基于全局有向图的商品会话序列推荐算法
2022-05-30苗启朋何丽莉白洪涛
苗启朋, 何丽莉, 姜 宇, 白洪涛
(吉林大学 计算机科学与技术学院, 长春 130012;吉林大学 符号计算与知识工程教育部重点实验室, 长春 130012)
在推荐系统中, 商品的会话序列是一种特殊的数据形式, 指在一段时间内某用户点击商品的次序, 具有数据量大、 随机性强、 用户匿名情况多等特点. 基于会话序列的商品推荐旨在通过已有的会话预测当前用户下一个可能感兴趣的商品实体. 传统的推荐系统通常只关注于会话序列最后一个商品项目实体(简称项目)或某几个会话中的项目转换[1], 局部偏好过强导致推荐效果不理想, 甚至易引起用户的反感. 随着会话序列数据量以及用户的不断增加, 传统方法做出推荐的计算代价也在增加. 在推荐领域, 协同过滤以实现简单且推荐准确被众多电商网站广泛使用. 协同过滤可分为基于用户的算法和基于项目的算法两类[2]. 基于用户的协同过滤核心是计算用户与邻居用户之间的相似性[3], 根据邻居用户的点击情况, 预测当前用户可能的点击情况, 需要用户的明确偏好和历史交互[4]. 在实际推荐系统中, 需要维护一个巨大的用户商品交互矩阵, 有严重的矩阵稀疏性问题, 新增加用户或商品也将导致重新计算用户相似度, 可伸缩性差[5-7]. 在用户匿名情况较多时, 基于用户的协同过滤也无法满足需求. 与基于用户的协同过滤算法不同, 在会话序列推荐中基于项目的协同过滤推荐准确度较好, 算法复杂度低, 但由于需要计算所有商品项目的相似度信息, 也有一定的计算代价. Markov链方法是一种基于当前用户最后一次点击项目的最近点击情况预测下一个项目的方法[8], 它不能捕捉会话整体特征以及全局项目点击信息, 且只关注了最后一次的点击项目, 基于Markov链推荐的准确度也低于基于项目的协同过滤算法. 总之, 传统的推荐方法在用户匿名以及大规模数据量的情况下性能较差. 因此, 能满足在匿名情况下使用且实现简便、 推荐效率高的算法成为该领域当前研究的热点问题.
基于上述问题, 本文提出一种基于全局有向图的商品会话序列推荐算法(session recommendation algorithm based on global directed graph, SRGDG). 采用Neo4j图数据库[9]存储项目点击关系构建全局会话序列有向图, 并使用全局偏好传播的策略得到当前会话序列每个项目的全局影响, 最后获得当前会话的待推荐项目评分信息. 在获取评分过程中, 通过提高会话序列中靠后项目对应的参数考虑点击的时间因素对推荐的重要影响, 并通过大量的对比实验验证了所提出方法的有效性.
1 预备知识
1.1 基于项目的协同过滤算法
Item-KNN[10]通过计算项目之间的相似度找到与当前项目最相似的k个项目.项目相似度的计算方式一般有两种: 通过共现规则和计算项目向量表示之间的余弦值[11].共现规则即若两个项目出现在同一会话中, 则它们即为共现的, 从而根据共现的次数计算相似度.
通过计算余弦值计算相似度[12]的一般算法如下:
步骤1) 对于会话序列中正在点击的项目, 通过计算项目向量之间的余弦值计算与待推荐项目的相似度, 选出与该项目最相似的前k个项目,k也称为该项目的邻居数;
步骤2) 从与项目最相似的k个邻居中删除用户已点击过的项目集合M, 剩余的保存到集合R中;
步骤3) 计算集合R和M中每两个项目的相似度, 最后按照相似度大小将R中项目排序并做出推荐.
项目之间的相似度可以离线进行计算, 在实际推荐过程中只需进行项目相似度的比较[13], 但若项目数据量较大, 则离线计算的代价也会很大. 此外, Item-KNN只计算了项目之间的相似度, 且仅基于最后一次点击生成预测, 并未考虑当前会话序列中项目的点击次序以及其他项目. 因此, 本文基于图数据库, 提出一种优于传统协同过滤的基于全局有向图的商品会话序列推荐算法[14].
1.2 图数据库
本文使用的Neo4j图数据库是一个目前在技术及市场中应用最广的NOSQL图数据库. Neo4j3.0可根据需要动态地扩展可用地址空间, 能存储任意大小的图数据, 并改进了Cost-based查询优化器, 支持多种语言驱动器, 能满足存储大数据量点击序列的需求, 与其他图数据库相比, Neo4j还具有规模较大及较活跃的社区. Cypher是Neo4j图数据库的声明式查询语言, 通过图模式匹配的方式进行数据查询或修改, 语法规则类似SQL. 本文使用neo4j-import api进行数据集的插入.
2 SRGDG算法
2.1 数据预处理
数据集的每行数据包含该次点击的session_id(会话id), item_id(项目id), timeframe(时间片), eventdate(日期). 首先将数据集进行预处理, 提取出图数据库节点集和节点关系集. 预处理步骤如下.
1) 对于每行点击数据, 提取项目以生成图数据库节点集.
2) 对于每个会话序列, 将项目按照时间片排序. 定义点击关系: 在同一会话中每两个前后相邻的项目有一次点击关系, 即“item_id1(项目id1), item_id2(项目id2)”.
3) 遍历数据集所有点击关系, 将点击关系出现的次数作为节点关系的属性值, 定义节点关系: “item_id1(项目id1), item_id2(项目id2), weight(属性值)”, weight表示该点击关系出现的次数. 提取所有节点关系生成节点关系集.
最终将原始数据集转化为图数据库节点集和节点关系集.
2.2 构建全局有向图
本文基于图数据库技术构建全局有向图. 通过Neo4j的neo4j-import api将数据预处理后得到的两个数据文件导入图数据库(将Diginetica数据集导入数据库用时4.57 s, 将Yoochoose数据集导入数据库用时3.78 s). 将所有的项目节点以及关系导入数据库后, 可得到数据集所有会话序列的全局有向图G=(V,E), 其中V为图数据库节点集,E为节点关系集. 图1为项目实体节点在图数据库中的连接情况示例, 其中实体之间的边具有属性click, 属性值为权重weight(节点关系集中的属性值类型为int).

图1 数据库节点连接示例Fig.1 Example of node connecting in database
2.3 全局偏好传播评分策略

图2 节点偏好传播“波纹”Fig.2 Node preference propagation “ripple”
波纹式传播[15-16]是一种典型的网络传播模型, 该模型体现了在社交网络中一对多广播的特点. 受波纹式拓扑模型的启发, 本文提出通过全局项目偏好传播策略获得项目的全局影响. 全局偏好传播就是项目按照偏好传播规则在全局有向图中传播影响. 一次点击就产生一个“水波”在有向图中向外扩散, “水波”会有叠加效应, 一个会话中有多次点击, 最后在图中寻找受“水波”影响最大的项目做出推荐. “水波”在传播过程中有衰减机制, 否则将永不停止地扩散, 本文将路径长度作为衰减参数. 图2为一个项目节点的偏好传播“波纹”示例, 其中内圈为1-hop节点, 外圈为2-hop节点, 从内到外传播的影响将逐渐减弱.
项目在图中偏好传播以及评分规则如下: 对于每个项目, 建立一个初始值为0的m元数组(m的大小为项目总数, 数组每个下标对应项目id), 数组中的每个元素对应一个项目节点的评分值, 通过该项目的偏好传播更新数组中对应的元素值. 评分策略如下:
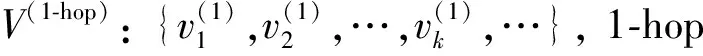


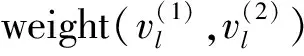
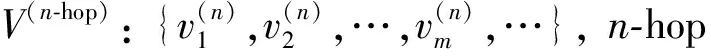
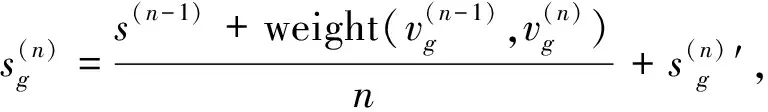
(1)

基于全局有向图的商品会话序列推荐算法步骤如下:
1) 对于当前会话S{v1,v2,…,vn}的项目vi, 初始化对应的m元为0的数组si,m为项目总数;
2) 使用cypher语句在图数据库中搜索vi项目的1-hop,2-hop集合, 并根据全局偏好传播策略更新对应的评分值到si数组中(在实验中遍历1-hop取得了较好结果);
3) 将通过会话S{v1,v2,…,vn}节点偏好传播得到的n个m元数组s1,s2,…,sn按照

(2)

图3 节点偏好传播示例Fig.3 Example of node preference propagation
的加和得到m元数组s,s即为当前会话S的全局评分, 取s中Top20元素的数组下标对应的项目做出推荐.
在考虑时间因素的情况下, 会话序列中最近被点击的项目有更大的影响力, 因此式(2)中参数ki设置规则为:kn>kn-1>…>k1, 本文通过实验分析验证了不同组参数设置对推荐的影响.
图3为会话{v1,v2,v3}的情况示例, 其中a,b,c,d,e为有向图中的关系权重,k2,k3是v2,v3对应的参数权重.此时v4,v5是v3的1-hop节点,v3,v5是v2的1-hop节点, 而v4则是v2的2-hop节点.由全局偏好传播策略, 此时v3总评分
scorev3=k2×e,
v5总评分
scorev5=k2×a+k3×b,
v4总评分
scorev4=k3×c+k2×(a+d)/2.
最后根据v3,v4,v5的评分值大小决定被推荐的优先级.
3 实 验
3.1 数据集与评价指标
本文使用目前在商品会话序列推荐研究中应用最广泛的两个标准数据集Diginetica(http://cikm2016.cs.iupui.edu/cikm-cup)和Yoochoose(http://2015.recsyschallenge.com/challege.html). Diginetica是CIKMCup2016公开数据集, 为欧洲某电商平台6个月内所有匿名用户的交易数据; Yoochoose是RecSys Challenge 2015比赛的公开数据集, 其包含了某电子商务网站6个月的点击流. 本文将Diginetica数据集最后7 d的会话作为测试集, 而将其他会话序列作为原始数据存入图数据库. Yoochoose 1/64数据集取最后1 d的会话作为测试集, 其他会话序列作为原始数据存入图数据库. 两个数据集的基本信息列于表1.

表1 实验数据集信息
本文采用P@20和MRR@20作为评价指标. P@20(Precision@20)表示前20名中有正确推荐的占所有推荐的比例, 在推荐领域广泛使用:
P@20=Chit/N,
(3)
其中N表示做出推荐的总次数,Chit表示前20名中有正确推荐的总次数. MRR@20(mean reciprocal rank)表示平均数倒数排名, 是正确推荐在前20名推荐结果排名的倒数相加结果(如果无正确推荐项就设倒数后的值为0), 其中较大的MRR值表示正确的推荐在推荐结果中排名靠前:

(4)
其中N表示做出推荐的总次数, rank(t)表示每次推荐中正确推荐项在推荐列表中所排的位置.
3.2 算法比较与分析
实验比较本文方法与基于项目相似性的方法Item-KNN[10]、 Bayes排序的方法BPR-MF[17]和Markov链的方法FPMC[2]的性能. 评价方法参考当前主流评价方法[18]. 通过在两个数据集上不同参数设置情形下的多次实验, 所得结果列于表2.

表2 不同方法在两个数据集上的推荐准确率结果比较
由表2可见: Item-KNN方法优于多数基于Markov链的方法, 因为多数基于Markov链的方法仅使用会话中最后一个项目实体在最近会话中的项目点击信息, 在大规模数据量情况下, 其不能获得某个项目全局的点击信息; 本文的SRGDG方法优于Item-KNN方法, 在Diginetica,Yoochoose 1/64两个数据集上, P@20分别提高了6.12%,30.25%, MRR@20分别提高了15.04%,33.88%. 相比较而言, MRR@20值提高的更多, 体现了Item-KNN方法只考虑了项目的相似关系, 未考虑先后次序的缺点. SRGDG方法通过对数据集全部会话进行建模构成全局有向图, 在全局有向图中扩散会话各项目的影响, 同时增加会话中靠后项目的偏好参数, 最终获得当前会话序列的推荐, 该方法既考虑了会话中项目的先后顺序, 又考虑了会话中其他项目的影响, 实验结果证明该方法有效. 由于Yoochoose 1/64数据集的项目数少于Diginetica数据集, 且各项目之间的关联性更强, 因此Yoochoose 1/64推荐的准确率远好于Diginetica数据集上的准确率, Diginetica数据集则更类似于现在的大规模商品与用户的实际情况. 此外, 图数据库可根据需求增加商品数量以及设置点击关系权重, 因此SRGDG方法也具有解决推荐系统可扩展性与避免矩阵稀疏性问题的优势[19]. 由于全局点击关系都是可见的, 因此使用图数据库也增强了推荐系统推荐的可解释性.
3.3 偏好传播策略的有效性检验
式(2)获得了全局评分信息. 通过在Diginetica和Yoochoose数据集上的大量实验表明, 全局偏好传播策略能提升推荐准确率. 由于式(2)中的k1,k2,…,kn有kn>kn-1>kn-2>…>k1的规则, 且由图4和图5的Diginetica和Yoochoose数据集会话序列长度分布图可见, 大量会话序列的长度都小于3和4, 因此, 实验中首先分析每次会话中最后3个项目实体对应kn-2,kn-1,kn的影响, 对于其余项目实体对应的k1,k2,…,kn-3则设置为0.不同的(kn-2,kn-1,kn)组合在数据集上的实验结果分别列于表3和表4. 在Diginetica数据集和Yoochoose数据集上各组参数设置的实验结果比较分别如图6和图7所示.

图4 Diginetica数据集会话序列长度分布Fig.4 Distribution of Diginetica data set session sequences length

图5 Yoochoose数据集会话序列长度分布Fig.5 Distribution of Yoochoose data set session sequences length

表3 在Diginetica数据集上各组参数设置的推荐准确率结果比较

表4 在Yoochoose数据集上各组参数设置的推荐准确率结果比较
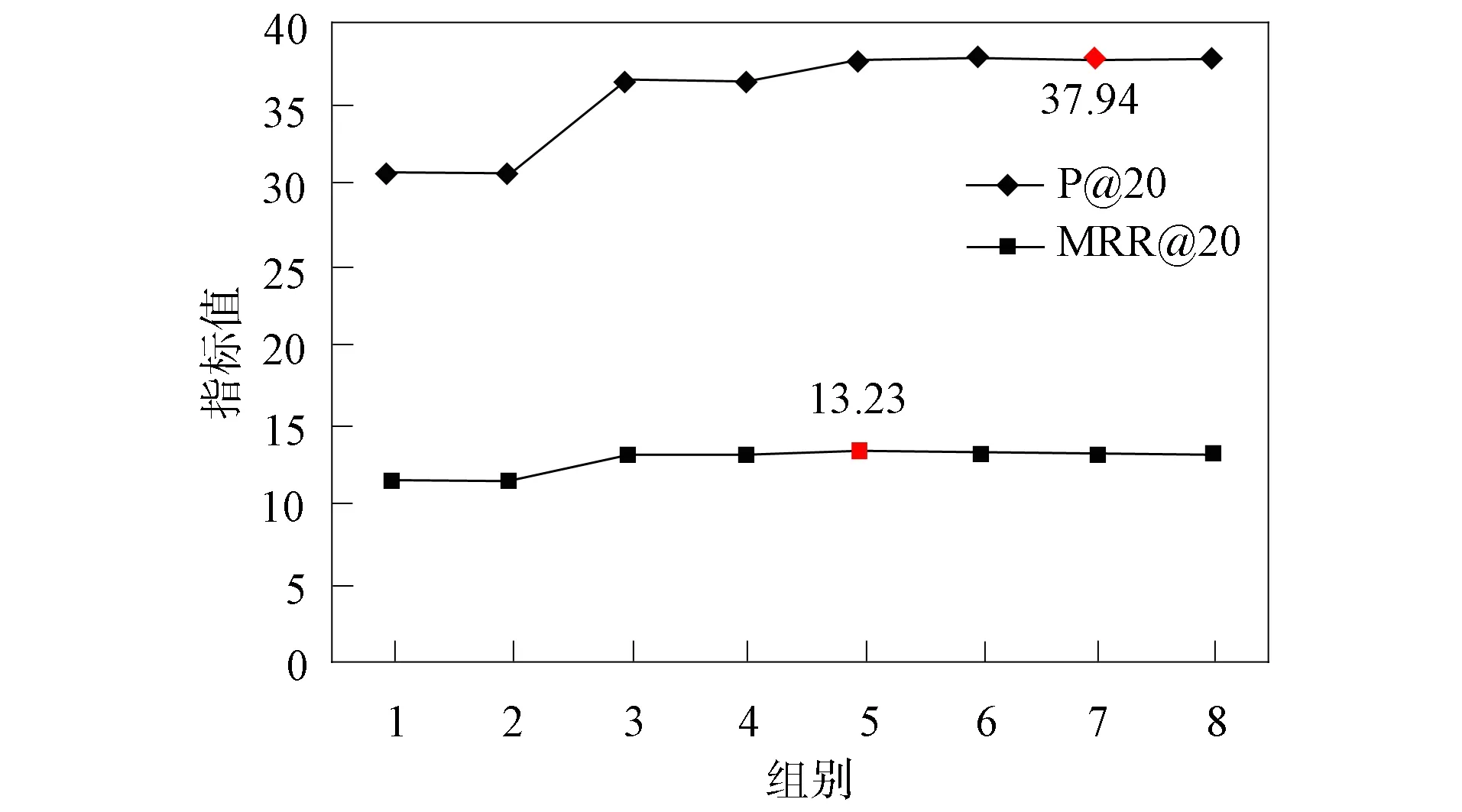
图6 Diginetica数据集上各组参数的推荐结果比较Fig.6 Comparison of recommended results of each group of parameters in Diginetica data set

图7 Yoochoose数据集上各组参数的推荐结果比较Fig.7 Comparison of recommended results of each group of parameters in Yoochoose data set
由表4可见: 在Diginetica数据集上的实验中, (0,0,1)组相当于只考虑了最后一个项目的影响, P@20值为30.77%; (0,0.4,1)组考虑了最后两个项目的影响, 但倒数第二个项目由于系数较小导致影响较小, 实验结果基本与(0,0,1)组相同; (0,0.6,1)组增加了倒数第二个项目的影响, P@20比上一组提高了19.07%, MRR@20提高了13.25%; (0,0.8,1)组相对于(0,0.6,1)组提升较小, 说明倒数第二个项目的影响已经达到了较好的效果; (0.2,0.6,1)组相比于(0,0.8,1)组P@20提高了3.46%, MRR@20提高了1.29%, 如图7所示. 表明考虑倒数第三个项目也会有影响, 并且能提升推荐的准确度, 但后序组提升不明显. 由于第5,6,7,8组提升相比于第2,3,4组提升较小, 因此本文认为仅考虑会话最后3个节点的全局影响已经能得到较好的推荐结果, 如果继续向前设置参数, 不仅会增加推荐的计算代价, 且提升较小, 考虑最后3个节点已经验证了考虑多个节点影响的全局偏好传播策略的有效性.
同理, 在Yoochoose 1/64数据集上也同时考虑后3个节点能得到推荐结果的较好值. 在组(0.2,0.4,1)中P@20取得了最好值, 比(0,0,1)提高了3.71%. 由于在Yoochoose 1/64数据集上已经达到了一个较好的精度, 在MRR@20值的比较上, 总体提升较小, 或者有下降. 经过在两个实际数据集上大量的实验证实, 多个实体的偏好传播策略能有效提升推荐的准确度.
综上所述, 针对目前很多推荐系统推荐效果差、 算法复杂度高的问题, 本文提出了通过构建全局有向图的方法对数据集所有会话序列进行建模, 对于当前会话使用偏好传播策略并考虑时间因素获得会话中项目的全局影响, 从而生成所有待推荐项目的评分, 从中优选Top20做出推荐. 在两个标准数据集上的实验结果表明, 与传统基于项目的协同过滤以及Markov链等方法相比, 本文方法在P@20和MRR@20评价指标下性能均更好.
