智能工厂中边缘服务器的部署方法研究
2022-06-06高晋洲朱晓娟张天浩
高晋洲,朱晓娟,张天浩,王 健,程 璐
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
边缘计算是指部署在近终端,为智能终端设备提供数据处理服务的计算模型,弥补了远程云计算在数据处理时效性上的不足[1]。近几年,边缘计算在智慧煤矿[2]、智慧医疗[3-4]及智能交通[5]等场景中得到了广泛应用。部署在特定位置的边缘服务器有助于智能工厂进行全面自主监测、设备故障检测、提高预警速度,保证工厂安全高效生产。确定待部署边缘服务器的数量和最佳部署位置以及确定边缘服务器与智能终端设备之间的分配连接关系[6]是边缘服务器部署在智能工厂中需要完成的2个关键步骤。其中,确定合理的待部署边缘服务器数量及部署方式,对企业和服务商进行边缘计算规划具有重要作用。
目前,边缘服务器部署的优化目标主要包括服务时延、服务可靠性以及服务器间的负载均衡和部署成本。翟立秋[6]采用分簇的思想,提出了一种基于WB-MP算法,通过节点权重部署边缘服务器的方法,降低了服务时延。Chen等[7]设计了K-Clustering算法,以最少的边缘服务器数量满足了用户的访问时延要求。Zeng等[8]运用图论中的最小支配集,在确保服务质量要求的同时最小化边缘服务器数量。Li等[9]提出将K-means算法与蚁群算法相结合,建立边缘服务器放置优化模型,使各服务器之间达到负载均衡。
当前仍然存在的2个问题[10-12]:①缺少对边缘服务器部署数量的研究;②不能动态考虑在基于全局计算任务总量与异构服务器计算能力的不同的情况下边缘服务器之间的负载均衡。因此,本文提出了一种智能工厂中边缘服务器的部署方法,采用数量决策算法Gap-statistic++算法确定边缘服务器数量;利用Rpack算法进行基于全局异构服务器之间的负载均衡部署,旨在进一步提高数据处理的可靠性与实效性。
1 系统模型与问题定义
1.1 系统模型
智能工厂边缘计算系统包括智能终端设备、云服务器、边缘服务器。为了便于研究,作出如下假设:①智能终端设备和云服务器已完成部署;②每个智能终端设备的计算任务量和数据量呈周期性变化。
1)智能终端设备集合。设智能工厂中有m台已部署完成的智能终端设备,记为集合SD,SD={sd1,sd2,…,sdm};智能终端设备的位置记为集合TL,TL={tl1,tl2,…,tlm};智能终端设备对其提交的计算任务能接受的最大等待时间记为集合P,P={p1,p2,…,pm}。为保证系统的健壮性,取集合最大值tmax=max{P}作为系统时间阈值。
2)潜在位置集合。在智能工厂中不是任何位置都具备部署边缘服务器的条件,因此需要将边缘服务器部署在通过生产工艺得出的潜在位置上[10]。设有n个潜在位置,记为集合PL,PL={pl1,pl2,…,pln},n≤m。
3)边缘服务器集合。设有k个待部署边缘服务器,记为集合SN,SN={sn1,sn2,…,snk};边缘服务器的计算能力记为集合CP,CP={cp1,cp2,…,cpk};边缘服务器的位置集合记为CL,CL={cl1,cl2,…,clk},clj∈PL,j≤k,k≤n。
智能工厂边缘计算系统可以看作是一个由智能终端设备、边缘服务器和云服务器组成的网络,可以用无向图G=(V,L)表示。其中,V=SD∪SN,表示网络无向图中的智能终端设备和边缘服务器设备;L表示所有智能终端设备与边缘服务器之间的分配连接[9]。每一个边缘服务器负责其所分配连接的智能终端设备的计算任务,当其接收的计算任务过多,而导致计算时间超过tmax时,后续到达的计算任务将上传至远程云服务器(云边协同)。
1.1.1服务时延定义
智能工厂边缘计算系统服务时延主要包括:边缘服务器的计算时延、边缘服务器与其所关联终端设备之间的通信时延。
设智能工厂生产线的工作周期为T,将工作周期划分为O个时段,即T={t1,t2,…,to}。智能终端设备计算量呈周期性变化,在周期T内,智能终端设备sdi在时段j时的计算任务量记为dij,所有智能终端设备的计算任务量矩阵记为DL:
(1)
为了保证边缘计算系统的健壮性,智能终端设备sdi的计算任务量取周期内计算任务量的最大值[10]di,max,di,max=max{dio}。
边缘服务器snj的计算负载记为slj:
(2)
式(2)中,Yji为二进制变量,表示边缘服务器snj与智能终端设备sdi的分配关系。Yji=1表示智能终端设备sdi上的计算任务分配到边缘服务器snj上;Yji=0则表示不分配。
边缘服务器snj的计算时延记为ctj:
(3)
在周期T内,智能终端设备sdi在时段j的数据量记为qij,智能终端设备的数据量矩阵记为DA:
(4)
为了保证边缘计算系统的健壮性,智能终端设备sdi的数据量取周期内数据量的最大值qi,max,qi,max=max{qio}。
边缘服务器snj的通信时延记为ttj:
(5)
(6)
式(5)~(6)中,lji为智能终端设备sdi与边缘服务器snj之间的距离;dave为一跳距离;e为sdi到snj所需跳数;b为中继设备带宽。
边缘服务器snj的服务时延记为stj:
stj=ttj+ctj
(7)
1.1.2负载均衡定义
负载均衡是用来衡量每个边缘服务器的负载与平均边缘服务器负载的差异情况,但是对于异构边缘服务器,系统的负载均衡并不是指每个服务器负载的计算任务量趋于相等,而是根据每个边缘服务器计算能力的不同,分配不同的负载,追求整体任务的完成时间最短。负载均衡标准差记为LB:
(8)
LB的值越小,则每个边缘服务器的计算时间与平均计算时间之间的差距越小,整体边缘服务器负载越均衡。
1.2 边缘服务器部署问题
智能工厂系统中边缘服务器的最优部署:首先,确定待部署边缘服务器的最佳数量;然后,在n个潜在位置中选取k个目标位置放置异构边缘服务器;最后,完成m个智能终端设备与k个边缘服务器的分配连接,同时满足一定的约束条件,即在边缘服务器部署过程中需要考虑服务时延、负载均衡和最长容忍时间约束。因此,建立加权目标函数为:
(9)
(10)
clj∈{pl1,pl2,…,pln},1≤j≤k
(11)
(12)
ω1+ω2=1,0≤ω1≤1,0≤ω2≤1
(13)
式(9)~(13)中,ω1为服务时延权重;ω2为负载均衡权重。式(10)可以确保每个智能终端设备只能分配给1个边缘服务器。式(11)可以确保每个边缘服务器均部署在潜在位置上。式(12)可以确保任何一个智能终端设备所提交的计算任务均能在tmax时间内完成。式(13)表示服务时延权重与负载均衡权重的约束条件。
2 部署算法
2.1最优数量决策算法Gap-statistic++
Gap-statistic算法是一种用于确定聚类个数的机器学习算法,其基本思想是将样本数据集的离散程度与参考数据集(等数量均匀生成)离散程度进行比较,以分类数为自变量,建立一个比较统计量,通过分析该统计量关于类数的变化情况来确定最佳聚类数量[11]。Gap-statistic算法的基本过程为:假设样本数据通过K-means算法已经被聚类为k(k即边缘服务器数量)个簇类,簇类集合记为C,C={c1,c2,…,ck},nj=|cj|,|cj|表示簇cj内节点个数。簇cj中所有数据点之间距离平方之和Dj可表示为:
(14)
将样本数据集分为k个簇类时,所有簇离散程度的总和Wk可表示为:
(15)
由此定义Gap-statistic算法的Gap值可表示为:
Gapn(k)=En*logWk*-logWk
(16)
式(16)中,Wk*为参考数据集分为k个簇时的离散程度总和;En*为logWk*的期望;Gap(k)为参考数据集和样本数据集被聚类为k个簇类时的总离散程度之差。
假设kb是样本数据集的最优聚类个数,参考数据的离散程度会随着k增大而均匀减小,当2个数据集的总离散程度之差最大时,样本数据集的簇内离散程度便达到了相对此时聚类数的最优值,即Gap(kb)取最大值,kb则是样本数据集的最优簇类个数。
由于Gap-statistic是借助K-means算法对数据集进行聚类,其对初始簇类中心的选择是随机的。这可能会造成局部最优现象,导致Gap值出现偏差。本文将原Gap-statistic算法中的K-means算法换成K-means++算法,推导出更加稳定的Gap-statistic++算法。
1)K-means++算法步骤为:①在数据集中随机选择1个样本点作为第1个簇类中心;②计算样本中的每1个样本点与第1个簇类中心点之间的距离,并将其中最远的点定义为第2个簇类中心点;③以概率进行选择,将与之前的簇类中心点距离之和最大的点,定义为下一个簇类中心点,重复上述过程,直到k个簇类中心都被确定;④计算所有样本点到这k个簇类中心的距离,离哪个簇类中心近就将其归于哪一类;⑤对每个聚类好的簇重新计算簇质心,并将其定义为新的簇类中心,然后回到④,直到簇类中心不变。
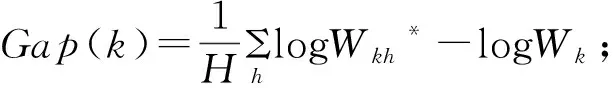
2.2部署算法Rpack
在部署边缘服务器时Rpack算法分为2部分。第1部分是运用K-means++得出初始部署,具体过程为:①随机选择一个智能终端设备位置作为第1个边缘服务器预定位置,将距离第1个预定位置最远的智能终端设备位置作为第2个边缘服务器预定位置,第3个边缘服务器预定位置为距离前2个预定点距离和最大,依次迭代k次得出k个边缘服务器预定位置;②计算所有剩余未被定义为边缘服务器预定位置的智能终端设备到k个预定位置的欧式距离,将所有智能终端设备归类到距离其最近的边缘服务器预定位置所在的簇内;③计算每个簇的质心,并将其定义为新的边缘服务器预定位置;④循环执行②和③,直到预定位置不变,得到k个簇类。
第2部分是对上一部分所得初始部署结果进行簇与边缘服务器的匹配,基于最小化目标函数进行最终部署。具体过程为:①以计算时延为权重,将初始部署所得簇集合C与边缘服务器集合SN构建有权二分图,运用匈牙利算法求得基于计算时延最小化的簇与边缘服务器之间的最小匹配;②对第1部分所得的智能终端设备sdi与边缘服务器snj的分配连接关系Yji进行基于目标函数最小化的重新赋值;③对第1部分所得边缘服务器预定位置集合CL基于最小化目标函数进行重新定位;④根据分配连接关系Yji和边缘服务器位置集合CL值计算目标函数值,并与初始部署得到的目标函数值进行比较,如果所得目标函数值小于初始部署的目标函数值,则结束计算。
3 实验与性能评估
3.1 参数设置
仿真平台配置为Intel i7,CPU为3.3 GHz,内存为16 G。利用MATLAB R2016a软件对本文所提出的Rpack算法进行测试。仿真参数见表1。
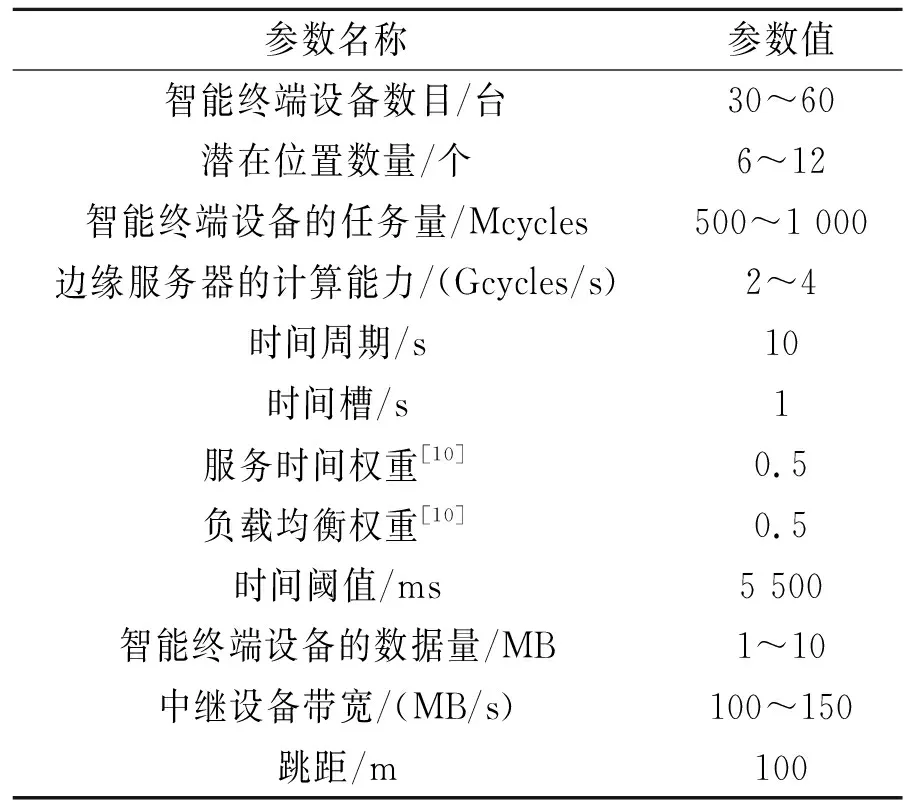
表1 仿真参数
3.2 实验对比分析
为评估Rpack算法在边缘服务器部署中的性能,分别从负载均衡和服务时延2个方面与KMP策略[12]和pack算法进行对比实验[13]。每组进行50次,取均值作为最终值。
KMP策略:将终端节点聚类为k类,取其质心作为边缘服务器部署位置,每个终端节点分配连接到离其最近的边缘服务器上。
pack算法:将边缘服务器放置作为一个容量受限的位置分配问题,以最小化边缘服务器与其关联的终端节点之间的距离和边缘服务器之间的负载均衡为目标,部署边缘服务器。
3.2.1负载均衡
实验生成60个随机分布的智能终端设备节点,通过Gap-statistic++算法得出边缘服务器数量。Gap函数值如图1所示。从图1可以看出,k=5时,Gap值最大,说明需要部署5个位缘服务器。测试不同部署算法在智能终端设备计算任务量增加过程中系统平均负载标准差变化情况。不同算法的负载变化情况如图2所示。从图2可以看出,随着智能终端设备计算任务量增加,本算法的负载标准差相较于KMP策略和pack算法更加稳定,差值最小。这是因为在边缘服务器的部署过程中,KMP策略仅依靠距离进行部署,存在局部最优现象。pack算法未考虑异构服务器部署问题和系统中整体边缘服务器的负载均衡。而本算法将具备不同计算能力的边缘服务器,以最小化所有边缘服务器的计算时延标准差为目标,与具有不同计算任务量的簇进行合理配对,使系统达到整体的负载均衡。
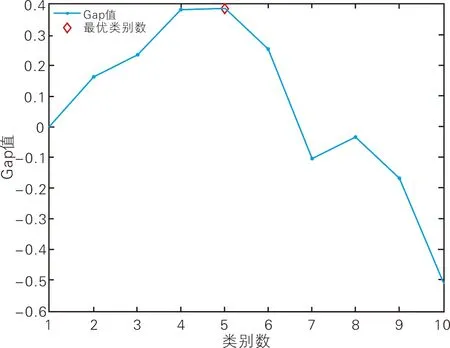
图1 Gap函数值
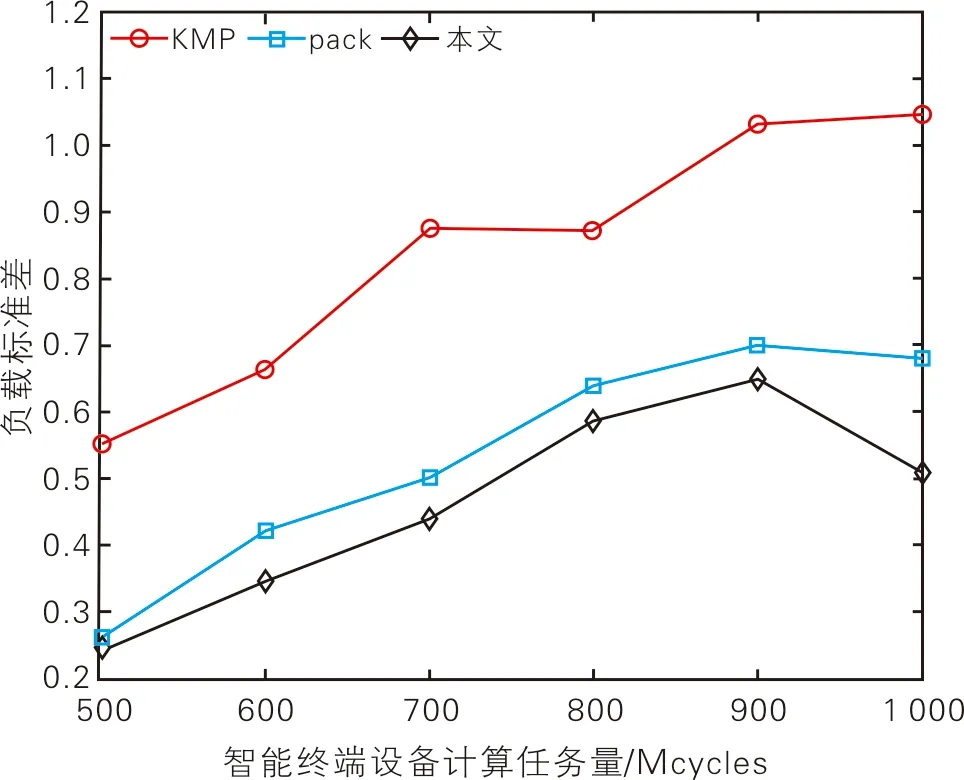
图2 不同算法的负载变化情况
3.2.2服务时延
服务时延分别从以下2个方面进行对比。
1)智能终端设备数量固定,计算任务量增加[6]。通过逐步增加智能终端设备计算任务量,分别对3种部署算法下系统总服务时延进行仿真计算。不同计算任务量下的服务总时延如图3所示。从图3可以看出,随着智能终端设备发送计算任务量的增加,3种算法的系统总服务时延都随之增加。其中,本算法的总服务时延小于KMP策略和pack算法,这是因为KMP策略负载均衡性差,且缺乏时间阈值tmax限制,当计算任务量增加时,边缘服务器的服务时间会过早达到时间阈值tmax,从而导致大量计算任务上传至云中心,增大了系统服务时间。pack算法未考虑异构服务器的部署策略,仅对单个边缘服务器的负载进行负载约束。当某个边缘服务器负载达到上限后,离它较近的智能终端设备不得不分配连接到相对较远的未过载边缘服务器上,增加了通信时延。同时,pack算法未设定时间阈值约束,随着智能设备终端设备计算任务量增大,边缘服务器的服务时间达到tmax,增大了系统服务时间。本算法具备更优的负载均衡,同时设定了最长容忍时间约束tmax,避免了智能终端设备计算任务上传到云中心。
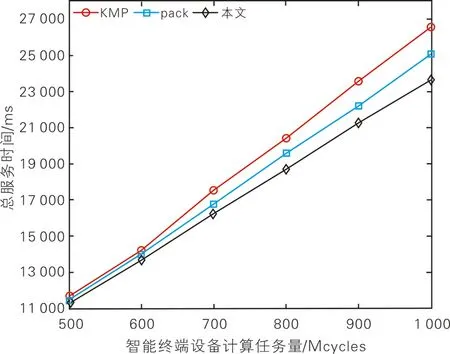
图3 不同计算任务量下的服务总时延
2)计算任务量固定,智能终端设备数量增加[6]。运用仿真工具随机生成不同数量的智能终端设备节点,再运用Gap-statistic++算法得出对应所需边缘服务器数量。终端设备数与边缘服务器数对应情况见表2。逐步增加智能终端设备数量,分别对3种部署算法下的系统服务时延进行仿真计算,得到不同终端数量下的服务总时延如图4所示。从图4可以看出,随着智能终端设备数量增加,3种算法的服务时延都在增加,而本算法在数值波动幅度和数值大小方面均优于KMP策略和pack算法。这是因为KMP策略和pack算法均未进行时间阈值限制,导致系统服务时延出现不稳定的突增。而本算法具备更优的负载均衡和时延阈值约束,在智能终端设备数量增长的过程中保持服务时间增长的稳定和数值最小。

表2 终端设备数与边缘服务器数对应情况 台
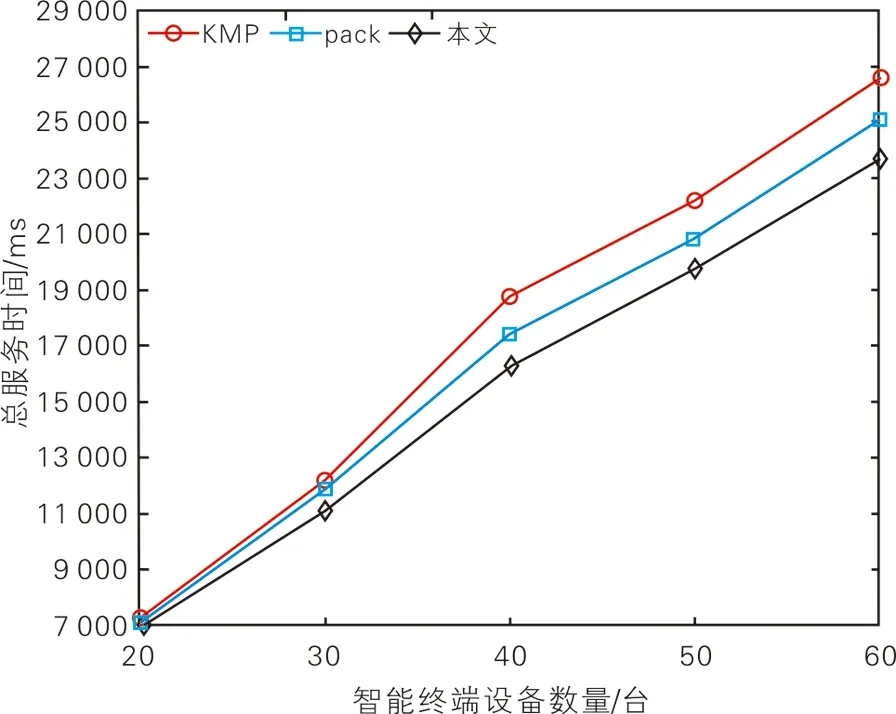
图4 不同终端数量下的服务总时延
4 结束语
边缘计算是一种将数据处理服务下沉到网络边缘的一种技术模式。通过边缘服务器的合理部署可以提高智能终端设备的服务质量。本文把边缘服务器的部署问题作为一个多目标、多约束的优化问题,通过Gap-statistic++算法得出最佳边缘服务器数量,再采用Rpack算法得出边缘服务器部署结果。结果表明,本算法负载均衡和服务时延性能指标均优于KMP部署策略和pack部署算法,具有较高的参考价值。
