利用AdaBoost的SDC错误检测方法
2022-05-09刘阳,庄毅
刘 阳,庄 毅
(南京航空航天大学 计算机科学与技术学院,软件新技术与产业化协同创新中心,南京 211106)
1 引 言
随着芯片制造工艺的进步,元器件的集成度不断提高,使得芯片的性能都得到了极大的提升.但同时,高度的集成化使得芯片对粒子辐射等环境因素的敏感度也提高了.当芯片受到单粒子撞击时,元器件存储区域上的一位或者相邻多位可能会发生翻转,从而导致软错误的发生.软错误主要指程序运行时,由不正确的信号或者数据造成的故障[1,2].静默数据损坏(Silent Data Corruption,SDC)[3]错误是最具有危害性的软错误类型之一.SDC错误具有较高的隐蔽性,通常会导致难以察觉的程序输出错误,在常规检测方法下难以被检测.而在有较高可靠性需求的航空航天领域,要降低程序对空间粒子辐射的敏感度,使得程序能够检测到SDC错误,故需要设计具有针对性的错误检测方法来检测SDC错误.
传统的基于冗余的SDC错误检测方案会导致较大的性能开销,对于性能约束较为严格的嵌入式程序而言,一个高效费比的SDC错误检测方法是尤为重要的.
本文的主要贡献如下:改进了故障模型,将物理空间中的多位翻转映射到单一指令中,使得故障注入模拟更加贴近真实辐射情况.提出了一种利用AdaBoost的SDC错误检测方法SEDA(SDC Error Detection Method based on AdaBoost),通过故障注入获取指令SDC相关特征,训练机器学习模型预测指令SDC脆弱性,最后通过粒度可配置的指令冗余操作加固源程序以达到检测SDC错误的目的.与现有方法相比,本文所提出的利用AdaBoost的SDC错误检测方法具有更低的时空开销和更高的检测率.
2 相关工作
目前针对SDC错误的检测方法主要包括:基于程序断言的SDC检错方法、基于故障注入的SDC检错方法、基于静态分析的SDC检错方法以及基于机器学习的SDC检错方法.
基于程序断言的SDC检错方法通过将断言插入到程序中来检测到数据流错误,包括在数值间隔和数据值之间的关系下程序的数字特征.Siva[4],Hiller[5]等人通过分析程序的功能逻辑,人工提取了变量之间的函数关系等特征来执行断言以检测程序中的错误.Racunas[6],Sahoo[7],Ma[8]等人采用自动提取的方法,通过在程序运行时获取变量的数值,根据数值的分布得出合法区间来执行断言以检测程序中的错误.这些基于程序断言的SDC检错方法的检错代价较低,但同时检错率也相对较低.
基于故障注入的SDC检错方法需要对指令依次进行故障注入,收集SDC相关信息.这类方法具有较高的时间开销,为了降低故障注入的时间开销.Hari 等人通过控制流等价策略来减小故障空间的大小,根据程序控制流上下文环境来预测可能的故障结果,并将预测结果相同的故障筛去,从而降低故障注入的时间开销[9].Xu 等人提出了一种偏向性故障注入框架CriticalFault,通过指令脆弱性分析明确错误高相关故障类型,从而降低故障注入的时间开销[10].这些方法虽然一定程度上降低了故障注入的开销,但如何平衡预测准确度与故障空间大小仍是亟需解决的问题.
基于静态分析的SDC检错方法专注于程序的特征,以分析程序的SDC脆弱性.Pattabiraman 等人提出了一个程序级框架SymPLFIED,该框架使用符号化执行对变量的错误状态进行抽象处理,并通过模型检验技术抽象执行程序,然后对错误传播路径及程序运行结果进行分析,从而对SDC 脆弱指令进行识别[11].这类基于静态分析的SDC检错方法虽然以较低的开销实现了较高的精度,但由于存在状态爆炸的问题,所以难以应用到大规模的程序之中.
基于机器学习的SDC检错方法通过提取目标程序的相关特征来训练机器学习模型[12],从而达到预测SDC脆弱性的目的.Lu等人提出了一种经验模型SDCTune,模型首先提取程序中指令的编译时静态特征,然后通过决策回归树和程序分析方法来预测程序中指令的SDC脆弱性[13].YANG等人提出了一种基于支持向量机的方法PVInsiden.该方法通过机器学习训练检测器,能够识别出SDC脆弱性高的指令[14].基于机器学习的方法通常可较为准确地预测指令的脆弱性,但目前的基于机器学习的SDC预测方法只考虑了寄存器或存储器中的单位翻转[14],没有考虑到多位翻转对指令SDC脆弱性的影响.
综上所述,基于程序断言的SDC检错方法检错率较低,基于故障注入的SDC检错方法开销过大,基于静态分析的SDC检错方法难以应用于大规模程序,基于机器学习的SDC检错方法目前则多局限于单位翻转.
为了解决上述问题,本文在故障模型中引入了多位翻转模型,使得模拟故障更加贴近真实空间辐射环境.并在此基础上提出了一种基于AdaBoost的SDC错误检测方法,该方法采用AdaBoost模型预测指令SDC脆弱性,并选择高脆弱指令进行冗余加固处理,进而达到SDC错误检测的目的.
3 故障模型
嵌入式计算机在极端工作环境中经常暴露在高能粒子的照射下,这些高能粒子会引发单粒子翻转(Single Event Upset,SEU),影响嵌入式计算机的正常运行.单粒子翻转是指高能粒子使元器件的逻辑状态发生翻转的现象[15].单粒子翻转存在着单位翻转和多位翻转两种情况,现有的SDC错误检测方法中,故障模型多侧重于单位翻转,对多位翻转的研究较少.但随着电子器件特征尺寸的持续减小,单粒子引发多位翻转的概率有所增长,多位翻转已成为SDC错误检测中不可忽视的一项因素[16].Chatzidimitriou等人研究表明,在多位故障注入和单位故障注入之间,程序的脆弱性相差了3.2倍[17].本文提出的方法主要通过分析指令的SDC脆弱性,并对脆弱性高的指令进行冗余来检测程序的SDC错误,故将指令多位翻转引入故障模型,本文设计的故障模型Fm可以表示为一个三元组:
Fm=(Utotal,Utype,P)
(1)
其中,Utotal为发生指令单粒子翻转故障的总数量,Utype为指令单粒子翻转类型,P为对应指令单粒子翻转类型发生的概率.
Zhang等人选用IDT7164型号的SRAM进行了辐照实验[18].实验结果显示:在所有的单粒子翻转现象中.单位翻转占据了总量的83.3%、两位翻转占总量的13.8%、三位翻转占总量的2.5%.四位及四位以上因比重过小忽略不计.如图 1所示给出了多位翻转的各种形式及对应的发生概率,P(n,m)是第m种形式的n位翻转发生的概率.
在内存中,指令对应的机器码在物理空间中是按行存储的[19].将内存上单粒子翻转映射到其上存储的指令中,即可得到指令的单粒子翻转情况.内存中的单位翻转、纵向两位翻转、斜向两位翻转和纵向三位翻转映射到单条指令中即为指令单位翻转;内存中的横向两位翻转映射到单条指令中即为指令两位翻转,内存中的横向三位翻转映射到单条指令中即为指令三位翻转,内存中的L型翻转映射到单条指令中为指令单位翻转和指令两位翻转,如图 2所示.
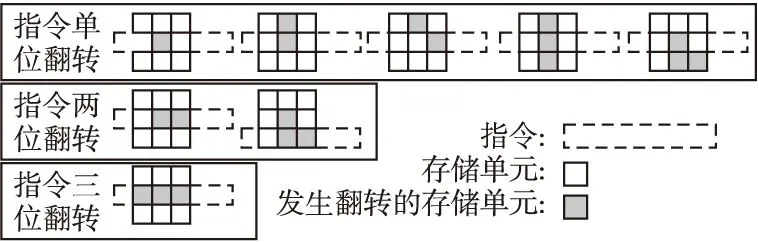
图2 指令单粒子翻转映射图Fig.2 Instruction single particle flip mapping
故障模型Fm中的,Utype表示为向量:
Utype={ISBU,IDBU,ITBU}
(2)
其中,ISBU,IDBU,ITBU分别为指令单位翻转,指令两位翻转和指令三位翻转,对应概率P表示为向量:
P={PISBU,PIDBU,PITBU}
(3)
其中,PISBU为指令单位翻转的概率,PIDBU为指令两位翻转的概率,PITBU为指令三位翻转的概率.
PISBU计算公式如下:
(4)
PIDBU计算公式如下:
(5)
PITBU计算公式如下:
PITBU=P(3,1)
(6)
通过计算可得指令单位翻转概率PISBU=92.315%,指令两位翻转概率PIDBU=7.665%,指令三位翻转概率PITBU=0.02%.故故障模型如表1所示.

表1 故障模型表Table 1 Fault model
4 基于AdaBoost 的SDC错误检测框架
基于上述故障模型,本文提出了一种利用AdaBoost的SDC错误检测方法.方法流程如图 3所示.
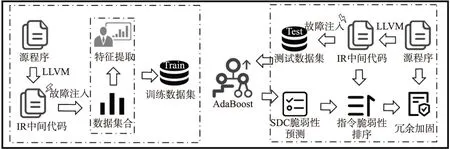
图3 利用AdaBoost的SDC错误检测方法流程图Fig.3 SDC error detection method flow based on AdaBoost
首先将源程序通过LLVM[20,21]编译器生成IR中间代码,通过故障注入生成数据集合以进行指令SDC脆弱性特征分析与提取,根据提取的SDC脆弱性特征和故障注入生成的数据集合来构建训练数据集.将所得数据集作为输入训练指令SDC脆弱性预测模型.然后使用训练过的模型来对故障注入得到的测试数据集中的指令SDC脆弱性进行预测,并根据预测值对指令进行SDC脆弱性排序.最后根据冗余粒度选择脆弱性高的部分指令对源程序进行冗余加固.
4.1 指令SDC脆弱性特征分析与提取
影响指令SDC脆弱性的因素有很多,为了更加准确的描述指令的SDC脆弱性,本节对指令的SDC脆弱性特征进行了分析与提取.
1)指令类型
指令类型是影响SDC脆弱性的一个重要因素.本文从MiBench测试程序集中选取了6个常用测试程序中的28种指令类型进行逐位故障注入实验.按照不同指令类型的SDC概率进行统计,以表示指令类型对SDC概率的影响.统计结果如图 4所示.

图4 不同指令类型SDC概率图Fig.4 SDC probability of different instruction types
可以看出,不同类型指令的SDC脆弱性具有较大差异.lshr移位指令,fcmp,icmp比较指令,fadd运算指令等指令具有较高的SDC脆弱性,而alloca,fptosi,mul,phi等指令具有较低的SDC脆弱性.故将指令类型作为一类指令SDC脆弱性特征,表示为Stype.
2)指令地址宽度
指令的地址宽度也是影响指令SDC的重要因素,指令的位数越多则发生单粒子翻转的概率越大,指令的SDC脆弱性也就越高.故将指令地址宽度作为一项指令SDC脆弱性特征,表示为Swidth.
3)指令调用次数
指令的调用次数影响着指令的SDC脆弱性.当指令处于分支,循环等结构内时,指令将会被多次调用执行,执行次数越多,对SDC脆弱性的贡献也就也大.故将指令调用作为一项指令SDC脆弱性特征,表示为Scall.
4)地址相关指令
地址相关指令发生单粒子翻转引发软错误后将大概率跳转到错误的地址,引起程序崩溃或挂起,不易发生SDC错误.该类指令的SDC脆弱性较低,故将地址相关指令作为一项指令SDC脆弱性特征,表示为Saddress.
5)数据操作
运算指令和读写指令等相关指令往往对数据进行访问,当其访问的数据受到单粒子翻转影响发生错误时,操作结果必将发生改变.根据数据变量的类型不同,其所占的数据位数也不同,故而对单粒子翻转的敏感度也不同.除此之外,指令操作的数据数量越大,其SDC脆弱性也就越高,所以将指令操作数据数量作为一类指令SDC脆弱性特征,表示为Sdata.
6)单粒子翻转位数
在第3节故障模型中已经介绍过,在一条指令内,指令单粒子翻转情况有单位翻转,双位翻转和三位翻转3种类型,翻转位数越多,程序运行出错的概率就越大,故而该指令的SDC脆弱性也就越大.因此,本文将单粒子翻转位数作为一项指令SDC脆弱性特征,表示为Sdigit.
综上所述,指令SDC脆弱性特征向量如式(7)所示:
S={Stype,Swidth,Scall,Saddress,Sdata,Sdigit}
(7)
4.2 指令SDC脆弱性预测模型
AdaBoost是一种集成学习方法,能够将多个弱学习器集成得到一个精度较高的强学习器[22,23].AdaBoost的主要优势如下:
1)本文提取的特征数据类型为整型和布尔类型,AdaBoost适用于上述两类数据类型.
2)相较于其他机器学习算法,AdaBoost具有较高的收敛速率,并且不容易造成过拟合现象,这将为模型提供更高的预测准确率.
3)AdaBoost在每次训练后调整样本权重,用以训练下一个弱学习器,故而不需要进行特征筛选,操作简单,具备较强的泛化能力.
基于AdaBoost上述优点,本文选取AdaBoost回归算法来训练指令SDC脆弱性预测模型,如图 5所示.

图5 AdaBoost回归构造图Fig.5 AdaBoost regression structural
首先对训练数据集赋予初始权重进行训练,得到弱学习器决策树1.
本文将训练数据集Tset定义如下:
(8)

训练数据集在第k个决策树的权重Wk为:
Wk=(wk1,wk2,…,wkm)
(9)
其中,wkm表示k个决策树中第m组训练样本所占的权重.
初始化训练数据集权重W1为:
(10)
使用具有权重Wk的训练数据集进行训练,得到弱学习器决策树SDCk(S).
然后基于决策树1的学习误差率e1来调整训练样本的权重值,将之前决策树1在训练样本中学习误差率高的点的权重提高,使得决策树2对这些点给予更多的重视.
学习误差率ek的计算方法如下所示:
(11)
(12)
(13)
其中,SDCk(si)为第k个决策树针对第i组样本的指令SDC脆弱性预测值,Ek为第k个决策树在训练数据集上的最大误差,eki为其中每个样本的相对误差.
第k个决策树权重系数αk计算方法如下所示:
(14)
对于更新样本权重W,第k+1个决策树的样本集权重系数为:
(15)
其中Zk为规范化因子:
(16)
最后以更新权重后的训练集为基础,对决策树2进行训练.重复执行上述步骤,直到决策树的数量达到预定数值N,最终取这N个决策树中权值中位数的决策树为强学习器,得到基于AdaBoost 的SDC脆弱性预测模型如下所示:
f(x)=SDCk*(S)
(17)

4.3 指令冗余加固算法
执行完指令SDC脆弱性预测操作后,需要根据预测结果对目标程序进行冗余加固处理.步骤如下:
1)根据模型预测出的指令SDC脆弱性值,从高到低对目标程序指令集合I进行排序,建立指令SDC脆弱性序列表;
2)在指令SDC脆弱性序列表中按照冗余粒度o选取冗余指令集合IR,并进行冗余操作;
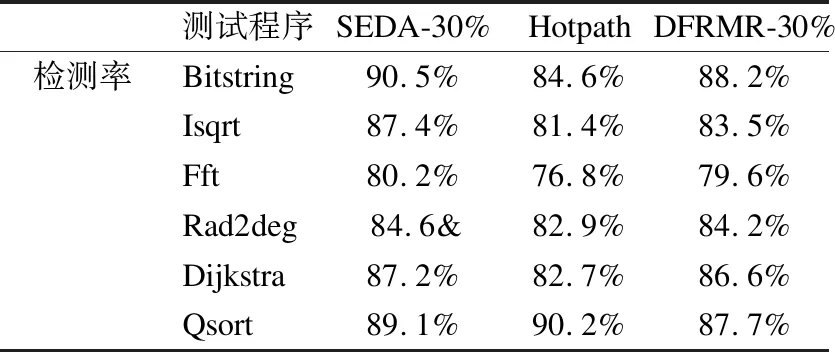
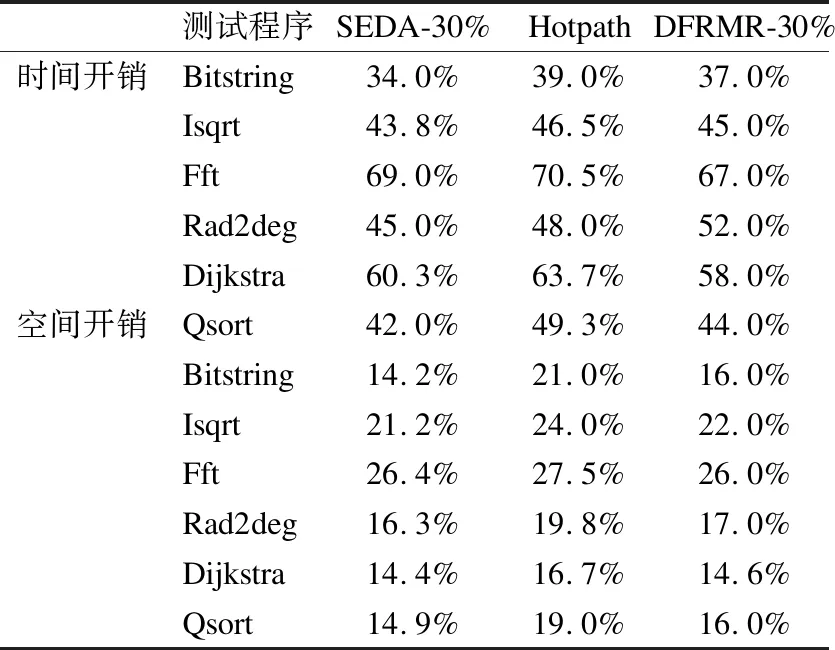
3)遍历冗余指令集IR中所有指令,若指令IR[i]依赖于指令IR[j],且j 4)比较指令比较原始指令与冗余指令的运行结果,相同则判断程序运行正确,不同则判断发生了SDC错误. 算法描述如算法1所示: 算法1.指令冗余加固 输入:指令集I,指令集大小O,冗余粒度o 输出:插桩后的指令集ID sort_instructions(I,O)//根据SDC脆弱性对指令集排序 OR←⎣O*o」//冗余指令集大小 IR←choose_instructions(I,OR)//按照冗余粒度选择冗余指令集 forj← 1toORdo clone_instruction(IR[j-1])//复制指令并插在下一条指令前 ifjudge_used(IR[j-1])= 0do//判断是否存在定义引用关系 ID← insert_check_instruction(IR[j-1])//插入检测指令 end else IR[i]← find_last_used_ins(IR[j-1])//找到引用链最后一条指令 ID← insert_check_instruction(IR[i])//在基本块末尾插入检测指令 end end 为了验证本文提出的利用AdaBoost的SDC错误检测方法的性能,本节设计了两项性能评估实验,分别为指令SDC脆弱性预测实验和SDC错误检测实验.实验环境如表 2所示. 表2 实验环境表Table 2 Experimental environment 测试用例选取了MiBench测试程序组中的6个测试程序,包括Bitstring、Isqrt、FFT、Rad2deg、Dijkstra和Qsort.所选的测试程序首先使用LLVM编译以获得中间(IR)指令,然后执行LLVM Pass以提取程序指令特征. 本文采用基于LLFI[24]二次开发的故障注入工具对目标程序进行故障注入.在故障注入过程中,根据第3节所述故障模型注入3种类型的指令位翻转故障来模拟实际辐射情况中的单粒子翻转故障. 预测指令的SDC脆弱性是SDC错误检测的关键环节.对于本文提出的SEDA模型,在模型参数设置时采用控制变量法对模型进行训练学习以寻求参数最优解,得到部分参数的MSE(Mean Square Error,均方误差)变化曲线如图 6所示. 图6 部分参数的MSE变化曲线图Fig.6 MSE curve of some parameters 可以看出在决策树数量为20时模型的MSE取到最小值,学习率为0.008时对应的MSE最小.同时AdaBoost算法对于回归问题,常使用指数函数作为损失函数,故SEDA模型参数如表 3所示. 表3 模型参数表Table 3 Model parameters 为了验证本文提出的SEDA模型的有效性,本节设计了对照实验,现选取其他常用机器学习模型算法作为对照组,对照模型算法包括支持向量回归算法SVR,随机森林算法RF和GBDT.通过本文二次开发的故障注入工具对6个测试程序各进行10000次故障注入,通过LLVM Pass收集指令SDC脆弱性数据样本作为模型输入.最后计算模型的均方误差和判定系数(R-squared,R2)来评估我们的模型的预测准确度.实验结果如表 4所示. 表4 预测实验结果表Table 4 Prediction experiment result 从实验结果可以看出,SVR和RF在大部分测试用例中所获得的MSE值均不理想,这是因为其模型特性容易受到噪声数据干扰,进而影响模型预测精度.相比之下,本文提出的SEDA模型在所有测试用例中均获得了较低的MSE值,虽然GBDT在大多数测试程序上的MSE值与SEDA相近,但在Qsort测试程序上取得了所有模型中的最高值,结合对应的R2值分析可以得出,GBDT在Qsort测试程序上发生了过拟合.而本文提出的SEDA模型在所有测试用例中都有着较高的R2值,这是因为SEDA模型在每次训练后都会根据学习误差率来调整训练集的权重并训练下一个弱学习器,从而能够更好地对数据进行拟合,提高模型预测准确性. 综上所述,在所选4种模型算法中,本文提出SEDA模型对数据的拟合效果最好,预测精度最高. 本节设计了对比实验来验证本文提出方法的SDC检错能力.对照实验组包括Hotpath方法[25]和30%冗余粒度的DFRMF方法[26].实验首先使用基于本文故障模型二次开发的故障注入工具对6个测试程序各自进行2000次故障注入.根据前期实验数据分析,本文选取30%的冗余粒度进行实验,在该粒度下模型能够在保证较高检测率的同时保证时空开销在较低的水平.实验从检错率,空间开销和时间开销3个方面对本文提出的方法进行评估. 如表 5所示为3种方法的SDC错误检测率,30%冗余粒度的SEDA,Hotpath和30%冗余粒度的DFRMR的平均检测率分别为86.5%,83.1%和85.0%.Hotpath在3种方法中取得了最低的错误检测率,究其原因是由于Hotpath方法采取的是对程序执行高频路径上的指令进行冗余的加固策略,忽略了高频路径外的SDC脆弱性指令,故而导致了该方法的检错率较低.而本文提出的SDC错误检测方法则有着较高的检错率,这是因为本文方法主要冗余SDC脆弱性高的指令,同时还考虑到了多位翻转对指令SDC脆弱性的影响,故而提高了错误的检测率. 表5 检测率对比表Table 5 Detection rate comparison table 如表 6所示为3种方法的时空开销对比,30%冗余粒度的SEDA,Hotpath和30%冗余粒度的DFRMR的平均时间开销分别为49.0%,52.8%和50.5%,平均空间开销分别为17.9%,21.3%和18.6%.可以看出,本文提出的SDC错误检测方法的时空开销较其他两种方法更低,这是因为本文方法通过分析冗余指令之间的定义引用关系,减少了比较指令的插桩数量.而且在诸如FfT和Dijkstra等循环结构比重较大的程序中,本文方法的时空开销虽略有上升,但尚在可以接受的范围之内. 表6 时空开销对比表Table 6 Time and space cost table 综上所述,本文提出的利用AdaBoost的SDC错误检测方法能够在较低的时空开销下获得较高的SDC错误检测率. 针对SDC错误难以检测,且现有方法多侧重于单位翻转的问题,本文改进了故障模型,将物理空间中的多位翻转映射到单一指令中,使得故障注入模拟更加贴近真实辐射情况.然后提出了一种利用AdaBoost的SDC错误检测方法SEDA,通过故障注入的方法获得指令SDC相关特征和故障注入结果,训练机器学习模型预测指令SDC脆弱性,最后通过粒度可配置的指令冗余操作加固源程序以达到检测SDC错误的目的.通过本文设计的对比实验验证,本文所提出的利用AdaBoost的SDC错误检测方法与现有方法相比,具有更低的时空开销和更高的检测率.5 实验与分析

5.1 指令SDC脆弱性预测实验



5.2 SDC错误检测实验
6 结 论
