基于改进YOLOv3算法的变电站安全防护装备智能检测方法
2022-06-02赵凌骏庄汝学周林康姚浩威
赵凌骏,庄汝学,周林康,王 慧,姚浩威,刘 娜
(苏州电力设计研究院有限公司,江苏 苏州 215011)
0 引言
变电站在电力系统电压转换、功率集中和分配过程中起着关键作用。随着电网规模不断扩大,大型变电站数量不断增加,其安全稳定运行对电力可靠传输至关重要[1]。
近年来,电力系统智能化水平不断提升,变电站智能运维技术引起了广泛的研究关注[2,3]。在施工现场,合理监控作业人员的安全防护装备是减少突发事故和工伤的关键。
目前,个人安全防护装备的自动检测方法大致可分为基于传统的图像处理和基于深度学习方法2类。传统方法利用图像处理技术来提取工人的肤色、头部和面部信息。例如,文献[4]开发了一种基于K最近邻算法的安全帽自动检测系统。文献[5]利用Hough变换确定安全帽的形状,使用提取的定向梯度直方图特征来训练支持向量机,以准确检测出安全帽。然而,传统的安全帽检测方法没有考虑变电站复杂运行环境的影响[6],检测结果易受环境光线、周围物体等的影响而导致误报。
深度学习算法因其能够从数据中自动学习有效的特征信息而被广泛应用于图像检测领域[7]。深度神经网络具有多层结构,可以学习当前输入和输出数据之间的映射关系[8]。深度学习算法为电力系统中目标检测任务的实现提供了新思路[9]。
作为基于深度学习的对象检测方法,Faster-RCNN[10]、SSD[11]、DSSD[12]、RetinaNet[13]和YOLO算法[14]分别在实际工程应用中显示出了各自的优势。文献[10]用一种改进的Faster-RCNN模型来检测单个设备部件的坐标、方位角和类别。文献[15]提出一种基于 Faster-RCNN的变电站作业人员安全帽检测方法,检测准确率达 90%。文献[16]将在线硬样本挖掘与多部分检测方法相结合,用于识别工人是否佩戴安全帽。此外,文献[17]用边界框回归和迁移学习来改进基于卷积神经网络的人脸识别技术。上述文献研究内容大多是关于安全帽的检测,很少有文献关注其他类别安全防护装备的检测。
文献[18]在YOLO算法架构上建立了3种深度学习模型,用于验证工人安全防护装备的合规性;然而,算法的平均检测精度不足 75%,且检测速度有待进一步提高。
变电站环境下的安全防护装备实时检测任务具有3个特征:(1)变电站视频的背景通常较为复杂且摄像机的分布远离变电站员工,导致采集到的视频图像分辨率和强度对比度较低。(2)安全防护装备尺寸太小导致其与背景不易区分。(3)实时监控要求检测模型具备高速处理能力。现有深度学习方法的简单应用尚无法满足要求。
针对上述问题,本文提出了一种改进YOLOv3方法:采用Gamma校正技术对数据进行预处理,突出图像的人物细节,提高检测精度。另外,引入K-means++算法确定最适合的先验边界框大小,以提高检测精度和速度。最后,在实际变电站的监控图像数据集上进行仿真实验;实验结果表明该方法能够准确监测变电站作业人员是否正确佩戴安全帽等防护装备。
1 安全装备智能检测方法构架
针对变电站监控图像背景复杂、角度多变的特点,本文提出了面向变电站作业人员和安全防护装备的综合检测定位模型。与现有模型仅关注安全帽的识别不同,该方法可以对变电站作业人员、安全帽、绝缘手套和靴子进行综合检测。
方法包括预处理、数据增强、改进 YOLOv3模型训练和迁移学习4个阶段,如图1所示。
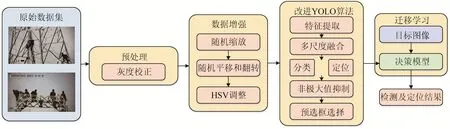
图1 算法基本架构Fig. 1 Basic structure of the algorithm
1.1 预处理
本文通过 Gamma校正对监控图像或视频进行预处理,过滤掉不相关信息,以加快后续YOLOv3算法的训练过程。
在计算机图形学领域中,屏幕输出电压与相应亮度之间的转换曲线称为Gamma曲线[19]。通过检测图像信号的暗部和亮部并改变它们的比例,Gamma校正可以用来修正Gamma曲线和调整图像的非线性色调,从而得到对比度效果较好的图像。
Gamma校正的具体步骤如下。
(1)标准化:将每个像素值转换为0~1之间的范围。即IN=(I+0.5)/256,其中I为原始像素值,IN为归一化的像素值。
(3)去规范化:将预补偿后的规格化值IN′转换到原始的0~255取值范围。
1.2 数据增强
由于变电站采集到的相关数据量通常比较有限,本文方法采用3步数据增强技术。
数据增强可以提高神经网络的泛化能力,避免学习过程中的过拟合问题[20]。
第一步:随机擦除。工作原理是随机选择图像中一个特定大小的部分,并将其用0 s、255 s、平均或随机像素值屏蔽。
第二步:使用随机平移和旋转来增加图像的数量。原始图像一般可以旋转1°~359°。将图像向左、向右、向上或向下移动,通常均是较为有效的变换方式。
第三步:将监测图像转换到HSV空间,随机调整图像的曝光度、饱和度和亮度,以生成辅助图像。
1.3 改进YOLOv3算法
1.3.1 基于YOLOv3的检测与定位网络
YOLOv3是一种单阶段的目标检测算法。经过改进后,该算法可以预测变电站作业人员和安全防护装备的边界框,其网络的基本架构如图 2所示。

图2 基于YOLOv3的检测与定位网络Fig. 2 Detection and location network based on YOLOv3
为了提取输入图像的特征,YOLOv3使用了Darknet-53网络结构,能够解决梯度消失或爆炸的问题[21]。YOLOv3预测了3种不同尺度的边界框,以便在特征图所对应的层较深时,减少相应的信息丢失。
多尺度特征图有助于提高对不同大小的安全防护装备的定位精度。如图2所示,在特征提取后,将输出特征图划分为s×s网格,确定每个网格单元预测边界框和所属类别的概率值。每个边界框包含4个坐标tx,ty,tw和th,以及预测的置信概率值。最后,利用非最大抑制技术选择概率最高的相似边界框,得到图像或视频中安全防护装备的类别和位置信息。
1.3.2 先验边界框的确定
为了降低训练难度,利用先验边界框对表征安全防护装备位置的预测边界框进行调整。
原始YOLOv3使用K-means聚类来获取最适合的先验边界框,但初始K个聚类点是随机选取的,这对最终的聚类结果影响很大。因此,本文采用K-means++聚类来改进先验边界框大小的选取过程,以有效分析监控图像中安全帽、绝缘靴和手套的高度和宽度。
设网格单元距离图像的左上角偏移量为(Cx,Cy),且先验边界框的宽度和高度分别为pw和ph,则预测边界框的位置将根据式(1)调整为:
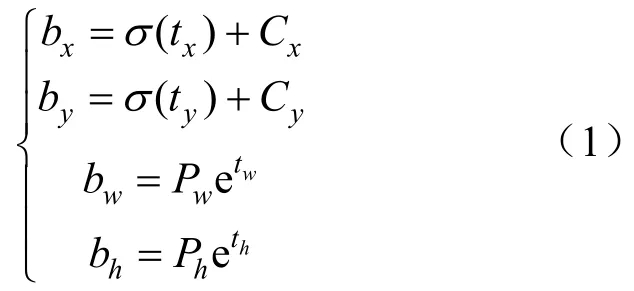
式中:bx和by为边界框的中心坐标;bw和bh分别表示边界框的宽度和高度;σ(∙)表示 sigmoid函数,可以将预测偏移量的值限制在0~1的范围内。
聚类中,关于距离的定义采用的是IOU距离,其计算方法如下:

式中:A、B为边界框;d为A、B之间的IOU距离,其值越大,表示A、B的边界框靠的越近。
相比之下,在使用K-means++聚类后,当一个点远离当前聚类点时,则该点被认为是聚类点的概率较高,这样就有效降低了初始聚类点随机选取对结果的影响,从而提高了检测速度。
具体计算过程如下:
(1)考虑训练集中边界框的标签信息。用Y1,Y2,···,Yk表示k个聚类点。
(2)随机选定一个边界框为第一个聚类点Y1。
(3)计算每个样本xi与其最近聚类点之间的IOU距离d(xi,Yk)。由式(3)得到该点被选为下一个聚类点的概率

根据轮盘赌法确定下一个聚类点。
(4)重复步骤(3),直到聚类点数为k。
(5)对于每个边界框,计算其与确定的k个聚类点的IOU距离,然后将其分配到IOU距离最小的集群。
(6)根据聚类中 IOU距离的中位数对聚类点进行修改,然后重复步骤(5),直到聚类点不再改变。最后,k个聚类点分别代表安全防护装备和工人的数量。
1.3.3 优化目标
改进YOLOv3的损失函数可分为3个部分:位置损失Lloc,置信度损失Lconf和分类损失Lcls,如式(4)所示:
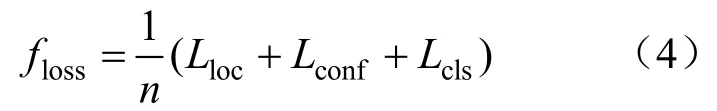
式中:n为训练图像的总个数。
Lloc、Lconf和Lcls的计算方法如下:

式中:Lxy为相对于边界框的坐标;Lwh为相对于边界框的距离;w、h分别为标准化预测边界框的宽度为高度。
当第i个网格单元中的第j个先验框被用来预测目标时,为1,否则为0。当第i个网格单元中的第j个边界框没有被用来预测目标时,为1,否则为0。表示第i个网格单元中第j个先验边界框对应的预测值的置信度为对应的实际值。当第i个网格单元的第j个边界框用于预测安全防护装备和工人时,对应边界框的实际置信度为1,否则为0。为第i个网格单元中第j个先验边界框所对应的类别预测值,为对应的标签值。
1.4 迁移学习
Darknet-53网络的训练需要依赖大量的训练数据;然而,变电站的监测图像数据不足。若通过原始数据集直接训练YOLOv3,则计算量巨大且性能较差。为了解决这一问题,本文采用的改进YOLOv3在Pascal VOC数据集上进行了预训练。
Pascal VOC数据集包含27 450张图像,涵盖人、动物、家具、车辆等20种对象。
迁移学习使YOLOv3具有更强的泛化能力,能够学习在安全防护装备检测中有用的基本特征和中级特征(如图像边缘、颜色信息、物体形状)[22]。
该过程可分为以下3个阶段:首先,将预训练模型中各层的网络参数传递到改进YOLOv3网络中。然后,对前几层的参数进行固定,对后几层的参数以较大的学习率进行训练,以提高改进YOLOv3的训练速度。最后,动态降低学习速率,并对所有参数解除固定并进行微调。
2 算例分析
2.1 数据集
由于没有公开可用的安全防护装备数据集,本算例分析中的数据从某供电局的几个变电站收集。
数据集包含522张图像,包括变电站作业人员和3种安全防护装备,即、安全帽、绝缘靴和绝缘手套。在实验研究中,随机选择大约 80%的图像作为训练集,其余的20%用于测试集。
图3显示了测试数据集中的典型样本。从图3中可以看出,变电站监控图像中不可避免地出现了很多噪声,如周边护栏、变压器等。随着摄像机角度的变化,电力设备可能会部分遮挡作业人员,导致边界框标注模糊,影响边界框的学习。同时,图像具有背景复杂、对比度弱、画面不清晰等特点。

图3 变电站监测图像数据集的典型样本Fig. 3 Typical examples of the substation monitoring image dataset
本文采用了 3个评价检测性能的指标:第 1个指标是平均精度(average precision,AP),用于衡量每个类别的检测结果。第2个指标是所有类别AP的平均值(mean of AP,mAP)。第3个指标是每秒帧数(frames per second,FPS),表示每秒检测到的图像数量,它反映了检测模型的运行速度。通过这3个指标,可以分析图像检测和定位模型的效果。
2.2 改进前后先验边界框的比较
本文改进YOLOv3算法使用K-means++聚类代替原始算法中的K-means聚类。
每组实验重复10次,实验结果如表1所示。

表1 聚类前后先验边界框的检测结果对比Tab. 1 Comparison of detection results of prior bounding boxes before and after clustering%
从表1可以看出:虽然本文方法得到的工人和安全帽的 AP略有下降,但绝缘手套和靴子的AP明显上升。总体而言,mAP相比原始YOLOv3显著上升了8.04%。同时,原始YOLOv3的FPS与改进算法几乎相同,但改进后先验边界框的识别和定位较之前更准确。
实验表明,改进YOLOv3可以准确获取先验边界框并检测出小型物体,即绝缘手套和靴子;因此,该模型更适用于变电站作业人员和安全防护装备的分类和定位。
2.3 预处理前后图像的比较
不同天气状况对监控视频和图像的影响很大;不同的角度也使安全帽、绝缘手套和靴子难以检测。
变电站的背景对安全防护装备的定位有显著影响。与简单背景的普通图像不同,变电站的监控图像往往包含避雷器、断路器等多种设备。
变电站监控图像和视频的以上这些特点增加了安全防护装备和作业人员的检测难度。
经过Gamma校正后,监测图像中的作业人员和安全防护装备更容易识别。图 4示出了基于Gamma校正的预处理结果。例如,在背光条件下,Gamma校正后图像中的物体明显更容易被分类和定位。

图4 Gamma校正的预处理效果Fig. 4 The pre-process effect of the Gamma correction
Gamma校正可以突出安全防护装备的细节,减少复杂背景的干扰。通过图像预处理,在有效地解决了上述2个问题的基础上,可以更方便地实现改进YOLOv3算法的后续检测。
图像预处理方法可以通过增强图像的对比度和特征细节来提高模型的检测能力。
如图5所示,预处理后,图像中的工人、安全帽、绝缘手套、绝缘靴的AP均增大。

图5 预处理前后监控图像的平均精度比较Fig. 5 Comparison of average accuracy of original and preprocessed images
表2给出了预处理前后变电站监控图像的检测结果。

表2 预处理前后变电站监控图像的检测结果Tab. 2 Detection results with and without pre-processing on monitoring images %
检测性能的提升充分体现了预处理的优越性,也证明了Gamma校正能使改进YOLOv3更适用于安全防护装备和工人的分类和定位。
2.4 与其它图像检测方法的比较
为了评价本文方法对变电站监控图像的处理效果,将改进YOLOv3对安全防护装备和作业人员的检测结果与 Faster R-CNN、SSD、DSSD和RetinaNet所得结果进行比较。
由表3可以看出,Faster R-CNN、SSD、DSSD实验结果的mAP均低于本文提出的检测模型。虽然使用SSD和DSSD对工人检测的AP略高于改进 YOLOv3,但本文方法对安全帽、绝缘手套和绝缘靴的检测精度要高很多。RetinaNet的检测精度略低于本文方法。Faster R-CNN、SSD、DSSD、RetinaNet的FPS明显低于本文改进YOLOv3的结果。

表3 不同方法检测结果比较Tab. 3 Comparative results using different detection methods %
与其它方法相比,本文方法的检测速度至少提升了50%。
图像预处理技术、改进的先验边界框和有效的迁移学习算法,提高了基于YOLOv3算法架构的检测精度,增强了对安全防护装备的检测能力。采用迁移学习的方法加速了改进YOLOv3的训练过程,大大提高了检测精度。因此,本文提出的检测模型相比 Faster R-CNN、SSD、DSSD和RetinaNet能更精确地实现对安全防护装备和工人的分类和定位。
本文改进YOLOv3算法的检测速度足以处理日常的实时检测任务。
3 结论
本文对YOLOv3算法进行改进,提出了一种新型变电站安全防护装备和作业人员的检测模型,实现了变电站运行中安全防护装备的准确检测。
(1)Gamma校正的使用,使检测结果的mAP提高了2.28%。改进YOLOv3算法中的K-means++比原始YOLOv3中的K-means聚类能够产生更有效的先验边界框,mAP提高了8.04%。
(2)改进 YOLOv3算法不仅在检测精度上优于目前广泛使用的图像检测算法,而且图像检测的速度至少提高了50%。
(3)改进 YOLOv3算法可以在图像背光、复杂背景和遮挡等极端条件下正常使用,说明该算法具有优越性。
鉴于YOLO算法架构灵活,在后续研究工作中可对YOLOv3中的各个模块进行改进,进而开发系列新的算法。
