的考试成绩乃至重大考试的情况,大多是授课老师凭借经验作出判断[1-2]。但实际上,这种局限于统计性的成绩分析过于浅显,无法挖掘出成绩数据背后的深层特征与关系,例如学习习惯、推理能力、生活影响等众多因素。目前的预测模型无法满足日常教学目的,更无法实现预测学生成绩的功能;反之,其他对成绩有影响的大量信息,如睡眠状况、意外情况、偏科等也未考虑进预测模型中[3-4]。
与学生成绩的分析和预测类似,已有的大量研究成果均是用于对运动员成绩的分析预测。其经常采用混沌理论、机器学习、决策树算法等实现。近年来,随着大数据与人工智能技术研究的愈发成熟,其已被广泛应用到更多工业、生活与教育的场景中。多位学者研究了基于大数据的运动员战术、成绩分析等算法和模型[5-7]。在教育领域,已有多篇关于大数据下的网络教育成绩预测,提高成绩的大数据服务、学业分析预警等文献[8-9]。大数据具有样本数量较大、分布均衡、便于分析的特点,这与国内学生人数较多、难以采样、分析困难的现状相互吻合,为学生成绩分析和预测提供了理想的解决方案[10-12]。
1 学生成绩分析模型
1.1 数据预处理
学生的成绩不仅与个人的考前准备、考时状态有关,还与客观的试卷难度有关。为了比较学生每个学期的成绩变化趋势,应对数据进行预处理,消除客观因素对分析学生成绩时的影响[13]。
一次考试的成绩分布包括3 种:正态分布、正偏态分布和负偏态分布。其中正态分布表明处于中等水平占大多数,高分和低分只占少数,为合理分布情况;正偏态分布表明高分人数占优,可视为由于试卷偏简单所导致;负偏态分布表明多数人成绩偏低,可视为试卷偏难导致[14]。成绩分布情况如图1 所示。

图1 成绩分布
文中采集某高校电子信息专业的在校本科生,前4 个学期的成绩作为样本数据进行分析。特征分布如表1 所示。
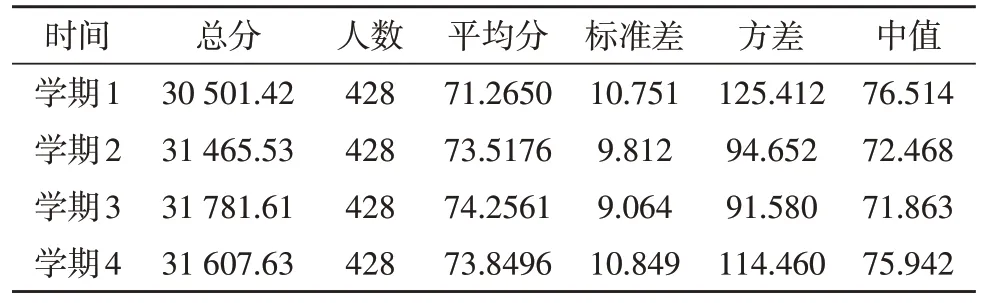
表1 学生成绩数据特征
对采集到的数据进行偏态量分布判断,如下:

其中,SK为Pearson 偏态量,KU为峰态系数,M为平均数,N为众数,Q为标准差。SK=0 时,为正态分布;SK>0,为正偏态分布;SK<0,为负偏态分布。判断得到的检验结果如表2 所示。
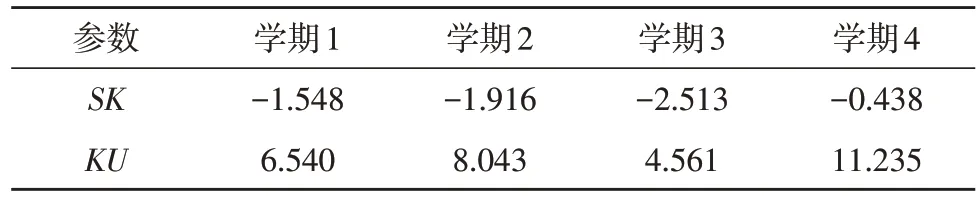
表2 偏态量检验表
从表2 可看出,第4 学期的试卷难度总体偏高,第3 学期的平均成绩最高,且分布更加集中。
假设xi为某个学生某一学期的成绩,则作如下变换:
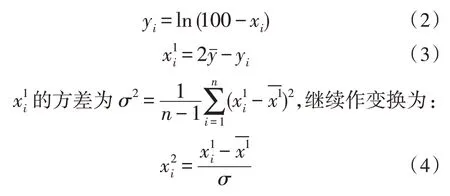
得到的是均值为0、方差为1 的正态分布。因此消除试卷难度产生的客观误差,使用作为标准化数据对学生成绩进行评估。
1.2 成绩稳定度分析
使用原始数据对各分段的人数进行统计分布,如表3 所示。
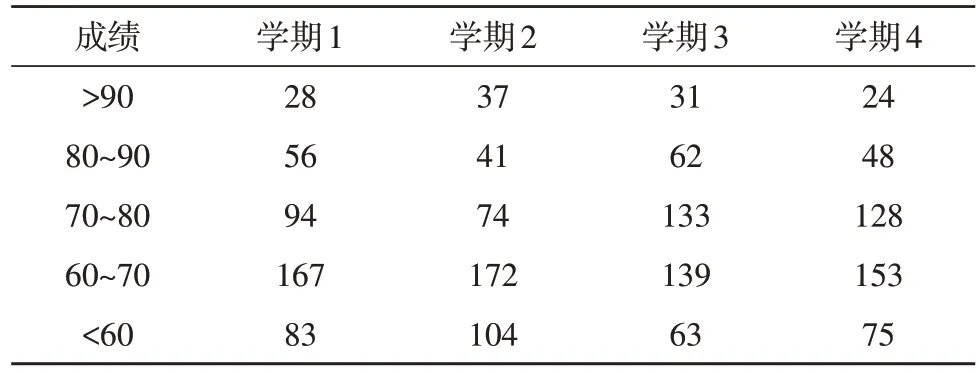
表3 成绩分布
从表3 可看出,高分段(80~90)的学生波动较小,较为稳定;较低分段(<70)的学生波动较大,总体呈现分数提高的趋势。
1.3 成绩进步程度分析
使用经过预处理的当前学期成绩减去上学期成绩,并计算出差值的平均值,即可得到平均成绩的进步率。对每位同学的进步率做出散点图,如图2所示。
从图2 中可看出,成绩在平均分以下的同学,略有退步;成绩在平均分上下的同学进步和退步程度波动较大;成绩较优的同学进步较小。且成绩较差和成绩较优的同学分布均较稀疏,进步与退步情况变化较小,平均分附近同学的人数最多。
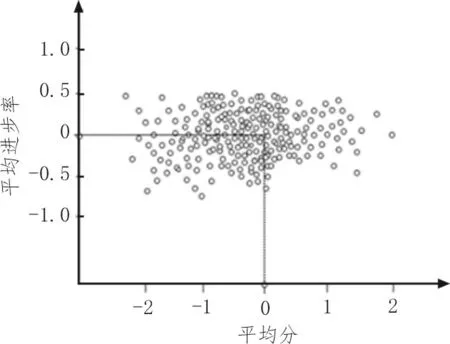
图2 学生进步率分布图
1.4 学生学习状态分析
使用层次分析法结合模糊分类来评价学生的学习状态。层次分类如图3 所示。

图3 层次分类
首先对所有的成绩分析数据归一化,每个数据除以该数据集的最大值,然后使用层次分析法计算权值矩阵。
第1 层的权值矩阵可由成绩情况、进步情况、个人情况3 个变量的相对重要程度对比得到:

第1 层的权值向量为:W1=(0.342 0.576 9 0.081)。经过可行性校验,成立。
第2 层的权值矩阵由每学期成绩考核的重要程度确定:

得到权值向量为:W2=(0.095 4 0.160 1 0.277 2 0.467 3),可行性检验成立。
成绩进步度的权重同样随着学期递增,构造的权重矩阵为:

得到权值向量为:W3=(0.163 4 0.296 9 0.539 6)。
设成绩向量、进步度向量、波动向量为:M=(m1,m2,m3,m4),S=(s1,s2,s3)、U,则综合成绩评价:最终计算出每位学生的综合评分,进行成绩排名等操作。
2 成绩预测模型
由第1.4 节所述的层次分类图构造遗传神经网络模型,以预测学生的下一次考试成绩。模型结构如图4 所示。

图4 成绩预测模型结构
2.1 遗传BP神经网络模型
BP 神经网络为多层前馈神经网络,每层连接的权值和阈值由网络训练得到。神经网络的结构如图5 所示[15-16]。

图5 BP神经网络结构
遗传算法的运算过程如下:
1)算法的初始化,随机生成一组可行解。
2)对每一组可行解使用适应度函数计算其适应程度,进而计算进化中该可行解被选中的概率,计算公式为:

3)选择上一代的两个可行解,将某一位置切断,然后再拼接,得到一个新的可行解,最终得到N~M个可行解。
4)在第3)步生成的新可行解中,随机修改其中几个变量值,引入变异。
5)选择上一代适应度最高的M个可行解复制。
6)生成N个可行解,一轮进化完毕,回到第3)步,进行新一轮进化。
7)当进化得到的可行解在误差范围内,则结束进化;否则,继续进化。
2.2 模型构建
在成绩预测模型中,引入遗传算法来求取进化过程中的每一代可行解,从而得到使神经网络的误差平方和最小的网络权值与阈值。遗传算法和神经网络的关系为:遗传算法中的适应度函数与每一个可行解的神经网络训练误差成反比:

其中,oi为神经网络输出预测成绩数据。
首先根据上式计算出某代可行解的适应度值fc,然后用该适应度值除以总适应度值。假设共有C个可行解,则选择单个可行解c作为母基因进化到下一代时的概率为Pc,则Pc可表示为:
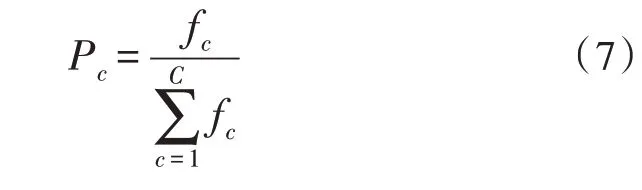
采用实数交叉法进行交叉操作,假设r是可行解,其包含s个变量值,拼接第h个可行解和第v个可行解的过程可表示为:
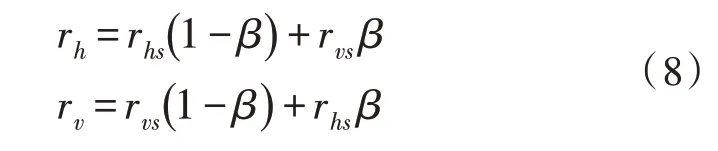
其中,rhs为第h个可行解的第s位,rvs为第v个可行解的第s位,β∈[0,1]。
对第h个可行解的第s位进行变异,变异方法为:

其中,Δx为取值范围为[rmin-rhs,rmax-rhs]的随机数。引入变异,可防止神经网络陷入某一局部最优,扩大搜索范围。
代入测试样本数据,训练神经网络模型。当预测成绩误差小于设定的训练误差时,停止迭代。
3 仿真与分析
3.1 仿真实验
使用Matlab R2018a 作为仿真环境,编写遗传BP神经网络模型的代码,对学生平均成绩进行预测。仿真的训练集为采集到的418 位学生的前三学期成绩,以及学校后勤、医院和教务部门提供的模型设计所需数据与相关调查问卷。并经过了标准化数据预处理,其余10 位同学的数据作为测试集。
遗传算法仿真时,初始种群规模设置为100,最大遗传设置为50 代。交叉概率通常设置为0.3~0.9,若交叉概率过大容易错失最优解,交叉概率过小则不能有效更新种群。因此仿真中将其设置为0.5,通常变异概率设置范围为0.001~0.2。仿真时为了保证种群的多样性,且不破坏现有的种群模式,设置变异概率为0.01。得到预测成绩与实际成绩对比,如图6 所示。
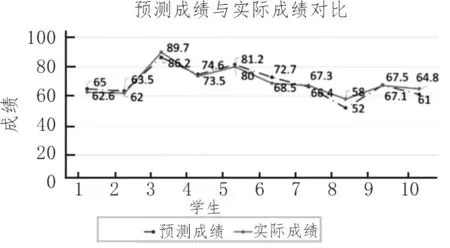
图6 预测成绩与实际成绩对比
3.2 结果分析
从图6 的分析结果可看出,实际分数的走势与预测分数的走势大体相同。每位学生的预测误差在±6 分的范围内,其预测误差如表4 所示。
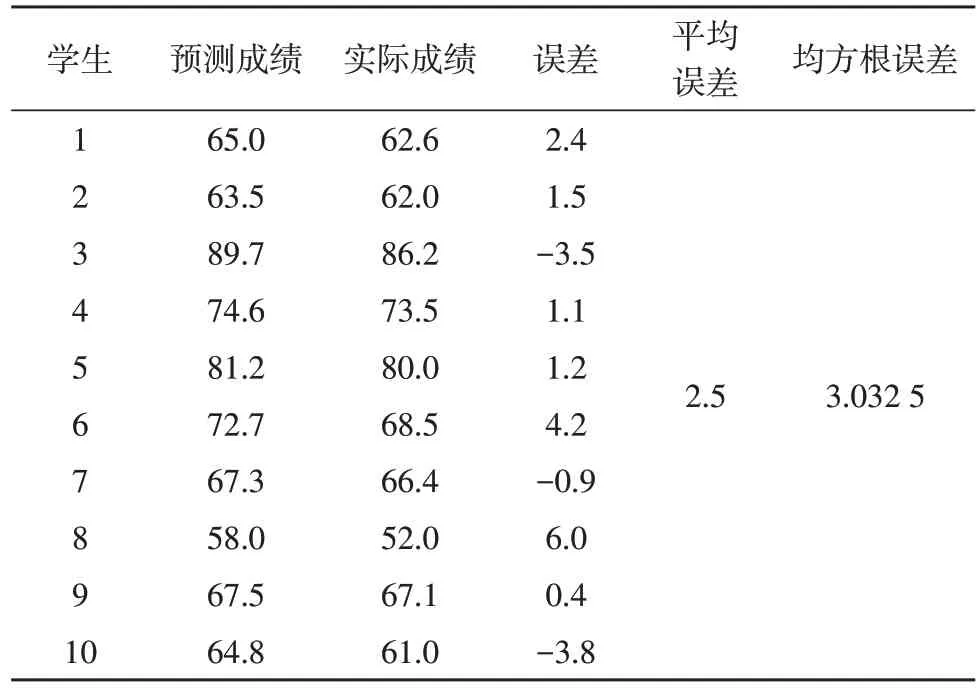
表4 预测结果与误差数据分析
经过遗传BP 神经网络输出的预测成绩与实际成绩之间的均方根误差为:

其中,Q为测试集个数,yi为学生实际的成绩,oi为神经网络输出的预测成绩。由此求解出BP 神经网络模型预测的均方根误差为3.032 5,与实际成绩较为接近。
4 结束语
当前对于学生成绩的研究多基于统计学方法,对学生主观层面的影响因素考察较少,且对于成绩数据的挖掘不够深入,利用也不全面。得益于校园大数据库的建立,可以得到更多的学生信息来分析、预测学生的成绩。该文基于大数据技术,首先对学生的综合成绩进行分析,去除了客观因素的影响,得到学生个人的进步率、综合评分等信息。然后使用BP 神经网络来实现遗传算法,求得BP 神经网络的最优权值与阈值,从而建立遗传神经网络学生成绩的预测模型。通过采集某高校428 位学生前三学期的综合成绩作为训练集和测试集,训练构建的遗传神经网络学生成绩预测模型,并将预测成绩与实际成绩相对比,仿真误差处于可接受的范围内。而该文研究的不足之处在于,对于学生的身体健康、情绪波动因素计算并不全面。从长远来看,虽然两者对学生成绩影响有限,但对单次模型预测会造成一定的误差,如何减小这种误差仍有待研究。
