基于图小波网络模型的文本分类研究
2022-06-15马诚贾凯莉李云红高子明候嘉乐
马诚,贾凯莉,李云红,高子明,候嘉乐
(西安工程大学电子信息学院,陕西西安 710048)
随着互联网技术的发展,文本信息呈指数增长。面对海量的文本信息,如何对各种文档进行恰当的表达和分类,从中快速、准确地找到所需的信息,已成为众多研究者关注的焦点。文本分类过程主要涉及文本表示、特征选择、分类器设计3 个步骤。其中最重要的步骤为文本表示。词袋(Bag of Words,BoW)模型[1]是最常用的文本表示方法,由于其将文本表示为One-hot 向量,忽略了语法和语序信息,因此丢失了大量的文本信息。为了解决文本表示中存在的问题,神经网络模型被应用于文本表示,如卷积神经网络(Convolutional Neural Networks,CNN)[2-5]、递归神经网络(Recurrent Neural Networks,RNN)[6-9]、胶囊神经网络(Capsule Neural Networks)[10]等。与传统的文本表示方法相比,RNN 在获取短文本的语义方面表现优越,但在学习长文档的语义特征方面效果较差;CNN 进行文本表示时,与n-gram[11]有些类似,只能提取连续单词的语义成分,可能会失去单词之间的长距离语义依赖性[12]。
近年来,由于图卷积网络(GCN)[13-14]能更好地捕获非连续词和长距离词的语义和语法信息,引起了众多研究者的关注。Kipf 和Welling[15]提出GCN 模型,该模型通过谱图卷积的局部化一阶近似对图卷积进行逼近与简化,使得计算复杂度降低,并可以对局部图结构和节点特征进行编码,学习隐藏层表示,改善了文本分类性能。Chiang 等人[16]为了降低图卷积网络的时间复杂度与内存复杂度,提出了聚类GCN方法,该方法使用图聚类算法对子图进行采样,并对采样子图中的节点进行图卷积。由于邻域搜索也被限制在采样子图范围内,因此聚类GCN 能同时处理较大的图和使用较深的体系结构,所用时间短、内存少。Xu 等人[17]为了降低计算复杂度并提高分类准确率,提出了GWNN(Graph Wavelet Neural Networks)方法,该方法用图小波代替图拉普拉斯的特征向量作为基集,并且利用小波变换和卷积定理定义卷积算子。Yao等人[18]提出TextGCN模型,该模型是将整个文本语料库建模为文档字图,并应用GCN 进行分类。
文中在Text-GCN[18]模型研究基础上建立基于图小波网络文本分类模型(Text-GWNN)。Text-GWNN模型使用改进的TF-IDF 算法计算词与文档间的权重,能突出特征词对类别的重要程度;同时,该模型在节点域是稀疏及局部化的,具有较高的计算效率。此外,通过超参数s更加灵活地调整节点的邻域,能更有效地根据邻域节点获取中心节点表示,从而改善文本分类效果。通过R8、R52 及Ohsumed 英文语料库的验证,提出方法提高了文本分类性能,具有较高的文本分类准确率。
1 Text-GWNN文本分类模型
图1 为使用Text-GWNN 模型进行分类的原理框图。对文本进行分类,首先需要对文本进行预处理,包括去除停止词、分词并清洗不需要的数据和去除标点符号;其次利用清洗后的文本通过词共现及词与文档的关系构建文本图;最后训练分类模型,在测试集上对分类模型进行测试,并对分类结果进行评价。
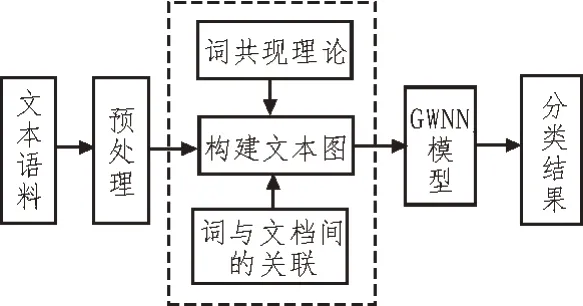
图1 Text-GWNN模型分类框图
1.1 构建文本图
根据语料库的特点,使用词共现原理及词与文档的关联构建无向文本图。在语料库中,节点的数目为文档数加上文档中不重复出现的词的数目。根据词与文档的关系,如果词在该文档中,则使用改进TF-IDF 算法建立词与文档之间的权重关系;否则,词与文档之间的权重为0。改进TF-IDF 算法的计算方式如式(1)所示:
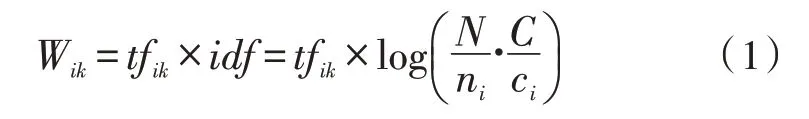
其中,tfik指的是词i在文档k中出现的次数,N为总文档数,ni为出现词i的文档数,C为总类别数,ci为出现词i的类别数。
根据词共现理论,采用PMI 算法建立词与词之间的权重关系:

其中,Nij为词i和词j出现在同一滑动窗口的数目,Ni为语料中包含词i的滑动窗口数目,N为语料中滑动窗口的总数目。
1.2 图小波文本分类模型
假设无向图G=(V,E),其中V代表所有节点的集合,E代表边的集合。通常用拉普拉斯矩阵L=D-A表示图,其中A为邻接矩阵,代表两个节点之间的连接关系,D为度矩阵,代表每个节点与其他节点连接的个数。
文中采用GWNN 模型[17](两层网络)进行文本分类,该模型是基于图数据操作的。正则化后的拉普拉斯矩阵为:
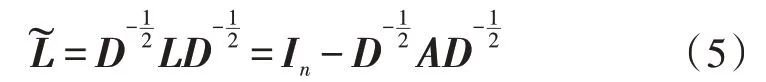

其中,⊗代表哈达玛积,y为卷积核,可以用对角矩阵g(θ)代替UTy,哈达玛积可以被视作矩阵乘法。上式可以被简化为:

图小波变换是将信号从顶点域变换为谱域进行操作,其是以一组小波基Ψs=(Ψs1,Ψs2,…,Ψsn) 为基础,每个Ψsi都代表以节点i为中心,邻域范围为s的信号。因此,图信号x的图小波变换为图小波逆变换为图小波卷积被定义为:

其中,Gs=diag((g(sλ1),…g(sλn))),g(sλi)=eλis,U为拉普拉斯的特征向量。
图小波神经网络(GWNN)为一个多层的神经网络,其传播规则为:

其中,Ψs为小波基,为图小波变换矩阵,是对角滤波矩阵,h为非线性函数。
2 仿真实验
实验采用R8、R52 及Ohsumed 英文语料库进行文本分类任务,对提出的文本分类方法进行评估。
2.1 实验数据
使用R8、R52 和Ohsumed 3 个标准数据集。其中,R8为8种类别的数据集,而R52为52种类 别的数据集,Ohsumed 为23 种心血管疾病病例的数据集。各数据集的统计信息见表1。

表1 数据集统计信息
2.2 实验设置
实验基于Python 语言实现,采用Tensorflow 框架对Text-GWNN 模型进行数据集测试验证。
1)实验参数设置
根据Text-GCN 及GWNN 模型进行参数设置,并通过反复多次实验验证,最终设置Text-GWNN 模型各参数的取值,具体见表2。

表2 实验参数设置
2)评价指标
采用文本分类中常用的准确率(Accuracy)、召回率(Recall)、F1 值对文本分类结果进行评价,其中TP、FP、TN和FN分别代表正阳性、假阳性、正阴性和假阴性的分类数量。各评价指标的计算如式(11)所示:

2.3 实验结果与分析
将文中模型与TF-IDF+LR、PV-DM+LR、LSTM、Bi-LSTM 和Text-GCN 文本分类模型对比,并在R8、R52 和Ohsumed 数据集进行实验验证。为验证Text-GWNN 模型的有效性,通过分类准确率、召回率、F1值3 个评价指标进行实验结果评估,结果如表3~表5所示。
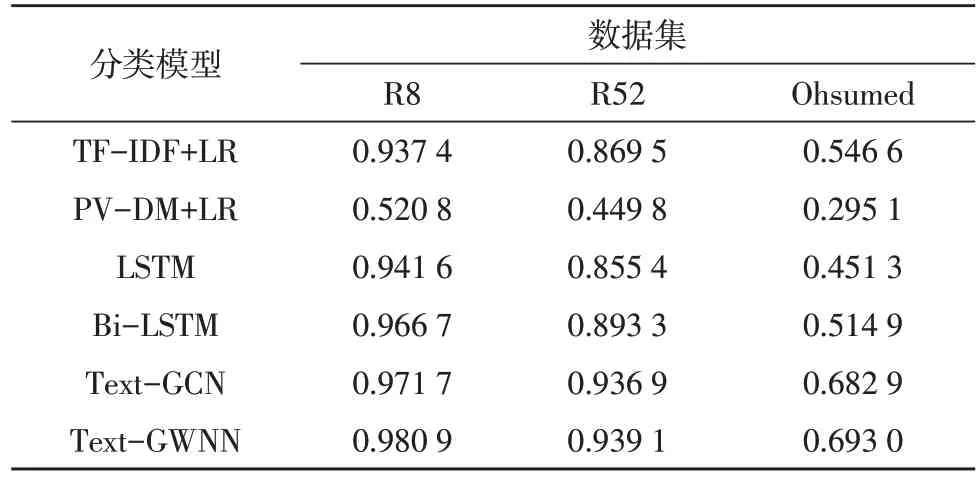
表3 分类准确率比较

表4 分类召回率比较
从表3~表5 列出各方法的实验结果可以得出,Text-GWNN 与TF-IDF+LR、PV-DM+LR以及LSTM、Bi-LSTM文本分类方法相比,对于R8、R52及Ohsumed3个数据集,Text-GWNN 分类评价指标均高于对比的分类方法,该结果说明文中方法可以改善文本分类效果。

表5 分类F1值比较
Text-GWNN 模型与TextGCN 模型相比,R8、R52及Ohsumed 3 个数据集的分类评价指标有所提高,Text-GWNN 模型测试准确率分别达到了98.09%、93.91%、69.30%,分别提升了0.92%、0.22%、1.01%,结果证明Text-GWNN 分类模型可以有效提高文本分类结果。
图2 给出了参数s对Text-GWNN 模型分类准确率的影响,参数s代表邻域范围,其取值范围一般为s∈[0.5,1]。当s较小时,无法将与该节点有关的节点信息全部包含在其中;当s的取值太大时,又会将无关的信息包括进来,因此,要合理选择s值。对于不同的数据集,参数s的取值往往不同。从图中可以看出,对于R8、R52 和Ohsumed 3 个数据集,分别取s=0.9、0.7、0.5 时,Text-GWNN 模型分类准确率最高。
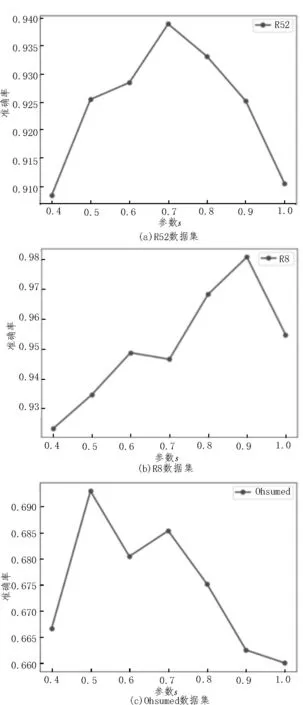
图2 参数s 对分类准确率的影响
3 结论
文中提出基于图小波网络模型(Text-GWNN)的文本分类方法,该方法利用图小波卷积的局部化特性,能更好地捕获局部词共现信息,改善文本分类效果。通过R8、R52 及Ohsumed 3 个英文语料库测试,验证了模型的有效性。未来工作中,将会研究加入池化层的图小波网络模型对文本分类性能的影响,并尝试将其应用于中文文本分类;另一方面,还会研究Text-GWNN 网络深度对于文本分类性能的影响,并在情感分类任务中应用该模型。
