基于Face++的人脸识别技术在智慧图书馆中的功能设计与实现*
——以中国药科大学图书馆为例
2022-05-14叶荣荣
叶荣荣 袁 泉 曹 雷
(中国药科大学图书与信息中心 南京 211198)
1 引言
新一轮科技革命方兴未艾,孕育了一批新兴技术,如人工智能等,新的科技革命正在重塑全球经济结构,为人类社会发展带来了新机遇[1]。其中,人脸识别技术作为最具有代表性的一种新兴的生物特征识别技术,已被广泛应用于银行、车站、道路监控等社会领域。
2 相关研究背景
2.1 人脸识别技术的发展
1889年,Nature发表一篇名为Personal identification and description的文章。自那时起,人类就开始了计算机用于人脸识别的探索[2]。
二十世纪九十年代,人脸识别技术蓬勃发展,各种算法(如“Eigenface”算法、“Fisher”算法和“FERET”算法)雨后春笋般涌现。这一阶段的人脸识别研究成果为下一阶段的应用提供了宝贵的理论和经验指导[3]。
进入新世纪,人脸识别技术井喷式发展。从基于简单算法的识别发展到深度的学习,非常多的经典算法(如“Guassian Face”算法、“Eaen Electron”算法)被提出。这一阶段的人脸识别商用案例大规模落地,如:2017年北京西站开通人脸识别验票系统,开启了我国铁路检票新时代。
2.2 智慧图书馆的兴起
随着人类生活与科学技术的结合越来越紧密,“智慧楼宇通行”、“智慧物流”等众多新的研究领域不断涌现,“智慧图书馆”也应运而生。
从Markus Aittloa于2003年发表的Smart Library-Location Aware Mobile Library Service一文中首次提出“智慧图书馆”的概念始,时至今日,“智慧图书馆”的概念与定义仍然是百花争鸣,不尽相同。
刘炜等人指出智慧图书馆一是能够提供大量的“无人”或“自助”服务,二是能够通过对用户需求的自动感知提供精准、高质量的服务[4]。袁红军指出图书馆智慧服务就是革新图书馆传统服务思想、内容、方式,形成一系列新方法、新思维,重塑图书馆智慧服务体系[5]。
智慧图书馆的定义相当宽泛且很难用精细的语言去表述辨析,这也不是本文的研究重点。如果仅从技术和读者服务的角度分析,智慧图书馆无非是通过人与物的互联互通,为读者提供最方便和最舒适的服务。
2.3 人脸识别与智慧图书馆的结合
2017年,国内众多省市图书馆开始将人脸识别技术应用于刷脸借书,代表有:厦门市图书馆、绍兴市图书馆、苏州工业园区图书馆[6]。而且,人脸识别技术不仅仅应用于借书服务,还应用于馆藏书目管理。南京大学图书馆智慧盘点机器人、浙江理工大学图书馆人脸识别图书查询机、上海交通大学图书馆人脸识别服务注册终端纷纷上[7]。
此外,南京大学、中国农业大学、武汉大学等多家图书馆已经部署将计算机视觉、RFID感知和智能机器人技术相结合的“图客”系统,实现图书盘点时速超过20 000册/小时,漏读率低于1%,并达到厘米级图书定位。
借助在身份核验方面体现的优势,人脸识别技术在图书馆的应用场景可以延伸到通行、文印、存包、座位预约和入馆信息推送等智慧服务,为图书馆创造更加互联高效、便利与个性化的智能服务环境。
3 基于人脸的智慧图书馆功能设计
智慧图书馆服务系统主要有三部分组成:操作端、交互端和识别端。操作端是与读者交互的连接于局域网的硬件设备,如借还书机、存包柜等;交互端主要包含摄像头、门禁、电子屏幕等;识别端则是后台服务器。图1是整个系统的结构图。

图1 基于人脸的智慧图书馆结构图
交互端的核心设备是摄像头。我们需要通过第三方服务商提供的SDK,将视频的每一帧图像数据进行人脸检测以及人脸特征信息提取,同时将信息通过HTTP协议传输给后台服务器[8]。
前端摄像头与后端不同设备的连接,例如门禁、借还书机等,形成读者与资源、读者与馆员、资源与馆员的互联互通、智能交互。摄像头采集人脸信息,通过调用人脸识别API接口,实现读者身份识别。这种将读者图像与图书馆数据库中存储的读者图像进行对比判断,实现读者身份识别与证件绑定的方式可广泛应用于图书馆智慧服务系统[9]。
由于篇幅有限,我们选择通行门禁进行重点介绍,其余功能只是不同硬件在不同场景下的不同应用,工作原理一样。
我们的人脸识别方案采用F-M4面板机来实现,该面板机具有体积小、轻前端、便于移动安装等众多优点。基于深度学习的人脸识别计算设立在服务器端,避免导致卡顿、识别过慢等问题,从而在实际应用场合中具有可操作性与准确性,这也是本文的研究意义所在。
3.1 整体设计
本文以CNKI、Web of science数据库为检索源(检索日期为2020年6月10日),在“信息科技”领域进行检索,以“人脸识别系统”为主题,得到期刊数据1 197条;以“人脸识别方法综述”为主题得到期刊数据249条。在剔除不相关文献后,结合具体内容分析发现,一个完整的人脸识别系统通常包含有如下几个模块:人脸图像采集、人脸检测识别、人脸特征对比以及结果输出。图2给出了人脸识别技术的一般设计思路。
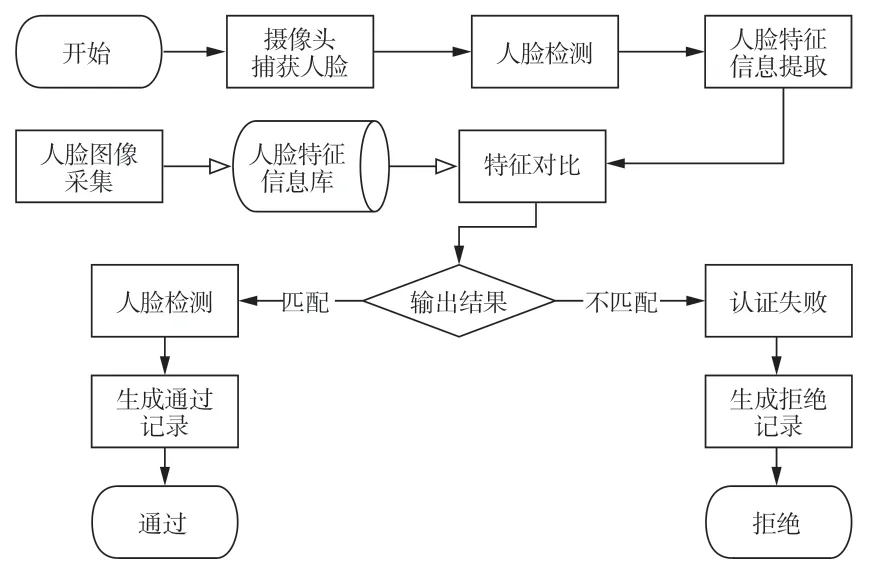
图2 人脸识别技术的一般设计思路
(1)人脸图像采集
人脸图像采集在人脸识别系统中属于前期准备工作,也是最重要的工作。采集的人脸图像质量直接影响人脸识别的准确率和识别速度,我们推荐参照中华人民共和国第二代居民身份证数字相片技术标准(GA461-2004)。标准要求采集的人脸图像为近期正面免冠照,纯色背景,人脸层次丰富,神态自然,无明显畸变和图像处理痕迹,照片规格为358像素(宽)*441像素(高),分辨率350dpi,24位RGB真彩色颜色模式。
(2)人脸检测识别
如何从待识别的视频监控图像上获取有效人脸信息是人脸识别算法的核心研究内容之一,不仅需要在复杂环境、多变光照、故意遮挡和多姿态人脸中准确捕获人脸坐标位置,而且需要判断成像质量、人脸数量等有价值的面部信息。
关于人脸关键点定位,海内外学者对此做了大量研究工作。香港中文大学汤晓欧等人[10-11]提出了基于TCDCN的人脸特征点检测算法,该算法将面部属性(如:是否戴眼镜、是否微笑)结合到人脸关键点检测任务上,显著提高了关键点检测的效率;英国剑桥大学Paul Viola和Michael Jones等人[12-15]提出一种基于积分图、级联检测器和AdaBoost学习算法的人脸检测方法,该方法大幅度提高了人脸识别速度。此外,还有SphereFace算法、DeepID算法以及DeepFace算法等[16-20],这些不同算法的检测方法框架大体是相同的,只是通过构造不同网络结构和损失函数,达到较好的人脸识别效果。
本研究选取基于Face++的目标检测算法对人脸位置、关键点和特征值进行计算提取,各算法的原理对比、计算差异及其优劣性不在本研究之中。
(3)人脸特征对比
人脸特征对比就是判断待识别人脸为人脸库中的哪一个人[21],大多为1:N比对,为此需要事先在人脸数据库中存储若干人脸特征值。一般而言,不同对比方法的主要创新点就在于怎样提取代表性的特征[22]。
(4)识别结果输出
检测到的人脸特征与人脸数据库中的人脸特征进行比对,得到相似度最高的值,再将该值与相似度阈值进行比较,若大于设定的阈值,则返回成功,反之则返回失败。
人脸识别系统的整个工作流程为管理员预先将人脸和身份信息存储到数据库,当前端摄像头抓拍到人脸照片时,将其信息发送给后端服务器,服务器负责人脸特征值对比,并将对比结果返回给前端设备。前端设备若是门禁,则给控制电磁锁单元门下发“打开”或者“闭合”的信号。
3.2 算法设计
本系统开发采用Java语言。Java语言的优势是可移植性,面对不同的软硬件平台和操作系统是无需修改的,即可运行。算法分三个部分:与Face++API的接口对接、数据库设计和标识码对比。
(1)接口对接
首先将摄像头抓拍到的人脸照片通过Base64算法进行编码,再通过post方法把http请求发送给服务器,在获得Face++API函数的使用权限后,对抓拍的图片进行处理,得到JSON格式标识码[23]。
(2)数据库设计
系统采用MySQL数据库建立人脸特征数据库。首先将收集的图像上传到Face++服务器,以JSON数据格式生成的唯一标识码并保存在数据库中。
在数据库中建立一个读者信息表,并以学号为主键,用于存放学生的姓名、专业、院系、权限等信息,表格之间通过主键进行映射。在数据库交互方面,采用封装函数的方法,每个表都是一个数据表类的子表,以操作数据库连接及数据增删改查。
(3)标识码对比
该模块主要实现的功能是在得到的JSON码中提取所需关键信息,即唯一标识码(facetoken)、人脸属性、系统耗时和错误代码等。将唯一标识码与人脸信息数据库中的标识码进行一一对比,若存在相似度最高的则可返回匹配成功,否则匹配失败。
3.3 关键代码
计算机识别人脸,首先要定位人脸在照片或视频画面中的位置,这需要依靠Landmark函数。Landmark为在脸上绘制的若干标记点,标记点一般画在边、角、轮廓、交叉等关键位置,借助它们就可以描述人脸的眼睛、眉毛、嘴唇和鼻子轮廓。图3为检测示例,每个圆点为Landmark关键点。

图3 Landmark关键点
Landmark中字段x表示横坐标位置,y表示纵坐标位置。以下是请求成功返回示例:


(1)人脸识别模块
人脸识别的过程封装在Detect API类中。这个接口的功能十分强大,可以获得人脸各类属性信息,如年龄、性别、眼睛状态、情绪等,但在这里我们只需要返回face-token。
人脸识别关键代码如下:
File file=new File("照片路径"); //存放欲识别的照片路径
byte[] buff=getBytesFromFile(file); //将 该照片转化为byte数组
String url="https://api-cn.faceplusplus.com/facepp/v3/detect"; //调用人脸识别api接口
HashMap<String,String>map=new HashMap<>(); //新建一个哈希表,用于存放数据
map.put("return-landmark","1"); //返 回人脸关键点坐标数组
map.put("returnattributes","ATTRIBUTES"); //返回人脸属性特征
(2)人脸对比模块
调用完人脸识别模块后,已经将人脸图像转换为face-Token。如果需要做人脸的分析比对等操作,还必须将对应的face-token添加到FaceSet中。FaceSet可以理解成一个存放所有人脸的容器或集合。
关键代码如下:
String url = "https://api-cn.faceplusplus.com/facepp/v3/faceset/addface"; //调用人脸识别api接口
List<BasicNameValuePair> faceset= new ArrayList<>(); //新建一个数组,用于存放数据
faceset.add(new BasicNameValuePair("apikey", "apikey")); //输入api key
faceset.add(new BasicNameValuePair("apisecret", "apisecret")); //输入api secret
faceset.add(new BasicNameValuePair("outerid", "outid")); //创建faceset标识,用来管理faceset对象
faceset.add(new BasicNameValuePair("facetokens", "e07e0d319e839aef0922a0c8669a4d1a")); //将face-tokens放到faceset中
post(faceset,url); //发送请求
在一个已有的FaceSet中找出与目标人脸最相似的一张或多张人脸,我们称之为人脸搜索或人脸对比。值得注意的是,对同一张图片进行多次人脸检测,同一个人脸得到的face-token是不同的。人脸检测和人脸对比流程如图4所示。

图4 人脸检测和人脸对比流程图
4 系统测试
为了测试本文的方法在实现智慧图书馆通行中的身份认证和人脸识别性能,我们在中国药科大学图书馆2楼进行了真实测试,测试时间是2020年3月-6月。期间共采样师生人脸信息16 465张,同时对采集的人脸照片进行特征信息库构造。智慧通行系统的测试场景如图 5所示。

图5 图书馆人脸识别通行测试场景
4.1 测评指标
在图书馆智慧通行中,人脸识别的身份对比测评指标有四个:通过率、漏识率、误识率和拒绝率。
通过率=正样本通过人数/正样本总数;
漏识率=正样本未通过人数/正样本总数;
误识率=负样本通过人数/负样本总数;
拒绝率=负样本未通过人数/负样本总数。
通过率+误识率=100%;误识率+拒绝率=100%。正负样本及身份测评指标如图 6所示。

图6 正负样本及身份测评指标
通过率是衡量人脸特征库中的正样本通过的比例,可直观理解为顺利通过人脸识别系统的概率。误识率是不在人脸特征库中的负样本通过的比例,可直观理解为非本单位人员通过人脸识别系统的概率。通过率越高越好,代表人脸识别系统的可实用性,误识率越低越好,如果高了就代表存在一定的安全隐患。
不过识别率不等于通过率。还是以智慧通行为例,1张人脸去特征库中比对N个数据,无论如何都得到N个分数,其中有一个最高分。我们要确认的是该最高分是不是“足够高”,足够高就视为准入,不够高就不准入,这个“足够高”的值称之为“阈值”。阈值是用于判断对一个人脸识别比对的结果是否放行。
图 7中○代表正样本的识别分布,△表示负样本的识别分布,虚线表示阈值,阈值以上的表示通过,阈值以下的表示不通过。

图7 身份对比中的阈值设置
阈值为0,所有正负样本都通过,正样本均通过率100%。也就是说,不管任何人都能通过,但是负样本误识率也是100%;阈值向上浮动,开始吞噬负样本。阈值上移的过程就是不在特征库中的人陆续被拒绝通过的过程,当上移到一定的高度就开始吞噬正样本,如果到达100阈值,那么所有人都视为拒绝通过。因此,阈值的设定是关键。我们的目标是让尽可能多的○停在阈值之上,同时让尽可能多的△停在阈值以下。FacePass SDK建议在80左右。
4.2 识别速度
人脸识别闸机通行系统的识别时间测试分为四个部分:人脸检测时间、人脸抓拍时间、人脸特征提取时间和数据库检索对比时间。系统前端采用F-M4面板机,配有300万高清摄像头。要想抓拍到清晰有效的人脸图像,摄像头频率设置不宜过高,本系统设置为15帧/S,图像获取时间为60ms左右。系统使用的人脸数据库图片为800*600像素。
在进行人脸检测时,设置“最小人脸”数值≥100,“光照标准”数值≥80,“清晰度”数值≥0.2,检测时只检测该范围之内的人脸图像,其他较小、阴阳脸、模糊等人脸图像忽略不计。我们排除恶劣光照条件和天气影响,通过大量统计,得到人脸检测平均所需时间为141ms。本测试历时4个月,抓拍人脸照片总计8 330张,得到有效正确人脸图像共计8 188张,采集的图像如图 8所示,人脸检测率为98.3%。
图8 图书馆测试采集到的人脸图像
人脸特征提取平均预处理时间为120ms。人脸特征对比及检索时间与训练正样本数、数据库索引条数有关系。训练正样本个数越多,识别时间越短;索引条数越多,识别时间越长。以测试的正样本数2 386为例,平均一张图片的比对时间是0.6ms。
4.3 识别结果
在统计人脸识别智慧通行系统的通过率、漏识率、误识率和拒绝率时,我们采用观察法。控制正负样本的参数,观察这四个参数。具体方法为:选中采集的人脸图片先放在正样本中,重复试验,调整阈值参数,统计通过率和漏识率;再将这张图片中的人放在负样本中,重复试验,调整阈值参数,统计误识率和拒绝率。测得结果如表1所示。

表1 阈值设置与通行测试结果
从表中可以看出,不管是正样本还是负样本,阈值越低,人员越容易通过;阈值越高,人员越不容易通过;对应的,阈值越低,通过率越高,误识率越高;阈值越高,通过率越低、误识率也越低,两者一个正样本一个负样本,同升同降。
由于实测环境下通过摄像头采集的照片在复杂光照、行走姿态、有遮挡等情况下照片质量变差,造成实际测试通过率有所下降,但是从实测效果看该方案基本满足需求具有一定实用性。
5 结语
人脸识别技术经过十来年的发展,在公共安全、电子商务等领域取得了巨大的应用价值。尤其是在应对突然爆发的新冠肺炎疫情防控期间,在隔离人员管理、流动人口要素管控、隐患排查、服务群众等各个方面发挥了更精细化、高效化的作用。
然而智能服务并不等同于智慧服务,以人脸识别系统构成的自助借还、文印存包、座位预约等自动化系统仍属于智慧图书馆的初级阶段,与人工智能密切相关的图书馆智慧服务尚需长期实践探索。
