基于阶段Q学习算法的机器人路径规划
2022-06-04杨秀霞高恒杰
杨秀霞,高恒杰,刘 伟,张 毅
(1.海军航空大学 岸防兵学院,山东 烟台 264001; 2.海军航空大学 战勤学院,山东 烟台 264001)
1 引言
随着机器人技术的不断发展进步,人们对机器人运动过程中适应周围环境、自主采取相应措施能力的要求越来越高[1]。通过建立诸如轨迹长度最短、运动时间最少的优化目标,找到复杂环境中起点和终点之间的最优路径,实现移动机器人的路径规划,是机器人自主导航的关键问题之一[2]。
目前常用的路径规划算法有图搜索算法,人工势场法[3-4],快速扩展随机树法[5-6],以及以遗传算法[7]、蚁群算法[8-9]为代表的群智能算法。但是上述路径规划算法进行规划前需要环境先验信息,对于未知复杂环境的应用性不强。作为一种重要的机器学习方法,强化学习在机器人路径规划中受到越来越多的关注和应用。机器人在环境中通过探索获取知识,在试错过程中进行学习,强化学习方法在环境先验信息较少的路径规划中优势十分明显。传统的Q学习算法在初始化过程中将Q值设为均等值或随机值,即在无先验知识的情况下进行学习,这样会使算法收敛速度慢[10]。文献[11]在Q值初始化过程中引入人工势场法中的引力势场,加快了算法的收敛速度。文献[12]利用接受信号强度定义回报值,提出了“导向强化”的原则,加快了学习算法的收敛速度。文献[13]通过结合玻尔兹曼概率选择策略和贪婪策略,提出了一种新的动作选择策略,加快了路径规划的收敛速度。文献[14]通过人工势场法的合力引导机制减少了路径搜索时间。文献[15]通过引入环境势能值作为搜索启发信息对Q值进行初始化,缩短了算法学习时间。由此可见,虽然Q学习算法在路径规划问题上研究已久,但如何加快其收敛速度仍是目前的研究热点。
针对传统Q学习算法收敛速度慢的问题,本文在传统Q学习算法基础上借鉴最优控制的思想,提出一种基于分阶段最优探索的路径规划算法。首先基于环境规模和预计探索信息确定每一阶段探索步长;其次根据每一阶段探索步长设置奖励池和奖励阈值,确保每一阶段探索路径为该阶段最优路径;然后重置变量因子,使本次阶段基于上一阶段的最优路径继续探索;最后确定各个阶段的最优路径,并将每一阶段最优路径组合为全局最优路径,实现机器人从起始点到目标点的路径规划。
2 问题描述
2.1 任务描述
本文的路径规划问题可以描述为:机器人从起始点出发,通过路径规划寻找安全路径,并按规划路径行动并躲避障碍物,最后安全达到目标点。
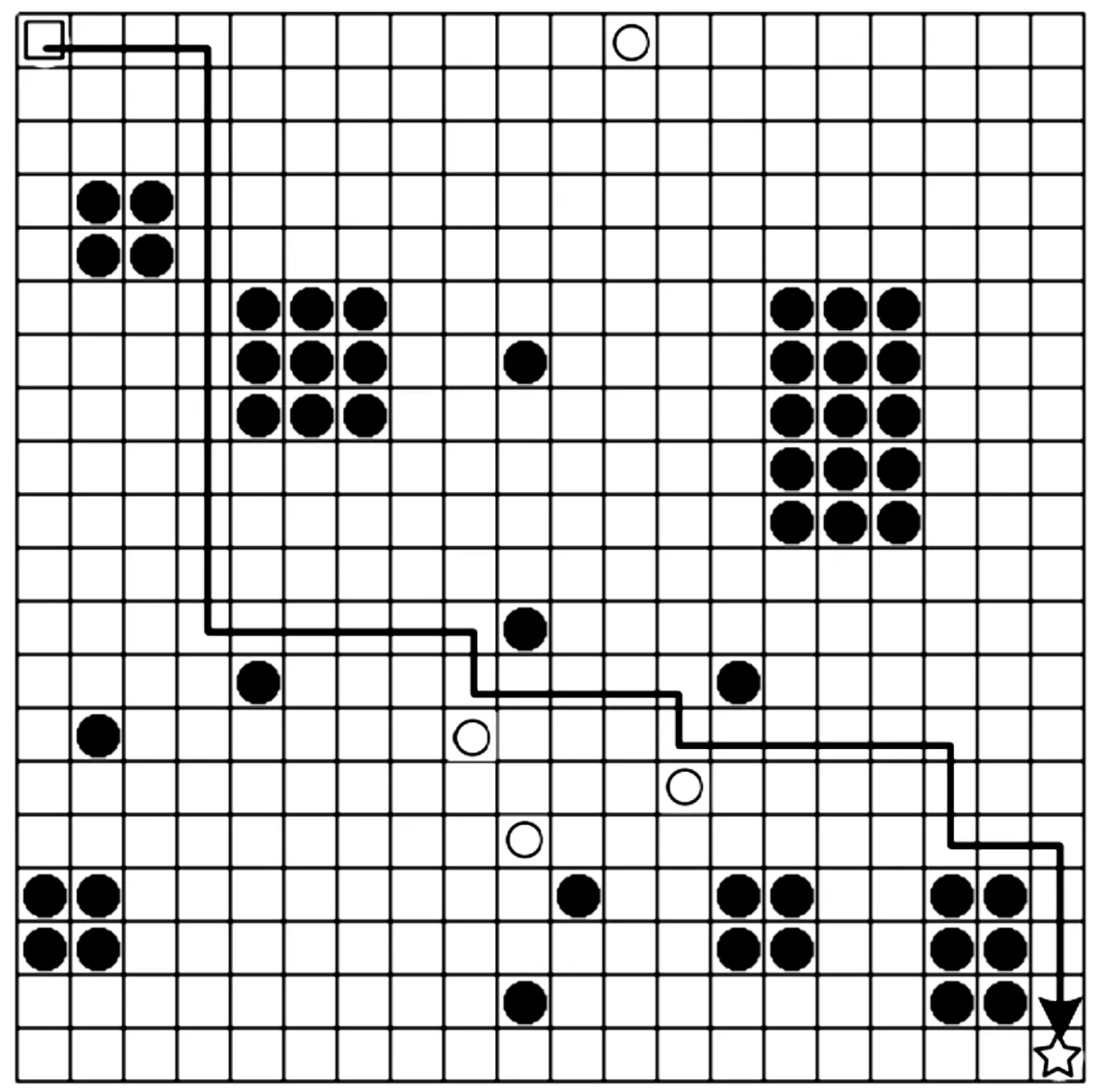
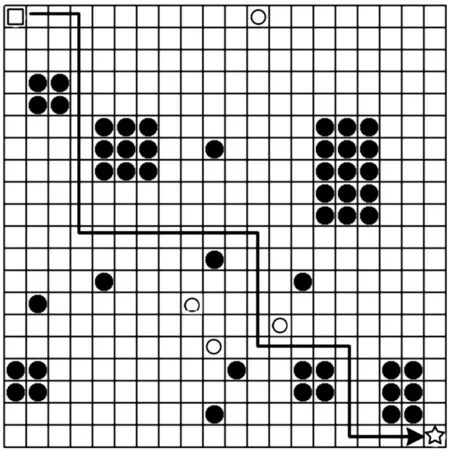
在本文的路径规划问题中通过栅格法建立环境模型,栅格地图由n*n的网格组成。地图中分布着多个位置不同的静态障碍物和动态障碍物。本文中路径规划环境如图1所示。
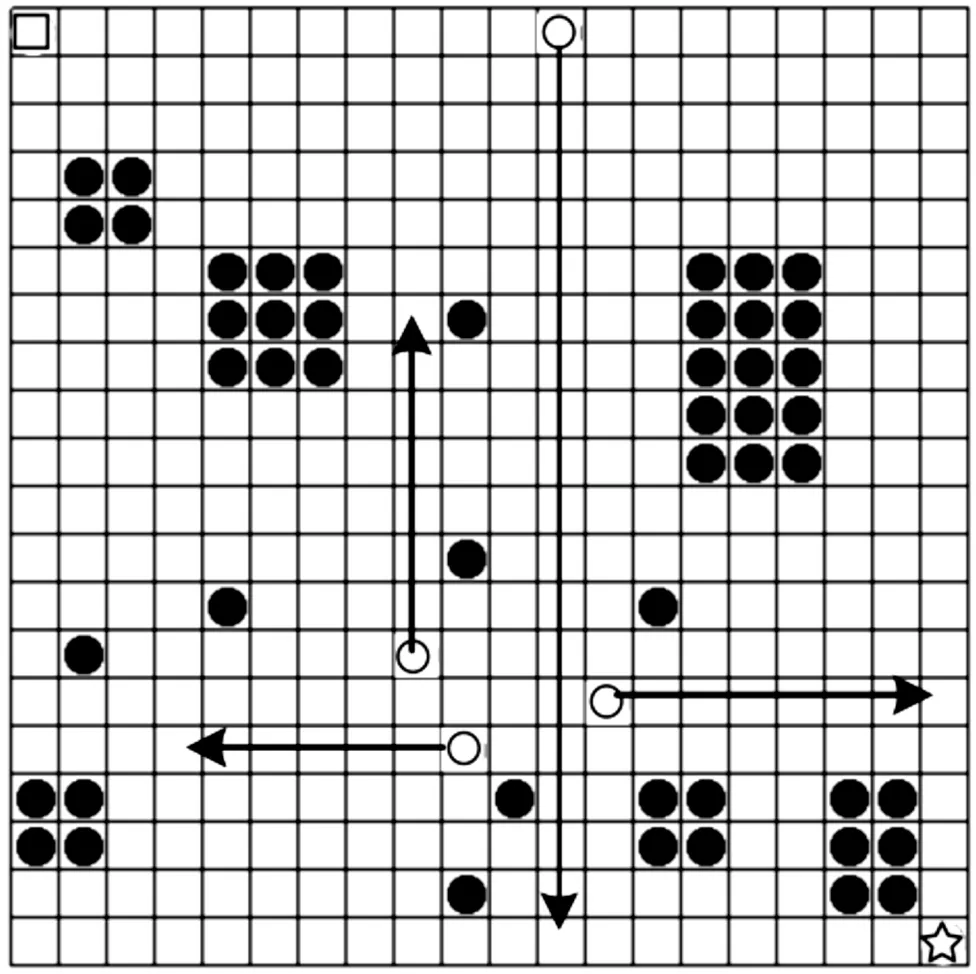
图1 路径规划环境模型示意图
图1中,矩形区域为机器人起始点,空心圆、实心圆、星型区域分别表示地图中动态障碍物、静态障碍物的位置和机器人的目标点。其中,动态障碍按一定规则在地图中移动。起始点和目标点的信息均已知,而障碍信息是未知的。
基于上述设定,本文提出算法的目标有2个:一是最快规划出机器人从起始点到目标点的最短可行路径,引导机器人安全到达目标点;二是避免行进过程中发生碰撞和出界。
2.2 机器人运动学模型
机器人二维运动学简化模型为:
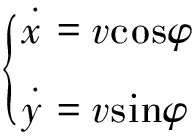
(1)
式(1)中:(x,y)为机器人位置坐标;v为机器人的运动速度;φ为本文的控制量,对应运动航向角。
3 改进Q学习路径规划算法
3.1 传统Q学习算法原理
Q学习算法最初是由WATKINS等提出的一种无模型的值函数强化学习算法。该算法可用马尔科夫决策过程(MDP)框架来形式化描述。MDP可用一个四元组(S,A,P(s,s′,a),R(s,s′,a)) 定义,其中S表示状态空间,A表示动作空间,P(s,s′,a)表示状态转移概率函数(模型),该模型定义了智能体执行动作a∈A后,环境状态s∈S转移到新状态s′∈S的概率。
奖励R(s,s′,a)是人为设定的在智能体选择并做出动作a∈A后,环境状态s∈S转移到新状态s′∈S的奖励。强化学习智能体遵循策略π从t1时刻状态开始到t2时刻状态结束时,状态累积奖励回报之和定义为:
(2)
式(2)中:ri为智能体每一次选择并做出动作后环境反馈的奖励;γ∈(0,1)为折扣因子。
Q学习算法会根据智能体的状态空间和动作空间建立一个Q表,用来存储所有的状态-动作对的Q值。同时,通过设计奖励函数,评价智能体选择的动作在环境中的优劣,如果状态-动作对得到来自环境的正奖励,则它对应的Q值会不断增大;如果状态-动作对得到来自环境的负奖励,则它对应的Q值会不断减小。通过每一回合的训练逐渐更新Q(st,a)逐渐逼近Q*(st,a),基于贝尔曼公式的Q表更新公式为:
Q(st,a)=Q(st,a)+α[rt+γmaxQ(st+1,a)-Q(st,a)]
(3)
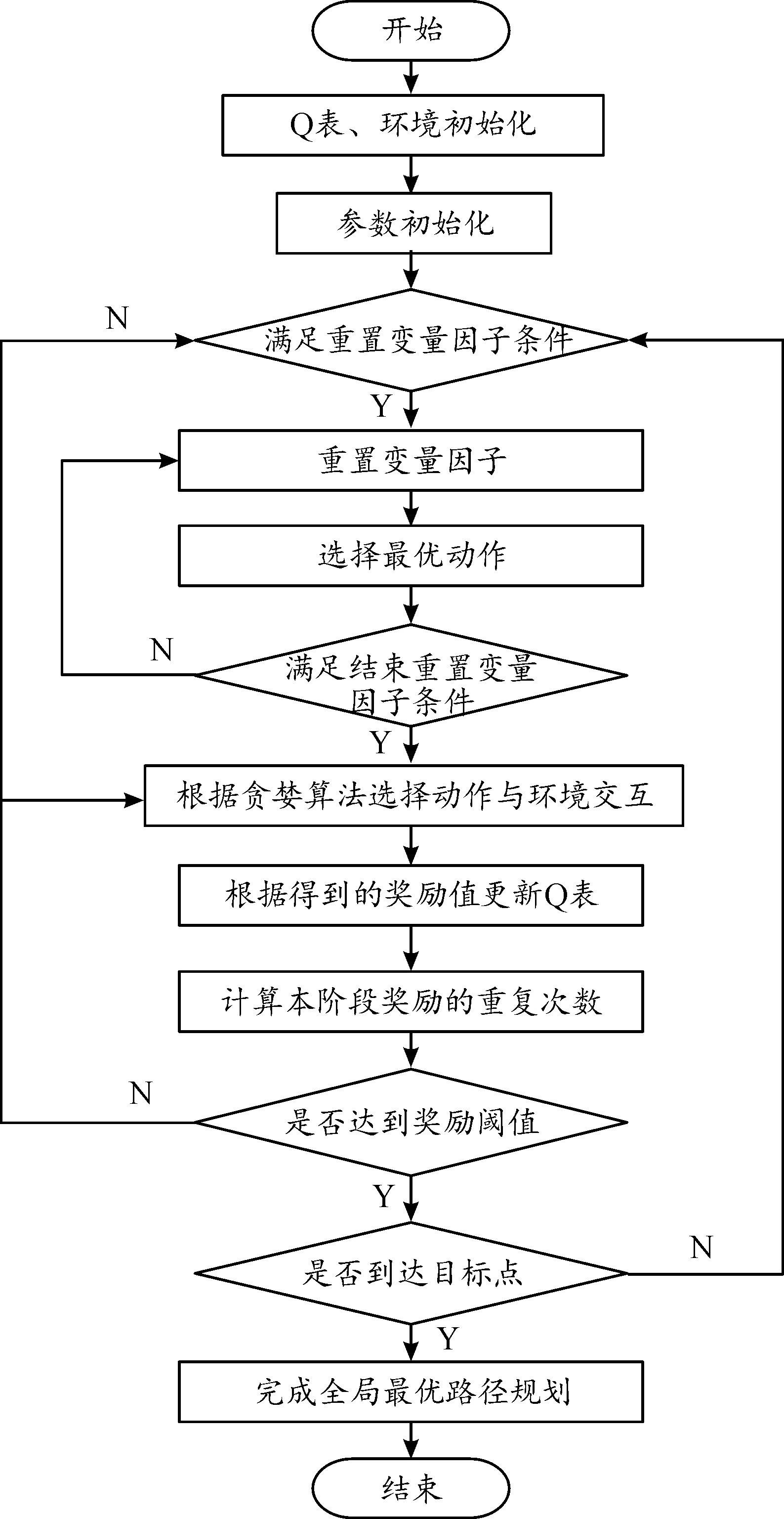
式(3)中:α∈(0,1)为学习率;rt为智能体每次选择动作时得到的奖励;γ∈(0,1)为折扣因子。最后,智能体根据Q表在每个状态下选择最优动作完成目标任务。Q学习算法流程如图2所示。
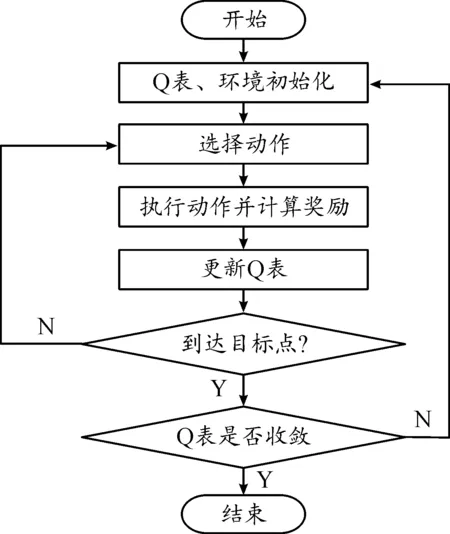
图2 传统Q学习算法流程框图
传统Q学习算法常用的策略为ε-贪婪策略。其策略思想是确定一个探索因子ε,在选择动作时,智能体以ε的概率选择最优动作,以1-ε的概率随机选择一个动作。其算法表达式为:
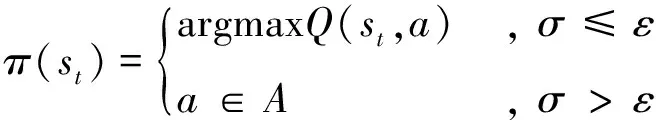
(4)
式(4)中,ε∈[0,1]。当ε趋近于0时,智能体仅探索环境;当ε趋近于1时,智能体仅利用环境。σ是一个随机变量,σ∈[0,1]。如果σ小于等于ε,则智能体选择能令Q值最大化的动作;如果σ大于ε,则智能体随机选择动作。
3.2 阶段Q学习路径规划算法原理
由3.1节传统Q学习算法的基本原理可知,传统Q学习算法采取新动作主要依赖于每一步中随机变量σ与ε的比较。在训练的每一回合中,若随机变量σ>ε的频数远远多于σ≤ε的频数,则智能体将一直探索新动作,而不会根据Q表选择最优动作,这时便不易规划出最优路径;若随机变量σ≤ε的频数远远小于σ>ε的频数,则智能体将一直遵循Q表选择当前状态的最优动作,从而缺乏对环境的探索使路径陷入局部最优。更重要的是,由于训练过程中需要的回合数过于庞大,智能体因为策略局限性而导致路径的大量重复探索,导致算法的学习效率低,收敛速度慢。
针对上述问题,本文对传统Q学习算法进行改进,提出一种基于分阶段最优探索的改进Q学习路径规划算法。
3.2.1 确定各阶段探索步长
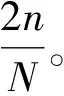
3.2.2 设置奖励池和奖励阈值
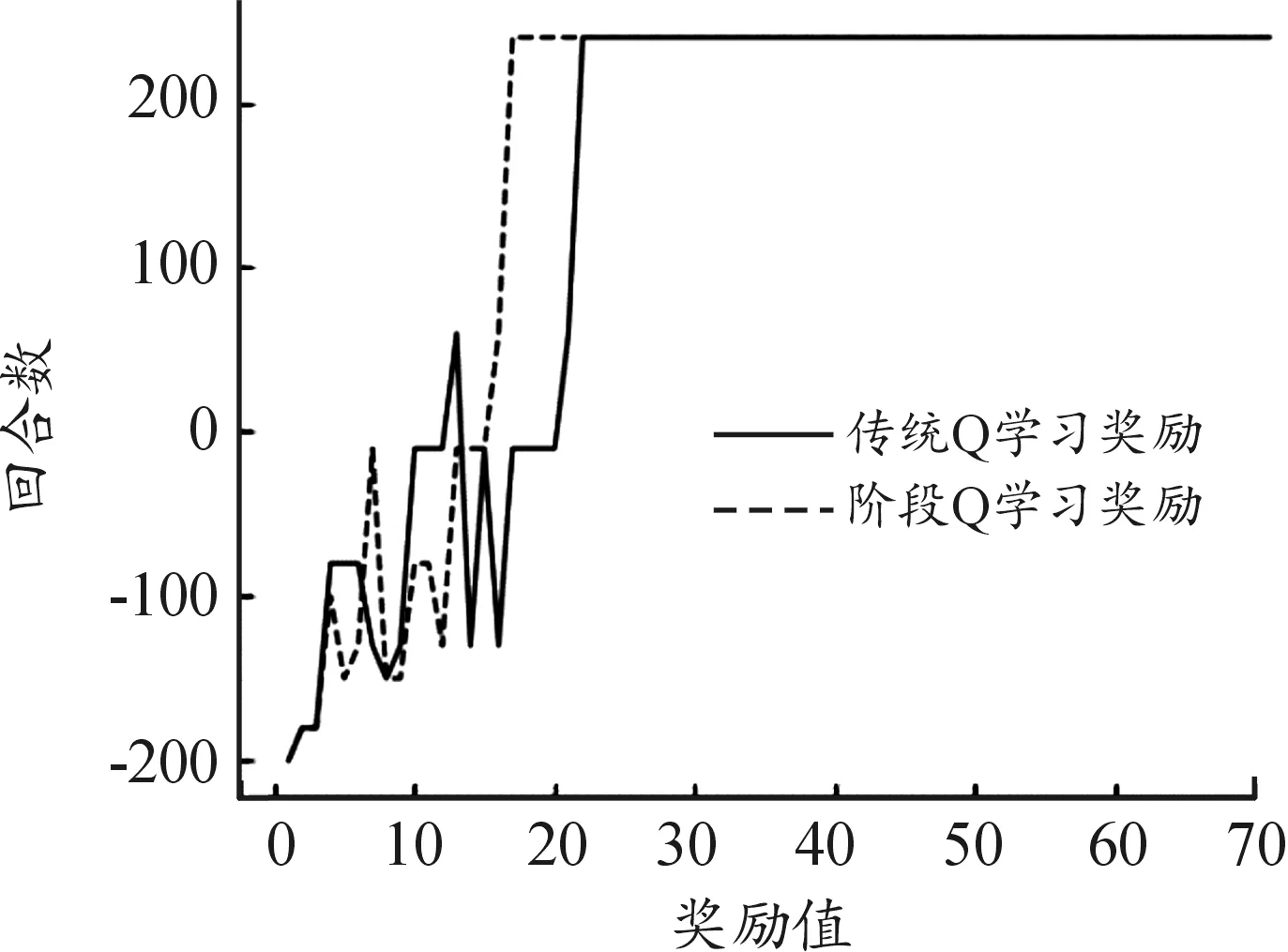
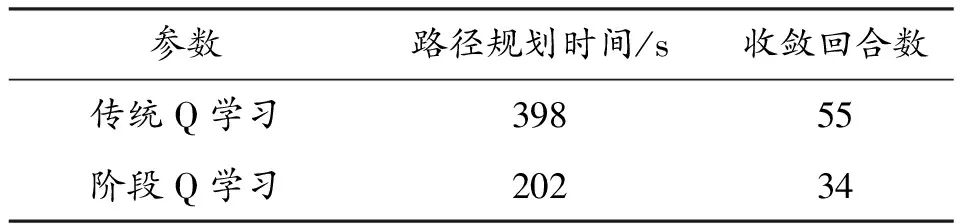
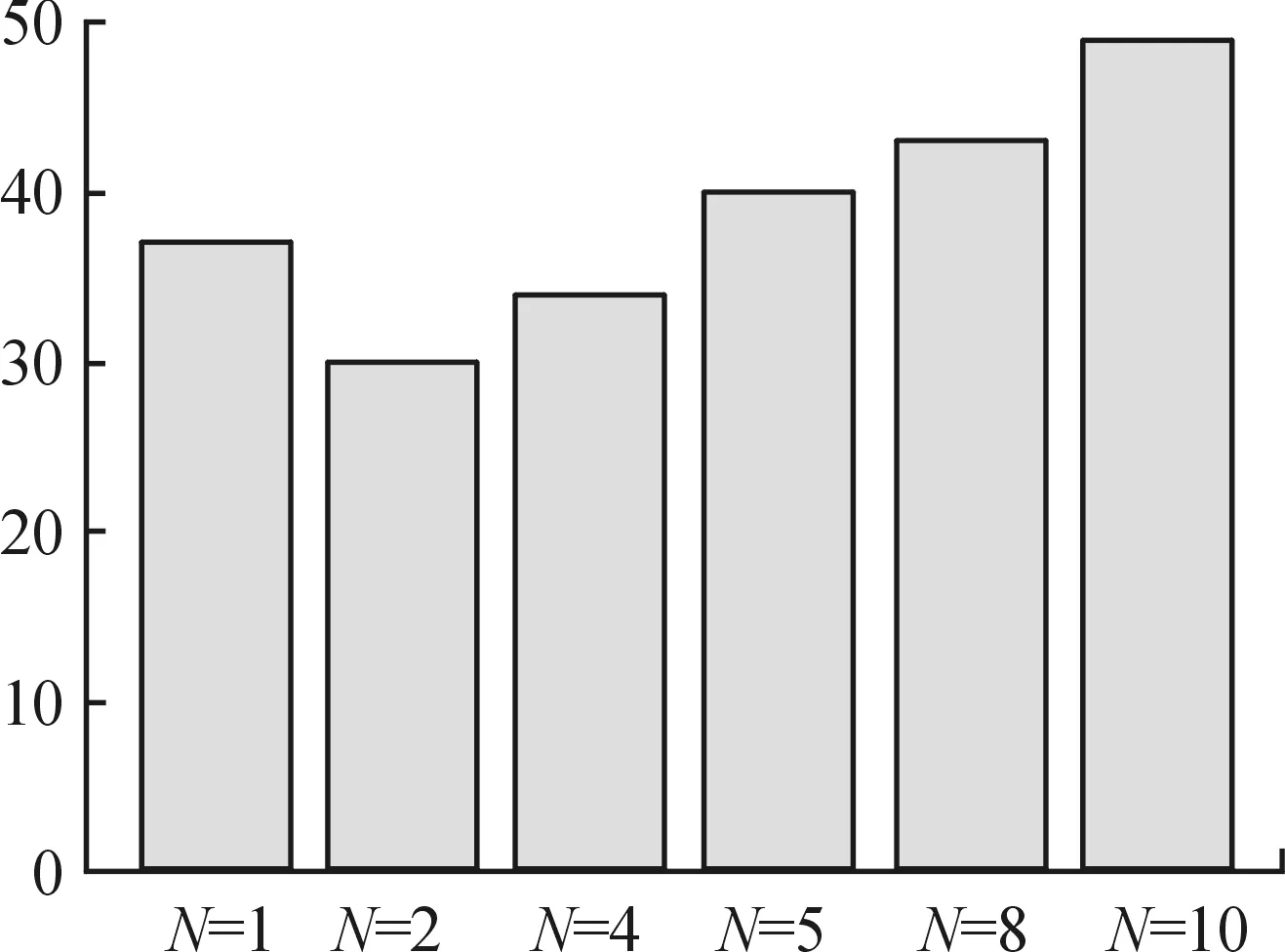
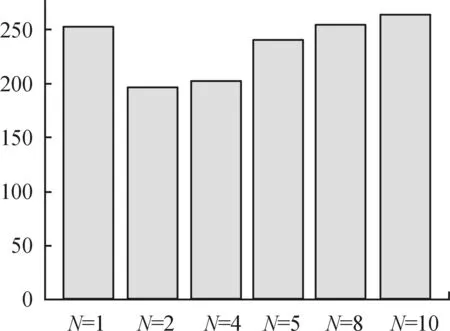
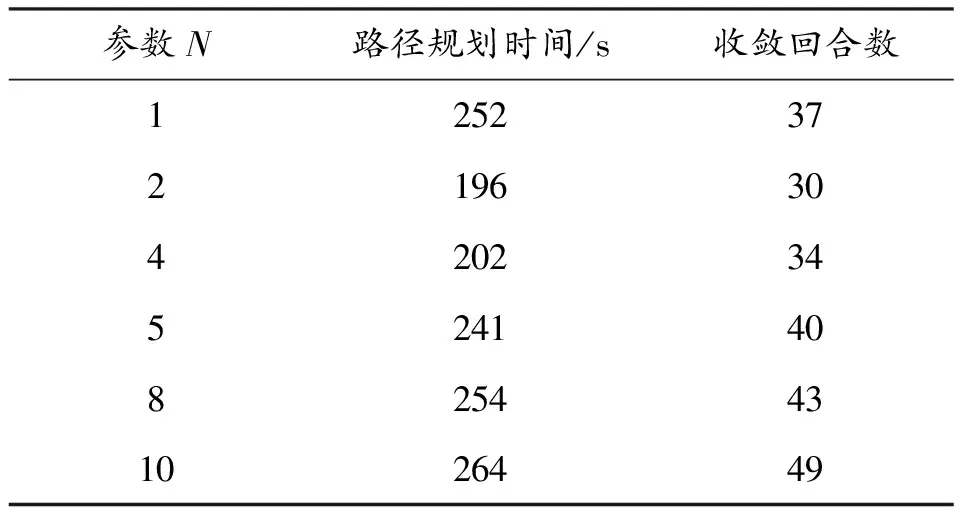
考虑到各阶段可能存在提前得到最优路径的情况(即m′次探索后得到最优路径,其中m′ 奖励池的作用是存储当前阶段中每次探索后的奖励值。每次探索后的奖励值都会与奖励池中最近一次得到的奖励相比较,如果相同,计数为+1。当计数达到奖励阈值Rmax时,视为当前阶段已经规划出最优路径,则结束本阶段的规划进入下一阶段规划路径。 3.2.3 重置变量因子 为了确保各阶段在前一阶段最优路径基础上继续对路径进行规划,基于式(4)设计重置变量因子机制。 (5) 由式(4)可知,当σ=0时,算法的动作策略总是会选择Q表中最优动作。即第X个阶段探索的起点为前面各个阶段探索的最优路径的终点。这样就保证了每一阶段的路径规划都是基于前一阶段的最优路径上进行的。 3.2.4 确定全局最优路径 定义:只要总是选取动作序列 (6) 则累积奖励期望总是最大的,即各个阶段路径组合即为最优路径。 证明:设全局策略(即全局动作序列) (7) 是最快规划出安全路径的最优策略,相应的最小代价为: (8) 式(8)中,x(i)为第i个阶段的状态。 (9) 因此,有2个动作序列 (10) 使得: J*>J** (11) 式(11)中: (12) 上述结论与J*为最小代价的假设相矛盾。因此,反设不成立,证毕。 将机器人路径规划问题建模为马尔科夫决策过程(MDP)。下面依次对该模型的3个要素,即状态空间、动作空间和奖励函数进行设计。 为了计算方便,机器人在环境中的位置表示为机器人的状态。即s={X,V},其中,X表示机器人的任意时刻位置及各个障碍的位置信息,V表示机器人的在当前状态下可能采取的动作。 为了提高训练速度,加快Q表收敛,在本文中将动作空间离散为A∈{0°,90°,180°,360°},在栅格环境内对应向右、向上、向左,向下。 本文奖励函数设计为:当智能体与目标点的当前距离小于前一时刻与目标点的距离时,奖励设为+2n;反之,奖励设为-6n。当智能体与障碍物相撞时,奖励设为-40n。其他可行区域的奖励值设为0。奖励函数的表达式为: (13) 根据上述内容,给出阶段Q学习路径规划算法步骤如下: 步骤2:计算本次阶段的初始步长k,计算已完成路径规划的所有阶段的总步长T。判断是否满足重置变量因子条件,若满足k≥T,进入步骤5,否则重置变量因子。 步骤3:重置变量因子。在当前阶段探索前,将ε-贪婪算法的随机变量σ置为0。 步骤4:判断重置因子结束条件。当前步长k′是否等于本次阶段初始步长k,若不满足,转入步骤3。 步骤5:迭代探索。根据ε-贪婪算法选择动作与环境交互,根据在环境中得到的奖励更新Q表。 步骤6:判断当前阶段奖励值重复次数,如果未达到奖励阈值Rmax,则转入步骤5。 步骤7:判断是否到达目标点,如果未达到目标点,跳出当前阶段路径规划,进入下一阶段路径规划,转入步骤2。如果达到目标点,则完成全局最优路径规划。 根据上述算法流程可得到算法流程如图3所示。 图3 阶段Q学习算法路径规划流程框图 为验证提出的阶段Q学习算法的可行性和有效性,本文将在Pycharm2020.1.3环境下进行仿真实验,采用Open AI的Gym环境建立栅格环境。 操作系统环境为Windows10 x64,使用软件工具包版本为Python3.6,硬件信息为Intel i7-9750H、DDR4 16GB和1.86TB SSD。 在同一实验环境下将本文阶段Q学习算法与传统Q学习算法进行对比。算法参数为:环境信息n=20,最大步长2n=40,阶段数量N=4,探索次数m=5,奖励阈值Rmax=3,学习系数α=0.2,折扣因子γ=0.9。在安全避障且能达到目标点的前提下,以最快路径规划为指标,分别采用传统Q学习算法和阶段Q学习算法进行仿真计算。仿真结果如图4、图5、图6及表1所示。 图4 传统Q学习规划路径示意图 图5 阶段Q学习规划路径示意图 图6 回合数-奖励值曲线 通过对比分析图4、图5及表1中仿真结果可知,本文设计的阶段Q学习算法能够有效规避路径中的障碍。在相同的仿真环境下,阶段Q学习在路径规划时间及算法收敛时间指标上均优于传统Q学习。阶段Q学习算法路径规划时间为202s,相比传统Q学习规划路径时间398s减少了49%。阶段Q学习算法在第22回合开始收敛,传统Q学习算法第36回合开始收敛,同比降低了39%。 表1 2种算法的仿真数据 在同一实验环境下,采用阶段Q学习算法将不同的阶段数量时的路径规划情况进行对比。仿真环境仍为大小为20*20的网格环境。 算法参数同3.2节。在安全避障且能达到目标点的前提下,以最快路径规划为指标,采用改进Q学习算法分别设置不同的阶段数量进行仿真计算,仿真结果如图7、图8及表2所示。 图7 不同阶段数量的收敛回合数直方图 图8 不同阶段数量的路径规划时间直方图 通过对比分析图7、图8及表2仿真结果可知,阶段Q学习算法中不同阶段数量会影响算法的收敛速度和路径规划时间。其中,当N=2时,算法的路径规划时间和收敛回合数最小,分别为196 s,30。当N逐渐增大时,算法的路径规划时间和收敛回合数随之增大,这一现象与奖励阈值设置有关。不论奖励阈值设置的大小,当阶段数量变多时,机器人在每一阶段探索时会重复之前所有阶段的路径,这将影响算法的学习效率和收敛时间。值得注意的是,当N=1时,意味着1次性规划从起始点到终止点的路径,这时阶段Q学习算法等价于传统Q学习算法。 表2 不同阶段数量的仿真数据 根据以上仿真结果可知,阶段Q学习算法相比传统Q学习算法更优,而且收敛时间更短。这是由于采用了分步最优搜索改进了Q学习算法中的搜索方式,避免了训练中选择动作的不确定性,因此可以提高算法的学习效率。此外,不同的阶段数量N将会影响阶段Q学习算法的收敛速度,通过设置合理的阶段数量可以有效提高阶段Q学习算法的学习效率,减少算法的收敛时间。 1) 为了提高算法的收敛速度和学习效率,借鉴最优控制思想,提出了基于阶段Q学习算法,通过设置探索步长和奖励值,确保每一阶段探索为最优路径,提高算法收敛速度。 2) 阶段Q学习算法与传统Q学习算法仿真对比可知,阶段Q学习算法能够明显提升算法收敛速度,减小路径规划时间,更利于机器人的行驶。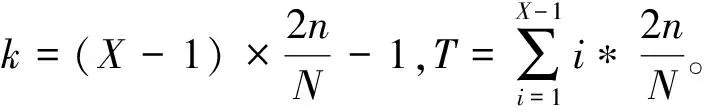
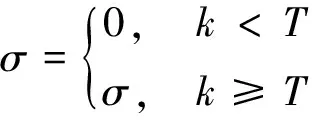
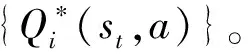
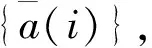
3.3 阶段Q学习路径规划算法设计

3.4 阶段Q学习路径规划算法流程
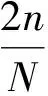
4 仿真与分析
4.1 仿真条件设定
4.2 阶段Q学习路径规划算法仿真验证
4.3 调整各阶段探索步长仿真验证
4 结论
