异构集群中密集型大数据负载网络调度仿真
2022-05-14吴誉兰舒建文
吴誉兰,舒建文
(1. 南昌航空大学科技学院,江西 南昌 332020;2. 南昌航空大学信息工程学院江西,南昌,330063)
1 引言
现今网络数据呈现出爆炸式增长,Hadoop系统在处理不断增加的密集大数据时,会赋予集群一批新的节点,导致新加入的网络节点在硬盘、内存以及处理器等性能方面形成了过大的差异性,由此生成异构集群,造成各节点数据量的不平衡。所以,异构集群的密集数据调度均衡具有重要的现实意义[1]。有相关学者对此进行研究,窦浩铭等[2]提出基于SDN的负载均衡网络控制器算法,根据网络范式与控制器,度量链路与服务器层面的影响因子,通过权重的计算,达成最终的调度。而余洋等[3]提出基于分布式计算的密集型多路网络流均衡调度方法,得出多路网络流负载调度方法,采用界定跳数信息与负载信息,得到网络流选取的决策函数,依据负载状态来调度过载链路的数据流。
由于在处理异构集群的密集型大数据时,容易因不同节点硬件配置差异过大,导致负载调度时间长,调度效果不理想。因此,提出一种异构集群中密集型大数据负载网络调度方法。依据异构集群中两节点之间的性能、储存空间关系;通过负载网络调度使两节点获取到相同的储存空间使用率,明确调度模型的储存空间、已用容量以及各项性能指标参数,提取使用率超过极大负载的节点,进一步缩短调度时间。根据异构集群节点在任务处理阶段消耗的总能量,采用节点间可调度的有效数据块,实现密集型大数据负载网络调度。
2 大数据负载网络调度模型与参数设置
2.1 负载网络调度原理与局限性
通常情况下,完成负载网络调度的前提条件是假设所有节点具有相同结构。基于同构集群的每个节点,其处理器、内存以及磁盘容量等硬件配置相一致[4]。而负载网络调度的效用则是令所有节点的储存空间使用率更加均衡。如果集群内少数的节点信息负载了较大规模的数据,那么,集群管理员应采用调度控制策略,对数据块进行重新安排与布局。针对用户提交的阈值与储存空间使用率,节点信息被负载调度应用划分成过载节点信息、比阈值大的节点信息、比阈值小的节点信息以及空载的节点信息等四个模块。负载网络调度的核心思想就是将比阈值大的节点与过载节点数据移动至比阈值小的节点和空载节点处,令所有节点的储存空间使用率与集群储存空间的平均使用率有所偏离,且满足阈值的取值范围。
尽管负载网络调度方案对于同构集群可以展示出明显的优势,但对于异构集群[5],会存在一定的可能性导致节点硬件配置出现较大差异,而具有较高性能的节点则能够处理更多相关数据,每个节点为Hadoop分布式文件系统(如图1所示)提供的使用空间大小也不同,甚至会呈倍数差。因此,即使异构集群所有节点的储存空间使用率不一致,无法满足负载网络调度的最终需求。

图1 Hadoop分布式文件系统框架示意图
根据上述负载网络的调度原理及局限,设定一个异构集群,将该集群中节点Na的性能与节点Nb的性能分别设定为Pa、Pb,则两节点性能之间的关系表达式为

(1)
假设节点Na与节点Nb的储存空间分别是Da和Db,那么,采用式(2)对两节点的储存空间关系进行描述
Da=2Db
(2)
根据式(1)、(2)得出,具有低性能的节点Na储存空间利用率为节点Nb的两倍,经过负载网络调度,两节点将获取到相同的储存空间使用率。虽然两个异构节点的储存空间使用率看起来像是呈现出比较均衡的状态[6],但实际的集群却是非常不均衡的。低性能的节点Na不仅被赋予了更多的处理数据,同时也承担了更大的数据负载,从而导致该节点逐渐演变为任务执行阶段的高负载节点,使非本地化的任务几率得到了上升,并提高了网络流量负载。因此,为了均衡异构集群的负载,将集群里所有节点的储存空间使用率调度为一个相同的期望值。
2.2 模型参数设定
通过探析负载网络调度原理以及局限性,对适用于异构集群中密集型大数据负载网络调度的数学模型进行构建。根据各节点的性能和储存空间,采用调度模型完成所有节点理论空间使用率的求解。
储存空间指的并不是某个节点的磁盘容量,而是节点为分布式文件系统提供的可用容量[7],其中,第i个节点的配置容量表示为Cconf(i);分布式文件系统使用的节点储存空间容量叫做已用容量,其中,第i个节点的已用容量表示为Cused(i);第i个节点的处理器性能表示为Pcpu(i),多核性能却不能呈现出等效的性能总和,因为理想状态下的各核性能是单核的0.8或0.9倍,因此,通常将多核处理器的转换参数ρ取值为0.8。采用下列公式对节点处理器的性能进行描述
Pcpu(i)=ρ×(Ncore(i)-1)×F(i)+F(i)
(3)
式(3)中,节点的处理器核数与频率分别表示为Ncore(i)、F(i)。
假设第i个节点的内存性能是Pmem(i),则需要通过下列表达式对其进行评估
Pmem(i)=Nmem(i)
(4)
式(4)中,节点i的内存大小表示为Nmem(i)。节点相对性能表达式为
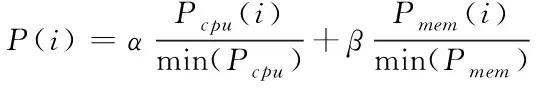
(5)
式(5)中,处理器性能与内存性能的权值因子分别为α、β,而且两者之间的关系满足α+β=1;异构集群里节点处理器性能与内存性能的极小值分别为min(Pcpu)、min(Pmem)。为了使计算更加简便,量化集群内全部节点的性能,取值为极小值1,从而得到节点性能总和P的计算公式为

(6)
式(7)所示为集群储存空间使用率的表达式

(7)
基于性能的理论储存空间,节点i的占用容量表达式及空间使用率表达式分别为
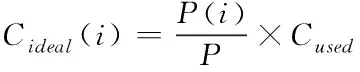
(8)

(9)
式(8)、(9)中,i=1,2,…,n。
节点动态储存空间的极大负载,则采用式(10)进行描述

(10)
式(10)中,极大负载M的取值范围是80%≤M<100%,且与集群储存空间使用率Ravg为正相关[8]。上列表达式对节点极大负载做出了较好的界定,避免节点发生负载过重的情况,也解决了因用户的静态配置而造成的参数不适用问题。
通过对比节点的极大负载与所有节点的理论储存空间使用率,对节点理论空间使用率超过节点极大负载的节点进行提取,进而采用异构集群盈余容量的运算公式,完成求解

(11)
式(11)中,i=1,2,…,n,Rideal(i)>M。
迭代运行为剩余节点分配多余容量这一操作,待异构集群内不再有理论容量比极大负载数值大的节点时,迭代终止。
每个节点的参数化阈值计算公式为
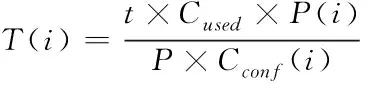
(12)
式(12)中,当均衡状态的集群节点储存空间使用率和异构集群储存空间使用率存在最大偏差时,该数值就是用户输入的阈值参数t。
至此,完成负载网络调度模型的参数设定,对比节点的存储空间使用率,提取负载过大的节点,对剩余节点分配盈余容量。缓解负载过大的情况,提高了存储空间利用率,为密集型大数据负载网络调度做铺垫。
3 密集型大数据负载网络调度算法
假设一个异构集群的构成节点有n个,若使用该异构集群处理Map Reduce任务,将所有处理任务的节点架构成一个集合,并设定为C,所以,得到任务处理阶段内所消耗能量总和的表达式
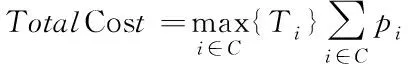
(13)
式(13)中,第i个节点的处理时长表示为Ti,功耗表示为pi。
根据总消耗能量表达式能够发现,如果覆盖节点已经得到明确,那么,负载网络调度为降低覆盖节点任务分配能耗的有效手段之一,两覆盖节点的负载调度示意如图2所示。所以,在实现异构集群中密集型大数据负载网络调度的过程中,需要先解决两个主要问题,即对负载网络调度的对象节点和调度程度进行确定。
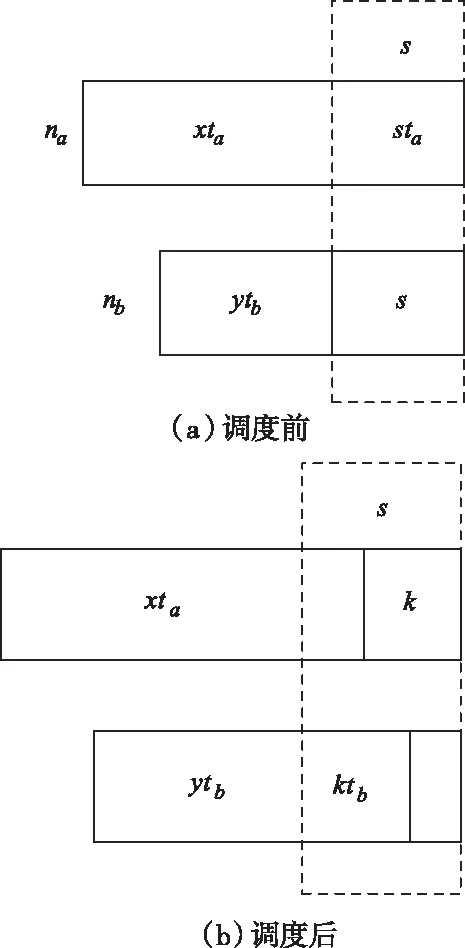
图2 两覆盖节点的负载调度示意图
已知图2(a)中的na与nb分别为两个覆盖节点[9],关键节点是na,如果节点na当前所含有的有效数据块数量为x+s个,且在节点nb上含带副本的数据块数量为s个,那么,节点nb当前所含有的有效数据块数量为y个。图2的虚线方框表示,在节点na与nb上均包含带副本的数据块数量为s个,各节点的有效数据块用阴影区域表示,只在节点中进行储存而不接受处理的数据块则用空白区域表示,节点na与nb处理一个数据块消耗的时长分别为ta与tb。实现节点na与nb的负载网络调度,就是为了满足节点na实际所用时长约等于节点nb。所以,把节点na的部分有效数据块交给节点nb进行处理。
如图2(b)中所示,经过负载网络调度,节点na的有效数据块数量为x+s-k,而节点nb的有效数据块数量为y+k,白框中的k个数据块为原属于节点na但现属于节点nb的有效数据块。节点na与节点nb的可调度数据块就是该k个数据块,其中,k值的选取应满足(x+s-k)ta与(y+k)tb的差值是极小值,通过计算能够得出下列条件式组
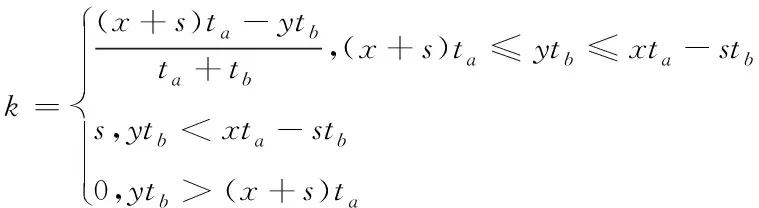
(14)
如果关键节点为节点na,ytb<(x+s)ta,那么,k值一定不是0[10]。由于经过负载网络调度后,节点na与nb的实际消耗时长要比(x+s)ta小,如若不然就没有达成调度的目标。当确定了当前覆盖节点的全部关键节点后,对其与剩余覆盖节点实施负载调度,在下一次的迭代操作过程中,反复调度关键节点,待其无法再与其它节点负载调度,迭代终止,完成密集型大数据负载网络调度。
4 仿真研究
4.1 仿真环境
仿真环境采用的操作系统为Ubuntu-12.04.1,JDK与Hadoop选用的分别是1.6版本与2.5.1版本,运行内存为4GB,硬盘可用空间是500G。模拟环境的网络拓扑结构设置了9台服务器的群集,构建三层网络拓扑。组建节点个数分别是4个、3个和2个。表1中的数据为拓扑节点的硬件配置参数表。
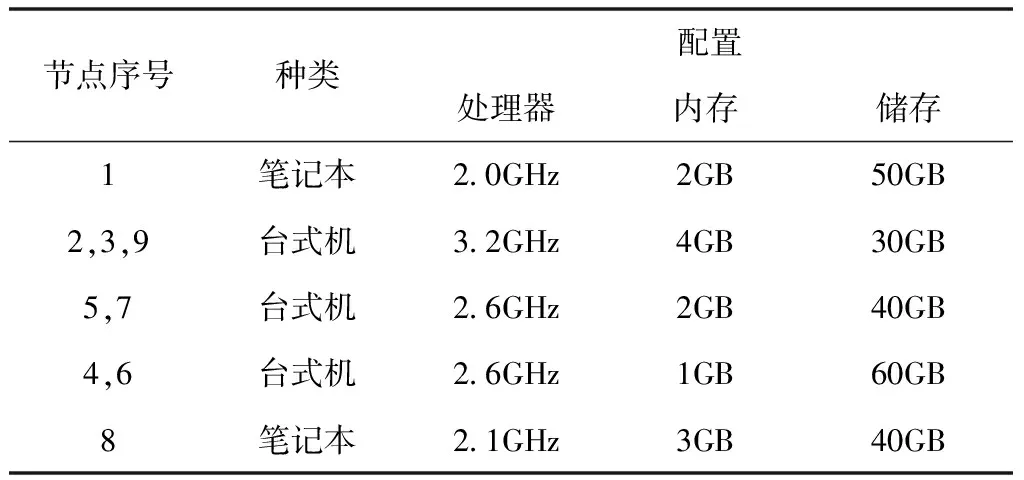
表1 拓扑节点的硬件配置统计表
此次实验数据设置中,以三种工作类型为基准,以观察所提方法对数据调度耗时的影响。表2中列出了实验数据及参数名称,并将数据分别重组为10个数据包。工作量是一种用于计算给定文本中每个单词的出现次数的应用程序。TeraSort是由TeraGen生成的一组给定的输入数据。推荐器是许多现实生活中使用的著名的机器学习应用程序。
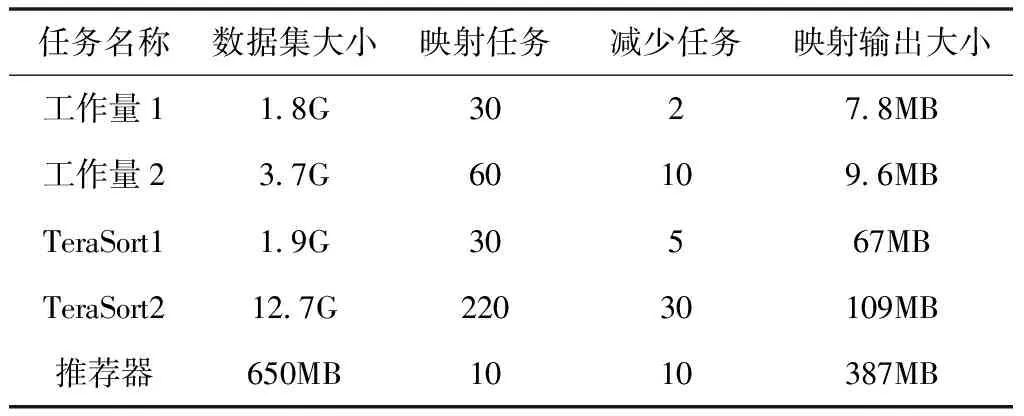
表2 实验数据
4.2 不同任务调度耗时分析
基于相同规模的实验环境及数据,对比基于SDN的负载均衡网络控制器算法(文献[2]方法)、基于分布式计算的密集型多路网络流均衡调度方法(文献[3]方法)与所提方法,处理表1中五种任务的用时,具体实验结果如图3所示。
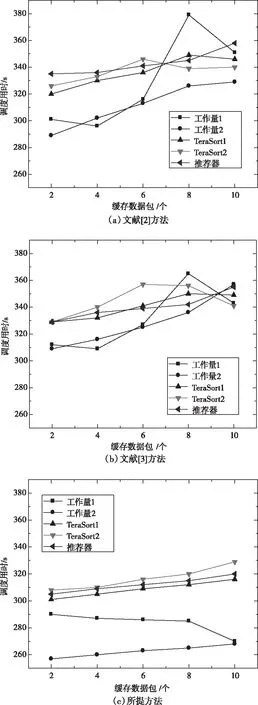
图3 不同方法调度消耗时长对比
通过图3可以看出,因不同的负载任务会提出不同的调度要求,所以处理时长也因负载情况发生变化而出现改变。相对于其它两种对比方法,所提方法的处理时长较短,且变化波动较小,拥有显著的优越性。是因为该方法在设定模型参数时提取了使用率超过节点极大负载的节点,通过迭代运行为剩余节点分配盈余容量,减少了调度耗时,从而提高了资源利用率。
5 结论
为了确保密集型大数据的处理效率,提出一种异构集群中密集型大数据负载网络调度方法。依据节点储存空间使用率相近似的负载调度原理以及硬件配置存在的局限性,将节点信息划分成四种类型。采用Hadoop分布式文件系统下各节点的性能和储存空间,完成负载网络调度数学模型的架构与相关参数指标设置,利用节点处理任务的能耗总和,获取覆盖节点与关键节点数据块的处理时长。根据可调度数据块数量的取值范围,通过关键节点与其它节点的反复迭代调度,达成最终的调度目标。仿真结果证明,在处理五种任务的过程中调度消耗时长低于330s,该方法为今后的相关领域研究奠定了良好的数据基础,拥有着至关重要的实践意义与理论意义。
