基于邻域信息的网络结构表示学习
2022-05-30王喆,李鑫
王 喆, 李 鑫
(吉林大学 符号计算与知识工程教育部重点实验室, 长春 130012;吉林大学 计算机科学与技术学院, 长春 130012)
网络中的节点具有一个或多个角色, 节点可根据其在网络中所扮演的角色划分等价类, 即角色识别. 分析和识别网络中节点的角色, 能帮助研究人员更好地理解网络的属性和演化, 并且拥有广泛的应用场景, 例如: 支付网络中的欺诈检测[1]、 蛋白质功能预测[2]等. 节点在网络中所扮演的角色可体现在节点的网络结构中[3-4], 例如: 社交网络中的领导者常对应网络中心节点[3]; 蛋白质相互作用网络中具有相似功能的蛋白质常具有相似的结构[5]. 因此, 可根据节点的结构信息进行角色识别.
由于网络数据具有高维、 非线性等特征, 因此直接在原始的网络数据上进行分析推理较困难. 为解决此类问题, 提出了网络表示学习方法[6], 它将网络中的节点映射为低维稠密的表示向量, 同时使原始网络中相似的节点在嵌入空间距离相近. Perozzi等[7]提出的DeepWalk方法在网络上执行随机游走产生节点序列, 然后将节点序列集合输入到自然语言处理处理模型Skip-Gram中, 从而学习节点的潜在表示向量; Grover等[8]提出的node2vec在DeepWalk的基础上弥补了随机游走采样策略单一化的缺点, 采用有偏随机游走策略, 在随机游走时平衡节点的深度优先遍历和宽度优先遍历, 更灵活地探索节点的网络邻域; 随着对节点邻域探索细致化的趋势, Tang等[9]提出了LINE算法, 该方法定义了节点间的一阶相似度和二阶相似度, 通过同时优化一阶损失函数和二阶损失函数的方法保留节点的局部网络结构和全局网络结构.
但上述经典的网络表示学习方法对节点间相似性的度量多是基于同质性. 两个节点连接越紧密, 在嵌入空间中距离越近, 而网络中相距较远的节点会被嵌入到较远的位置, 即使它们具有相似的网络结构, 扮演相似的角色. 显然这种节点相似性的概念对于社区发现相关任务是理想的, 但却无法发现节点间的结构相关性. 网络中具有相似功能角色的节点, 它们的邻域网络结构有一定相似性[5], 但却不一定是网络邻近. 因此, 典型的网络表示学习方法并不适用于节点角色识别相关任务.
为支撑角色识别任务, 需设计一种能识别网络结构的网络表示学习方法. 基于此, 本文提出一种灵活的基于邻域信息的网络结构表示学习模型(structural network embedding via neighborhood, SEN). 该模型分为结构识别和网络嵌入两部分: 在结构识别部分, 使用节点邻域信息标识节点网络结构, 建模不同邻域范围内的节点间结构相似度; 在网络嵌入部分, 使用降噪自编码器模型完成数据降维过程, 降噪自编码器能提出数据中的非线性特征得到有效的数据表示, 并且通过在样本输入过程中加入噪声的方式提高模型的鲁棒性. 此外, 网络嵌入过程中还使用了结构相似度作为监督信息, 以指导网络表示的生成, 使结构相似的节点得到相似的表示向量. 实验结果表明, 该方法能较好地识别节点间的结构相关性.
1 算法设计
1.1 相关定义
定义1(网络(图)) 给定一个网络G=(V,E), 其中:V={v1,v2,…,vn},n=|V|表示网络中节点的集合;E表示网络中边的集合,eij=(vi,vj)∈E表示节点vi与节点vj之间存在边.
定义2(网络表示学习(网络嵌入)) 网络表示学习旨在将高维稀疏的网络G从原始空间映射到低维稠密的嵌入空间, 即将网络中的节点表示为低维向量:
f:vi→zi,zi∈d,i∈[1,n],d≪n,
(1)
其中zi为节点vi的表示向量,zi的维度d远小于维度n.
定义3(k阶邻居Rk(u)) 距离节点u最短距离为k的节点集合,R0(u)为节点u本身.
定义4(k阶邻域) 与中心节点最短距离小于等于k的所有邻居节点构成的子网络.
1.2 算法描述
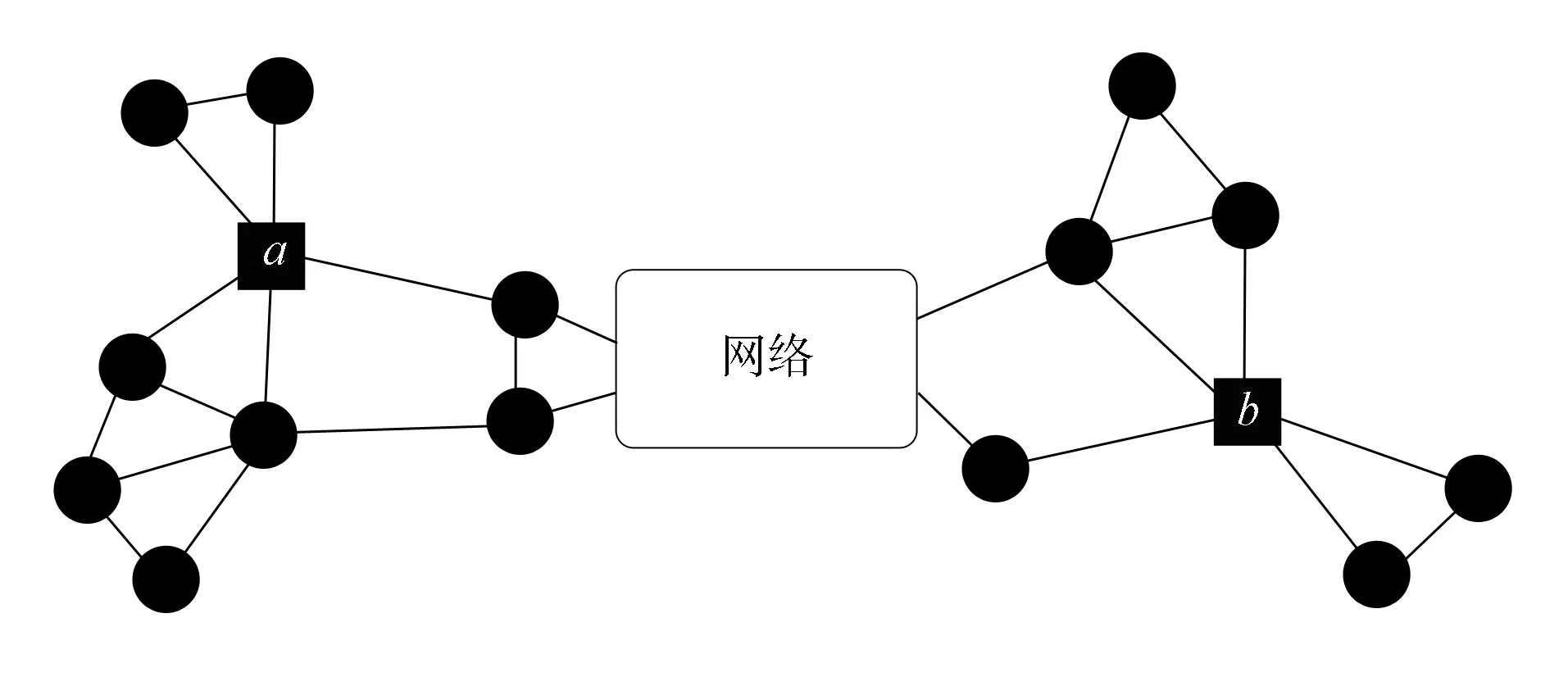
图1 结构相似节点示例Fig.1 Examples of nodes with similar structures
经典网络表示学习方法, 如node2vec和LINE等仅基于同质性发掘节点间的相似性, 无法捕获网络中距离较远或无链路节点间的结构相关性. 图1为结构相似节点示例. 由图1可见, 节点a和b具有相似的网络结构, 但由于没有直接连边, 有限的链路无法发现彼此, 所以无法捕捉到它们之间的结构相关性.因此, 为识别距离较远且具有相似网络结构的节点, 一个合格的网络结构表示方法需符合两个条件: 1) 低维, 嵌入空间的维度应远小于|V|; 2) 保留结构相关性, 网络嵌入过程中应保留原有的结构相关性, 网络结构相似的节点在嵌入空间距离相近, 而网络结构不同的节点在嵌入空间距离较远.
基于上述特征, 本文提出一种灵活的基于邻域信息的网络结构表示学习模型SEN.对于给定网络G, 为每个节点学习潜在的结构表示, 使网络结构相似节点得到相似的表示向量.模型框架如图2所示.SEN非常灵活, 不要求任何特定的网络嵌入模型, 只需引入结构相似度作为权重或监督信息, 典型的网络嵌入方法均可替换到本文模型中.

图2 SEN模型框架Fig.2 Model framework of SEN
1.3 结构识别
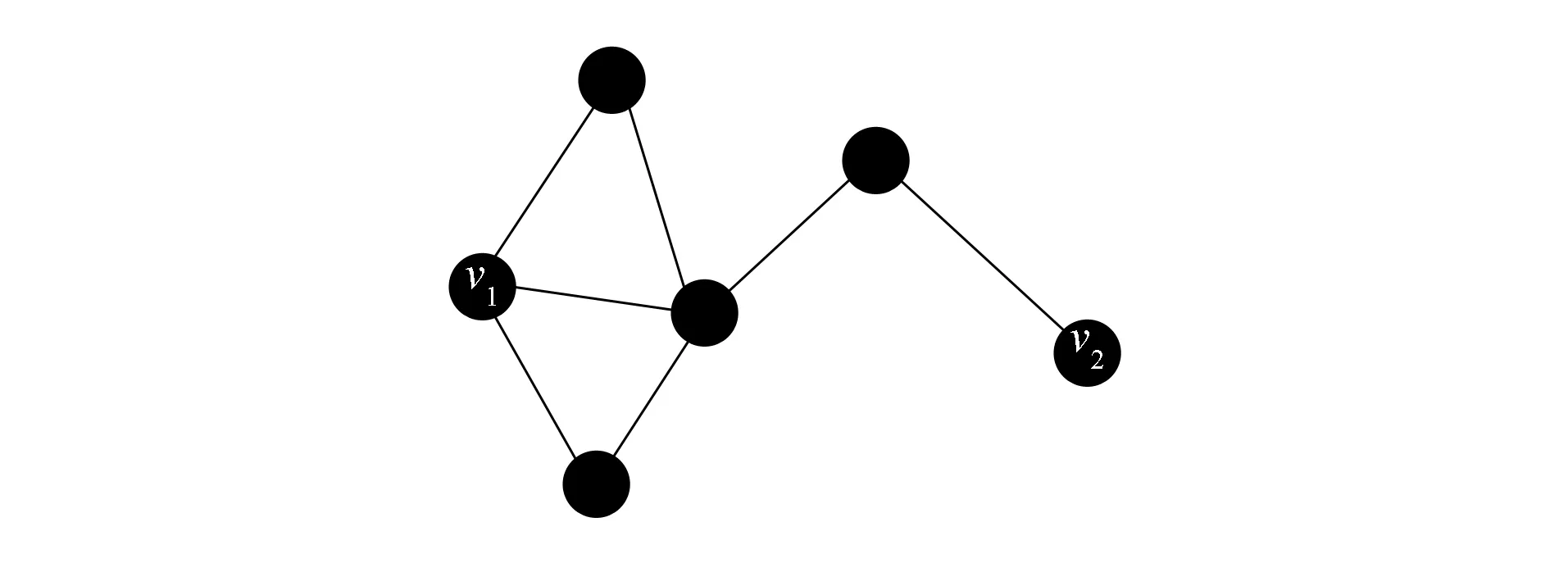
图3 3阶邻域同构节点示例Fig.3 Example of third-order neighborhood isomorphic nodes
SEN模型旨在挖掘网络中节点的结构相关性, 为网络结构相似节点学习到相似的网络表示. 首先标识节点的邻域网络结构, 并计算结构相似度. 基于节点邻域度分布相似, 则节点网络结构相似的假设[4], SEN使用节点邻域度分布标识节点网络结构. 在计算节点间结构相关性时, 最简单的方法是只考虑节点的一个子图间的相关性, 但这种方法可能会导致结构不同的节点得到完全相同的网络结构表示. 图3为3阶邻域同构节点示例. 由图3可见, 节点v1,v2的1阶邻域和2阶邻域有较大差别, 但其3阶邻域完全重叠, 因此仅使用3阶邻域会使它们得到相同的表示.
为避免此类问题, 更好地度量节点之间的结构相关性, SEN对0~K阶不同邻域分别建模结构相关性.以节点u,v的k阶结构相似度Sk(u,v)为例, 使用节点u,v的k阶邻域度分布的差异Dk(u,v)度量它们之间的结构相似度, 邻域度分布差异越大, 则其结构相似度越小.Dk(u,v)定义为

(2)
其中:f(Rk(u))={a1,a2,…,amax-degree}为节点u的k阶邻居度分布;ai表示节点u的k阶邻居中有ai个节点的度为i;d(A,B)为计算邻域度分布差异的距离函数, 定义为

(3)
因此, 节点u,v的k阶结构相似度为
Sk(u,v)=e-Dk(u,v).
(4)
递归计算上述过程, 得到邻域范围由0到K的网络结构相似度{S0,S1,…,SK}. 通过计算不同邻域范围内的结构相似度, 使节点间结构相似性的度量更准确, 有利于后续表示学习过程中更好地保存网络的结构信息.
1.4 基于深度学习的网络嵌入
SEN采用降噪自编码器完成网络嵌入部分. 自编码器是一种压缩数据的神经网络, 能学习到数据中的非线性特征, 并为每个样本学习到低维有效的表示[10]. 降噪自编码器在样本输入时加入噪声, 提高了模型的鲁棒性. 使用结构识别过程所得到的结构相似度信息作为监督信息指导网络表示的生成, 使邻域网络结构相似的节点得到相似的表示向量.
自编码器包含编码器和解码器两部分.
1) 编码器: 将输入数据映射到表示空间, 完成数据的编码过程. 对给定数据xi, 每个编码层的表示yi为

(5)
其中σ(·)为激活函数,W(m)和b(m)分别为第m层编码层的权重和偏置.
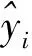

(6)


(7)


(8)
为更好地学习网络中节点的结构表示, 对邻域范围0~K分别建模学习节点的k阶结构表示Yk, 最后将(K+1)个结构表示连接得到网络表示Y.因此, 模型SEN的损失函数为

(9)
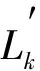
SEN算法流程如下.
输入: 网络G=(V,E), 探索邻域范围K, 表示向量维度d;
输出: 网络表示Y;
fori=0,1,2,…,Kdo
计算网络中所有节点的i阶邻域度分布
计算结构相似度矩阵Si
End for
fori=0,1,2,…,Kdo
构建自编码器, 用Si作为监督信息对网络进行降维得到i阶表示Yi
End for
将Y0,Y1,…,YK拼接得到网络表示Y
ReturnY.
2 实 验
下面使用多个数据集在不同场景中评估模型SEN在识别网络结构方面的有效性.
2.1 数据集
共使用5个网络数据集, 包括1个合成数据集[4]和4个真实网络数据集.其中真实网络数据集信息如下:
1) Chinese expressways(China)[13]. 该网络为中国高速公路网络, 由248个城市及其之间的675条高速公路组成, 按城市等级分为两类, 一类是直辖市、 特别行政区、 省会城市, 另一类为其他城市;
2) Brazilian air-traffic(Brazil)[4]. 该网络为巴西航空网络, 由131个机场及其之间的1 038条商业航线组成, 按机场内飞机起飞和降落次数划分为4个等级.
3) European air-traffic(Europe)[4]. 该网络为欧洲航空网络, 由399个机场及其之间的5 995条航线组成, 按机场内飞机起飞和降落次数划分为4个等级.
4) American air-traffic(USA)[4]. 该网络为美国航空网络, 由1 190个机场及其之间的13 599条商业航线组成, 按机场内人流量划分为4个等级.
2.2 对比算法
使用以下网络表示学习方法作为对照算法:
1) node2vec为典型的网络嵌入方法, 采用有偏随机游走和自然语言处理模型学习节点表示. 在随机游走中定义参数, 使随机游走在广度优先搜索和深度优先搜索中达到平衡, 能更灵活地探索邻域.
2) SDNE为基于深度学习的网络表示学习方法, 采用自编码器学习节点表示, 同时捕获节点的局部和全局网络结构.
3) struc2vec为基于结构识别的网络表示学习, 其根据结构相关性构建多层网络, 采用有偏随机游走和自然语言处理模型学习节点表示.
2.3 同构节点识别
Karate Club空手道社交网络[14]: 包含34个节点和78条边, 每个节点代表俱乐部的一个成员, 边表示相应两个成员是朋友关系. 为验证模型SEN对网络中结构等价性和结构相关性的识别能力, 使用Karate Club构造一个镜像网络, 如图4(A)所示. 由图4(A)可见, 该网络由两个拷贝的Karate Club网络G1,G2组成, 网络G1中的任意节点都有一个网络G2中的镜像节点与之对应, 并增加一条边连接网络G1,G2. 使用镜像Karate Club网络验证模型对同构节点以及结构相关性的识别能力, 期待SEN在学习节点的表示向量时能捕捉网络中节点的结构相关性, 使结构相似节点得到相似的表示向量, 结构上等价的节点得到相同的表示向量.
图4(B)~(E)为不同算法在镜像Karate Club上的可视化效果. 其中node2vec和SDNE很好地学习到了网络中节点的社区属性, 但却未学习到网络中镜像节点对之间的结构相关性. struc2vec虽然捕获到网络中的结构相关性, 但由于随机游走的采样特性等限制, 结构信息仍有一定的信息丢失, 镜像节点对完全同构却未得到相同的表示向量, 无法准确识别网络中的结构等价性; 而SEN不仅能准确识别网络中的同构节点, 使完全同构的镜像节点对得到完全相同的表示向量, 还能很好地学习网络中的结构相关性, 将具有较强结构相关性的节点映射到同一簇.

图4 镜像Karate Club网络及不同算法在该镜像网络上的可视化效果Fig.4 Mirror Karate Club network and visualization effect of different algorithms on mirror network

图5 镜像节点对及所有节点对之间的距离分布Fig.5 Distance distributions between mirrored node pairs and all node pairs
为更直观地感受各算法对同构性的识别能力, 计算每种算法在嵌入空间内镜像节点对之间以及所有节点对之间的距离分布, 图5展示了各算法学习表示向量的两种距离分布, 其中横轴为欧氏距离d, 纵轴为距离大于d的节点对占比P. 由图5可见: node2vec和SDNE的两种距离分布基本相同; struc2vec中两种距离分布有明显差异, 但仍有10%的镜像节点对之间距离大于1; 而SEN的两种距离分布有明显差异, 且镜像节点对之间的距离均为0, SEN能准确识别网络中的同构节点. 因此, SEN能较好地学习到网络中的结构相关性, 并且能准确识别网络中的同构节点.
2.4 分 类
为验证SEN的角色识别能力, 本文选取规模较大的数据集China,USA和Europe进行节点分类实验. 这些网络的标签与节点角色相关, 因此该实验的分类效果能反映网络表示学习方法的角色识别能力. 对每个数据集分别使用node2vec,SDNE,struc2vec,SEN学习表示向量, 上述方法均使用默认参数, 表示向量维度为128. 随机地将数据集划分为训练集和测试集, 训练集比例R=10%~90%, 当训练集比例为10%时, 测试集比例为90%, 以此类推. 使用XGBoost分类器对数据进行分类, 并通过Bayes优化对分类器进行参数优化. 由于这3个数据集的标签不是完全平衡的, 因此使用macro-F1分数作为性能度量, 每个分类实验重复10次得到平均分数, 以减少分类器引入的噪声.
表1~表3分别为不同算法在各数据集上的分类性能. 由表1~表3可见, SEN能识别网络中节点的角色信息, 且均优于其他对比算法. SEN相对于node2vec,SDNE,struc2vec, 在数据集China上分别平均提高了11.8%,8.4%,5.3%; 在数据集USA上分别平均提高了13.2%,5.7%,3.3%; 在数据集Europe上分别平均提高了50.6%,10.6%,4.9%.

表1 不同算法在China数据集上的分类效果

表2 不同算法在USA数据集上的分类效果

表3 不同算法在Europe数据集上的分类效果
从node2vec在3个数据集上表现可见, 仅考虑网络中节点的共现关系无法识别网络中节点的结构角色. 而结构表示学习方法struc2vec,SEN在3个数据集中均取得了较好的效果. 由此可见节点的邻域网络结构与节点角色有一定的相关性, 学习节点的结构表示有利于网络角色识别任务. 而典型的网络表示学习方法无法识别网络中节点的结构特征, 不适用于角色识别任务. 此外, 随着训练集比例的提高, SEN较其他算法的分类效果增益也随之提高. 在训练集比例较小时, SEN的性能仍优于其他方法, 表明了本文方法SEN具有较好的鲁棒性.
2.5 跨网络分类
为验证SEN在迁移学习中的潜力, 本文进行了跨网络角色分类实验. 实验设定为: 对给定的两个网络Ga,Gb, 构造一个合并网络Gab, 对于合并网络分别使用node2vec,SDNE,struc2vec,SEN学习表示向量. 将Ga中的节点表示向量和标签作为训练集训练分类器, 预测Gb中所有节点的标签. 使用数据集Brazil,Europe,USA网络根据网络规模相近原则创建4个合并网络数据集:GUSA-Europe,GEurope-USA,GEurope-Brazil,GBrazil-Europe, 它们仅包含原始两个子网络的节点和边, 并采用原标签数据作为分类依据. 例如, 网络GUSA-Europe由数据集Europe和USA的节点和边的并集组成. 遵循与2.4节相同的实验步骤, 使用macro-F1分数作为性能度量, 每个分类重复10次求得平均值. 跨网络分类实验结果列于表4. 由表4可见, SEN在这4个数据集中均优于其他方法. SEN相比于SDNE和struc2vec, 在数据集Europe-USA中分别提高了15.1%,13.4%; 在数据集Europe-Brazil上分别提高了14.6%,29.2%; 在数据集Brazil-Europe上分别提高了6.7%,27.7%. 此外, 从node2vec的分类性能可见, 典型的网络表示学习方法无法进行跨网络知识传输, 而考虑全局结构信息的SDNE,struc2vec,SEN均表现出更好的性能, 体现了结构识别在迁移学习中的潜力.

表4 跨网络分类实验结果
综上所述, 针对典型网络表示学习方法无法识别节点间结构相关性的不足, 本文提出了一种基于邻域信息的网络结构表示学习模型SEN, 将结构识别引入到网络表示学习过程中, 为节点学习结构表示. SEN使用节点的邻域度分布标识节点网络结构, 对不同邻域范围的结构相关性建模, 应用深度学习方法建模, 并使用结构相似度作为模型的监督信息, 使结构相似的节点得到相似的表示向量. 在多个场景下进行验证的实验结果表明, SEN能识别节点的网络结构, 学习节点间的结构相关性, 为结构相似的节点得到相似的表示, 所得到的网络表示可用于角色识别和跨网络知识传输.
